目录
- 前言
- 需求分析与环境配置
- 明确需求
- 环境准备
- 选择合适的大模型
- 蓝耘Mass平台介绍
- API调用
- 大模型API介绍
- API 调用流程
- 可交互AI助理开发
- 总结
前言
大数据时代,个人隐私很难得到保障,如果我们需要借助大模型解决一些私人问题,又不想隐私被泄露和所用的大模型公司收集,这里我提供一个解决方案:调用大模型的API实现一个本地化个人ai助理帮助我们解决问题,这是一个很好的解决办法。本次实验主要是借助蓝耘的Maas平台来调用大模型API,打造专属的AI助理。
需求分析与环境配置
在开始动手实验之前,我们首先要明确我们的需求和进行环境配置。不清楚需求,干起活就会没有清晰的思路,没有好环境,就没有办法实现我们的AI助理。
明确需求
- 功能层面, AI 助理需要能够精准理解我们的私人问题,并根据我们个人情况能给出准确且详细的解答。
- 数据层面,涉及私人数据,我们要确保所有输入给AI 助理的数据仅在本地环境中处理,不会被上传至外部服务器。
- 交互层面,有可视化图形界面窗口,AI 助理应该具备自然流畅的对话风格,并且响应迅速。
环境准备
注册蓝耘平台账号
如果还未拥有蓝耘平台账号的小伙伴,需前往蓝耘平台官网注册一下账号。(https://cloud.lanyun.net//#/registerPage?promoterCode=0131)
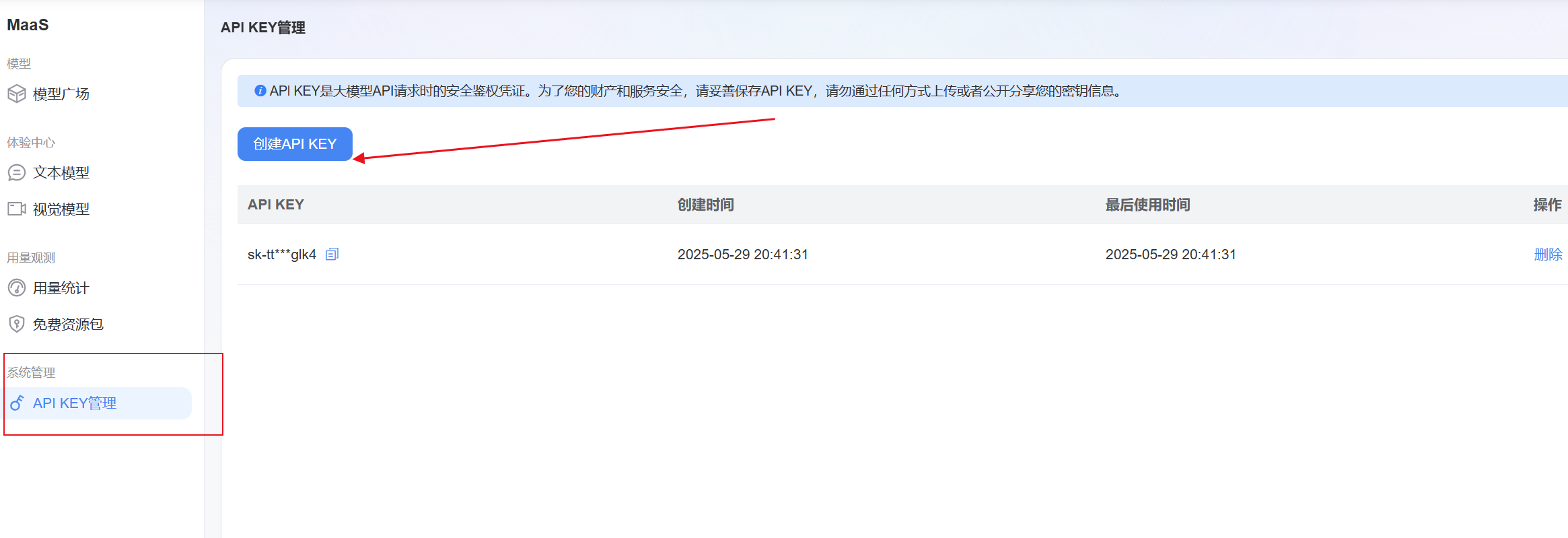
获取 API 密钥
成功登录蓝耘平台后,点击Maas平台找到 “API KEY管理” 选项,点击 “创建API KEY” 平台将为你生成一串唯一的 API 密钥。这串密钥是你调用蓝耘 Maas 平台 API 的重要凭证,务必妥善保管,切勿向他人透露,以免造成安全风险。
选择合适的大模型
蓝耘 Maas 平台提供了多种大模型供选择,如 DeepSeek - R1、DeepSeek - V3、QwQ - 32B 等。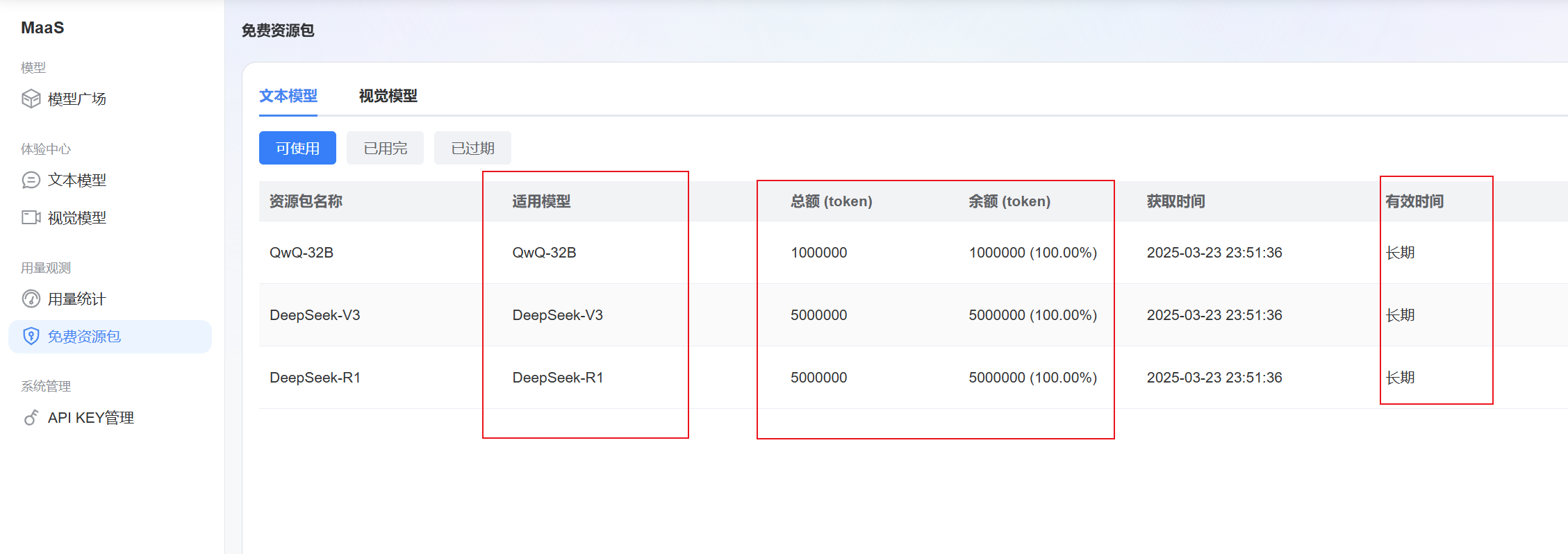
每个模型在自然语言处理、图像识别、代码生成等方面各有专长。鉴于我们打造个人 AI 助理主要用于处理文本类的私人问题,在自然语言处理方面表现卓越的 DeepSeek - R1 模型是不错的选择。它具备强大的语义理解能力,能深入剖析我们输入的问题,并生成高质量的回答。
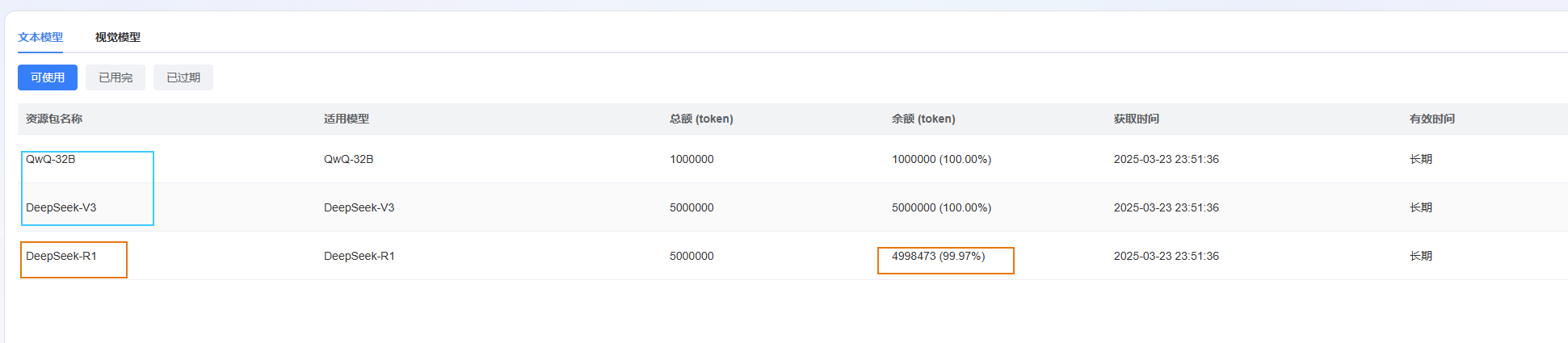
在平台的模型介绍页面,我们可详细了解各模型的特点、适用场景以及调用价格(蓝耘平台会免费赠送超千万 Token,并且长期有效,可以支持我们使用很长一段时间),综合评估后确定符合自身需求的模型。
蓝耘Mass平台介绍
考虑到有些读者可能不了解Mass平台究竟是什么,这里做简单介绍。

MaaS 平台即 “模型即服务”(Model as aService)平台,是一种依托云计算的人工智能服务模式。模型即服务(MaaS)平台面向企业开发者、创业者及非技术背景用户,提供开箱即用的热门AI模型服务,支持零代码体验、API快速集成与灵活计费,降低AI应用开发门槛,加速业务创新。允许用户通过API接口或其他方式访问和使用预先训练好的机器学习模型,无需自己从头开始训练模型,使得即使没有深厚机器学习背景的用户也能享受到高水平的AI技术支持。(引用蓝耘官方介绍)
平台也支持各种文本、图像、视频大模型的选择。
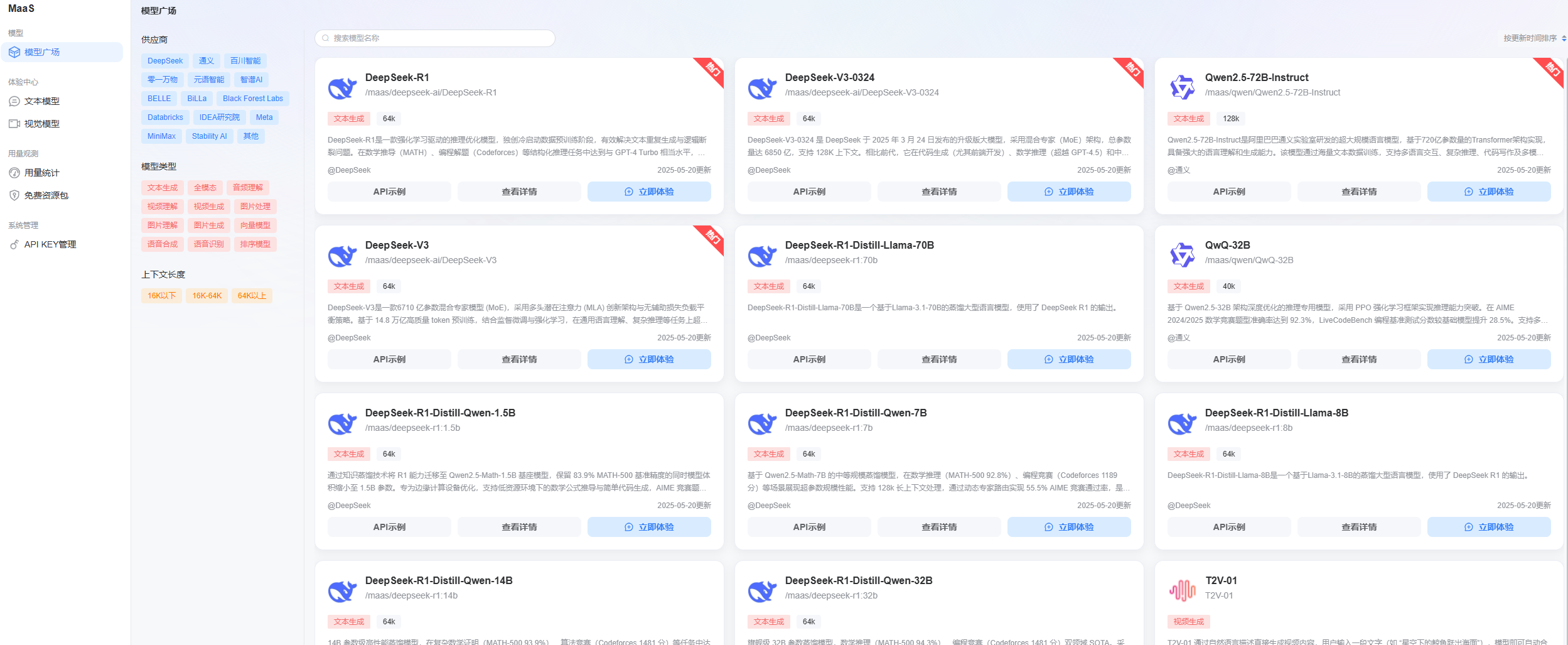
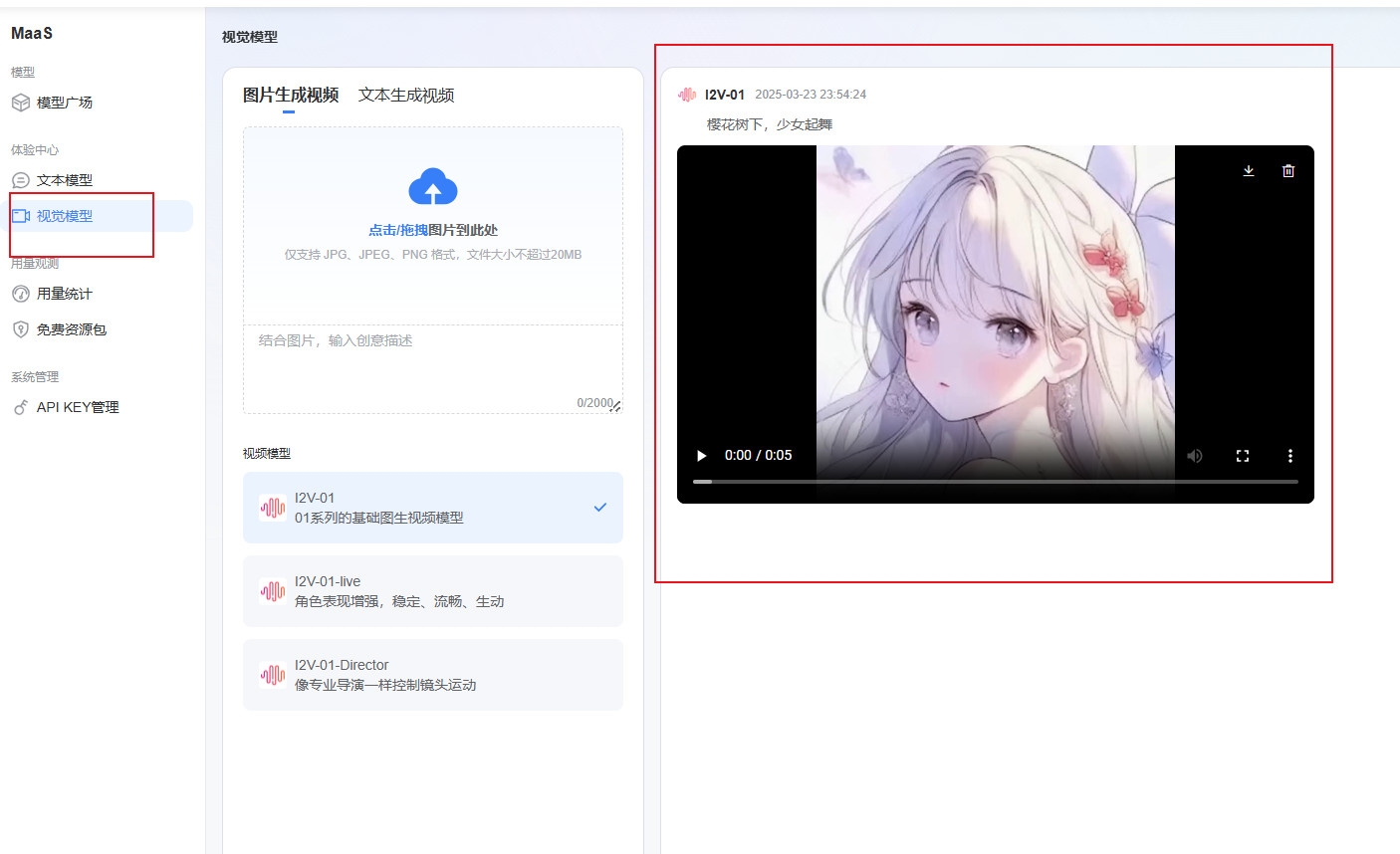
也可以在体验中心,直接体验模型。
API调用
完成上述需求分析与环境配置后,接下来进入更关键的 API 调用与功能实现环节。
大模型API介绍
大模型API是大模型对外提供服务的接口。通过API,开发者不需要了解大模型复杂的内部结构和运行机制,就能将大模型强大的功能集成到自己的应用、系统中。同时我们也可以调用大模型的API对模型进行微调、推理训练等。
API 调用流程
确定调用方式
蓝耘 Maas 平台为开发者提供了清晰且便捷的 API 调用方式。以常见的 HTTP 请求为例,我们可以借助各类编程语言中的 HTTP 请求库来发起调用。在 Python 语言中,常用的requests库能够方便地构造请求。我们要根据所选大模型 API 的要求,确定请求的 URL 地址。
构造请求参数
请求参数是 API 调用的关键部分,它决定了我们向大模型传递的信息以及期望得到的响应形式 。
- 认证信息:将之前获取的蓝耘平台 API 密钥包含在请求头中,获取调用权限。
- 模型相关参数:指定要调用的具体模型名称,在请求参数中明确设置模型参数。根据需求设置生成文本的最大长度(max_tokens),如设置为 200,意味着大模型生成的回答不超过 200 个 token;控制生成文本的随机性(temperature),取值范围在 0 - 1 之间,这里设置为 0.7,生成的文本会相对更具多样性。
Python 使用requests库调用蓝耘 Maas 平台大模型 API 代码:
import requestsurl = "https://maas-api.lanyun.net/v1/chat/completions"
headers = {"Content-Type": "application/json","Authorization": "Bearer 这里改成自己的API密钥"
}
data = {"model": "/maas/deepseek-ai/DeepSeek-R1","messages": [{"role": "system","content": "You are a helpful assistant."},{"role": "user","content": "Hello!"}]
}response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:result = response.json()print(result)
else:print(f"请求失败,状态码: {response.status_code}")不懂的朋友可以再看看官方文档,想快速实现的也可以直接用我的代码。
利用Jupyter Notebook环境我们先试试,模型API是否调用成功
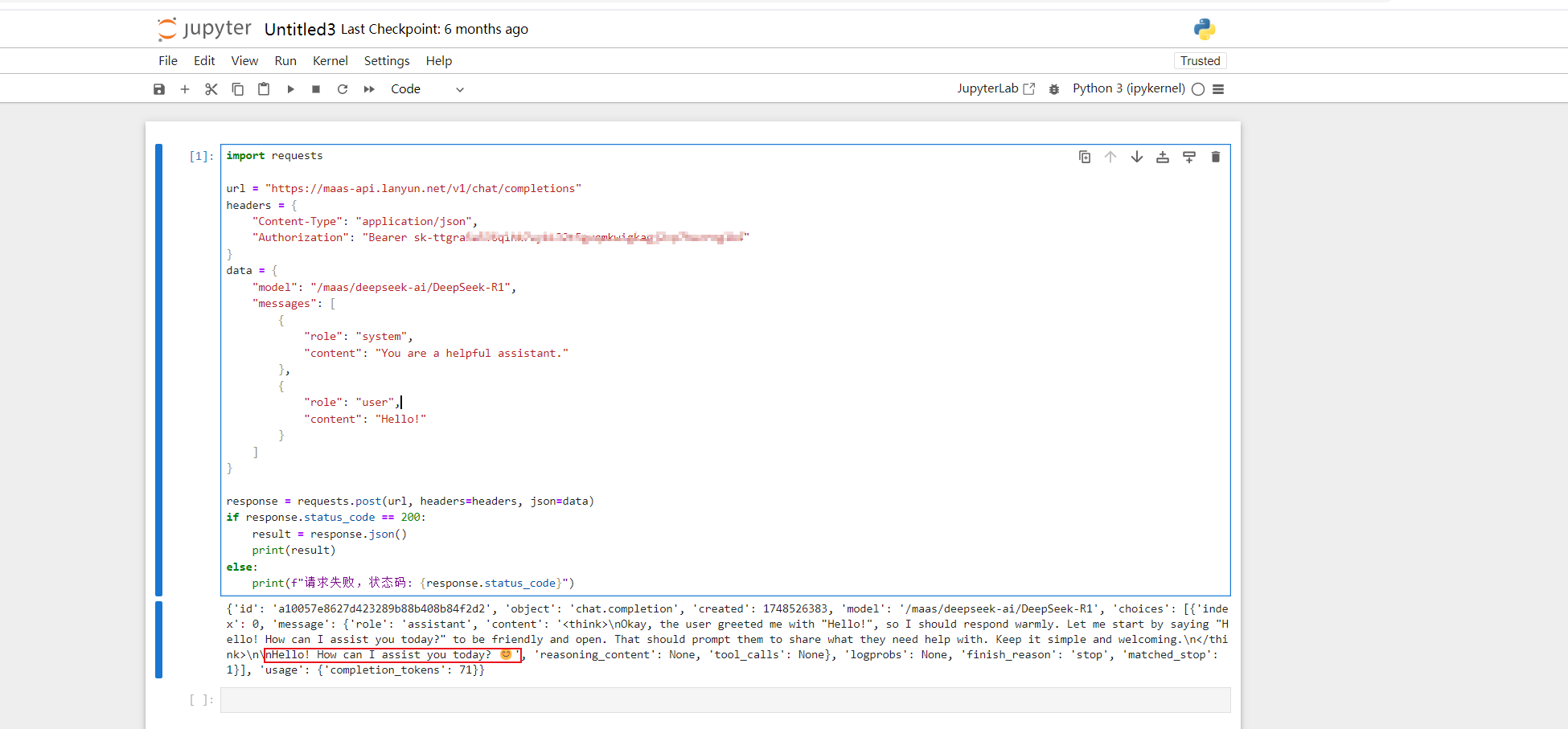
AI助理回答:Hello! How can I assist you today? 😊
调用的deepseek-r1模型API,deepseek也是有深度思考和正常输出的,还给我们回复了一个微笑的可爱表情包。看来已经进入助理角色了。
可交互AI助理开发
上面那个界面,对于不懂代码的用户来说,比较不友好,我们要开发的是在UI窗口能直接用自然语言进行交互的AI助理。这次开发环境是 VS code,用python代码实现。
1.首先是蓝耘Mass平台API调用,进行设置API信息,这一步是我们调用大模型的关键
self.api_url = "https://maas-api.lanyun.net/v1/chat/completions"
self.api_key = "请替换为您的实际API密钥" # 请替换为您的实际API密钥
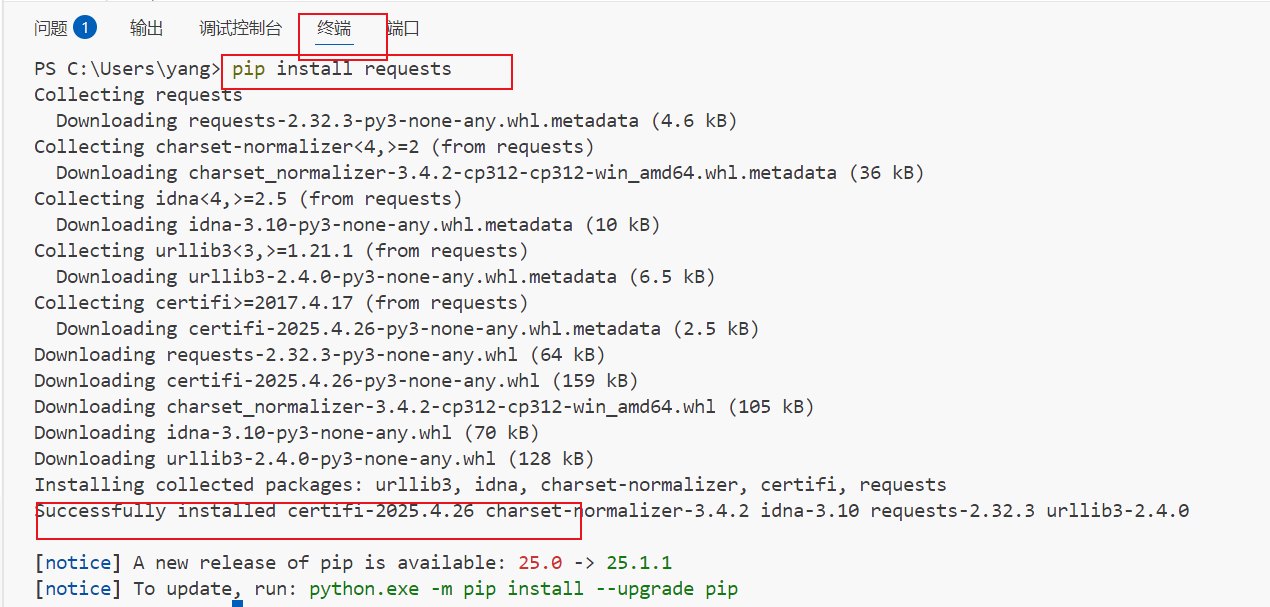
API调用主要是用到python的requests库,因为这个库是python的第三方库,我们本地可能并没有安装,调用的时候就会报错。
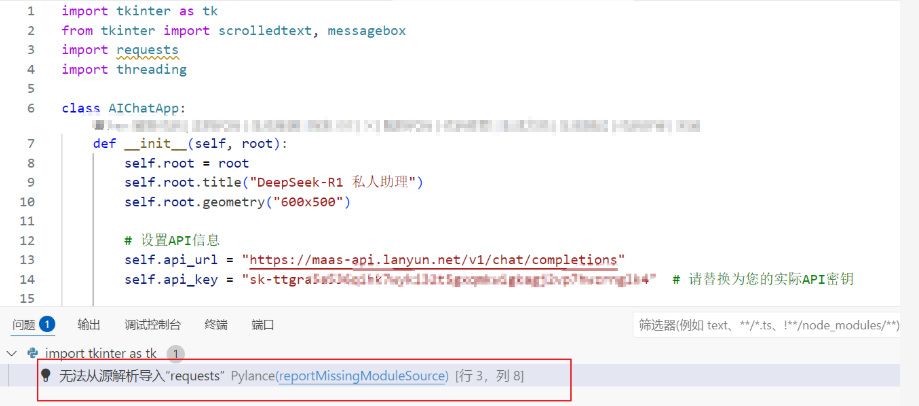
别担心,我们只需要在终端输入命令
pip install requests
就能完成库的安装,看见有“Successfully installed”就是安装成功了。
2.选择需要调用的模型为deepseek -r1模型,并且给模型设置身份为私人助理
headers = {"Content-Type": "application/json","Authorization": f"Bearer {self.api_key}"}data = {"model": "/maas/deepseek-ai/DeepSeek-R1","messages": [{"role": "system","content": self.system_role},{"role": "user","content": user_message}]}这里可以看到,我们给模型的身份和我们自己的身份。
# 初始化对话self.append_message("系统", "私人助理已就绪,请问有什么可以帮您?")# 设置系统角色self.system_role = "你是一位专业的私人助理,负责帮助用户处理各种事务。你的回答应该简洁、专业且友好。"

3.交互窗口的开发
主窗口和基本的设置,将窗口大小设置为600*500的块
self.root.geometry("600x500")
用户输入区域(输入框+发送按钮)
# 输入框框架
self.input_frame = tk.Frame(root)
self.input_frame.pack(padx=10, pady=5, fill=tk.X)# 输入框
self.user_input = tk.Entry(self.input_frame)
self.user_input.pack(side=tk.LEFT, fill=tk.X, expand=True)
self.user_input.bind("<Return>", self.send_message) # 绑定回车键发送# 发送按钮
self.send_button = tk.Button(self.input_frame, text="发送", command=self.send_message)
self.send_button.pack(side=tk.RIGHT)
消息显示功能实现
def append_message(self, sender, message):self.chat_history.configure(state='normal')self.chat_history.insert(tk.END, f"{sender}: {message}\n\n")self.chat_history.configure(state='disabled')self.chat_history.see(tk.END) # 自动滚动到底部
消息发送功能实现
def send_message(self, event=None):user_message = self.user_input.get()if not user_message.strip():returnself.append_message("你", user_message)self.user_input.delete(0, tk.END)# 禁用控件防止重复发送self.send_button.config(state=tk.DISABLED)self.user_input.config(state=tk.DISABLED)# 使用线程发送请求threading.Thread(target=self.get_ai_response, args=(user_message,)).start()
上面就是我们实现的主要代码了,现在运行看看效果。
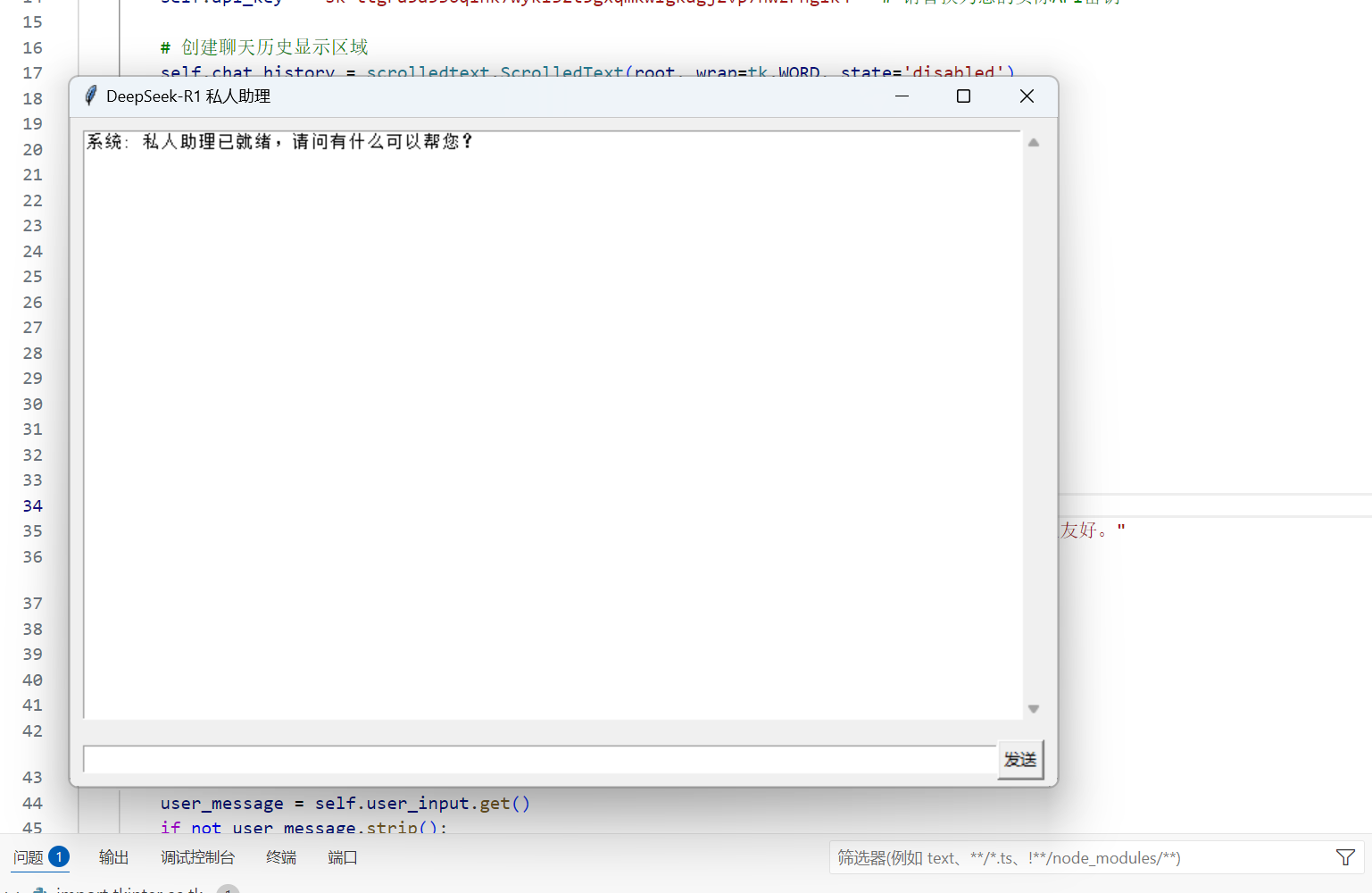
最上面是整个窗口的名字“Deepseek-R1 私人助理”,初始时,系统会告诉我们他是你的私人助理,并且询问你是否需要帮助,下面的框可以输入我们的请求,比如我下面的prompt“你好,现在是晚饭时间,为我推荐清淡且富有营养的晚餐”,点击右下角的发送按钮,发送请求就好。
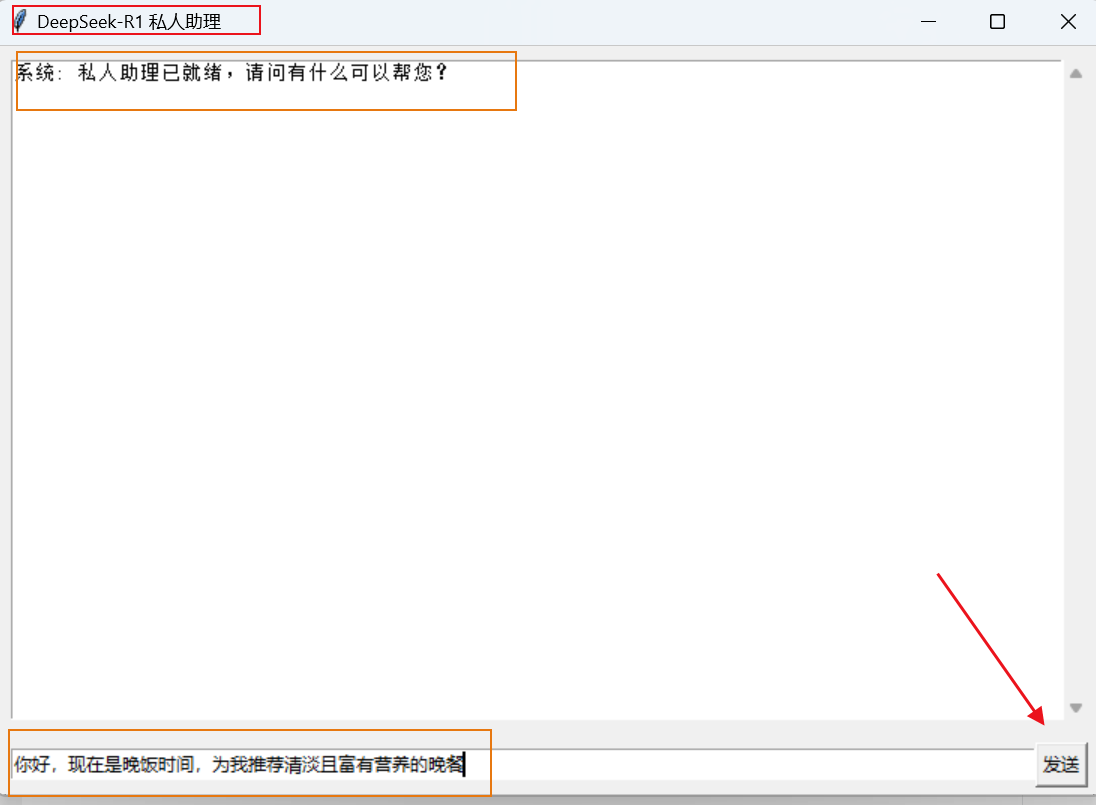
现在,是不是已经开始期待我们的私人助理会给出怎么样的回答了,一起看看吧。(十几秒的时间AI助理就能给我们回复,还是很快的,不需要像本地部署的大模型一样要等很久才能收到回复)
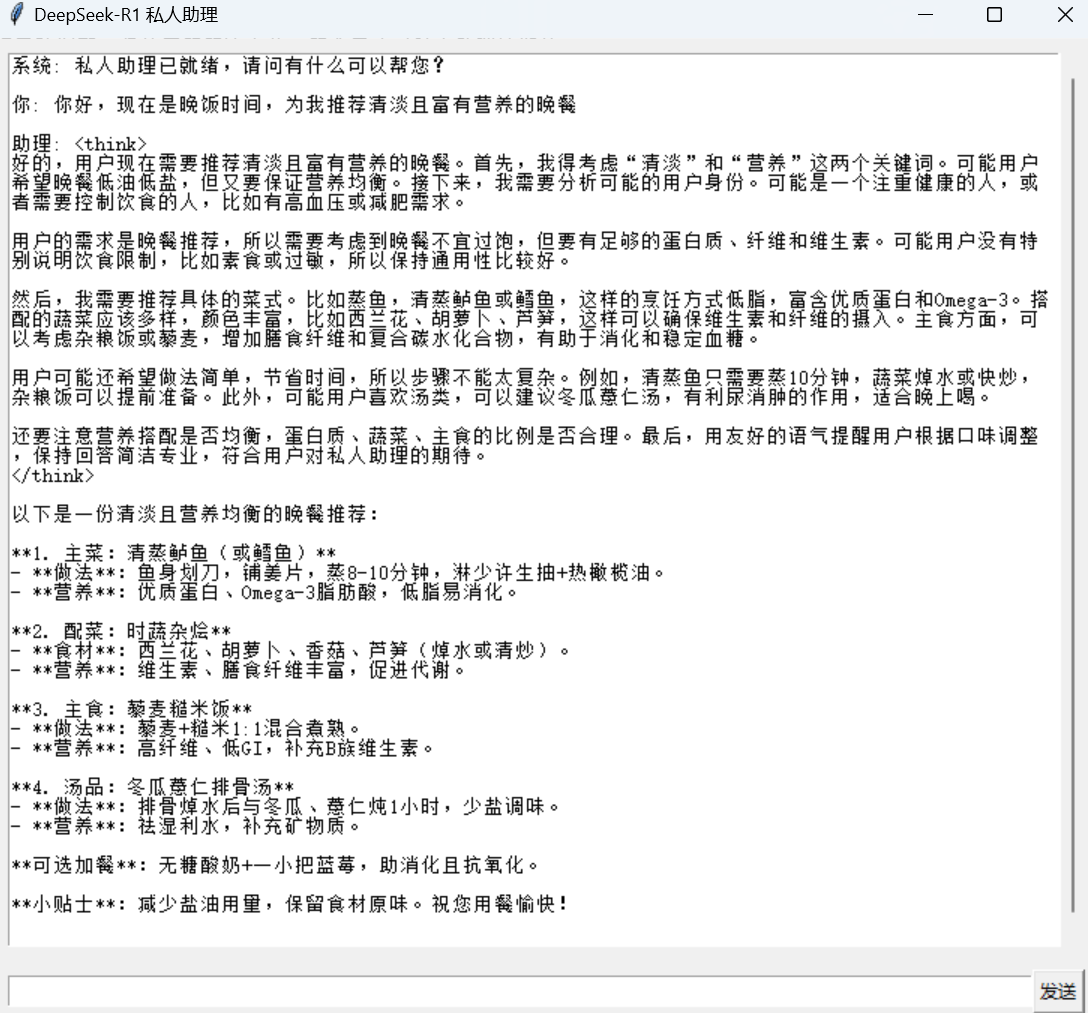
我们的小助理给出了一份很不错的食谱,接下来告诉小助理我们的忌口食物和喜爱食物,让他调整食谱。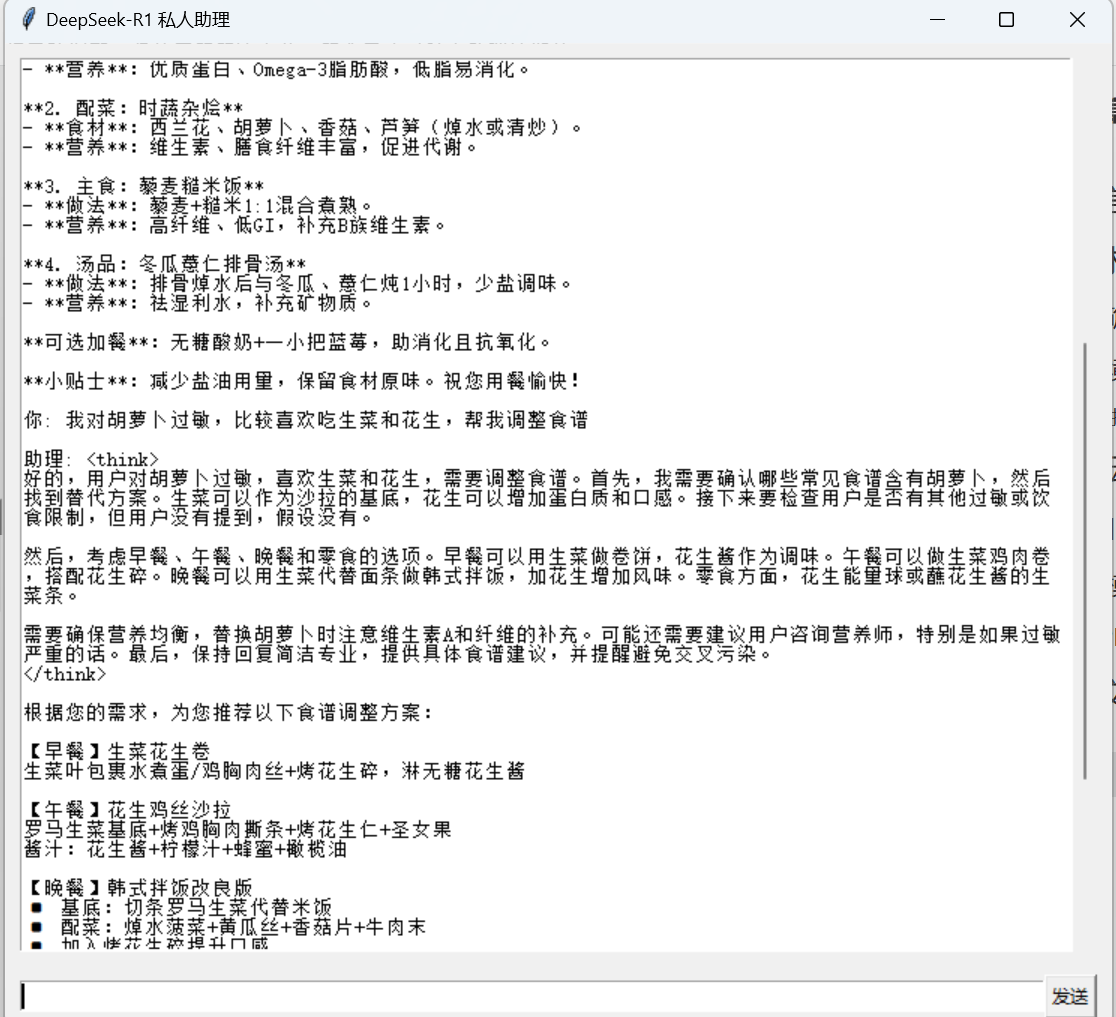 小助手根据我的喜好为我提供了新食谱,考虑到营养问题,把一日三餐的食都提供了,还告诉我应该怎么搭配,怎么食用。真所谓考虑的面面俱到,我对我的小助理非常满意。
小助手根据我的喜好为我提供了新食谱,考虑到营养问题,把一日三餐的食都提供了,还告诉我应该怎么搭配,怎么食用。真所谓考虑的面面俱到,我对我的小助理非常满意。
这里我们的小助手是有长记忆的,可以支持进行多轮对话,不用担心token不够,蓝耘平台给我们提供了免费的千万token。
4.可调整:
- 窗口界面可根据自己的喜好进行调整美化。
- 可以根据自己的喜好对助手回复风格进-行设置,还可以让助手扮演自己喜欢的角色。
- 模型可更换,用完了deepseek-r1的token也可以换成其他的。
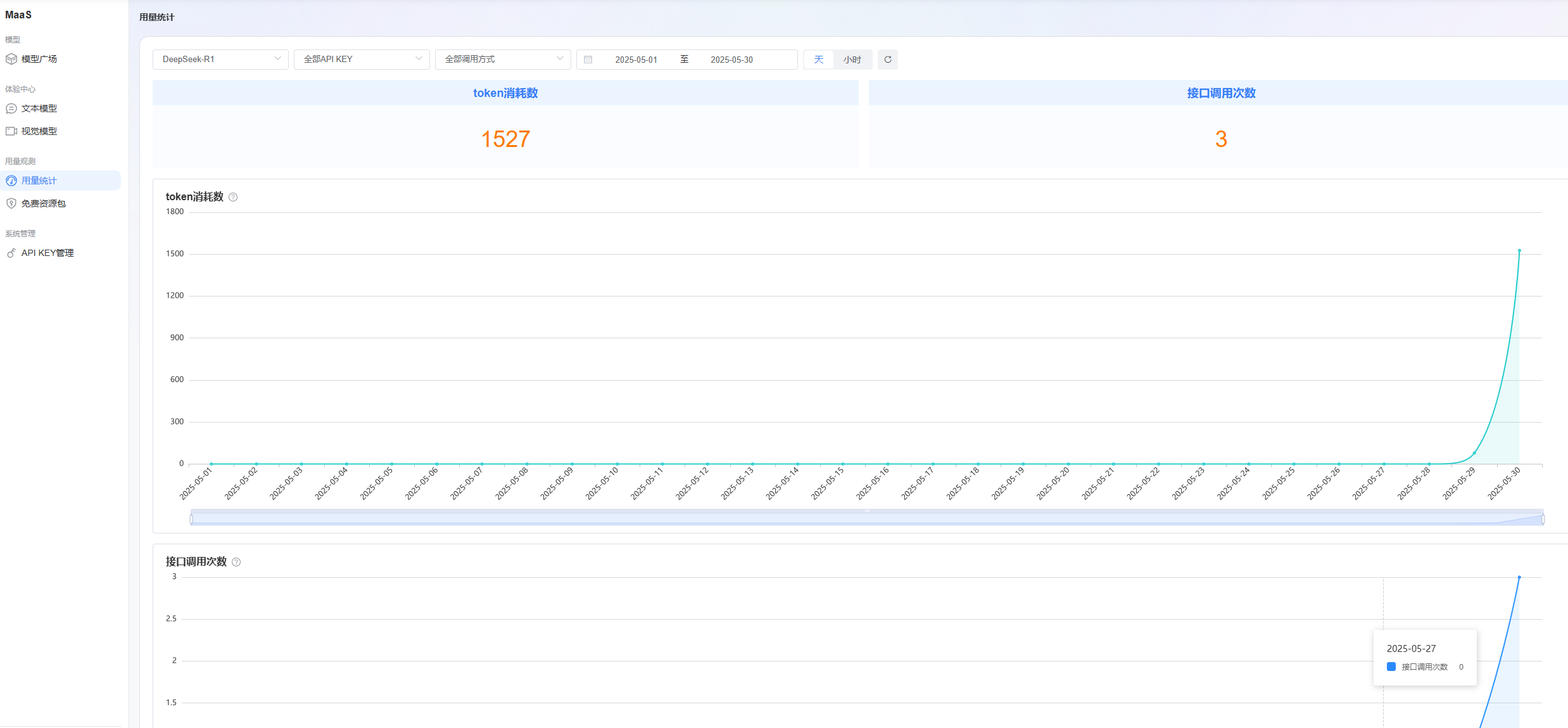
平台可以看到调用API的数量和token用量,实时监控并更新,方便我们查看
5.为了让更多人都能轻松实现这一AI私人助理,我决定把完整的代码分享给大家。
import tkinter as tk
from tkinter import scrolledtext, messagebox
import requests
import threadingclass AIChatApp:def __init__(self, root):self.root = rootself.root.title("DeepSeek-R1 私人助理")self.root.geometry("600x500")# 设置API信息self.api_url = "https://maas-api.lanyun.net/v1/chat/completions"self.api_key = "请替换为您的实际API密钥" # 请替换为您的实际API密钥# 创建聊天历史显示区域self.chat_history = scrolledtext.ScrolledText(root, wrap=tk.WORD, state='disabled')self.chat_history.pack(padx=10, pady=10, fill=tk.BOTH, expand=True)# 创建用户输入区域self.input_frame = tk.Frame(root)self.input_frame.pack(padx=10, pady=5, fill=tk.X)self.user_input = tk.Entry(self.input_frame)self.user_input.pack(side=tk.LEFT, fill=tk.X, expand=True)self.user_input.bind("<Return>", self.send_message)self.send_button = tk.Button(self.input_frame, text="发送", command=self.send_message)self.send_button.pack(side=tk.RIGHT)# 初始化对话self.append_message("系统", "私人助理已就绪,请问有什么可以帮您?")# 设置系统角色self.system_role = "你是一位专业的私人助理,负责帮助用户处理各种事务。你的回答应该简洁、专业且友好。"def append_message(self, sender, message):self.chat_history.configure(state='normal')self.chat_history.insert(tk.END, f"{sender}: {message}\n\n")self.chat_history.configure(state='disabled')self.chat_history.see(tk.END)def send_message(self, event=None):user_message = self.user_input.get()if not user_message.strip():returnself.append_message("你", user_message)self.user_input.delete(0, tk.END)# 禁用发送按钮和输入框,避免重复发送self.send_button.config(state=tk.DISABLED)self.user_input.config(state=tk.DISABLED)# 在新线程中发送请求,避免界面冻结threading.Thread(target=self.get_ai_response, args=(user_message,)).start()def get_ai_response(self, user_message):try:headers = {"Content-Type": "application/json","Authorization": f"Bearer {self.api_key}"}data = {"model": "/maas/deepseek-ai/DeepSeek-R1","messages": [{"role": "system","content": self.system_role},{"role": "user","content": user_message}]}response = requests.post(self.api_url, headers=headers, json=data)if response.status_code == 200:result = response.json()ai_response = result.get('choices', [{}])[0].get('message', {}).get('content', "未能获取有效回复")self.append_message("助理", ai_response)else:self.append_message("系统", f"请求失败,状态码: {response.status_code}")messagebox.showerror("错误", f"API请求失败: {response.status_code}")except Exception as e:self.append_message("系统", f"发生错误: {str(e)}")messagebox.showerror("错误", f"发生异常: {str(e)}")finally:# 重新启用发送按钮和输入框self.root.after(0, lambda: [self.send_button.config(state=tk.NORMAL),self.user_input.config(state=tk.NORMAL),self.user_input.focus()])if __name__ == "__main__":root = tk.Tk()app = AIChatApp(root)root.mainloop()总结
在大数据隐私风险下,我们可以尝试利用蓝耘 Maas 平台调用大模型 API 实现打造本地化 AI 助理,保护隐私数据不被泄露。通过 Python 代码实现 API 调用,开发带 UI 的交互助理,支持多轮对话。重中之重是蓝耘平台免费送超千万长期有效 Token,降低使用成本,为隐私保护下的智能问题解决提供新方案,为我们的AI助理实现提供了坚实的保障。

蓝耘平台注册链接奉上
https://cloud.lanyun.net//#/registerPage?promoterCode=0131











![题海拾贝:P8598 [蓝桥杯 2013 省 AB] 错误票据](https://i-blog.csdnimg.cn/direct/6848721f37aa40ca84322a78517857ab.png)
