一、 文本预处理的基石:为什么关注停用词?
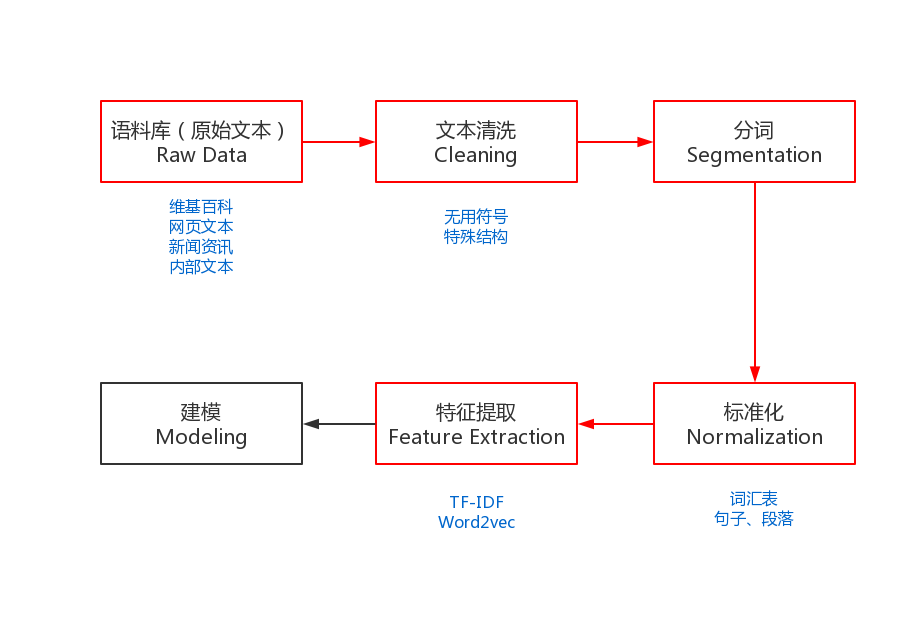
在自然语言处理(NLP)的流程中,原始文本数据必须经过预处理才能被算法有效理解。文本预处理包括:
-
分词(Tokenization)
-
停用词过滤(Stopword Removal)
-
词干提取/词形还原(Stemming/Lemmatization)
-
大小写转换(Lowercasing)
-
拼写校正等步骤
其中,停用词处理直接关系到特征空间的质量与模型效率。未经处理的文本中,高频功能词(如“的”、“是”、“in”、“the”)占比可达30%-50%,这些词汇:
-
携带极少语义信息
-
显著增加计算复杂度
-
稀释关键词语义权重
-
导致稀疏特征矩阵问题
例如在情感分析中,“这个产品真的非常好”中,“真的”作为停用词去除后,“非常好”的情感强度反而更突出。
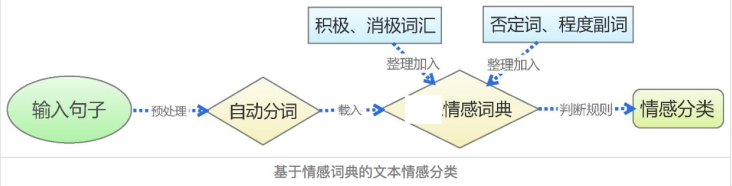
二、 停用词的深层定义:超越直觉的理解
2.1 语言学视角
停用词(Stop Words)主要指不承担核心语义功能的词语类别:
-
功能词:介词(in, on)、连词(and, or)、冠词(a, the)
-
代词:我、你、它(I, you, it)
-
助动词:是、有(be, have)
-
部分副词:很、非常(very, extremely)
2.2 统计学视角
基于词频(TF-IDF)的停用词判定:
from sklearn.feature_extraction.text import TfidfVectorizercorpus = ["This is a sample document.", "Another example document."]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)# 输出词项IDF值
print(dict(zip(vectorizer.get_feature_names_out(), vectorizer.idf_)))输出示例:
{'document': 1.0, 'sample': 1.4, 'this': 1.4, 'is': 1.4, 'a': 1.4}
# "a", "is", "this" 具有较高IDF?实际场景需更大语料关键洞察:完全依赖预设词表可能导致错误过滤。如“can”在“I can help”中为助动词,但在“tin can”中为名词。
三、 停用词处理的核心方法
3.1 基于预定义词表(Rule-Based)
-
常用库默认词表:
-
NLTK:179个英文停用词
-
spaCy:326个英文停用词
-
中文:哈工大停用词表(1200+)、百度停用词表
# 中文停用词过滤示例 (Jieba分词) import jieba from jieba.analyse import set_stop_wordsset_stop_words("chinese_stopwords.txt") text = "机器学习模型需要高质量的数据预处理" words = [word for word in jieba.cut(text) if word not in stopwords] # ['机器学习', '模型', '需要', '高质量', '数据', '预处理']
-
3.2 基于统计阈值(Data-Driven)
-
词频倒排法:移除语料中频率最高的前N%词语
-
TF-IDF阈值法:过滤IDF值低于阈值的词项
-
词熵筛选法:选择信息熵高的词语保
# 基于词频自动生成停用词表 from collections import Counterword_counts = Counter(all_tokens) top_10_percent = int(len(word_counts) * 0.1) stopwords_auto = {word for word, count in word_counts.most_common(top_10_percent)}
3.3 混合方法(Hybrid Approach)
- 使用基础词表进行初筛
- 基于当前语料统计动态补充
- 结合词性标注(POS Tagging)过滤特定词性
# spaCy实现词性辅助过滤 import spacynlp = spacy.load("en_core_web_sm") doc = nlp("The quick brown fox jumps over the lazy dog") filtered = [token.text for token in doc if not token.is_stop and token.pos_ not in ["DET", "AUX"]]
四、 多语言停用词处理的特殊挑战
4.1 中文处理的特殊性
-
分词依赖:停用词移除必须在分词后进行
-
虚词复杂性:如助词“了”、“着”、“过”的语义敏感性
-
未登录词问题:新词与停用词冲突(如“的士”含“的”)
解决方案:
-
使用分词工具的词性标注功能
-
构建领域自适应停用词表
# Jieba词性标注过滤 import jieba.posseg as psegwords = pseg.cut("人工智能的发展速度惊人") filtered = [word for word, flag in words if flag not in ['u', 'c'] and word not in stopwords]
4.2 形态丰富语言(如俄语、阿拉伯语)
-
功能词存在复杂变体
-
需要词形归一化后再过滤
-
示例:阿拉伯语冠词 "ال" (al-) 需处理附着形式
五、 实践中的关键决策点
5.1 何时应该保留停用词?
-
情感分析:否定词(not, never)决定情感极性
-
问答系统:代词(it, he)可能指代关键实体
-
短语检索:介词决定关系(“flight to” vs “flight from”)
5.2 领域自适应策略
-
医疗领域:保留否定词(“no”, “negative”)
-
法律文本:保留情态动词(“shall”, “must”)
-
社交媒体:添加网络用语停用词(“lol”, “omg”)
领域停用词扩展代码:
medical_stopwords = base_stopwords - {'no', 'without', 'negative'} | {'patient', 'diagnosis'} # 添加领域高频非功能词六、 主流NLP库的停用词实现对比
| 工具 | 语言支持 | 词表大小 | 自定义便捷性 | 词性集成 |
|---|---|---|---|---|
| NLTK | 多语言 | ★★☆ | ★★★ | ✘ |
| spaCy | 多语言 | ★★★ | ★★☆ | ✔ |
| Gensim | 多语言 | ★★☆ | ★★★ | ✘ |
| Jieba | 中文 | ★★★ | ★★★ | ✔ |
| SnowNLP | 中文 | ★★☆ | ★★☆ | ✘ |
# spaCy停用词自定义示例
from spacy.lang.en.stop_words import STOP_WORDS# 添加新停用词
STOP_WORDS |= {"awesome", "cool"}
# 从停用词集中移除
STOP_WORDS.remove("not")七、 处理陷阱与最佳实践
7.1 常见错误
-
过度过滤:删除否定词导致语义反转
-
跨语言误用:英文词表用于中文处理
-
忽略大小写:“US” (美国) vs “us” (我们)
-
未处理变形:goes, went 未关联到go
7.2 最佳实践清单
-
任务驱动选择:根据下游任务决定过滤策略
-
语料分析先行:可视化词频分布(词云/直方图)
-
保留否定词:显式标记否定范围
-
版本控制词表:记录停用词表版本
-
A/B测试验证:比较过滤前后的模型效果
# 否定范围处理示例(spaCy依赖解析) def handle_negation(doc):negations = {"not", "no", "never"}for token in doc:if token.dep_ == "neg" or token.text in negations:# 标记后续词语为否定for child in token.head.children:child._.is_negated = Truereturn doc
八、 深度学习时代的新思考
8.1 嵌入技术的挑战
-
Word2Vec/GloVe等嵌入模型受停用词影响:
-
高频停用词作为上下文噪声
-
但可能携带风格/作者信息
-
-
BERT等Transformer模型:
-
自注意力机制自动学习词语重要性
-
[CLS], [SEP]等特殊标记部分替代停用词功能
-
8.2 可解释性需求
-
在模型决策解释中,停用词可能揭示:
-
文本风格特征
-
模板化结构
-
作者写作习惯
-
实验数据:在新闻分类任务中,保留停用词使CNN模型的准确率下降2.3%,但提高了可解释性报告中关键短语的完整性。
九、 完整处理流程示例(英文+中文)
# ===== 英文处理流水线 =====
import spacy
nlp_en = spacy.load("en_core_web_sm")def preprocess_en(text):doc = nlp_en(text)return [token.lemma_.lower()for token in docif not token.is_stop and not token.is_punctand token.is_alpha]# ===== 中文处理流水线 =====
import jieba
import jieba.posseg as psegjieba.load_userdict("custom_dict.txt")
stopwords = set(open('chinese_stopwords.txt').read().splitlines())def preprocess_zh(text):words = pseg.cut(text)return [word for word, flag in wordsif word not in stopwords and flag not in ['x', 'c'] # 过滤助词和连词and len(word) > 1 # 移除单字非实体]十、 未来发展与总结
10.1 进化方向
-
动态停用词识别:基于上下文的实时过滤
-
跨语言统一框架:解决低资源语言问题
-
神经网络过滤层:可学习的端到端停用词模块
10.2 核心结论
停用词处理不是简单的“删除高频词”,而是一个需要结合语言学知识、统计方法和业务目标的决策过程。在当今NLP实践中:
-
传统方法依然在轻量级场景中占优
-
深度学习模型降低了预处理的重要性
-
可解释性需求使停用词分析焕发新生