导语
最近赶上618活动,将家里的RTX 4060显卡升级为了RTX 5060Ti 16GB版本,显存翻了一番,可以进行一些LLM微调实验了,本篇博客记录使用unsloth框架在RTX 5060Ti 16GB显卡上进行Qwen3-4B-Base模型的GRPO强化微调实验。
简介
GPU性能对比
让ChatGPT帮我总结了一下整体性能规格参数的对比,简要整理如下:
| 关键指标 | RTX 5060 Ti 16 GB | RTX 4060 8 GB | AI-相关意义 |
|---|---|---|---|
| 架构 / GPU | Blackwell GB206 | Ada Lovelace AD107 | 50 系为全新第 5 代 Tensor Core & FP4 |
| 制程 | TSMC 4N 5 nm | TSMC 4N 5 nm | 相同能效基线,差距来自架构 |
| CUDA 核心 | 4 608 | 3 072 | +50% 原生算力 |
| Tensor Core 代际 | 第 5 代,FP4/FP8 | 第 4 代,FP8 | FP4 可把权重+激活再减半 |
| AI TOPS(INT8) | 759 TOPS | 242 TOPS | ~3.1× 推理吞吐提升 |
| VRAM 容量 / 类型 | 16 GB GDDR7 28 Gbps | 8 GB GDDR6 17 Gbps | 单卡能装下 fp16 7 B LLM / SD XL 全分辨率 |
| 内存总线 / 带宽 | 128-bit / 448 GB/s | 128-bit / 272 GB/s | 带宽 +65%,降低 KV-cache & 大卷积瓶颈 |
| L2 缓存 | 32 MB | 24 MB | 更高 KV-cache 命中率 |
| Base / Boost Clock | 2.41 / 2.57 GHz | 1.83 / 2.46 GHz | 核心频率略高 |
| FP16 (半精) 理论算力 | 23.7 TFLOPS | 15.1 TFLOPS | +57% 训练/推理混精吞吐 |
| PCIe 接口 | PCIe 5.0 ×8 | PCIe 4.0 ×8 | CPU↔GPU 传输带宽翻倍 |
| TBP / 供电 | 180 W,1×8-pin/Gen5 | 115 W,1×8-pin | 仍属“小电”级别,易于上机 |
unsloth框架
unsloth是一个专为 LLM 快速微调而生的开源 Python 框架,支持 LoRA/QLoRA 量化适配、4/8/16-bit 训练、完整微调与预训练等能力整合到统一 API 中,在单张消费级 GPU 上即可实现 2-5 倍的训练速度提升,同时节省约 60-70 % 的显存,却几乎不损失精度。
由于RTX 50系显卡是新一代GPU架构,所以环境安装暂时比较麻烦。折腾了好久后终于找到了一个解决方案,命令如下:
conda create --name unsloth_qwen3 python=3.12 -yconda activate unsloth_qwen3
pip install "unsloth @ git+https://github.com/unslothai/unsloth.git@main"
pip install unsloth_zoopip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128export MAX_JOBS=8
pip install "triton @ git+https://github.com/triton-lang/triton.git@main"
pip install bitsandbytes
conda install -c conda-forge libstdcxx-ng
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main
pip install filecheck
GRPO训练
这里使用unsloth官方给出的notebook中代码来进行GRPO强化学习训练,使用的模型为最新的qwen3-4B-base
完整训练脚本如下:
# Part 0:导入相关库与配置模型、处理数据集
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Can increase for longer reasoning traces
lora_rank = 32 # Larger rank = smarter, but slowermodel, tokenizer = FastLanguageModel.from_pretrained(model_name = "/home/jxqi/project/model/Qwen3-4B-Base",max_seq_length = max_seq_length,load_in_4bit = True, # False for LoRA 16bitfast_inference = False, # Enable vLLM fast inferencemax_lora_rank = lora_rank,gpu_memory_utilization = 0.7, # Reduce if out of memory
)model = FastLanguageModel.get_peft_model(model,r = lora_rank, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],lora_alpha = lora_rank*2, # *2 speeds up traininguse_gradient_checkpointing = "unsloth", # Reduces memory usagerandom_state = 3407,
)reasoning_start = "<start_working_out>" # Acts as <think>
reasoning_end = "<end_working_out>" # Acts as </think>
solution_start = "<SOLUTION>"
solution_end = "</SOLUTION>"system_prompt = \
f"""You are given a problem.
Think about the problem and provide your working out.
Place it between {reasoning_start} and {reasoning_end}.
Then, provide your solution between {solution_start}{solution_end}"""chat_template = \"{% if messages[0]['role'] == 'system' %}"\"{{ messages[0]['content'] + eos_token }}"\"{% set loop_messages = messages[1:] %}"\"{% else %}"\"{{ '{system_prompt}' + eos_token }}"\"{% set loop_messages = messages %}"\"{% endif %}"\"{% for message in loop_messages %}"\"{% if message['role'] == 'user' %}"\"{{ message['content'] }}"\"{% elif message['role'] == 'assistant' %}"\"{{ message['content'] + eos_token }}"\"{% endif %}"\"{% endfor %}"\"{% if add_generation_prompt %}{{ '{reasoning_start}' }}"\"{% endif %}"# Replace with out specific template:
chat_template = chat_template\.replace("'{system_prompt}'", f"'{system_prompt}'")\.replace("'{reasoning_start}'", f"'{reasoning_start}'")
tokenizer.chat_template = chat_templatetokenizer.apply_chat_template([{"role" : "user", "content" : "What is 1+1?"},{"role" : "assistant", "content" : f"{reasoning_start}I think it's 2.{reasoning_end}{solution_start}2{solution_end}"},{"role" : "user", "content" : "What is 2+2?"},
], tokenize = False, add_generation_prompt = True)from datasets import load_dataset
import pandas as pd
import numpy as npdataset = load_dataset("unsloth/OpenMathReasoning-mini", split = "cot")
dataset = dataset.to_pandas()[["expected_answer", "problem", "generated_solution"]
]# Try converting to number - if not, replace with NaN
is_number = pd.to_numeric(pd.Series(dataset["expected_answer"]), errors = "coerce").notnull()
# Select only numbers
dataset = dataset.iloc[np.where(is_number)[0]]def format_dataset(x):expected_answer = x["expected_answer"]problem = x["problem"]# Remove generated <think> and </think>thoughts = x["generated_solution"]thoughts = thoughts.replace("<think>", "").replace("</think>", "")# Strip newlines on left and rightthoughts = thoughts.strip()# Add our custom formattingfinal_prompt = \reasoning_start + thoughts + reasoning_end + \solution_start + expected_answer + solution_endreturn [{"role" : "system", "content" : system_prompt},{"role" : "user", "content" : problem},{"role" : "assistant", "content" : final_prompt},]dataset["Messages"] = dataset.apply(format_dataset, axis = 1)
tokenizer.apply_chat_template(dataset["Messages"][0], tokenize = False)
dataset["N"] = dataset["Messages"].apply(lambda x: len(tokenizer.apply_chat_template(x)))
dataset = dataset.loc[dataset["N"] <= max_seq_length/3].copy()
print("dataset.shape: ", dataset.shape)from datasets import Dataset
dataset["text"] = tokenizer.apply_chat_template(dataset["Messages"].values.tolist(), tokenize = False)
dataset = Dataset.from_pandas(dataset)
print("dataset: ", dataset)# Part 1:有监督微淘冷启动实验
from trl import SFTTrainer, SFTConfig
trainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset,args = SFTConfig(dataset_text_field = "text",per_device_train_batch_size = 1,gradient_accumulation_steps = 1, # Use GA to mimic batch size!warmup_steps = 5,num_train_epochs = 2, # Set this for 1 full training run.learning_rate = 2e-4, # Reduce to 2e-5 for long training runslogging_steps = 5,optim = "adamw_8bit",weight_decay = 0.01,lr_scheduler_type = "linear",seed = 3407,report_to = "none", # Use this for WandB etc),
)
trainer.train()
text = tokenizer.apply_chat_template(dataset[0]["Messages"][:2],tokenize = False,add_generation_prompt = True, # Must add for generation
)from transformers import TextStreamer
_ = model.generate(**tokenizer(text, return_tensors = "pt").to("cuda"),temperature = 0,max_new_tokens = 1024,streamer = TextStreamer(tokenizer, skip_prompt = False),
)del dataset
torch.cuda.empty_cache()
import gc
gc.collect()# Part 2:GRPO强化学习训练
from datasets import load_dataset
dataset = load_dataset("open-r1/DAPO-Math-17k-Processed", "en", split = "train")def extract_hash_answer(text):# if "####" not in text: return None# return text.split("####")[1].strip()return text
extract_hash_answer(dataset[0]["solution"])dataset = dataset.map(lambda x: {"prompt" : [{"role": "system", "content": system_prompt},{"role": "user", "content": x["prompt"]},],"answer": extract_hash_answer(x["solution"]),
})import re
# Add optional EOS token matching
solution_end_regex = r"</SOLUTION>[\s]{0,}" + \"(?:" + re.escape(tokenizer.eos_token) + ")?"match_format = re.compile(rf"{reasoning_end}.*?"\rf"{solution_start}(.+?){solution_end_regex}"\rf"[\s]{{0,}}$",flags = re.MULTILINE | re.DOTALL
)def match_format_exactly(completions, **kwargs):scores = []for completion in completions:score = 0response = completion[0]["content"]# Match if format is seen exactly!if match_format.search(response) is not None: score += 3.0scores.append(score)return scoresdef match_format_approximately(completions, **kwargs):scores = []for completion in completions:score = 0response = completion[0]["content"]# Count how many keywords are seen - we penalize if too many!# If we see 1, then plus some points!# No need to reward <start_working_out> since we always prepend it!# score += 0.5 if response.count(reasoning_start) == 1 else -1.0score += 0.5 if response.count(reasoning_end) == 1 else -1.0score += 0.5 if response.count(solution_start) == 1 else -1.0score += 0.5 if response.count(solution_end) == 1 else -1.0scores.append(score)return scoresdef check_answer(prompts, completions, answer, **kwargs):question = prompts[0][-1]["content"]responses = [completion[0]["content"] for completion in completions]extracted_responses = [guess.group(1)if (guess := match_format.search(r)) is not None else None \for r in responses]scores = []for guess, true_answer in zip(extracted_responses, answer):score = 0if guess is None:scores.append(-2.0)continue# Correct answer gets 5 points!if guess == true_answer:score += 5.0# Match if spaces are seen, but less rewardelif guess.strip() == true_answer.strip():score += 3.5else:# We also reward it if the answer is close via ratios!# Ie if the answer is within some range, reward it!try:ratio = float(guess) / float(true_answer)if ratio >= 0.9 and ratio <= 1.1: score += 2.0elif ratio >= 0.8 and ratio <= 1.2: score += 1.5else: score -= 2.5 # Penalize wrong answersexcept:score -= 4.5 # Penalizescores.append(score)return scoresglobal PRINTED_TIMES
PRINTED_TIMES = 0
global PRINT_EVERY_STEPS
PRINT_EVERY_STEPS = 5match_numbers = re.compile(solution_start + r".*?[\s]{0,}([-]?[\d\.\,]{1,})",flags = re.MULTILINE | re.DOTALL
)def check_numbers(prompts, completions, answer, **kwargs):question = prompts[0][-1]["content"]responses = [completion[0]["content"] for completion in completions]extracted_responses = [guess.group(1)if (guess := match_numbers.search(r)) is not None else None \for r in responses]scores = []# Print only every few stepsglobal PRINTED_TIMESglobal PRINT_EVERY_STEPSif PRINTED_TIMES % PRINT_EVERY_STEPS == 0:print('*'*20 + f"Question:\n{question}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")PRINTED_TIMES += 1for guess, true_answer in zip(extracted_responses, answer):if guess is None:scores.append(-2.5)continue# Convert to numberstry:true_answer = float(true_answer.strip())# Remove commas like in 123,456guess = float(guess.strip().replace(",", ""))scores.append(3.5 if guess == true_answer else -1.5)except:scores.append(0)continuereturn scorestokenized = dataset.map(lambda x: {"tokens" : tokenizer.apply_chat_template(x["prompt"], add_generation_prompt = True, tokenize = True)},batched = True,
)
print(tokenizer.decode(tokenized[0]["tokens"]))
tokenized = tokenized.map(lambda x: {"L" : len(x["tokens"])})import numpy as np
maximum_length = int(np.quantile(tokenized["L"], 0.9))
print("Max Length = ", maximum_length)# Filter only samples smaller than 90% max length
dataset = dataset.select(np.where(np.array(tokenized["L"]) <= maximum_length)[0])
del tokenizedmax_prompt_length = maximum_length + 1 # + 1 just in case!
max_completion_length = max_seq_length - max_prompt_lengthfrom trl import GRPOConfig, GRPOTrainer
training_args = GRPOConfig(temperature = 1.0,learning_rate = 5e-6,weight_decay = 0.01,warmup_ratio = 0.1,lr_scheduler_type = "linear",optim = "adamw_8bit",logging_steps = 1,per_device_train_batch_size = 1,gradient_accumulation_steps = 4, # Increase to 4 for smoother trainingnum_generations = 8, # Decrease if out of memorymax_prompt_length = max_prompt_length,max_completion_length = max_completion_length,# num_train_epochs = 1, # Set to 1 for a full training runmax_steps = 100,save_steps = 100,report_to = "none", # Can use Weights & Biasesoutput_dir = "outputs",
)trainer = GRPOTrainer(model = model,processing_class = tokenizer,reward_funcs = [match_format_exactly,match_format_approximately,check_answer,check_numbers,],args = training_args,train_dataset = dataset,
)
trainer.train()
整体代码分为三个部分:
- 第0部分为导入相关库与配置模型、处理数据集
- 第1部分为SFT冷启动,主要帮助模型快速掌握回复的格式,使用OpenMathReasoning-mini数据集
- 第2部分为GRPO强化学习,使用GRPO算法对模型进行强化学习微调,使用open-r1/DAPO-Math-17k-Processed这个数据集
强化学习实验中,我们设置了每个Prompt采样8次,设置梯度累计gradient_accumulation_steps=4,这样一个group就是32个样本。
奖励函数包括4个:
- 精准格式匹配奖励:能否准确匹配。格式完全不符合时,不奖励,即0分;格式完全符合时,奖励 3.0 分。
- 模糊格式匹配奖励:这里共检查了 3 个关键标志:
- reasoning_end
- solution_start(即 )
- solution_end(即 )
如果每个标志恰好出现 1 次,给 +0.5;如果出现次数不是 1(包括 0 次或 >1 次),则给 -1.0。
- 答案正确性奖励:答案是否正确;
- 答案数字性奖励:输出里正确提取到与
true_answer完全相同的数值;最大值:+3.5,最小值:-2.5
训练过程的输出如下:
(torch28) (base) jxqi@DESKTOP-GD042P8:~/project/unsloth$ python grpo_unsloth_qwen3.py
🦥 Unsloth: Will patch your computer to enable 2x faster free finetuning.
🦥 Unsloth Zoo will now patch everything to make training faster!
==((====))== Unsloth 2025.5.10: Fast Qwen3 patching. Transformers: 4.52.4.\\ /| NVIDIA GeForce RTX 5060 Ti. Num GPUs = 1. Max memory: 15.928 GB. Platform: Linux.
O^O/ \_/ \ Torch: 2.8.0.dev20250529+cu128. CUDA: 12.0. CUDA Toolkit: 12.8. Triton: 3.3.0
\ / Bfloat16 = TRUE. FA [Xformers = 0.0.31+da84ce3.d20250530. FA2 = False]"-____-" Free license: http://github.com/unslothai/unsloth
Unsloth: Fast downloading is enabled - ignore downloading bars which are red colored!
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:11<00:00, 3.71s/it]
/home/jxqi/project/model/Qwen3-4B-Base does not have a padding token! Will use pad_token = <|vision_pad|>.
Unsloth 2025.5.10 patched 36 layers with 36 QKV layers, 36 O layers and 36 MLP layers.
dataset.shape: (1, 5)
dataset: Dataset({features: ['expected_answer', 'problem', 'generated_solution', 'Messages', 'N', 'text', '__index_level_0__'],num_rows: 1
})
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
num_proc must be <= 1. Reducing num_proc to 1 for dataset of size 1.
Unsloth: Tokenizing ["text"]: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 134.70 examples/s]
==((====))== Unsloth - 2x faster free finetuning | Num GPUs used = 1\\ /| Num examples = 1 | Num Epochs = 2 | Total steps = 2
O^O/ \_/ \ Batch size per device = 1 | Gradient accumulation steps = 1
\ / Data Parallel GPUs = 1 | Total batch size (1 x 1 x 1) = 1"-____-" Trainable parameters = 66,060,288/4,000,000,000 (1.65% trained)0%| | 0/2 [00:00<?, ?it/s]huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
Unsloth: Will smartly offload gradients to save VRAM!
{'train_runtime': 2.5398, 'train_samples_per_second': 0.787, 'train_steps_per_second': 0.787, 'train_loss': 1.0110118389129639, 'epoch': 2.0}
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.27s/it]
The following generation flags are not valid and may be ignored: ['temperature']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
You are given a problem.
Think about the problem and provide your working out.
Place it between <start_working_out> and <end_working_out>.
Then, provide your solution between <SOLUTION></SOLUTION><|endoftext|>Compute the value of the expression $(x-a)(x-b)\ldots (x-z)$.<start_working_out>Let's analyze the given expression: $(x-a)(x-b)\ldots (x-z)$. This expression is a product of terms, each of the form $(x - \text{letter})$, where the letters range from $a$ to $z$. There are 26 terms in total, corresponding to the 26 letters of the alphabet.Notice that the term $(x - x)$ is included in the product. This is because the sequence of letters goes from $a$ to $z$, and $x$ is the 24th letter in the alphabet. Therefore, the term $(x - x)$ is the 24th term in the product.Now, let's consider the value of the term $(x - x)$. Since $x - x = 0$, the entire product will be equal to 0, regardless of the values of the other terms. This is because any number multiplied by 0 is 0.Therefore, the value of the expression $(x-a)(x-b)\ldots (x-z)$ is 0.<end_working_out><SOLUTION>0</SOLUTION><|endoftext|>
You are given a problem.
Think about the problem and provide your working out.
Place it between <start_working_out> and <end_working_out>.
Then, provide your solution between <SOLUTION></SOLUTION><|endoftext|>In triangle $ABC$, $\sin \angle A = \frac{4}{5}$ and $\angle A < 90^\circ$. Let $D$ be a point outside triangle $ABC$ such that $\angle BAD = \angle DAC$ and $\angle BDC = 90^\circ$. Suppose that $AD = 1$ and that $\frac{BD}{CD} = \frac{3}{2}$. If $AB + AC$ can be expressed in the form $\frac{a\sqrt{b}}{c}$ where $a, b, c$ are pairwise relatively prime integers, find $a + b + c$.<start_working_out>
Max Length = 201
Unsloth: We now expect `per_device_train_batch_size` to be a multiple of `num_generations`.
We will change the batch size of 1 to the `num_generations` of 8
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
==((====))== Unsloth - 2x faster free finetuning | Num GPUs used = 1\\ /| Num examples = 12,709 | Num Epochs = 1 | Total steps = 100
O^O/ \_/ \ Batch size per device = 8 | Gradient accumulation steps = 4
\ / Data Parallel GPUs = 1 | Total batch size (8 x 4 x 1) = 32"-____-" Trainable parameters = 66,060,288/4,000,000,000 (1.65% trained)0%| | 0/100 [00:00<?, ?it/s]/home/jxqi/miniconda3/envs/torch28/lib/python3.12/site-packages/unsloth/kernels/utils.py:443: UserWarning: An output with one or more elements was resized since it had shape [1, 32, 2560], which does not match the required output shape [32, 1, 2560]. This behavior is deprecated, and in a future PyTorch release outputs will not be resized unless they have zero elements. You can explicitly reuse an out tensor t by resizing it, inplace, to zero elements with t.resize_(0). (Triggered internally at /pytorch/aten/src/ATen/native/Resize.cpp:31.)out = torch_matmul(X, W, out = out)
********************Question:
Compute the number of positive integers that divide at least two of the integers in the set $\{1^1,2^2,3^3,4^4,5^5,6^6,7^7,8^8,9^9,10^{10}\}$.
Answer:
22
Response:Since $1^1 = 1$ and $10^{10} > 10^9 > 9^9>>8^8>10^8>>7^7>>6^7>>5^5>>4^4>>3^3>>2^2>>1$, the only integers that can divide at least $1$ element in the set are $1$, $2$ and $5$.
Computing the values, we find
$2^2 = 4$,
$5^5 = 3125$. …… # 太长省略
Extracted:
None
{'loss': 0.0002, 'grad_norm': 8.34195613861084, 'learning_rate': 0.0, 'num_tokens': 34381.0, 'completions/mean_length': 938.65625, 'completions/min_length': 1.0, 'completions/max_length': 1846.0, 'completions/clipped_ratio': 0.125, 'completions/mean_terminated_length': 809.0357666015625, 'completions/min_terminated_length': 1.0, 'completions/max_terminated_length': 1578.0, 'rewards/match_format_exactly/mean': 0.84375, 'rewards/match_format_exactly/std': 1.3704102039337158, 'rewards/match_format_approximately/mean': -0.609375, 'rewards/match_format_approximately/std': 1.517289400100708, 'rewards/check_answer/mean': -2.640625, 'rewards/check_answer/std': 1.0942250490188599, 'rewards/check_numbers/mean': -1.34375, 'rewards/check_numbers/std': 0.8838834762573242, 'reward': -3.75, 'reward_std': 2.124946117401123, 'frac_reward_zero_std': 0.0, 'completion_length': 938.65625, 'kl': 0.0039907393511384726, 'epoch': 0.0}1%|██▋ | 1/100 [06:46<11:10:56, 406.63s/it]/home/jxqi/miniconda3/envs/torch28/lib/python3.12/site-packages/unsloth/kernels/utils.py:443: UserWarning: An output with one or more elements was resized since it had shape [1, 32, 2560], which does not match the required output shape [32, 1, 2560]. This behavior is deprecated, and in a future PyTorch release outputs will not be resized unless they have zero elements. You can explicitly reuse an out tensor t by resizing it, inplace, to zero elements with t.resize_(0). (Triggered internally at /pytorch/aten/src/ATen/native/Resize.cpp:31.)out = torch_matmul(X, W, out = out)
{'loss': 0.0005, 'grad_norm': 0.2457444816827774, 'learning_rate': 5.000000000000001e-07, 'num_tokens': 97157.0, 'completions/mean_length': 1846.0, 'completions/min_length': 1846.0, 'completions/max_length': 1846.0, 'completions/clipped_ratio': 1.0, 'completions/mean_terminated_length': 0.0, 'completions/min_terminated_length': 0.0, 'completions/max_terminated_length': 0.0, 'rewards/match_format_exactly/mean': 0.0, 'rewards/match_format_exactly/std': 0.0, 'rewards/match_format_approximately/mean': -3.0, 'rewards/match_format_approximately/std': 0.0, 'rewards/check_answer/mean': -2.0, 'rewards/check_answer/std': 0.0, 'rewards/check_numbers/mean': -2.5, 'rewards/check_numbers/std': 0.0, 'reward': -7.5, 'reward_std': 0.0, 'frac_reward_zero_std': 1.0, 'completion_length': 1846.0, 'kl': 0.012083161040209234, 'epoch': 0.0}2%|█████▍ | 2/100 [11:40<9:16:16, 340.58s/it]
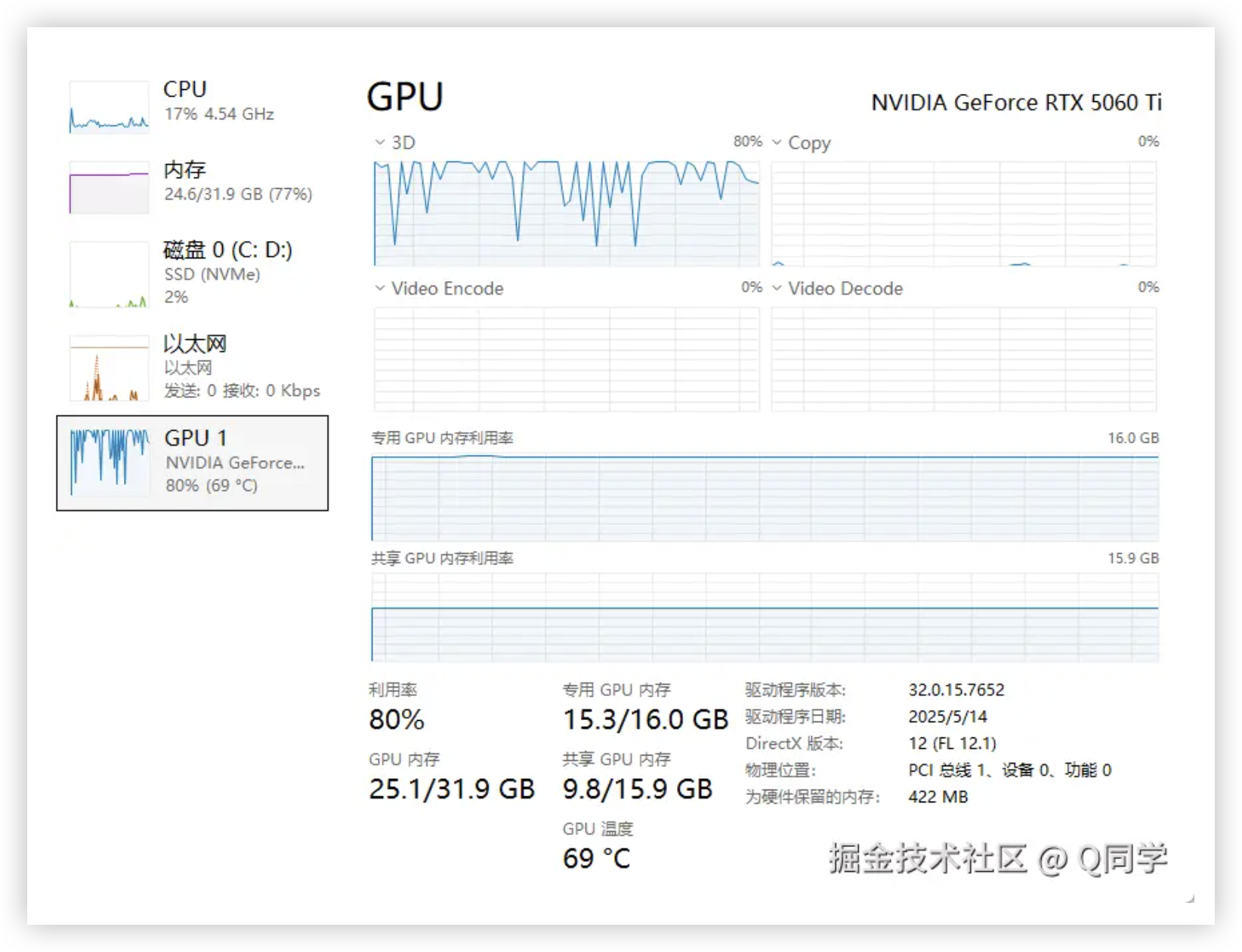
显存占用情况如下,基本可以吃满16GB的独立显存:
总结
这次使用RTX 5060Ti 16GB成功跑通了Qwen3-4B-Base模型的冷启动SFT和GRPO强化学习训练流程,由于架构较新,一些框架适配不是太好,后续随着各个框架的适配,整体实验环境配置应该会容易很多。
参考
- Please support RTX 50XX GPUs,https://github.com/unslothai/unsloth/issues/1856#issuecomment-2849009744