概念
什么是进程优先级,为什么需要进程优先级,怎么做到进程优先级这是本文需要解释清楚的。
优先级的本质其实就是排队,为了去争夺有限的资源,比如cpu的调度。cpu资源分配的先后性就是指进程的优先级。优先级高的进程有优先执行的,配置进程优先级对多任务环境的Linux很有用,可以改善系统的性能。在Linux中进程的PCB也就是task_struct中优先级属性是有几个int类型的数字来表示的,数字越小优先级越高。这里我们可以查看一个进程的优先级和修改。我们用ps -l指令可以看到以下几个数据
![]()
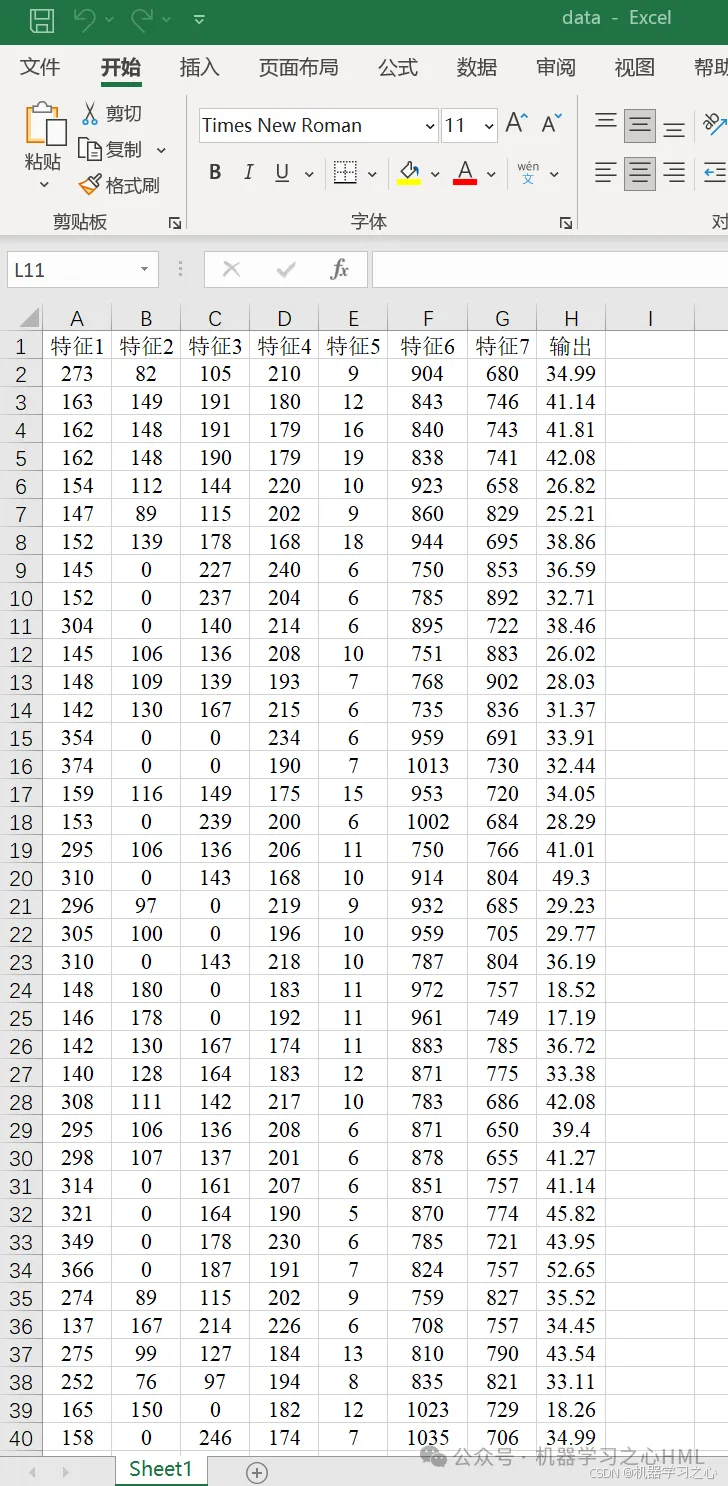
这里可以看到,PRI为39 NI值为19,这是我修改以后的数值,原本是PRI 20 NI 0,即使我输入修改100但是最后值修改了19,说明修改NI值是有范围的 ,这是为了进程调度尽量公平,不会出现个别极端进程,为什么是在这40的范围内后续我们会讲到。
进程切换
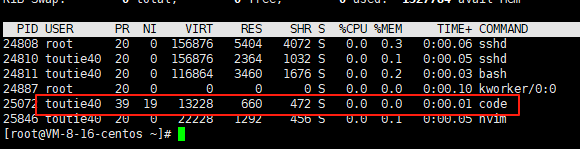
有了优先级就是为了在进程切换的时候进行排序,那么什么是进程切换?进程切换的核心其实就是保存上下文数据恢复上下文数据,那么什么是上下文数据,容我慢慢叙说。一个进程被被cpu调度的时候,此时它的PCB就是现在调度队列的当前节点,在CPU内部有一套寄存器来储存代码和数据,其中的eip来储存当前执行指令的下一地址,ir存储的是当前需要执行的指令,控制器先ir读指令执行,执行完毕又会反馈给eip寄存器。此时储存在寄存器中的代码和数据就是上下文数据。当前进程的时间片到了即将被切换的时候,它会将上下文数据储存到PCB中的一个tss_struct结构体中,方便下次切换回来的时候能够知道上一次运行到了哪里,恢复寄存器中的数据,每个程序在进程切换的时候都需要做这个事情,因为寄存器只有一套,这种行为是对进程代码数据运行的一种保护,如果不做保护就无法进行调度与切换。
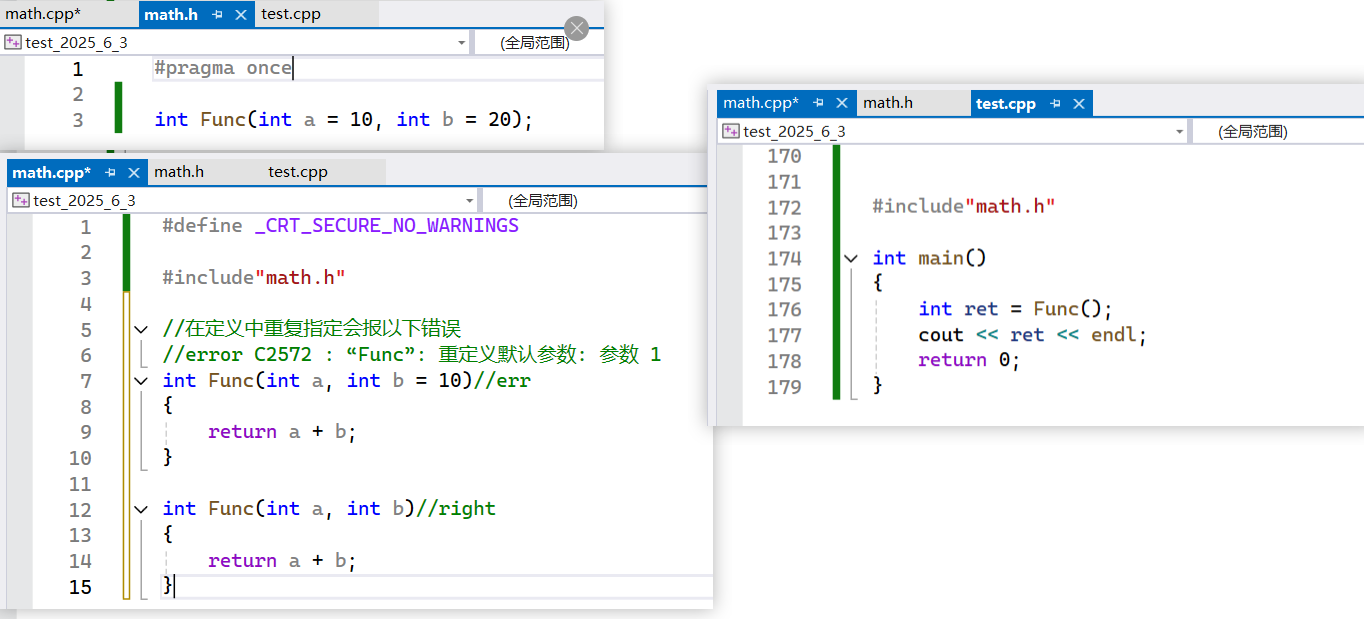
这里可以参考Linux0.11的内核代码发现上下文数据确实是保存在tss之中,但是在现在的内核中由于保护算法已经过于复杂了,没有十章八章难以叙述,所以而且不方便观察

Linux真实调度算法
说了这么多优先级的本质还是为了更好的了解Lniux调度算法。这个算法并不是简单的FIFO调度,cpu在调度进程时会在一个runqueue结构体中选择需要调度的进程,这个runqueue主要由一个有两个元素queue结构体数组,两个指向queue结构体数组的指针,*active和*expored即活跃的和过期的,以下用示意图说明。
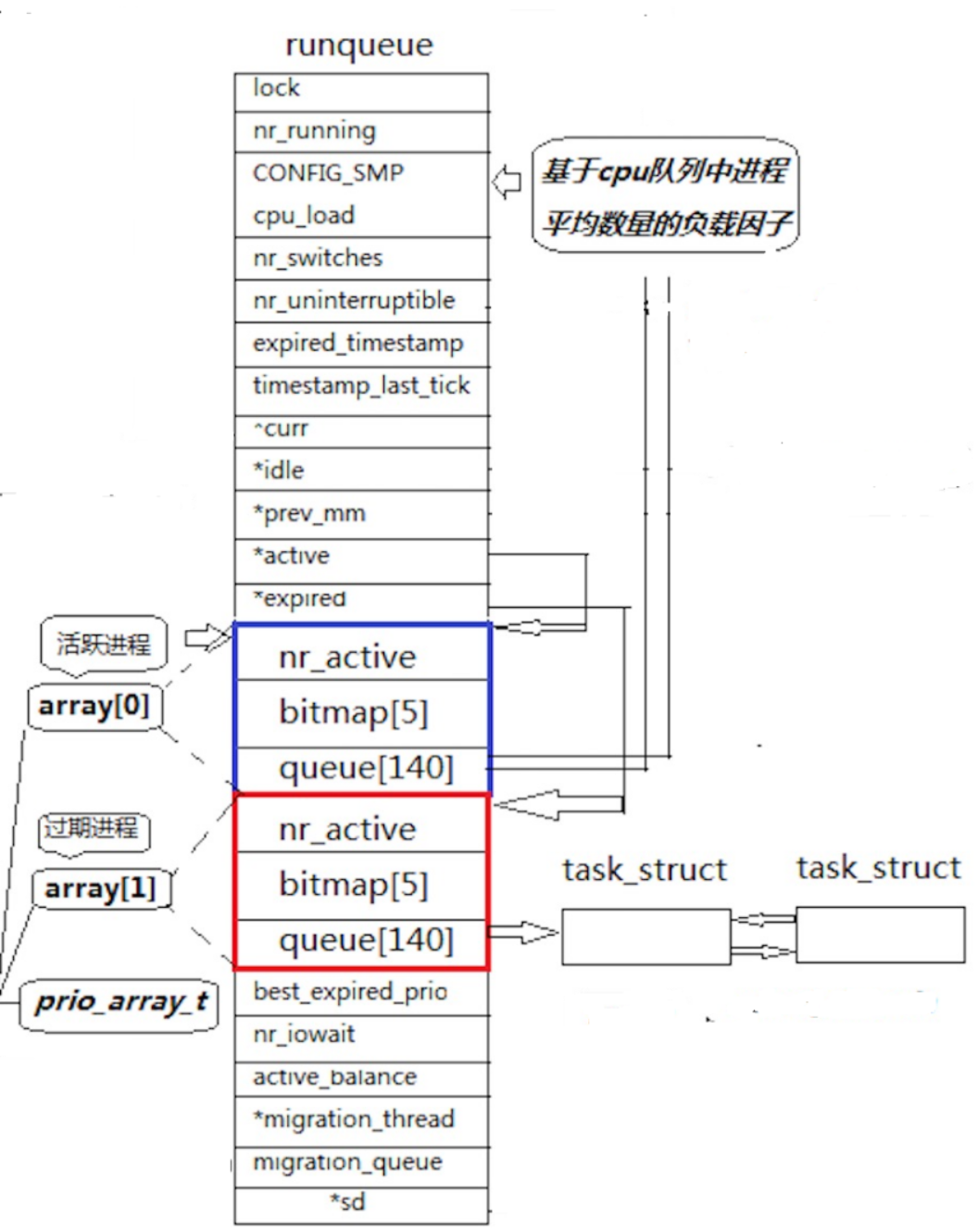
我们可以看到这这两个数组的元素的结构体时由一个int 类型的nr_active,和一个有五个元素int类型的bitmap数组组成的。*active和*expored指针分别指向这两个数组元素,cpu调度时只会从活跃指针这个结构体中的queue队列来调度进程,这个队列通常前一百位是不用的,而后四十位就是对应我们上面所提到的优先级范围,40这个范围就是因为队列中只有四十个位置是储存进程的。这个队列每个元素下又挂着一个哈希桶,所以每个相同优先级的进程都会被挂在同一个桶中,调度的时候按照队列先进先出的规则被调度,当这个优先级桶的元素空了cpu才会调度下一个优先级的进程。其中这里的nr_active是一个计数器,记录当前队列中还有多少个进程,bitmap是为了提高cpu调度效率而存在的,它用5*32个比特位来表示当前调度queue队列中哪个优先级有进程再去这个地方调度进程,而不是进行遍历队列查找再调度。过期队列上放置的进程,都是时间⽚耗尽的进程和新插入的进程,当活动队列上的进程都被处理完毕之后,对过期队列的进程进⾏时间⽚重新计算。active指针永远指向活动队列, expired指针永远指向过期队列, 可是活动队列上的进程会越来越少,过期队列上的进程会越来越多,因为进程时间⽚到期时⼀直都存在的,所以在合适的时候交换active指针和expired指针的内容,就相当于有具有了⼀批新的活动进程。这个合适的时候就是当活跃进程nr_active计数器为0的时候,此时两个两个队列就会被调换开始新一轮的调度。注意结束的进程是不会进入过期队列的,而是会被父进程接管并释放。
在系统当中查找⼀个最合适调度的进程的时间复杂度是⼀个常数,不随着进程增多⽽导致时间成 本增加,我们称之为进程调度O(1)算法!Linux中的内核调度算法就是进程调度O(1)算法。
顺便提到一点Linux中的task_struct中的链式结构并不是和普通双链表那样将节点和属性放在一起,它的链表节点中只有next节点和prev节点,然后在task_struct中和其他属性一起储存。这样做的好处是能够让一个task_struct在多个队列(调度和阻塞)中存在,而不需要将相同的进程属性放在不同的链表之中再链接。如图所示

补充
那么有的同学会问了只有链表节点如何访问数据,每个数据类型的偏移量相对于结构体指针是固定的,我们可以通过链表节点的地址和偏移量来找到当前结构体指针再访问其他的数据。我们可以通过offseto这个宏来获得该成员相对于0地址的偏移。
#define offsetof(type, member) ((size_t)&(((type *)0)->member))这里有一个代码可以方便大家理解具体过程
#include <iostream>#define offsetof(type, member) ((size_t)&(((type *)0)->member))
using namespace std;int main()
{struct A{int a;int b;float c;double d;};A instanceA; // Renamed variable to avoid conflict with struct namecout << " 结构体A的地址 : " << &instanceA << endl;cout << " 成员a的地址 :" << &instanceA.a << " 偏移量 :" << offsetof(A, a) << endl;cout << " 成员b的地址 :" << &instanceA.b << " 偏移量 :" << offsetof(A, b) << endl;cout << " 成员c的地址 :" << &instanceA.c << " 偏移量 :" << offsetof(A, c) << endl;cout << " 成员d的地址 :" << &instanceA.d << " 偏移量 :" << offsetof(A, d) << endl;return 0;
}我们可以看到两次运行的各个成员地址都不一样,但是偏移量都是相同的
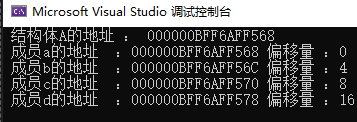
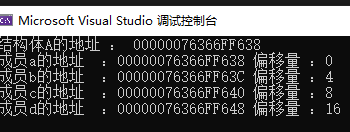
然后我们就可以通过这样的方法来找到对象本身从而访问其他的数据
int main() {A instanceA;int* pB = &instanceA.b;A* pStruct = (A*)((char*)pB - offsetof(A, b));cout << "instanceA 地址: " << &instanceA << endl;cout << "通过成员b地址和偏移量得到的结构体地址: " << pStruct << endl;return 0;
}![]()