CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
一.增 insert
1.单行数据 + 全列插入
语法特点:不指定字段名,按表结构字段顺序依次提供所有值。
注意:字段顺序必须与表定义一致。
into可省略 每个字段都填入值时可以省略values前面的()
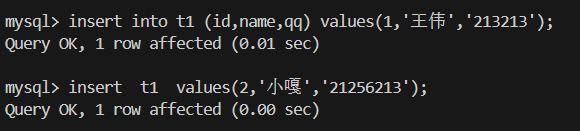
2.多行插入 + 指定列插入
优势:插入效率更高,推荐写法。
注意:指定列名后,后面所有的 value_list 数量和顺序必须一致。
多行插入时 用 ,号隔开

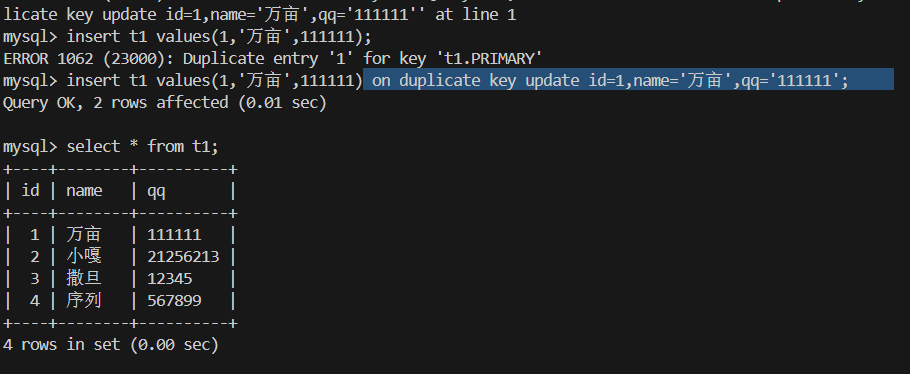
3.插入失败则更新 on duplicate key update
我们知道由于 主键 或者 唯一键 对应的值已经存在会导致插入失败 冲突,但我们想更新这行的内容怎么办?
on duplicate key update 字段=新值 ...
on duplicate key update表示如果前面的行插入失败了,说明和表中的某行冲突了,就把冲突的行对应字段值换成后面新值的行,当然新行不能和原表中的行冲突。
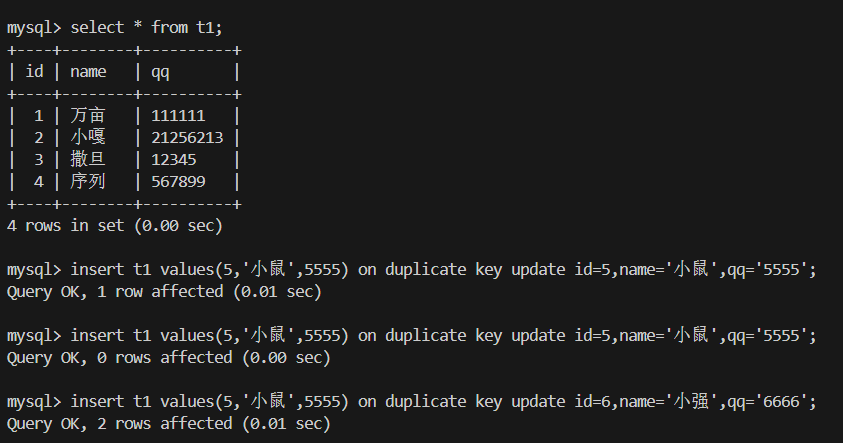
insert语句执行结果返回的 受影响行数
1.没有冲突行 插入成功 受影响1行
2.冲突 但值一致不需要改 受影响0行
3.冲突 值不一致 删除冲突行 换新行 受影响2行
情况 结果说明 没有冲突 正常插入 返回 1 行受影响 主键/唯一键冲突,值不变 不插入,也不更新,返回 0 行受影响 主键/唯一键冲突,值有更新 冲突行被更新,返回 2 行受影响 UPDATE 中再次引起其他唯一键冲突 会报错,事务中止
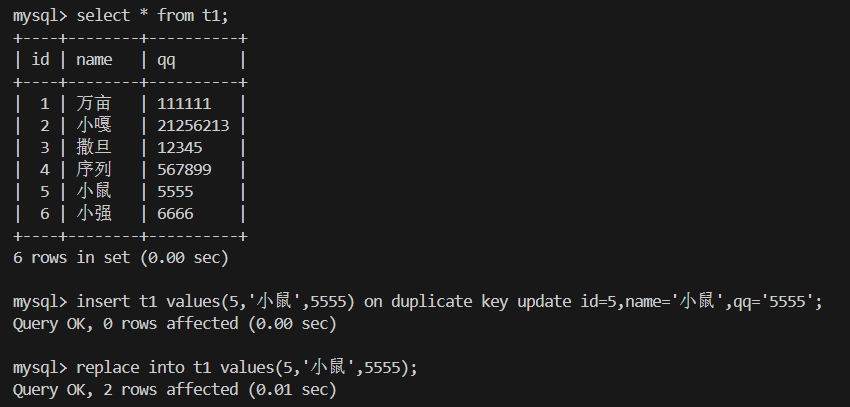
4.替换 replace into
replace into替换和insert into on duplicate key update更新区别在于,出现冲突时
1.replace into是先删除 再插入新的行
2.insert into duplicate key update只有修改主键时才会删除 再插入新行,不修改主键就只更新对应字段值就可以了。简单来说就是,不修改主键 就可以在原行中进行更新。
最明显的就是插入一个完全一样的行 冲突时,replace into还是会先删除再插入,执行完返回受影响的行数为2
而duplicate并不会进行删除修改,返回受影响的行数为0
replace into:无脑删+插,哪怕值一样也删你;
insert into on duplicate key update:只改有变的,不动就不碰你,改主键才会删+插。
| 维度 | replace into | insert into on duplicate key update |
|---|---|---|
| 基本功能 | 插入数据,如主键/唯一键冲突,则先删除旧行再插入新行 | 插入数据,如冲突,则直接更新已存在的冲突行 |
| 是否保留原主键(或 auto_increment) | ❌ 不保留,重新分配主键 ID(除非显式写入) | ✅ 保留原主键 |
| 是否真执行了 删除+插入 | ✅ 是(底层执行删除再插入) | ❌ 否(除非你显式更新主键字段,此时也会变成 删除+插入) |
| 是否支持部分字段更新 | ❌ 不支持,必须完整提供所有列(没有 UPDATE 子句) | ✅ 支持,只需要指定更新哪些列 |
| 使用场景推荐 | ✅ 推荐用于缓存表、日志表、临时去重 | ✅ 推荐用于需要维护业务数据一致性、幂等更新操作 |
| 性能影响 | ❌ 高(因为删除+插入) | ✅ 更好(原地更新) |
| 影响行数(无冲突) | 插入成功:1 行 | 插入成功:1 行 |
| 影响行数(冲突 + 值未变) | 删除 + 插入同值:2 行 | UPDATE 无变化:0 行 |
| 影响行数(冲突 + 值有变化) | 删除 + 插入不同值:2 行 | UPDATE 成功:2 行 |
二.查 select
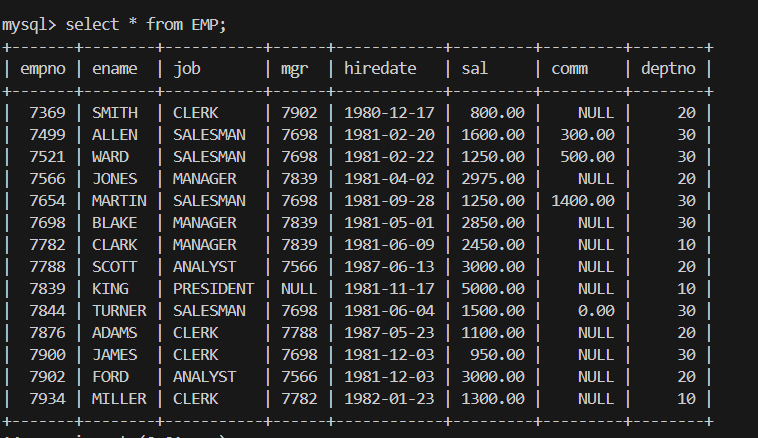
1.全列查询 select * from
2.指定列查询select 字段,字段 from
查询多个字段用 ,号隔开
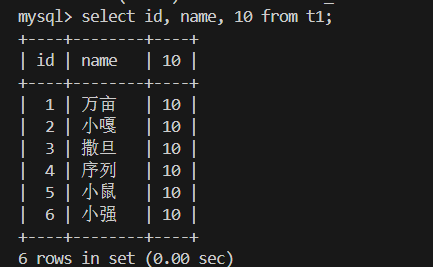
3.查询字段为表达式 select 字段 from
1.常量表达式(无字段):
所有行都会显示一个值为 10 的列。
2.单字段表达式:
每行qq加 1 后展示。
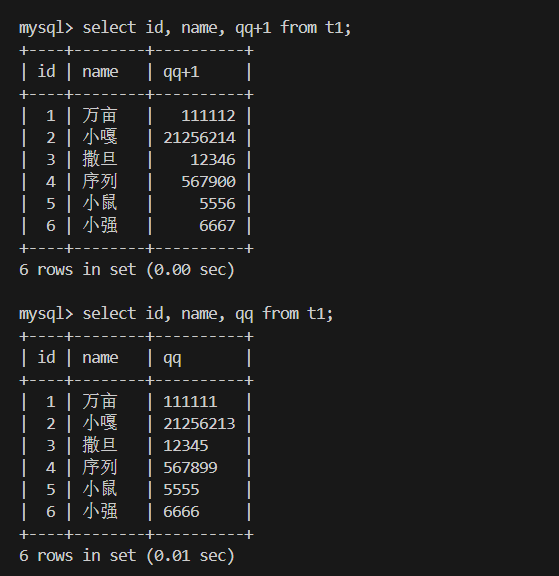
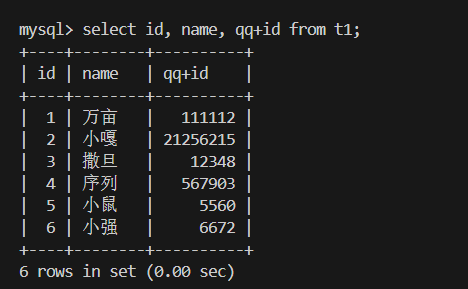
3.多字段表达式(计算总分):
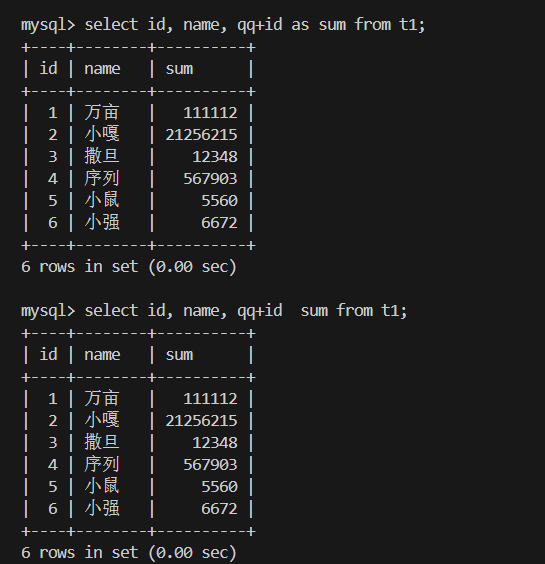
4.为查询结果指定别名
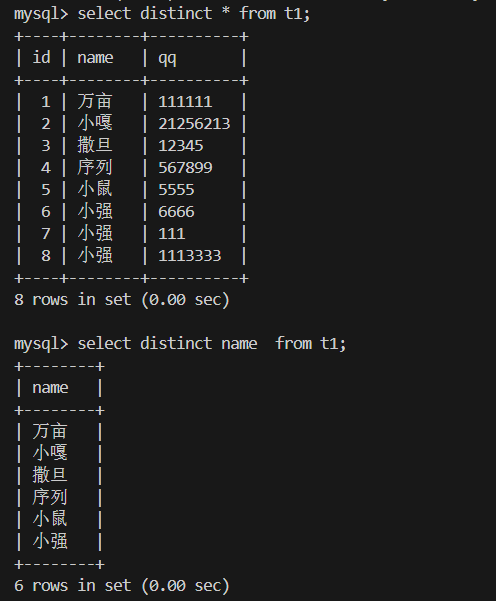
5.查询结果去重 select distinct 字段 from
去除查询结果中的重复值;
可用于单列或多列组合去重:
条件筛选where
用于限定查询结果,只返回满足指定条件的记录。
返回满足条件的行
一、比较运算符
| 运算符 | 含义 | 示例 |
|---|---|---|
> / < | 大于 / 小于 | where score > 60 |
>= / <= | 大于等于 / 小于等于 | where score <= 90 |
= | 等于(不推荐用于 null) | where name = '张三' |
<=> | 安全等于(支持 null 比较) | where a <=> null |
!= / <> | 不等于 | where name != '张三' |
between a and b | 范围闭区间 [a, b] | where score between 80 and 90 |
in (...) | 是否在某几个值中 | where name in ('张三', '李四') |
is null | 是否为空 | where qq is null |
is not null | 是否非空 | where qq is not null |
like | 模糊匹配 %任意字符 _一个字符 | where name like '张%' |
二、逻辑运算符
| 运算符 | 含义 | 示例 |
|---|---|---|
and | 所有条件都成立,结果为 true | where math > 70 and english > 70 |
or | 任一条件成立,结果为 true | where name = '张三' or name = '李四' |
not | 对结果取反 | where not (english > 60) |
查询操作练习
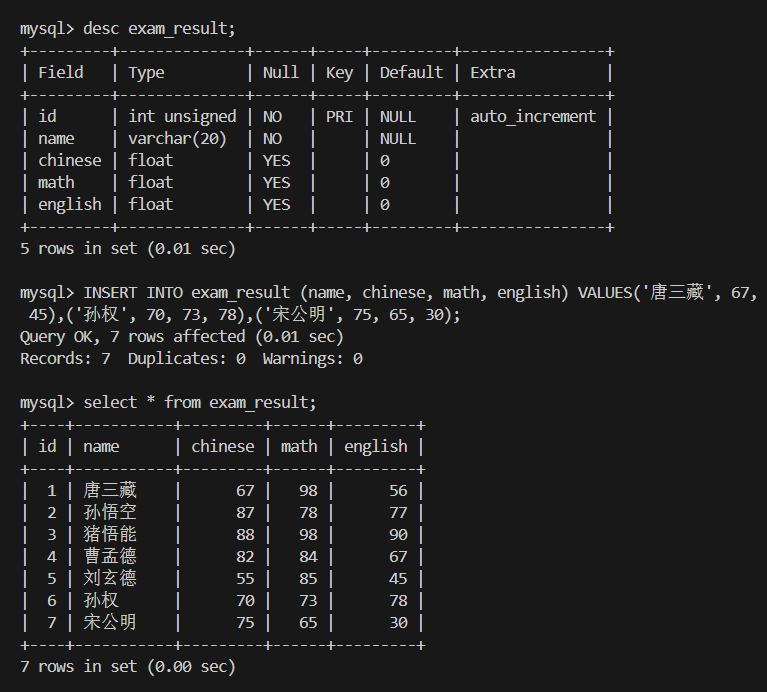
1.英语不及格的同学
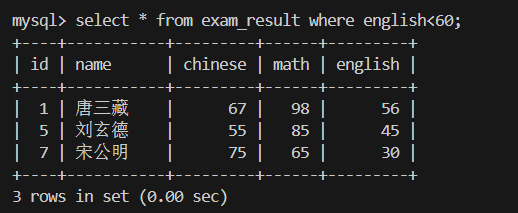
2.语文成绩在 80~90 分之间的同学
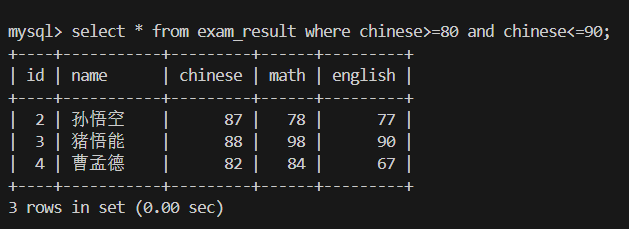
3.数学成绩为 58、59、98 或 99 的同学
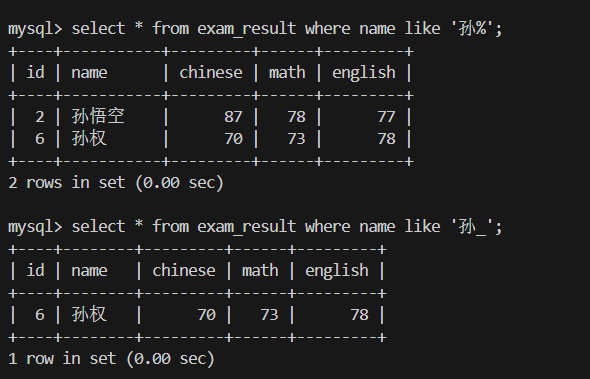
4.姓“孙”的同学
条件 %:name LIKE '孙%' → 任意“孙某某”
条件 _:name LIKE '孙_' → 精确“孙某”两个字的姓名
5.语文成绩 > 英语成绩的同学
where chinese>english;
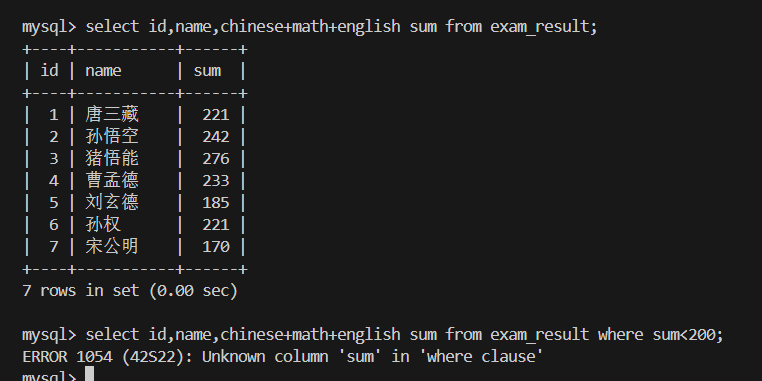
6.总分 < 200 的同学
为什么where用别名查询不行呢?
因为select语句的执行顺序是1.form确定数据来源 2.where 筛选条件 3.select计数表达式 生成结果。
在2.where执行时,select中的别名(如 sum)还没被定义出来,自然不能在 where中使用!
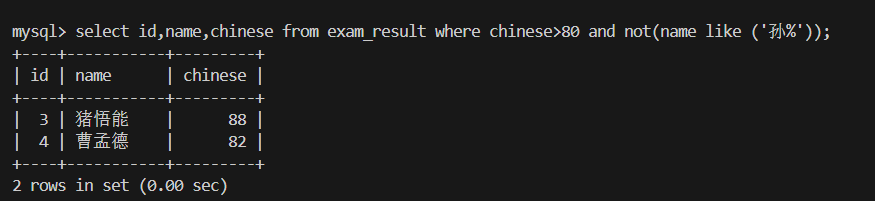
7.语文成绩 > 80 并且不姓孙的同学
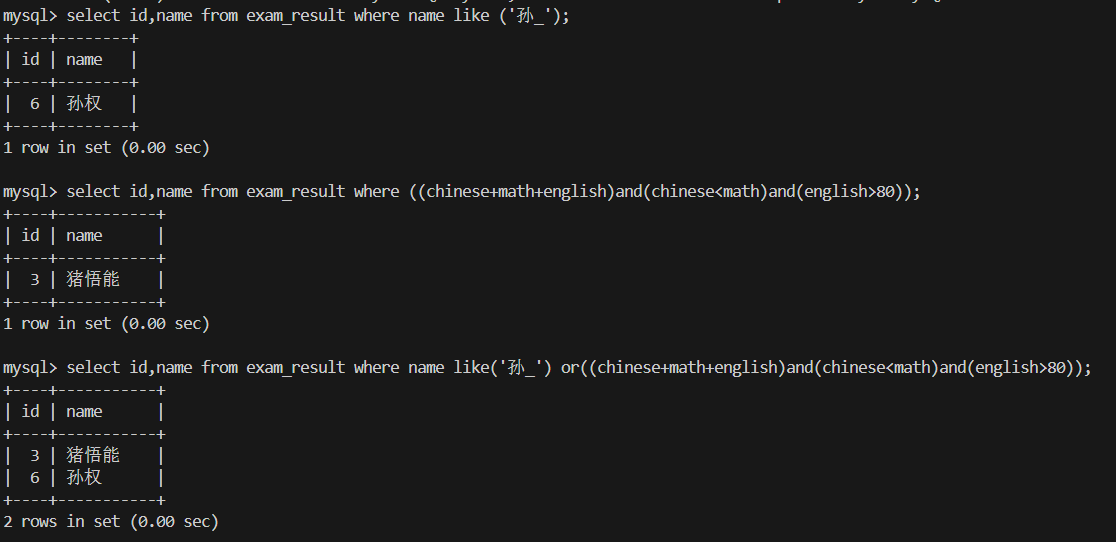
8.孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80

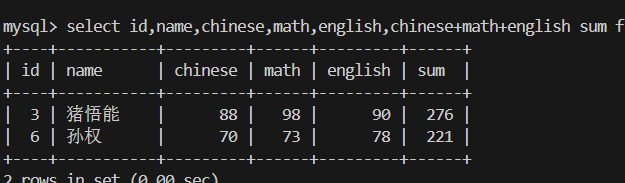
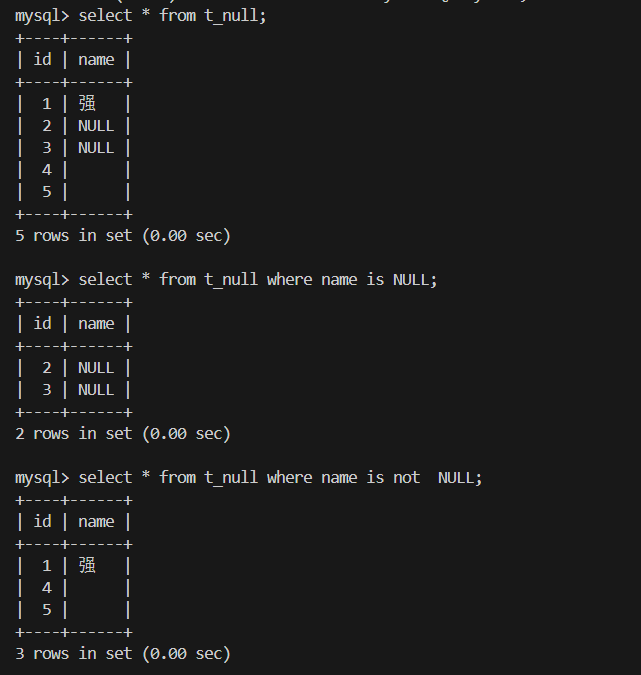
9.NULL 的查询
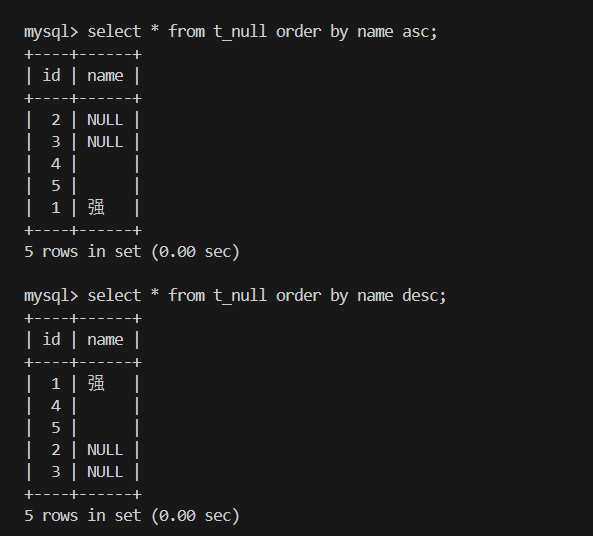
结果排序 order by 字段 asc|desc
关键词 含义 默认 asd 升序(从小到大) ✅ 是默认排序 desc 降序(从大到小) ❌ 需手动指定 多列排序 先按前列,再按次列(类似 Excel 多重排序) 支持
排序练习
1.同学及数学成绩,按数学成绩升序显示
2.NULL被视为最小值
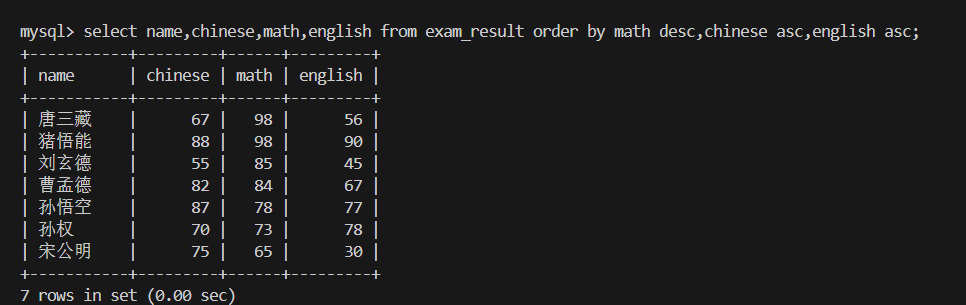
3.查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
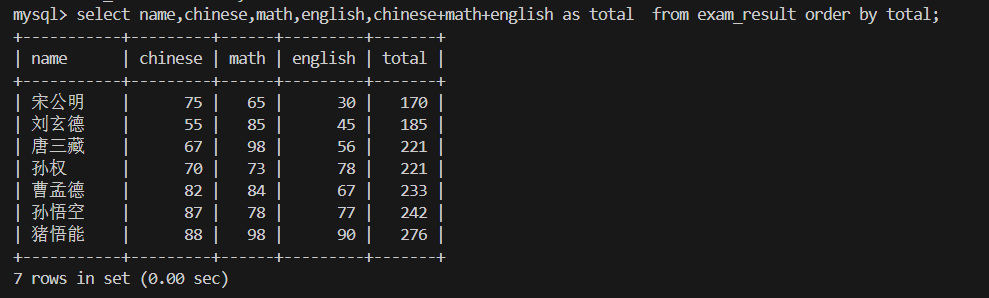
4.查询同学及总分,由高到低
为什么这里 order by 别名 就能用别名排序了呢?
因为我们可以说先筛选出符合条件的行再进行排序的 ,也就是order by是select执行完以后排序的,total别名已经存在了。
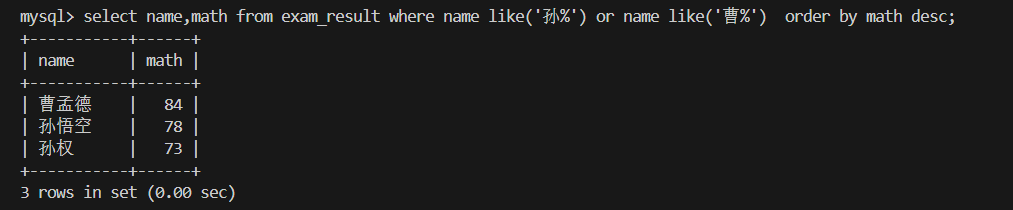
5.查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
筛选分页结果 limit
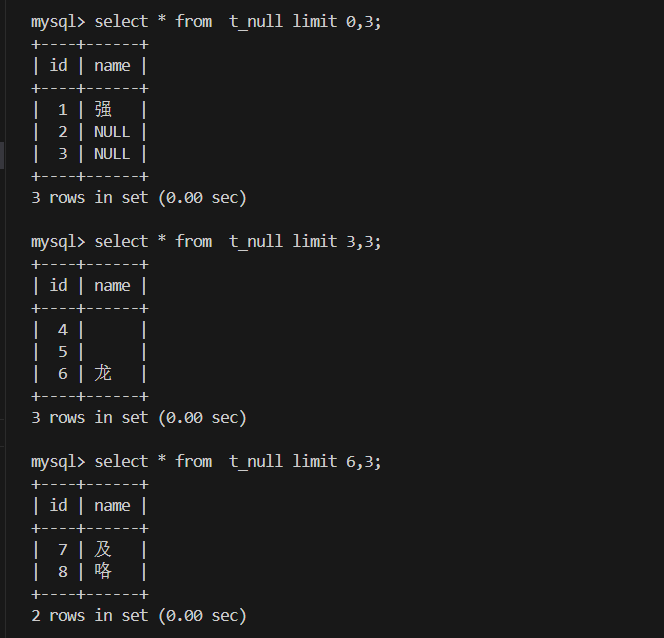
写法 含义 示例 limit n取前 n条记录limit 3limit s, n从下标为s的行开始取 n条limit 0,3limit n offset s同上 limit 3 offset 0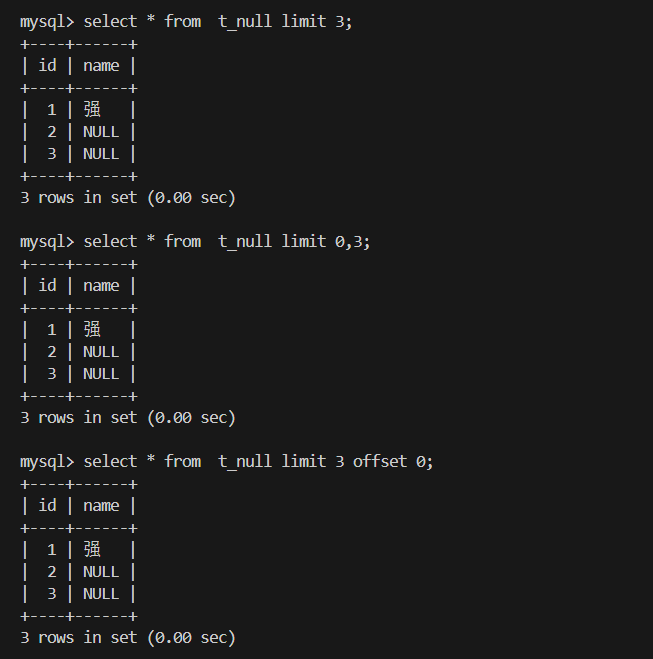
分页查询
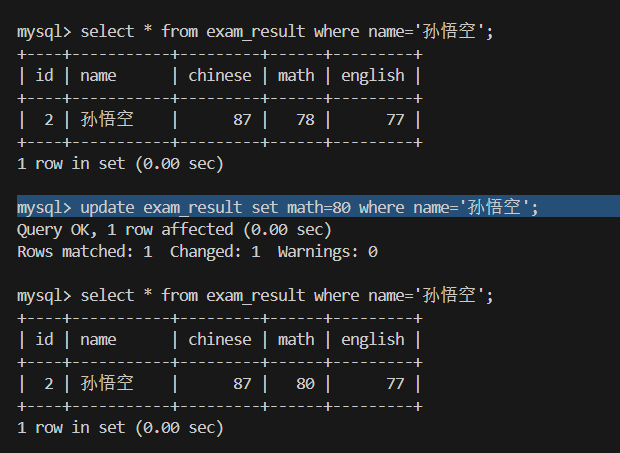
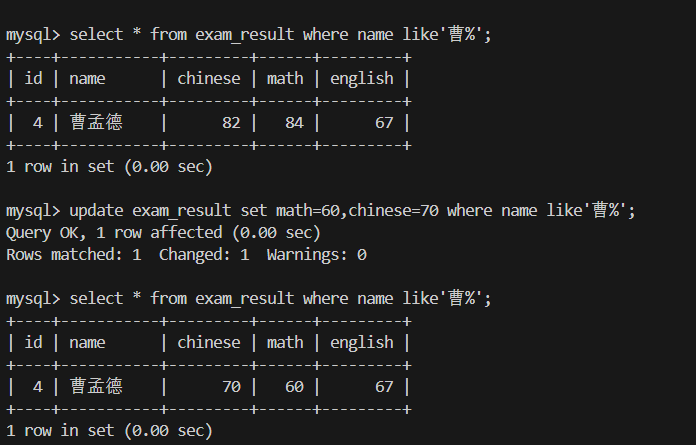
三.改 update set
update 表名 set 列1 = 新值1, 列2 = 新值2, ... where条件;
1 将孙悟空同学的数学成绩变更为 80 分
2.将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
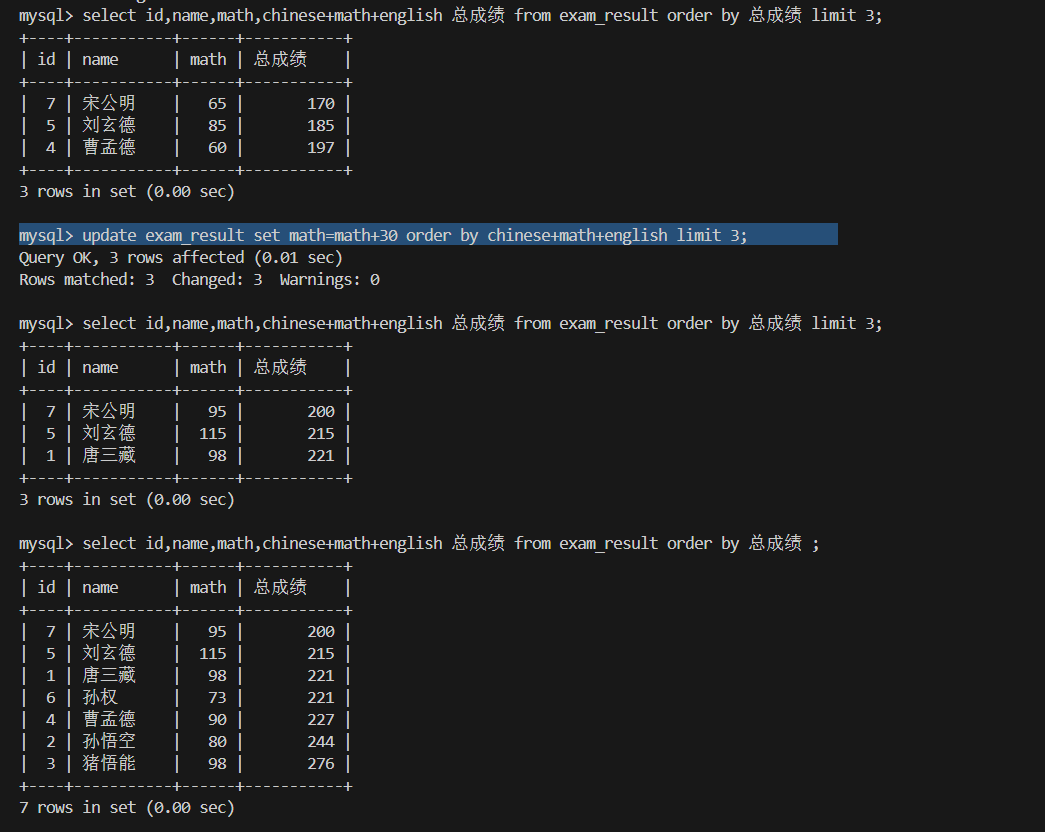
3.将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
1.总成绩升序 limit 3 取3名 order by 总成绩 limit 3;
2.update
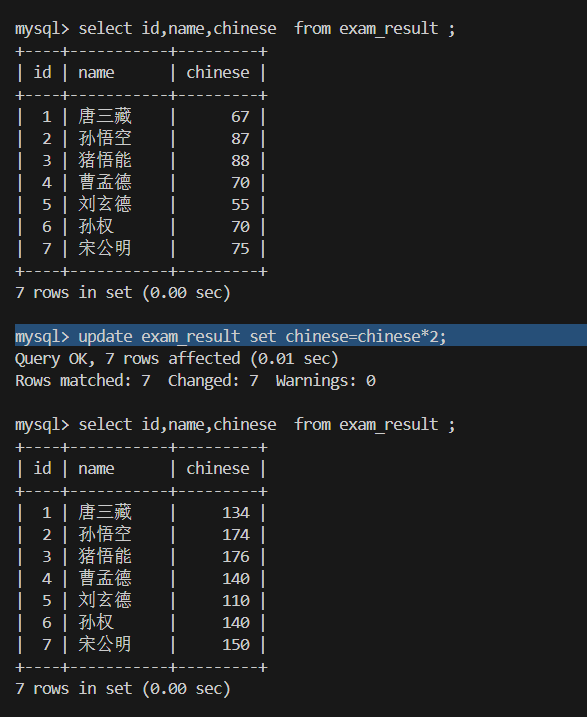
4.将所有同学的语文成绩更新为原来的 2 倍 慎用
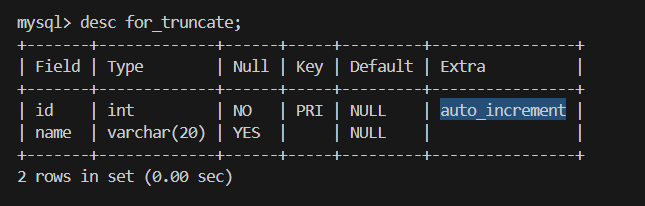
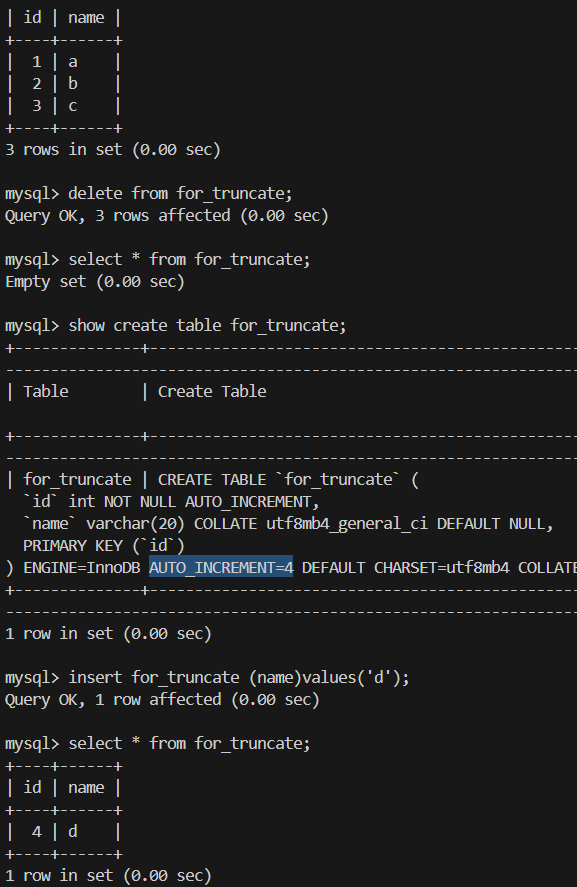
四.删 delete from / truncate
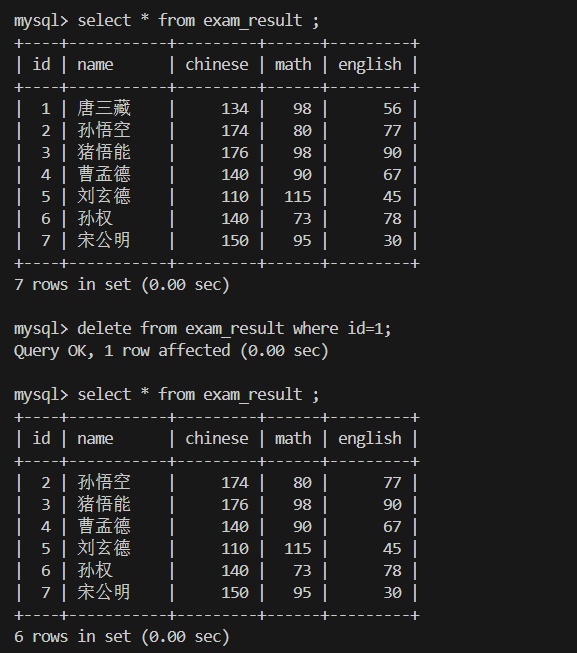
1.删除数据delete from
delete from 表 where ; 删除满足条件的数据
delete from 表;删除整张表的数据
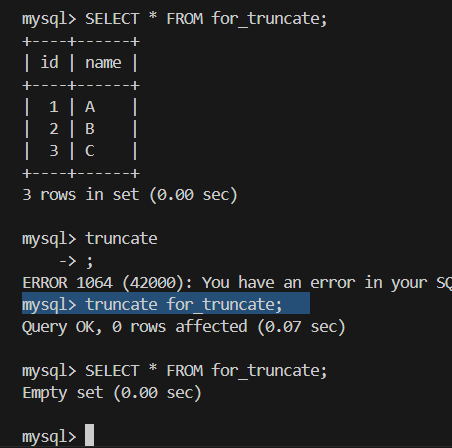
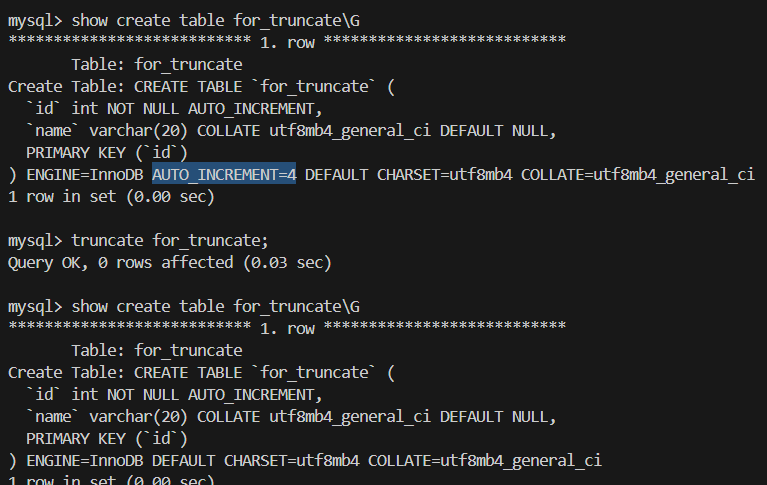
2.截断表 truncate 表
delete from 和 truncate 有什么区别?
1.delete from 表 where; 可以选择删除一部分的数据。但truncate只能删除整表的数据
2.delete属于事务操作 删除数据后可以撤回,truncate非事务操作 删除数据没有记录 不能撤回 执行更快。
3.delete 删除不会重置auto_increment表的自增计数器,而truncate会重置
delete
truncate
比较项 DELETETRUNCATE删除范围 可通过 WHERE删除部分数据只能整表删除,不支持 WHERE是否支持事务 ✅ 支持(InnoDB引擎下可 ROLLBACK回滚)❌ 不支持事务,操作不可撤回 是否可撤回(回滚) ✅ 可撤回 ❌ 不可撤回 操作类型 DML(数据操作语言) DDL(数据定义语言) 删除速度 较慢,逐行删除 很快,相当于重建表结构 影响自增计数器 ❌ 不重置 AUTO_INCREMENT✅ 会重置,自增从 1 开始 是否记录 binlog ✅ 会记录 ✅ 会记录(以 DROP 重建方式记录) 触发器(Trigger)支持 ✅ 支持触发器 ❌ 不触发触发器 安全性 相对安全,可控 风险较大,执行立即生效,无法恢复 delete:精确、慢、安全,适合删除部分数据;
truncate:快速、粗暴、不可回滚,适合清空整表。
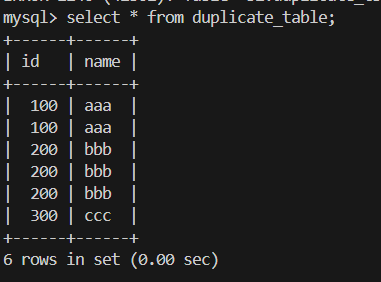
插入查询结果 (对表中数据去重)
这个表中有重复的数据 我们想对表中数据进行去重怎么操作?
1.创建一个结构相同的空表
2.插入 去重查询的结果到空表
3.最后让插入去重数据的表 改为原表名字
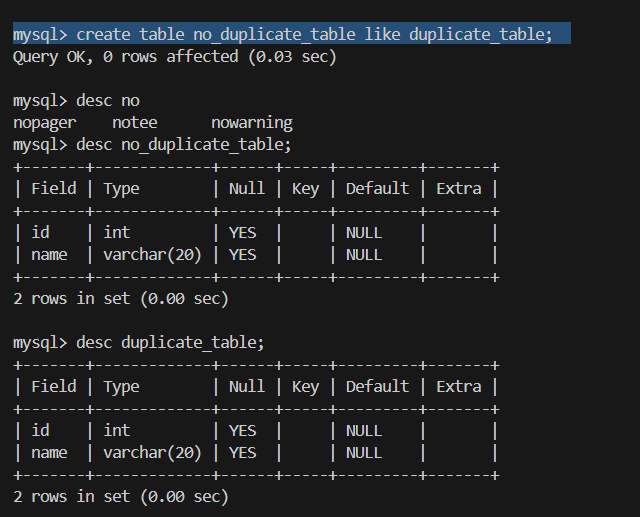
1.创建空白表 no_duplicate_table(结构相同)
create table no_duplicate_table like duplicate_table;
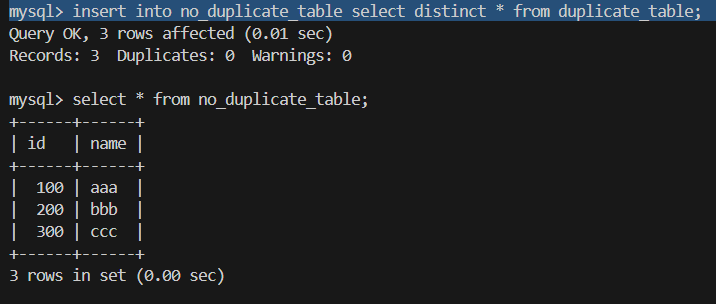
2.插入去重后的数据
insert into no_duplicate_table select distinct * from duplicate_table;
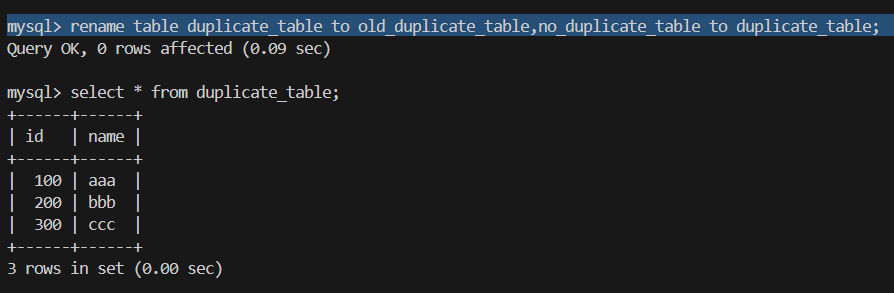
3.用rename table更改表名字
rename table duplicate_table to old_duplicate_table,no_duplicate_table to duplicate_table;
为什么通过rename table替换表名的方式进行操作?
原子操作 安全,中间处理的、转换的、过滤的所有数据,在 rename 这一刻,全部打包替换上去,一键生效,没有任何不一致或过渡状态。
聚合函数
| 函数 | 说明 | 示例 | 特点 |
|---|---|---|---|
count(*) | 返回记录总数(包括 null) | select count(*) from students; | 最常用,效率高 |
count(expr) | 返回非 null 值的数量 | select count(qq) from students; | null 不计入 |
count(distinct expr) | 返回去重后非 null 的数量 | select count(distinct math) from exam_result; | 可去重 |
sum(expr) | 求和(数值型) | select sum(math) from exam_result; | null 忽略,全部 null 则返回 null |
avg(expr) | 平均值(数值型) | select avg(math) from exam_result; | null 忽略 |
max(expr) | 最大值 | select max(english) from exam_result; | 支持数值/字符串 |
min(expr) | 最小值 | select min(math) from exam_result where math > 70; | 支持数值/字符串 |
聚合函数特点
| 特点 | 说明 |
|---|---|
只能出现在 select 或 having 子句中 | 不能直接在 where 里用 |
可配合 group by 分组使用 | 每组单独汇总,常见于报表分析 |
忽略 null(部分函数) | 如 sum(), avg(),会跳过 null 值 |
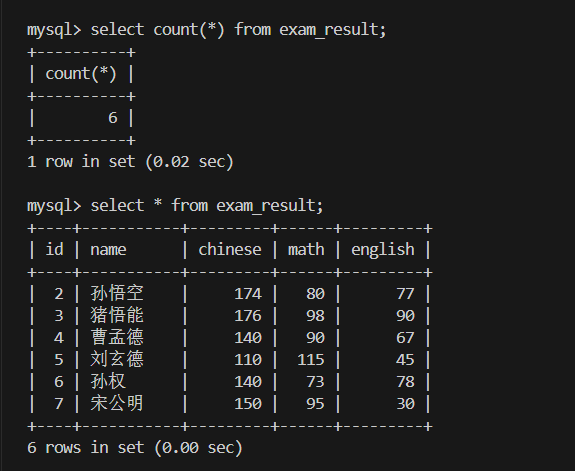
1. 统计班级共有多少同学
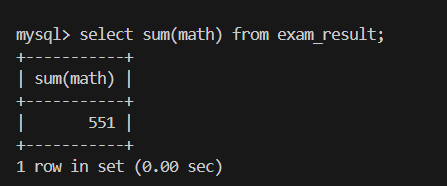
2.统计数学成绩总分
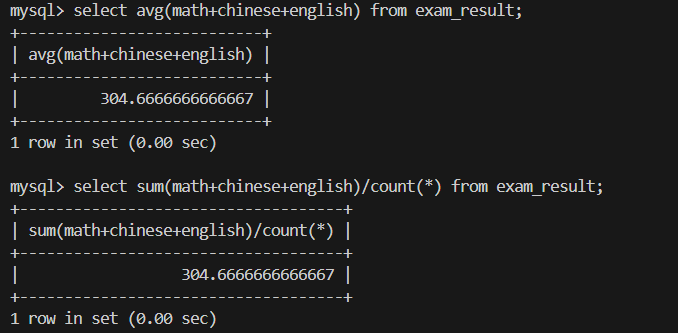
3.统计平均总分
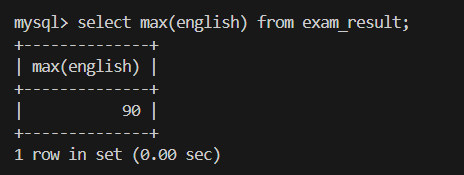
4.返回英语最高分
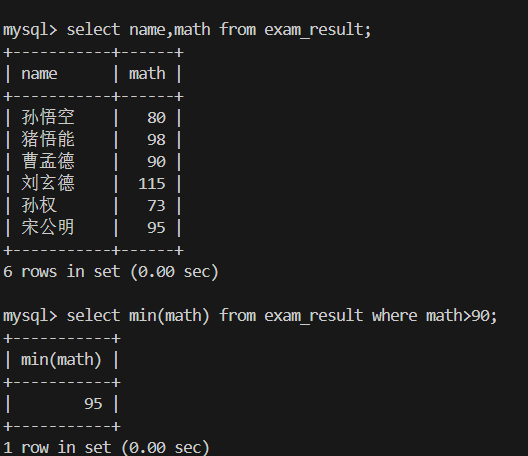
5.返回 > 90 分以上的数学最低分
分组统计group by
select 语句的执行流程:
where先筛选原数据 group by再进行分组(把一整个表分为多个)having 对分组后的结果再进行筛选 select选择要输出的内容 order by对输出内容进行排序 最后limit控制输出的数量
where: 对 原始数据进行筛选 不能用聚合函数
步骤 子句 作用说明 1️⃣ from读取数据表,形成数据源 2️⃣ where对原始数据进行行过滤(不能用聚合函数) 3️⃣ group by将数据分组 4️⃣ having对分组后的聚合结果进行组过滤 5️⃣ select选择需要输出的列、表达式、聚合函数 6️⃣ order by对最终结果进行排序 7️⃣ limit限制输出记录条数(分页常用)
having:对 分组聚合的结果进行筛选 可以用聚合函数
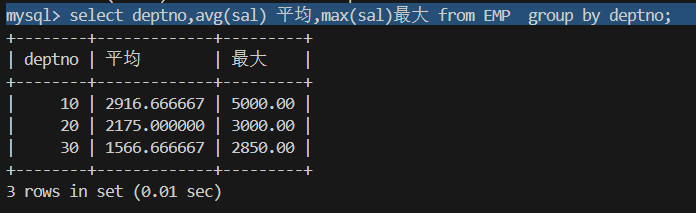
1.显示每个部门的平均工资和最高工资
avg()平均 max()最高 group by 部门
select deptno,avg(sal) 平均,max(sal)最大 from EMP group by deptno;
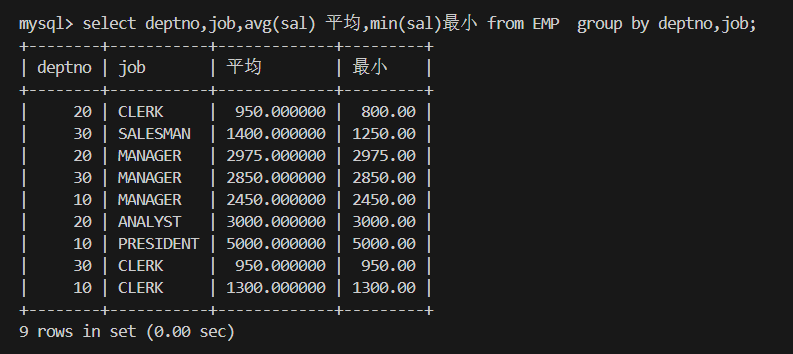
2.显示每个部门的每种岗位的平均工资和最低工资
group by 部门,岗位;可以理解为先以部门进行分组,再以岗位进行分组。
select 里字段,只有两种能出现:
select deptno,job,avg(sal) 平均,min(sal)最小 from EMP group by deptno,job;
一个是聚合函数,一个是 group by 里的字段。
因为SQL 是基于分组后的“每一组”来生成结果行的,必须是一组中共同的东西
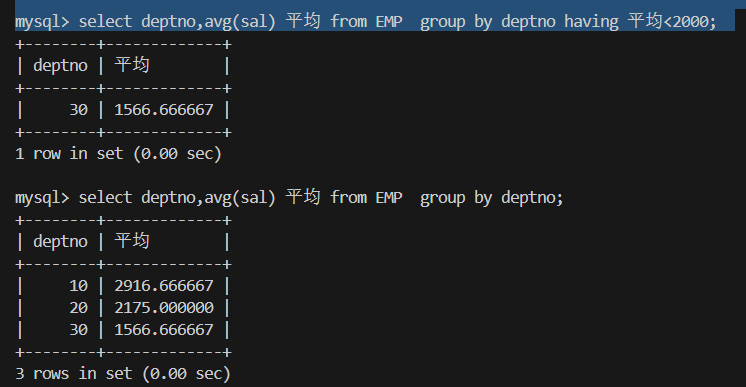
3.显示平均工资低于2000的部门和它的平均工资
1.group by以部门分组 avg算出平均薪资 2.having再对分完组的结果进行筛选
select deptno,avg(sal) 平均 from EMP group by deptno having 平均<2000;
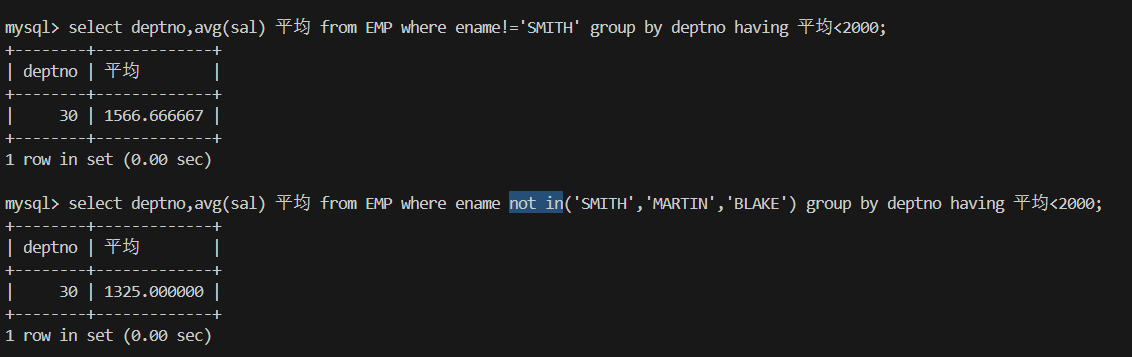
4.除去SMITH员工 显示平均工资低于2000的部门和它的平均工资
not in(...)不在里面