前言:🐭🐭已经两年没更新了,主要原因是因为🐭🐭考研去了,前段时间读研和工作压力都比较大所以没时间更新,今后🐭🐭会慢慢恢复更新
1 流程和原理梳理
日志体系的解析可以详细看看Slf4j官网和Log4j2官网
整体的大致思路如下:
-
使用Slf4j作为门面统一API接口
-
一般公司都会选择Log4j2的绑定包来将Log4j2作为日志的实现类
-
基于Log4j2的万物即插件的思想,我们可以自定义appender用来指定日志IO输出的具体位置和实现
-
比如我们就可以把日志指定输出到Kafka的某一个具体的topic里
-
然后我们就可以使用ES和hive对Kafka进行消费,从而对日志数据进行检索增强以及持久化存储
1.1 Java日志框架介绍
在计算机程序设计领域,有一句至理名言:“没有什么问题是抽象一层不能解决的,如果有,那就再抽象一层。”
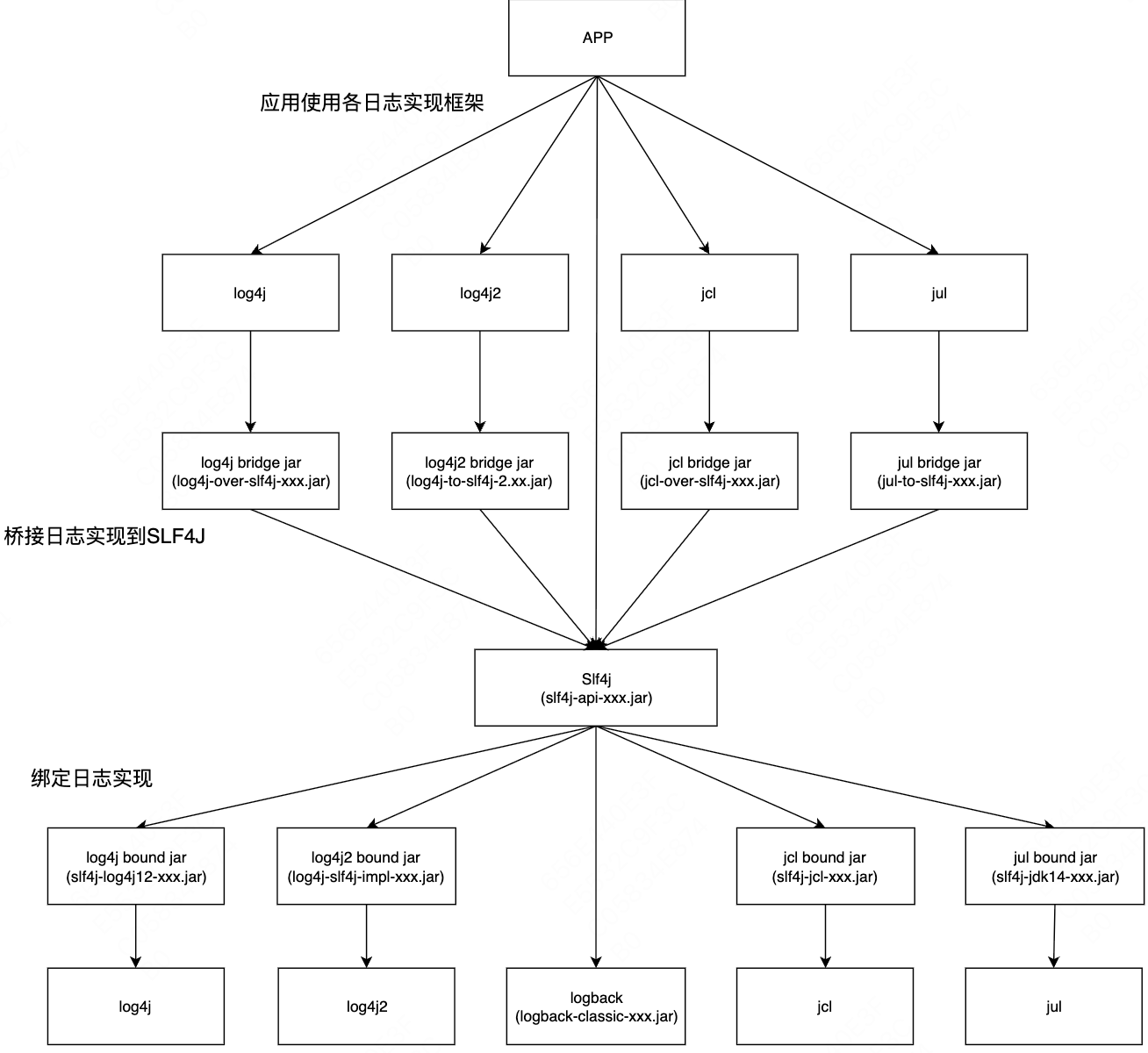
日志门面(Logging Facade)正是这种理念的体现。由于市面上存在众多不同的日志实现,应用程序往往会依赖于具体的日志实现。这种情况导致了第三方库引用的日志实现各不相同,最终使得应用程序的日志系统变得混乱,甚至影响到整个应用的正常运行。
在这种情况下,Slf4j(Simple Logging Facade for Java)应运而生。Slf4j的原理是通过抽象出一个高层API,使得应用程序无需依赖具体的日志实现。应用程序只需依赖Slf4j的API,而具体的日志实现则通过SPI(Service Provider Interface)机制来实现。
具体的日志实现负责实际的日志记录工作,兢兢业业地打印应用程序中的各种日志信息。通过这种方式,Slf4j有效地解决了日志实现混乱的问题,使得应用程序的日志系统更加统一和稳定。
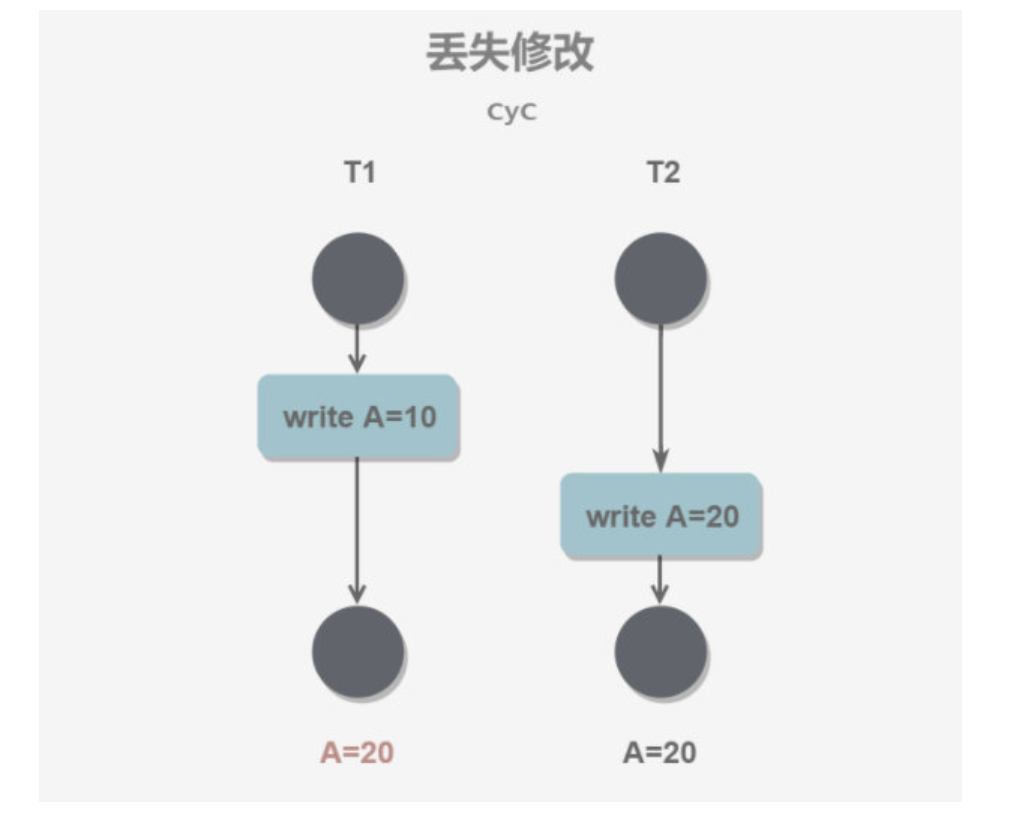
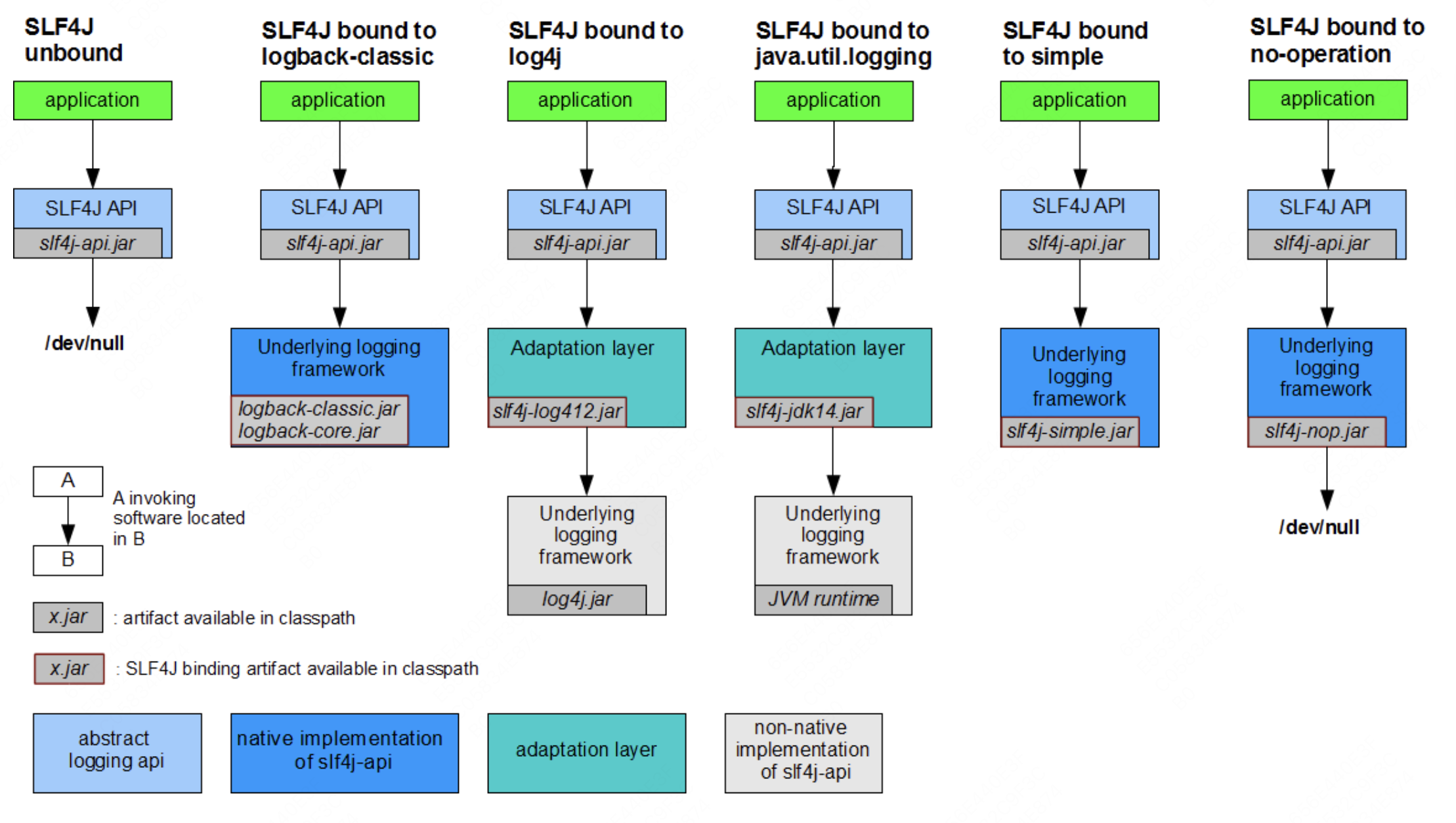
上图展示了各个日志框架之间的关系以及它们组合使用的方式(从上到下共分为六层)。所有的使用方式都由两部分组成:日志绑定包和日志桥接包。
PS:日志绑定包指的是具体的实现库,它们提供了实际的日志记录功能;日志桥接包则是用来解决已有代码依赖了不同日志系统的问题。
首先,日志绑定包(上图第5层)负责将具体的日志实现绑定到Slf4j上。Slf4j旨在成为日志标准,但其他日志框架并不认可它,拒绝实现其提供的API。无奈之下,Slf4j只能自己实现绑定包。因此,除了Slf4j自己的日志实现Logback之外,使用其他日志框架时都需要通过日志绑定包来绑定具体的日志实现。
其次,日志桥接包负责将应用或第三方包中直接使用的日志实现桥接到Slf4j上,再由Slf4j具体绑定的日志实现统一输出。这样解决了遗留项目中直接使用具体日志实现但仍希望接入Slf4j进行统一日志管理的问题,也解决了业务应用使用Log4j2而某些第三方包使用Log4j或jul等不同日志框架的日志输出问题。通过日志桥接包,可以将其他日志实现桥接到Slf4j上,然后由统一的日志实现完成日志输出。
Slf4j通过绑定包和桥接包的方式实现了日志管理的统一,最终市场份额不断扩大,成为了事实上的标准。虽然Slf4j最初没有为Log4j2提供绑定包和桥接包,但Log4j2也不得不顺应趋势,自己提供了Slf4j的绑定包(log4j-slf4j-impl-xxx.jar)和桥接包(log4j-to-slf4j-xxx.jar)。整个日志体系就形成了上图所示的关系图。
1.2 Slf4j实现日志桥接
首先我们来看一下Slf4j官网给出的图:
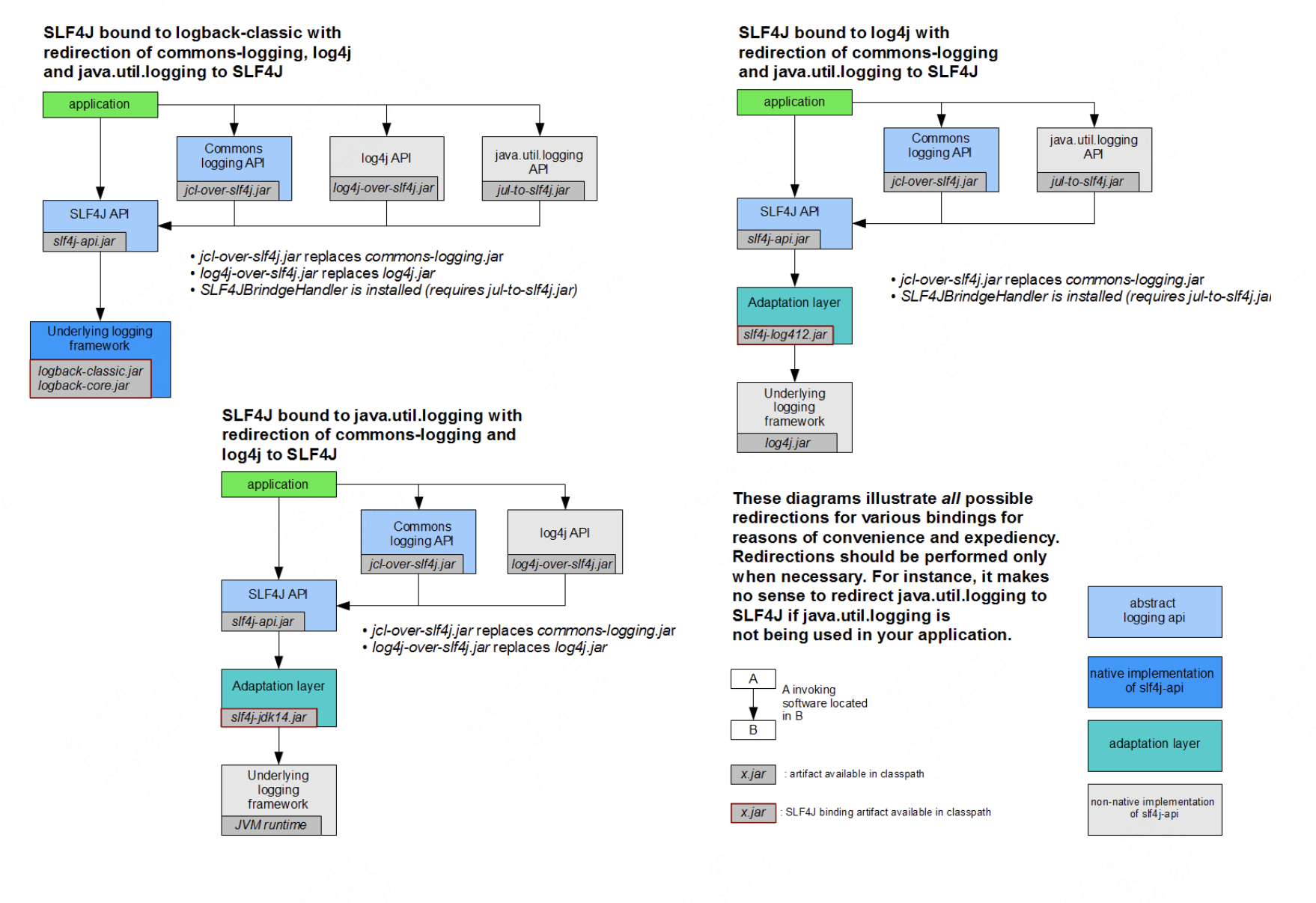
从上图可以看出,Slf4j的桥接功能是通过以下几个jar包实现的:log4j-over-slf4j.jar、jcl-over-slf4j.jar和jul-to-slf4j.jar。由于JCL和JUL日志框架已经基本退出历史舞台,我们在此不再详细讨论。如果您对此感兴趣,可以访问Slf4j官网获取更多信息。 接下来,我们重点介绍Log4j和Log4j2的桥接包实现方式:
1.2.1 Log4j的桥接包(log4j-over-slf4j-xxx.jar)的实现方式
Log4j的桥接包是由Slf4j实现的,但Log4j官方并不认可这种实现方式。这意味着Log4j的代码并未为Slf4j提供直接的实现权限。因此,Slf4j采用了一种较为直接的方法:使用桥接包中的类替换Log4j中的核心类。下图显示了桥接包中的类与日志实现包中的类的包名和类名完全一致
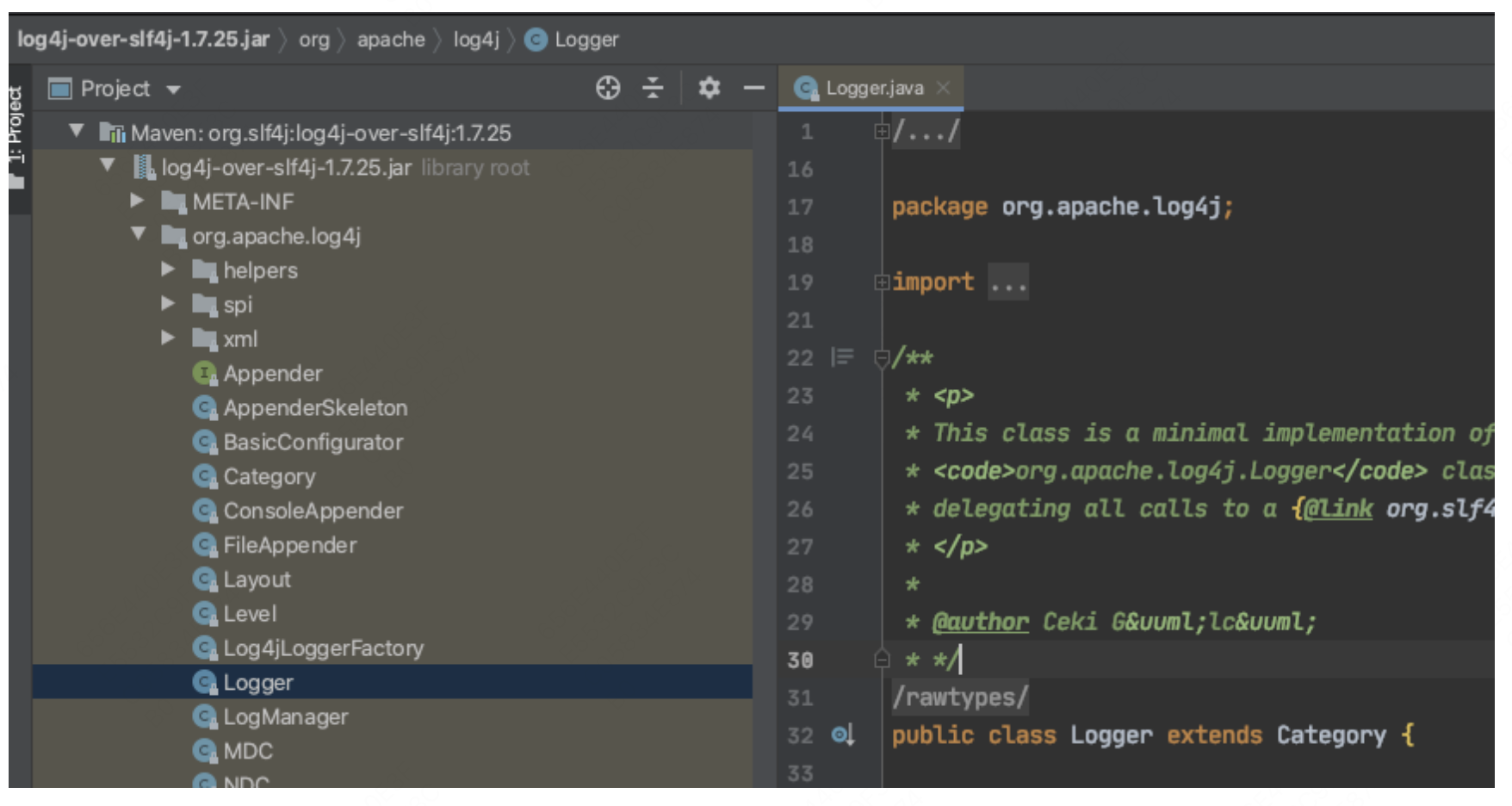
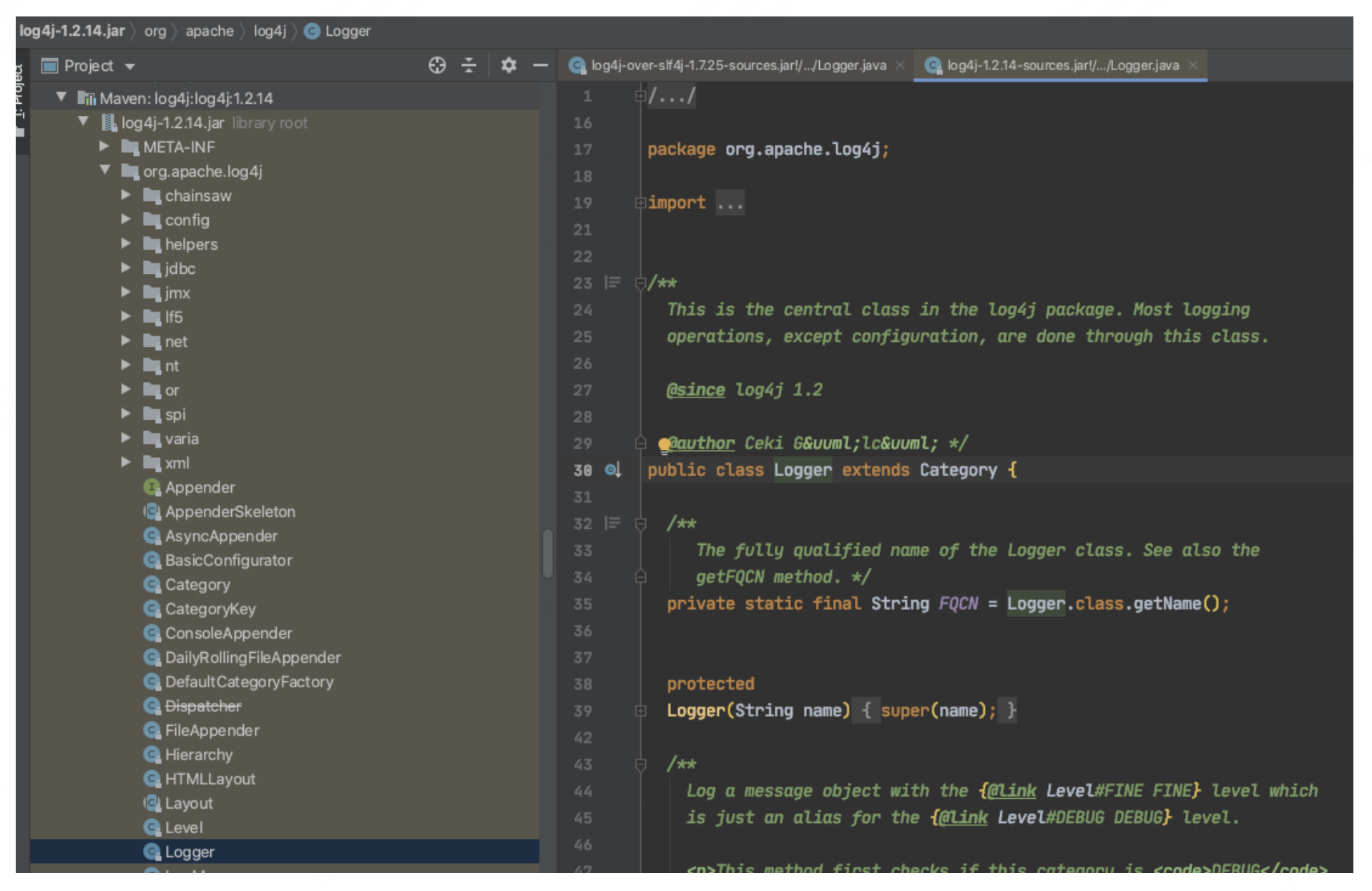
为了确保Slf4j能够正确管理具体的日志实现,我们在介绍Log4j桥接包的使用时特别强调需要排除所有原有的Log4j依赖。如果不排除这些依赖,可能会导致类重复,从而使JVM在加载时无法确定加载的是桥接包中的类,这样桥接包可能会失效。实际上,还有另一种解决方案,这种方案依赖于JVM的类加载机制,我们将在后续的问题分析中详细介绍。
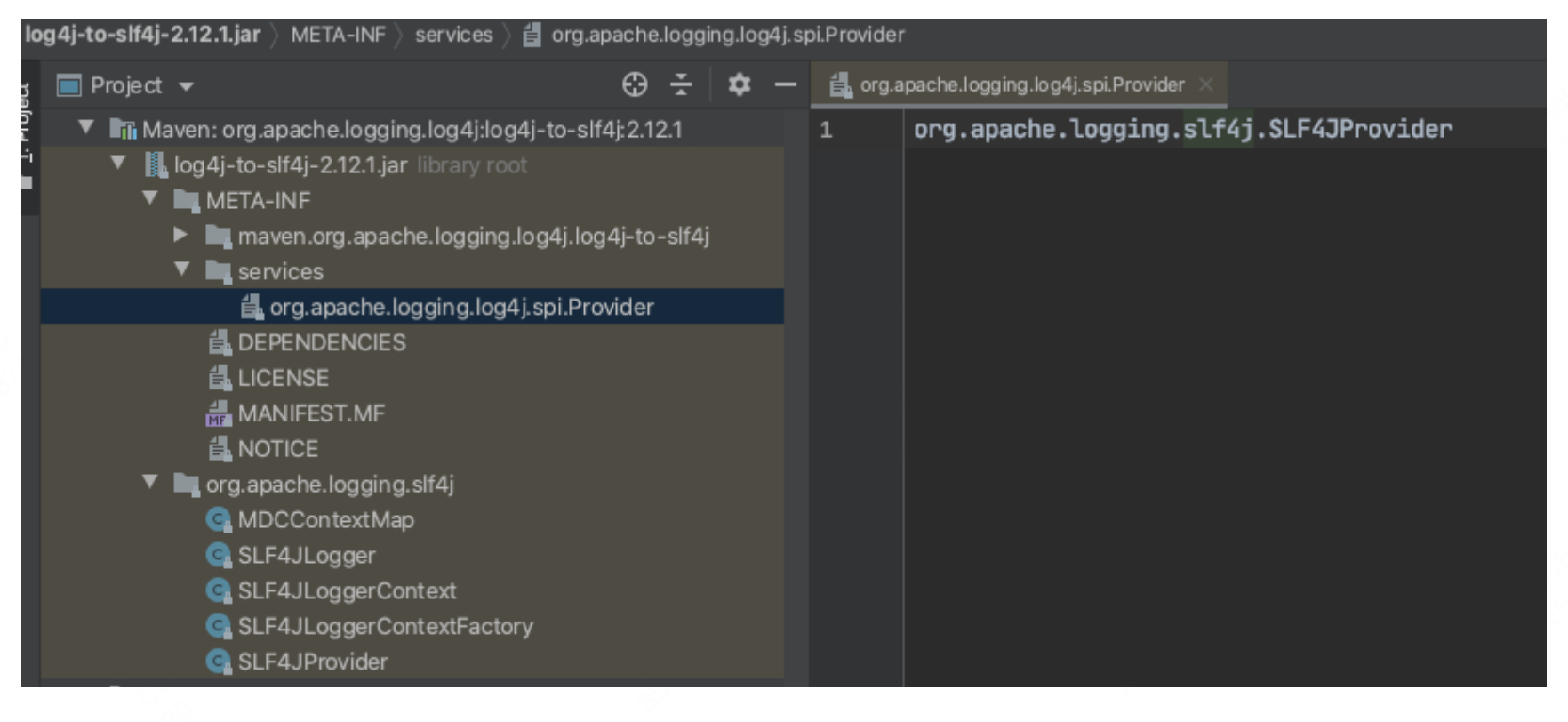
1.2.2 Log4j2的桥接包(log4j-to-slf4j-2.xx.jar)的实现方式
Log4j2的桥接包是由Log4j2官方开发和维护的,因此在代码层面上得到了官方的支持。该桥接包的实现方式相对简洁,采用了Java的服务提供者接口(SPI)机制。下图展示了这一实现方式的概况。如果您对SPI的具体实现方式感兴趣,可以进一步深入研究,这里就不再详细说明了。
1.3 Slf4j实现绑定不同日志
首先我们还是来看一下Slf4j官网给出的图:
绑定包的实现相对统一,因为它得到了Slf4j代码层面的支持,这是Slf4j设计的一部分。因此,绑定包的实现方式较为灵活,采用了类似SPI(Service Provider Interface)的机制。下面我将以Log4j2的绑定包为例,简要介绍其实现过程。
首先,当我们使用Slf4j时,所有Logger对象的获取都是通过LoggerFactory.getLogger()方法进行的。因此,我们也从这个方法开始介绍,如下图所示:
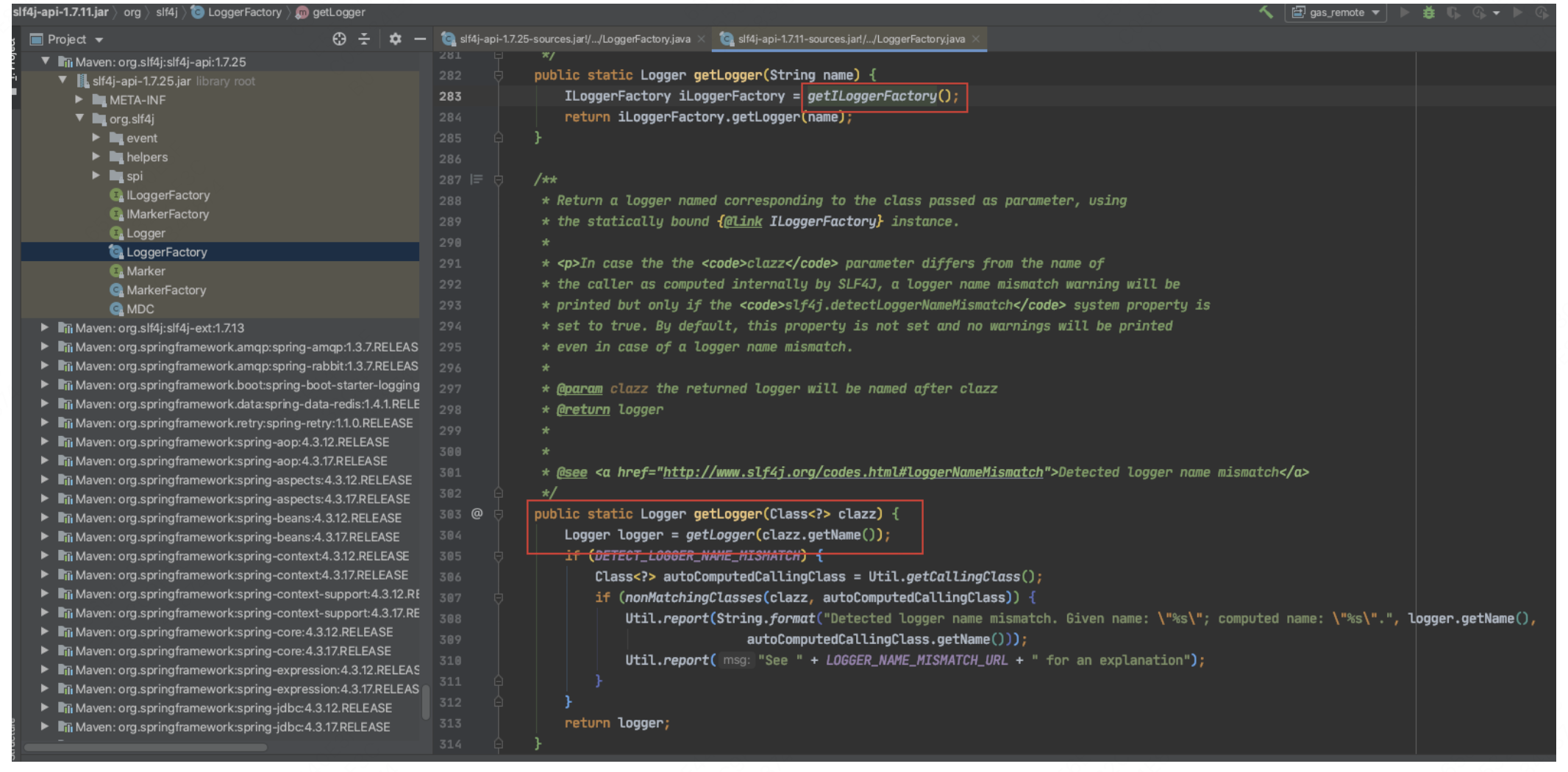
通过 LoggerFactory.getLogger() 方法,我们可以获取具体的 Logger 实例。这个过程实际上是由 SLF4J 的绑定包来完成的。绑定包负责将 SLF4J 的日志请求转发到具体的日志实现库,例如 Log4j2。这样,SLF4J 就能够在不直接依赖具体日志实现库的情况下,提供统一的日志接口。 这种设计赋予了 SLF4J 高度的灵活性和可扩展性。用户可以根据需要选择不同的日志实现库,而无需修改代码中的日志调用部分。我们主要关注 getILoggerFactory() 方法。首先,通过 getILoggerFactory()方法获取 ILoggerFactory实例,然后通过 ILoggerFactory的 getLogger() 方法获取最终的 Logger 实现。现在,我们来看一下 getILoggerFactory() 方法的具体实现:
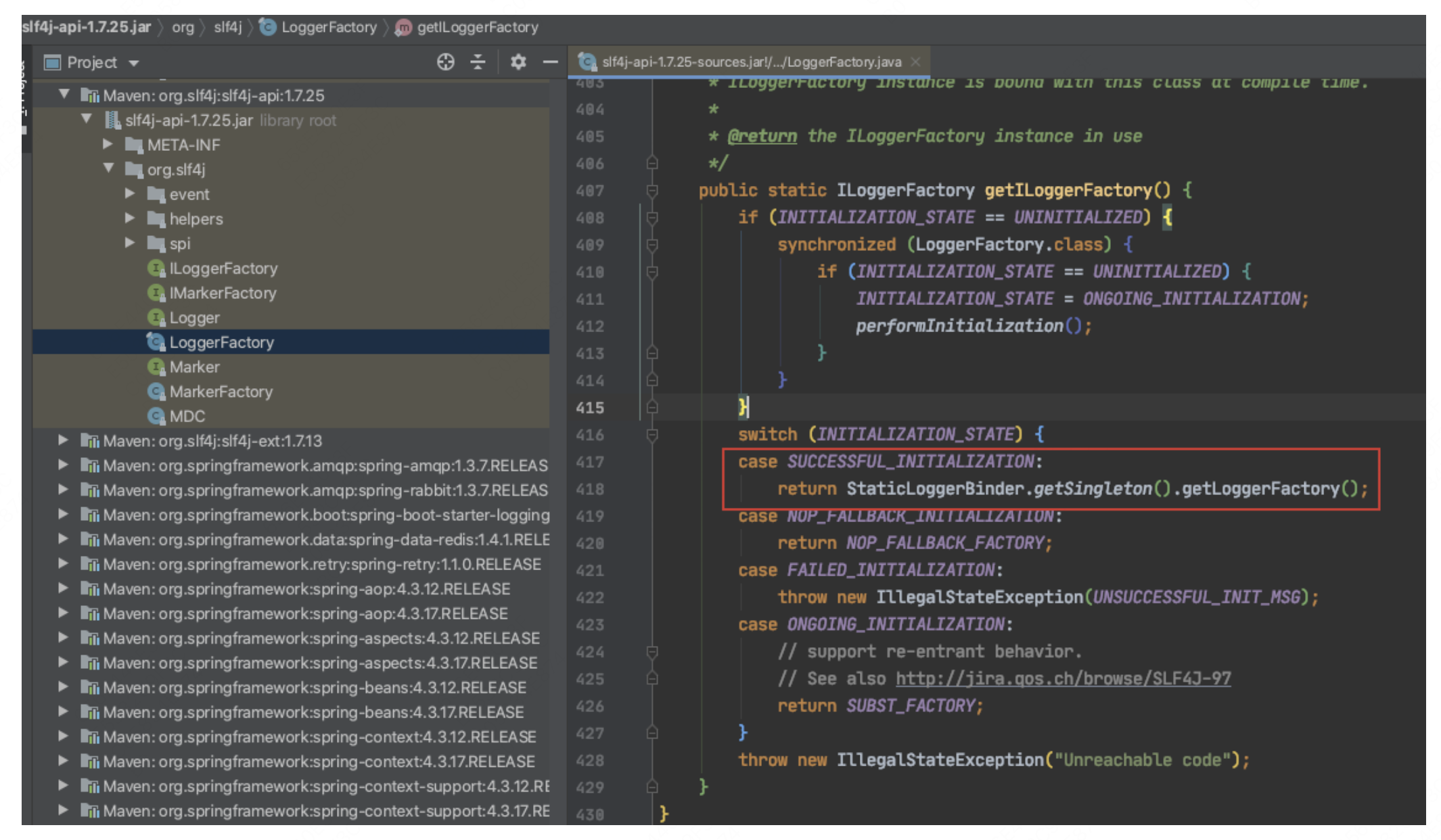
我们主要关注红色圈出的部分。在这里,我们已经确定了是由 StaticLoggerBinder 来包装 LoggerFactory。那么,是否所有的绑定包只需提供一个具有相同包名和类名的类,就可以实现不同日志实现的绑定呢?接下来,我们将对此进行验证。
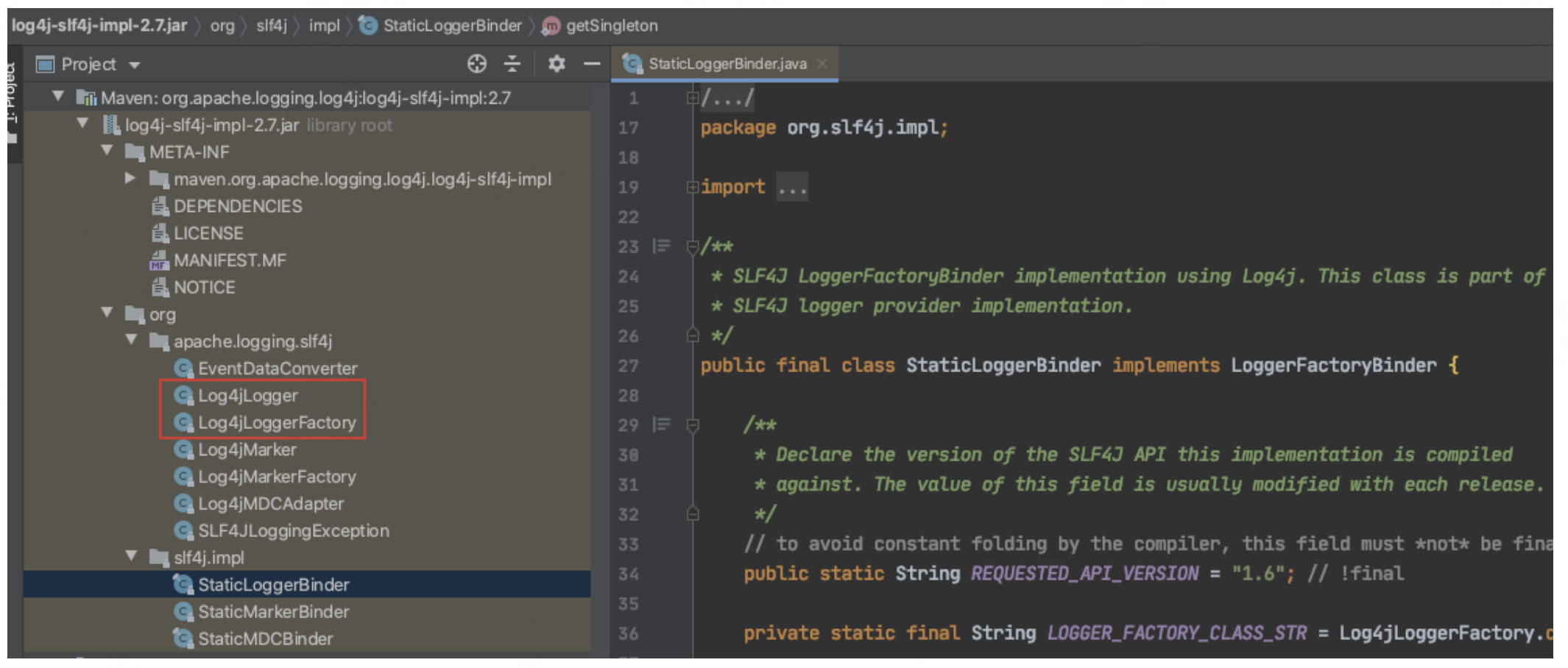
在Log4j2的绑定包中,我们发现了名为StaticLoggerBinder的类,它与我们之前提到的包名和类名一致。此外,我们还找到了具体的LoggerFactory和Logger实现(见红框部分)。
至此,我们已经了解了日志绑定的实现原理。如果大家有兴趣,可以自行查阅源码以深入了解具体细节。 这里有一个值得探讨的小问题:如果我们的应用添加了多个日志绑定包,Slf4j会选择哪一个呢?根据Slf4j官网的解释,它会随机选择一个。然而,这里的“随机”并不完全是随机的,而是依赖于JVM的版本。不同版本的JVM在加载类时可能会有所不同。例如,在我们当前使用的JDK1.8版本中,当JVM遇到相同包名和类名的类时,只会加载第一个类(如前所述,日志绑定包的实现是通过StaticLoggerBinder类实现的),后续扫描到的类不会被加载。因此,在这个版本中,第一个加载的类会生效。然而,这个规则在后续版本中可能会有所变化,因此在不同版本中可能表现为随机。 此外,启动方式也会影响日志实现的绑定。例如,SpringBoot项目使用FatJar技术将所有第三方库封装到一个Jar包中,并保证pom.xml中的依赖顺序。而普通的Spring项目则使用Java -cp方式加载某个目录下的第三方包,这时pom.xml中的顺序可能会被打乱,依赖于操作系统的文件系统排序。因此,这两种启动方式绑定的日志实现可能会有所不同。 然而,当我们的应用工程使用固定的JDK版本和固定的启动方式时,绑定的日志实现也是固定的。只有在修改启动方式、启动参数或JDK版本时,才可能会发生变化。
2 环境搭建
梳理完流程后下一步就是环境搭建了
2.1 topic申请
首先是向Kafka平台申请topic(公司一般都会有kafka平台)
2.2 hive表申请
首先日志是区别业务日志和服务日志的,只有业务日志需要存储,因为可能要用于模型训练分析等。服务日志就是记录error的,用于排查bug
2.3 pom配置
依据公司来
2.4 log4j2配置
依据公司来
2.5 测试代码编写
依据公司来
3 实战
例如现在的业务需求为分别记录模型的未经处理的输出以及经过处理的输出。
3.1 数据结构定义
首先设计数据结构
| 字段 | 类型 | 描述(根据实际需求设置值) |
|---|---|---|
| scene | string | 当前日志的场景 |
| request | object | 请求体 |
| response | object | 返回体 |
| extraInfo | map<string, object> | 其他的信息 |
| timestamp | long | 日志时间 |
细节:request、response以及extraInfo设计成object是为了方便业务入参操作,转化为json或者说string这种事情交给更底层的工具类
/*** 日志上下文类* 用于收集和管理整个请求生命周期中的日志信息* 支持泛型,可以处理不同类型的请求和响应对象*/
@Data
public class LogInfo {// 日志字段常量,定义日志中各个字段的键名private String scene; // 场景标识/*** 请求响应* request: 原始请求对象* response: 响应对象*/private Object request;private Object response;private Map<String, Object> extraInfoMap; // 扩展信息
}scene字段的目的是为了区别不同场景下的业务日志例如我现在就有两个需求那么就可以用这个字段进行区分,到时候查数据库的时候直接where scene=XXXX即可
当然针对于这种可以枚举的场景为了提升代码的可靠性可以采用枚举的方式
/*** 场景枚举类* 定义系统中的各种业务场景*/
@Getter
public enum LogScene {Scene1("Scene1"),Scene2("Scene2");private final String value;LogScene(String value) {this.value = value;}/*** 根据字符串值获取对应的枚举* @param value 场景值* @return 对应的枚举值,如果不存在则返回null*/public static LogScene fromValue(String value) {if (value == null) {return null;}for (LogScene logScene : LogScene.values()) {if (logScene.getValue().equals(value)) {return logScene;}}return null;}
}3.2 工具类的书写
注意多用try-catch不要让异常跑到其他人的代码里
ImmutableMap是一个不可修改的map,set过一次KV就不可修改了,更加安全
/*** 日志工具类* 提供将LogContext对象转换为标准日志格式并输出的功能* 使用@UtilityClass注解标记为工具类,所有方法都是静态的*/
@UtilityClass
public class LogUtil {// 日志记录器,使用scribe作为日志名称,通常用于远程日志收集private static final Logger localLogger = LoggerFactory.getLogger(LogUtil.class);private static final Logger remoteLogger = LoggerFactory.getLogger("topic");// 日志字段常量,定义日志中各个字段的键名private static final String SCENE = "scene"; // 场景标识private static final String REQUEST = "request"; // 请求对象private static final String RESPONSE = "response"; // 响应对象private static final String EXTRA_INFO = "extraInfo"; // 扩展信息private static final String TIMESTAMP = "timestamp"; // 时间戳/*** 记录业务日志* 将LogContext对象中的信息格式化为JSON并输出到日志系统* @param logInfo 日志上下文对象,包含所有需要记录的信息*/public static void logInfo(LogInfo logInfo) {if (Objects.isNull(logInfo)){return;}XMDLogFormat formatter = XMDLogFormat.build();try {// 使用ImmutableMap.Builder构建不可变MapImmutableMap.Builder<String, Object> tags = buildBasicInfo(logInfo);
// formatter.putTags(tags.build());formatter.putJson(JacksonUtils.toJson(tags.build()));String extraMessage = "";remoteLogger.info(formatter.message(extraMessage));} catch (Exception e) {// 记录日志过程中发生异常时,记录错误日志localLogger.error("记录业务日志异常", e);}}/*** 构建基础信息* 添加时间戳等基础字段到日志中** @param logInfo 日志上下文对象*/private static ImmutableMap.Builder<String, Object> buildBasicInfo(LogInfo logInfo) {ImmutableMap.Builder<String, Object> tags = ImmutableMap.builder();try {if (logInfo.getScene() != null) {tags.put(SCENE, logInfo.getScene());}// 将请求和响应对象转换为JSON字符串if (logInfo.getRequest() != null) {tags.put(REQUEST, JacksonUtils.toJson(logInfo.getRequest()));}if (logInfo.getResponse() != null) {tags.put(RESPONSE, JacksonUtils.toJson(logInfo.getResponse()));}if (MapUtils.isNotEmpty(logInfo.getExtraInfoMap())) {tags.put(EXTRA_INFO, JacksonUtils.toJson(logInfo.getExtraInfoMap()));}tags.put(TIMESTAMP, System.currentTimeMillis());} catch (Exception e) {localLogger.error(" build log info tag error", e);}return tags;}}3.3 业务LogService的编程
这也是代码部分最难的地方,这要求你对公司业务代码和需求理解十分透彻
这里我就不梳理业务,直接给出示例
值得注意的是由于写日志是属于IO操作所以速度是比较慢的,所以建议使用线程池做多线程的异步处理
@Configuration
public class ThreadConfig {private static final Logger LOGGER = LoggerFactory.getLogger(ThreadConfig.class);@Bean(name = "logThreadPool")public ThreadPool logThreadPool() {ThreadPool threadPool = new ThreadPool("logThreadPool", DefaultThreadPoolProperties.Setter().withCoreSize(64).withMaxSize(128).withMaxQueueSize(1024).withKeepAliveTimeMinutes(10).withRejectHandler(new RejectedExecutionHandler() {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {LOGGER.error("logThreadPool reject");}}));//warmupwarmup(threadPool, 64);return threadPool;}private void warmup(ThreadPool threadPool, int coreSize) {if (coreSize <= 0 || threadPool == null) {return;}for (int i = 0; i < coreSize; i++) {threadPool.submit(()->{ThreadUtil.sleep(5);});}}
}
整体思路就是构造LogInfo的构造然后丢到线程池里
@Service
public class LogService {private static final Logger LOGGER = LoggerFactory.getLogger(LogService.class);@Data@AllArgsConstructorclass LogMessage {private String role;private String content;}@ResourceThreadPool logThreadPool;/*** 记录模型调用信息** @param ctx 代理上下文,包含请求和响应信息*/public void logModelInfo(Context ctx) {try{LogInfo loginfo = build(ctx);// 提交日志记录任务logInfo(logInfo);} catch (Throwable t) {// 捕获所有可能的异常,包括ErrorLOGGER.error("Unexpected error in logModelInfo", t);}}/*** 记录代理信息** @param request 代理请求* @param response 代理响应*/public void logAgentInfo(Request request, Response response) {try {LogInfo loginfo = build(request,response);logInfo(logInfo);} catch (Throwable t) {// 捕获所有可能的异常,包括ErrorLOGGER.error("Unexpected error in logAgentInfo", t);}}/*** 将日志信息提交到线程池异步处理** @param info 日志信息对象*/private void logInfo(LogInfo info) {try {if (info == null) {LOGGER.warn("logModelInfo failed: LogInfo is null");return;}// 检查线程池是否可用if (logThreadPool != null) {try {logThreadPool.submit(() -> {try {LogUtil.logInfo(info);} catch (Exception e) {LOGGER.error("Failed to log model info in thread pool task", e);} catch (Throwable t) {LOGGER.error("Unexpected error in thread pool log task", t);}});} catch (Exception e) {LOGGER.error("Failed to submit log task to thread pool", e);// 降级处理:直接记录日志try {LogUtil.logInfo(info);} catch (Exception ex) {LOGGER.error("Failed to log model info directly after thread pool failure", ex);}}} else {LOGGER.warn("logThreadPool is null, logging synchronously");try {LogUtil.logInfo(info);} catch (Exception e) {LOGGER.error("Failed to log model info synchronously", e);}}} catch (Throwable t) {// 捕获所有可能的异常,包括ErrorLOGGER.error("Unexpected error in logModelInfo method", t);// 最后的尝试:直接记录日志try {LogUtil.logInfo(info);} catch (Exception e) {LOGGER.error("Final attempt to log info failed", e);}}}
}
4 服务上线
其实也蛮简单的就是图形化界面点点
5 总结与收获
-
对于日志体系有了更深刻的认识包括但不限于日志系统的整个链路、Slf4j的门面设计模式和桥接模式、log4j2的plugin的思想
-
对于日志体系有了一个完整的全流程的认识
-
实战中学会了一些小细节
-
对外提供的接口要简单,底层的工具类功能要单一,复杂的业务逻辑用Service进行处理
-
可以讲对象类型设置成Object来简化对外接口
-
多用try-catch避免将自己的锅甩给别人
-
对于写日志这种IO密集型操作采用多线程
-
对于KV类型的数据可以用ImmutableMap提高安全性
-
-
体验服务上线的流程


![[USACO1.5] 八皇后 Checker Challenge Java](https://i-blog.csdnimg.cn/direct/394c85b3b96546c9a9d0c7c43feff5ab.png)