在分布式消息系统中,消息确认机制是保障数据可靠性的关键。Apache Kafka 通过 ACK(Acknowledgment)机制 实现了灵活的数据确认策略,允许用户在 数据可靠性 和 系统性能 之间进行权衡。本文将深入解析 Kafka ACK 机制的工作原理、配置参数及其应用场景,并结合示意图和代码示例进行说明。
一、ACK机制的基本概念
1.1 什么是ACK?
在 Kafka 中,ACK 是生产者(Producer)与 Broker 之间的确认机制。当生产者发送消息到 Broker 时,Broker 会根据配置的 ACK 策略返回确认响应,告知生产者消息是否成功写入。
1.2 ACK机制的核心作用
- 保障数据可靠性:确保消息不丢失
- 控制吞吐量:不同的 ACK 级别对系统性能有显著影响
- 实现幂等性:配合 enable.idempotence=true 确保消息不重复
二、ACK机制的三种模式
Kafka 提供了三种 ACK 模式,通过 acks 参数进行配置:
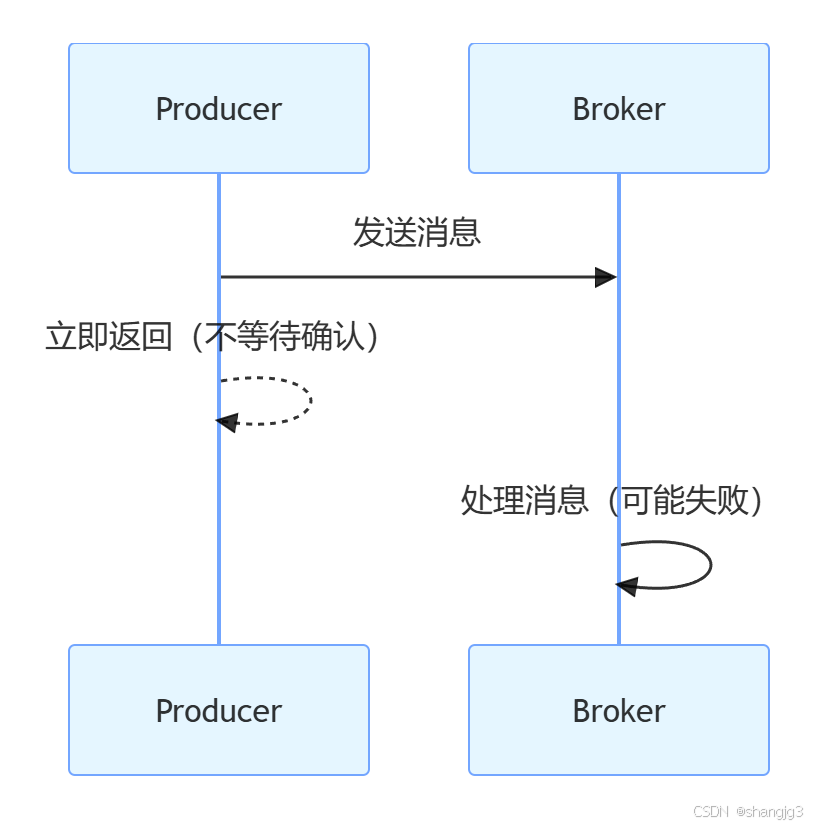
2.1 acks=0(生产者不等待确认)
- 工作原理:生产者发送消息后立即返回,不等待 Broker 的确认。
- 优点:吞吐量最高,延迟最低。
- 缺点:可靠性最低,若 Broker 接收失败,消息会丢失。
- 适用场景:对数据可靠性要求不高,追求极致性能的场景(如日志收集)。
示意图:
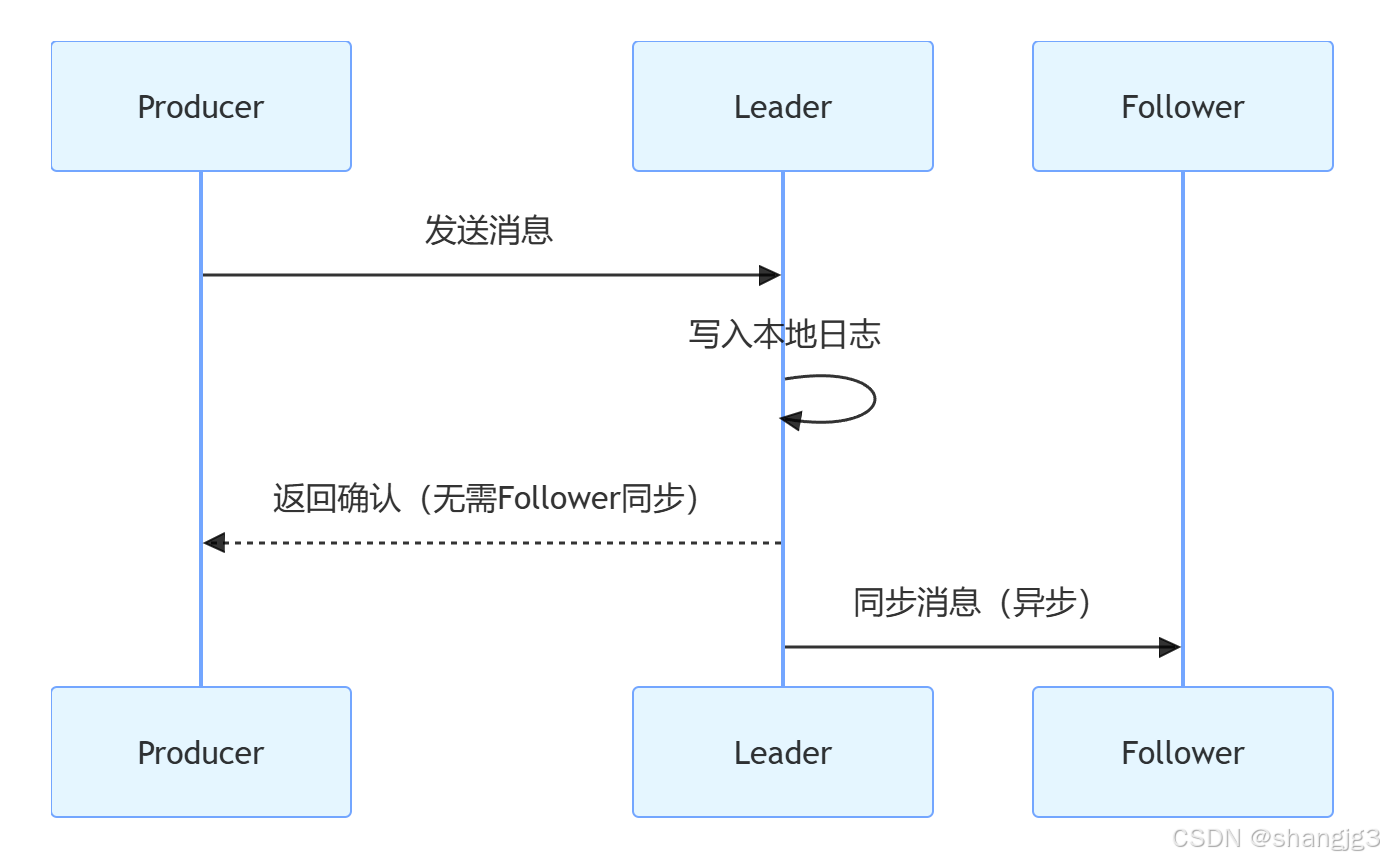
2.2 acks=1(默认值,等待Leader确认)
- 工作原理:生产者发送消息后,等待 Leader 副本确认接收(写入本地日志)。
- 优点:在 Leader 正常工作的情况下,保障消息不丢失。
- 缺点:若 Leader 接收后未同步给 Follower 就宕机,消息可能丢失。
- 适用场景:对数据可靠性有一定要求,同时兼顾性能的场景(如普通业务数据)。
示意图:
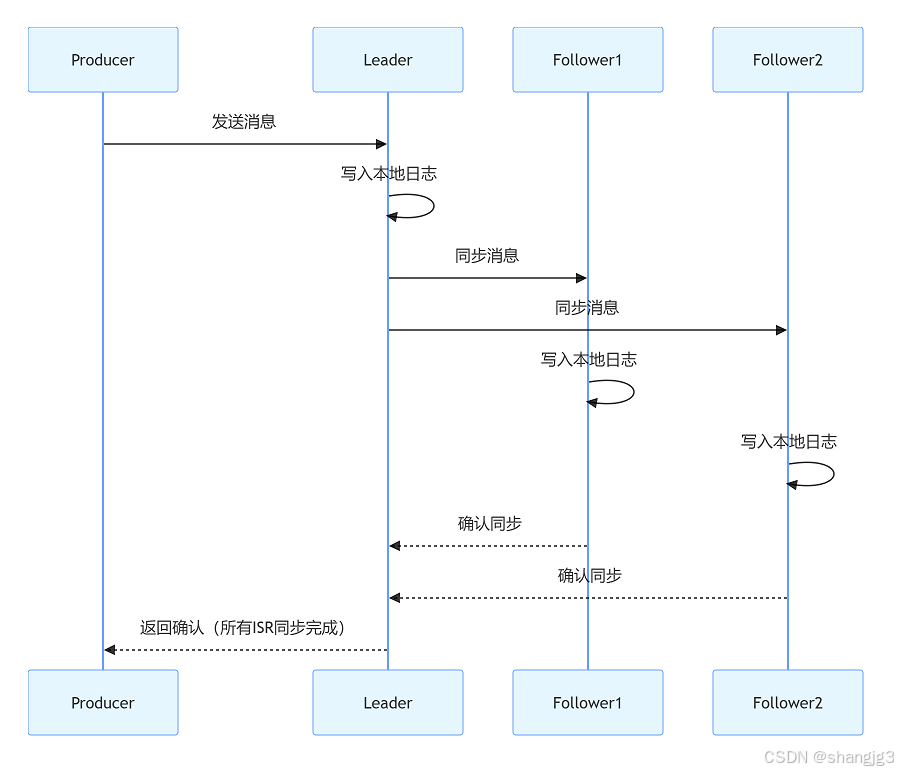
2.3 acks=all(或 acks=-1,等待所有ISR确认)
- 工作原理:生产者发送消息后,等待所有 ISR(In-Sync Replicas) 副本确认接收。
- 优点:最高可靠性,确保消息至少存在于一个 ISR 副本中。
- 缺点:吞吐量最低,延迟最高,需等待所有 ISR 副本同步。
- 适用场景:对数据可靠性要求极高的场景(如金融交易、订单系统)。
示意图:
三、ACK机制与ISR的协同工作
ACK 机制与 Kafka 的 ISR(In-Sync Replicas) 机制密切相关。当 acks=all 时,生产者必须等待所有 ISR 副本 确认接收消息,而非所有 Follower 副本。
3.1 ISR的动态调整
- ISR 列表:包含与 Leader 保持同步的 Follower 副本。
- 动态调整:当 Follower 副本落后 Leader 超过阈值(replica.lag.time.max.ms)时,会被移出 ISR。
3.2 最小ISR配置
通过 min.insync.replicas 参数设置 ISR 的最小副本数:
- 当 acks=all 时,若 ISR 副本数小于 min.insync.replicas,生产者会收到异常。
- 该参数可防止数据在 ISR 副本不足时被提交。
配置示例:
# 生产者配置
acks=all
min.insync.replicas=2# Broker配置
default.replication.factor=3
min.insync.replicas=2四、ACK机制的性能与可靠性权衡
不同 ACK 模式对系统性能和可靠性的影响:
| ACK 模式 | 可靠性 | 吞吐量 | 延迟 | 适用场景 |
| acks=0 | 最低 | 最高 | 最低 | 日志收集、监控数据 |
| acks=1 | 中等 | 中等 | 中等 | 普通业务数据 |
| acks=all | 最高 | 最低 | 最高 | 金融交易、订单系统 |
4.1 性能优化建议
- 若对数据可靠性要求不高,使用 acks=0 提升吞吐量。
- 若需保证可靠性,使用 acks=all 并结合 min.insync.replicas=2。
- 启用生产者幂等性(enable.idempotence=true)避免重试导致的重复消息。
4.2 可靠性保障策略
- 使用 acks=all 确保消息被所有 ISR 副本接收。
- 设置 min.insync.replicas 防止在 ISR 副本不足时提交数据。
- 监控 ISR 状态,确保副本同步正常。
五、ACK机制的配置与代码示例
5.1 生产者配置示例
import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// ACK机制配置
props.put("acks", "all"); // 最高可靠性
props.put("min.insync.replicas", "2"); // 最小ISR副本数
props.put("retries", 3); // 重试次数
props.put("enable.idempotence", true); // 启用幂等性Producer<String, String> producer = new KafkaProducer<>(props);// 发送消息ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");
producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception != null) {System.err.println("消息发送失败: " + exception.getMessage());} else {System.out.println("消息发送成功,offset: " + metadata.offset());}}}); producer.close();}
}
5.2 关键配置参数说明
| 参数名 | 含义 |
| acks | 消息确认级别(0、1、all) |
| min.insync.replicas | ISR 最小副本数,与 acks=all 配合使用 |
| retries | 发送失败时的重试次数 |
| retry.backoff.ms | 重试间隔时间(毫秒) |
| enable.idempotence | 是否启用生产者幂等性(默认 true) |
六、ACK机制常见问题与解决方案
6.1 消息丢失问题
- 原因:使用 acks=0 或 acks=1 且 Leader 故障。
- 解决方案:使用 acks=all 并确保 min.insync.replicas > 1。
6.2 吞吐量下降问题
- 原因:acks=all 需要等待所有 ISR 副本确认。
- 解决方案:
- 增加 ISR 副本数并优化网络环境。
- 使用批量发送(batch.size 和 linger.ms)。
6.3 生产者异常处理
- 错误码:NOT_ENOUGH_REPLICAS(ISR 副本不足)。
- 处理方式:
if (exception instanceof RetriableException) {// 可重试异常,自动重试} else {// 不可重试异常,记录日志或回滚操作}
七、总结
Kafka 的 ACK 机制是实现数据可靠性的核心组件,通过灵活配置 acks 参数,用户可以在可靠性和性能之间找到平衡点。以下是关键要点总结:
1. 三种 ACK 模式:
- acks=0:不等待确认,性能最高但可靠性最低。
- acks=1:等待 Leader 确认,平衡可靠性和性能。
- acks=all:等待所有 ISR 确认,可靠性最高但性能最低。
2. 与 ISR 协同:
- acks=all 需结合 min.insync.replicas 确保数据安全。
- 监控 ISR 状态是保障可靠性的关键。
3. 最佳实践:
- 金融交易等敏感场景使用 acks=all + min.insync.replicas=2。
- 普通业务使用 acks=1 并启用幂等性。
- 日志收集使用 acks=0 提升性能。
通过深入理解 ACK 机制的工作原理和配置策略,开发者可以构建出既可靠又高效的 Kafka 应用系统。