关键词:数据库高可用,HA架构,数据库集群,负载均衡,故障转移,SQL Server Always On,MySQL InnoDB Cluster,高可用性组,读写分离,灾难恢复
在当今瞬息万变的数字化时代,数据的价值日益凸显,数据库作为承载核心业务数据的基石,其可用性直接决定了业务的连续性与用户体验。一次意外的数据库停机,无论持续时间长短,都可能给企业带来巨大的经济损失和声誉损害。因此,设计和实现高可用的数据库架构,已成为IT基础设施建设中的重中之重。
本文将深入探讨数据库高可用(High Availability, HA)架构设计的核心理念,包括集群、负载均衡和故障转移机制,并结合Microsoft SQL Server的Always On可用性组和MySQL官方的InnoDB Cluster,提供具体的实践案例和优化建议。

1. 数据库高可用核心概念
要构建健壮的数据库高可用系统,首先需要理解几个核心概念:
- 高可用性(High Availability, HA):指系统在面对各种故障时,仍能保持正常运行的能力。衡量指标通常包括:
- RTO (Recovery Time Objective):恢复时间目标,即系统从故障发生到恢复服务所允许的最长时间。
- RPO (Recovery Point Objective):恢复点目标,即系统从故障中恢复后,数据丢失量可接受的最大值。
- 集群(Clustering):将多台独立的服务器连接起来,作为一个统一的计算资源池。在数据库HA中,集群通常意味着数据冗余和故障自动切换。
- 负载均衡(Load Balancing):将客户端的请求均匀地分发到集群中的多个节点上,以提高整体的吞吐量和响应速度,同时避免单个节点过载。
- 故障转移(Failover):当集群中的某个主节点发生故障时,系统能够自动或手动地将服务切换到备用节点上,从而保证服务的持续性。自动化故障转移是HA的关键。
2. 常见数据库高可用架构模式
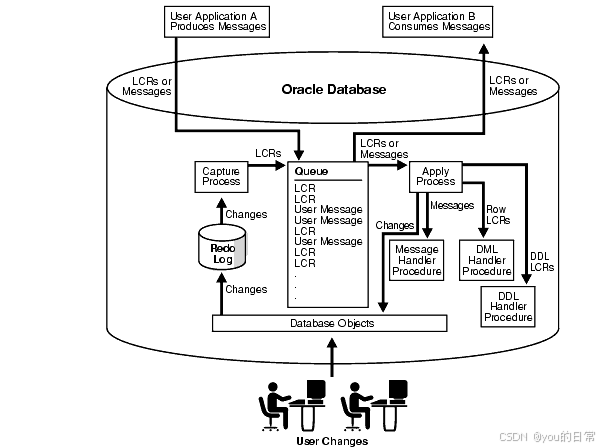
数据库HA架构模式多种多样,各有优缺点,适用于不同的业务场景:
- 主从复制/主备模式:一个主库(Master)负责所有写入和大部分读取,一个或多个从库(Slave/Replica)通过复制主库的日志来同步数据,只提供读服务或作为热备。
- 优点:架构简单,成本较低,可实现读写分离。
- 缺点:主库单点写,故障转移通常需手动或依赖第三方工具,存在数据延迟风险。
- 主从多活/双主模式:多个主库都能接受写操作,数据在它们之间相互复制。
- 优点:读写均可扩展,无单点写入。
- 缺点:数据冲突解决复杂,需要应用层支持,配置和维护难度大。
- 共享存储集群:多个数据库实例连接到同一个共享存储设备(如SAN)。当主实例故障时,备用实例可以直接接