Vector类第4版:散列和快速等值测试
我们要再次实现__hash__ 方法。加上现有的__eq__ 方法,这会把
Vector 实例变成可散列的对象。
示例 9-8 中的__hash__ 方法简单地计算 hash(self.x) ^
hash(self.y)。这一次,我们要使用^(异或)运算符依次计算各个分
量的散列值,像这样:v[0] ^ v[1] ^ v[2]…。这正是
functools.reduce 函数的作用。之前我说 reduce 没有以往那么常
用, 但是计算向量所有分量的散列值非常适合使用这个函数。reduce
函数的整体思路如图 10-1 所示。
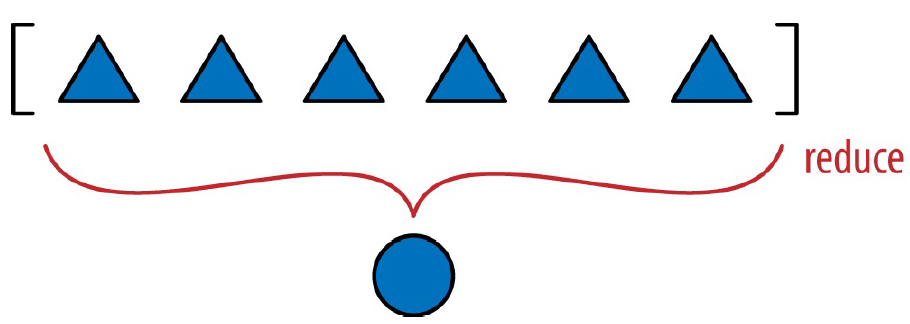
我们已经知道 functools.reduce() 可以替换成 sum(),下面说说它
的原理。它的关键思想是,把一系列值归约成单个值。reduce() 函数
的第一个参数是接受两个参数的函数,第二个参数是一个可迭代的对
象。假如有个接受两个参数的 fn 函数和一个 lst 列表。调用
reduce(fn, lst) 时,fn 会应用到第一对元素上,即 fn(lst[0],
lst[1]),生成第一个结果 r1。然后,fn 会应用到 r1 和下一个元素上,即 fn(r1, lst[2]),生成第二个结果 r2。接着,调用 fn(r2,
lst[3]),生成 r3……直到最后一个元素,返回最后得到的结果 rN。
使用 reduce 函数可以计算 5!(5 的阶乘):
>>> 2 * 3 * 4 * 5 # 想要的结果是:5! == 120
120
>>> import functools
>>> functools.reduce(lambda a,b: a*b, range(1, 6))
120
回到散列问题上。示例 10-11 展示了计算聚合异或的 3 种方式:一种使
用 for 循环,两种使用 reduce 函数。
示例 10-11 计算整数 0~5 的累计异或的 3 种方式
>>> n = 0
>>> for i in range(1, 6): # ➊
... n ^= i
...
>>> n
1 >>> import functools
>>> functools.reduce(lambda a, b: a^b, range(6)) # ➋
1 >>> import operator
>>> functools.reduce(operator.xor, range(6)) # ➌
1
❶ 使用 for 循环和累加器变量计算聚合异或。
❷ 使用 functools.reduce 函数,传入匿名函数。
❸ 使用 functools.reduce 函数,把 lambda 表达式换成
operator.xor。
示例 10-11 中的 3 种方式里,我最喜欢最后一种,其次是 for 循环。你
呢?
5.10.1 节讲过,operator 模块以函数的形式提供了 Python 的全部中缀
运算符,从而减少使用 lambda 表达式。
为了使用我喜欢的方式编写Vector.__hash__方法,我们要导入
functools 和 operator 模块。Vector 类的相关变化如示例 10-12 所
示。
示例 10-12 vector_v4.py 的部分代码:在 vector_v3.py 中 Vector
类的基础上导入两个模块,添加__hash__ 方法
from array import array
import reprlib
import math
import functools # ➊
import operator # ➋
class Vector:typecode = 'd'# 排版需要,省略了很多行...def __eq__(self, other): # ➌return tuple(self) == tuple(other)def __hash__(self):hashes = (hash(x) for x in self._components) # ➍return functools.reduce(operator.xor, hashes, 0) # ➎
# 省略了很多行...
❶ 为了使用 reduce 函数,导入 functools 模块。
❷ 为了使用 xor 函数,导入 operator 模块。
❸ __eq__ 方法没变;我把它列出来是为了把它和 __hash__ 方法放在
一起,因为它们要结合在一起使用。
❹ 创建一个生成器表达式,惰性计算各个分量的散列值。
❺ 把 hashes 提供给 reduce 函数,使用 xor 函数计算聚合的散列值;
第三个参数,0 是初始值(参见下面的警告框)。
使用 reduce 函数时最好提供第三个参
数,reduce(function, iterable, initializer),这样能避
免这个异常:TypeError: reduce() of empty sequence with
no initial value(这个错误消息很棒,说明了问题,还提供了
解决方法)。如果序列为空,initializer 是返回的结果;否
则,在归约中使用它作为第一个参数,因此应该使用恒等值。比
如,对 +、| 和 ^ 来说, initializer 应该是 0;而对 * 和 & 来
说,应该是 1。
示例 10-12 中实现的__hash__方法是一种映射归约计算(见图 10-
2)。
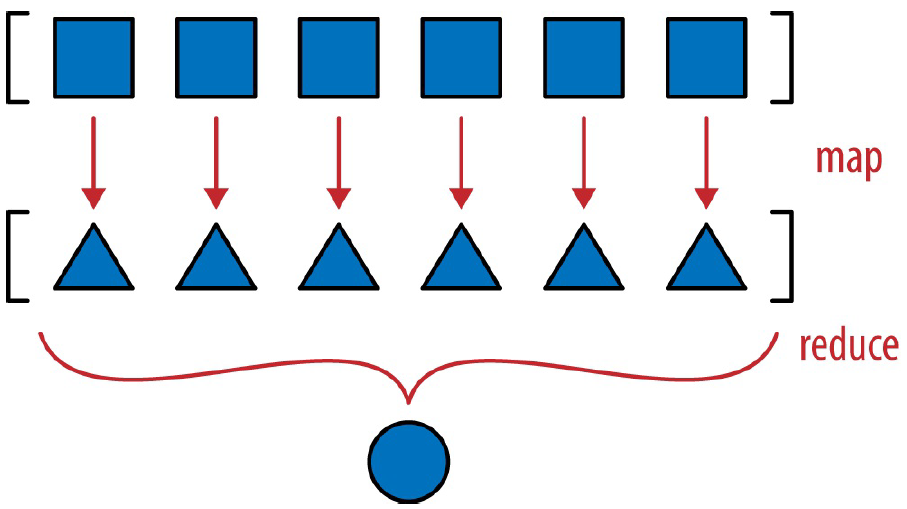
映射过程计算各个分量的散列值,归约过程则使用 xor 运算符聚合所有
散列值。把生成器表达式替换成 map 方法,映射过程更明显:
def __hash__(self):hashes = map(hash, self._components)return functools.reduce(operator.xor, hashes)
在 Python 2 中使用 map 函数效率低些,因为 map 函数要使用
结果构建一个列表。但是在 Python 3 中,map 函数是惰性的,它会
创建一个生成器,按需产出结果,因此能节省内存——这与示例
10-12 中使用生成器表达式定义__hash__方法的原理一样。
既然讲到了归约函数,那就把前面草草实现的 __eq__ 方法修改一下,
减少处理时间和内存用量——至少对大型向量来说是这样。如示例 9-2
所示,__eq__ 方法的实现可以非常简洁:
def __eq__(self, other):return tuple(self) == tuple(other)
Vector2d 和 Vector 都可以这样做,它甚至还会认为 Vector([1,
2]) 和 (1, 2) 相等。这或许是个问题,不过我们暂且忽略。 可是,
这样做对有几千个分量的 Vector 实例来说,效率十分低下。上述实现
方式要完整复制两个操作数,构建两个元组,而这么做只是为了使用
tuple 类型的__eq__方法。对 Vector2d(只有两个分量)来说,这
是个捷径,但是对维数很多的向量来说情况就不同了。示例 10-13 中比
较两个 Vector 实例(或者比较一个 Vector 实例与一个可迭代对象)
的方式更好。
示例 10-13 为了提高比较的效率,Vector.__eq__ 方法在 for
循环中使用 zip 函数
def __eq__(self, other):if len(self) != len(other): # ➊return Falsefor a, b in zip(self, other): # ➋if a != b: # ➌return Falsereturn True # ➍
❶ 如果两个对象的长度不一样,那么它们不相等。
❷ zip 函数生成一个由元组构成的生成器,元组中的元素来自参数传入
的各个可迭代对象。如果不熟悉 zip 函数,请阅读“出色的 zip 函数”附
注栏。前面比较长度的测试是有必要的,因为一旦有一个输入耗
尽,zip 函数会立即停止生成值,而且不发出警告。
❸ 只要有两个分量不同,返回 False,退出。
❹ 否则,对象是相等的。
示例 10-13 的效率很好,不过用于计算聚合值的整个 for 循环可以替换
成一行 all 函数调用:如果所有分量对的比较结果都是 True,那么结
果就是 True。只要有一次比较的结果是 False,all 函数就返回
False。使用 all 函数实现 __eq__ 方法的方式如示例 10-14 所示。
示例 10-14 使用 zip 和 all 函数实现 Vector.__eq__ 方法,逻
辑与示例 10-13 一样
def __eq__(self, other):return len(self) == len(other) and all(a == b for a, b in zip(self, other)
注意,首先要检查两个操作数的长度是否相同,因为 zip 函数会在最短
的那个操作数耗尽时停止。
我们选择在 vector_v4.py 中采用示例 10-14 中实现的__eq__方法。
本章最后要像 Vector2d 类那样,为 Vector 类实现__format__方
法。
出色的 zip 函数
使用 for 循环迭代元素不用处理索引变量,还能避免很多缺陷,但
是需要一些特殊的实用函数协助。其中一个是内置的 zip 函数。使
用 zip 函数能轻松地并行迭代两个或更多可迭代对象,它返回的元
组可以拆包成变量,分别对应各个并行输入中的一个元素。如示例
10-15 所示。
使用 for 循环迭代元素不用处理索引变量,还能避免很多缺陷,但
是需要一些特殊的实用函数协助。其中一个是内置的 zip 函数。使
用 zip 函数能轻松地并行迭代两个或更多可迭代对象,它返回的元
组可以拆包成变量,分别对应各个并行输入中的一个元素。如示例
10-15 所示。
zip 函数的名字取自拉链系结物(zipper fastener),因为
这个物品用于把两个拉链边的链牙咬合在一起,这形象地说明
了 zip(left, right) 的作用。zip 函数与文件压缩没有关
系。
示例 10-15 zip 内置函数的使用示例
>>> zip(range(3), 'ABC') # ➊
<zip object at 0x10063ae48>
>>> list(zip(range(3), 'ABC')) # ➋
[(0, 'A'), (1, 'B'), (2, 'C')]
>>> list(zip(range(3), 'ABC', [0.0, 1.1, 2.2, 3.3])) # ➌
[(0, 'A', 0.0), (1, 'B', 1.1), (2, 'C', 2.2)]
>>> from itertools import zip_longest # ➍
>>> list(zip_longest(range(3), 'ABC', [0.0, 1.1, 2.2, 3.3], fillvalue=-1))
[(0, 'A', 0.0), (1, 'B', 1.1), (2, 'C', 2.2), (-1, -1, 3.3)]
❶ zip 函数返回一个生成器,按需生成元组。
❷ 为了输出,构建一个列表;通常,我们会迭代生成器。
❸ zip 有个奇怪的特性:当一个可迭代对象耗尽后,它不发出警告
就停止。
❹ itertools.zip_longest 函数的行为有所不同:使用可选的
fillvalue(默认值为 None)填充缺失的值,因此可以继续产
出,直到最长的可迭代对象耗尽。
为了避免在 for 循环中手动处理索引变量,还经常使用内置的
enumerate 生成器函数。如果你不熟悉 enumerate 函数,一定要
阅读“Build-in Functions”文档
(https://docs.python.org/3/library/functions.html#enumerate)。内置的
zip 和 enumerate 函数,以及标准库中其他几个生成器函数在
14.9 节讨论。