前言
在NLP领域中,RNN、LSTM及GRU曾是处理序列问题的主力模型,但它们都面临着两个关键问题:
- 无法并行计算:序列数据需要完成前一步后再处理下一步,这会使得训练效率低下
- 长期依赖问题:即使是LSTM、GRU,在面对非常长的序列时也难以捕捉远距离依赖
Transformer的提出彻底改变了这一现状。Transformer完全基于Attention机制,摒弃了RNN、GRU的递归循环结构,支持并行计算,并且能很好地建模长距离依赖。
一、Transformer的历史地位
Transformer模型在2017年被Google提出,并发表在《Attention is all you need》中,其提出后迅速成为NLP模型设计的基石,并由此衍生出了各种大模型系列:
- BERT:用于预训练表示的双向编码器
- GPT系列:用于文本生成的解码器架构
- T5/BART:编码器-解码器通用架构
- ViT:将Transformer拓展到图像领域
可以说,Transformer是现代深度学习中大模型领域中最重要的模型架构。
二、Transformer的总体架构
Transformer是一个编码器-解码器架构,主要由多个编码器、解码器堆叠而成,如下图所示:

上图左侧是Transformer的Encoder部分,右侧是Decoder部分,每个部分都包含六个Block。
对于Encoder,每个Block包括:
- 多头自注意力层
- 前馈全连接层
- 残差链接+Layernorm
对于Decoder,和Encoder组成类似,只不过每个Block增加了:
- Masked Multi-head Self Attention
- 与编码器输出交互的Encoder-Decoder Attention
三、Transformer的流程
我们已经知道,Transformer由两部分组成,接下来,我通过一个英文翻译任务来讲一下Transformer的具体流程:
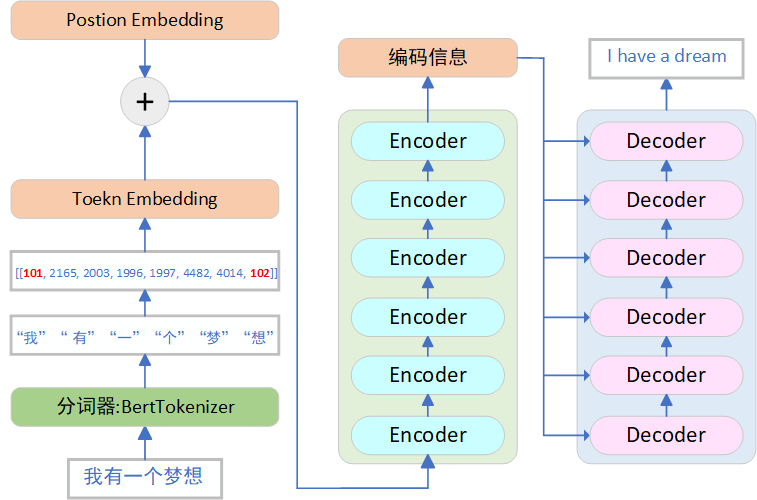
1. 输入预处理
输入中文句子:“我有一个梦想”
- 使用中英文分词器进行分词:“我”,“有”,“一”, “个”, “梦”, “想”
- 编码映射为为token id:[[101, 2165, 2003, 1996, 1997, 4482, 4014, 102]],其中101,102是分词器自动添加的开始与结束的token
- 构造Embedding + 位置编码
- 输入编码器
在这里,我简单的写一下分词,token嵌入与位置嵌入:
首先是分词,我直接使用HuggingFace的分词器-BertTokenizer,接着是token词嵌入,然后是位置编码:
from transformers import BertTokenizer
import torch
import torch.nn as nn# 分词 ================================================================================
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
text = '我有一个梦想'tokens = tokenizer.tokenize(text)
token_ids = tokenizer.encode(text, return_tensors='pt')
print(f'分词结果:{tokens}')
print(f'Token id:{token_ids}')# 词嵌入================================================================================
embed_dim = 16
vocab_size = tokenizer.vocab_sizeembed = nn.Embedding(vocab_size, embed_dim)
token_emb = embed(token_ids) # shape:[1, seq_len, embed_dim]# 位置嵌入模块==========================================================================
class PositionEmbedding(nn.Module):def __init__(self, d_model, max_len=512):super(PositionEmbedding, self).__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1).float()div = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(10000.0)/d_model))pe[:,0::2] = torch.sin(position * div)pe[:,1::2] = torch.cos(position * div)# shape:[1, max_len, d_model]pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:,:x.size(1)]
pos_emb = PositionEmbedding(d_model=embed_dim)
emb = pos_emb(token_emb)
print(f'词嵌入+位置嵌入:{emb.shape}')2. 将位置编码后的向量输入到Encoder中
在第一步中,我们已经得到了位置编码后的向量,那么在这一步中,我将调用Pytorch内容的函数组件来构造一个简单的编码器(包括多头注意力 + 残差 + FFN),然后输入到里面:
import torch
import torch.nn as nn
import torch.nn.functional as F
# Encoder Block ===========================================================================
class TransformerEncoderLayer(nn.Module):def __init__(self, embed_dim, num_heads, ffn_dim, dropout=0.1):super(TransformerEncoderLayer, self).__init__()self.attn = nn.MultiHeadAttention(embed_dim. num_heads, dropout=dropout, batch_first=True)self.norm1 = nn.LayerNorm(embed_dim)self.dropout1 = nn.Dropout(dropout)self.fnn = nn.Sequential(nn.Linear(embed_dim. ffn_dim),nn.ReLU(),nn.Linear(ffn_dim, embed_dim))self.norm2 = nn.LayerNorm(embed_dim)self.dropout2 = nn.Dropout(dropout)def forward(self, x, src_padding_mask=None):attn_output, _ = self.attn(x, x, x, key_paading_mask=src_padding_mask)x = x + self.dropout1(attn_output)x = self.norm1(x) ffn_output = self.ffn(x)x = x + self.dropout2(x)x = self.norm2(x)return x# 完整的Encoder=============================================================================
class TransformerEncoder(nn.Module):def __init__(self, num_layer, embed_dim, num_heads, ffn_dim, dropout=0.1):super(TransformerEncoder,self).__init__()self.layers = nn.ModuleList([TransformerEncoderLayer(embed_dim, num_heads, ffn_dim, dropout) for _ in range(num_layers)])def forward(self, x, src_padding_mask=None):for layer in self.layers:x = layer(x, src_padding_mask)return x# 将第一步中,得到的emb输入到Encoder中
embed_dim = 16
num_heads = 2
ffn_dim = 64
num_layers = 2encoder = TransformerEncoder(num_layers, embed_dim, num_heads, ffn_dim)
encoder_output = encoder(emb)
# shape:[batch_size, seq_len, embed_dim]
print(f'Encoder输出:{encoder_output.shape}')3. 逐步解码Decoder
经过前两步,我们已经得到了Encoder的输出,接下来,就是根据编码器的输出与目标的掩码输入,来解码Decoder:我们实现一个简单的Decoder层(masked Self Attention, Encoder-Decoder Attention, ffn)
import torch
import torch.nn as nn
import torch.nn.functional as F# Decoder Block=========================================================================
class TransformerDecoderLayer(nn.Module):def __init__(self, embed_dim, num_heads, ffn_dim, dropout=0.1):super().__init__()self.self_attn = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout, batch_first=True)self.norm1 = nn.LayerNorm(embed_dim)self.dropout1 = nn.Dropout(dropout)self.cross_attn = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout, batch_first=True)self.norm2 = nn.LayerNorm(embed_dim)self.dropout2 = nn.Dropout(dropout)self.ffn = nn.Sequential(nn.Linear(embed_dim, ffn_dim),nn.ReLU(),nn.Linear(ffn_dim, embed_dim))self.norm3 = nn.LayerNorm(embed_dim)self.dropout3 = nn.Dropout(dropout)def forward(self, tgt, encoder_output, tgt_mask=None, encoder_mask=None):# Masked self-attn_tgt, _ = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask)tgt = tgt + self.dropout1(_tgt)tgt = self.norm1(tgt)# Encoder-decoder attention_tgt, _ = self.cross_attn(tgt, encoder_output, encoder_output, attn_mask=encoder_mask)tgt = tgt + self.dropout2(_tgt)tgt = self.norm2(tgt)# ffn_tgt = self.ffn(tgt)tgt = tgt + self.dropout3(_tgt)tgt = self.norm3(tgt)return tgt
# 完整的Decoder==========================================================================
class TransformerDecoder(nn.Module):def __init__(self, num_layers, embed_dim, num_heads, ffn_dim):super().__init__()self.layers = nn.ModuleList([TransformerDecoderLayer(embed_dim, num_heads, ffn_dim)for _ in range(num_layers)])self.linear_out = nn.Linear(embed_dim, len(en_vocab))def forward(self, tgt_embed, encoder_output, tgt_mask=None):x = tgt_embedfor layer in self.layers:x = layer(x, encoder_output, tgt_mask)logits = self.linear_out(x)return logits # [batch, seq_len, vocab_size]
# 构造一个英文词表,在这里我简单构造一个,但是在实际的任务中,通常用Transformers或者torchtext词表
en_vocab = {'<PAD>':0, 'BOS':1, 'EOS':2, 'I':3, 'have':4, 'a':5, 'dream':6}
id2word = {i:w for w, i in en_vocab.items()}
en_embed = nn.Embedding(len(en_vocab), embed_dim)
pos_embed = PositionalEmbedding(embed_dim, max_len=50)# 解码Decoder===========================================================================
def Translation(encoder_output, max_len=10):device = encoder_output.devicetgt_ids = [en_vocab['BOS']]for _ in range(max_len):# 目标掩码输入tgt_tensor = torch.tensor(tgt_ids, dtype=torch.long).unsqeeze(0).to(device)tgt_embed = em_embed(tgt_tensor)tgt_embed = pos_embed(tgt_embed)# 构造目标Maskseq_len = tgt_tensor.size(1)tgt_mask = torch.triu(torch.ones((seq_len, seq_len), device=device)*float('-inf'),diagonal=1)# Decoder解码logits = decoder(tgt_embed, encoder_output, tgt_mask)next_token_logits = logitis[:,-1,:] # 取最后一个位置next_token = torch.argmax(next_token_logits, dim=-1).item()if next_token == en_vocab['EOS']tgt_ids.append(next_token)return [idword[idx] for idx in tgt_ids[1:]]# 整体流程就可表示为=====================================================================# 第一步:得到encoder_output
encoder_output = encoder(emb)
# 第二步:生成翻译:
translation_tokens = Translation(encoder_output)
translated_sentence = " ".join(translation_tikens)
print(f'翻译结果为:{translated_sentence}')四、注意力机制

有了第三部分的介绍,我们再次看一下Transformer架构图,可以发现,左侧为Encoder Block,包含一个多头自注意力层;右侧为Decoder Block,包含两个多头自注意力层,其中第一个多头自注意力层是带有掩码的;其余部分包括了层,Add表示残差连接,用于防止网络退化,Norm表示LayerNorm,用于对每一层的激活值归一化。
因此,Transformer其实就是一个注意力模型,其重点就是注意力机制,这个注意力就像我们平时在看书一样,不会平均地关注每个信息,而是有重点地“注意某些”关键部分,注意力机制就是模拟这种行为的一种计算方式。因此,我们来详细地看一下其中的注意力机制。
1. Attention
我们已经知道了,Attention的动机就是:模拟人类在读文章时对某个词、某段句子的重点关注程度。看一下它的数学表达:
其中:
(query):查询向量
(key):键向量
(value):值向量
:键向量的维度,用于缩放(防止Softmax输入值过大导致梯度消失问题;因为Softmax输入值过大时,导数会趋近于0,因此除以
,使得注意力分数的分布更平滑,避免Softmax进入饱和区域,从而保留有效的梯度信息)
:计算每个query与所有key的相关性,即注意力分数
- Softmax:将得分归一化为概率
- 最终结果是这些概率加权的V,得到最终的“注意信息”
具体的Scale Dot-Product Attention代码实现为:
import torch
import torch.nn.functional as Fdef scaled_dot_product_attention(Q, K, V, mask=None):d_k = K.size(-1)scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))if mask is not None:scores = scores.masked_fill(mask == 0, float('-inf'))attention = F.softmax(scores, dim=-1)output = torch.matmul(attention, V)return output, attention
2. Self-Attention
自注意力是指对序列内容的信息交互——序列中每个位置可以根据其他位置的信息来更新自身的表示,例如在句子“我 吃 苹果”中,“吃”可以关注“苹果”补充语义信息。它的具体实现和Scale Dot-Product Attention 一样,只不过Q、K、V用同一个向量表示。具体实现如:
class SelfAttention(torch.nn.Module):def __init__(self, embed_dim):super(SelfAttention, self).__init__()self.embed_dim = embed_dimself.W_q = torch.nn.Linear(embed_dim, embed_dim)self.W_k = torch.nn.Linear(embed_dim, embed_dim)self.W_v = torch.nn.Linear(embed_dim, embed_dim)def forward(self, x, mask=None):Q = self.W_q(x)K = self.W_k(x)V = self.W_v(x)output, attention = scaled_dot_product_attention(Q, K, V, mask)return output, attention
3. Multi-Head Attention
为什么要使用多头呢:
- 单个注意力头只能学习一种关系(如句法、语义等)
- 多头并行学习不同的子空间投影,能够使模型更有表达力
具体表达形式为:
h 为 头数,每个头都有独立的,输出拼接后再进行线性变换。
具体实现如下:
class MultiHeadAttention(torch.nn.Module):def __init__(self, embed_dim, num_heads):super(MultiHeadAttention, self).__init__()assert embed_dim % num_heads == 0, "embed_dim 必须能被 num_heads 整除"self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsself.W_q = torch.nn.Linear(embed_dim, embed_dim)self.W_k = torch.nn.Linear(embed_dim, embed_dim)self.W_v = torch.nn.Linear(embed_dim, embed_dim)self.fc_out = torch.nn.Linear(embed_dim, embed_dim)def forward(self, x, mask=None):batch_size, seq_len, embed_dim = x.size()# 1. 投影为 Q, K, VQ = self.W_q(x)K = self.W_k(x)V = self.W_v(x)# 2. 拆分为多个头def split_heads(tensor):return tensor.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)Q = split_heads(Q)K = split_heads(K)V = split_heads(V)# 3. 缩放点积注意力out, attention = scaled_dot_product_attention(Q, K, V, mask)# 4. 拼接头out = out.transpose(1, 2).contiguous().view(batch_size, seq_len, self.embed_dim)# 5. 线性映射return self.fc_out(out), attention
4. Mask Multi-Head Attention
在训练Decoder时,模型不能看到“未来的信息”,否则预测下一个词就相当于提前知道了答案。因此,需要使用Mask,保证模型生成的每个词只依赖它前面出现的词:
- 将当前位置之后的Token对应的注意力分数设为-inf
- 通过Softmax之后,相当于这些位置的概率为0
其具体实现公式为
mask是一个包含-inf的矩阵,被添加到Softmax的输入中,使得对应位置的attention权重变为0。
具体实现如下:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MaskedMultiHeadAttention(nn.Module):def __init__(self, embed_dim, num_heads):super(MaskedMultiHeadAttention, self).__init__()assert embed_dim % num_heads == 0, # "embed_dim必须能被num_heads整除"self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsself.q = nn.Linear(embed_dim, embed_dim)self.k = nn.Linear(embed_dim, embed_dim)self.v = nn.Linear(embed_dim, embed_dim)self.out = nn.Linear(embed_dim, embed_dim)def forward(self, q, k, v, mask=None):B, T, E = q.size()H = self.num_headsD = self.head_dim# 线性映射Q = self.q(q).view(B, T, H, D).transpose(1, 2) # (B, H, T, D)K = self.k(k).view(B, T, H, D).transpose(1, 2)V = self.v(v).view(B, T, H, D).transpose(1, 2)scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(D)if mask is not None:# mask 必须 broadcast 到 (B, H, T, T)if mask.dim() == 2:mask = mask.unsqueeze(0).unsqueeze(0) # (1, 1, T, T)elif mask.dim() == 3:mask = mask.unsqueeze(1) # (B, 1, T, T)scores = scores.masked_fill(mask == 0, float('-inf'))attn_weights = F.softmax(scores, dim=-1)attn_output = torch.matmul(attn_weights, V) # (B, H, T, D)# 合并多头attn_output = attn_output.transpose(1, 2).contiguous().view(B, T, E)return self.out(attn_output)五、完整Transformer代码实现
到这里,我们已经弄清楚了Transformer模块中所有的细节,下面,我们试着来写一下整个完整的Transformer:
import torch
import torch.nn as nn
import torch.nn.functional as F# 位置嵌入
class PositionalEmbedding(nn.Module):def __init__(self, d_model, max_len=5000):super(PositionalEmbedding, self).__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1).float()div = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0))/d_model))pe[:, 0::2] = torch.sin(position * div)pe[:, 1::2] = torch.cos(position * div)self.pe = pe.unsqueeze(0) #(1, max_len, d_model)def forward(self, x):x = x + self.pe[:,:x.size(1)]return x
# 多头自注意力层
class MultiHeadAttention(nn.Module):def __init__(self, embed_dim, num_heads):super(MultiHeadAttention,self).__init__()assert embed_dim % num_heads == 0self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsself.q = nn.Linear(embed_dim, embed_dim)self.k = nn.Linear(embed_dim, embed_dim)self.v = nn.Linear(embed_dim, embed_dim)self.out = nn.Linear(embed_dim, embed_dim)def forward(self, query, key, vlaue, mask=None):B, T, E = query.size()H, D = self.num_heads, self.head_dimQ = self.q(query).view(B, T, H, D).transpose(1, 2)K = self.k(key).view(B, T, H, D).transpose(1, 2)V = self.v(value).view(B, T, H, D).transpose(1, 2)scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(D)if mask is not None:if mask.dim() == 2:mask = mask.unsqueeze(0).unsqueeze(0)elif mask.dim() == 3:mask = mask.unsqueeze(1)scores = scores.masked_fill(mask==0, float('-inf))attn_weights = F.softmax(scores, dim=-1)attn_output = torch.matmul(attn_weights, V)attn_output = attn_output.transpose(1, 2).contiguous().view(B, T, E)return self.out(attn_output)
# 前馈层
class FeedForward(nn.Module):def __init__(self, d_model, d_ff):super(FeedForward, self).__init__()self.net = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model))def forward(self, x):return self.net(x)
# Encoder Block
class TransformerEncoderLayer(nn.Module):def __init__(self, d_model, num_heads, d_ff):super(TransformerEncoderLayer, self).__init__()self.mha = MultiHeadAttention(d_model, num_heads)self.ff = FeedForward(d_model, d_ff)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)def forward(self, x, mask=None):attn_out = self.mha(x, x, x, mask)x = self.norm1(x + attn_out)ff_out = self.ff(x)x = self.norm2(x + ff_out)return x
# Decoder Block
class TransformerDecoderLayer(nn.Module):def __init__(self, d_model, num_heads, d_ff):super(TransformerDecoderLayer, self).__init__()self.self_mha = MultiHeadAttention(d_model, num_heads)self.cross_mha = MultiHeadAttention(d_model, num_heads)self.ff = FeedForward(d_model, d_ff)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)def forward(self, x, enc_out, tgt_mask=None, memory_mask=None):x = self.norm1(x + self.self_mha(x, x, x, tgt_mask))x = self.norm2(x + self.cross_mha(x, enc_out, enc_out, memory_mask))x = self.norm3(x + self.ff(x))return x
# Encoder
class TransformerEncoder(nn.Module):def __init__(self, vocab_size, d_model, num_heads, d_ff, num_layers):super(TransformerEncoder, self).__init__()self.embed = nn.Embedding(vocab_size, d_model)self.pos = PositionalEncoding(d_model)self.layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])def forward(self, x, mask=None):x = self.pos(self.embed(x))for layer in self.layers:x = layer(x, mask)return x
# Decoder
class TransformerDecoder(nn.Module):def __init__(self, vocab_size, d_model, num_heads, d_ff, num_layers):super(TransformerDecoder, self).__init__()self.embed = nn.Embedding(vocab_size, d_model)self.pos = PositionalEncoding(d_model)self.layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])self.fc_out = nn.Linear(d_model, vocab_size)def forward(self, x, enc_out, tgt_mask=None, memory_mask=None):x = self.pos(self.embed(x))for layer in self.layers:x = layer(x, enc_out, tgt_mask, memory_mask)return self.fc_out(x)
# Transformer
class Transformer(nn.Module):def __init__(self, src_vocab, tgt_vocab, d_model=512, num_heads=8, d_ff=2048, num_layers=6):super().__init__()self.encoder = Encoder(src_vocab, d_model, num_heads, d_ff, num_layers)self.decoder = Decoder(tgt_vocab, d_model, num_heads, d_ff, num_layers)def make_subsequent_mask(self, size):return torch.tril(torch.ones(size, size)).bool()def forward(self, src, tgt, src_mask=None, tgt_mask=None):enc_out = self.encoder(src, src_mask)if tgt_mask is None:tgt_mask = self.make_subsequent_mask(tgt.size(1)).to(tgt.device)out = self.decoder(tgt, enc_out, tgt_mask)return out
总结
以上就是本文的全部内容,相信小伙伴们在看完之后对Transformer的原理有了深刻的理解:Transformer 的提出让深度学习进入了真正的“注意力时代”。无论是 NLP、CV 还是多模态任务,Transformer 都展示了极强的建模能力。通过彻底摒弃循环结构,用注意力机制建立全局依赖关系,Transformer 成为当前几乎所有大规模模型的架构基础。
如果小伙伴们觉得本文对各位有帮助,欢迎:👍点赞 | ⭐ 收藏 | 🔔 关注。我将持续在专栏《人工智能》中更新人工智能知识,帮助各位小伙伴们打好扎实的理论与操作基础,欢迎🔔订阅本专栏,向AI工程师进阶!