一、什么是支持向量机(SVM)
1. 基本概念
1.1 二分类问题的本质
在机器学习中,分类问题是最常见的任务之一。最简单的情况就是二分类:比如一封邮件是“垃圾邮件”还是“正常邮件”?一个病人是“患病”还是“健康”?一个图像是“猫”还是“狗”?
SVM专门擅长处理这种“把样本分成两类”的问题。它的核心目标是:找到一个最优的边界,把两类样本尽可能清晰地分开。
1.2 最大间隔划分思想
SVM的最大特点,就是它不像KNN那样靠近邻,也不像逻辑回归那样直接拟合概率,而是追求“最大间隔”:
它试图在两个类别之间,找到一条“超平面”(一个直线、一个面、或者一个高维空间中的超平面),这个超平面与两类样本中最近的点之间的距离最大,这个“最近的点”就是“支持向量”。
为什么要最大化这个间隔?
简单来说:更大的间隔 = 更强的容错率 = 更好的泛化能力。
1.3 支持向量的意义
在SVM中,真正决定这个“最佳分隔线”的,并不是所有数据点,而是最接近这条线的一小部分点,我们称之为“支持向量”。
这些支持向量对模型训练有决定性作用,一旦它们的位置改变,分界线就可能会改变。而其他点的影响几乎为零。
2. 超平面与间隔
-
超平面:在二维中是直线,在三维中是平面,在更高维中是“超平面”。SVM的目标就是找到这样一个能分开两类样本的超平面。
-
间隔:超平面到支持向量的最小距离。SVM通过最大化这个间隔来优化模型。
这是一种几何直觉非常强的优化方式,适合处理线性可分的数据。
2.1 硬间隔
**硬间隔(Hard Margin)**是支持向量机(SVM)中的一个概念,指的是在分类过程中,模型要求训练数据必须被完全正确分类,且每个样本点都不能落在分类间隔区域内。
直白解释:
硬间隔就是:“我要找到一条完美的分界线,一个样本都不能错分,也不能碰到分界线附近的空白区域。”
2.1.1 硬间隔的定义
设训练数据集为:
{ ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) } , x i ∈ R d , y i ∈ { − 1 , + 1 } \{(x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\},\quad x_i \in \mathbb{R}^d,\quad y_i \in \{-1, +1\} {(x1,y1),(x2,y2),…,(xn,yn)},xi∈Rd,yi∈{−1,+1}
SVM 要求找到一个线性可分的超平面:
w T x + b = 0 w^T x + b = 0 wTx+b=0
使得所有训练样本被完全正确分类,并且分类间隔最大。
约束条件(分类正确 + 间隔大):
对所有样本 i = 1 , 2 , . . . , n i = 1, 2, ..., n i=1,2,...,n,要求:
y i ( w T x i + b ) ≥ 1 y_i (w^T x_i + b) \geq 1 yi(wTxi+b)≥1
这表示:
-
如果 y i = + 1 y_i = +1 yi=+1,则 w T x i + b ≥ 1 w^T x_i + b \geq 1 wTxi+b≥1
-
如果 y i = − 1 y_i = -1 yi=−1,则 w T x i + b ≤ − 1 w^T x_i + b \leq -1 wTxi+b≤−1
也就是说:每个样本都要落在自己那一侧的“边界外”,而且不能在间隔区域里、也不能分类错误。
优化目标(最大间隔 = 最小化 ∥ w ∥ 2 \|w\|^2 ∥w∥2):
支持向量机通过最大化间隔来实现最优划分。因为几何间隔是 2 ∥ w ∥ \frac{2}{\|w\|} ∥w∥2,最大化它等价于最小化 ∥ w ∥ 2 \|w\|^2 ∥w∥2。
所以硬间隔 SVM 的优化问题是:
min w , b 1 2 ∥ w ∥ 2 subject to y i ( w T x i + b ) ≥ 1 , ∀ i = 1 , . . . , n \begin{aligned} \min_{w, b} \quad & \frac{1}{2} \|w\|^2 \\ \text{subject to} \quad & y_i (w^T x_i + b) \geq 1,\quad \forall i = 1, ..., n \end{aligned} w,bminsubject to21∥w∥2yi(wTxi+b)≥1,∀i=1,...,n
硬间隔只适用于:
-
数据完全线性可分
-
没有噪声和异常值
如果你的数据本身是完全线性可分的,比如下图中的两类点完全不重叠,那么硬间隔SVM就可以很完美地找到一个“最大间隔的超平面”来分开它们。
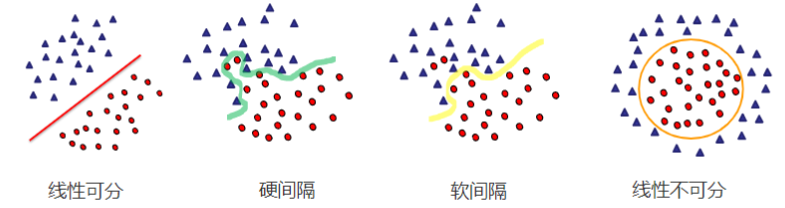
一旦数据中有噪声或重叠样本,硬间隔就无法找到合理解,甚至根本无法收敛。这时我们就要用软间隔,允许一些“点分类错了”,换取更强的容错能力。
2.1.2 硬间隔的对偶问题
构造拉格朗日函数(Lagrangian)
引入拉格朗日乘子 α i ≥ 0 \alpha_i \geq 0 αi≥0,对应约束 y i ( w T x i + b ) ≥ 1 y_i(w^T x_i + b) \geq 1 yi(wTxi+b)≥1。
构造拉格朗日函数:
L ( w , b , α ) = 1 2 ∥ w ∥ 2 − ∑ i = 1 n α i [ y i ( w T x i + b ) − 1 ] \mathcal{L}(w, b, \alpha) = \frac{1}{2} \|w\|^2 - \sum_{i=1}^n \alpha_i [y_i(w^T x_i + b) - 1] L(w,b,α)=21∥w∥2−i=1∑nαi[yi(wTxi+b)−1]
对偶问题推导步骤
我们要最小化 L \mathcal{L} L 关于 w w w 和 b b b,最大化关于 α \alpha α。
先求偏导设置为 0:
1. 对 w w w 求导并令其为 0:
∂ L ∂ w = w − ∑ i = 1 n α i y i x i = 0 ⇒ w = ∑ i = 1 n α i y i x i \frac{\partial \mathcal{L}}{\partial w} = w - \sum_{i=1}^n \alpha_i y_i x_i = 0 \Rightarrow w = \sum_{i=1}^n \alpha_i y_i x_i ∂w∂L=w−i=1∑nαiyixi=0⇒w=i=1∑nαiyixi
2. 对 b b b 求导并令其为 0:
∂ L ∂ b = − ∑ i = 1 n α i y i = 0 ⇒ ∑ i = 1 n α i y i = 0 \frac{\partial \mathcal{L}}{\partial b} = - \sum_{i=1}^n \alpha_i y_i = 0 \Rightarrow \sum_{i=1}^n \alpha_i y_i = 0 ∂b∂L=−i=1∑nαiyi=0⇒i=1∑nαiyi=0
代入得对偶问题
将 w w w 表达式代入 L \mathcal{L} L,得到只关于 α \alpha α 的对偶问题:
max α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j s.t. ∑ i = 1 n α i y i = 0 α i ≥ 0 , ∀ i \begin{aligned} \max_{\alpha} \quad & \sum_{i=1}^n \alpha_i - \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n \alpha_i \alpha_j y_i y_j x_i^T x_j \\ \text{s.t.} \quad & \sum_{i=1}^n \alpha_i y_i = 0 \\ & \alpha_i \geq 0,\quad \forall i \end{aligned} αmaxs.t.i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjxiTxji=1∑nαiyi=0αi≥0,∀i
这就是 硬间隔 SVM 的对偶形式。
它是一个凸二次规划问题,可以用标准优化算法求解。
2.2 软间隔
软间隔(Soft Margin)是支持向量机(SVM)在面对现实中不可完美划分数据时,引入的一种“宽容机制”。
通俗来说:
如果“硬间隔”是一个完美主义者,要求训练集所有点都正确分类;
那么“软间隔”就是个现实主义者,承认一些点可能分类错误,但整体效果更重要。
现实中的数据常常:
-
有噪声(例如标注错误、输入异常);
-
两类样本有重叠;
-
完全线性可分几乎不可能。
此时,如果继续使用硬间隔 SVM,会导致:
-
模型无法收敛;
-
过拟合噪声点,泛化能力差。
所以我们需要“放松限制”——允许一部分样本距离边界近,甚至被分错,但整体间隔仍尽可能大。
2.2.1 软间隔的形式定义
引入松弛变量 ξ i ≥ 0 \xi_i \geq 0 ξi≥0 来表示第 i i i 个样本允许“违背间隔要求”的程度。
优化问题变成:
min w , b , ξ 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ξ i subject to y i ( w T x i + b ) ≥ 1 − ξ i , ∀ i ξ i ≥ 0 , ∀ i \begin{aligned} \min_{w, b, \xi} \quad & \frac{1}{2} \|w\|^2 + C \sum_{i=1}^{n} \xi_i \\ \text{subject to} \quad & y_i (w^T x_i + b) \geq 1 - \xi_i,\quad \forall i \\ & \xi_i \geq 0,\quad \forall i \end{aligned} w,b,ξminsubject to21∥w∥2+Ci=1∑nξiyi(wTxi+b)≥1−ξi,∀iξi≥0,∀i
解释各个部分含义:
- 1 2 ∥ w ∥ 2 \frac{1}{2} \|w\|^2 21∥w∥2:仍然是“最大化间隔”的目标;
- ξ i \xi_i ξi:表示第 i i i 个样本有多“违反”分类边界;
* ξ i = 0 \xi_i = 0 ξi=0:正常分类、在间隔外;
* 0 < ξ i < 1 0 < \xi_i < 1 0<ξi<1:在间隔边界内但没错分;
* ξ i > 1 \xi_i > 1 ξi>1:被分错类;- C C C:是一个超参数,控制“间隔最大化”与“容忍错误”的权衡:
* C 大:更偏向少错分(严格)→ 更可能过拟合;
* C 小:更偏向宽容误差(松弛)→ 更强泛化能力。
2.2.2 软间隔的对偶问题
构造拉格朗日函数
引入拉格朗日乘子:
-
α i ≥ 0 \alpha_i \geq 0 αi≥0:对应约束 y i ( w T x i + b ) ≥ 1 − ξ i y_i(w^T x_i + b) \geq 1 - \xi_i yi(wTxi+b)≥1−ξi
-
μ i ≥ 0 \mu_i \geq 0 μi≥0:对应约束 ξ i ≥ 0 \xi_i \geq 0 ξi≥0
拉格朗日函数为:
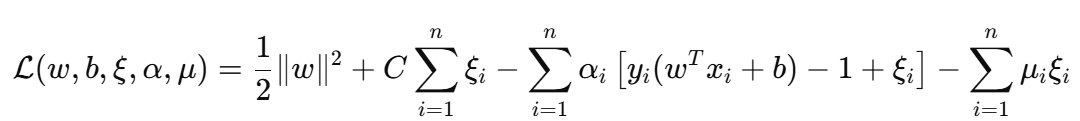
对偶问题推导(KKT 条件)
我们将对 w , b , ξ w, b, \xi w,b,ξ 求偏导并设为 0:
对 w w w 求导:
∂ L ∂ w = w − ∑ i = 1 n α i y i x i = 0 ⇒ w = ∑ i = 1 n α i y i x i \frac{\partial \mathcal{L}}{\partial w} = w - \sum_{i=1}^n \alpha_i y_i x_i = 0 \Rightarrow w = \sum_{i=1}^n \alpha_i y_i x_i ∂w∂L=w−i=1∑nαiyixi=0⇒w=i=1∑nαiyixi
对 b b b 求导:
∂ L ∂ b = − ∑ i = 1 n α i y i = 0 ⇒ ∑ i = 1 n α i y i = 0 \frac{\partial \mathcal{L}}{\partial b} = -\sum_{i=1}^n \alpha_i y_i = 0 \Rightarrow \sum_{i=1}^n \alpha_i y_i = 0 ∂b∂L=−i=1∑nαiyi=0⇒i=1∑nαiyi=0
对 ξ i \xi_i ξi 求导:
∂ L ∂ ξ i = C − α i − μ i = 0 ⇒ α i ≤ C ( 因为 μ i ≥ 0 ) \frac{\partial \mathcal{L}}{\partial \xi_i} = C - \alpha_i - \mu_i = 0 \Rightarrow \alpha_i \leq C \quad (\text{因为 } \mu_i \geq 0) ∂ξi∂L=C−αi−μi=0⇒αi≤C(因为 μi≥0)
最终对偶问题形式
整理后,软间隔 SVM 的对偶问题为:
max α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j s.t. ∑ i = 1 n α i y i = 0 0 ≤ α i ≤ C , ∀ i \begin{aligned} \max_{\alpha} \quad & \sum_{i=1}^n \alpha_i - \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n \alpha_i \alpha_j y_i y_j x_i^T x_j \\ \text{s.t.} \quad & \sum_{i=1}^n \alpha_i y_i = 0 \\ & 0 \leq \alpha_i \leq C,\quad \forall i \end{aligned} αmaxs.t.i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjxiTxji=1∑nαiyi=00≤αi≤C,∀i
相比于硬间隔的对偶问题,这里:
-
增加了上界 α i ≤ C \alpha_i \leq C αi≤C,体现对误差的容忍;
-
因此更适合实际带噪音的数据;
-
仍然是一个凸二次规划问题。
3. 核函数
3.1 核函数的定义
支持向量机算法分类和回归方法的中都支持线性性和非线性类型的数据类型。非线性类型通常是二维平面不可分,为了使数据可分,需要通过一个函数将原始数据映射到高维空间,从而使得数据在高维空间很容易可分,需要通过一个函数将原始数据映射到高维空间,从而使得数据在高维空间很容易区分,这样就达到数据分类或回归的目的,而实现这一目标的函数称为核函数。
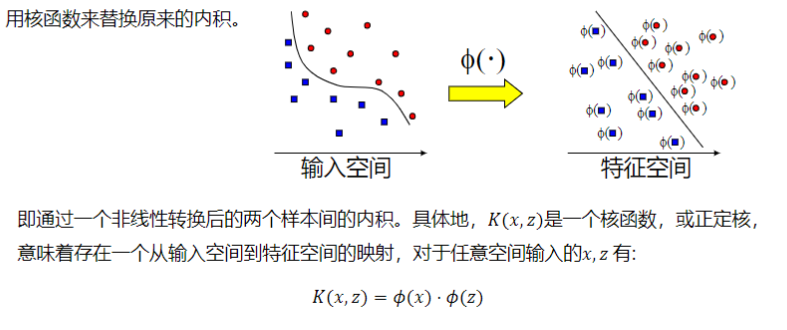
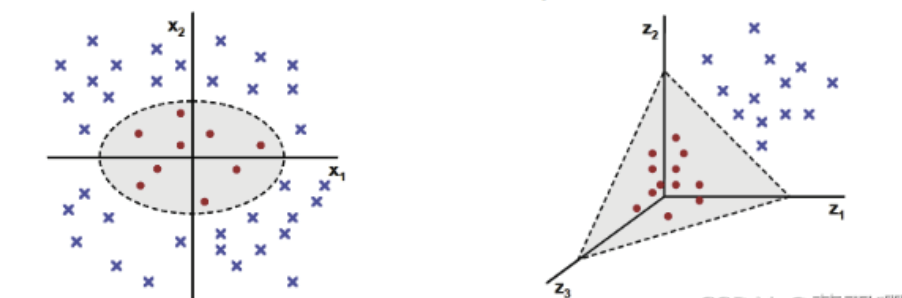
3.2 常见的核函数
1. 线性核(Linear Kernel)
K ( x , x ′ ) = x T x ′ K(x, x') = x^T x' K(x,x′)=xTx′
适用场景:
-
特征数非常大(如文本分类)
-
数据本身已经线性可分或接近线性
2. 多项式核
K ( x , x ′ ) = ( x T x ′ + c ) d K(x, x') = (x^T x' + c)^d K(x,x′)=(xTx′+c)d
其中 d d d:多项式的次数, c c c:常数项(通常 c ≥ 0 c \geq 0 c≥0)
适用场景:
-
特征间有高阶交互关系的情况
-
对非线性边界较敏感的问题
3. 高斯核
K ( x , x ′ ) = exp ( − ∥ x − x ′ ∥ 2 2 σ 2 ) K(x, x') = \exp\left(-\frac{\|x - x'\|^2}{2 \sigma^2} \right) K(x,x′)=exp(−2σ2∥x−x′∥2)
其中 σ \sigma σ:控制“邻近范围”的宽度(或使用 γ = 1 2 σ 2 \gamma = \frac{1}{2\sigma^2} γ=2σ21)
适用场景:
-
不知道数据的具体分布情况
-
默认首选的非线性核
4. Sigmoid 核(双曲正切核)
K ( x , x ′ ) = tanh ( κ x T x ′ + c ) K(x, x') = \tanh(\kappa x^T x' + c) K(x,x′)=tanh(κxTx′+c)
类似于神经元中的激活函数
适用场景:
-
模拟神经网络的效果(如早期神经 SVM 研究)
-
情况较少使用
二、代码实战
1. 实验内容
实战要求:使用SVM建立自己的垃圾邮件过滤器。首先需要将每个邮件x变成一个n维的特征向量,并训练一个分类器来分类给定的电子邮件x是否属于垃圾邮件 ( y = 1 ) (y=1)(y=1) 或者非垃圾邮件 ( y = 0 ) (y=0)(y=0) 。
已有数据集:emailSample1.txt, vocab.txt, spamTrain.mat, spamTest.mat
2.代码实现
1. 加载并查看样例邮件内容
#查看样例邮件
f = open('emailSample1.txt', 'r').read()
print(f)
读取一封样例邮件的原始文本内容,便于后续处理。
2. 邮件预处理函数 processEmail
def processEmail(email):email = email.lower() #转化为小写email = re.sub('<[^<>]+>', ' ', email) #移除所有HTML标签email = re.sub(r'(http|https)://[^\s]*', 'httpaddr', email) #将所有的URL替换为'httpaddr'email = re.sub(r'[^\s]+@[^\s]+', 'emailaddr', email) #将所有的地址替换为'emailaddr'email = re.sub(r'\d+', 'number', email) #将所有数字替换为'number'email = re.sub('[$]+', 'dollar', email) #将所有美元符号($)替换为'dollar'#将所有单词还原为词根//移除所有非文字类型,空格调整stemmer = nltk.stem.PorterStemmer() #使用Porter算法tokens = re.split(r'[ @$/#.-:&*+=\[\]?!()\{\},\'\">_<;%]', email) #把邮件分割成单个的字符串,[]里面为各种分隔符tokenlist = []for token in tokens:token = re.sub('[^a-zA-Z0-9]', '', token) #去掉任何非字母数字字符try: #porterStemmer有时会出现问题,因此用trytoken = stemmer.stem(token) #词根except:token = ''if len(token) < 1: continue #字符串长度小于1的不添加到tokenlist里tokenlist.append(token)return tokenlist
核心步骤解释:
-
统一格式:转小写、去 HTML 标签、替换网址、邮箱、数字、货币符号等。
-
分词:使用正则表达式切分文本成单词。
-
词干提取(stemming):调用 NLTK 的 PorterStemmer,还原单词基本形式,如 running → run。
-
清洗:剔除空词、特殊符号,返回标准词汇列表。
- 词汇表映射及向量化处理
vocab_list = np.loadtxt('vocab.txt', dtype='str', usecols=1)
词汇表 vocab.txt 中存有 1899 个关键词。
下面两个函数实现了“文本 → 向量”转换:
def word_indices(processed_f, vocab_list):indices = []for i in range(len(processed_f)):for j in range(len(vocab_list)):if processed_f[i]!=vocab_list[j]:continueindices.append(j+1)return indices
def emailFeatures(indices):features = np.zeros((1899))for each in indices:features[each-1] = 1 #若indices在对应单词表的位置上词语存在则记为1return features
效果:
每封邮件被表示成一个 1899维的二进制特征向量,其中:
-
第 i i i 个位置为
1,表示邮件中包含词汇表中第 i i i 个词。 -
类似 One-hot 编码,但是多热(multi-hot)表示。
- 训练 SVM 模型
train = scio.loadmat('spamTrain.mat')
train_x = train['X']
train_y = train['y']
- 载入 .mat 格式的训练数据。
- X 为 4000 封邮件的特征矩阵,y 为对应的垃圾与非垃圾标签(1 或 0)。
clf = svm.SVC(C=0.1, kernel='linear')
clf.fit(train_x, train_y)
- 使用线性核训练 SVM 模型。
- 参数 C=0.1 控制软间隔的惩罚程度,越小越宽容。
- 模型评估
def accuracy(clf, x, y):predict_y = clf.predict(x)m = y.sizecount = 0for i in range(m):count = count + np.abs(int(predict_y[i])-int(y[i])) #避免溢出错误得到225return 1-float(count/m)
- 自定义精度计算函数,统计预测正确率。
train_accuracy = accuracy(clf, train_x, train_y)
test_accuracy = accuracy(clf, test['Xtest'], test['ytest'])
- 解释模型——重要单词排序
print(vocab_list[np.argsort(clf.coef_).flatten()[i]], end=' ')
- SVM 的线性模型可以通过系数权重判断哪些词对“判定为垃圾邮件”影响最大。
打印前 15 个正权重最大词汇,说明:
邮件中若含这些词,更可能是垃圾邮件。
- 预测新邮件是否为垃圾邮件
t = open('spamSample2.txt', 'r').read()
processed_f = processEmail(t)
f_indices = word_indices(processed_f, vocab_list)
x = np.reshape(emailFeatures(f_indices), (1,1899))
clf.predict(x)
- 流程和训练集一致,对新邮件样本做预处理 → 向量化 → 调用模型预测。
- 输出为 1(垃圾)或 0(正常)。
- PCA 可视化 SVM 决策边界
# PCA降维到2维
pca = PCA(n_components=2)
train_x_pca = pca.fit_transform(train_x)# 重新训练一个2维的SVM,用于绘制决策边界
clf_pca = svm.SVC(C=0.1, kernel='linear')
clf_pca.fit(train_x_pca, train_y)# 画图
plt.figure(figsize=(10, 6))# 绘制不同类别样本点
plt.scatter(train_x_pca[train_y==0, 0], train_x_pca[train_y==0, 1], c='blue', label='Non-spam', edgecolors='k')
plt.scatter(train_x_pca[train_y==1, 0], train_x_pca[train_y==1, 1], c='red', label='Spam', edgecolors='k')# 绘制决策边界
# 创建一个网格
x_min, x_max = train_x_pca[:, 0].min() - 1, train_x_pca[:, 0].max() + 1
y_min, y_max = train_x_pca[:, 1].min() - 1, train_x_pca[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 500),np.linspace(y_min, y_max, 500))# 计算决策函数值
Z = clf_pca.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)# 绘制决策边界和间隔带
plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='green')
plt.contour(xx, yy, Z, levels=[-1, 1], linestyles='--', colors='gray')plt.legend()
plt.title('SVM Decision Boundary (PCA Reduced 2D)')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
- 用 PCA 将高维特征压缩成 2 维空间。
- 使用 SVM 在这个低维空间重新训练一个模型(仅用于可视化)。
- 展示不同类别的点分布情况,以及 SVM 的分界线与间隔。
- 完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.io as scio
from sklearn import svm
import re #处理正则表达式的模块
import nltk #自然语言处理工具包
from sklearn.decomposition import PCA#查看样例邮件
f = open('emailSample1.txt', 'r').read()
print(f)def processEmail(email):email = email.lower() #转化为小写email = re.sub('<[^<>]+>', ' ', email) #移除所有HTML标签email = re.sub(r'(http|https)://[^\s]*', 'httpaddr', email) #将所有的URL替换为'httpaddr'email = re.sub(r'[^\s]+@[^\s]+', 'emailaddr', email) #将所有的地址替换为'emailaddr'email = re.sub(r'\d+', 'number', email) #将所有数字替换为'number'email = re.sub('[$]+', 'dollar', email) #将所有美元符号($)替换为'dollar'#将所有单词还原为词根//移除所有非文字类型,空格调整stemmer = nltk.stem.PorterStemmer() #使用Porter算法tokens = re.split(r'[ @$/#.-:&*+=\[\]?!()\{\},\'\">_<;%]', email) #把邮件分割成单个的字符串,[]里面为各种分隔符tokenlist = []for token in tokens:token = re.sub('[^a-zA-Z0-9]', '', token) #去掉任何非字母数字字符try: #porterStemmer有时会出现问题,因此用trytoken = stemmer.stem(token) #词根except:token = ''if len(token) < 1: continue #字符串长度小于1的不添加到tokenlist里tokenlist.append(token)return tokenlist#查看处理后的样例
processed_f = processEmail(f)
for i in processed_f:print(i, end=' ')#得到单词表,序号为索引号+1
vocab_list = np.loadtxt('vocab.txt', dtype='str', usecols=1)
#得到词汇表中的序号
def word_indices(processed_f, vocab_list):indices = []for i in range(len(processed_f)):for j in range(len(vocab_list)):if processed_f[i]!=vocab_list[j]:continueindices.append(j+1)return indices#查看样例序号
f_indices = word_indices(processed_f, vocab_list)
for i in f_indices:print(i, end=' ')def emailFeatures(indices):features = np.zeros((1899))for each in indices:features[each-1] = 1 #若indices在对应单词表的位置上词语存在则记为1return featuressum(emailFeatures(f_indices)) #45def emailFeatures(indices):features = np.zeros((1899))for each in indices:features[each-1] = 1 #若indices在对应单词表的位置上词语存在则记为1return featuressum(emailFeatures(f_indices)) #45#训练模型
train = scio.loadmat('spamTrain.mat')
train_x = train['X']
train_y = train['y']clf = svm.SVC(C=0.1, kernel='linear')
clf.fit(train_x, train_y)#精度
def accuracy(clf, x, y):predict_y = clf.predict(x)m = y.sizecount = 0for i in range(m):count = count + np.abs(int(predict_y[i])-int(y[i])) #避免溢出错误得到225return 1-float(count/m) train_accuracy = accuracy(clf, train_x, train_y) #0.99825
print("Train accuracy:", train_accuracy)#测试模型
test = scio.loadmat('spamTest.mat')test_accuracy = accuracy(clf, test['Xtest'], test['ytest']) #0.989
print("Test accuracy:", test_accuracy)#打印权重最高的前15个词,邮件中出现这些词更容易是垃圾邮件
i = (clf.coef_).size-1
while i >1883:#返回从小到大排序的索引,然后再打印print(vocab_list[np.argsort(clf.coef_).flatten()[i]], end=' ')i = i-1t = open('spamSample2.txt', 'r').read()
#预处理
processed_f = processEmail(t)
f_indices = word_indices(processed_f, vocab_list)
#特征提取
x = np.reshape(emailFeatures(f_indices), (1,1899))
#预测
clf.predict(x)# 载入训练数据
train = scio.loadmat('spamTrain.mat')
train_x = train['X']
train_y = train['y'].flatten() # 拉平成1维数组方便使用# 用线性核训练SVM
clf = svm.SVC(C=0.1, kernel='linear')
clf.fit(train_x, train_y)# PCA降维到2维
pca = PCA(n_components=2)
train_x_pca = pca.fit_transform(train_x)# 重新训练一个2维的SVM,用于绘制决策边界
clf_pca = svm.SVC(C=0.1, kernel='linear')
clf_pca.fit(train_x_pca, train_y)# 画图
plt.figure(figsize=(10, 6))# 绘制不同类别样本点
plt.scatter(train_x_pca[train_y==0, 0], train_x_pca[train_y==0, 1], c='blue', label='Non-spam', edgecolors='k')
plt.scatter(train_x_pca[train_y==1, 0], train_x_pca[train_y==1, 1], c='red', label='Spam', edgecolors='k')# 绘制决策边界
# 创建一个网格
x_min, x_max = train_x_pca[:, 0].min() - 1, train_x_pca[:, 0].max() + 1
y_min, y_max = train_x_pca[:, 1].min() - 1, train_x_pca[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 500),np.linspace(y_min, y_max, 500))# 计算决策函数值
Z = clf_pca.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)# 绘制决策边界和间隔带
plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='green')
plt.contour(xx, yy, Z, levels=[-1, 1], linestyles='--', colors='gray')plt.legend()
plt.title('SVM Decision Boundary (PCA Reduced 2D)')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
3.运行结果
-
决策边界与支持向量带
绿色实线:SVM 的决策边界(分类超平面),表示模型判断垃圾/非垃圾邮件的分界线。
灰色虚线(上下各一条):代表 SVM 的“间隔边界”(margin)——支持向量带。
SVM 的目标就是最大化这两条边界之间的间隔(margin)。
落在虚线之间的点是支持向量,最影响决策边界的位置。 -
分类结果分布
红色点(Spam):预测为垃圾邮件
蓝色点(Non-spam):预测为非垃圾邮件
观察结果:
大部分红点和蓝点被成功分开,说明模型效果不错。
决策边界大致水平(沿 x 轴延展),说明分类器主要依据 PCA 的第 2 主成分 进行分类(也就是 y 轴方向)。
有少量红蓝点混杂,尤其靠近边界或 margin 区域,是分类难度较大的样本,也可能是误分类点。