目录
- 1. 全文搜索引擎(Elastic Search)的由来
- 2. Elastic Search 概述
- 2.1 Elastic Search 介绍
- 2.2 Elastic Search 功能
- 2.3 Elastic Search 特点
- 3. 安装 Elastic Search
- 3.1 ES 的安装
- 3.2 安装 kibana
- 3.3 ES 客户端的安装
- 4. Elastic Search 基本概念
- 4.1 集群(Cluster)
- 4.2 节点(Node)
- 5. 索引&类型&文档&字段&映射
- 5.1 索引(Index)
- 5.2 类型(Type)
- 5.3 文档(Document)
- 5.4 映射(Mapping)
- 6. 分片&副本
- 6.1 分片(Shards)
- 6.2 副本(Replicas)
- 6.3 分析器
- 7. ES RESTful 操作
- 7.1 索引操作
- 7.1.1 创建索引
- 7.1.2 查看索引
- 7.1.3 删除索引
- 7.2 类型操作
- 7.2.1 创建类型
- 7.2.2 查看类型
- 7.3 文档操作
- 7.3.1 增加文档
- 7.3.2 查看文档
- 7.3.3 修改文档
- 7.3.4 删除文档
- 8. 倒排索引
- 9. Elastic Search 总结
1. 全文搜索引擎(Elastic Search)的由来
(1)当系统数据量上了10亿、100亿条的时候,我们用什么数据库好?如何解决单点故障?如何提升检索速度?如何解决统计分析问题?
- 传统数据库的应对解决方案:
- 关系型数据库:
- 通过主从备份解决数据安全性问题;
- 通过数据库代理中间件心跳监测,解决单点故障问题;
- 通过代理中间件将查询语句分发到各个slave节点进行查询,并汇总结果;
- 非关系型数据库:
- 通过副本备份保证数据安全性;
- 通过节点竞选机制解决单点问题;
- 先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果;
- 关系型数据库:
- 另辟蹊径
- 存储数据时按有序存储;
- 将数据和索引分离;
- 压缩数据;
- 于是,Elastic Search就在这种背景下诞生了。

2. Elastic Search 概述
2.1 Elastic Search 介绍
(1)介绍如下:
- Elatic search,简称为 ES, ES 是一个开源的高扩展的分布式全文搜索引擎,是整个 Elastic Stack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
- Elastic search是一个分布式、可扩展、近实时的高性能搜索与数据分析引擎。Elastic search基于Apache Lucene构建,采用Java编写,并使用Lucene构建索引、提供搜索功能。Elastic search的目标是让全文搜索功能的落地变得简单。
2.2 Elastic Search 功能
(1)具体功能如下:
- Lucene 是开源的搜索引擎工具包,Elastic search 充分利用Lucene,并对其进行了扩展,使存储、索引、搜索都变得更快、更容易, 而最重要的是, 正如名字中的“ elastic ”所示, 一切都是灵活、有弹性的。而且,应用代码也不是必须用Java 书写才可以和Elastic search兼容,完全可以通过JSON 格式的HTTP 请求来进行索引、搜索和管理Elastic search 集群。
- Elasticsearch是一个基于Apache Lucene™的开源搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
- 但是,Lucene只是一个库。想要发挥其强大的作用,你需使用Java并要将其集成到你的应用中。Lucene非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的。
- Elastic search也是使用Java编写并使用Lucene来建立索引并实现搜索功能,但是它的目的是通过简单连贯的RESTful API让全文搜索变得简单并隐藏Lucene的复杂性。
(2)不过,Elastic search不仅仅是Lucene和全文搜索引擎,它还提供:
- 分布式的实时文件存储,每个字段都被索引并可被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据 而且,所有的这些功能被集成到一台服务器,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。
(3)上手Elasticsearch非常简单,它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。
- 它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。
- Elastic search在Apache 2 license下许可使用,可以免费下载、使用和修改。 随着知识的积累,你可以根据不同的问题领域定制Elastic search的高级特性,这一切都是可配置的,并且配置非常灵活。
2.3 Elastic Search 特点
(1)特点如下所示:
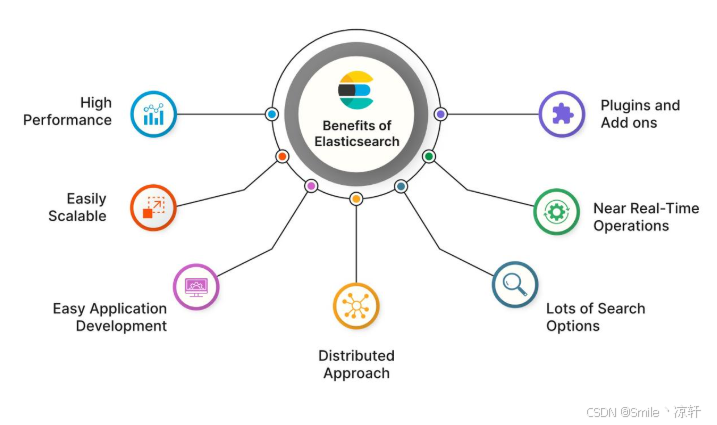
- 分布式实时文件存储。Elasticsearch可将被索引文档中的每一个字段存入索引,以便字段可以被检索到。
- 实时分析的分布式搜索引擎。Elasticsearch的索引分拆成多个分片,每个分片可以有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;负载再平衡和路由会自动完成。
- 高可拓展性。大规模应用方面,Elasticsearch可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。当然,Elasticsearch也可以运行在单台PC上。
- 可插拔插件支持。Elasticsearch支持多种插件,如分词插件、同步插件、Hadoop插件、可视化插件等。
3. 安装 Elastic Search
3.1 ES 的安装
# 添加仓库秘钥
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
# 上边的添加方式会导致一个 apt-key 的警告,如果不想报警告使用下边这个
curl -s https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --no-default-keyring --keyring gnupgring:/etc/apt/trusted.gpg.d/icsearch.gpg --import
# 以上两种方法二选一# 添加镜像源仓库
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elasticsearch.list
# 更新软件包列表
sudo apt update
# 安装 es
sudo apt-get install elasticsearch=7.17.21
# 启动 es
sudo systemctl start elasticsearch
# 安装 ik 分词器插件
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/7.17.21
3.2 安装 kibana
# 使用 apt 命令安装 Kibana。
sudo apt install kibana
# 配置 Kibana(必选):根据需要配置 Kibana。配置文件通常位于 /etc/kibana/kibana.yml。可能需要设置如服务器地址、端口、Elasticsearch URL 等。
sudo vim /etc/kibana/kibana.yml
# 例如,你可能需要设置 Elasticsearch 服务的 URL: 大概 32 行左右elasticsearch.host: "http://localhost:9200"
# 修改如下位置并且将注释去除:
# server.host: "0.0.0.0"# 启动 Kibana 服务:
sudo systemctl start kibana
# 设置开机自启(可选):如果你希望 Kibana 在系统启动时自动启动,可以使用以下命令来启用自启动。
sudo systemctl enable kibana
# 验证安装:使用以下命令检查 Kibana 服务的状态。
sudo systemctl status kibana
# 访问 Kibana:在浏览器中访问 Kibana,通常是 http://<your-ip>:5601
3.3 ES 客户端的安装
# 先安装依赖
sudo apt-get install libmicrohttpd-dev
# 克隆代码
git clone https://github.com/seznam/elasticlient
# 切换目录
cd elasticlient
# 更新子模块
git submodule update --init --recursive
# 编译代码
mkdir build && cd build
# cmake生成Makefile
cmake -DCMAKE_INSTALL_PREFIX=/usr ..
# 安装
make && sudo make install
4. Elastic Search 基本概念
(1)基本概念:
- Elasticsearch就被设计为能处理数以亿计的文档和每秒数以百计的搜索请求的分布式解决方案。这归功于几个重要的概念,我们现在将更详细地描述。
(2)节点&集群:
- Elastic search 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic search 实例。单个 Elastic search 实例称为一个节点(Node),一组节点构成一个集群(Cluster)。节点&集群的详细介绍如下。
4.1 集群(Cluster)
(1)集群的概念:
- 集群是一个或多个节点的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。群集由唯一的名称标识,默认情况下为“elasticsearch”。此名称很重要,因为如果节点设置为按名称加入群集,则该节点只能是群集的一部分。
- 确保不要在不同的环境中重用相同的群集名称,否则很可能会导致节点加入错误的群集。例如,您可以使用logging-dev,logging-stage以及logging-prod用于开发,预发和生产环境。
- 值得注意的是,如果群集中只有一个节点,那么它是完全正常的。此外,您还可以拥有多个独立的集群,每个集群都有自己唯一的集群名称。
4.2 节点(Node)
(1)节点的概念:
- 节点是作为集群一部分的单个服务器,存储数据并参与集群的索引和搜索功能。就像集群一样,节点由名称标识,默认情况下,该名称是在启动时分配给节点的随机通用唯一标识符(UUID)。如果不需要默认值,可以定义所需的任何节点名称。此名称对于管理目的非常重要,您可以在其中识别网络中哪些服务器与Elasticsearch集群中的哪些节点相对应。
- 可以将节点配置为按集群名称加入特定群集。默认情况下,每个节点都设置为加入一个名为cluster的集群elasticsearch,这意味着如果您在网络上启动了许多节点并且假设它们可以相互发现,它们将自动形成并加入一个名为elasticsearch的集群。
- 在单个集群中,可以拥有任意数量的节点。此外,如果网络上当前没有其他Elasticsearch节点正在运行,则默认情况下启动单个节点将形成一个名为elasticsearch的新单节点集群。
5. 索引&类型&文档&字段&映射
(1)和数据库的映射关系如下图:
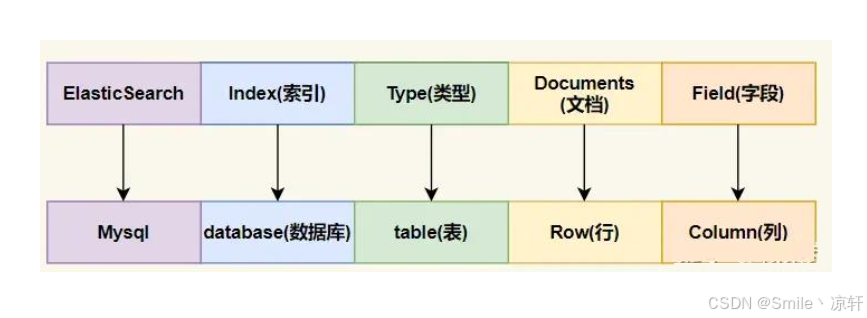
(2)什么是 index (索引) ?
- 一个 索引 就是一个拥有几分相似特征的文档的集合。ES 将数据存储于一个或多个索引中,索引 就相当于 SQL 中的一个数据库。
(3)什么是 Type(类型)?
- 类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。类比传统的关系型数据库领域来说,类型 相当于 表,7.x 版本默认使用 _doc 作为 type 。
(4)什么是 Document(文档)?
- 文档是 Lucene 索引和搜索的 原子单位,它是包含了一个或多个域的容器,基于 Json 格式进行表示。文档有一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常被称为 多值域,每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。相当于 mysql 表中的 row 。
(5)什么是 Field (字段)?
- Field 是相当于数据库中的 Column。
(6)上述索引&类型&文档&字段结构图如下:
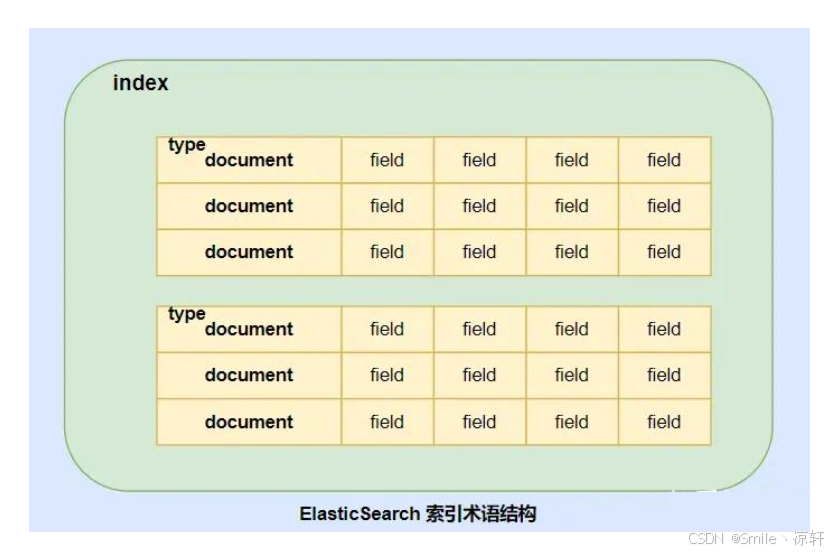
(7)什么是 Mapping(映射)?
- Mapping 是定义文档及其包含的字段如何存储和索引的过程。Mapping 是 ES 中的一个很重要的内容,它类似于传统关系型数据中 table 的 schema,用于定义一个索引(index)的某个类型(type)的数据结构。
5.1 索引(Index)
(1)索引的概念:
- 索引是具有某些类似特征的文档集合。 例如,可以给客户数据建立一个索引,给产品目录建立另一个索引或给订单数据的建立一个索引。
- 索引有一个名称标识(必须全部小写),此名称用于在对其中的文档执行索引,搜索,更新和删除操作时引用索引所用。 在单个群集中,您可以根据需要定义任意数量的索引。
- 索引 (index)是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分。你可以把索引看成关系型数据库的表。然而,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。
- Elasticsearch可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片 (shard),每个分片可以有多个副本 (replica)。
5.2 类型(Type)
(1)类型的概念:
- type是一个逻辑意义上的分类或者叫分区,允许在同一索引中建立多个type。本质是相当于一个过滤条件,高版本将会废弃type概念。
- 不同_type下的字段不能冲突,删除整个_type也不会释放空间。在实际应用中,数据模型不同,有不同_type需求的时候,我们应该建立单独的索引,而不是在一个索引下使用不同的_type。删除过期老化的数据时,最好以索引为单位,而不是_type和_id。
- 正由于_type在实际应用中容易引起概念混淆,以及允许索引存在多_type并没有什么实际意义,在ES 6.x版本中,一个索引只允许存在一个_type,未来的7.x版本将完全删除_type的概念。
5.3 文档(Document)
(1)文档的概念:
- 文档是可以编制索引的基本信息单元。例如,您可以为单个客户提供文档,为单个产品提供另一个文档,为单个订单提供另一个文档。该文档以JSON(JavaScript Object Notation)表示,JSON是一种普遍存在的互联网数据交换格式。
- ES是面向文档的。各种文本内容以文档的形式存储到ES中,文档可以是一封邮件、一条日志,或者一个网页的内容。一般使用 JSON 作为文档的序列化格式,文档可以有很多字段,在创建索引的时候,我们需要描述文档中每个字段的数据类型,并且可能需要指定不同的分析器,就像在关系型数据中“CREATE TABLE”一样。
- 在索引/类型中,可以根据需要存储任意数量的文档。 值得注意的是,尽管文档实际上驻留在索引中,但实际上必须将文档分配给索引中的一个类型(type)中。
- 在存储结构上,由_index、_type和_id唯一标识一个文档。
- _index指向一个或多个物理分片的逻辑命名空间,_type类型用于区分同一个集合中的不同细分,在不同的细分中,数据的整体模式是相同或相似的,不适合完全不同类型的数据。多个_type可以在相同的索引中存在,只要它们的字段不冲突即可(对于整个索引,映射在本质上被“扁平化”成一个单一的、全局的模式)。_id文档标记符由系统自动生成或使用者提供。
- 存储在Elastic search中的主要实体叫文档 (document)。用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。Elasticsearch的文档中,相同字段必须有相同类型。这意味着,所有包含title 字段的文档,title 字段类型都必须一样,比如string 。
- 文档由多个字段 组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段 (multivalued)。每个字段有类型,如文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数组。字段类型在Elasticsearch中很重要,因为它给出了各种操作(如分析或排序)如何被执行的信息。幸好,这可以自动确定,然而,我们仍然建议使用映射。
- 与关系型数据库不同,文档不需要有固定的结构,每个文档可以有不同的字段,此外,在程序开发期间,不必确定有哪些字段。当然,可以用模式强行规定文档结构。
- 从客户端的角度看,文档是一个JSON对象。每个文档存储在一个索引中并有一个Elasticsearch自动生成的唯一标识符和文档类型 。文档需要有对应文档类型的唯一标识符,这意味着在一个索引中,两个不同类型的文档可以有相同的唯一标识符。
(2)文档类型:
- 在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评论。文档类型让我们轻易地区分单个索引中的不同对象。每个文档可以有不同的结构,但在实际部署中,将文件按类型区分对数据操作有很大帮助。
- 当然,需要记住一个限制,不同的文档类型不能为相同的属性设置不同的类型。例如,在同一索引中的所有文档类型中,一个叫title 的字段必须具有相同的类型。
5.4 映射(Mapping)
(1)映射的概念:
- 文档中的每个字段都必须根据不同类型做相应的分析。举例来说,对数值字段和从网页抓取的文本字段有不同的分析,比如前者的数字不应该按字母顺序排序,后者的第一步是忽略HTML标签,因为它们是无用的信息噪音。
- Elasticsearch在映射中存储有关字段的信息。每一个文档类型都有自己的映射,即使我们没有明确定义。
6. 分片&副本
(1)什么是 Shard (分片)?
- 一个 索引 可以存储超出单个结点硬件限制的大量数据。比如,一个具有 10亿文档的索引占据 1TB 的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
- 为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,这些份就叫做 分片。当你创建一个索引的时候,你可以指定你想要的 分片的数量。每个分片本身也是一个功能完善并且独立的 索引,这个 索引 可以被放置到集群中的任何节点上。
(2)分片之所以重要,主要有两方面的原因:
- 允许你水平分割/扩展你的内容容量。
- 允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
- 一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由 Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的
(3)什么是 Replica (副本)?
- 副本是一个分片的精确复制,每个分片可以有零个或多个副本。副本的作用:
- 提高系统的容错性,当某个节点某个分片损坏或丢失时,可以从副本中恢复。
- 提高 ES 查询效率,ES 会自动对搜索请求进行负载均衡。
6.1 分片(Shards)
(1)分片概述:
- 索引可能存储大量可能超过单个节点硬件限制的数据。例如,占用1TB磁盘空间的十亿个文档的单个索引可能不适合单个节点的磁盘,或者可能太慢而无法单独从单个节点提供搜索请求。
- 为了解决这个问题,Elasticsearch提供了将索引细分为多个称为分片的功能。创建索引时,只需定义所需的分片数即可。每个分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。
(2)分片很重要,主要有两个原因:
- 它允许集群进行水平扩展;
- 它允许集群跨分片(可能在多个节点上)分布和并行化操作,从而提高性能和吞吐量。 分片的分布方式以及如何将其文档聚合回搜索请求的机制完全由Elastic Search管理,对用户而言是透明的。
(3)当有大量的文档时,由于内存的限制、硬盘能力、处理能力不足、无法足够快地响应客户端请求等,一个节点可能不够。在这种情况下,数据可以分为较小的称为分片 (shard)的部分(其中每个分片都是一个独立的Apache Lucene索引)。
- 每个分片可以放在不同的服务器上,因此,数据可以在集群的节点中传播。当你查询的索引分布在多个分片上时,Elasticsearch会把查询发送给每个相关的分片,并将结果合并在一起,而应用程序并不知道分片的存在。此外,多个分片可以加快索引。
- 在分布式系统中,单机无法存储规模巨大的数据,要依靠大规模集群处理和存储这些数据,一般通过增加机器数量来提高系统水平扩展能力。因此,需要将数据分成若干小块分配到各个机器上。然后通过某种路由策略找到某个数据块所在的位置。
6.2 副本(Replicas)
(1)副本概述:
- 为了提高查询吞吐量或实现高可用性,可以使用分片副本。副本 (replica)只是一个分片的精确复制,每个分片可以有零个或多个副本。换句话说,Elasticsearch可以有许多相同的分片,其中之一被自动选择去更改索引操作。这种特殊的分片称为主分片 (primary shard),其余称为副本分片 (replica shard)。在主分片丢失时,例如该分片数据所在服务器不可用,集群将副本提升为新的主分片。
- 除了将数据分片以提高水平扩展能力,分布式存储中还会把数据复制成多个副本,放置到不同的机器中,这样一来可以增加系统可用性,同时数据副本还可以使读操作并发执行,分担集群压力。但是多数据副本也带来了一致性的问题:部分副本写成功,部分副本写失败。
- 为了应对并发更新问题,ES将数据副本分为主从两部分,即主分片(primary shard)和副分片(replica shard)。主数据作为权威数据,写过程中先写主分片,成功后再写副分片,恢复阶段以主分片为准。
- 分片(shard)是底层的基本读写单元,分片的目的是分割巨大索引,让读写可以并行操作,由多台机器共同完成。读写请求最终落到某个分片上,分片可以独立执行读写工作。ES利用分片将数据分发到集群内各处。分片是数据的容器,文档保存在分片内,不会跨分片存储。分片又被分配到集群内的各个节点里。当集群规模扩大或缩小时,ES 会自动在各节点中迁移分片,使数据仍然均匀分布在集群里。
6.3 分析器
(1)分析器概述:
- 对于字符串类型的字段,可以指定Elastic search应该使用哪个分析器。使用分析器时,只需在指定字段的正确属性上设置它的名字,就这么简单。
- Elastic search允许我们使用众多默认定义的分析器中的一种。如下分析器可以开箱即用:
- standard :方便大多数欧洲语言的标准分析器。
- simple :这个分析器基于非字母字符来分离所提供的值,并将其转换为小写形式。
- whitespace :这个分析器基于空格字符来分离所提供的值。
- stop :这个分析器类似于simple 分析器,但除了simple 分析器的功能,它还能基于所提供的停用词(stop word)过滤数据。
- keyword :这是一个非常简单的分析器,只传入提供的值。你可以通过指定字段为not_analyzed 来达到相同的目的。
- pattern :这个分析器通过使用正则表达式灵活地分离文本。
- language :这个分析器旨在特定的语言环境下工作。
- snowball :这个分析器类似于standard 分析器,但提供了词干提取算法。
7. ES RESTful 操作
7.1 索引操作
7.1.1 创建索引
(1)语法如下:
// 创建索引 请求方式只能是PUT /user表示创建一个user索引
// settings表示这个索引的一些设置 number_of_shards表示分片数量
// number_of_replicas 表示每个分片的副本数量
PUT /user
{"settings": {"number_of_shards": 3,"number_of_replicas": 1}
}
(2)结果:
// acknowledged表示索引创建的回执信息,也就是响应的结果
// shards_acknowledged表示索引分片创建的回执信息
// index表示索引的名称
{"acknowledged" : true, "shards_acknowledged" : true,"index" : "user"
}
7.1.2 查看索引
(1)语法如下:
GET /user
(2)结果:
// user表示索引名称
// aliases表示索引的别名
// mappings表示索引中的字段
// settings表示索引的创建信息
{"user" : {"aliases" : { },"mappings" : { },"settings" : {"index" : {"creation_date" : "1667629798434","number_of_shards" : "3","number_of_replicas" : "1","uuid" : "VwShKX6-TliIeCIKttsRwA","version" : {"created" : "7060299"},"provided_name" : "user"}}}
}
7.1.3 删除索引
(1)语法如下:
DELETE /user
(2)结果:
{"acknowledged" : true
}
7.2 类型操作
7.2.1 创建类型
(1)语法如下:
// /user/_mappings表示设置user索引的具体数据结构,相当于定义类中的属性
// class User{ String name; String sex; int age; Date birthday;}
PUT /user/_mappings
{"properties": {"name": {"type": "text","analyzer": "ik_max_word","index": true,"store": false},"sex": {"type": "keyword"},"age": {"type": "integer"},"birthday": {"type": "date","format": "yyyy-MM-dd"}}
}
(2)结果:
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "user"
}
7.2.2 查看类型
(1)语法如下:
GET /user
(2)结果:
{"user" : {"aliases" : { },"mappings" : {"properties" : {"age" : {"type" : "integer"},"birthday" : {"type" : "date","format" : "yyyy-MM-dd"},"name" : {"type" : "text","analyzer" : "ik_max_word"},"sex" : {"type" : "keyword"}}},"settings" : {"index" : {"creation_date" : "1667631425739","number_of_shards" : "5","number_of_replicas" : "1","uuid" : "hfhUHBKWQZukfeZLlteHKQ","version" : {"created" : "7060299"},"provided_name" : "user"}}}
}
7.3 文档操作
7.3.1 增加文档
(1)语法如下:
POST /user/_doc
{"name": "张三","sex": "男","age": 20,"birthday": "2000-05-06"
}
(2)结果:
{"_index" : "user","_type" : "_doc","_id" : "lfKkRoQB18W7DskkwOaq","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}
7.3.2 查看文档
(1)语法如下:
GET /user/_search
{"query": {"match_all": {}}
}
(2)结果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "user","_type" : "_doc","_id" : "lfKkRoQB18W7DskkwOaq","_score" : 1.0,"_source" : {"name" : "张三","sex" : "男","age" : 20,"birthday" : "2000-05-06"}}]}
}
7.3.3 修改文档
(1)语法如下:
// 修改语法: /索引/_doc/数据ID
// 这种修改需要注意,不是只修改一个属性,而是对整个文档进行修改,可以理解为是用一个新的文档去替换原来的文档完成修改。如果新的文档
// 只有1个属性,那么替换后的文档也只有1个属性。
PUT /user/_doc/lfKkRoQB18W7DskkwOaq
{"sex": "女"
}
(2)结果:
{"_index" : "user","_type" : "_doc","_id" : "lfKkRoQB18W7DskkwOaq","_version" : 3,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1
}
7.3.4 删除文档
(1)语法如下:
DELETE /user/_doc/lfKkRoQB18W7DskkwOaq
(2)结果:
{"_index" : "user","_type" : "_doc","_id" : "lfKkRoQB18W7DskkwOaq","_version" : 4,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1
}
8. 倒排索引
(1)如下图所示:
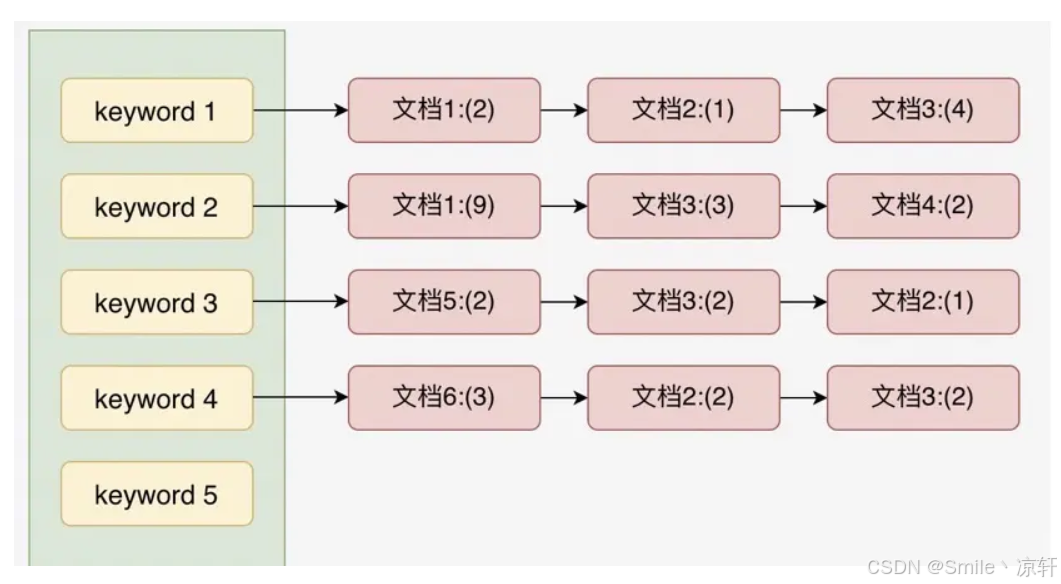
- 将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中。
- 当用户去查询数据时,会将用户的查询关键字进行分词。
- 然后去分词库中匹配内容,最终得到数据的id标识。
- 根据id标识去存放数据的位置拉取到指定的数据。
9. Elastic Search 总结
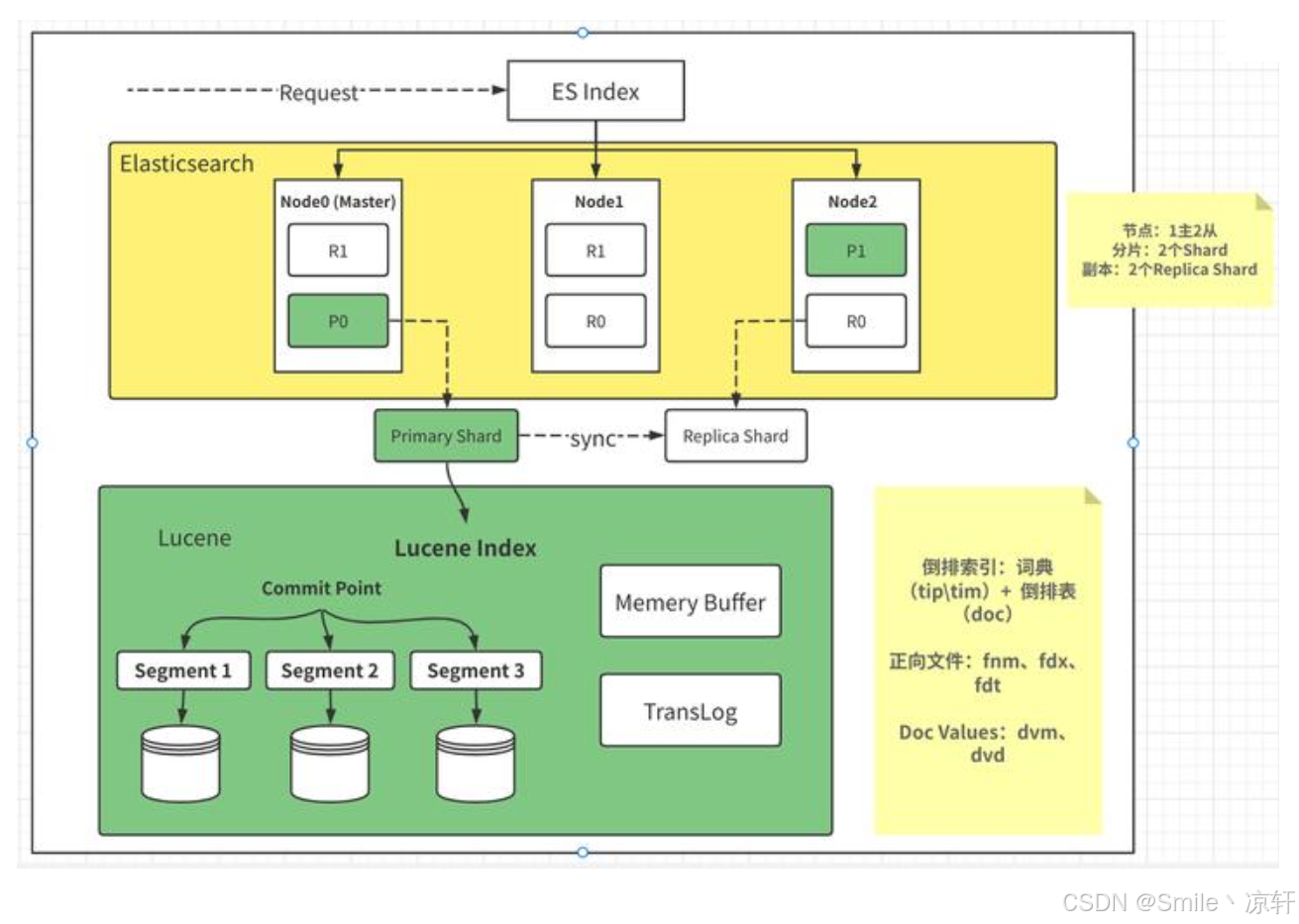
(1)ES 的框架图:
(2)核心概念:

(3)核心特性:
- 分布式架构:
- 数据自动分片(Sharding)和副本(Replication)。
- 支持水平扩展至上千节点,处理 PB 级数据。
- 实时搜索:
- 写入数据后 1 秒内 可被检索(近实时 NRT)。
- 全文搜索:
- 支持复杂查询:模糊匹配、短语搜索、同义词扩展等。
- 基于 TF-IDF 或 BM25 的相关性评分。
- 聚合分析:
- 支持统计、分组、直方图、地理分析等,如:
"aggs": { "avg_price": { "avg": { "field": "price" } } }
- RESTful API:
- 所有操作通过 HTTP API 完成,如:
GET /books/_search?q=title:elastic
(4)核心组件:
- Elastic Stack(ELK):
| 组件 | 作用 |
|---|---|
| Elasticsearch | 数据存储与检索 |
| Logstash | 数据采集、转换、管道处理 |
| Kibana | 数据可视化、仪表盘 |
| Beats | 轻量级数据采集器(Filebeat, Metricbeat) |
- 分词器(Analyzer):
- 包含:字符过滤器 → 分词器 → 词单元过滤器。
- 内置分词器:standard、ik_smart(中文智能分词)。
(5)应用场景:
- 日志分析:结合 ELK Stack 实现实时日志收集、分析和告警。
- 全文搜索引擎:电商商品搜索、新闻内容检索。
- 实时监控:应用性能监控(APM)、基础设施指标分析。
- 推荐系统:基于用户行为的个性化推荐(结合协同过滤)。
- 地理空间分析:支持 geo_point 类型,实现附近地点搜索。
(6)Elasticsearch 的核心价值在于:
- 实时处理海量数据。
- 分布式扩展应对高并发。
- 全文搜索与复杂分析一体化。
- 强大的 ELK 生态集成。











![[免费]SpringBoot+Vue垃圾分类管理【论文+源码+SQL脚本】](https://i-blog.csdnimg.cn/direct/6e930f3dde3c4f2bb9cf4501c8642e1c.jpeg)