note
文章目录
- note
- 一、新模型趋势
- 任意模态模型
- 推理模型
- 小巧但功能强大的模型
- 专家混合解码器
- 视觉-语言-行动模型 VLA
- 二、特殊能力
- 视觉语言模型中的目标检测、分割和计数
- 多模态安全模型
- 多模态RAG:检索器和重排器
- 三、多模态代理
- 四、视频语言模型
- 五、视觉语言模型的新对齐技术
- 六、新基准测试
- MMT-Bench
- MMMU-Pro
- Reference
一、新模型趋势
任意模态模型
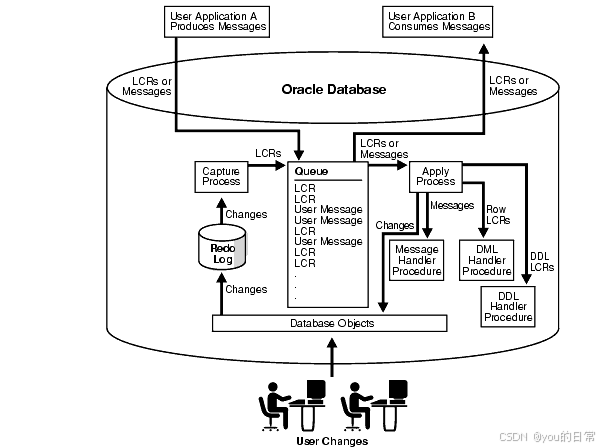
任意模态模型能够接受任何模态的输入,并输出任何模态(图像、文本、音频)。它们通过模态对齐来实现这一点。典型的全模态模型Qwen 2.5 Omni:
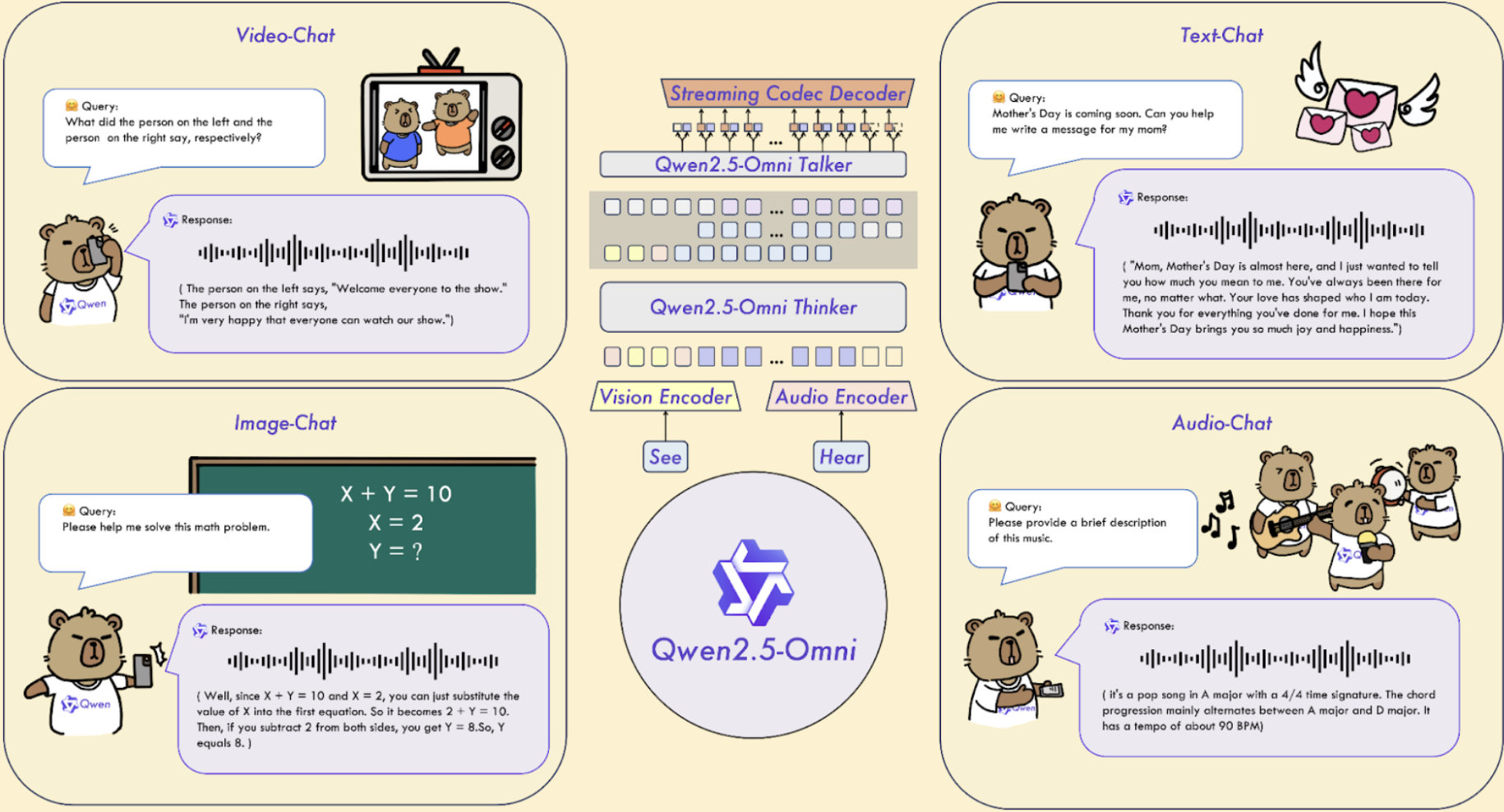
Qwen2.5-Omni采用了一种新颖的“思考者-说话者”架构,其中“思考者”负责文本生成,而“说话者”则以流式方式产生自然语音响应。MiniCPM-o 2.6是一个拥有80亿参数的多模态模型,能够理解并生成视觉、语音和语言模态的内容。DeepSeek AI推出的Janus-Pro-7B是一个统一的多模态模型,在跨模态的理解和生成方面表现出色。它采用了分离的视觉编码架构,将理解过程与生成过程分开。
推理模型
直到2025年5月,唯一一个开源的多模态推理模型是Qwen的QVQ-72B-preview。
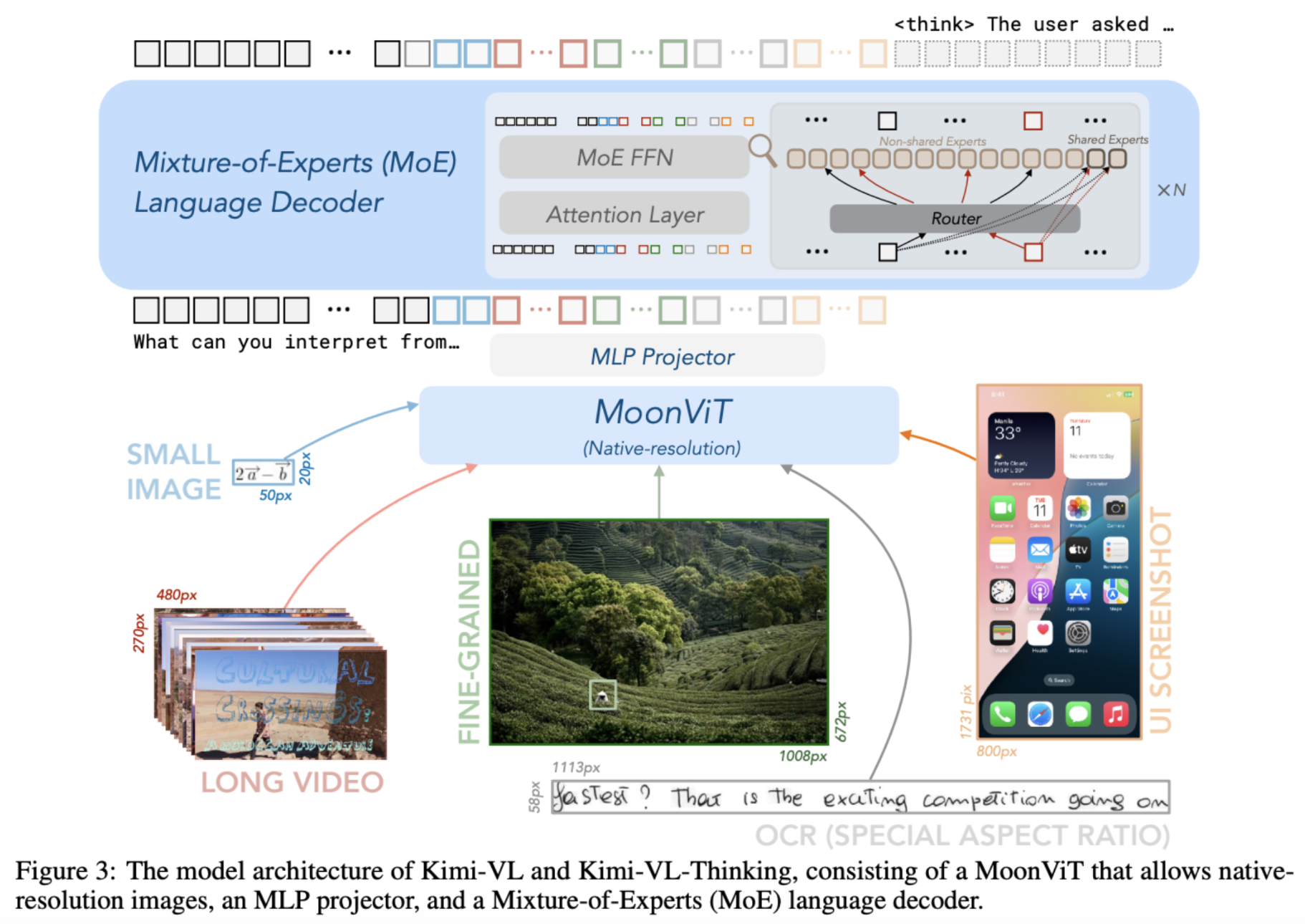
Moonshot AI团队的Kimi-VL-A3B-Thinking。它由MoonViT(SigLIP-so-400M)作为图像编码器,以及一个拥有160亿总参数、仅28亿活跃参数的专家混合(MoE)解码器组成。该模型是Kimi-VL基础视觉语言模型的长链推理微调版本,并进一步通过强化学习进行了对齐。作者还发布了一个指令微调版本,名为Kimi-VL-A3B-Instruct。该模型可以接受长视频、PDF文件、屏幕截图等输入,并且还具备代理能力。
小巧但功能强大的模型
通过增加模型参数数量和高质量合成数据来提升智能水平,但模型越大收益边际效益越小,所以可以通过知识蒸馏等缩小模型规模。小型视觉语言模型,通常指的是参数少于20亿、可以在消费级GPU上运行的模型。
(1)SmolVLM是一个小型视觉语言模型家族的典型代表。它没有通过缩小大型模型来实现,而是直接尝试将模型参数数量控制在极低水平,如2.56亿、5亿和22亿。例如,SmolVLM2试图在这些规模下解决视频理解问题,并发现5亿参数是一个很好的折中方案。在Hugging Face,我们开发了一款名为HuggingSnap的iPhone应用程序,以证明这些规模的模型可以在消费级设备上实现视频理解。
(2)谷歌DeepMind的gemma3-1b-it。它特别令人兴奋,因为它是目前最小的多模态模型之一,拥有32k的上下文窗口,并支持140多种语言。该模型属于Gemma 3模型家族,其中最大的模型在Chatbot Arena上排名第一。随后,该大型模型被蒸馏为一个10亿参数的变体。
(3)虽然不是最小的模型,但Qwen2.5-VL-3B-Instruct也值得关注。该模型可以执行多种任务,包括定位(目标检测和指向)、文档理解以及代理任务,上下文长度可达32k个标记。
# 可以通过MLX和Llama.cpp集成来使用小型模型。对于MLX,假设您已经安装了它,您可以通过以下一行代码开始使用SmolVLM-500M-Instruct:
python3 -m mlx_vlm.generate --model HuggingfaceTB/SmolVLM-500M-Instruct --max-tokens 400 --temp 0.0 --image https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vlm_example.jpg --prompt "What is in this image?"# 可以通过以下一行代码,使用GGUF格式的gemma-3-4b-it模型,通过CLI和Llama.cpp开始使用:
llama-mtmd-cli -hf ggml-org/gemma-3-4b-it-GGUF# 可以通过以下命令将同一模型作为服务运行:
llama-server -hf ggml-org/gemma-3-4b-it-GGUF
专家混合解码器
专家混合(MoEs)模型通过动态选择并激活与给定输入数据片段最相关的子模型(称为“专家”)来处理数据。
与参数密集的同类模型相比,MoEs在推理时速度更快,因为它们只激活网络中的一小部分。它们在训练时也能快速收敛。然而,MoEs需要更高的内存成本,因为整个模型都存储在GPU上,即使只使用其中的一小部分。
在广泛采用的Transformer架构中,MoE层通常是通过替换每个Transformer块中的标准前馈网络(FFN)层来集成的。密集网络在推理时会使用整个模型,而同样大小的MoE网络则会选择性地激活一些专家。这有助于更好地利用计算资源并加快推理速度。
配备专家混合解码器的视觉语言模型似乎具有增强的性能。例如,Kimi-VL目前是最先进的开源推理模型,它采用了专家混合解码器。专家混合在MoE-LLaVA的效率提升和幻觉减少以及DeepSeek-VL2的广泛多模态能力方面也显示出令人鼓舞的结果。最新版本的Llama(Llama 4)是一个具有视觉能力的MoE。专家混合作为解码器是一个有前景的研究领域,我们预计这类模型的数量将会增加。
视觉-语言-行动模型 VLA
VLAs接受图像和文本指令作为输入,并返回指示机器人直接采取行动的文本。VLAs通过添加行动和状态标记扩展了视觉语言模型,以与物理环境进行交互和控制。这些额外的标记代表了系统的内部状态(它如何感知环境)、行动(根据命令采取的行动)以及与时间相关的信息(例如任务中步骤的顺序)。这些标记被附加到视觉语言输入中,以生成行动或策略。
VLAs通常是在基础VLM之上进行微调的。有些人进一步扩展了这一定义,将VLAs定义为任何与现实或数字世界进行视觉交互的模型。在这个定义下,VLAs可以用于UI导航或代理工作流程。但许多人认为这些应用属于VLM领域。
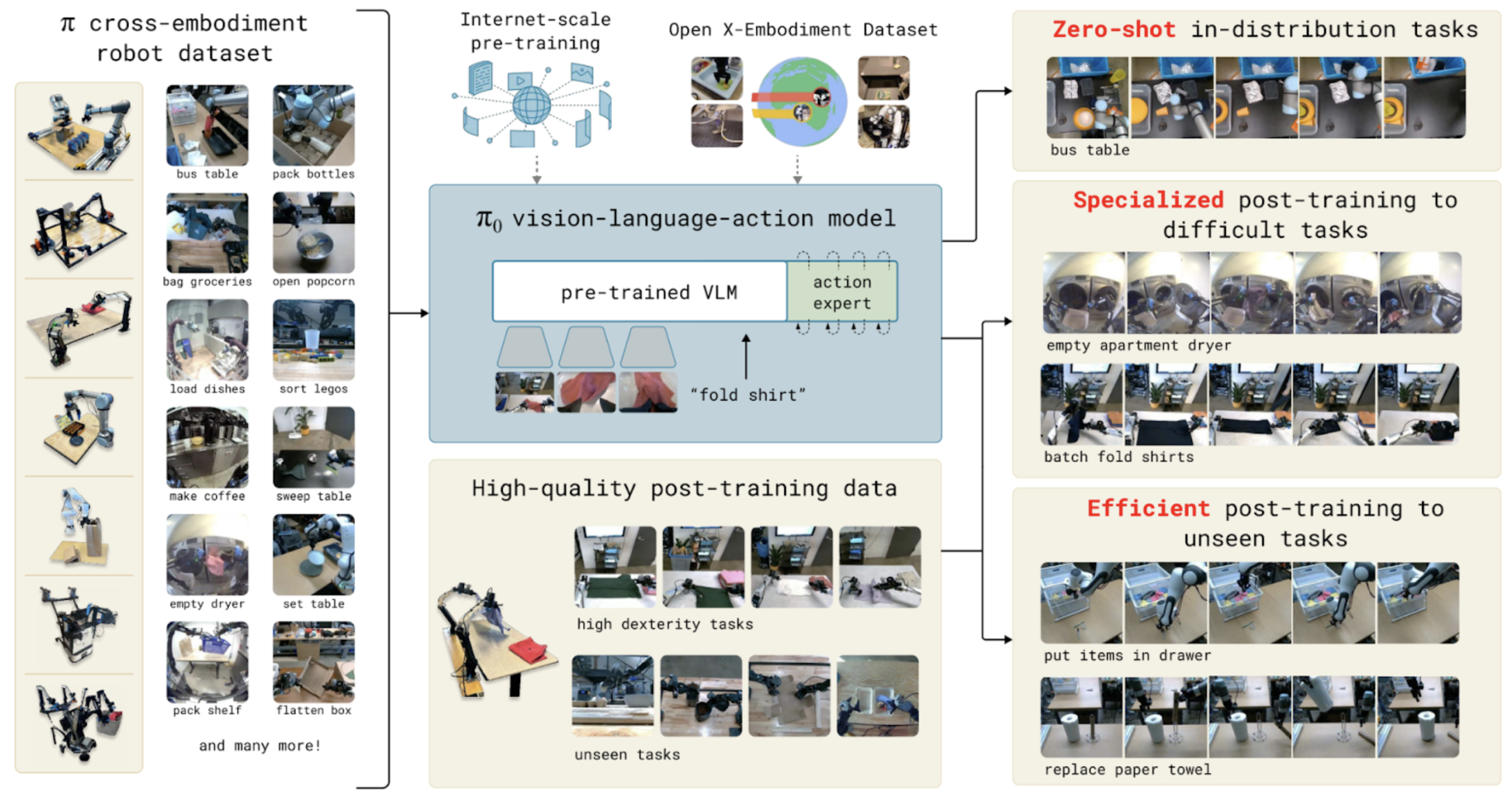
π0和π0-FAST是Physical Intelligence推出的首批机器人基础模型,已移植到Hugging Face的LeRobot库中。这些模型在7个机器人平台上针对68项独特任务进行了训练。它们在复杂的真实世界活动中表现出强大的零样本和微调性能,例如洗衣折叠、餐桌清理、杂货装袋、盒子组装和物体检索。
GR00T N1是NVIDIA的开源VLA基础模型,用于通用人形机器人。它能够理解图像和语言,并将其转化为行动,例如移动手臂或遵循指令,这得益于一个将智能推理与实时运动控制相结合的系统。GR00T N1也基于LeRobot数据集格式构建,这是一种简化机器人演示共享和训练的开放标准。
二、特殊能力
视觉语言模型中的目标检测、分割和计数
VLMs能够在传统计算机视觉任务上实现泛化。如今,模型可以接受图像和各种提示(如开放式文本),并输出带有定位标记的结构化文本(用于检测、分割等)。
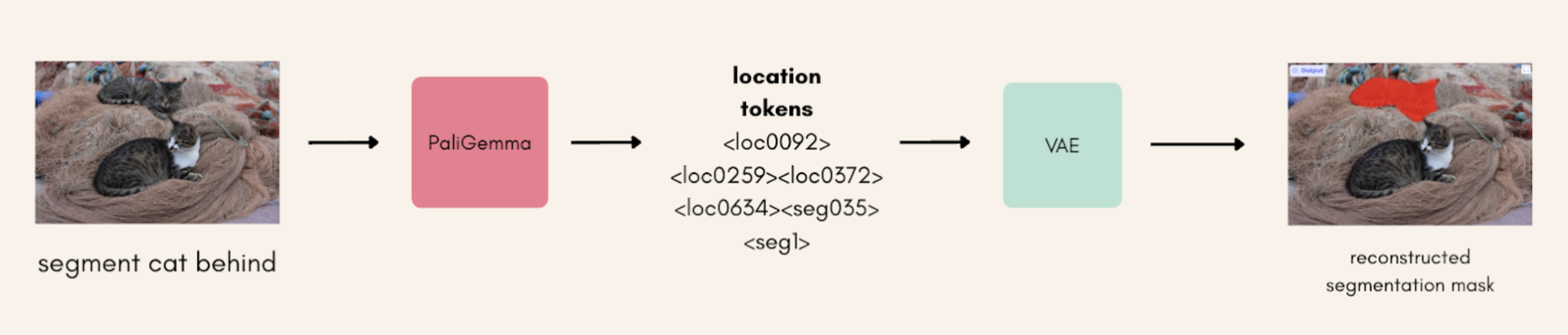
去年,PaliGemma是首个尝试解决这些任务的模型。该模型接受图像和文本输入,其中文本是对感兴趣对象的描述,以及一个任务前缀。文本提示看起来像“segment striped cat”(分割条纹猫)或“detect bird on the roof”(检测屋顶上的鸟)。
对于检测任务,模型以标记的形式输出边界框坐标。而对于分割任务,模型则输出检测标记和分割标记。这些分割标记并不是所有分割像素的坐标,而是由变分自编码器解码的码本索引,该自编码器被训练用来将这些标记解码为有效的分割掩码(如下图所示)。
在PaliGemma之后,许多模型被引入用于执行定位任务。去年年底,PaliGemma的一个升级版本PaliGemma 2出现了,它具有相同的能力,但性能更好。另一个后来出现的模型是Allen AI的Molmo,它可以使用点来指向实例并计数对象实例。
Qwen2.5-VL也能够检测、指向和计数对象,这包括将UI元素作为对象进行处理!

多模态安全模型
2025年初,谷歌推出了首个开源多模态安全模型ShieldGemma 2。它基于文本安全模型ShieldGemma构建。该模型接受图像和内容策略作为输入,并返回图像是否符合给定策略的安全性判断。策略是指图像不适当的标准。ShieldGemma 2还可以用于过滤图像生成模型的输出。
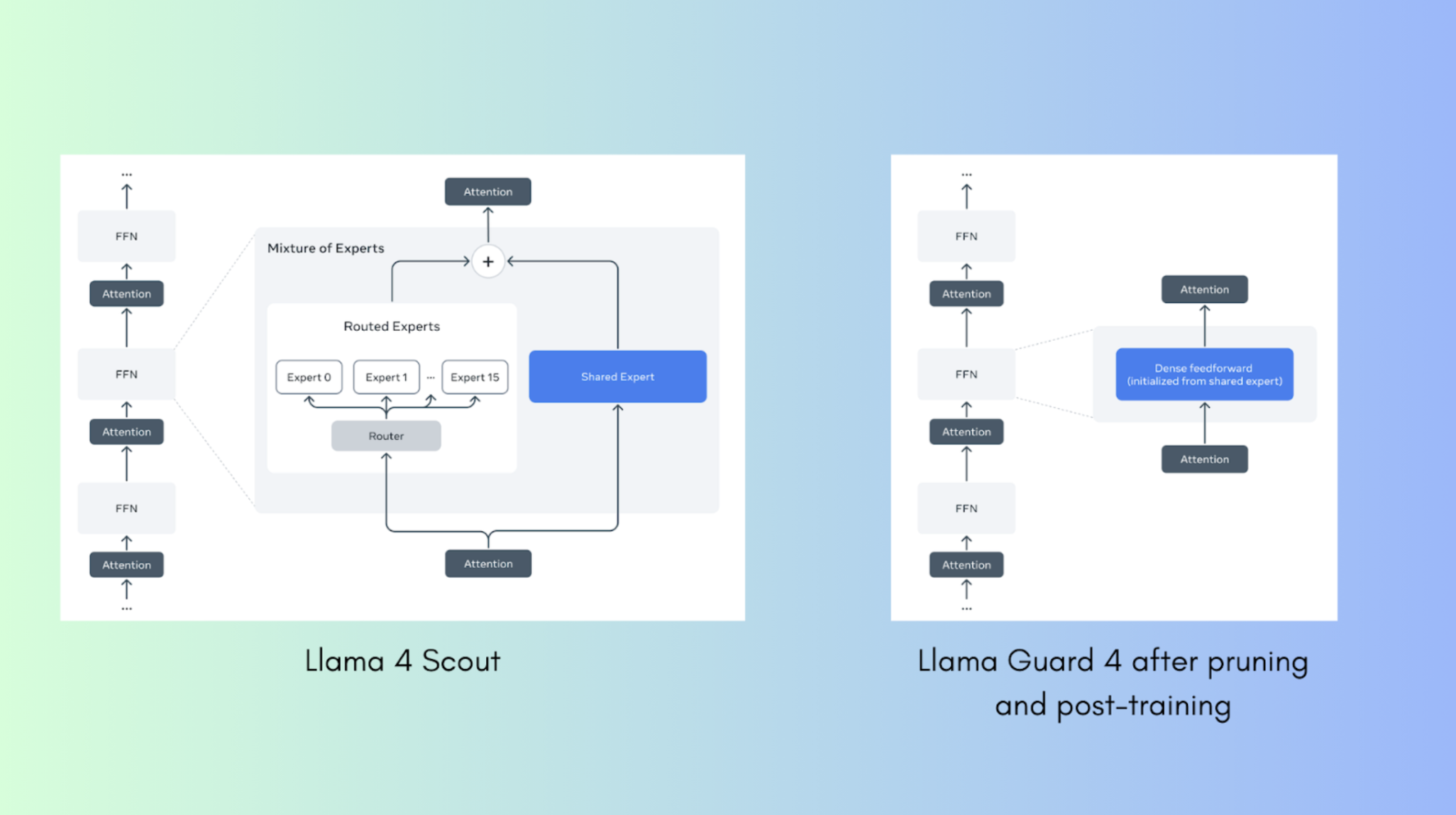
Meta的Llama Guard 4是一个密集的多模态和多语言安全模型。它是从Llama 4 Scout(一个多模态专家混合模型)密集修剪而来,并进行了安全微调。该模型可用于纯文本和多模态推理。该模型还可以接受视觉语言模型的输出、完整的对话内容,并在将它们发送给用户之前对其进行过滤。
多模态RAG:检索器和重排器
检索增强生成(RAG)在多模态领域是如何发展的。对于复杂的文档(通常以PDF格式呈现),RAG的处理过程通常分为三个步骤:
- 将文档完全解析为文本将
- 纯文本和查询传递给检索器和重排器,以获取最相关的文档
- 将相关上下文和查询传递给LLM
传统的PDF解析器由多个元素组成,以保留文档中的结构和视觉元素,如布局、表格、图像、图表等,所有这些元素都被渲染成Markdown格式。但这种设置很难维护。
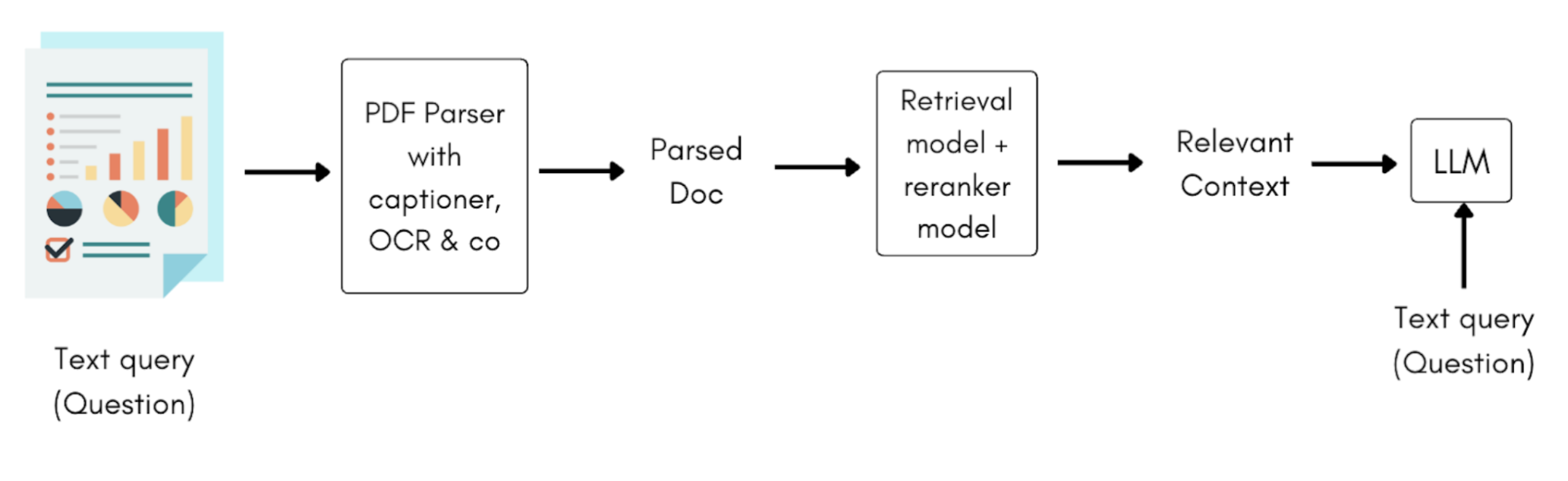
随着视觉语言模型的兴起,这个问题得到了解决:现在有了多模态检索器和重排器。多模态检索器接受一堆PDF文件和一个查询作为输入,并返回最相关的页面编号及其置信度分数。这些分数表示页面包含查询答案的可能性,或者查询与页面的相关性。这绕过了脆弱的解析步骤。然后将最相关的页面与查询一起输入视觉语言模型,VLM生成答案。
主要有两种多模态检索器架构:
- 文档截图嵌入(DSE,MCDSE)
- ColBERT类模型(ColPali、ColQwen2、ColSmolVLM)
DSE模型由一个文本编码器和一个图像编码器组成,每个查询返回一个向量。返回的分数是嵌入向量点积的softmax。它们为每个段落返回一个向量。
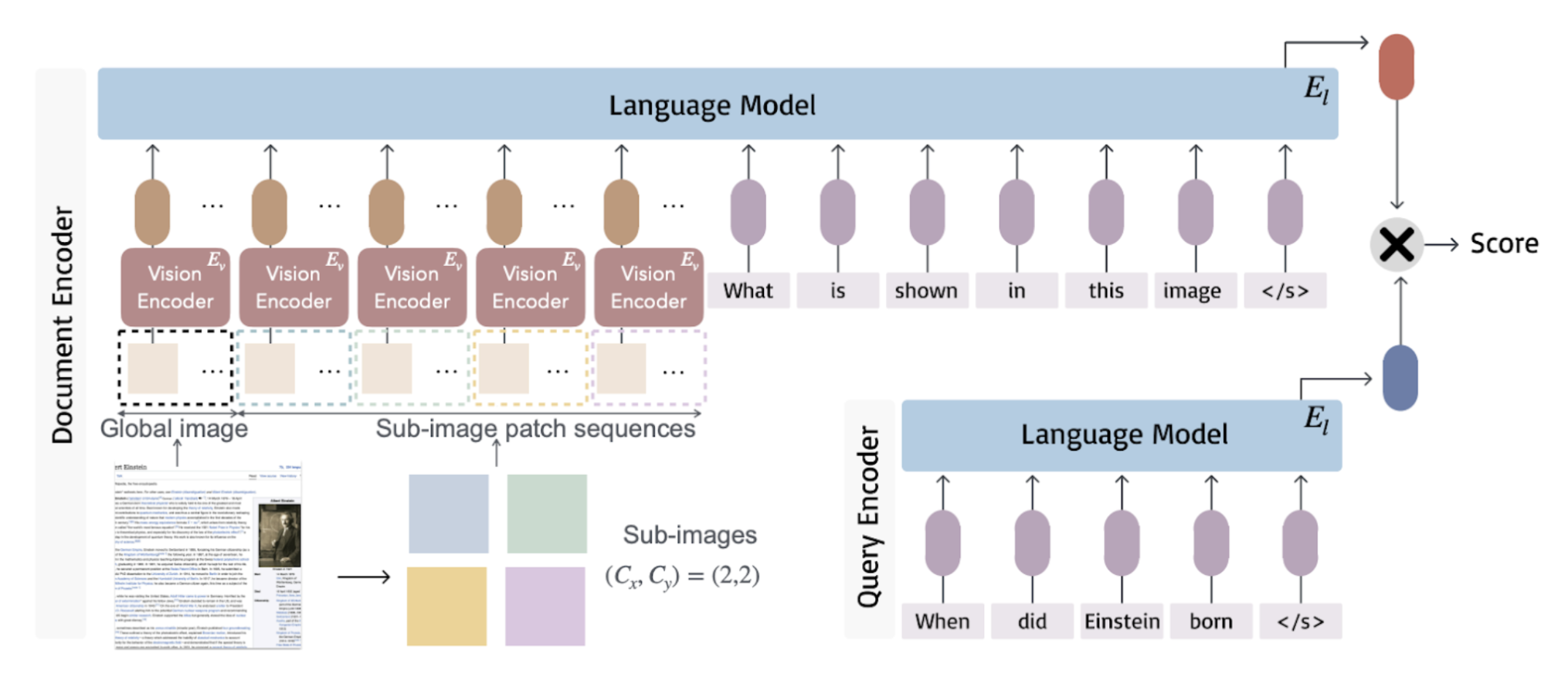
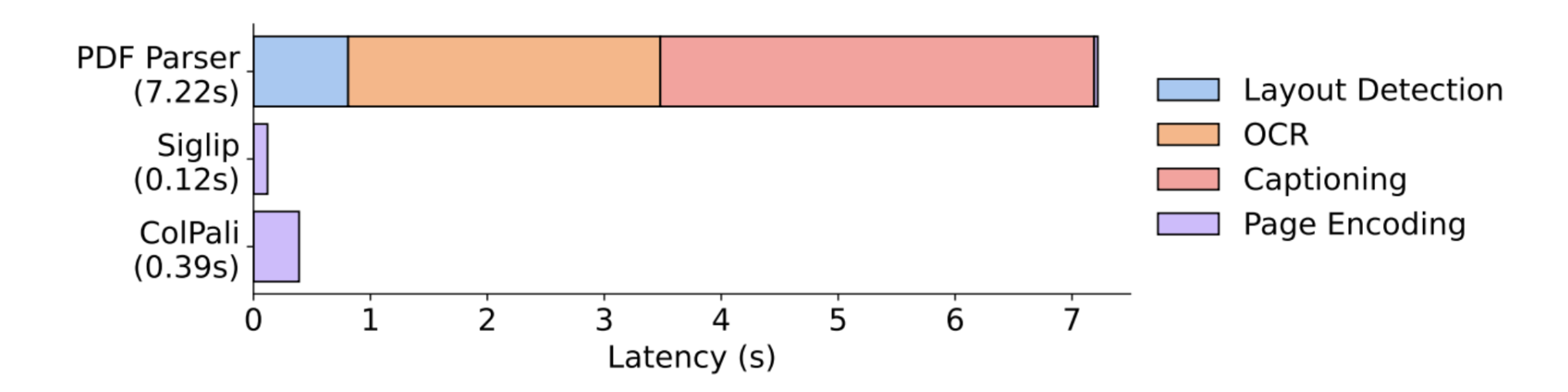
ColBERT类模型,如ColPali,也是双编码器模型,但有一个特点:ColPali使用视觉语言模型作为图像编码器,使用大型语言模型作为文本编码器。这些模型本质上不是编码器,但它们输出嵌入向量,然后传递给“MaxSim”。与DSE不同,这些模型的输出是每个标记的一个向量,而不是一个单一向量。在MaxSim中,计算每个文本标记嵌入向量与每个图像块嵌入向量之间的相似度,这种方法能够更好地捕捉细微差别。正因为如此,ColBERT类模型的计算成本更高,但性能更好。以下是ColPali的索引延迟情况。由于它只是一个单一模型,因此也更容易维护。
该任务最受欢迎的基准测试是ViDoRe,它包含英文和法文的文档,文档类型从财务报告、科学图表到行政文件不等。ViDoRe中的每个示例都包含文档图像、查询和可能的答案。文档与查询的匹配有助于对比预训练,因此ViDoRe训练集被用于训练新模型。
三、多模态代理
许多视觉语言模型发布,它们能够理解和操作用户界面(UI)。其中最新的是ByteDance的UI-TARS-1.5,它在浏览器、计算机和手机操作方面取得了出色的结果。它还可以进行推理游戏,并在开放世界游戏中运行。今年的另一个重要发布是MAGMA-8B,它是一个用于UI导航和与现实世界进行物理交互的基础模型。此外,Qwen2.5-VL(尤其是其32B变体,因为它在代理任务上进行了进一步训练)和Kimi-VL推理模型在GUI代理任务上表现出色。
2025年初,我们推出了smolagents,这是一个新的轻量级代理库,实现了ReAct框架。不久之后,我们为该库增加了视觉语言支持。这种集成发生在两个用例中:
- 在运行开始时一次性提供图像。这对于带有工具使用的文档AI很有用。
- 动态检索图像。这对于需要VLM代理进行GUI控制的情况很有用,因为代理需要反复截取屏幕截图。
该库为用户提供构建自己的图像理解代理工作流程的构建块。我们提供了不同的脚本和单行CLI命令,以便用户轻松开始。
(1)对于第一种情况,假设我们希望一个代理描述文档(这并不太具有代理性,但对于最小化用例来说还不错)。您可以像下面这样初始化CodeAgent(一个可以自己编写代码的代理):
agent = CodeAgent(tools=[], model=model) # 不需要工具
agent.run("Describe these documents:", images=[document_1, document_2, document_3])
(2)对于第二种情况,我们需要一个代理来获取屏幕截图,我们可以定义一个回调函数,在每个ActionStep结束时执行。对于您自己的需要动态获取图像的用例,您可以根据需要修改回调函数。为了简单起见,这里我们不详细定义它。您可以选择阅读博客文章和博客文章末尾的脚本。现在,让我们看看如何初始化带有回调和浏览器控制步骤的代理。
def save_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:"""截取屏幕截图并写入观察结果。
"""png_bytes = driver.get_screenshot_as_png()memory_step.observations_images = [image.copy()] # 将图像持久化到memory_stepurl_info = f"当前网址:{driver.current_url}"memory_step.observations = (url_info if memory_step.observations is None else memory_step.observations + "\n" + url_info)returnagent = CodeAgent(tools=[go_back, close_popups, search_item_ctrl_f], # 传递导航工具model=model,additional_authorized_imports=["helium"],step_callbacks=[save_screenshot], # 传递回调
)
# CLI命令:
webagent "前往 xyz.com/men,进入销售部分,点击您看到的第一件服装。获取产品详情和价格,并返回它们。注意,我正在从法国购物"可以通过运行以下CLI命令来尝试整个示例。它启动一个代理,该代理通过视觉语言模型控制网络浏览器,以完成网络自动化任务(请替换为您想要导航的网站)。
smolagents提供了不同类型的模型,例如本地Transformer模型、使用推理提供商托管的开源模型,或闭源模型提供商的端点。我们鼓励使用开源模型,因为许多代理工作流程目前需要推理,这从拥有大量参数的模型中受益。截至2025年4月,Qwen 2.5 VL是一个适合代理工作流程的候选模型,因为该模型在代理任务上进行了进一步训练。
四、视频语言模型
大多数视觉语言模型都能够处理视频,因为视频可以表示为一系列帧。然而,视频理解是棘手的,因为帧之间存在时间关系,而且帧的数量通常很多,因此需要使用不同的技术来选择一组具有代表性的视频帧。
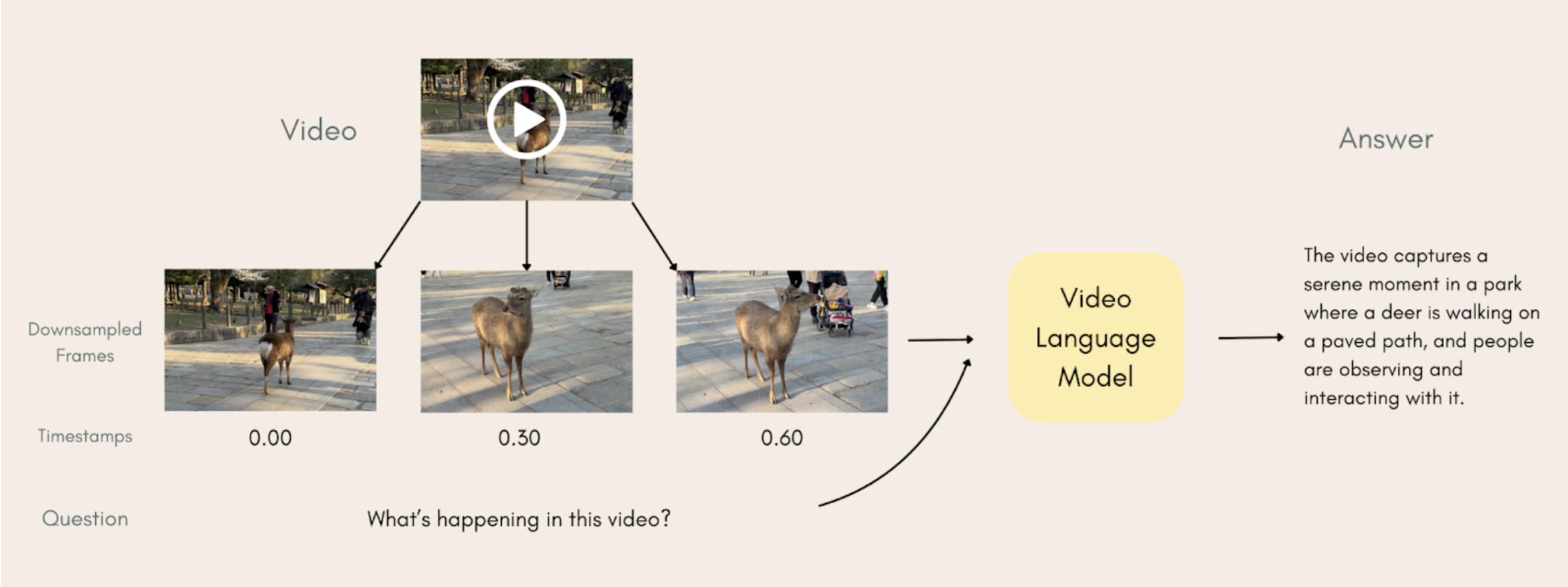
一个很好的例子是Meta的LongVU模型。它通过将视频帧传递给DINOv2来降低采样率,以选择最相似的帧并将其去除,然后模型进一步通过根据文本查询选择最相关的帧来细化帧,其中文本和帧都被投影到同一个空间,并计算相似度。
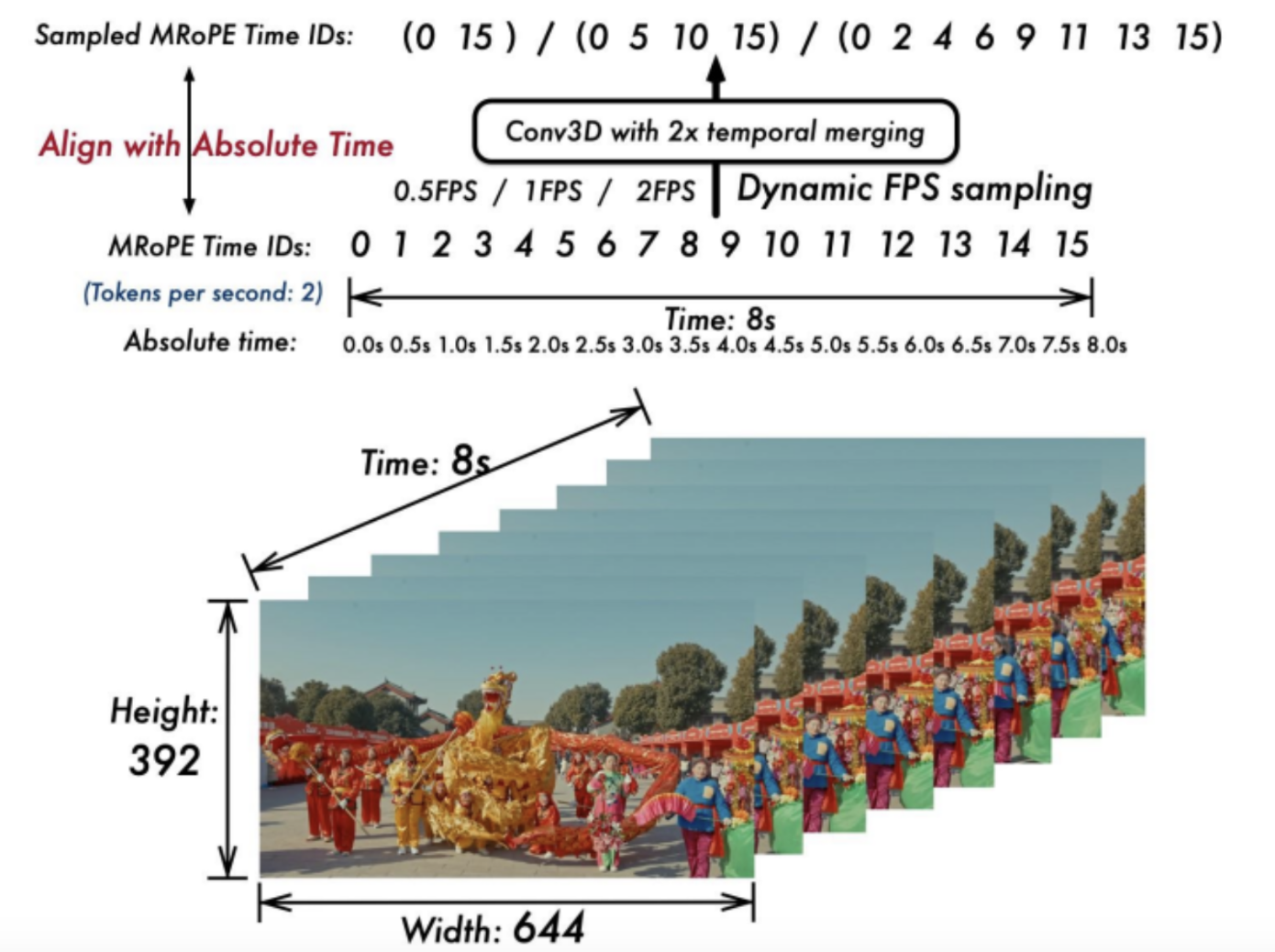
Qwen2.5VL能够处理长上下文,并适应动态帧率,因为该模型是用不同帧率的视频进行训练的。通过扩展的多模态RoPE,它能够理解帧的绝对时间位置,并且可以处理不同的速率,同时仍然能够理解现实生活中事件的速度。
另一个模型是Gemma 3,它可以接受在文本提示中交错的时间戳和视频帧,例如“Frame 00.00: …”,并且在视频理解任务中表现非常出色。
五、视觉语言模型的新对齐技术
偏好优化是一种替代的语言模型微调方法,也可以扩展到视觉语言模型。这种方法不依赖于固定的标签,而是专注于根据偏好比较和排名候选响应。trl库提供了对直接偏好优化(DPO)的支持,包括对VLMs的支持。
以下是VLM微调的DPO偏好数据集的结构示例。每个条目由一个图像+问题对以及两个对应的答案组成:一个被选中的答案和一个被拒绝的答案。VLM被微调以生成与首选(被选中)答案一致的响应。
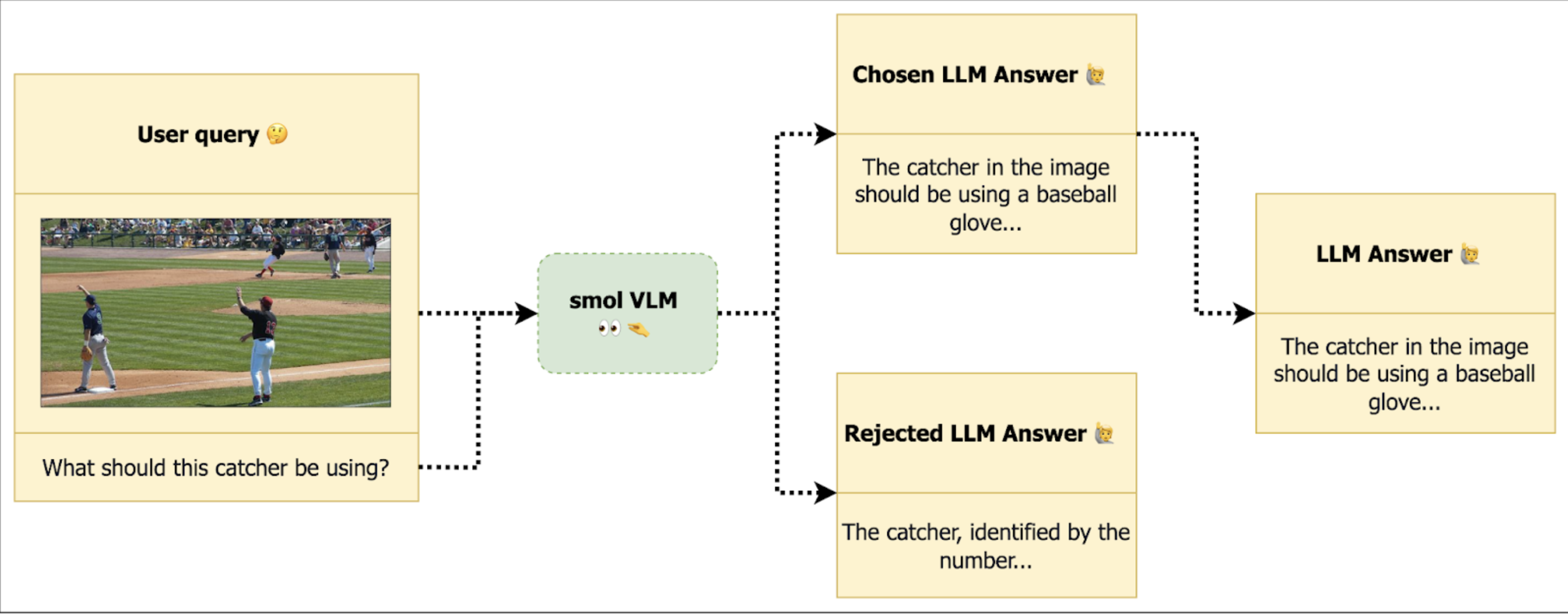
RLAIF-V是一个用于此过程的示例数据集,它包含超过83000个按照上述结构标注的样本。每个条目包括一个图像列表(通常是一个图像)、一个提示、一个被选中的答案和一个被拒绝的答案,正如DPOTrainer所期望的那样。这里有一个已经按照相应格式格式化的RLAIF-V格式数据集。以下是单个样本的示例:
{'images': [<PIL.JpegImagePlugin.JpegImageFile image mode=L size=980x812 at 0x154505570>],'prompt': [ { "content": [ { "text": null, "type": "image" }, { "text": "What should this catcher be using?", "type": "text" } ], "role": "user" } ],'rejected': [ { "content": [ { "text": "The catcher, identified by the number...", "type": "text" } ], "role": "assistant" } ],'chosen': [ { "content": [ { "text": "The catcher in the image should be using a baseball glove...", "type": "text" } ], "role": "assistant" } ]}
准备好数据集后,您可以使用trl库中的_DPOConfig_和_DPOTrainer_类来配置并启动微调过程。以下是使用_DPOConfig_的示例配置:
from trl import DPOConfigtraining_args = DPOConfig(output_dir="smolvlm-instruct-trl-dpo-rlaif-v",bf16=True,gradient_checkpointing=True,per_device_train_batch_size=1,per_device_eval_batch_size=1,gradient_accumulation_steps=32,num_train_epochs=5,dataset_num_proc=8, # tokenization will use 8 processesdataloader_num_workers=8, # data loading will use 8 workerslogging_steps=10,report_to="tensorboard",push_to_hub=True,save_strategy="steps",save_steps=10,save_total_limit=1,eval_steps=10, # Steps interval for evaluationeval_strategy="steps",
)
要使用_DPOTrainer_训练您的模型,您可以选择提供一个参考模型来计算奖励差异。如果您使用的是参数高效微调(PEFT),则可以通过设置_ref_model=None_来省略参考模型。
from trl import DPOTrainertrainer = DPOTrainer(model=model,ref_model=None,args=training_args,train_dataset=train_dataset,eval_dataset=test_dataset,peft_config=peft_config,tokenizer=processor
)trainer.train()
六、新基准测试
在之前,MMMU和MMBench作为评估视觉语言模型的两个新兴基准测试,但随着模型发展,现在这些benchmark已经趋于饱和。
MMT-Bench
MMT-Bench旨在评估VLMs在需要专业知识、精确视觉识别、定位、推理和规划的广泛多模态任务上的表现。该基准测试包括来自各种多模态场景的31325个多选视觉问题,涵盖图像、文本、视频和点云等多种模态。它包含32个不同的元任务和162个子任务,涵盖了OCR、视觉识别或视觉-语言检索等多种任务。
MMMU-Pro
MMMU-Pro是原始MMMU基准测试的改进版本。它还评估先进AI模型在多种模态上的真实理解能力。它比MMMU更复杂,例如,它有一个仅视觉输入的设置,并且候选选项的数量从4个增加到了10个。该基准测试还纳入了真实世界模拟,其仅视觉问题来源于在模拟显示屏内截取的屏幕截图或照片,具有不同的背景、字体样式和大小,以模拟真实世界条件。
Reference
[1] Vision Language Models (Better, Faster, Stronger:https://huggingface.co/blog/vlms-2025 20250512发布