PINN for PDE(偏微分方程)1 - 正向问题
目录
- PINN for PDE(偏微分方程)1 - 正向问题
- 一、什么是PINN的正问题
- 二、求解的实际例子
- 三、基于Pytorch实现的代码 - 分解
- 3.1 引入库函数
- 3.2 设置超参数
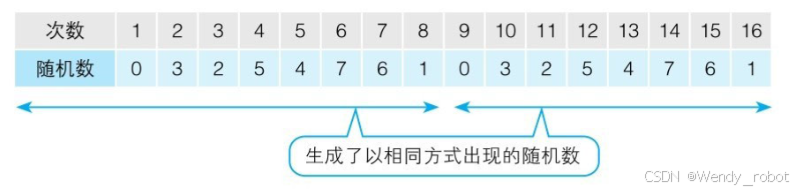
- 3.3 设计随机种子,确保复现结果的一致性
- 3.4 对于条件等式生成对应的训练数据
- 3.5 定义PINN网络
- 3.6 定义求导函数
- 3.7 定义损失函数
- 3.8 模型训练
- 3.9 绘制结果图像
- 结果
- 4.1 真实结果图
- 4.2 PINN预测结果图
- 4.3 两者误差图
- 参考
一、什么是PINN的正问题
在 PINN(Physics-Informed Neural Networks,物理信息神经网络)中,**正问题(Forward Problem)**指的是:
给定一个偏微分方程(PDE)的形式、边界条件和初始条件,求解该方程在定义域内的解函数。
在 PINN 框架下,求解正问题的基本步骤如下:
- 构建神经网络 u θ ( x , t ) u_\theta(x, t) uθ(x,t) 作为 PDE 解的近似;
- 利用自动微分计算偏导数,将 PDE 表达为损失函数项;
- 同时将边界条件和初始条件也转化为损失函数;
- 通过最小化总损失来训练神经网络参数 θ \theta θ,使其近似满足物理规律。
正问题的特征是:问题的数学描述是充分确定的,即 PDE 与条件信息足够多,因此目标是通过神经网络来模拟已知物理过程。
二、求解的实际例子
偏微分方程如下:
∂ 2 u ∂ x 2 − ∂ 4 u ∂ y 4 = ( 2 − x 2 ) e − y \frac{\partial ^2u}{\partial x^2}-\frac{\partial ^4u}{\partial y^4}=\left( 2-x^2 \right) e^{-y} ∂x2∂2u−∂y4∂4u=(2−x2)e−y
考虑以下边界条件,
u y y ( x , 0 ) = x 2 u y y ( x , 1 ) = x 2 e u ( x , 0 ) = x 2 u ( x , 1 ) = x 2 e u ( 0 , y ) = 0 u ( 1 , y ) = e − y u_{yy}\left( x,0 \right) =x^2 \\ u_{yy}\left( x,1 \right) =\frac{x^2}{e} \\ u\left( x,0 \right) =x^2 \\ u\left( x,1 \right) =\frac{x^2}{e} \\ u\left( 0,y \right) =0 \\ u\left( 1,y \right) =e^{-y} uyy(x,0)=x2uyy(x,1)=ex2u(x,0)=x2u(x,1)=ex2u(0,y)=0u(1,y)=e−y
以上偏微分方程真解为:
u ( x , y ) = x 2 e − y u(x,y)=x^2 e^{-y} u(x,y)=x2e−y
x x x 和 y y y 的区域范围均为 [ 0 , 1 ] [0,1] [0,1] 。
三、基于Pytorch实现的代码 - 分解
3.1 引入库函数
import torch
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
3.2 设置超参数
# ====================== 超参数 ======================
epochs = 10000 # 训练轮数
h = 100 # 作图时的网格密度
N = 1000 # PDE残差点(训练内点)
N1 = 100 # 边界条件点
N2 = 1000 # 数据点(已知解)
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设置GPU运行
3.3 设计随机种子,确保复现结果的一致性
def setup_seed(seed):torch.manual_seed(seed) # 设置 PyTorch 中 CPU 上的随机数种子,使得所有如 torch.rand()、torch.randn() 等函数在 CPU 上的随机数生成具有可重复性。torch.cuda.manual_seed_all(seed) # 设置所有 GPU 设备上的随机数种子。GPU 上也有自己的随机数生成器,用于模型参数初始化、Dropout 等操作。torch.backends.cudnn.deterministic = True # 设置 cuDNN 后端为确定性模式。'''cuDNN 是 NVIDIA 为深度学习优化的加速库,但它为了加速有时使用了非确定性算法(比如卷积时自动选择最快的实现方式,某些可能会导致浮点计算顺序不同)。这个设置会强制它只使用确定性算法(牺牲一些速度),确保每次前向/反向传播都一致。'''# 设置随机数种子
setup_seed(888888)
3.4 对于条件等式生成对应的训练数据
'''
# 下面这些,都是在构建数据集,对每个微分方程(包括边界点和中间点)都构建对应的数据集,包含(x,y,对应的条件值(微分方程的真值部分))
'''
# Domain and Sampling,内点采样
def interior(n=N):# 生成 PDE(偏微分方程)区域内的训练点# 随机生成 n 个 x 坐标(范围在 [0, 1))x = torch.rand(n, 1).to(device)# 随机生成 n 个 y 坐标(范围在 [0, 1))y = torch.rand(n, 1).to(device)# 计算对应点的“条件值”(可能是解析解、真值或用于损失函数的目标值)# 这里定义为 cond = (2 - x²) * exp(-y),# 是里面的点偏导等于的一个值cond = (2 - x ** 2) * torch.exp(-y)# 返回的 x 和 y 启用自动求导功能,以便后续可用于计算梯度(如 PDE 中的导数)return x.requires_grad_(True), y.requires_grad_(True), cond# 下边界条件的第一个,对y的二阶导等于 x 平方
def down_yy(n=N1):# 下边界上的 u_yy(x, 0) = x² 条件# 随机生成 n 个 x 坐标,范围在 [0, 1)x = torch.rand(n, 1).to(device)# y 坐标全为 0,表示这是在 y=0 的边界上y = torch.zeros_like(x).to(device)# 条件值:u_yy(x, 0) = x²,即函数在边界上的二阶偏导值(对 y 的二阶导数)等于 x²cond = x ** 2# 返回启用自动求导的 x、y,以及边界条件值 condreturn x.requires_grad_(True), y.requires_grad_(True), cond# 这个是边界条件的第二个,对y的二阶导等于x平方除以e
def up_yy(n=N1):# 边界 u_yy(x,1)=x^2/ex = torch.rand(n, 1).to(device)y = torch.ones_like(x).to(device)cond = x ** 2 / torch.ereturn x.requires_grad_(True), y.requires_grad_(True), cond# 这个是边界条件的第三个,对u(x,0)等于x平方
def down(n=N1):# 边界 u(x,0)=x^2x = torch.rand(n, 1).to(device)y = torch.zeros_like(x).to(device)cond = x ** 2return x.requires_grad_(True), y.requires_grad_(True), conddef up(n=N1):# 边界 u(x,1)=x^2/ex = torch.rand(n, 1).to(device)y = torch.ones_like(x).to(device)cond = x ** 2 / torch.ereturn x.requires_grad_(True), y.requires_grad_(True), conddef left(n=N1):# 边界 u(0,y)=0y = torch.rand(n, 1).to(device)x = torch.zeros_like(y).to(device)cond = torch.zeros_like(x)return x.requires_grad_(True), y.requires_grad_(True), conddef right(n=N1):# 边界 u(1,y)=e^(-y)y = torch.rand(n, 1).to(device)x = torch.ones_like(y).to(device)cond = torch.exp(-y)return x.requires_grad_(True), y.requires_grad_(True), cond'''
# 真实数据模拟
'''
# 真实解的数据点(监督学习),也就是构建真实数据,(x,y,value),因为u=x^2 * exp(-y) 是解析解,所以是利用这个来模拟真实数据
def data_interior(n=N2):# 内点x = torch.rand(n, 1).to(device)y = torch.rand(n, 1).to(device)cond = (x ** 2) * torch.exp(-y)return x.requires_grad_(True), y.requires_grad_(True), cond'''
# 因此综合来说,解决一个PINN的正向问题,需要对应的真实数据,(输入(x,y),输出(value)),边界条件的数据,(x_边界,y_边界,value_边界条件)
# 训练的时候,输入网络输入信息(比如位置或者时间信息等等),输出为值,此时计算其数据loss,
如果是边界的位置上,需要计算其边界loss(因为正常来说,我们能拿到的数据都是中间的那些真实数据,我们都需要手动去构建边界的数据去使其满足边界条件)。
'''
3.5 定义PINN网络
# Neural Network,简单的一个的神经网络。
class MLP(torch.nn.Module):def __init__(self):super(MLP, self).__init__()self.net = torch.nn.Sequential(torch.nn.Linear(2, 32),torch.nn.Tanh(),torch.nn.Linear(32, 32),torch.nn.Tanh(),torch.nn.Linear(32, 32),torch.nn.Tanh(),torch.nn.Linear(32, 32),torch.nn.Tanh(),torch.nn.Linear(32, 1))def forward(self, x):return self.net(x)
# MSEloss,其实就是平方损失,L2距离
# Loss
loss = torch.nn.MSELoss()
3.6 定义求导函数
def gradients(u, x, order=1):"""计算函数 u 对变量 x 的高阶导数。参数:u (torch.Tensor): 待求导的函数输出。x (torch.Tensor): 自变量。order (int): 导数的阶数,默认为 1。返回:torch.Tensor: u 对 x 的导数,阶数为 order。""""""grad函数参数解释:参数名 解释u (outputs) 待求导的结果(标量或向量张量),即你想知道它对某些变量的导数。x (inputs) 自变量,通常是你需要对其求导的张量(需要 requires_grad=True)。grad_outputs=torch.ones_like(u) 通常用于处理非标量输出(比如 u 是向量)。注意:PyTorch 默认只能对标量求导,如果 u 是向量,grad_outputs 代表“如何把 u 合成一个标量”(通过对每个分量乘以 1,然后求和,相当于 $\sum u_i$)。所以这个值填写的是u里面每个数值的权重比例create_graph=True 创建一个可用于高阶导数的计算图(即反向传播的图也支持再次求导)。必须设置为 True 才能求二阶导。only_inputs=True 只计算 inputs 的梯度。一般设为 True。返回的是元组,里面是一个一个tensor,代表了每个input的梯度,如果input是[x,y],那返回的是(tensor([3.]), tensor([2.])),这里只有一个,因此,返回第一个的(也就是对x求导)就行"""if order == 1:return torch.autograd.grad(u, x, grad_outputs=torch.ones_like(u),create_graph=True,only_inputs=True, )[0]# 嵌套求导else:return gradients(gradients(u, x), x, order=order - 1)
3.7 定义损失函数
# 以下7个损失是PDE损失,对每个构造的数据,进行计算loss,包含了6个边界损失和一个数据损失。
def l_interior(u):# 损失函数L1x, y, cond = interior()uxy = u(torch.cat([x, y], dim=1))return loss(gradients(uxy, x, 2) - gradients(uxy, y, 4), cond)def l_down_yy(u):# 损失函数L2x, y, cond = down_yy()uxy = u(torch.cat([x, y], dim=1))return loss(gradients(uxy, y, 2), cond)def l_up_yy(u):# 损失函数L3x, y, cond = up_yy()uxy = u(torch.cat([x, y], dim=1))return loss(gradients(uxy, y, 2), cond)def l_down(u):# 损失函数L4x, y, cond = down()uxy = u(torch.cat([x, y], dim=1))return loss(uxy, cond)def l_up(u):# 损失函数L5x, y, cond = up()uxy = u(torch.cat([x, y], dim=1))return loss(uxy, cond)def l_left(u):# 损失函数L6x, y, cond = left()uxy = u(torch.cat([x, y], dim=1))return loss(uxy, cond)def l_right(u):# 损失函数L7x, y, cond = right()uxy = u(torch.cat([x, y], dim=1))return loss(uxy, cond)# 构造数据损失
def l_data(u):# 损失函数L8x, y, cond = data_interior()uxy = u(torch.cat([x, y], dim=1))return loss(uxy, cond)
3.8 模型训练
# Trainingu = MLP().to(device) # 定义网络
opt = torch.optim.Adam(params=u.parameters()) # 定义优化器for i in range(epochs):opt.zero_grad() # 优化器清除梯度l = l_interior(u) \+ l_up_yy(u) \+ l_down_yy(u) \+ l_up(u) \+ l_down(u) \+ l_left(u) \+ l_right(u) \+ l_data(u)l.backward() # 损失反向传播opt.step() # 优化器,参数更新if i % 100 == 0: # 每一百次,输出现在的进度print(i)3.9 绘制结果图像
# Inference
'''
# 推理,对空间内随便取点,然后利用解析解,解出真实值,然后利用网络得到数值解,最后计算每个之间从距离,得到每个位置的误差,最后绘制出了三个图,真实值图,预测值图,误差值图
'''xc = torch.linspace(0, 1, h).to(device)
xm, ym = torch.meshgrid(xc, xc, indexing='ij')
xx = xm.reshape(-1, 1)
yy = ym.reshape(-1, 1)
xy = torch.cat([xx, yy], dim=1)
u_pred = u(xy)
u_real = xx * xx * torch.exp(-yy)u_error = torch.abs(u_pred-u_real)
u_pred_fig = u_pred.reshape(h,h)
u_real_fig = u_real.reshape(h,h)
u_error_fig = u_error.reshape(h,h)
print("Max abs error is: ", float(torch.max(torch.abs(u_pred - xx * xx * torch.exp(-yy)))))
# 仅有PDE损失 Max abs error: 0.004852950572967529
# 带有数据点损失 Max abs error: 0.0018916130065917969# 作PINN数值解图
fig = plt.figure()
ax = Axes3D(fig)
fig.add_axes(ax)
ax.plot_surface(xm.cpu().detach().numpy(), ym.cpu().detach().numpy(), u_pred_fig.cpu().detach().numpy())
ax.text2D(0.5, 0.9, "PINN", transform=ax.transAxes)
plt.show()
fig.savefig("PINN solve.png")# 作真解图
fig = plt.figure()
ax = Axes3D(fig)
fig.add_axes(ax)
ax.plot_surface(xm.cpu().detach().numpy(), ym.cpu().detach().numpy(), u_real_fig.cpu().detach().numpy())
ax.text2D(0.5, 0.9, "real solve", transform=ax.transAxes)
plt.show()
fig.savefig("real solve.png")# 误差图
fig = plt.figure()
ax = Axes3D(fig)
fig.add_axes(ax)
ax.plot_surface(xm.detach().cpu().numpy(), ym.cpu().detach().numpy(), u_error_fig.cpu().detach().numpy())
ax.text2D(0.5, 0.9, "abs error", transform=ax.transAxes)
plt.show()
fig.savefig("abs error.png")
结果
4.1 真实结果图

4.2 PINN预测结果图

4.3 两者误差图

参考
该篇主要内容基础:PINN解偏微分方程实例1-CSDN博客
github资料:PINNs-for-PDE/PINN_exp1_cs at main · YanxinTong/PINNs-for-PDE