前文【FlashRAG】本地部署与demo运行(一)
下载必要的模型文件
完成了项目拉取和依赖下载后,我们需要进一步下载模型文件

Faiss(Facebook AI Similarity Search)是由Facebook AI团队开发的高效相似性搜索和密集向量聚类库。它专门优化了大规模向量数据库的搜索和聚类任务,适用于机器学习中的嵌入向量检索场景,如推荐系统、图像检索、自然语言处理等。
这里CPU/GPU版本可以自己选择,GPU版本需要看自己的卡和cuda进行选择
pip install faiss-gpu-cu12pip install faiss-cpu
检索器(Retriever)
我使用的是e5-base-v2模型和bge-small-zh-v1.5模型
git clone https://hf-mirror.com/intfloat/e5-base-v2
git clone https://hf-mirror.com/BAAI/bge-small-zh-v1.5
生成器(Generator)
使用qwen3-0.6b作为生成器
git lfs install
git clone https://www.modelscope.cn/Qwen/Qwen3-0.6B.git
Git LFS(Large File Storage)是 Git 的一个扩展,用于高效管理大文件。我这里因为之前使用过这个模型,所以没有下载到flashrag项目目录内,后面使用时注意看目录是在哪
examples文件配置
可以看到这里有中英两个demo文件,我们以中文demo为例运行,直接贴出修改后的代码
import sys
import ossys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "../../")))
import streamlit as st
from flashrag.config import Config
from flashrag.utils import get_retriever, get_generator
from flashrag.prompt import PromptTemplateconfig_dict = {"save_note": "demo","generator_model": "qwen-local","retrieval_method": "bge-local","model2path": {"bge-local": "D:/PycharmProjects/FlashRAG/bge-small-zh-v1.5","qwen-local": "D:/PycharmProjects/Qwen3-0.6B",},"corpus_path": "./indexes/general_knowledge.jsonl","index_path": "./indexes/bge_flat.index",
}@st.cache_resource
def load_retriever(_config):return get_retriever(_config)@st.cache_resource
def load_generator(_config):return get_generator(_config)if __name__ == '__main__':st.set_page_config(page_title="FlashRAG 中文 Demo", page_icon="⚡")st.sidebar.title("配置选项")temperature = st.sidebar.slider("温度系数 (temperature):", 0.01, 1.0, 0.5)topk = st.sidebar.slider("检索文档数 TopK:", 1, 10, 5)max_new_tokens = st.sidebar.slider("最大生成长度 (tokens):", 1, 2048, 256)st.title("⚡FlashRAG 中文 Demo")st.write("本系统支持中文文档检索与问答生成,支持本地模型。")query = st.text_area("请输入你的问题:")config = Config("my_config.yaml", config_dict=config_dict)generator = load_generator(config)retriever = load_retriever(config)system_prompt_rag = ("你是一个友好的中文智能助手。请根据下方提供的参考文档回答用户的问题。\n\n{reference}")system_prompt_no_rag = ("你是一个友好的中文智能助手。请根据你的知识回答用户的问题。\n")base_user_prompt = "{question}"prompt_template_rag = PromptTemplate(config, system_prompt=system_prompt_rag, user_prompt=base_user_prompt)prompt_template_no_rag = PromptTemplate(config, system_prompt=system_prompt_no_rag, user_prompt=base_user_prompt)if st.button("生成回答"):with st.spinner("正在检索并生成回答..."):retrieved_docs = retriever.search(query, num=topk)st.subheader("检索参考文档", divider="gray")for i, doc in enumerate(retrieved_docs):doc_title = doc.get("title", "无标题")doc_text = "\n".join(doc["contents"].split("\n")[1:])expander = st.expander(f"【{i + 1}】:{doc_title}", expanded=False)with expander:st.markdown(doc_text, unsafe_allow_html=True)st.subheader("生成回答结果", divider="gray")input_prompt_with_rag = prompt_template_rag.get_string(question=query, retrieval_result=retrieved_docs)response_with_rag = generator.generate(input_prompt_with_rag, temperature=temperature, max_new_tokens=max_new_tokens)[0]st.subheader("带文档的回答:")st.write(response_with_rag)input_prompt_without_rag = prompt_template_no_rag.get_string(question=query)response_without_rag = generator.generate(input_prompt_without_rag, temperature=temperature, max_new_tokens=max_new_tokens)[0]st.subheader("无文档的回答:")st.write(response_without_rag)主要的修改在config里,把路径替换成自己的本地模型,当然你网速够快、硬件资源够好,直接从线上加载推荐的模型也是可以的
config_dict = {"save_note": "demo","generator_model": "qwen-local","retrieval_method": "bge-local","model2path": {"bge-local": "D:/PycharmProjects/FlashRAG/bge-small-zh-v1.5","qwen-local": "D:/PycharmProjects/Qwen3-0.6B",},"corpus_path": "./indexes/general_knowledge.jsonl","index_path": "./indexes/bge_flat.index",
}
这段代码的作用是让解释器生效,将上级目录的上级目录(即项目根目录)添加到系统的 Python 路径中,不然找不到。
import sys
import ossys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "../../")))
除此之外还要新建一个bat文件,用来跑jsonl进而生成所需的index
代码如下:
python -m flashrag.retriever.index_builder ^--retrieval_method e5 ^--model_path D:/PycharmProjects/FlashRAG/e5-base-v2 ^--corpus_path D:/PycharmProjects/FlashRAG/examples/quick_start/indexes/general_knowledge.jsonl ^--save_dir D:/PycharmProjects/FlashRAG/examples/quick_start/indexes ^--use_fp16 ^--max_length 512 ^--batch_size 256 ^--pooling_method mean ^--faiss_type Flat```bash
python -m flashrag.retriever.index_builder ^--retrieval_method bge ^--model_path D:/PycharmProjects/FlashRAG/bge-small-zh-v1.5 ^--corpus_path D:/PycharmProjects/FlashRAG/examples/quick_start/indexes/general_knowledge.jsonl ^--save_dir D:/PycharmProjects/FlashRAG/examples/quick_start/indexes ^--use_fp16 ^--max_length 512 ^--batch_size 256 ^--pooling_method mean ^--faiss_type Flat
CD到retriever目录下执行run_indexing.bat即可

run之后就会在indexes生成两个index文件
路径为FlashRAG/examples/quick_start/indexes
接着修改examples/quick_start/my_config.yaml文件下的模型,这里我替换为本地模型
save_note: "demo"
generator_model: "qwen-local"
retrieval_method: "bge-local"
model2path:bge-local: "D:/PycharmProjects/FlashRAG/bge-small-zh-v1.5"qwen-local: "D:/PycharmProjects/Qwen3-0.6B"
corpus_path: "./data/general_zh.jsonl"
index_path: "./indexes/bge_flat.index"examples/methods/my_config.yaml
这里的也改改
# ------------------------------------------------Global Paths------------------------------------------------#
# Paths to models
model2path:e5: "D:/PycharmProjects/FlashRAG/e5-base-v2"bge: "D:/PycharmProjects/FlashRAG/bge-small-zh-v1.5"contriever: "facebook/contriever"llama2-7B-chat: "meta-llama/Llama-2-7b-chat-hf"llama2-7B: "meta-llama/Llama-2-7b-hf"llama2-13B: "meta-llama/Llama-2-13b-hf"llama2-13B-chat: "meta-llama/Llama-2-13b-chat-hf"llama3-8B-instruct: "meta-llama/Meta-Llama-3-8B-Instruct"Qwen3-0.6B: "D:/PycharmProjects/Qwen3-0.6B"# Pooling methods for each embedding model
model2pooling:e5: "mean"bge: "cls"contriever: "mean"jina: 'mean'dpr: cls# Indexes path for retrieval models
method2index:e5: D:/PycharmProjects/FlashRAG/examples/methods/index/nq/e5_Flat.indexbm25: ~contriever: ~# ------------------------------------------------Environment Settings------------------------------------------------#
# Directory paths for data and outputs
data_dir: "dataset/"
save_dir: "output/"gpu_id: "0,1,2,3"
dataset_name: "nq" # name of the dataset in data_dir
split: [ "test" ] # dataset split to load (e.g. train,dev,test)# Sampling configurations for testing
test_sample_num: ~ # number of samples to test (only work in dev/test split), if None, test all samples
random_sample: False # whether to randomly sample the test samples# Seed for reproducibility
seed: 2024# Whether save intermediate data
save_intermediate_data: True
save_note: 'experiment'# -------------------------------------------------Retrieval Settings------------------------------------------------#
# If set the name, the model path will be find in global paths
retrieval_method: "e5" # name or path of the retrieval model.
index_path: ~ # set automatically if not provided.
faiss_gpu: False # whether use gpu to hold index
corpus_path: ~ # path to corpus in '.jsonl' format that store the documentsinstruction: ~ # instruction for retrieval model
retrieval_topk: 5 # number of retrieved documents
retrieval_batch_size: 256 # batch size for retrieval
retrieval_use_fp16: True # whether to use fp16 for retrieval model
retrieval_query_max_length: 128 # max length of the query
save_retrieval_cache: False # whether to save the retrieval cache
use_retrieval_cache: False # whether to use the retrieval cache
retrieval_cache_path: ~ # path to the retrieval cache
retrieval_pooling_method: ~ # set automatically if not provideduse_reranker: False # whether to use reranker
rerank_model_name: ~ # same as retrieval_method
rerank_model_path: ~ # path to reranker model, path will be automatically find in `retriever_model2path`
rerank_pooling_method: ~
rerank_topk: 5 # number of remain documents after reranking
rerank_max_length: 512
rerank_batch_size: 256 # batch size for reranker
rerank_use_fp16: True# -------------------------------------------------Generator Settings------------------------------------------------#
framework: vllm # inference frame work of LLM, supporting: 'hf','vllm','fschat'
generator_model: "D:/PycharmProjects/Qwen3-0.6B" # name or path of the generator model
generator_max_input_len: 2048 # max length of the input
generator_batch_size: 2 # batch size for generation, invalid for vllm
generation_params:do_sample: Falsemax_tokens: 32
use_fid: False # whether to use FID, only valid in encoder-decoder model# -------------------------------------------------Refiner Settings------------------------------------------------#
# If set, the refiner will be used to refine the retrieval documents.
refiner_name: ~
refiner_model_path: ~# Used for extractive method (e.g embedding models)
refiner_topk: 5 # number of remain sentence after refiner
refiner_pooling_method: 'mean' # pooling method of refiner model
refiner_encode_max_length: 256
# Used for abstractive method (e.g. generation models like bart-large-cnn)
refiner_max_input_length: 1024
refiner_max_output_length: 512# Specify settings for llmlingua
llmlingua_config:rate: 0.55condition_in_question: 'after_condition'reorder_context: 'sort'dynamic_context_compression_ratio: 0.3condition_compare: Truecontext_budget: "+100"rank_method: 'longllmlingua'
sc_config:'reduce_ratio': 0.5# -------------------------------------------------Evaluation Settings------------------------------------------------#
# Metrics to evaluate the result
metrics: [ 'em','f1','acc','precision','recall']
# Specify setting for metric, will be called within certain metrics
metric_setting:retrieval_recall_topk: 5
save_metric_score: True # whether to save the metric score into txt file
demo文件启动
在quickstart目录下,执行demo文件
streamlit run demo_zh.py
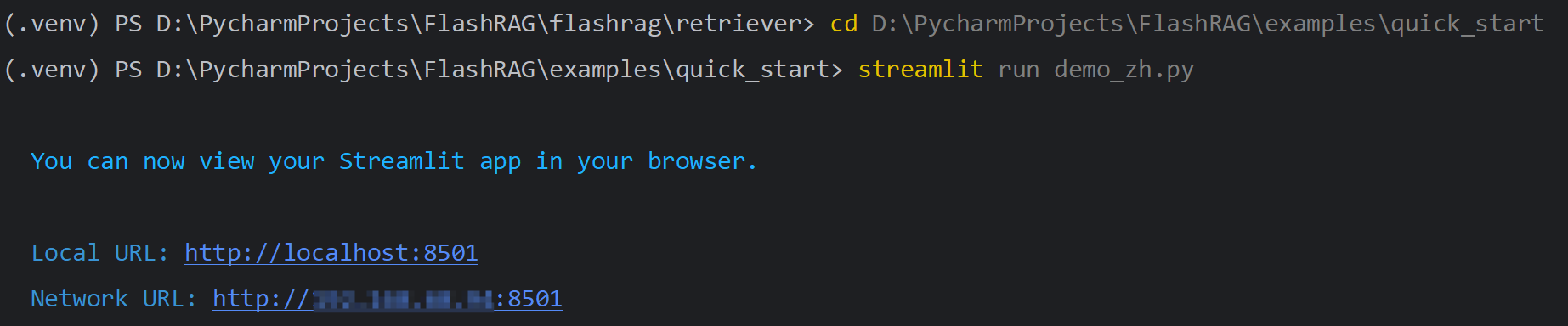
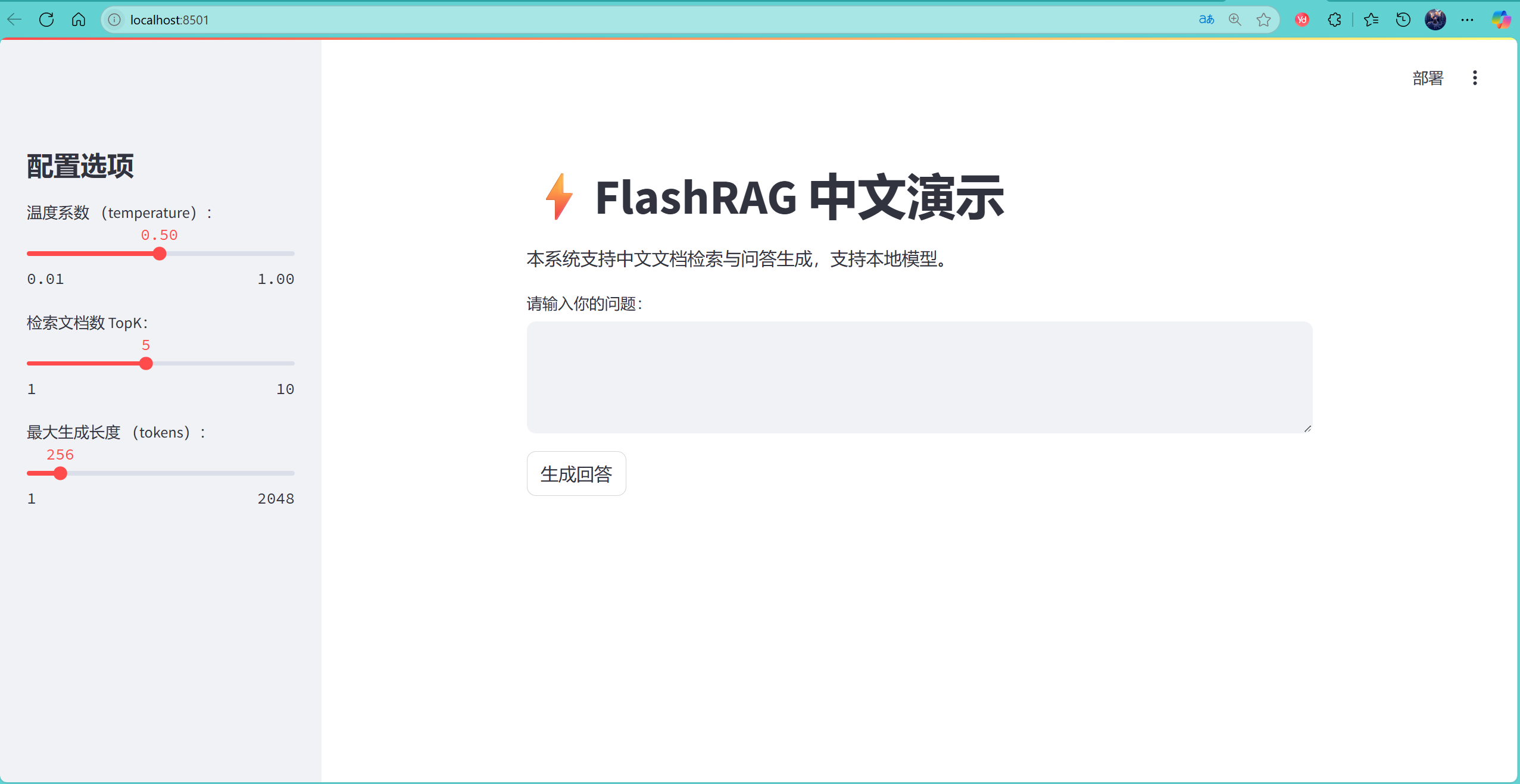
完成启动


![[yolov11改进系列]基于yolov11引入倒置残差块块注意力机制iEMA的python源码+训练源码](https://i-blog.csdnimg.cn/direct/99682f4c69c940aca8c78a1e76bb7f0b.jpeg)



![[C++]vc6.0在win10或者win11上下载安装和简单使用教程](https://i-blog.csdnimg.cn/direct/bd4026cf3ee7488fa8f7c192cfd2820c.png)