说明:这是一个机器学习实战项目(附带数据+代码+文档),如需数据+代码+文档可以直接到文章最后关注获取。

1.项目背景
在当今数据驱动的时代,回归分析作为预测和建模的重要工具,在科学研究和工业应用中占据着重要地位。BP(Back Propagation)神经网络是一种广泛应用于回归任务的机器学习模型,能够通过非线性映射实现复杂函数的逼近。然而,BP神经网络在训练过程中存在一些固有缺陷,例如对初始权值和阈值敏感、容易陷入局部最优解以及收敛速度慢等问题,这些问题限制了其在高精度回归任务中的表现,尤其是在面对大规模或高维数据时。
为了解决BP神经网络的上述问题,研究者们尝试将智能优化算法引入到神经网络的训练过程中。粒子群优化算法(PSO)作为一种基于群体智能的全局优化方法,因其高效性和易用性备受关注。然而,传统PSO算法在搜索过程中可能存在早熟收敛或搜索效率低下的问题。为此,改进的P-PSO(带压缩因子的粒子群优化算法)应运而生,通过调整粒子的速度更新机制,能够更好地平衡全局探索与局部开发能力,从而为BP神经网络的优化提供更加稳定和高效的解决方案。
本项目旨在结合P-PSO算法与BP神经网络,构建一个高性能的回归预测模型,用于解决复杂的非线性回归问题。通过使用P-PSO优化BP神经网络的初始权值和阈值,提升模型的预测精度和泛化能力,同时加快收敛速度并降低陷入局部最优的风险。该项目不仅具有重要的理论研究意义,还能够在实际场景中广泛应用,如能源消耗预测、股票价格趋势分析和环境监测等领域,为相关行业提供更加精准的数据驱动决策支持工具。
本项目通过Python实现P-PSO优化算法优化BP神经网络回归模型项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | x1 | |
| 2 | x2 | |
| 3 | x3 | |
| 4 | x4 | |
| 5 | x5 | |
| 6 | x6 | |
| 7 | x7 | |
| 8 | x8 | |
| 9 | x9 | |
| 10 | x10 | |
| 11 | y | 因变量 |
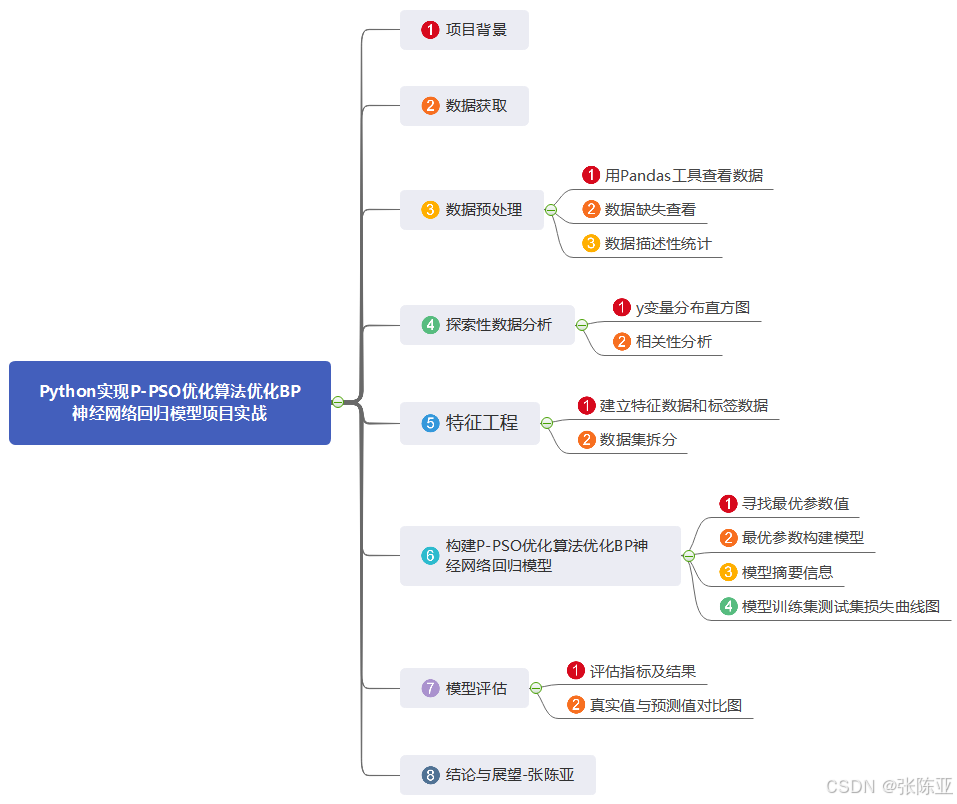
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
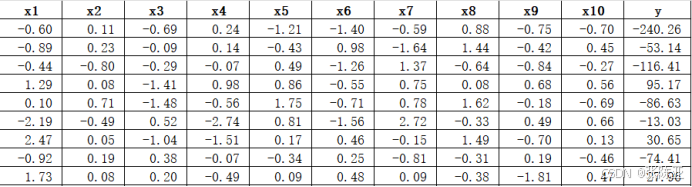
使用Pandas工具的info()方法查看数据信息:
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

3.3数据描述性统计
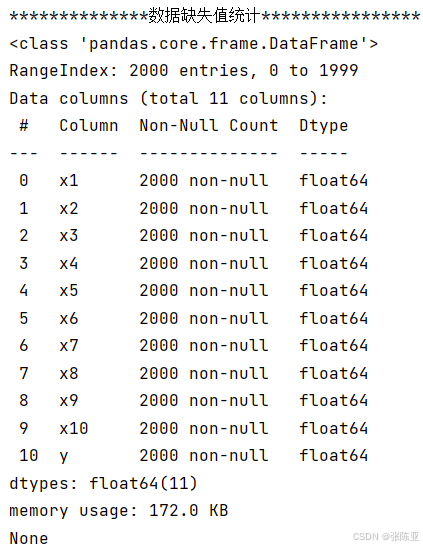
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:

4.探索性数据分析
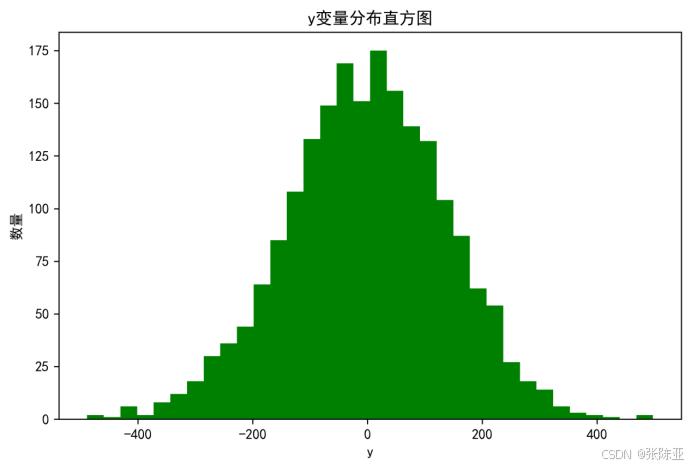
4.1 y变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.2 相关性分析
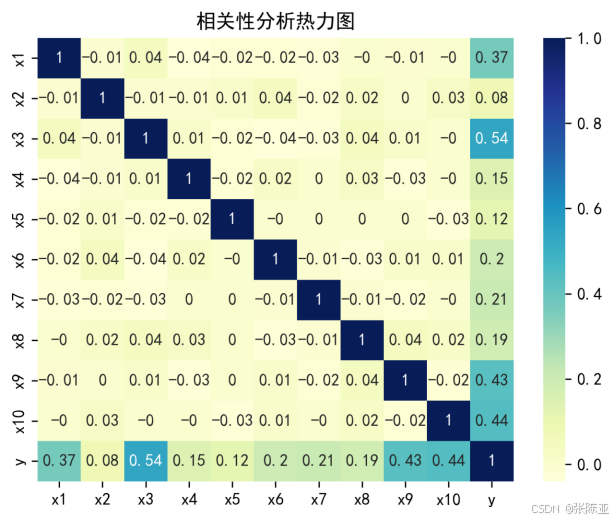
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:

6.构建P-PSO优化算法优化BP神经网络回归模型
主要使用通过P-PSO优化算法优化BP神经网络回归模型,用于目标回归。
6.1 寻找最优参数值
最优参数值:

6.2 最优参数构建模型
| 编号 | 模型名称 | 参数 |
| 1 | BP神经网络回归模型 | units=best_units |
| 2 | optimizer = tf.keras.optimizers.Adam(best_learning_rate) | |
| 3 | epochs=best_epochs |
6.3 模型摘要信息

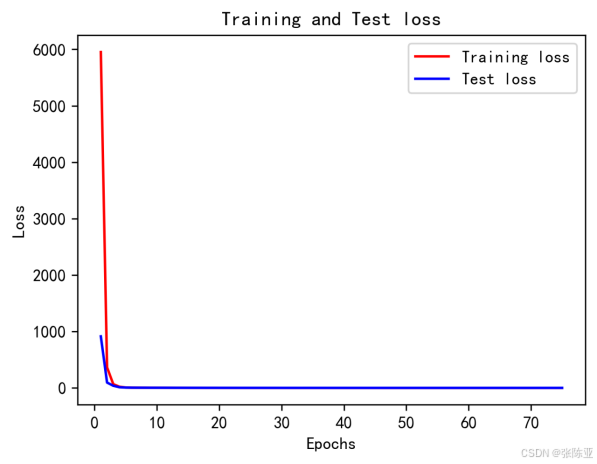
6.4 模型训练集测试集损失曲线图
7.模型评估
7.1评估指标及结果
评估指标主要包括R方、均方误差、解释性方差、绝对误差等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| BP神经网络回归模型 | R方 | 1.0 |
| 均方误差 | 0.6383 | |
| 解释方差分 | 1.0 | |
| 绝对误差 | 0.6169 | |
从上表可以看出,R方分值为1.0,说明模型效果很好。
关键代码如下:

7.2 真实值与预测值对比图
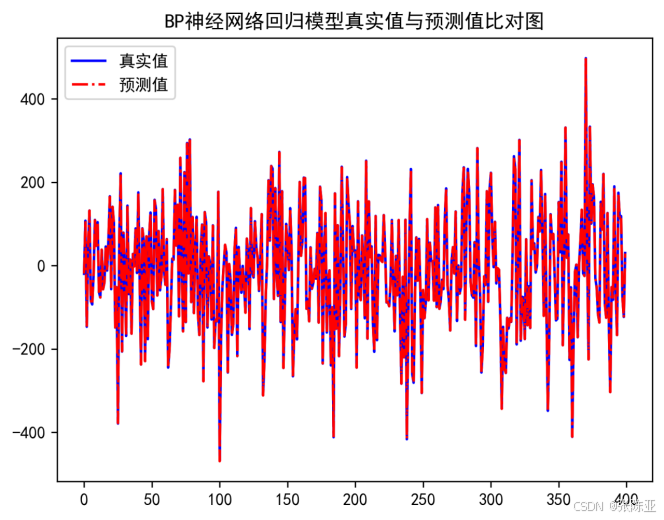
从上图可以看出真实值和预测值波动基本一致,模型效果很好。
8.结论与展望
综上所述,本文采用了Python实现P-PSO优化算法优化BP神经网络回归算法来构建回归模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。