目录
(0)string和char *的区别
(1)string类对象的构造
(2)容量操作
(3)访问遍历
1.用下标访问和遍历
2.用迭代器访问和遍历
①迭代器说明
②迭代首尾注意事项
③使用举例
3.用"范围for"访问和遍历(c++11特性)
4.用for+auto关键字(c++11特性)
(4)增删改查
1.相关接口说明
2.使用例子
3.一些细节说明
①push_back优化插入数据效率
②find和rfind说明
③npos说明
④find_first_of()和find_last_of()
⑤linux环境下c_str()问题
⑥substr说明
⑦replace替换
⑧erase删除
⑨insert插入
(5)牛刀小试
1.仅仅反转字母
2.字符串中的第一个唯一字符
3.字符串最后一个单词的长度
4.验证回文串
5.整数字符串相加
(6)c++中string的assign方法使用
(7)string常用算法
(8)相关工具函数
去掉两端空格
获取子串出现的次数
(0)string和char *的区别
string是STL的字符串类型,通常用来表示字符串。而在使用string之前,字符串通常是用char*表示的。string与char*都可以用来表示字符串,那么二者有什么区别呢:
- string是一个类,,char*是一个指向字符的指针。string封装了char*,管理这个字符串,是一个char*型的容器。
- string不用考虑内存释放和越界。string管理char*所分配的内存。每一次string的复制,取值都由string类负责维护,不用担心复制越界和取值越界等。
- string提供了一系列的字符串操作函数,比如查找find,拷贝copy,删除erase,替换replace,插入insert
(1)string类对象的构造
#include <iostream>
#include <string>
using namespace std;int main()
{// 1.构造空的string类对象s1string s1;// 2.用C格式字符串构造string类对象s2 string s2("hello world"); string s3 = "hello world";// 3.拷贝构造string s4(s2); // 地址都不相同printf("%p,%p,%p", &s2, &s3, &s4); // 000000000061fdc0,000000000061fda0,000000000061fd80// 4.初始化由n个相同字符组成的字符串string s6(4, '6'); string s7 = string(4, '7'); // 5.将s6赋值给s1s1.assign(s6); // 6.将数组直接赋值给stringchar name[7] = "601669";string x = name;cout << x.c_str() << endl; // 601669cout << x.size() << endl; // 6return 0;
}(2)容量操作
常用容量属性/方法
- size 返回字符串有效字符长度
- length 返回字符串有效字符长度
- capacity 返回空间总大小
- empty 检测字符串是否为空串,是返回true,否则返回false
- clear 清空有效字符
- reserve 改变字符串空间总大小,即为string预留空间
- resize 将有效字符的个数改成n个,多出的空间用字符c填充
说明:
- size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()。
- clear()只是将string中有效字符清空,不改变底层空间大小。
- resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。
- resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
- reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数。
用法举例
#include <iostream>
#include <string>
using namespace std;int main()
{string s1 = "hello world";cout << s1 << endl;cout << s1.size() << endl; // 11cout << s1.length() << endl; // 11cout << s1.capacity() << endl; // 15// 将s1中的字符串清空,注意清空时只是将size清0,不改变底层空间的大小cout << "---------------------" << endl;s1.clear(); // 空cout << s1 << endl;cout << s1.size() << endl; // 0cout << s1.capacity() << endl; // 15// 判断是否为空字符串if (s1.empty())cout << "s1 = empty" << endl; // s1 = emptyelsecout << "s1 != empty" << endl;string s2;if (s2.empty())cout << "s2 = empty" << endl; // s2 = emptyelsecout << "s2 != empty" << endl;// 将s1中有效字符个数增加到20个,多出位置用'a'进行填充cout << "---------------------" << endl;s1.resize(20, 'a');cout << s1 << endl; // aaaaaaaaaaaaaaaaaaaacout << s1.size() << endl; // 20cout << s1.capacity() << endl; // 30// 将s1中有效字符个数减少到15个cout << "---------------------" << endl;s1 = "hello world study hard";s1.resize(15);cout << s1 << endl; // hello world stucout << s1.size() << endl; // 15cout << s1.capacity() << endl; // 30// 测试reserves1.reserve(100);cout << s1.size() << endl; // 15 //说明不会改变string中有效元素个数cout << s1.capacity() << endl; // 100s1.reserve(50);cout << s1.size() << endl; // 15cout << s1.capacity() << endl; // 50return 0;
}(3)访问遍历
1.用下标访问和遍历
#include <iostream>
#include <string>
using namespace std;int main()
{// 1.直接下标访问string s1("hello world");const string s2("Hello world");cout << s1 << " " << s2 << endl; cout << s1[0] << " " << s2[0] << endl; s1[0] = 'H';cout << s1 << endl; // Hello world// 2.使用for遍历所有字符string s("hello world");for (size_t i = 0; i < s.size(); ++i)cout << s[i];cout << endl;return 0;
}2.用迭代器访问和遍历
①迭代器说明
迭代器是一种抽象的概念,它类似于指针,但比指针更加通用和安全。迭代器封装了底层数据结构的访问细节,为算法提供了一种统一的接口来遍历和操作容器中的元素。通过迭代器,算法可以无需关心容器的具体实现细节,只需按照迭代器的规则进行操作即可。
对于容器而言,每个位置的数据都对应一个迭代器。
迭代器有很多种类,这里以正向迭代器为例说明,现在我们有字符串对象s,常见操作如下
// 获取首位置的迭代器
string::iterator it = s.begin()// 获取迭代器指向位置的数据
cout << *it;// 获取末位置的迭代器
string::iterator it = s.end()// 用迭代器遍历全部数据
string::iterator it = s.begin()
while (it != s.end()) {cout << *it;++it;
}②迭代首尾注意事项
这里还有一个细节,这个首尾具体指的哪一个数据?见下图
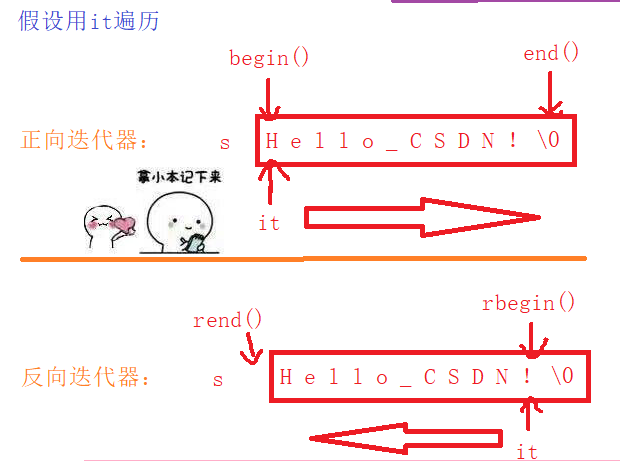
③使用举例
#include <iostream>
#include <string>
using namespace std;int main()
{string s("hello world");// 1.正向迭代器访问和遍历string::iterator it = s.begin();while (it != s.end()){cout << *it;++it;}cout << endl;// 2.反向迭代器访问和遍历string::reverse_iterator rit = s.rbegin(); while (rit != s.rend()){cout << *rit;++rit;}cout << endl;// 3.改值string::iterator tp = s.begin();string::iterator &tmp = tp;while (tmp != s.end()){(*tmp)++;++tmp;}cout << s << endl;return 0;
}3.用"范围for"访问和遍历(c++11特性)
#include <iostream>
#include <string>
using namespace std;int main()
{string s("hello world");// 普通使用for (char e: s) {cout << e;}cout << endl;// 加上引用for (char &e : s){e += 1;}// 再加一个const,变为不可修改for (const char &e : s)cout << e;cout << endl;return 0;
}4.用for+auto关键字(c++11特性)
用auto,自动判断类型,更加灵活高级
#include <iostream>
#include <string>
using namespace std;int main()
{string s("hello world");// 可修改for (auto &e : s){e += 1;}// 不可修改for (const auto &e : s)cout << e;cout << endl;return 0;
}(4)增删改查
1.相关接口说明
| 函数名称 | 功能与用法 |
| push_back | 在字符串后尾插字符c |
| append | 在字符串后追加一个字符串
|
| operator+= | (常用) 在字符串后追加字符串str。string和string,string和字符数组可直接相加。对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。 |
| c_str | (常用) 返回C格式字符串 |
| 结合npos进行find | (常用) 从字符串pos位置(默认开始位置)开始往后找字符c,返回该字符在字符串中的位置。找不到时返回std::string::npos |
| rfind | 从字符串pos位置(默认最后面)开始往前找字符c,返回该字符在字符串中的位置 |
| substr | 在str中从pos位置开始,截取n个字符,然后将其返回 |
| erase | erase(int pos=0, int n=npos); //删除pos开始的n个字符,返回修改后的字符串 |
| replace | 字符串的替换 replace(int pos, int n, const char *s);//删除从pos开始的n个字符,然后在pos处插入串s replace(int pos, int n, const string &s); //删除从pos开始的n个字符,然后在pos处插入串s |
| swap | void swap(string &s2); //交换当前字符串与s2的值 |
2.使用例子
#include <iostream>
#include <string>
using namespace std;int main()
{string str;// 1.追加操作str.push_back(' '); // 在str后插入空格cout << "(" << str << ")" << endl; // ( )str.append("Hello"); // 在str后追加一个字符"Hello"str += 'X'; // 在str后追加一个字符'X'str += "world"; // 在str后追加一个字符串"world"cout << "(" << str << ")" << endl; // ( HelloXworld)// 2.c_str 的意义cout << "(" << str.c_str() << ")" << endl; // 以C语言的方式打印字符串printf("(%s)\n", str.c_str()); // c_str 的意义// printf("%s\n", str); // 类型不匹 乱码// 3.用rfind和substr获取file的后缀string file("string.cpp");size_t pos = file.rfind('.');cout << pos << endl; // 6string suffix(file.substr(pos, file.size() - pos));cout << suffix << endl; //.cpp// 4. npos// npos是string里面的一个静态成员变量// static const size_t npos = -1;// string::npos是一个静态成员常量,表示size_t的最大值// std::string::npos// 该值表示直到字符串结尾,作为返回值它通常被用作表明没有匹配。// 5.用find、npos和substr取出url中的域名string url("http://www.cplusplus.com/reference/string/string/find/");cout << url << endl;string key("://");size_t start = url.find(key); // 如果找到返回第一个字符所在位置if (start == string::npos) // 没有找到 返回的是nposcout << "invalid url" << endl;else{string result(url.substr(start + key.size(), url.size() - start - key.size()));cout << result << endl; // www.cplusplus.com/reference/string/string/find/}// 6.用erase删除url的协议前缀size_t mypos = url.find("://");url.erase(0, mypos + 3);cout << url << endl; // www.cplusplus.com/reference/string/string/find/return 0;
}
3.一些细节说明
①push_back优化插入数据效率
当字符串空间总大小不够而需要追加字符时,会扩展一定容量
如果每次追加都要扩容一下,那么开销明显增大
可以利用reserve提前预备好足够的容量提高效率
#include <iostream>
#include <string>
using namespace std;// 利用reserve提高插入数据的效率,避免增容带来的开销
void TestPushBack()
{string s;size_t sz = s.capacity();cout << sz << endl;cout << "making s grow:\n";for (int i = 0; i < 100; ++i){s.push_back('c');if (sz != s.capacity()){sz = s.capacity();cout << "i = " << i << ", capacity changed: " << sz << '\n';}}
}void TestPushBackReserve()
{string s;s.reserve(100);size_t sz = s.capacity();cout << sz << endl;cout << "making s grow:\n";for (int i = 0; i < 100; ++i){s.push_back('c');if (sz != s.capacity()){sz = s.capacity();cout << "i = " << i << ", capacity changed: " << sz << '\n';}}
}int main()
{// 当字符串空间总大小不够而需要追加字符时,会扩展一定容量TestPushBack();// 提前准备好充足的容量TestPushBackReserve();return 0;
}②find和rfind说明
- int find(char c,int pos=0) const; //从pos开始查找字符c在当前字符串的位置
- int find(const char *s, int pos=0) const; //从pos开始查找字符串s在当前字符串的位置
- int find(const string &s, int pos=0) const; //从pos开始查找字符串s在当前字符串中的位置
- int rfind(char c, int pos=npos) const; //从pos开始从后向前查找字符c在当前字符串中的位置
- int rfind(const char *s, int pos=npos) const;
- int rfind(const string &s, int pos=npos) const;
find函数如果查找不到,就返回std::string::npos(是-1)
rfind是反向查找的意思,如果查找不到, 返回std::string::npos(是-1)
使用例子
#include <iostream>
#include <string>
using namespace std;int main()
{string str = "hello world";size_t pos1 = str.find('o');size_t pos2 = str.rfind('o');cout << pos1 << endl; // 4cout << pos2 << endl; // 7size_t pos3 = str.find('o', 5); // 从第五个位置开始找cout << pos3 << endl; // 7size_t pos4 = str.rfind('o', 5); // 从第五个位置开始找cout << pos4 << endl; // 4return 0;
}查看不到则返回std::string::npos
#include <iostream>
using namespace std;#include <string>int main()
{string xx = "601998,601669";cout << xx.find("601998") << endl; // 0cout << xx.find("123") << endl; // 18446744073709551615if (xx.find("123") == std::string::npos){cout << "xxx" << endl; // 会执行此语句}return 0;
}③npos说明
string::npos是一个静态成员常量,表示size_t的最大值(Maximum value for size_t)。该值表示“直到字符串结尾”,作为返回值它通常被用作表明没有匹配。
string::npos是这样定义的:
static const size_type npos = -1;因为string::size_type描述的是size,故需为无符号整数型类别。因为缺省配置为size_t作为size_type,于是-1被转换为无符号整数类型,npos也就成为了该类别的最大无符号值。不过实际值还是取决于size_type的实际定义类型,即无符号整型(unsigned int)的-1与无符号长整型(unsigned long)的-1是不同的。
如果对 -1表示size_t的最大值有疑问可以采用如下代码验证:
#include <iostream>
#include <limits>
#include <string>
using namespace std;int main()
{size_t npos = -1;cout << "npos: " << npos << endl;cout << "size_t max: " << numeric_limits<size_t>::max() << endl;
}④find_first_of()和find_last_of()
find_first_of()函数
正向查找在原字符串中第一个与指定字符串(或字符)中的某个字符匹配的字符,返回它的位置。若查找失败,则返回npos。
- string str=“abcdefab”;
- cout<<str.find_first_of(“hce”)<<endl;//待查串hce第一个出现在原串str中的字符是c,返回str中c的下标2,故结果为2。第二个参数为0,默认从原串下标为0开始正向查。
- cout<<str.find_first_of(“ab”,1)<<endl;//从下标为1开始查,待查串ab第一个出现在原串str中的字符是b,返回b的下标,结果为1。
find_last_of()函数
逆向查找在原字符串中最后一个与指定字符串(或字符)中的某个字符匹配的字符,返回它的位置。若查找失败,则返回npos。
- string str=“abcdefab”;
- cout<<str.find_last_of(“wab”)<<endl;//原串最后一个字符首先与待查子串的每一个字符一一比较,一旦有相同的就输出原串该字符的下标.。结果为b的下标7。第二个参数为0,默认为npos。
- cout<<str.find_last_of(“wab”,5)<<endl;//从原串中下标为5开始逆向查找,首先f与待查子串每一字符比较,若有相同的就输出该字符在原串的下标。若一个都没有,就依次逆向比较,即e再与待查子串一一比较,直到原串的b与待查子串中的b相同,然后输出该b在原串的下标1。
find和find_first_of的区别
find()和rfind()可以说是完全匹配查询,而find_first_of()和find_last_of()可以说是部分匹配。 但它们的返回值都是原串某字符的下标,是无符号整数类型。如果待查为字符串的话,前者可以说是字符串与字符串的比较,后者可以说是字符与字符的比较。需要好好体会。
代码加深理解
#include<iostream>
using namespace std;int main()
{string str="abcdefab";cout<<str.find_first_of('a')<<endl; // 0cout<<str.find_first_of("hce")<<endl; // 2cout<<str.find_first_of("ab",1)<<endl; // 1cout<<str.find_first_of('h')<<endl; // npos,也就是-1cout<<str.find_first_of("hw")<<endl; // npos。cout<<str.find_last_of("wab")<<endl; // 7cout<<str.find_last_of("wab", 5)<<endl; // 1cout<<str.find_last_of("fab",5)<<endl; // 5cout<<str.find_last_of("fab",7)<<endl; // 7cout<<str.find_last_of("hwk")<<endl; //npos。return 0;
}⑤linux环境下c_str()问题
c_str()返回一个以'\0'结尾的字符串的首地址,但在linux下使用c_str()可能会出现一点问题,这里做了记录与解决办法:
问题描述:将string用.c_str()转化为C语言的字符串后,在字符最后可能会多出一个乱码
示例代码
#include <iostream>
using namespace std;
#include <string>
#include <cstring>void func(string code)
{cout << code << endl;cout << code.c_str() << endl;for (int i = 0; i < strlen(code.c_str()); i++){cout << "(" << code.c_str()[i] << ")" << endl;}
}int main()
{string testcode = "601998.SH";func(testcode);return 0;
}错误结果如下,可以看到结尾多了一个乱码字符。然后就是因为多的这个乱码字符,导致在使用strcat(filepath, code.c_str())后再使用strcat(filepath, ".csv");出现了结果上的错误。
601998.SH
601998.SH
(6)
(0)
(1)
(9)
(9)
(8)
(.)
(S)
(H)
)
解决办法
根据实际需要判断string.c_str()的最后一个字符是不是乱码,通常若string.c_str()的长度比string长,则多出来的部分为乱码,则需将code.c_str()的最后一个字符或者倒数某个字符变成 0 或者'\0'
#include <iostream>
using namespace std;
#include <string>
#include <cstring>void read_grid_info(string code)
{char filepath[100] = {0};sprintf(filepath, "%s", "../grid/");strcat(filepath, code.c_str());size_t diff = strlen(code.c_str()) - code.size();if (diff > 0) {filepath[strlen(filepath) - diff] = 0;}strcat(filepath, ".csv");cout << filepath << endl;}int main()
{string testcode = "601998.SH";read_grid_info(testcode);return 0;
}输出结果
../grid/601998.SH.csv⑥substr说明
- 形式 : s.substr(pos, len)
- 返回值: string,包含s中从pos开始的len个字符的拷贝(pos的默认值是0,len的默认值是s.size() - pos,即不加参数会默认拷贝整个s)
- 异常 :若pos的值超过了string的大小,则substr函数会抛出一个out_of_range异常;若pos+n的值超过了string的大小,则substr会调整n的值,只拷贝到string的末尾
⑦replace替换
需求:把小写wbm===>WBM
#include <iostream>
#include <string>using namespace std;int main()
{string s1 = "wbm hello wbm 111 wbm 222 wbm 333 ";// 把小写wbm===>WBMsize_t offindex = s1.find("wbm", 0);while (offindex != string::npos){cout << "offindex:" << offindex << endl;// 从offindex位置起的3个字符替换为"WBM"s1.replace(offindex, 3, "WBM");offindex = offindex + 3;offindex = s1.find("wbm", offindex); }cout << s1 << endl;// WBM hello WBM 111 WBM 222 WBM 333return 0;}⑧erase删除
需求:将字符串中的hello全部删除
#include <iostream>
#include <string>using namespace std;int main()
{string s1 = "hello world, hello string";// 将string中的hello全部删除string part = "hello";size_t i = s1.find(part, 0);while (i != std::string::npos){s1.erase(i, part.size());i = s1.find(part, 0);cout << "(" << s1 << ")" << endl;}// ( world, hello string)// ( world, string)cout << "(" << s1 << ")" << endl; // ( world, string)return 0;}⑨insert插入
需求:在字符串指定位置插入新的子串
#include <iostream>
#include <string>using namespace std;int main()
{string s2 = "BBB";// 在位置0处插入数据s2.insert(0, "AAA"); cout << s2 << endl; // AAABBB// 在末尾插入数据s2.insert(s2.size(), "CCC");cout << s2 << endl; // AAABBBCCCreturn 0;}(5)牛刀小试
1.仅仅反转字母
力扣题目:917. 仅仅反转字母 - 力扣(LeetCode)
class Solution {
public:string reverseOnlyLetters(string s) {size_t left = 0 , right = s.size() - 1;while(left < right){while(left < right && !isalpha(s[left])){left++;}while(left < right && !isalpha(s[right])){right--;}if(left < right){swap(s[left] , s[right]);right--;left++;}}return s;}
};2.字符串中的第一个唯一字符
力扣题目:387. 字符串中的第一个唯一字符 - 力扣(LeetCode)
class Solution {
public:int firstUniqChar(string s) {int count[26] = { 0 };for(int i = 0; i < s.size() ; i++){count[s[i] - 'a']++;}for(int i = 0; i < s.size() ; i++){if(count[s[i] - 'a'] == 1)return i;}return -1;}
};
3.字符串最后一个单词的长度
牛客题目:字符串最后一个单词的长度_牛客题霸_牛客网
#include<iostream>
#include<string>
using namespace std;
int main()
{string s;getline(cin, s);size_t pos = s.rfind(' ');cout << s.size() - pos - 1 << endl;return 0;
}4.验证回文串
力扣题目:125. 验证回文串 - 力扣(LeetCode)
class Solution {
public:bool isLetterOrNumber(char ch){return (ch >= '0' && ch <= '9')|| (ch >= 'a' && ch <= 'z')|| (ch >= 'A' && ch <= 'Z');}bool isPalindrome(string s) {// 先将小写字母转换成大写,再判断for(auto& ch : s){if(ch >= 'a' && ch <= 'z')ch -= 32;}int begin = 0, end = s.size() - 1;while(begin < end){while(begin < end && !isLetterOrNumber(s[begin]))begin++;while(begin < end && !isLetterOrNumber(s[end]))end--;if(s[begin] != s[end])return false;else{begin++;end--;}}return true;}
};5.整数字符串相加
力扣题目:415. 字符串相加 - 力扣(LeetCode)
class Solution {
public:string addStrings(string num1, string num2) {int end1 = num1.size() - 1;int end2 = num2.size() - 1;int value1 = 0, value2 = 0, next = 0;string addret; // 用来接收相加后的值while(end1 >= 0 || end2 >= 0){if(end1 >= 0)value1 = num1[end1--] - '0';elsevalue1 = 0;if(end2 >= 0)value2 = num2[end2--] - '0';elsevalue2 = 0;int valueret = value1 + value2 + next;if(valueret >= 10){valueret -= 10;next = 1;}elsenext = 0;addret += valueret + '0';}if(next == 1){addret += '1';}reverse(addret.begin(),addret.end());return addret;}
};(6)c++中string的assign方法使用
①assign的声明
string的实际.h和.cpp文件是basic_string.h 和basic_string.tcc,所以string中assign也在这两个文件声明和定义;
basic_string& assign(const basic_string& __str)
basic_string& assign(basic_string&& __str)
basic_string& assign(const basic_string& __str, size_type __pos, size_type __n)
basic_string& assign(const _CharT* __s, size_type __n)
basic_string& assign(const _CharT* __s)
basic_string& assign(size_type __n, _CharT __c)
basic_string& assign(_InputIterator __first, _InputIterator __last)
basic_string& assign(initializer_list<_CharT> __l) ②assign是赋值运算符
其实string的赋值运算符basic_string& operator=(const basic_string& __str)就是调用了assign方法。赋值运算符就是简单的包装了assign方法:
basic_string&
operator=(const basic_string& __str)
{ return this->assign(__str); }其中:basic_string& assign(const basic_string& __str)的定义:
basic_string&
assign(const basic_string& __str)
{this->_M_assign(__str);return *this;
}
所以:
string s1;
string s2;
s1=s2;
s1.assign(s2); //是等效的具体用法:
- string &operator=(const string &s); //把字符串s赋给当前的字符串
- string &assign(const char *s); //把字符串s赋给当前的字符串
- string &assign(const char *s, int n); //把字符串s的前n个字符赋给当前的字符串
- string &assign(const string &s); //把字符串s赋给当前字符串
- string &assign(int n,char c); //用n个字符c赋给当前字符串
- string &assign(const string &s,int start, int n); //把字符串s中从start开始的n个字符赋给当前字符串
③例子
#include <iostream>
#include <string>
using std::string;int main()
{string s1; // 默认初始化,s1是一个空的字符串string s6(4, '6'); // 初始化n个字符'6‘串成的字符串s1.assign(s6); // 将s6赋值给s1return 0;
}(7)string常用算法
#include <iostream>
#include <string>
#include <algorithm> // STL算法对应的头文件using namespace std;// string算法相关
int main()
{// 1.查找数据string s1 = "hello world";string::iterator it = find(s1.begin(), s1.end(), 'h');if ( it != s1.end()){// 打印对应的字符cout << *it << endl; // h}// 2.删除数据string s2 = "hello world";// 将s2全部删除s2.erase(s2.begin(), s2.end());cout << s2.size() << endl; // 0string s3 = "hello world";// 将s3中的l全部删除string::iterator m_it = find(s3.begin(), s3.end(), 'l');while ( m_it != s3.end() ){s3.erase(m_it, m_it+1);m_it = find(s3.begin(), s3.end(), 'l');cout << "[" << s3 << "]" << endl;}// [helo world]// [heo world]// [heo word]string s4 = "my new book name is your new book name";// 将s4中的name全部删除string part = "name";m_it = find(s4.begin(), s4.end(), part[0]);while (m_it != s4.end()){// cout << *m_it << endl;bool is_find = true;for (int i = 0; i < part.size(); i++){string::iterator temp = m_it + i;if (*temp != part[i]){is_find = false;}}if (is_find){s4.erase(m_it, m_it+part.size());cout << "[" << s4 << "]" << endl;}m_it++;m_it = find(m_it, s4.end(), part[0]);}// [my new book is your new book name]// [my new book is your new book ]// 3.使用transform和toupper进行大小写转化// toupper, tolowerstring s5 = "AAAbbb";// transform(s5.begin(), s5.end(), s5.begin(), toupper);// 报错no matching function for call to 'transform(std::__cxx11::basic_string<char>// 错误原因:既有C版本的toupper/tolower函数,又有STL模板函数toupper/tolower,二者存在冲突// 解决办法:在toupper/tolower前面加::,强制指定是C版本的transform(s5.begin(), s5.end(), s5.begin(), ::toupper);cout << s5 << endl; // AAABBBtransform(s5.begin(), s5.end(), s5.begin(), ::tolower);cout << s5 << endl; // aaabbbreturn 0;}(8)相关工具函数
去掉两端空格
#include <iostream>
#include <string>std::string remove_left_right_space(std::string src)
{int is_all_space = 1;for (size_t i = 0; i < src.size(); i++){if (src.substr(i, 1) != " "){is_all_space = 0;}}if (is_all_space == 1){return "";}std::string dst = src;size_t index;// deal leftstd::string dst2 = dst;if (dst.substr(0, 1) == " "){size_t start;for (size_t i = 0; i < dst.size(); i++){if (dst.substr(i, 1) == " "){start = i;}else{break;} }dst2 = dst.substr(start+1);}// deal rightstd::string dst3 = dst2;if (dst2.substr(dst2.size()-1, 1) == " "){size_t end;for (size_t i = dst2.size() - 1; i >= 0; i--){if (dst2.substr(i, 1) == " "){end = i;}else{break;} }dst3 = dst2.substr(0, end);}return dst3;
}int main()
{std::string src = " hello world ";src = remove_left_right_space(src);std::cout << "(" << src << ")" << std::endl; // (hello world)
}获取子串出现的次数
#include <iostream>
#include <string>using namespace std;size_t CountSubstr(const string &data, const string &substr)
{// 函数作用:获取data中substr的出现次数int index = data.find(substr, 0);size_t ret = 0;while (index != string::npos) {// cout << index << endl;ret++;index++;index = data.find(substr, index);}return ret;
}int main()
{string s1 = "wbm hello wbm 111 wbm 222 wbm 333 ";// 需求:查找wbm的出现次数cout << CountSubstr(s1, "wbm") << endl;return 0;}end



![[Java 基础]打印金字塔](https://i-blog.csdnimg.cn/img_convert/038d5b5699da962cbdb9127c227d33c9.png)