文章目录
- Pre
- 1. 常用的性能测试工具
- 2. nmon —— 获取系统级性能数据
- 2.1 安装与启动
- 2.2 采样并生成报表
- 3. jvisualvm —— 获取 JVM 性能数据
- 3.1 启动与连接
- 3.2 CPU 分析(Sampler & Profiler)
- 3.3 内存监视与 Heap Dump
- 3.4 线程分析
- 4. JMC(Java Mission Control)与 JFR(Java Flight Recorder)
- 4.1 JFR 录制基本流程
- 4.2 JMC 可视化分析
- 5. Arthas —— 获取单个请求的调用链耗时
- 5.1 快速启动
- 5.2 常用命令示例:trace
- 5.2.1 使用示例
- 5.3 其他常见命令
- 6. wrk —— 获取 Web 接口的性能数据
- 6.1 安装与使用示例
- 6.2 Lua 脚本扩展
- 7. 小结

Pre
性能优化 - 理论篇:常见指标及切入点
性能优化 - 理论篇:性能优化的七类技术手段
性能优化 - 理论篇:CPU、内存、I/O诊断手段
1. 常用的性能测试工具
-
nmon:安装、启动方式、界面说明及生成报表流程;
-
jvisualvm:原理、远程监控配置、CPU/内存/线程三大采样功能;
-
JMC(Java Mission Control)和 JFR(Java Flight Recorder):录制方式、各功能面板(线程、内存、锁、I/O、JIT、GC、TLAB)说明;
-
Arthas:快速启动、常用命令(以 trace 为例)及调用链视图解析;
-
wrk:基本使用示例、主要指标含义及 Lua 脚本扩展;
2. nmon —— 获取系统级性能数据
在真正做性能测试或容量评估时,我们需要同时查看 CPU、内存、网络、磁盘、文件系统、NFS 等多种指标,才能获得系统全貌。nmon(Nigel’s Monitor)是一款老牌、功能全面的 Linux/Unix 性能监控工具,它能够:
- 直接在终端生成实时交互式面板;
- 记录若干采样周期内的原始指标数据,导出为
.nmon文件; - 配合
nmonchart等脚本,将.nmon数据转换为 HTML 可视化报表。
2.1 安装与启动
-
从 SourceForge 下载对应发行版的二进制可执行文件(例如:CentOS 7 上下载
nmon_x86_64_centos7)。 -
将其放到一台测试服务器(或性能评估节点)上,赋予可执行权限:
chmod +x nmon_x86_64_centos7 -
实时交互模式:直接运行
./nmon_x86_64_centos7,然后根据提示按下字母键。例如:C:加入 CPU 面板;M:加入内存面板;N:加入网络面板;D:加入磁盘面板;F:加入文件系统面板;Q:退出。
此时在终端会看到如下所示的实时数据面板 :
-------------------------------------------------------------------------------- Load Average: 0.25 0.30 0.15 CPU %%usr %%sys %%wait %%idle 00:00:05 up 5 days, 3:47, 3 users, load average: 0.25, 0.30, 0.15 Tasks: 98 total, 1 running, 97 sleeping, 0 stopped, 0 zombie %Cpu0 3.0 1.0 0.5 95.5 0.0 0.0 Net I/O: 250KB/s in, 100KB/s out Disk I/O: sda 100 read/s 200 write/s Mem 8GB total, 2GB free, 4GB used, 2GB buffer/cache Swap 1GB total, 1GB free, 0GB used ...(更多面板信息)... --------------------------------------------------------------------------------%%usr/%%sys/%%wait/%%idle等同于top中us/sy/wa/id。- 实时网络 I/O、磁盘 I/O、文件系统 I/O、NFS 活动等,都在一个界面中可见,便于连贯观察。
2.2 采样并生成报表
在性能测试时,往往需要在某段测试脚本或压测结束后,拿到“历史数据”与图表。nmon 可以把若干采样周期的数据保存到文件,便于后续离线分析。
-
采样命令格式:
./nmon_x86_64_centos7 -f -s <间隔秒数> -c <循环次数> -m <输出目录>-f:表示进入“采样模式”并生成文件,命名规则一般为<hostname>_<日期>_<时间>.nmon;-s 5:每 5 秒收集一次指标;-c 12:总共采集 12 次(即持续 12×5 = 60 秒);-m .:将输出的.nmon文件保存到当前目录。
例如:

./nmon_x86_64_centos7 -f -s 5 -c 12 -m .执行后,会在当前目录生成类似
localhost_210623_1633.nmon的文件。 -
生成 HTML 报表:
-
安装
nmonchart(一般是一个 Python 脚本或 Java 程序,仓库中提供可执行文件)。 -
运行:
nmonchart/./nmonchart localhost_210623_1633.nmon -
这一步会在同一目录下生成一个
localhost_210623_1633.html,打开后可见所有面板指标的折线图或条形图,按 CPU/内存/网络/磁盘等分类展示每秒(或每 5 秒)采样的结果。
-
-
报表示例说明:

- CPU 面板:展示每个逻辑核的使用率趋势,以及整体
user/sys/iowait/idle百分比随时间变化; - 内存面板:
free/used/buffer/cache随时间变化,以及 Swap 使用趋势; - 网络面板:每秒网卡的输入/输出带宽;
- 磁盘面板:每秒对各个设备的读/写 IOPS、吞吐量(MB/s)、队列长度、
%util等; - 进程面板:列出在采样期间 CPU 占用最高的 Top N 进程,以及内存占用 Top N;
- 文件系统面板:文件系统的挂载点、活动 I/O、可用空间等指标;
- NFS 面板:若存在 NFS 挂载,则显示 NFS 读写延迟和吞吐。
- CPU 面板:展示每个逻辑核的使用率趋势,以及整体
适用场景:在前端压测、后端接口测试阶段,可并行启动 nmon 采集。当压测脚本结束后,直接拿到 .nmon 文件并生成报表,观察系统在测试期间是否出现 CPU 饱和、I/O 过高、线程抖动等问题。
3. jvisualvm —— 获取 JVM 性能数据
jvisualvm 是 Oracle/OpenJDK 附带的可视化 JVM 诊断工具,后续版本被拆分为独立项目。它能连接到本地或远程 JVM 实例,获取以下几类关键监控与分析信息:
- CPU 分析(Profiler):基于采样(Sampling)或采集(Instrumented)两种模式,检测方法调用次数与耗时;
- 内存分析(Heap Dump & Heap Walker):可以在运行时获取堆快照(Heap Dump),分析对象数量、大小及引用链,挖掘内存泄漏;
- 线程监控(Thread Dump & Thread Grapher):实时监测线程状态(Runnable、Blocked、Waiting、Timed Waiting)、锁等待情况及死锁检测。
3.1 启动与连接
-
本地连接:在服务器或开发者机器上执行:
jvisualvm默认会扫描本地的所有 Java 进程,并列在左侧“本地”节点下。
-
远程连接:需要在被监控的 JVM 进程上加参数:
-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=14000 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false意味着:
- 开启 JMX 端口 14000;
- 关闭用户名/密码认证与 SSL;
- 从安全角度考虑,仅在测试环境使用;生产时应配合防火墙或加密认证。
-
在 jvisualvm 左侧“远程”节点,右键“添加远程主机”,填入 IP,然后在对应进程上右键“连接”,输入 JMX 端口即可。
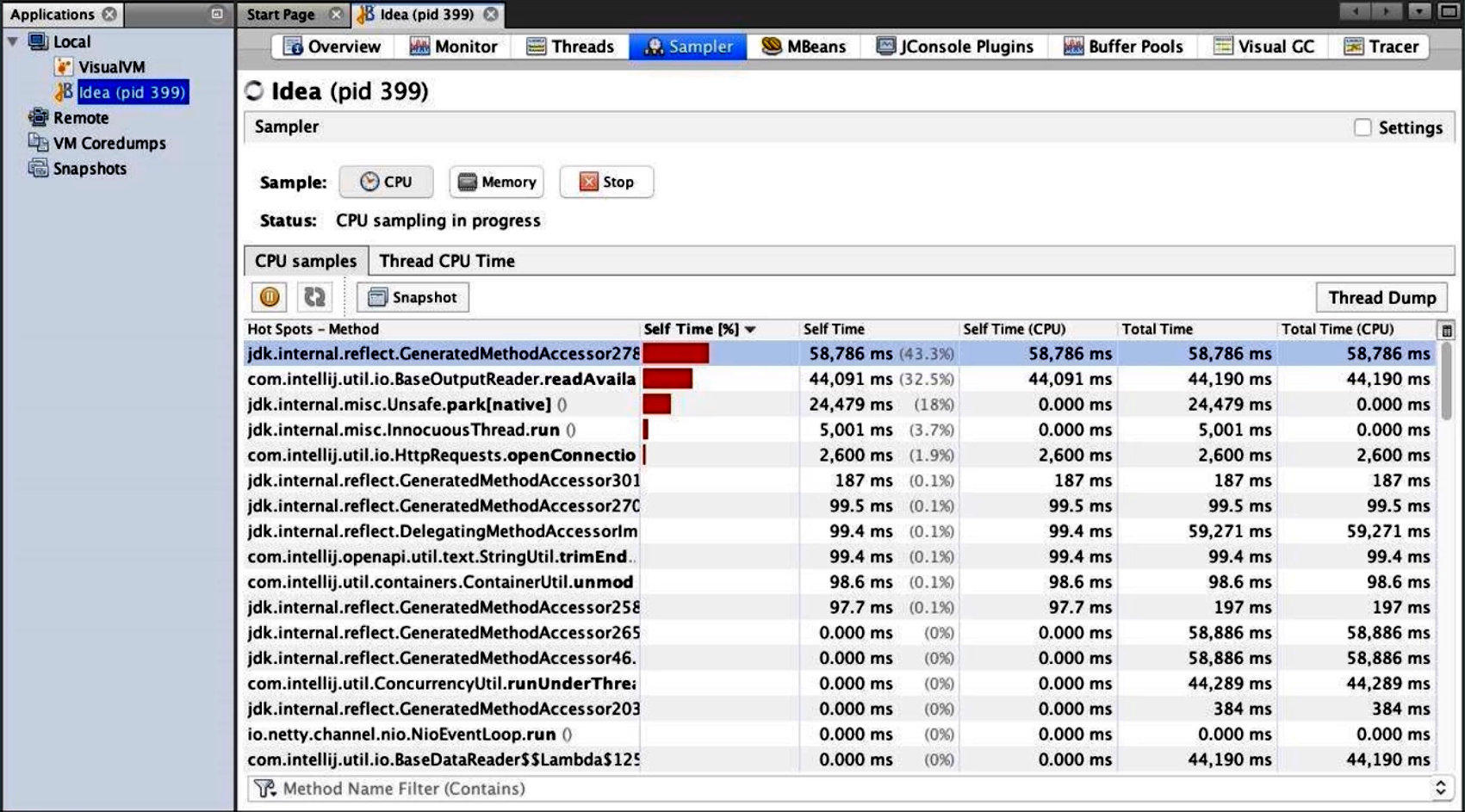
3.2 CPU 分析(Sampler & Profiler)
-
Sampler 模式:采样频率默认约 100 毫秒抓取一次当前调用栈,开销较小。
- 选择一个 Java 进程,点击“Sampler”选项卡;
- 点击“CPU”按钮开始采样,再运行一段典型业务负载;
- 停止采样后,查看“方法调用”排行榜,列出占用最久 CPU 时间的前 N 大方法,以及它们各自的调用比例。
-
Profiler 模式:基于插桩(Instrumentation)方式,会在字节码层面插入计时热点检测代码,精确度更高,但对应用影响更大,通常只在短时测试阶段使用。
示例说明(结合文字描述):
- 采样结果中会显示
com.example.Service.process()方法累计耗时 2.5s,占总 CPU 时间的 45%;- 如果某个方法存在过多短暂调用(如每次只耗时 0.01ms),采样器可能不一定捕获,但在 Profiler 模式下会被准确统计。
3.3 内存监视与 Heap Dump
-
在 jvisualvm 中,选中目标进程后,切换到“Monitor”选项卡,可以看到:
- 当前堆内存使用(Eden、Survivor、Old Generation)随时间的实时变化曲线;
- 堆外内存(Metaspace/PermGen)、线程数、Class 加载数等指标。
-
Heap Dump:点击“Heap Dump”按钮,工具会暂停应用若干毫秒并生成一个
.hprof文件。- 打开生成的
.hprof,切换到“Class”或“Histogram”视图,按实例数量或占用内存大小排序; - 找到占用过多内存的对象,比如
java.util.HashMap$Node[]占用了 200MB,此时就要回溯业务逻辑,看为何需要这么多缓存; - 在“Reference Tree”中查看对象引用链,分析 GC roots 到该对象之间的引用路径,迅速定位内存泄漏根源。
- 打开生成的
3.4 线程分析
- 在“Threads”选项卡,可以看到所有线程列表以及各自状态(Runnable/Blocked/Waiting/TimedWaiting);
- 点击某个线程,可查看它的调用栈快照和锁等待信息;如果出现死锁,会自动高亮标注涉及的线程与锁对象;
- 在“Thread Grapher”或“Thread Dump”面板,可导出
.tdr文件,用于离线分析线程状态演变情况。
注意:使用 jvisualvm 采样或 Profiler 会对应用性能有一定影响,建议在测试环境或压力较低的阶段使用,不要直接在生产高峰期打开长时间采样。
4. JMC(Java Mission Control)与 JFR(Java Flight Recorder)
对于 HotSpot JVM 而言,Java Mission Control(JMC) + Java Flight Recorder(JFR)是一套更轻量级、开销更低的内置诊断方案。它通过“内置事件采集”方式,持续记录各种运行时指标,然后在事后进行可视化分析。
4.1 JFR 录制基本流程
-
启动应用时即可开启(针对 Java 11+):
java -XX:StartFlightRecording=duration=1h,filename=app.jfr,settings=profile -jar app.jarduration=1h:表示录制 1 小时;filename=app.jfr:录制文件输出路径;settings=profile:使用“profile”(采样+方法热点)或“default”(只采集少量事件)等预设配置;
-
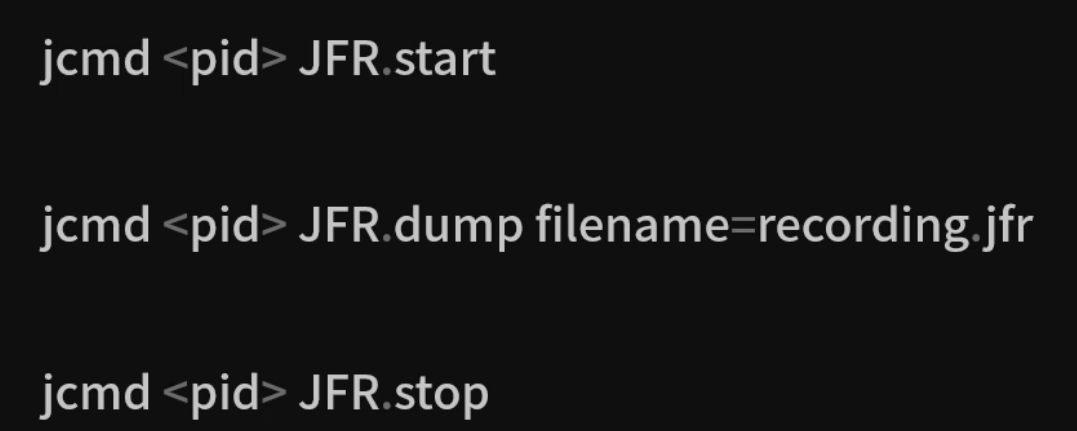
如果应用已在运行,可通过
jcmd动态开启/停止:jcmd <pid> JFR.start name=MyRecording settings=profile jcmd <pid> JFR.dump name=MyRecording filename=app.jfr jcmd <pid> JFR.stop name=MyRecordingJFR.start:开始录制,支持指定settings(profile、default)与事件阈值;JFR.dump:将当前缓冲区中的事件写入文件;JFR.stop:停止录制并清理内存。
录制完成后,会得到一个二进制的 .jfr 文件,包含从系统到 JVM 各层面的事件:
- 系统级事件:CPU 负载、上下文切换、I/O 等;
- JVM 级事件:GC 活动、内存使用、线程调度、锁争用、JIT 编译、类加载、异常抛出等;
- 方法热点采样:包括方法调用栈、方法执行耗时分布等。
4.2 JMC 可视化分析
启动 JMC(版本 7+ 推荐),通过“File → Open”打开 .jfr 文件后,可在左侧导航栏看到多个主要面板:
-
Overview(概览):
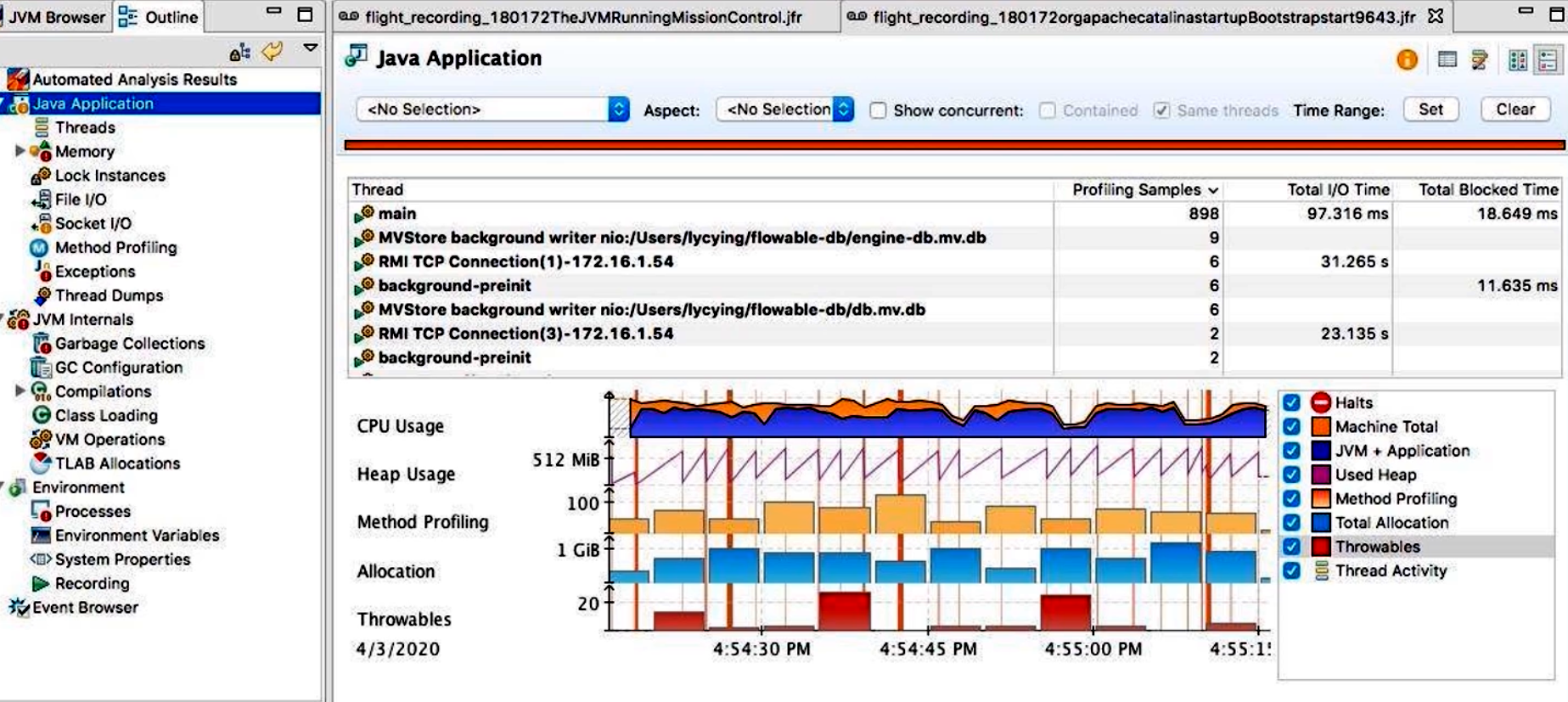
- 显示录制时间轴、总体 CPU/内存/GC 框架简况;
- 可快速定位“CPU 峰值”、“GC 峰值”等时间窗口。
-
Threads(线程):
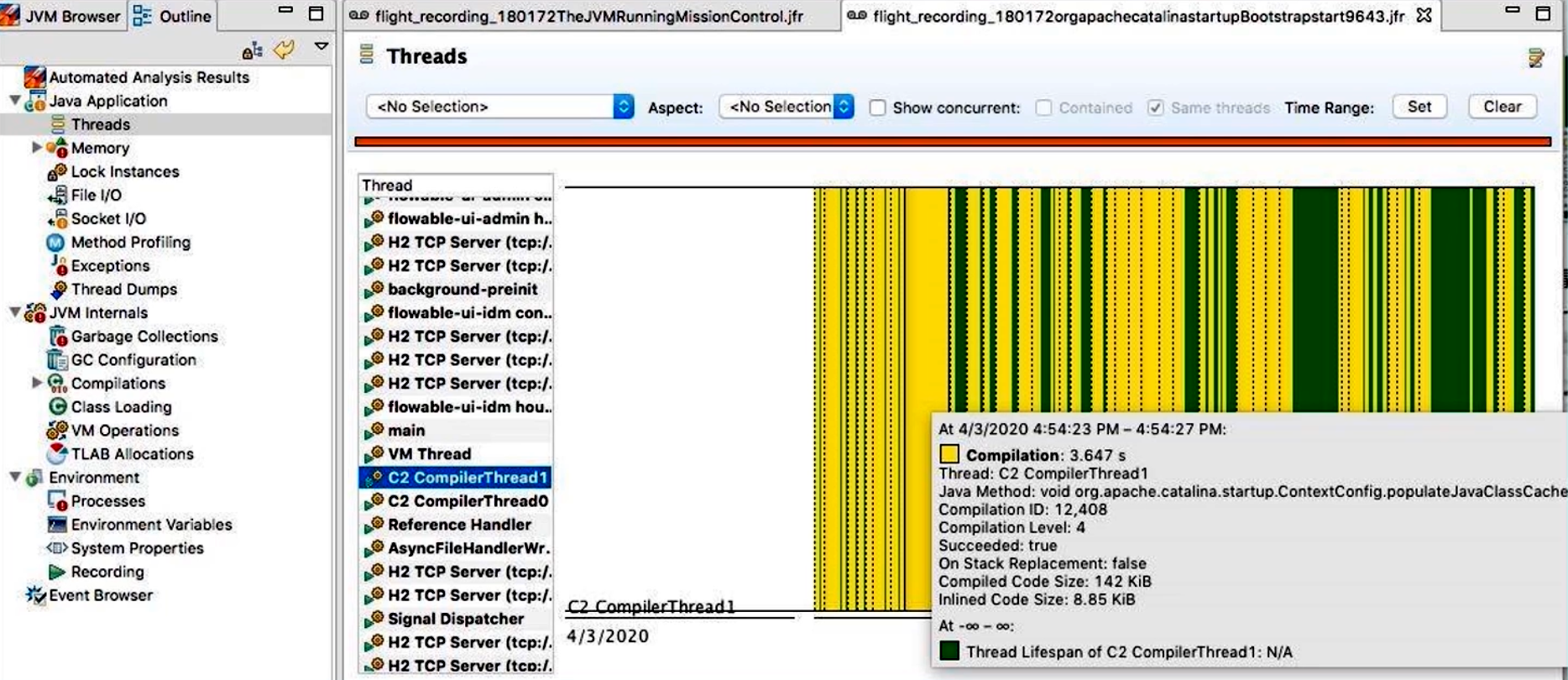
- 展示所有线程按照状态(Runnable、Blocked、Waiting、Timed Waiting)随时间的变化;
- 可以对某个时间点点击,查看活跃线程列表并导出线程快照;
- 对于 C2/JIT 编译线程(Compiler Threads),可以看到其执行了哪些内联、生成了哪些 CodeCache。
-
Memory(内存):
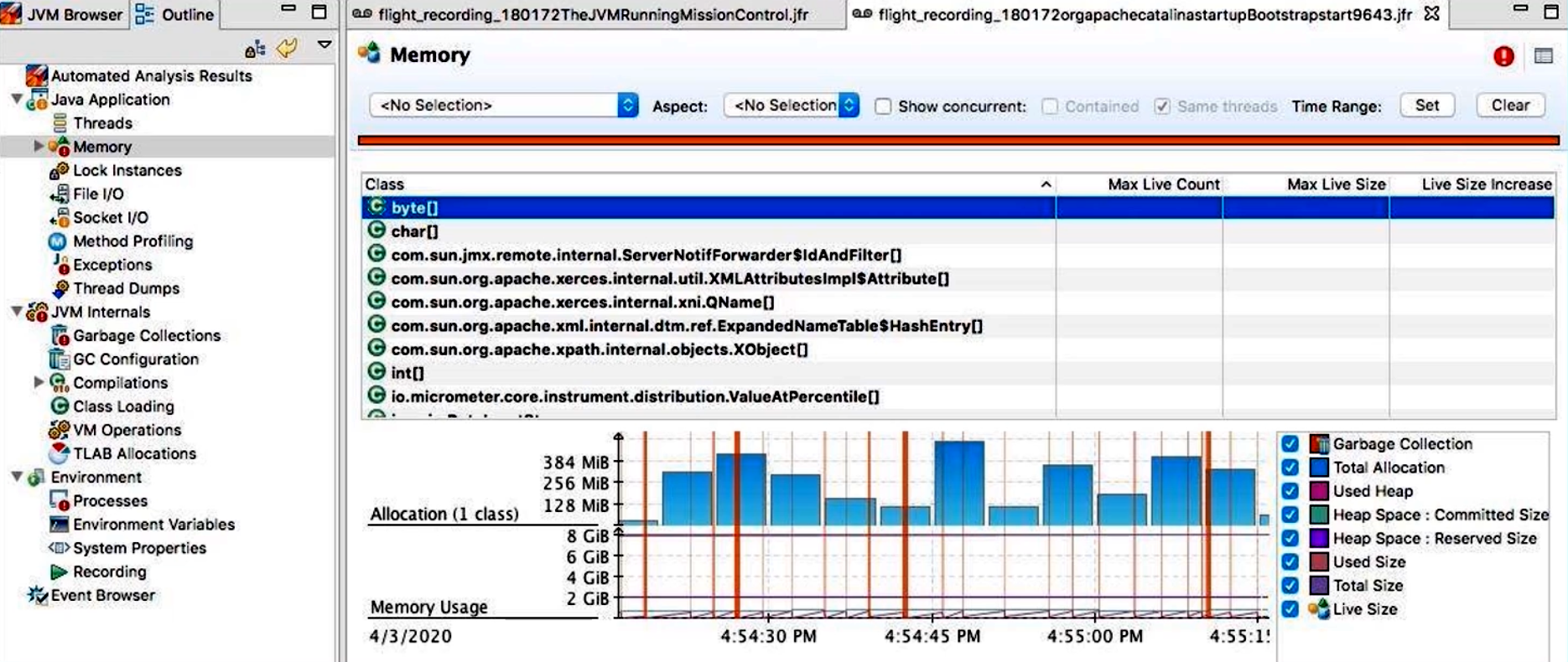
- 以堆图表形式展示 Eden、Survivor、Old、Metaspace 随时间的使用情况;
- “Heap Summary”可查看各代使用比例、各 GC 周期中回收了多少内存;
- “Object Statistics”可筛选某个类的创建与销毁次数、内存峰值。
-
Locks(锁):
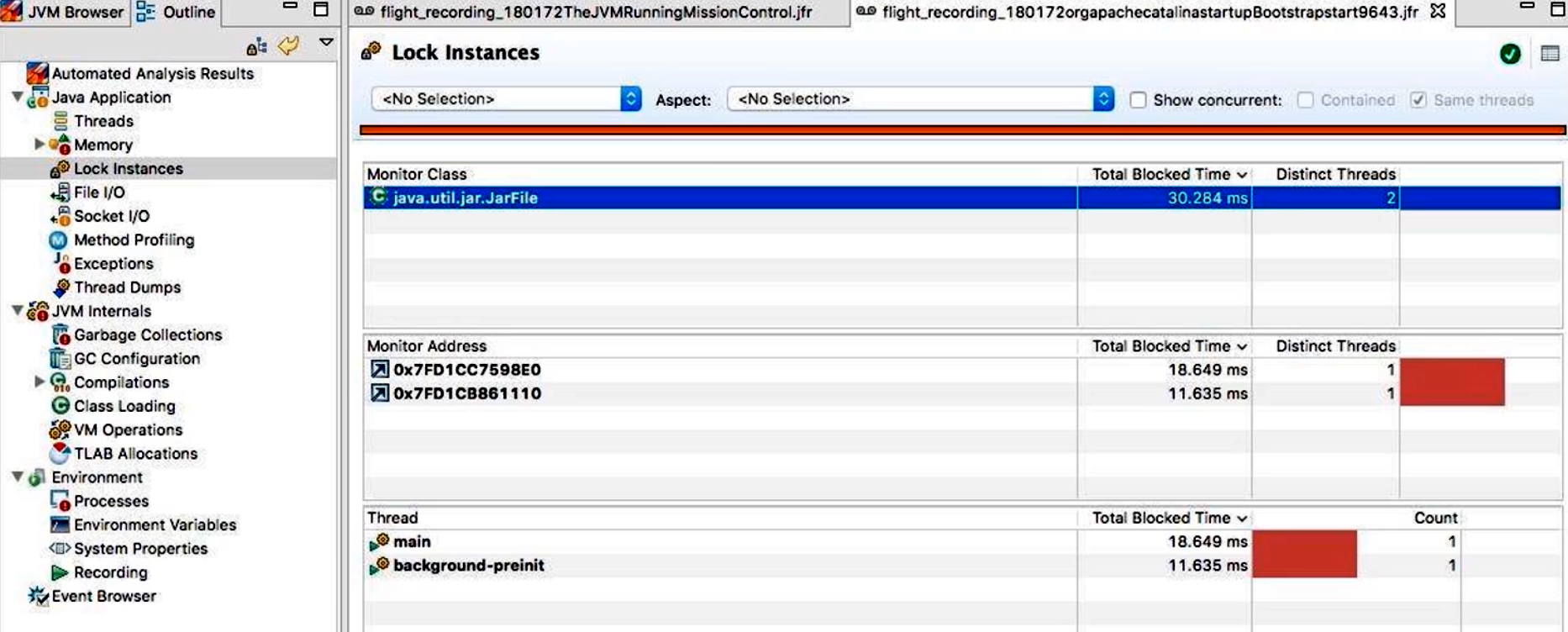
- 列出所有发生过竞争的锁对象,及其总等待时间和竞争次数;
- 可以根据“Lock Occupation”或“Lock Contention”排序,快速定位最热锁;
- 若出现死锁,会在此面板中直接高亮相关线程与锁 ID。
- I/O(文件和 Socket):
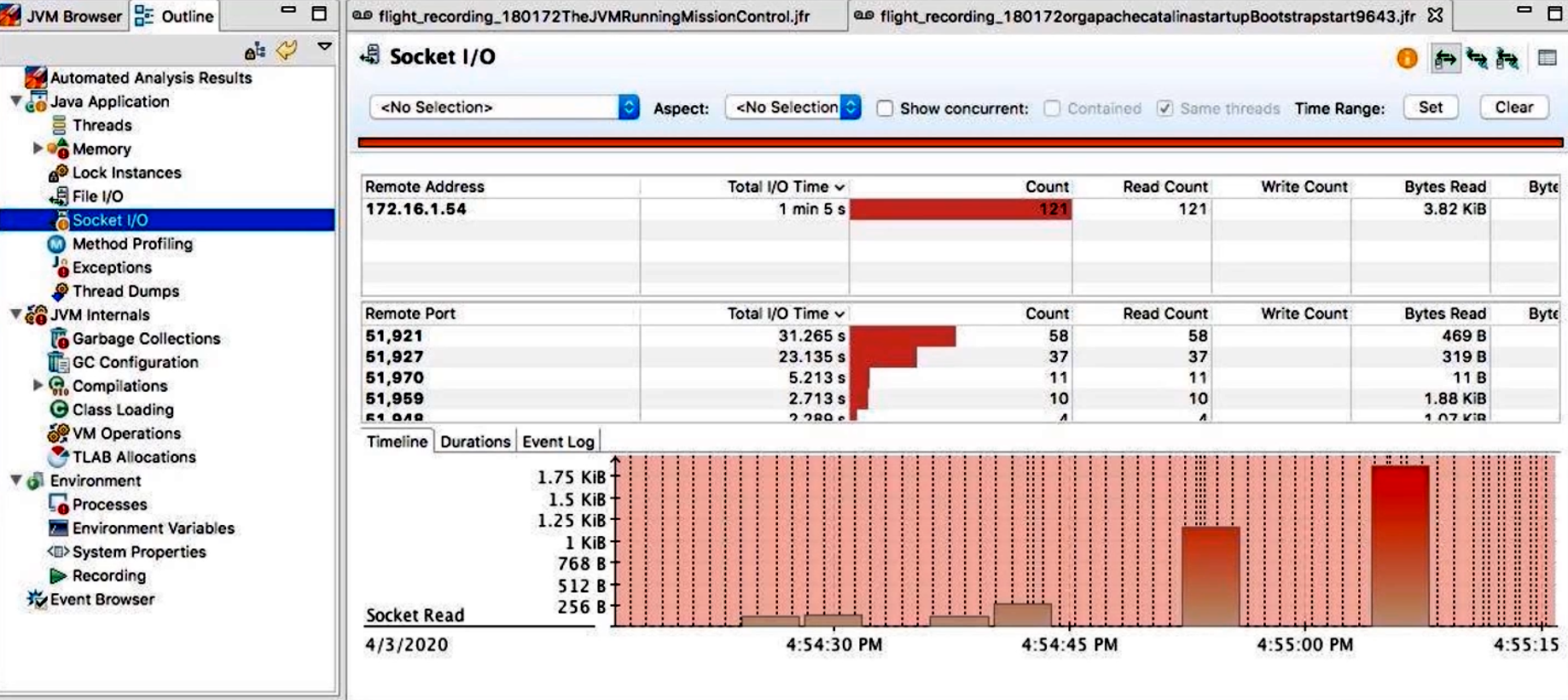
- “File I/O”面板展示对磁盘的读写次数、字节数及平均延迟;
- “Socket I/O”面板展示网络连接的打开/关闭、读写吞吐量以及对应线程;
- 可以将 I/O 操作与线程调用栈关联起来,方便定位某个请求或任务引发的 I/O 活动。
- Method Profiling(方法调用):
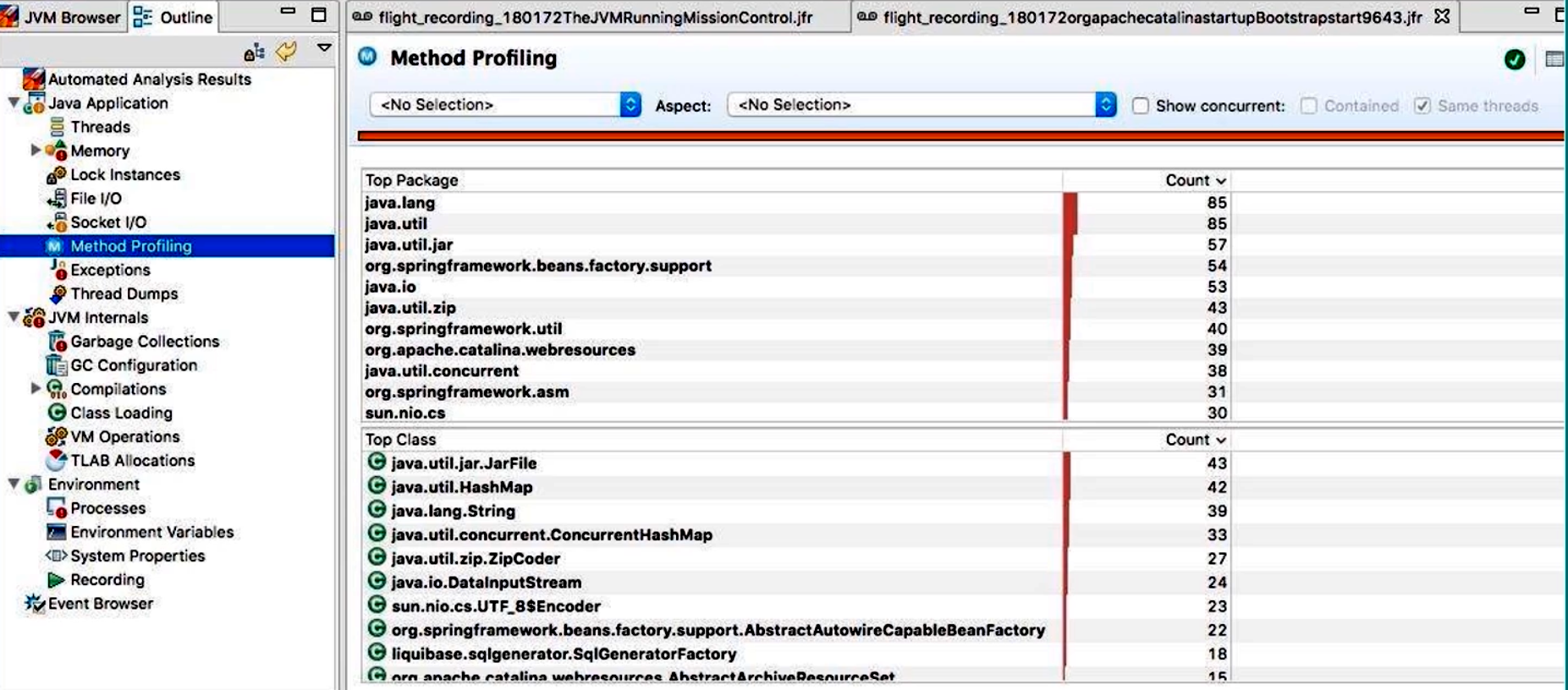
- 展示采样得到的热点方法列表,包括方法累计耗时、占比和调用次数;
- 支持展开调用树(Call Tree),分析调用链的深度与各层耗时分布;
- 支持将 Method Profiling 与 GC、锁事件结合,观察某个方法是否因 GC 或锁阻塞导致延迟。
- Garbage Collection(垃圾回收):
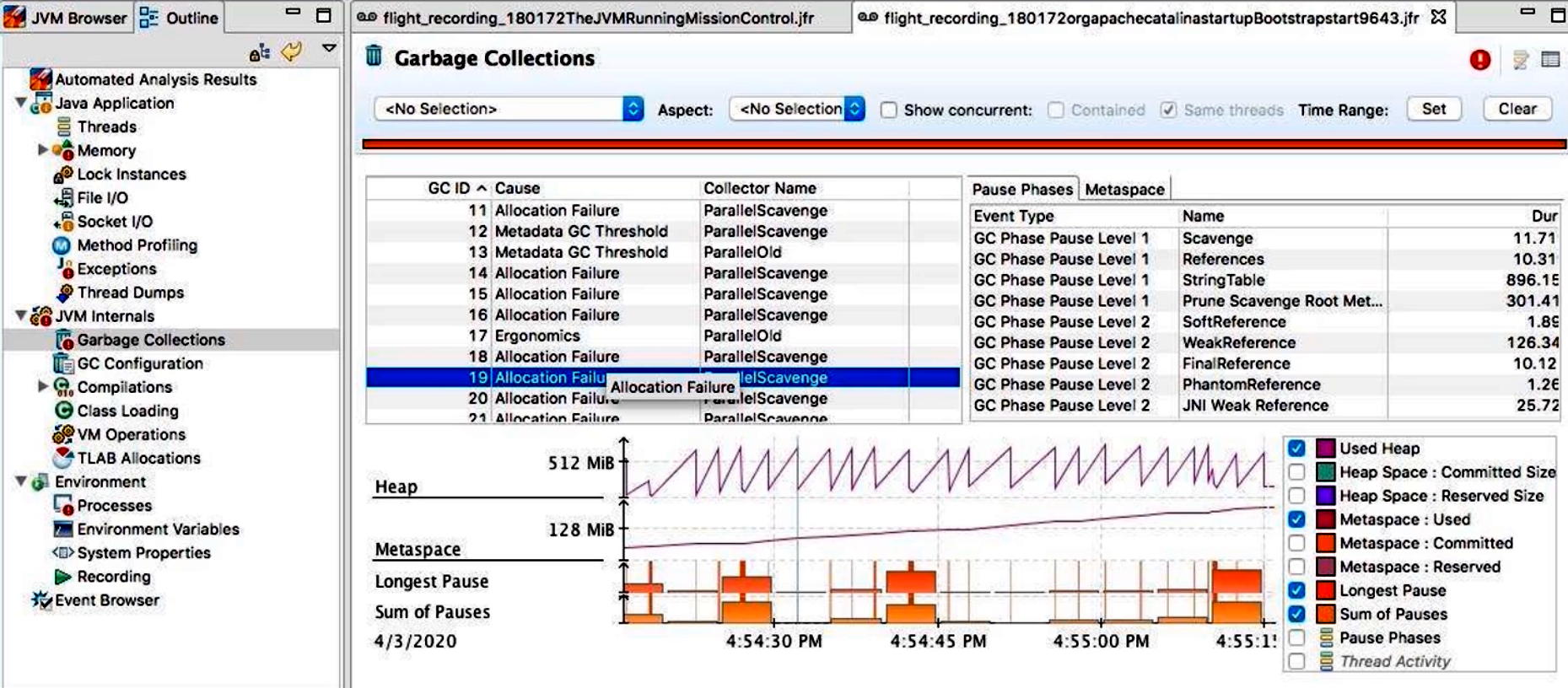
- 展示各 GC 周期(Young Gen、Mixed/Full GC)发生的时间戳与持续时长;
- 可以按 GC 类型(G1、Parallel GC、ZGC 等)筛选;
- 查看每次 GC 回收前后 Eden/Old 空间大小、停顿原因(SafePoint、Humongous Allocation 等)。
- Compilation(JIT 编译):
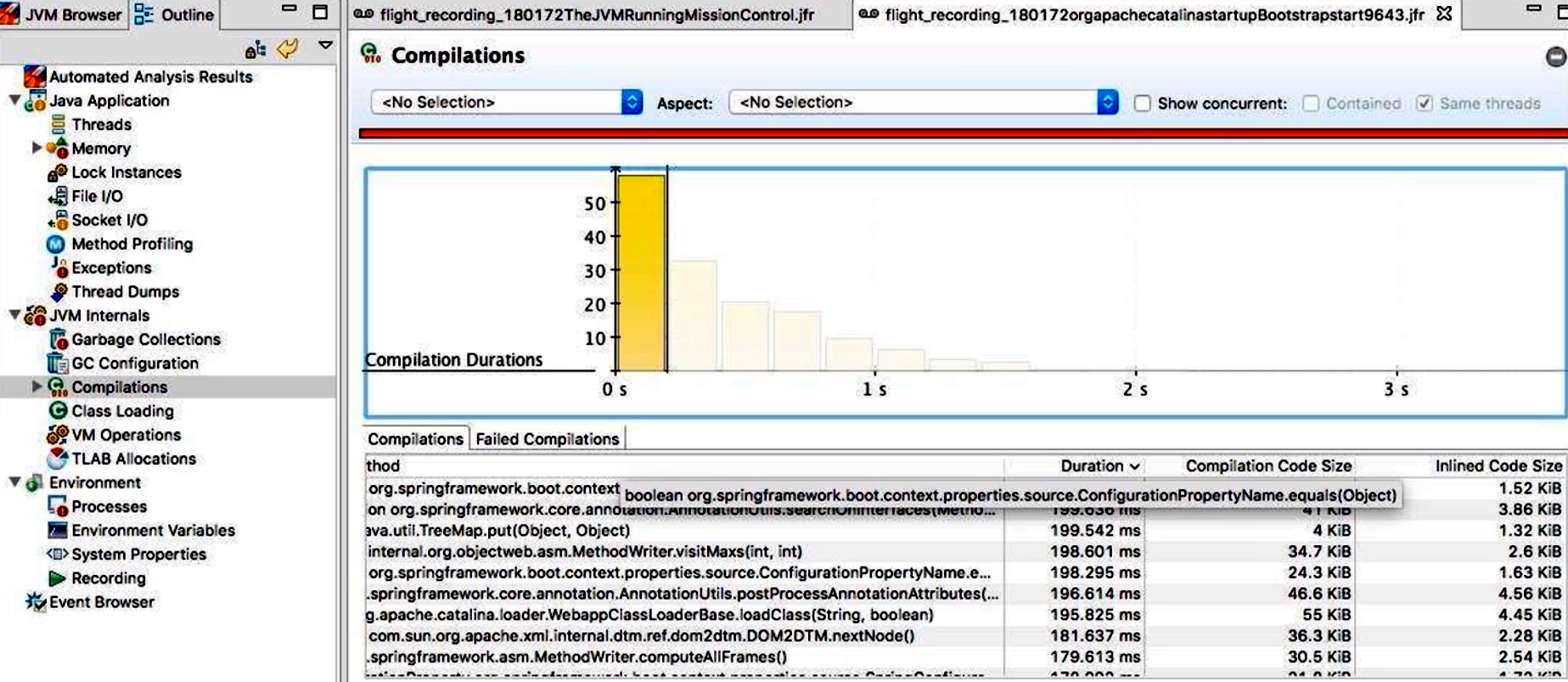
- 列出被 JIT 编译的所有方法名称、编译时长、CodeCache 大小变化、内联信息;
- 如果某些大型方法无法内联或耗时过久,可以通过此面板进行针对性优化。
-
TLAB(Thread Local Allocation Buffer):
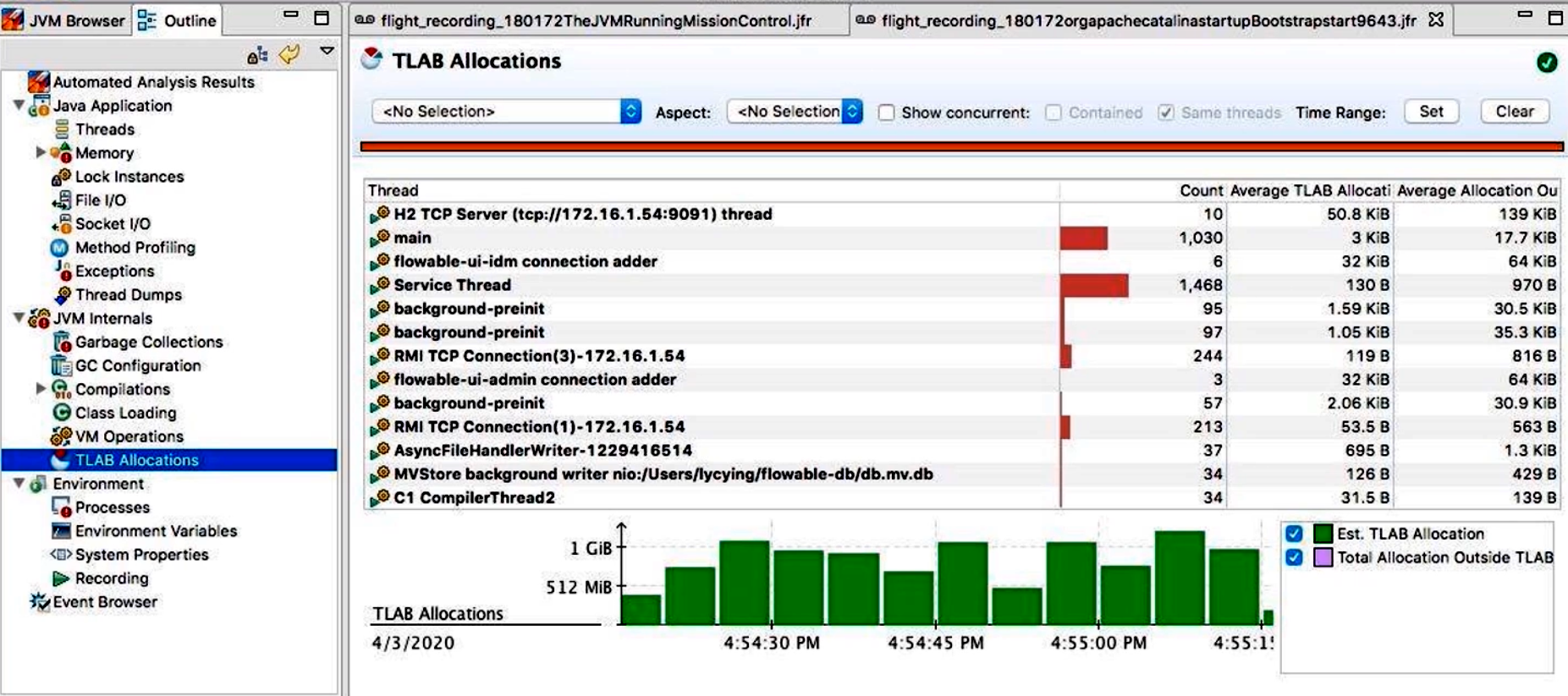
- 展示各线程在 Eden 区中分配对象的速度与分配失败次数;
- 可根据“Allocation Rate”排序,找出分配压力最大的线程;
- 若某个线程频繁触发 TLAB 分配失败时,会直接记录在这里。
示例说明:
- 在“Locks”面板中,我们发现
Service.process()方法持有的ReentrantLock[0x123456]累计等待时间达 500ms,而Thread-25在该锁前排队 50 次,说明该锁竞争较严重;- 在“File I/O”面板中,
RandomAccessFile.read平均延迟达 12ms,与iostat中的await > 10ms相互印证,表明磁盘随机 I/O 是系统瓶颈;- 在“Method Profiling”面板中,
CacheManager.get()累计耗时占 CPU 采样总耗时的 30%,且存在大量缓存 MISS 后的数据库查询调用,应考虑增加本地缓存或优化查询语句。
适用场景:
- JMC + JFR 采集对线上服务开销极低,可在生产环境启用“profile”级别持续采集当天的关键业务流量;
- 通过事后分析
.jfr文件,回顾&Troubleshoot 从多个维度(系统、JVM、线程、Lock、I/O、JIT)找出潜在瓶颈。
5. Arthas —— 获取单个请求的调用链耗时
Arthas 是阿里巴巴开源的一款 Java 诊断工具,它集成了内存、CPU、线程、Class、JVM 参数查询、方法跟踪等丰富命令。相比传统的 jstack、jmap、jstat 等命令组合,Arthas 提供了更友好的交互式 CLI 和 Web 控制台,并且无需重启应用。
5.1 快速启动
-
在目标 JVM 机器上直接下载并执行
as.sh脚本:wget https://alibaba.github.io/arthas/arthas-boot.jar java -jar arthas-boot.jar -
启动后,会列出当前机器上的所有 Java 进程 ID(PID),让你选择要 attach 的目标进程,选定后即可以进入 Arthas 的交互界面。
注意:在 Linux 上,需要给 Arthas/Zulu JDK 的
attach权限,通常需要在命令前加sudo。
5.2 常用命令示例:trace
trace <类名> <方法名>:在方法执行前后打桩并打印耗时和调用链。trace命令会记录该方法被调用时的完整调用栈,并在方法返回时统计耗时。- 如果目标方法被多次调用,Arthas 会汇总每一次的耗时并输出“树状”结果,显示调用分支和各分支耗时。
5.2.1 使用示例
假设我们有一个 DemoService.calculate() 方法,对应的执行示例:
# 进入 arthas 交互后
$ trace com.example.DemoService calculate
# Arthas 会拦截 DemoService.calculate() 的调用,对每次调用打印调用栈与耗时
Press Q or Ctrl+C to abort.
Affect(class-cnt:1, method-cnt:1) cost in 45 ms.
`---ts=2021-06-30 10:15:05;thread_name=http-nio-8080-exec-1;id=23;priority=5;TCCL=... `---[1.234567ms] com.example.DemoService:calculate() `---[0.345678ms] com.example.CacheManager:getFromCache() #45 `---[1.567890ms] com.example.DBClient:query() #123 `---[2.234567ms] com.example.Utils.processData() #67 `---ts=2021-06-30 10:15:05;thread_name=http-nio-8080-exec-2;id=24;priority=5;TCCL=... `---[10.234567ms] com.example.DemoService:calculate() `---[0.456789ms] com.example.CacheManager:getFromCache() #45 `---[8.345678ms] com.example.DBClient:query() #123 `---[1.432109ms] com.example.Utils.processData() #67
- 每个调用节点后方
#45表示该方法调用发生在字节码第 45 行; - 第一条记录:某次请求总耗时 1.234567ms,主要开销在
Utils.processData(); - 第二条记录:另一线程调用总耗时 10.234567ms,其中
DBClient.query()耗时 8.345678ms,说明数据库延迟是这次请求的瓶颈。
通过 trace,我们能够快速看到“某个接口在一次请求中的完整调用链”和“每个节点实际耗时”,非常适合诊断单请求延迟、找出“热点环节”。
5.3 其他常见命令
dashboard:实时查看 CPU、内存、GC、线程数量等基础监控指标;thread:查看所有线程状态与调用栈;heap:查看堆使用情况并生成堆转储;monitor:监控某个 Java 方法的 QPS、平均耗时、异常比例等;watch:在某个方法执行前后采集参数、返回值、耗时,支持表达式过滤;sm(search method):搜索某个关键字对应的类名与方法名;jad:反编译指定类,查看源码;tt(trace time):记录方法执行耗时分布,并生成统计报告。
适用场景:
- 单个接口或方法延迟较高,不知道为何时;
- 需要查看某个方法调用链中哪一步耗时最多;
- 快速排查线上某次请求的调用细节,无需重启应用。
6. wrk —— 获取 Web 接口的性能数据

在对外提供 HTTP 接口或微服务时,经常需要进行高并发压测,以便了解系统在不同并发量、不同请求类型下的吞吐能力和延迟分布。wrk 是一款功能强大的命令行 HTTP 压测工具(和ab类似),支持:
- 多线程并发发起请求;
- 自定义 HTTP 头、请求方式、请求体;
- Lua 脚本扩展,可模拟复杂业务场景。
与 ab、httperf 相比,wrk 的优势在于:
- 支持多线程且每线程可维护大量 TCP 连接,提高压测并发能力;
- 内置报告显示平均延迟、标准差、最大值、请求失败数;
- 支持自定义 Lua 脚本,用于在
setup/init/request/response等阶段插入逻辑,可灵活模拟带参数的 POST、Cookie、鉴权等场景。
6.1 安装与使用示例
-
安装(以 Ubuntu/Debian 为例):
sudo apt-get update sudo apt-get install build-essential libssl-dev git git clone https://github.com/wg/wrk.git cd wrk make sudo cp wrk /usr/local/bin/ -
基本压测命令格式:
wrk -t<线程数> -c<并发连接数> -d<测试时长> <URL>-t12:使用 12 个线程;-c400:并发维持 400 个 HTTP 连接;-d30s:压力测试持续 30 秒;http://127.0.0.1:8080/index.html:目标 URL;
-
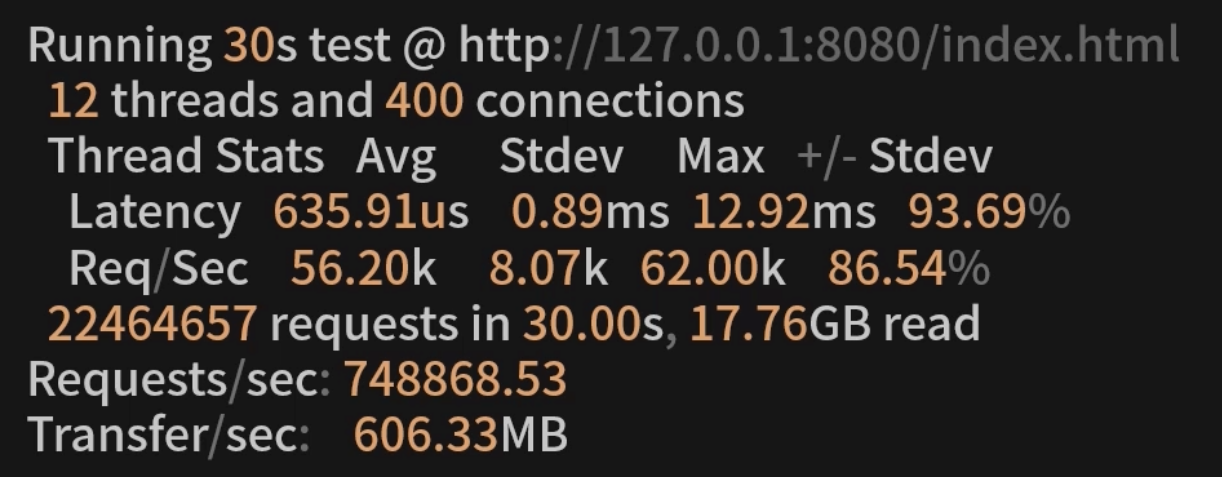
示例如下:
$ wrk -t12 -c400 -d30s http://127.0.0.1:8080/index.html Running 30s test @ http://127.0.0.1:8080/index.html 12 threads and 400 connections Thread Stats Avg Stdev Max +/- Stdev Latency 635.91us 0.89ms 12.92ms 93.69% Req/Sec 56.20k 8.07k 62.00k 86.54% 22,464,657 requests in 30.00s, 17.76GB read Requests/sec: 748,868.53 Transfer/sec: 606.33MB- Latency:平均延迟 635.91µs,标准差 0.89ms,最大延迟 12.92ms。其中
+/– Stdev表示 93.69% 的请求延迟都在平均值 ±1 标准差范围内; - Req/Sec:每秒平均请求数 56.20k,标准差 8.07k;
- Requests/sec:30 秒内共发起 22,464,657 次请求,平均每秒 748,868.53 次;
- Transfer/sec:每秒读取响应数据 606.33MB。
- Latency:平均延迟 635.91µs,标准差 0.89ms,最大延迟 12.92ms。其中
6.2 Lua 脚本扩展
wrk 提供了 Lua 脚本钩子,包含以下几个阶段:
setup(thread):初始化阶段;request():每次发送请求前生成wrk.request对象,可自定义 HTTP 方法、路径、请求头与请求体;response(status, headers, body):收到响应后触发,可对返回值做校验或统计;init(args):读取命令行参数并传入脚本内部;delay():控制请求发送间隔(默认不延迟)。
示例:带参数的 POST 请求(post.lua):
-- post.lua
wrk.method = "POST"
wrk.headers["Content-Type"] = "application/json" -- 带随机 userId 的 JSON body
math.randomseed(os.time())
body = function() local id = math.random(1000,9999) return string.format('{"userId":%d,"action":"login"}', id)
end request = function() local b = body() return wrk.format("POST", "/api/login", nil, b)
end response = function(status, headers, body) if status ~= 200 then table.insert(errors, status) end
end
运行命令:
wrk -t8 -c100 -d60s -s post.lua -L http://127.0.0.1:8080
-s post.lua:指定 Lua 脚本;-L:使 wrk 输出完整的 latency 分布(可选);- Lua 中
body()每次会生成不同的 JSON,使请求更加接近真实业务。
7. 小结
介绍了获取“系统级指标”、“JVM 级指标”、“应用级调用链”和“Web 接口吞吐”四个层面的几款常用工具:
-
nmon:
- 定位维度:CPU/内存/网络/磁盘/文件系统/NFS 等系统级指标;
- 输出形式:交互式终端面板 + 离线
.nmon数据文件 →nmonchart转 HTML 报表; - 适用场景:压测期间、基线评估、容量规划,需要全局系统负载数据。
-
jvisualvm:
- 定位维度:JVM 内部:方法耗时采样、堆快照、线程状态;
- 输出形式:GUI 可视化交互,生成 CPU/内存/线程快照;
- 适用场景:测试环境中对单节点 JVM 性能热点定位、内存泄漏排查、死锁检测;
-
JMC + JFR:
- 定位维度:基于轻量级事件采集:系统事件、JVM 事件、锁竞争、GC、JIT 等全链路数据;
- 输出形式:
.jfr二进制录制文件 → JMC 可视化分析面板; - 适用场景:生产环境低开销持续采样,事后对全链路性能瓶颈进行深入剖析。
-
Arthas:
- 定位维度:单个方法/接口的调用链全耗时分析、实时线程/内存/类信息;
- 输出形式:CLI 可交互式操作,
trace、monitor、heap等命令直接输出调用链与耗时; - 适用场景:线上或测试环境快速诊断某次请求延迟问题,精准定位某个方法/锁/I/O 问题。
-
wrk:
- 定位维度:HTTP 接口性能,包括吞吐(Req/sec)、延迟分布(Avg/Stdev/Max)、传输速率等;
- 输出形式:终端输出详细统计,可结合 Lua 脚本进行定制化请求生成;
- 适用场景:模拟用户并发访问、压测微服务入口 API、验证负载均衡与限流策略效果。
通过这五款工具的组合,我们能够:
-
在压测开始前后先用
nmon和wrk定义系统与业务吞吐基线; -
在测试过程中,用
jvisualvm初步确认 JVM 内存/CPU 热点; -
使用
Arthas快速追踪单个高延迟请求的调用链; -
最终在生产/预发布环境开启
JFR进行长时段采样,再通过JMC全面分析锁竞争、GC 影响与 JIT 代价。 -
建议:
- 通过 nmon 整合系统级数据,增强测试结果说服力;
- 细化 JVM 层面采样、堆分析与线程分析的工具差异;
- 用 JMC + JFR 展示生产级低开销持续采样思路;
- 用 Arthas 高效定位单接口调用链耗时;
- 用 wrk 进行 Web 服务压测并评估吞吐与延迟。

![[AI算法] 什么事RoPE scaling](https://i-blog.csdnimg.cn/direct/3734ec5e3a194c42b1fe0ab22d46ef7c.png)