在分布式系统中,Redis 凭借高性能和高并发处理能力,成为常用的缓存组件。然而,在实际应用中,缓存穿透、缓存击穿、缓存雪崩这三大问题会严重影响系统的性能与稳定性。本文将详细解析这三个问题的成因,并提供对应的解决方案,同时结合 Java 示例代码和图示帮助你更好地理解和实践。
一、缓存穿透
1. 问题描述
缓存穿透指的是大量请求访问 Redis 缓存中不存在的数据,导致请求直接穿透到数据库,给数据库带来巨大压力。例如,黑客恶意构造大量不存在的商品 ID 请求,每次请求都无法命中缓存,只能查询数据库,可能导致数据库被压垮。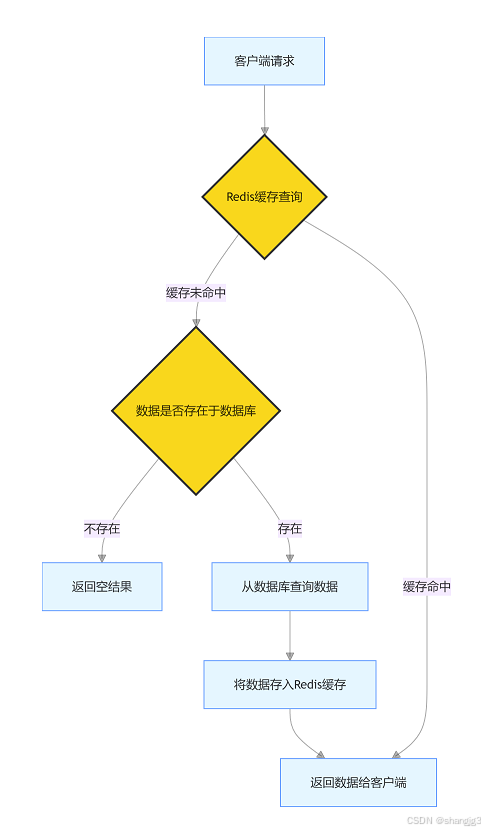
图中展示了缓存穿透的过程,大量不存在的请求绕过 Redis 缓存,直接访问数据库。
2. 成因分析
- 恶意攻击:攻击者故意发送不存在的键值请求,使缓存无法命中。
- 业务逻辑漏洞:应用程序未对请求参数进行有效校验,导致不合理的查询进入缓存层。
3. 解决方案
(1)布隆过滤器
布隆过滤器是一种概率型数据结构,用于判断某个元素是否存在于集合中。它可以在请求进入 Redis 之前,快速判断数据是否存在,若不存在则直接返回,避免请求穿透到数据库。
示例代码(基于 Google Guava 库):
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import redis.clients.jedis.Jedis;
public class BloomFilterDemo {
private static final int EXPECTED_ELEMENTS = 10000; // 预计元素数量
private static final double FALSE_POSITIVE_RATE = 0.01; // 误判率
private static final BloomFilter<Integer> bloomFilter = BloomFilter.create(
Funnels.integerFunnel(), EXPECTED_ELEMENTS, FALSE_POSITIVE_RATE);
static {
// 初始化布隆过滤器,假设数据库中存在的商品ID为1 - 10000
for (int i = 1; i <= EXPECTED_ELEMENTS; i++) {
bloomFilter.put(i);
}
}
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
int productId = 10001; // 假设不存在的商品ID
if (!bloomFilter.mightContain(productId)) {
System.out.println("数据大概率不存在,直接返回");
return;
}
// 从Redis查询数据
String cacheValue = jedis.get("product:" + productId);
if (cacheValue == null) {
// 缓存未命中,查询数据库(此处省略数据库查询逻辑)
String dbValue = "模拟从数据库查询到的值";
if (dbValue != null) {
// 将数据存入Redis
jedis.set("product:" + productId, dbValue);
} else {
// 数据库也不存在,设置一个空值缓存,避免后续重复查询数据库
jedis.setex("product:" + productId, 60, "");
}
} else {
System.out.println("缓存命中,返回数据");
}
}
}
(2)缓存空对象
当数据库查询结果为空时,也将空值存入 Redis 缓存,并设置较短的过期时间。后续相同请求可直接命中缓存,避免穿透到数据库。
import redis.clients.jedis.Jedis;
public class CacheNullObjectDemo {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
int productId = 10001; // 假设不存在的商品ID
// 从Redis查询数据
String cacheValue = jedis.get("product:" + productId);
if (cacheValue == null) {
// 缓存未命中,查询数据库(此处省略数据库查询逻辑)
String dbValue = null;
if (dbValue != null) {
// 将数据存入Redis
jedis.set("product:" + productId, dbValue);
} else {
// 数据库也不存在,设置一个空值缓存,避免后续重复查询数据库
jedis.setex("product:" + productId, 60, "");
System.out.println("数据库中不存在该数据,已设置空值缓存");
}
} else {
if (cacheValue.equals("")) {
System.out.println("缓存命中空值,数据不存在");
} else {
System.out.println("缓存命中,返回数据");
}
}
}
}
二、缓存击穿
1. 问题描述
缓存击穿指的是某个热点数据(如热门商品信息、高访问量接口数据)的缓存过期瞬间,大量并发请求同时访问该数据,导致请求直接落到数据库,造成数据库压力瞬间增大。
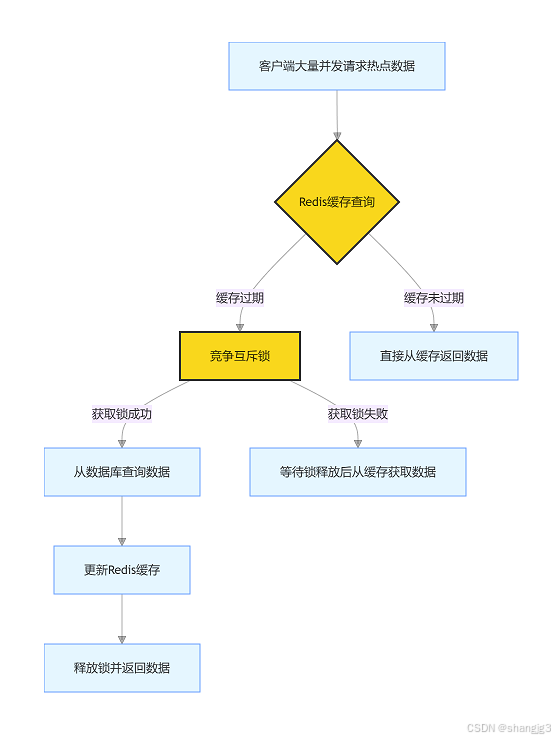
图中展示了缓存击穿的场景,热点数据缓存过期时,大量请求同时访问数据库。
2. 成因分析
- 缓存过期时间集中:热点数据的缓存过期时间设置不合理,同时到期。
- 高并发访问:大量用户同时请求同一热点数据。
3. 解决方案
(1)互斥锁
在缓存过期时,只允许一个线程去查询数据库并更新缓存,其他线程等待该线程更新完成后,直接从缓存获取数据。
示例代码:
import redis.clients.jedis.Jedis;
import java.util.concurrent.locks.ReentrantLock;
public class CacheBreakdownMutexDemo {
private static final ReentrantLock lock = new ReentrantLock();
private static final int CACHE_EXPIRE_TIME = 60; // 缓存过期时间,单位:秒
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
int productId = 1; // 假设热门商品ID
// 从Redis查询数据
String cacheValue = jedis.get("product:" + productId);
if (cacheValue == null) {
lock.lock();
try {
// 再次检查缓存,避免多个线程重复查询数据库
cacheValue = jedis.get("product:" + productId);
if (cacheValue == null) {
// 缓存未命中,查询数据库(此处省略数据库查询逻辑)
String dbValue = "模拟从数据库查询到的热门商品数据";
if (dbValue != null) {
// 将数据存入Redis
jedis.setex("product:" + productId, CACHE_EXPIRE_TIME, dbValue);
System.out.println("缓存更新成功");
}
}
} finally {
lock.unlock();
}
} else {
System.out.println("缓存命中,返回数据");
}
}
}
(2)逻辑过期
给缓存数据设置一个逻辑过期时间,当缓存数据即将过期时,后台异步线程提前更新缓存,避免大量请求直接访问数据库。
import redis.clients.jedis.Jedis;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class CacheBreakdownLogicExpireDemo {
private static final int CACHE_EXPIRE_TIME = 60; // 缓存过期时间,单位:秒
private static final int LOGIC_EXPIRE_TIME = 5; // 逻辑过期时间,单位:秒
private static final ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
int productId = 1; // 假设热门商品ID
// 从Redis查询数据
String cacheValue = jedis.get("product:" + productId);
if (cacheValue == null) {
// 缓存未命中,查询数据库(此处省略数据库查询逻辑)
String dbValue = "模拟从数据库查询到的热门商品数据";
if (dbValue != null) {
// 设置逻辑过期时间和缓存数据
jedis.setex("product:" + productId, CACHE_EXPIRE_TIME, dbValue);
jedis.setex("product:" + productId + ":expire", LOGIC_EXPIRE_TIME, "1");
// 启动异步线程更新缓存
executorService.schedule(() -> {
String newDbValue = "模拟从数据库查询到的最新热门商品数据";
if (newDbValue != null) {
jedis.setex("product:" + productId, CACHE_EXPIRE_TIME, newDbValue);
jedis.setex("product:" + productId + ":expire", LOGIC_EXPIRE_TIME, "1");
System.out.println("缓存异步更新成功");
}
}, LOGIC_EXPIRE_TIME, TimeUnit.SECONDS);
System.out.println("缓存更新成功");
}
} else {
// 检查逻辑过期时间
String expireFlag = jedis.get("product:" + productId + ":expire");
if (expireFlag == null) {
System.out.println("缓存命中,返回数据");
} else {
// 逻辑过期,返回旧数据,等待异步线程更新
System.out.println("缓存逻辑过期,返回旧数据");
}
}
}
}
三、缓存雪崩
1. 问题描述
缓存雪崩是指由于 Redis 缓存中的大量数据同时过期或 Redis 服务宕机,导致大量请求直接落到数据库,造成数据库负载过高,甚至崩溃。
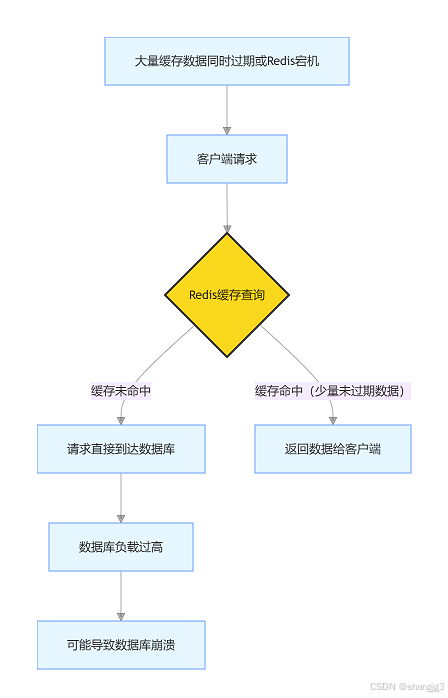
图中展示了缓存雪崩的情况,大量缓存数据同时失效,请求如潮水般涌向数据库。
2. 成因分析
- 缓存过期时间集中:大量缓存数据设置了相同或相近的过期时间,导致同时失效。
- Redis 故障:Redis 服务器发生故障,无法提供服务。
3. 解决方案
(1)均匀设置过期时间
在设置缓存过期时间时,添加一个随机时间偏移,避免大量数据同时过期。
示例代码:
import redis.clients.jedis.Jedis;
import java.util.Random;
public class CacheAvalancheRandomExpireDemo {
private static final int BASE_EXPIRE_TIME = 60; // 基础过期时间,单位:秒
private static final int RANDOM_OFFSET = 10; // 随机偏移时间,单位:秒
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
int productId = 1; // 假设商品ID
// 设置随机过期时间
int expireTime = BASE_EXPIRE_TIME + new Random().nextInt(RANDOM_OFFSET);
String data = "模拟商品数据";
jedis.setex("product:" + productId, expireTime, data);
System.out.println("缓存设置成功,过期时间:" + expireTime + "秒");
}
}
(2)多级缓存
采用本地缓存(如 Guava Cache、Caffeine)和 Redis 缓存相结合的方式。当 Redis 缓存失效时,先从本地缓存获取数据,减轻数据库压力。同时,可使用 Redis 集群提高缓存服务的可用性。
(3)服务熔断与降级
当数据库压力过大时,启用服务熔断机制,暂时拒绝部分请求;或者进行服务降级,返回默认数据或提示信息,保证核心服务的可用性。
四、总结
缓存穿透、缓存击穿和缓存雪崩是 Redis 应用中常见的性能问题,通过合理运用布隆过滤器、互斥锁、随机过期时间等技术手段,可以有效解决这些问题。在实际开发中,需要根据业务场景选择合适的解决方案,同时结合监控和预警机制,保障系统的稳定性和可靠性。


![[AI算法] 什么事RoPE scaling](https://i-blog.csdnimg.cn/direct/3734ec5e3a194c42b1fe0ab22d46ef7c.png)