邻近粽子节,KWDB 的朋友给我发消息,问我吃过红茶味的粽子没,作为北方人的我一般只吃蜜枣白粽,还没见过茶香粽子,顶多泡碗祁红,就着茶水吃粽子。
她又问道,两个月时间到了,你准备好了么。我这才反应过来,原来是【KWDB 2025 创作者计划】征稿截止日期要到了,我只是 Star 了一下 gitee.com/kwdb/kwdb 这个“Gitee 最有价值开源项目”,连 README 还没看完。只好来杯白雾红尘醒醒脑,挑灯夜读 KWDB,争取一夜写一页。
KaiwuDB 小羊毛
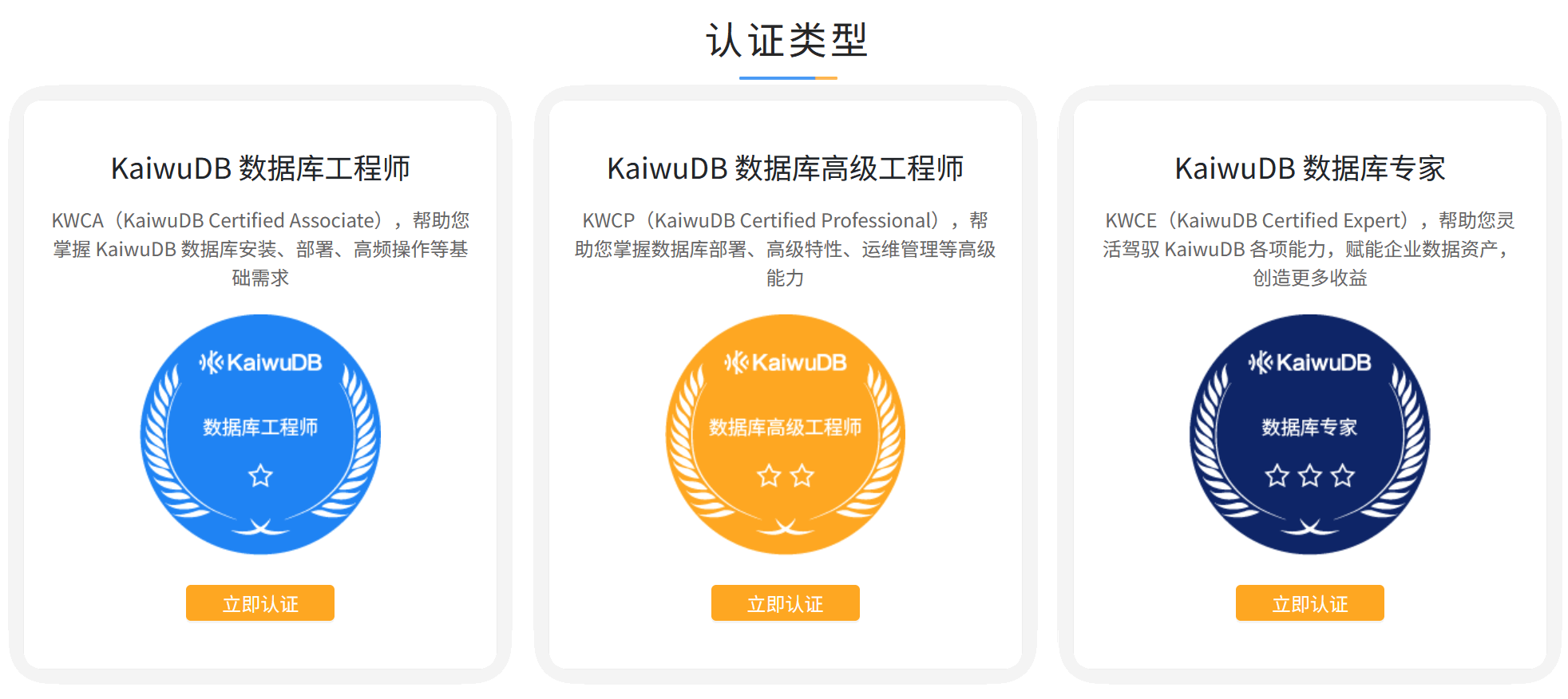
其实我对 KaiwuDB 倒不是全然陌生。去年抽空读了几篇官方文档,顺利考到了一个“KaiwuDB 数据库工程师 KWCA(KaiwuDB Certified Associate)”认证。

KWCA 认证主要考察 KaiwuDB 数据库安装、部署、高频操作等基础知识,考试形式为选择题,登录官方网站即可预约考试。
在考 KWCA 认证之前,请认真读完下面这段文字。
KaiwuDB 是一款分布式多模数据库,定位于满足广泛行业需求的数据库解决方案。其架构既包含分布式和单机数据库类型,又涉及数据库和数据库管理系统两部分,是信息系统中承上启下的核心环节。
KaiwuDB 面向工业互联网、数字能源、车联网和智慧产业等多个行业领域,在多个场景实现落地实践。提供自适应时序、事务处理和预测分析等多种引擎,支持模型的全生命周期管理。具备时间对齐、数据补齐、查询优化等功能,支持多种数据类型和标签列操作,允许灵活的生命周期设置。
KaiwuDB 支持多种操作系统和开发语言,可通过多种方式连接和写入数据。在知识产权方面成果显著,并已获超 300 项发明专利。

看到这里,相信你对 KaiwuDB 已经有所了解,欢迎点击下方链接预约 KWCA 认证考试,也许这将是你第一个数据库认证。
https://www.kaiwudb.com/learning/
关于 KWDB
上海沄熹科技有限公司 是浪潮在基础软件领域重点布局的数据库企业。以面向 AIoT 的分布式多模数据库 KaiwuDB 为核心产品,致力于打造自主、先进、安全、创新的数据库产品及数据服务平台。
5 月 23 日,第一新声《2025 年度中国数据库优秀厂商图谱》正式发布,KaiwuDB 成功入选“时序数据库”和“其他非关系型数据库”优秀厂商。
5月27日,中国信息通信研究院联合产学研各界力量,正式在京成立“开源创新发展推进中心(OpenCenter)”,旨在搭建开源协作枢纽平台,全面赋能数字技术产业协同创新。浪潮 KaiwuDB 凭借近年来在核心技术研发、行业标准建设、开源生态贡献等方面的突出表现通过严格遴选,成为 OpenCenter 首批高级别成员单位。

KWDB 基于浪潮 KaiwuDB 分布式多模数据库研发开源,典型应用场景包括但不限于物联网、能源电力、交通车联网、智慧政务、IT 运维、金融证券等,旨在为各行业领域提供一站式数据存储、管理与分析的基座,助力企业数智化建设,以更低的成本挖掘更大的数据价值。KWDB 包含 KaiwuDB 企业版除 AI 驱动自治和预测分析引擎外的全部能力。
KWDB 存储引擎
1. 关系引擎
要想探索 KWDB 更多技术细节,只看文档是远远不够的,还需要上手实操,甚至翻阅代码。
启动 KWDB 后,在日志中看到这段输出。信息提示,KWDB 当前使用 RocksDB 存储引擎。
KWDB node starting at 2025-05-30 13:44:01.329674321 +0000 UTC (took 0.4s)
build: 2.2.0 @ 2025/03/31 07:20:02 (go1.16.15)
...
store[0]: path=/kaiwudb/deploy/kaiwudb-container
storage engine: rocksdb
RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。用户写入的键值对会先写入磁盘上的 WAL (Write Ahead Log),然后再写入内存中的跳表(MemTable)。LSM-tree 引擎由于将用户的随机修改(插入)转化为了对 WAL 文件的顺序写,因此具有比 B 树类存储引擎更高的写吞吐。
RocksDB 为 KWDB 的关系表提供底层数据存储能力,将表数据(行记录)以 Key-Value 形式持久化。RocksDB 的原子写入和 MVCC(多版本并发控制)特性帮助 KWDB 实现 ACID 事务,确保数据一致性。适用于用户表、订单表等关系型数据。
通过 KCD 查看 KWDB 的 RocksDB 配置参数。

也可通过 kwbase 客户端实用 SHOW CLUSTER SETTING 语句查看 kv 相关集群设定。
[shawnyan@kwdb ~]$ podman exec -it kwdb1 ./kwbase sql --host=0.0.0.0:26257 --certs-dir=/kaiwudb/certs -e 'show cluster settings' | grep 'variable\|kv'variable | value | setting_type | descriptionkv.allocator.load_based_lease_rebalancing.enabled | true | b | set to enable rebalancing of range leases based on load and latencykv.allocator.load_based_rebalancing | leases and replicas | e | whether to rebalance based on the distribution of QPS across stores [off = 0, leases = 1, leases and replicas = 2]kv.allocator.qps_rebalance_threshold | 0.25 | f | minimum fraction away from the mean a store's QPS (such as queries per second) can be before it is considered overfull or underfullkv.allocator.range_rebalance_threshold | 0.05 | f | minimum fraction away from the mean a store's range count can be before it is considered overfull or underfullkv.bulk_io_write.max_rate | 1.0 TiB | z | the rate limit (bytes/sec) to use for writes to disk on behalf of bulk io opskv.closed_timestamp.follower_reads_enabled | true | b | allow (all) replicas to serve consistent historical reads based on closed timestamp informationkv.protectedts.reconciliation.interval | 5m0s | d | the frequency for reconciling jobs with protected timestamp recordskv.range_split.by_load_enabled | true | b | allow automatic splits of ranges based on where load is concentratedkv.range_split.load_qps_threshold | 2500 | i | the QPS over which, the range becomes a candidate for load based splittingkv.rangefeed.enabled | true | b | if set, rangefeed registration is enabledkv.replication_reports.interval | 1m0s | d | the frequency for generating the replication_constraint_stats, replication_stats_report and replication_critical_localities reports (set to 0 to disable)kv.snapshot_rebalance.max_rate | 8.0 MiB | z | the rate limit (bytes/sec) to use for rebalance and upreplication snapshotskv.snapshot_recovery.max_rate | 8.0 MiB | z | the rate limit (bytes/sec) to use for recovery snapshotskv.transaction.max_intents_bytes | 262144 | i | maximum number of bytes used to track locks in transactionskv.transaction.max_refresh_spans_bytes | 256000 | i | maximum number of bytes used to track refresh spans in serializable transactions
[shawnyan@kwdb ~]$
设定类型 setting_type 包含如下可能的值:
- b (true 或 false)
- z (以字节为单位的大小)
- d (持续时间)
- e (集合中的某个值)
- f (浮点值)
- i (整型)
- s (字符串)
这些集群设定可通过 SET CLUSTER SETTING 语句在线修改。以下是几个重要参数释义。
kv.allocator.load_based_lease_rebalancing.enabled
表示基于负载和延迟重新平衡 Range 租约。默认开启。
kv.allocator.load_based_rebalancing
表示基于存储之间的 QPS 分布重新平衡。0 表示不启动,1(leases) 表示重新平衡租约,2(leases and replicas) 表示平衡租约和副本。默认值为 2。
kv.allocator.qps_rebalance_threshold
表示存储节点的 QPS 与平均值之间的最小分数,用于判断存储节点负载是否过高或过低。
kv.allocator.range_rebalance_threshold
表示存储的 Range 数与平均值的最小分数,用于判断存储节点负载是否过高或过低。
当新节点加入时,新节点会向其他节点传达自身的信息,表明其有可用空间。然后,集群会将一些副本重新平衡到新节点上。当有节点下线时,如果 Raft 组的成员停止响应,5 分钟后,集群将开始重新平衡,将故障节点持有的数据复制到其他节点上。
重新平衡是通过使用来自租约持有者的副本快照,然后通过 gRPC 将数据发送到另一个节点来实现的。传输完成后,具有新副本的节点将加入该范围的 Raft 组;然后,它检测到其最新时间戳位于 Raft 日志中最新条目之后,并自行重放 Raft 日志中的所有操作。
租约和副本还会根据集群内节点间的相对负载(发生负载倾斜的情况)自动重新平衡。当某个节点的 Range 数量或数据量超过阈值,也会触发重新平衡。判断依据由参数 kv.allocator.qps_rebalance_threshold 和 kv.allocator.range_rebalance_threshold 控制。
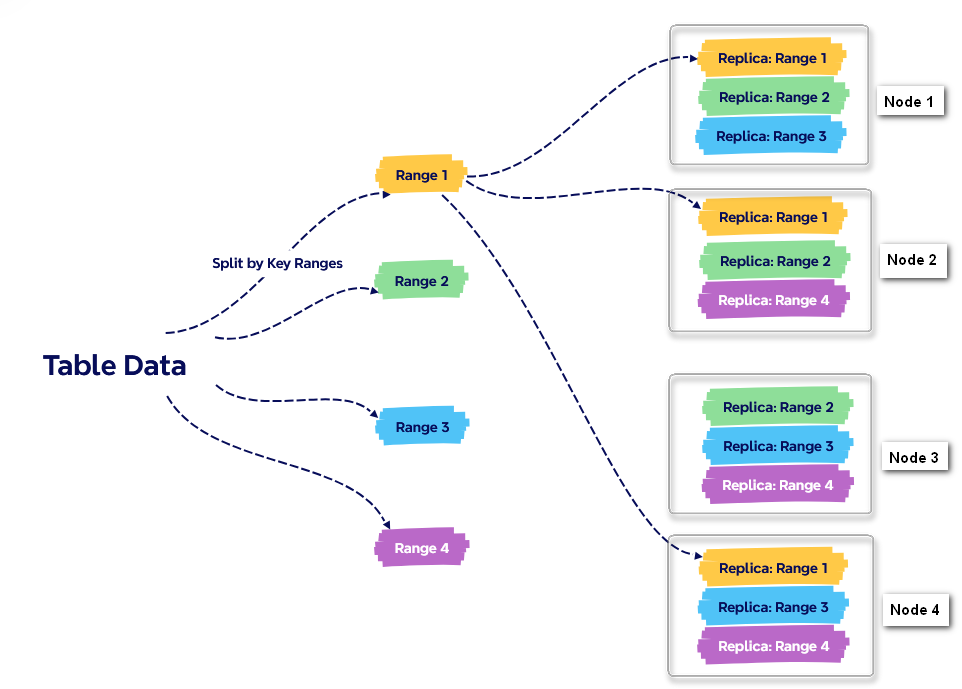
2. 关系数据分片
从上面的内容我们了解到,关系数据写入 KWDB 数据库后,会转化为键值对,经排序后存入内置的 RocksDB 引擎中。在 KWDB 中,这个键空间被划分为多个键空间中的连续块,即数据分片(RANGE)。数据分片的大小达到 512 MiB 后,系统会自动将其拆分为两个数据分片。
我们可通过以下 SQL 语句修改数据库级的数据分片大小以及副本数。
ALTER DATABASE mytest CONFIGURE ZONE USINGrange_min_bytes = 134217728, -- 128 MiBrange_max_bytes = 536870912, -- 512 MiBnum_replicas = 3
;
查看修改后的设定信息。
root@0.0.0.0:26257/mytest> select raw_config_sql,full_config_yaml from kwdb_internal.zones where database_name = 'mytest';raw_config_sql | full_config_yaml
---------------------------------------------+-----------------------------ALTER DATABASE mytest CONFIGURE ZONE USING | range_min_bytes: 134217728range_min_bytes = 134217728, | range_max_bytes: 536870912range_max_bytes = 536870912, | gc:num_replicas = 3 | ttlseconds: 90000| num_replicas: 3| constraints: []| lease_preferences: []|
(1 row)
数据分片的合并与拆分由如下设定控制。

以四节点三副本为例,当表的数据写入 KWDB 数据后,系统会自动拆分成数据分片,并将副本自动平衡到不同节点。
3. 查看数据分区
新建一张表 city,并写入测试数据。
create table city (city_id int, city_name varchar(50));
insert into city select generate_series(1,10),'beijing' || generate_series(1,10)::string;
insert into city select generate_series(11,20),'shanghai' || generate_series(11,20)::string;
insert into city select generate_series(21,30),'jinan' || generate_series(21,30)::string;
查看数据分区。
root@0.0.0.0:26257/mytest> show ranges from table city;start_key | end_key | range_id | range_size_mb | lease_holder | lease_holder_locality | replicas | replica_localities
------------+---------+----------+---------------+--------------+-----------------------+----------+---------------------NULL | NULL | 59 | 139.780743 | 1 | region=NODE1 | {1} | {region=NODE1}
(1 row)
再次写入一些数据,并查看数据分区。可以看到表 city 已经拆分成两个数据分区。
root@0.0.0.0:26257/mytest> insert into city select * from city;
INSERT 2800002Time: 28.208673582sroot@0.0.0.0:26257/mytest> commit;
ERROR: there is no transaction in progress
root@0.0.0.0:26257/mytest> show ranges from table city;start_key | end_key | range_id | range_size_mb | lease_holder | lease_holder_locality | replicas | replica_localities
-----------------------+----------------------+----------+---------------+--------------+-----------------------+----------+---------------------NULL | /1077450434441084929 | 59 | 196.222032 | 1 | region=NODE1 | {1} | {region=NODE1}/1077450434441084929 | NULL | 60 | 207.999994 | 1 | region=NODE1 | {1} | {region=NODE1}
(2 rows)Time: 2.283246ms
4. 垃圾回收
对表 city 进行截断(TRUNCATE),再次写入数据,如此多次执行后,可以发现 mytest 库存在多个 city 表的数据分片。
root@0.0.0.0:26257/mytest> show ranges from database mytest;table_name | start_key | end_key | range_id | range_size_mb | lease_holder | lease_holder_locality | replicas | replica_localities
-------------+----------------------+----------------------+----------+---------------+--------------+-----------------------+----------+---------------------city | NULL | NULL | 54 | 0.00054 | 1 | region=NODE1 | {1} | {region=NODE1}city | NULL | NULL | 55 | 0.002333 | 1 | region=NODE1 | {1} | {region=NODE1}city | NULL | /1077449334439772161 | 56 | 144.466007 | 1 | region=NODE1 | {1} | {region=NODE1}city | /1077449334439772161 | NULL | 57 | 0.36652 | 1 | region=NODE1 | {1} | {region=NODE1}city | NULL | /1077450434441084929 | 59 | 183.208223 | 1 | region=NODE1 | {1} | {region=NODE1}city | /1077450434441084929 | NULL | 60 | 96.353263 | 1 | region=NODE1 | {1} | {region=NODE1}
(6 rows)
而实际当前正在生效的数据分片只有后两个,前面的是执行截断操作后,并没有回收的分片。查看后台任务,可以看到存在正在运行的任务,任务类型为 SCHEMA CHANGE GC,运行状态正在等待 GC TTL。
GC TTL 由参数 gc.ttlseconds 控制,该参数表示垃圾收集之前将保留被覆盖的 MVCC 值的秒数,支持库级、表级控制。
如果数据库中的值被更新,或用于类似队列的工作负载,较小的 TTL 值可以节省磁盘空间并提高性能。设定较大的值将有助保留历史记录,用于数据回滚或备份。一般用途的数据库设定为 24 小时即可。
这里方便测试,临时将表 city 的 GC TTL 设定为一分钟。
root@0.0.0.0:26257/mytest> alter table city configure zone using gc.ttlseconds=60;
CONFIGURE ZONE 1
查看全局配置。
root@0.0.0.0:26257/mytest> SHOW ZONE CONFIGURATIONS;target | raw_config_sql
---------------------------------------------------+------------------------------------------------------------------------------
...DATABASE mytest | ALTER DATABASE mytest CONFIGURE ZONE USING| range_min_bytes = 134217728,| range_max_bytes = 536870912,| num_replicas = 3TABLE mytest.public.city | ALTER TABLE mytest.public.city CONFIGURE ZONE USING| gc.ttlseconds = 60
(9 rows)
再次对表 city 做 TRUNCATE 操作,验证垃圾回收功能。
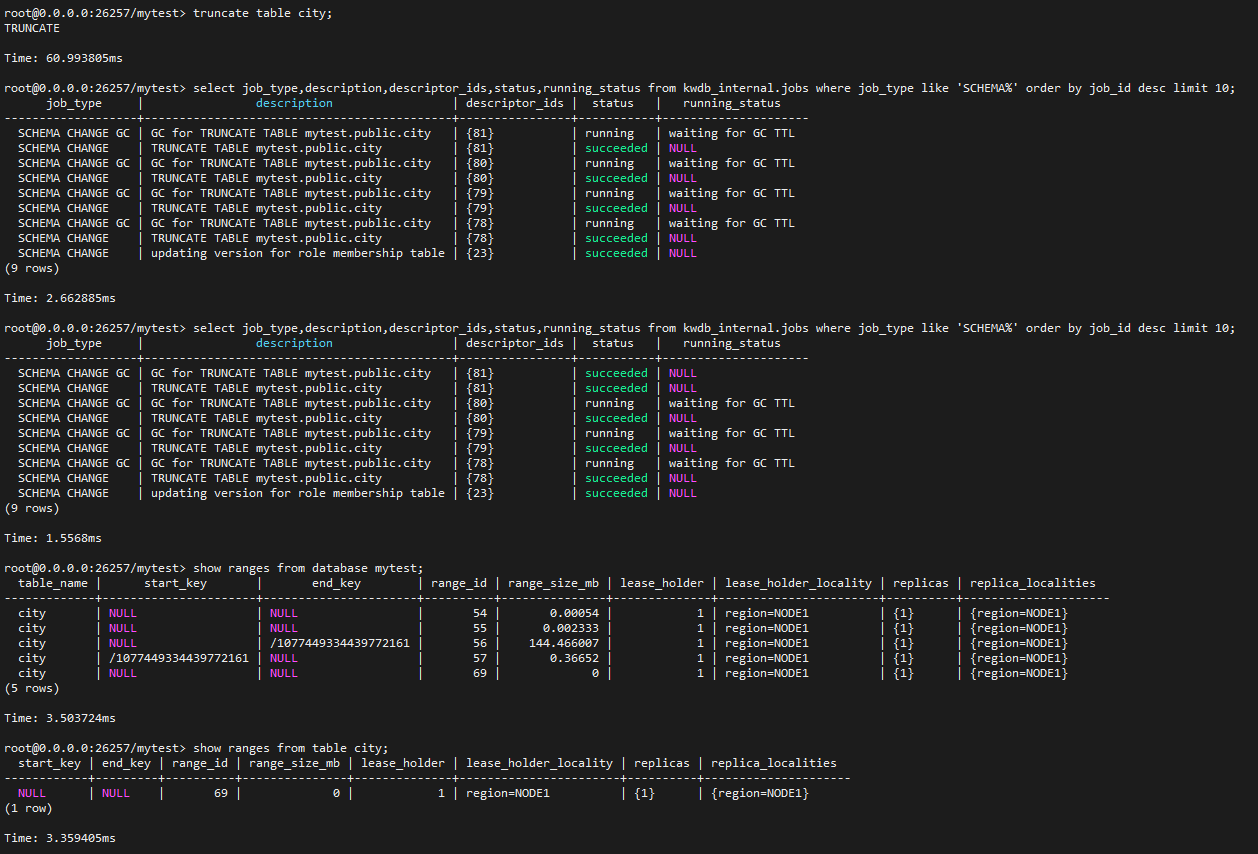
可以看到最新一条的 SCHEMA CHANGE GC 已经完成,但是由于之前的 GC 任务集成库级设定,时间较长,所以还处于等待状态。
5. 时序表
时序表(TIME SERIES TABLE)是用于存储时间序列数据的数据表。
创建时序数据库的语法。
CREATE TS DATABASE mytsdb RETENTIONS 30d PARTITION INTERVAL 1d;
RETENTIONS 表示数据库的生命周期设置为 30 天,默认为 0d,表示永不过期。PARTITION INTERVAL 表示数据目录分区时间范围分别设置为 1d。
创建时序表。
create table sensor_data (
ts timestamp not null,
value float not null)
tags ( sensor_id int not null )
primary tags (sensor_id)
RETENTIONS 7d ACTIVETIME 1d PARTITION INTERVAL 1h;
ACTIVETIME 表示数据的活跃时间。超过设置的时间后,系统自动压缩表数据。默认值为 1d,表示系统对表数据中 1 天前的分区进行压缩。
插入数据。
INSERT INTO sensor_data VALUES ('2025-05-03 14:15:9.265', 35, 89);
INSERT INTO sensor_data VALUES ('2025-05-03 14:15:9.266', 36, 89);
INSERT INTO sensor_data VALUES ('2025-05-03 14:15:9.267', 37, 90);
查看查询时序表的执行计划。
root@0.0.0.0:26257/mytsdb> explain (TYPES) select * from sensor_data;tree | field | description | columns | ordering
---------------+-------------+----------------+--------------------------------------------------+-----------| distributed | true | || vectorized | false | |synchronizer | | | (ts timestamptz(3), value float, sensor_id int4) |└── ts scan | | | (ts timestamptz(3), value float, sensor_id int4) || ts-table | sensor_data | || access mode | tableTableMeta | |
(6 rows)
6. 跨模查询
KWDB 跨模查询是指支持在关系数据库和时序数据库之间进行数据检索,具体支持关联查询、嵌套查询、联合查询。
创建关系表 sensor,并写入测试数据。
create table sensor ( id int, sensor_name varchar(50) );insert into sensor values (89,'kwdb');
insert into sensor values (90,'shawnyan');
对关系表 sensor 和时序表 sensor_data 进行关联查询,查看跨模查询的执行计划。
explain analyze (TYPES)
select * from mytest.sensor t1
left join mytsdb.sensor_data t2
on t1.id = t2.sensor_id;
输出结果。
{"sql": "EXPLAIN ANALYZE (DISTSQL, TYPES) SELECT * FROM mytest.sensor AS t1 LEFT JOIN mytsdb.sensor_data AS t2 ON t1.id = t2.sensor_id","processors": [{"nodeIdx": 1,"inputs": [],"core": {"title": "TagReader/1","details": ["TableID: 85","mode: tableTableMeta","Out: @3","outtype: TimestampTZFamily","outtype: FloatFamily","outtype: IntFamily",
..."core": {"title": "TableReader/2",
..."core": {"title": "TSSynchronizer/3",
..."core": {"title": "HashJoiner/5","details": ["Type: LEFT OUTER JOIN","left(@1)=right(@3)","Out: @1,@2,@3,@4,@5","left rows read: 2","left stall time: 236µs","right rows read: 3","right stall time: 574µs","stored side: left","max memory used: 30 KiB"
还可使用 debug 参数,得到更为详细 trace 级别的日志。
root@0.0.0.0:26257/mytsdb> explain ANALYZE(DEBUG) select * from mytsdb.sensor_data;text
--------------------------------------------------------------------------------Statement diagnostics bundle generated. Download from the Admin UI (AdvancedDebug -> Statement Diagnostics History), via the direct link below, or usingthe command line.Admin UI: https://0.0.0.0:8080Direct link: https://0.0.0.0:8080/_admin/v1/stmtbundle/1077674149786714113Command line: kwbase statement-diag list / download
(6 rows)Time: 130.439666ms
下载生成的日志报告。
$ kwbase statement-diag list --certs-dir=/kaiwudb/certs
Statement diagnostics bundles:ID Collection time Statement1077667589529862145 2025-05-30 11:00:48 UTC SELECT * FROM sensor_dataNo outstanding activation requests.
$ kwbase statement-diag download 1077667589529862145 /tmp/1077667589529862145 --certs-dir=/kaiwudb/certs
7. 时序存储引擎
在了解如何创建时序表后,我们还需要了解时序数据如何存储。KWDB 使用自研时序存储引擎,相关代码在 kwdbts2 目录下。
https://gitee.com/kwdb/kwdb/tree/master/kwdbts2
翻阅代码后,与大家分享几个时序存储引擎的知识点。
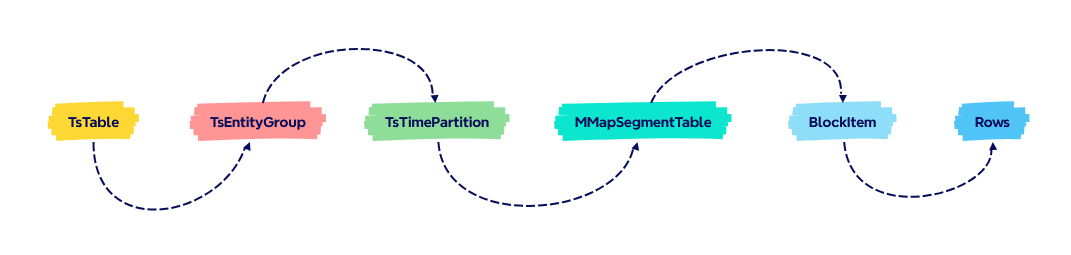
- TsTable
TsTable 表示 KWDB 中的时间序列表。它负责将数据组织成实体组,管理表模式和元数据,处理数据插入和查询操作,协调跨实体组的表操作。每个时间序列表都包含一个或多个实体组,这些实体组进一步组织数据,以实现高效的存储和检索。在分布式 v2 中,每个时序表只有一个实体组。
class TsTable {virtual KStatus CreateEntityGroup(kwdbContext_p ctx, RangeGroup range, vector<TagInfo>& tag_schema,std::shared_ptr<TsEntityGroup>* entity_group);virtual KStatusGetEntityGroup(kwdbContext_p ctx, uint64_t range_group_id, std::shared_ptr<TsEntityGroup>* entity_group);virtual KStatus GetEntityGroupByHash(kwdbContext_p ctx, uint16_t hashpoint, uint64_t *range_group_id,std::shared_ptr<TsEntityGroup>* entity_group);KStatus GetEntityGroupByPrimaryKey(kwdbContext_p ctx, const TSSlice& primary_key,std::shared_ptr<TsEntityGroup>* entity_group);};
- TsEntityGroup
TsEntityGroup 是一个核心抽象,它将相关时序实体分组在一起。每个实体组包含一个用于识别和查找实体的标签表,管理用于组织实体的子组集合,基于时间处理数据分区,协调跨分区的数据操作。实体组基于标签和时间分区,提供对时间序列数据的高效组织。
- TsTimePartition
TsTimePartition 表示实体组内基于时间的数据分区。它负责管理特定时间范围内的数据,将数据组织到分段表中,处理数据压缩和清理,使用预写日志功能协调数据操作。时间分区通过将同一时间范围内的记录分组,提供了一种高效地组织和查询基于时间的数据的方法。
MMapSegmentTable* TsTimePartition::createSegmentTable(BLOCK_ID segment_id, uint32_t table_version, ErrorInfo& err_info,uint32_t max_rows_per_block, uint32_t max_blocks_per_segment) {
- MMapSegmentTable
MMapSegmentTable 是一个底层存储组件,用于管理用于存储列式数据的内存映射文件。主要功能包括列式存储格式、内存映射文件管理、基于块的数据组织、支持定长和变长数据、聚合计算和缓存。分段表使用内存映射实现高效的数据访问,并为时间序列数据提供物理存储。一个段中可以容纳的最大 1000 个块。
- BlockItem
BlockItem 是用于存放时间序列数据行的固定大小容器,一个块中可以容纳的最大 1000 行。
可通过修改以下设定对最大值进行调整。
[shawnyan@kwdb ~]$ podman exec -it kwdb1 ./kwbase sql --host=0.0.0.0:26257 --certs-dir=/kaiwudb/certs -e 'show cluster settings' | grep 'var\|block'variable | value | setting_type | descriptionsql.ts_insert_select.block_memory | 200 | i | memory of block written at a time in ts insert selectts.blocks_per_segment.max_limit | 1000 | i | the maximum number of blocks that can be held in a segmentts.rows_per_block.max_limit | 1000 | i | the maximum number of rows that can be held in a block item
[shawnyan@kwdb ~]$
总结
KWDB 的分布式架构实现了水平扩展、容错和高可用性。只有深入了解 KWDB 的存储引擎,才能更好地了解分布式 SQL 写入和读取流程、跨模查询以及数据库调优。从 关系引擎到专门的时序存储引擎,KWDB 为不同数据类型提供了强大的存储和查询能力,并创新性的提出了关系和时序的跨模查询。无论是处理关系型数据还是时序数据,KWDB 都展现出其作为分布式多模数据库的强大功能和灵活性。希望在更多边缘计算、物联网和工业能源的项目中看到 KWDB 的身影。