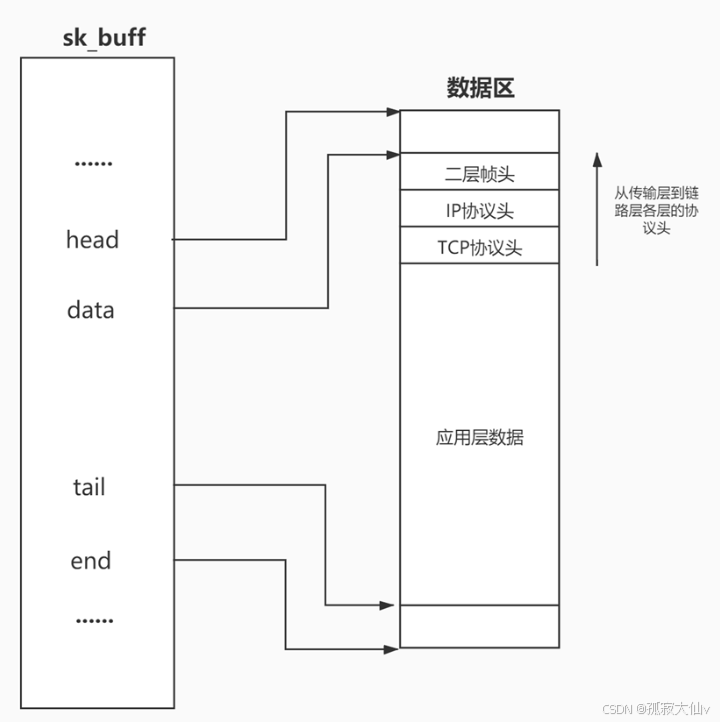
一、核心思想


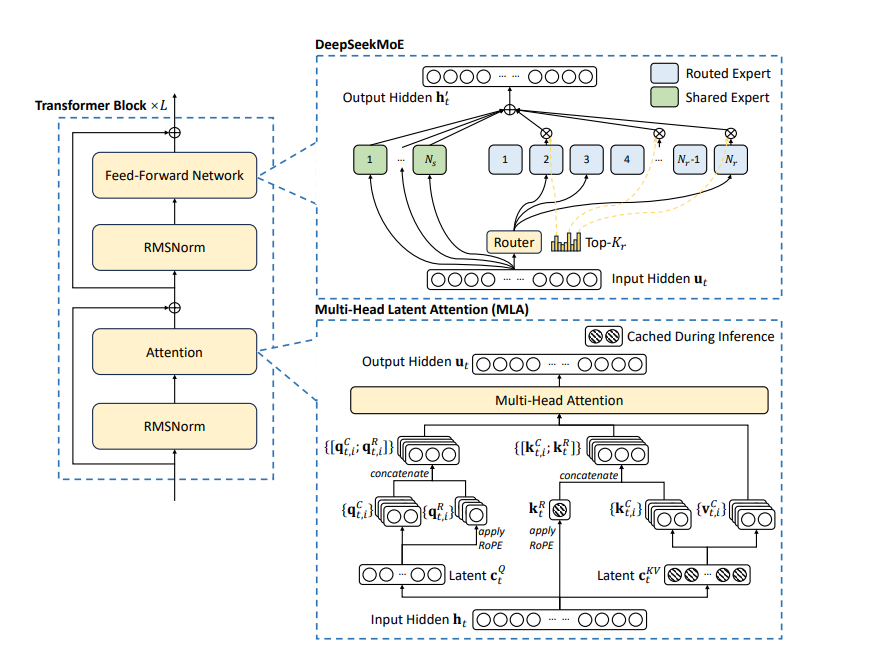 先看下初始的MLA的一般性公式:
先看下初始的MLA的一般性公式:
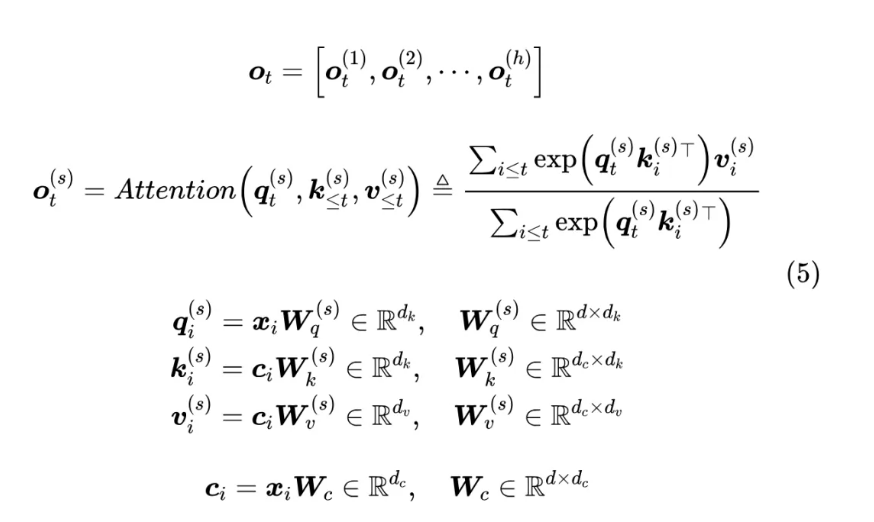
我们一般会缓存的是投影后的k_i, v_i而不是投影前的x_i, c_i ,根据 MLA 的这个做法,通过不同的投影矩阵再次让所有的 K、V Head 都变得各不相同,那么 KV Cache 的大小就恢复成跟 MHA 一样大了,因为需要存下每一个k_i, v_i,这显然违背了减少kv cache的本意。MLA算法作者发现,可以结合 Dot-Attention 的矩阵运算的具体形式,通过一个简单但不失巧妙的恒等变换来实现输入的低秩压缩。根据如下公式:
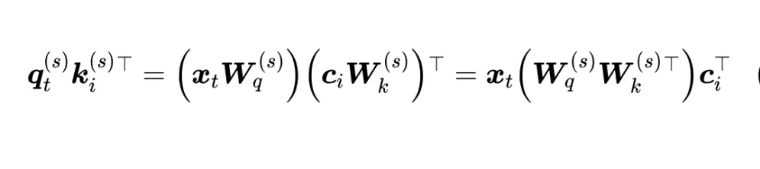
二、考虑位置编码的问题

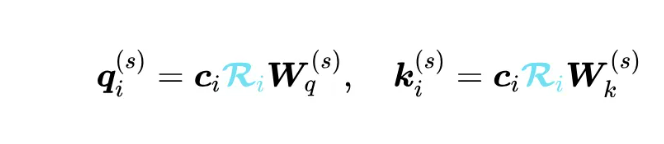

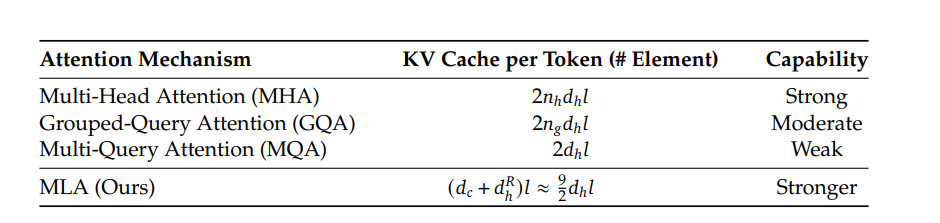
需要缓存的信息就是蓝色的两个数据。Prefill 阶段涉及到对输入所有 Token 的并行计算,然后把对应的 KV Cache 存下来,这部分对于计算、带宽和显存都是瓶颈,MLA 虽然增大了计算量,但 KV Cache 的减少也降低了显存和带宽的压力,二者相互制约;但是 Generation 阶段由于每步只计算一个 Token,实际上它更多的是带宽瓶颈和显存瓶颈,因此 MLA 的引入理论上能明显提高 Generation 的速度。
目前V2代码中,Attention中的KV Cache缓存的仍然是全量的key和value(从隐向量又解压缩出来),而并非论文中所说的压缩后的compressed_kv以及k_pe,导致其实没有减少KV Cache的缓存。可能开源的是训练代码。
参数维度举例:DeepSeek-V3的参数配置
"vocab_size": 129280,
"dim": 7168,
"inter_dim": 18432,
"n_heads": 128,
"q_lora_rank": 1536,
"kv_lora_rank": 512,
"qk_nope_head_dim": 128,
"qk_rope_head_dim": 64,
"v_head_dim": 128,
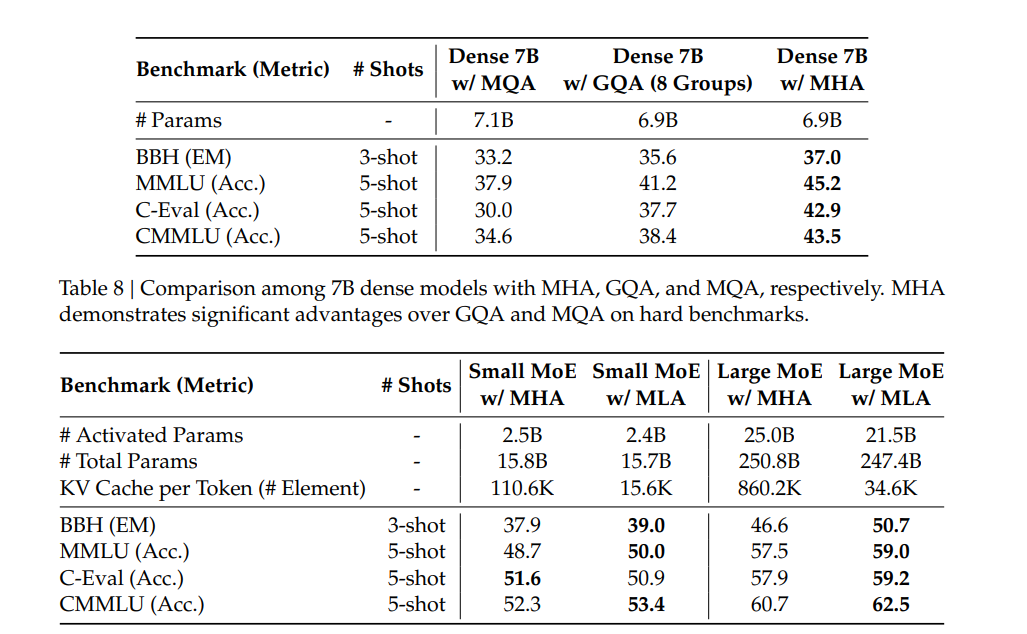
 三、实验数据
三、实验数据