文章目录
- 1. 前置知识
- Softmax函数
- 信息熵(Entropy)
- 2. 熵最小化
- 3. 案例理解
- 4. 总结
熵最小化是一种利用未标记数据的策略,其核心思想是鼓励模型对未标记数据做出“自信”的预测,即预测概率分布尽可能尖锐(Peaky)而非平坦(Flat)。熵最小化在半监督学习(Semi-Supervised Learning, SSL)和域自适应(Domain Adaptation, DA)中得到广泛应用。
例如,源域有标签,目标域无标签,在目标域数据上应用熵最小化,鼓励模型在目标域上做出自信的预测(降低预测的不确定性)。具体的迁移学习应用,可以看文末提供的文献。
1. 前置知识
Softmax函数
也称归一化指数函数[1],使每一个元素的范围都压缩在(0,1)之间,并且所有元素的和为1 。
σ ( z ) j = e z j ∑ k = 1 K e z k for j = 1 , … , K . \sigma(\mathbf{z})_j = \frac{e^{z_j}}{\sum_{k = 1}^K e^{z_k}} \quad \text{for } j = 1, \ldots, K. σ(z)j=∑k=1Kezkezjfor j=1,…,K.
eg:
import math
z = [1.0, 2.0, 3.0]
z_exp = [math.exp(i) for i in z] # z_exp=[2.72, 7.39, 20.09]
sum_z_exp = sum(z_exp) # 30.19
softmax = [round(i / sum_z_exp, 2) for i in z_exp] # softmax=[0.09, 0.24, 0.67]
信息熵(Entropy)
在信息论里面,熵是对不确定性的测量。熵越高,则能传输越多的信息,熵越低,则意味着传输的信息越少[2]。通俗来说,事件发生的概率越高(P越大),则该事件暗含的信息量越少,熵越小(H越小),事件不确定性越低。
熵用于度量系统的混乱程度,熵越大(H越大),系统越混乱,不确定性越大(P越小)。
H ( X ) = − ∑ i P ( x i ) log P ( x i ) , \mathrm{H}(X) =- \sum_{i} \mathrm{P}(x_i) \log \mathrm{P}(x_i), H(X)=−i∑P(xi)logP(xi),
直观解释[3]:

eg:
import numpy as npT1 = np.array([0.33, 0.33, 0.34]) # 事件1
T2 = np.array([0.15, 0.7, 0.15]) # 事件2H1 = -np.sum(T1 * np.log(T1)) # 1.0985
H2 = -np.sum(T2 * np.log(T2)) # 0.8188
可以看出,T1概率分布更均匀,熵更大(不确定性更高);T2概率分布更集中,熵更小(不确定性更低)。
2. 熵最小化
下面从熵最小化的梯度角度理解其作用。首先,定义softmax函数和信息熵H(x):
Softmax:
p k = e z k ∑ j = 1 K e z j , k = 1 , 2 , … , K p_k = \frac{e^{z_k}}{\sum_{j=1}^K e^{z_j}}, \quad k = 1, 2, \ldots, K pk=∑j=1Kezjezk,k=1,2,…,K
Entropy:
H = − ∑ k = 1 K p k log p k H = -\sum_{k=1}^K p_k \log p_k H=−k=1∑Kpklogpk
对 logits z m z_m zm 的偏导:
∂ H ∂ z m = − ∑ k = 1 K ∂ ( p k log p k ) ∂ z m = − ∑ k = 1 K ( ∂ p k ∂ z m ∗ log p k + p k ∗ ∂ log p k ∂ z m ) = − ∑ k = 1 K ( ∂ p k ∂ z m ∗ log p k + ∂ p k ∂ z m ) = − ∑ k = 1 K ∂ p k ∂ z m ( log p k + 1 ) = − ∂ p m ∂ z m ( log p m + 1 ) − ∑ k = 1 , k ≠ m K ∂ p k ∂ z m ( log p k + 1 ) , 第一项 k = m ,第二项 k ≠ m \begin{align*} \frac{\partial H}{\partial z_m} &= -\sum_{k=1}^K \frac{\partial(p_k \log p_k)}{\partial z_m} \\ &= -\sum_{k=1}^K \left(\frac{\partial p_k}{\partial z_m}*\log p_k + p_k*\frac{\partial \log p_k}{\partial z_m} \right) \\ &= -\sum_{k=1}^K \left(\frac{\partial p_k}{\partial z_m} * \log p_k +\frac{\partial p_k}{\partial z_m} \right) \\ &= -\sum_{k=1}^K \frac{\partial p_k}{\partial z_m} \left(\log p_k + 1 \right) \\ &= -\frac{\partial p_m}{\partial z_m} \left(\log p_m + 1 \right)-\sum_{k=1,k\neq m}^K \frac{\partial p_k}{\partial z_m} \left(\log p_k + 1 \right) \text{, 第一项$k=m$,第二项$k\neq m$} \\ \end{align*} ∂zm∂H=−k=1∑K∂zm∂(pklogpk)=−k=1∑K(∂zm∂pk∗logpk+pk∗∂zm∂logpk)=−k=1∑K(∂zm∂pk∗logpk+∂zm∂pk)=−k=1∑K∂zm∂pk(logpk+1)=−∂zm∂pm(logpm+1)−k=1,k=m∑K∂zm∂pk(logpk+1), 第一项k=m,第二项k=m
其中,Softmax的偏导数有两种情况:
① 当 k = m k=m k=m时, p m = e z m / ∑ j = 1 K e z j p_m=e^{z_m}/\sum_{j=1}^{K}e^{z_j} pm=ezm/∑j=1Kezj:
∂ p k ∂ z m = e z m ∗ ∑ j = 1 K e z j − e z m ∗ e z m ( ∑ j = 1 K e z j ) 2 = e z m ∑ j = 1 K e z j × ∑ j = 1 K e z j − e z m ∑ j = 1 K e z j = e z m ∑ j = 1 K e z j × ( 1 − e z m ∑ j = 1 K e z j ) = p m ( 1 − p m ) \begin{align*} \frac{\partial p_k}{\partial z_m} &= \frac{e^{z_m}*\sum_{j=1}^{K}e^{z_j}-e^{z_m}*e^{z_m}}{(\sum_{j=1}^{K}e^{z_j})^2} \\ &= \frac{e^{z_m}}{\sum_{j=1}^{K}e^{z_j}} \times \frac{\sum_{j=1}^{K}e^{z_j}-e^{z_m}}{\sum_{j=1}^{K}e^{z_j}} \\ &= \frac{e^{z_m}}{\sum_{j=1}^{K}e^{z_j}} \times \left(1-\frac{e^{z_m}}{\sum_{j=1}^{K}e^{z_j}}\right) \\ &= p_m(1-p_m) \end{align*} ∂zm∂pk=(∑j=1Kezj)2ezm∗∑j=1Kezj−ezm∗ezm=∑j=1Kezjezm×∑j=1Kezj∑j=1Kezj−ezm=∑j=1Kezjezm×(1−∑j=1Kezjezm)=pm(1−pm)
② 当 k ≠ m k\neq m k=m时, p k = e z k / ∑ j = 1 K e z j p_k=e^{z_k}/\sum_{j=1}^{K}e^{z_j} pk=ezk/∑j=1Kezj:
∂ p k ∂ z m = 0 ∗ ∑ j = 1 K e z j − e z k ∗ e z m ( ∑ j = 1 K e z j ) 2 = − e z k ∑ j = 1 K e z j × e z m ∑ j = 1 K e z j = − p k p m \begin{align*} \frac{\partial p_k}{\partial z_m} &= \frac{0*\sum_{j=1}^{K}e^{z_j}-e^{z_k}*e^{z_m}}{(\sum_{j=1}^{K}e^{z_j})^2} \\ &= -\frac{e^{z_k}}{\sum_{j=1}^{K}e^{z_j}} \times \frac{e^{z_m}}{\sum_{j=1}^{K}e^{z_j}} \\ &= -p_kp_m \end{align*} ∂zm∂pk=(∑j=1Kezj)20∗∑j=1Kezj−ezk∗ezm=−∑j=1Kezjezk×∑j=1Kezjezm=−pkpm
即,Softmax的偏导数为:
∂ p k ∂ z m = { p m ( 1 − p m ) if k = m − p k p m if k ≠ m \frac{\partial p_k}{\partial z_m} = \begin{cases} p_m(1 - p_m) & \text{if } k = m \\ -p_kp_m & \text{if } k \neq m \end{cases} ∂zm∂pk={pm(1−pm)−pkpmif k=mif k=m
将Softmax的偏导数带入上式:
∂ H ∂ z m = − ∂ p m ∂ z m ( log p m + 1 ) − ∑ k = 1 , k ≠ m K ∂ p k ∂ z m ( log p k + 1 ) , 第一项 k = m ,第二项 k ≠ m = − [ p m ( 1 − p m ) ( log p m + 1 ) + ∑ k = 1 , k ≠ m K ( − p k p m ) ( log p k + 1 ) ] = − p m [ ( 1 − p m ) ( log p m + 1 ) − ∑ k = 1 , k ≠ m K p k ( log p k + 1 ) ] = − p m [ log p m + 1 − p m log p m − p m − ∑ k = 1 , k ≠ m K p k log p k − ∑ k = 1 , k ≠ m K p k ] = − p m [ log p m + 1 − ∑ k = 1 K p k log p k − ∑ k = 1 K p k ] , 其中 ∑ k = 1 K p k = 1 = − p m ( log p m − ∑ k = 1 K p k log p k ) = − p m ( log p m + H ) \begin{align*} \frac{\partial H}{\partial z_m} &= -\frac{\partial p_m}{\partial z_m} \left(\log p_m + 1 \right)-\sum_{k=1,k\neq m}^K \frac{\partial p_k}{\partial z_m} \left(\log p_k + 1 \right) \text{, 第一项$k=m$,第二项$k\neq m$} \\ &= -\left[p_m(1-p_m)(\log p_m+1) + \sum_{k=1,k\neq m}^K (-p_kp_m)(\log p_k+1) \right] \\ &= -p_m\left[(1-p_m)(\log p_m+1) - \sum_{k=1,k\neq m}^K p_k(\log p_k+1) \right] \\ &= -p_m\left[\log p_m+1-p_m\log p_m-p_m - \sum_{k=1,k\neq m}^K p_k\log p_k-\sum_{k=1,k\neq m}^K p_k \right] \\ &= -p_m\left[\log p_m+1 - \sum_{k=1}^K p_k\log p_k-\sum_{k=1}^K p_k \right] \text{, 其中$\sum_{k=1}^K p_k=1$}\\ &= -p_m\left(\log p_m - \sum_{k=1}^K p_k\log p_k \right) \\ &= -p_m\left(\log p_m + H \right) \\ \end{align*} ∂zm∂H=−∂zm∂pm(logpm+1)−k=1,k=m∑K∂zm∂pk(logpk+1), 第一项k=m,第二项k=m=− pm(1−pm)(logpm+1)+k=1,k=m∑K(−pkpm)(logpk+1) =−pm (1−pm)(logpm+1)−k=1,k=m∑Kpk(logpk+1) =−pm logpm+1−pmlogpm−pm−k=1,k=m∑Kpklogpk−k=1,k=m∑Kpk =−pm[logpm+1−k=1∑Kpklogpk−k=1∑Kpk], 其中∑k=1Kpk=1=−pm(logpm−k=1∑Kpklogpk)=−pm(logpm+H)
即,
∂ H ∂ z m = − p m ( log p m + H ) \boxed{\frac{\partial H}{\partial z_m} = -p_m\left(\log p_m + H \right) } ∂zm∂H=−pm(logpm+H)
参数更新:
z m : = z m − η ∗ ∂ H ∂ z m = z m + η ∗ p m ( log p m + H ) \boxed{z_m:=z_m-\eta*\frac{\partial H}{\partial z_m}=z_m+\eta*p_m(\log p_m + H)} zm:=zm−η∗∂zm∂H=zm+η∗pm(logpm+H)
- 当模型预测的确定性很大(概率值大、熵很小),即 ( log p m + H ) → 0 (\log p_m+H)\rightarrow 0 (logpm+H)→0,则梯度很小,参数 z m z_m zm微调(更新幅度小)。
- 当模型预测的确定性很小(概率值小、熵很大),即 ( log p m + H ) > 0 (\log p_m+H)> 0 (logpm+H)>0,则梯度较大,增大模型预测输出 z m z_m zm的数值,以提升预测的确定性。
3. 案例理解
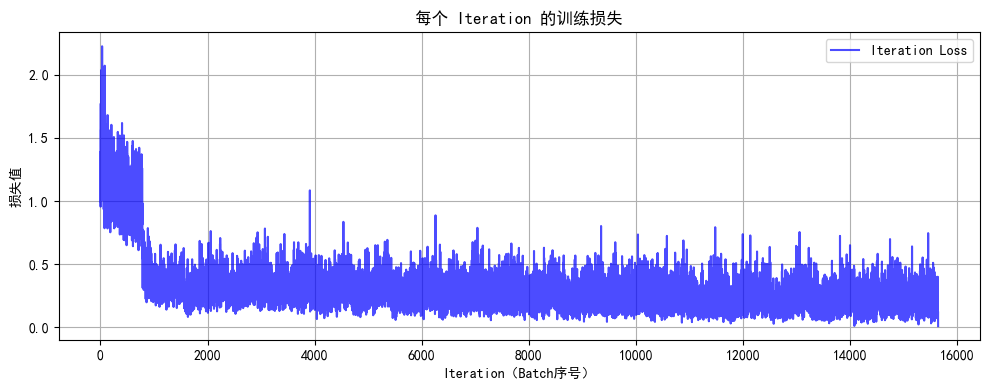
下面采用一个简单的案例,观察熵最小化对参数更新的影响。
import numpy as np
import matplotlib.pyplot as plteta = 0.5 # 学习率
n_iter = 20 # 增加迭代次数
z = np.array([1.0, 0.8, 0.5], dtype=np.float32) # 初始logits# 存储历史记录
history = {'z': [z.copy()], 'p': [], 'entropy': [], 'max_prob': []}for i in range(n_iter):# 计算梯度:dH/dzz_exp = np.exp(z)p = z_exp / z_exp.sum()log_p = np.log(p + 1e-8)H = -np.sum(p * log_p)grad_z = -p * (log_p + H)# 更新:z = z - eta*grad_zz = z - eta * grad_z# 记录历史history['z'].append(z.copy())history['p'].append(p.copy())history['entropy'].append(H)history['max_prob'].append(p.max())# 可视化结果
plt.figure(figsize=(15, 10))# 1. 概率变化
plt.subplot(2, 2, 1)
for i in range(3):probs = [p[i] for p in history['p']] # plt.plot(probs, label=f'Class {i+1}')
plt.title('Class Probabilities')
plt.xlabel('Epoch')
plt.ylabel('Probability')
plt.legend()
plt.grid(True)# 2. 熵变化
plt.subplot(2, 2, 2)
plt.plot(history['entropy'], color='r')
plt.title('Entropy Minimization')
plt.xlabel('Epoch')
plt.ylabel('H(p)')
plt.grid(True)# 3. 最大概率变化
plt.subplot(2, 2, 3)
plt.plot(history['max_prob'])
plt.title('Max Probability')
plt.xlabel('Epoch')
plt.ylabel('max(p)')
plt.grid(True)# 4. Logits变化
plt.subplot(2, 2, 4)
for i in range(3):logits = [z[i] for z in history['z'][:-1]]plt.plot(logits, label=f'z_{i+1}')
plt.title('Logits Evolution')
plt.xlabel('Epoch')
plt.ylabel('Logit Value')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()
结果:

4. 总结
- 熵最小化,迫使主导类的概率进一步增大,次要类概率进一步降低,进而降低模型的预测不确定性;
- 在无监督DA中,熵最小化使模型对未标记样本的预测变得更加确定,从而实现了降低预测熵的目的;
- 相反,如果我们想增大模型预测的不确定性,提升多样性,就可以最大化熵。
进一步学习:
- Grandvalet, Yves, and Yoshua Bengio. “Semi-supervised learning by entropy minimization.” Advances in neural information processing systems 17 (2004).
- Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I Jordan. Unsupervised domain adaptation with residual transfer networks. In Advances in Neural Information Processing Systems, pages 136–144, 2016.
- Zhang, Jing, et al. “Importance weighted adversarial nets for partial domain adaptation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
- Zhang, Yabin, et al. “Domain-symmetric networks for adversarial domain adaptation.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
- Wu, Xiaofu, et al. “Entropy minimization vs. diversity maximization for domain adaptation.” arXiv preprint arXiv:2002.01690 (2020).
参考:
[1] Softmax函数 - 维基百科,自由的百科全书
[2] 熵 (信息论) - 维基百科,自由的百科全书
[3] 熵正则(pytorch实现)_熵正则化-CSDN博客
[4] 熵正则化(entropy regularization) - 知乎
[5] 推导一下最小化信息熵的作用 - 没有名字啊的文章 - 知乎