Revisiting Knowledge Distillation for Autoregressive Language Models
发表:ACL 2024
机构:School of Computer Science
Abstract
知识蒸馏(Knowledge Distillation, KD)是一种常见的方法,用于压缩教师模型,以减少其推理成本和内存占用,通过训练一个更小的学生模型来实现。然而,在自回归语言模型(autoregressive LMs)的背景下,我们通过实验证明:更大的教师模型反而可能导致更差的学生模型表现。针对这一问题,我们进行了系列分析,发现不同的 token 在教学过程中有不同的“教学模式”,而忽视这一点会导致性能下降。受此启发,我们提出了一种简单而有效的自适应教学方法(Adaptive Teaching for Knowledge Distillation,简称 ATKD),以改进知识蒸馏过程。ATKD 的核心思想是:减少机械记忆式的学习,让教学变得更加多样化和灵活。我们在 8 个语言模型任务上进行了广泛实验,结果表明:借助 ATKD,各种基础的 KD 方法在所有模型类型和规模上都能实现一致且显著的性能提升,平均分数最高提升达 +3.04%。更令人鼓舞的是,ATKD 还能有效提升学生模型的泛化能力。
1 Introduction
自回归语言模型(Autoregressive Language Models,LMs),如 GPT-4(OpenAI, 2023)、PaLM(Chowdhery 等, 2023)和 LLaMA2(Touvron 等, 2023),在众多任务中取得了巨大成功(Zhong 等, 2023;Peng 等, 2023b;Lu 等, 2023)。然而,随着模型规模的扩展,这些语言模型的推理和部署变得越来越计算密集和内存消耗大,从而阻碍了其在工业场景中的应用发展。因此,在尽可能保持性能的前提下压缩这些模型、加速推理过程是十分关键且环保的(Schwartz 等, 2020)。
为实现这一目标,知识蒸馏(Knowledge Distillation, KD)是一种常用方法,旨在通过将大型教师模型的知识“蒸馏”到一个较小的学生模型中,从而压缩模型规模(Hinton 等, 2015;Kim 和 Rush, 2016)。近年来,针对自回归语言模型的知识蒸馏,已有多种新颖的学习算法被提出,以提升蒸馏效果(Wen 等, 2023;Agarwal 等, 2024)。尽管这些方法取得了显著的成果,但我们在实验中却发现一个反直觉的现象:当教师模型过大时,学生模型的性能反而会显著下降,尤其是当师生模型之间能力差距较大时。
如图 1 所示,当教师模型规模过大时,学生模型的性能会下降,这一现象也在其他研究中被观察到(Mirzadeh 等, 2020;Cho 和 Hariharan, 2019;Zhang 等, 2023)。
尽管已有一些工作尝试研究并缓解这一问题,但大多集中在视觉模型(Mirzadeh 等, 2020;Cho 和 Hariharan, 2019)或判别式语言理解模型上(Zhang 等, 2023),而针对生成式自回归语言模型的知识蒸馏仍缺乏系统研究。
在本研究中,我们从蒸馏目标(distillation objective)的角度出发,重新审视这一问题,这是自回归蒸馏的核心所在。具体而言,我们以经典的基于 token 的知识蒸馏目标 —— 正向 KL 散度(forward KL-Divergence)为例,对其进行了重新分解,划分为两个部分:
-
目标导向的知识蒸馏(Target-oriented Knowledge Distillation,TKD):促使学生模型学习与目标 token 相关的信息;
-
多样性导向的知识蒸馏(Diversity-oriented Knowledge Distillation,DKD):鼓励学生从教师模型中学习非目标类别中的更多多样性知识。
这两个部分通过一个 token 级别的系数联系在一起,该系数反映了教师模型的“不确定性”,我们称之为不确定性系数(UNC)。
在重构蒸馏目标后,我们对流行的 OPT 系列模型(Zhang 等, 2022)进行了初步分析,发现如下几点:
❶ UNC 可衡量 token 的学习难度,学习难的 token 对蒸馏更为重要;
❷ DKD 对蒸馏贡献更大,但在教师模型较大时会被严重抑制;
❸ TKD 在不同学习难度的 token 上起着不同作用。
基于以上观察,我们得出结论:不同的 token 具有不同的教学模式,而忽视这一点正是当前知识蒸馏方法的一大局限。
为了解决这一问题,我们提出了一种简单但有效的自适应教学方法(Adaptive Teaching for Knowledge Distillation, ATKD),旨在改进蒸馏过程。ATKD 的核心思想是:减少死记硬背式的学习,使教学更加多样化和灵活。具体来说,ATKD 会跳过对易学(信息少)token 的目标导向教学,将更多关注放在难学 token 的多样性学习上。
我们在多个语言建模基准任务上评估了 ATKD,包括 5 个语言生成任务和 3 个语言理解任务,涉及三种自回归语言模型:OPT(Zhang 等, 2022)、Pythia(Biderman 等, 2023)和 LLaMA(Touvron 等, 2023)。结果表明,ATKD 不仅可以缓解教师模型过大带来的性能下降问题,还能在所有模型类型和规模下,为各种基础 KD 方法带来一致且显著的性能提升(平均最高提升 +3.04%)。
此外,与标准 KD 方法相比,ATKD 还能显著提升学生模型的泛化能力。
贡献总结:
我们的主要贡献包括以下三点:
-
我们发现:不同的 token 存在不同的教学模式,忽视这一点会导致蒸馏效果不佳,尤其在使用大型教师模型时更为明显。
-
我们提出了一种简单但有效、即插即用的自适应教学方法(ATKD),以缓解该问题并提升教学质量。
-
大量实验表明,ATKD 相较于标准 KD 方法,可带来高达 +3.04% 的平均性能提升,并有效增强学生模型的泛化能力
2 Rethinking Knowledge Distillation for Autoregressive LMs
在本节中,我们首先深入探讨经典知识蒸馏机制,然后详细介绍我们对该策略的实证分析。
2.1 Recap of Knowledge Distillation

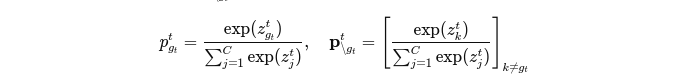
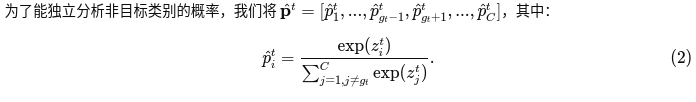

2.2 Empirical Analyses
Setting.
我们首先在 instruction-response 数据集 𝒟 上对较大的语言模型进行微调,使其作为教师模型。然后,我们使用不同的 KD 方法在教师的引导下,在 𝒟 上训练一个较小的学生模型。在实验中,我们使用原始的 OPT-125M 作为学生模型,并使用其他 OPT 系列模型(即 OPT-350M/-1.3B/-2.7B/-6.7B)作为教师模型。Alpaca-GPT4(Peng et al., 2023a)用作训练数据,模型在三个 instruction-following 数据集上进行评估,即 DollyEval(Gu et al., 2023)、VicunaEval(Chiang et al., 2023)和 SelfInst(Wang et al., 2022)。我们遵循 Gu et al. (2023) 的做法,采用 LLM-based 的评估指标 —— 即 LLM-as-a-Judge 来量化模型输出。
具体而言,我们让 GPT-3.5-Turbo-1106⁴ 将模型生成的响应与真实答案进行比较,并对两者打分(1-10 分),然后统计模型输出与真实答案分数总和的比例
Findings.
为了揭示损失函数 𝓛_KL 的局限性,并探索大型教师模型下性能退化的原因,我们进行了系统性的分析,以分别考察 UnC、TKD 和 DKD 的不同影响。通过大量实证分析,我们得到如下观察:
❶ UnC 衡量 token 的学习难度,难学的 token 对 KD 更关键。
受到 token 不平衡性的启发,即一个 token 在句子中的真实重要性取决于其在语义中的贡献(Church and Hanks, 1990;Chen et al., 2020),我们猜想不同的 token 在自回归 KD 中的作用不同。直观地讲,不确定性高的 token 更具信息性,因而更难学。
为了验证这一猜想,我们按照每个 mini-batch 中的 UnC 对 token 排序,并平均分成两个子集。为简洁起见,一个子集(称为“难学集”)包含不确定性排名前 50% 的样本,另一个子集则是剩余样本(称为“易学集”)。我们在不同训练集上使用 vanilla 𝓛_KL 训练学生模型,并展示结果(见图 2)。
显然,在“难学集”上训练的模型效果明显优于“易学集”,甚至超过了全数据训练。这表明具有更高不确定性的 token 通常包含更多“暗知识”(dark knowledge),对 KD 更重要。反过来,由于易学 token 模式浅显,强迫学生学习它们反而会导致过拟合,进而性能变差。更有趣的是,这种现象在大型教师模型中更为明显。
❷ DKD 比 TKD 更重要,但在大教师模型中受到抑制。
为深入分析 TKD 和 DKD 的独立效果,我们比较了以下三种方案的表现:
-
“TKD-only”
-
“DKD-only”
-
“TKD+DKD”(将两者解耦后简单相加,即忽略 UnC 的影响)
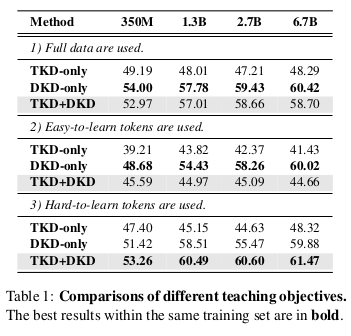
比较不同训练集(如 ❶ 所述)上的对比结果见表 1。
如图所示,“DKD-only” 在各种模型规模和训练集上均显著优于 “TKD-only”,表明在自回归 KD 中,多样性导向的知识(non-target 类)更为重要。然而,正如公式 (4) 所示,我们发现 DKD 的效果受到了 UnC 的强烈抑制。
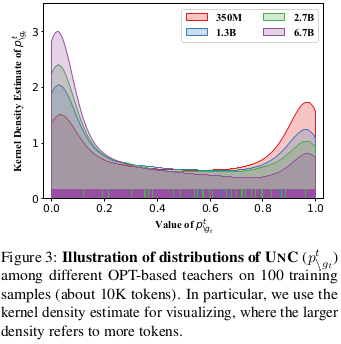
UnC 的范围是 [0, 1],可能导致 DKD 在大模型中难以发挥作用,从而性能下降。为验证此点,我们进一步分析了不同模型大小下 UnC 的分布。在实践中,我们从训练集中随机采样 100 个实例,并展示它们的 UnC 分布(见图 3)。可以看到,在大模型中,UnC 一般更小(趋近于 0),即模型越大,DKD 的效果越受抑制。
此外,“TKD+DKD” 的实验结果也表明,移除 UnC 后能缓解大模型下性能退化的问题(除了对“易学 token”训练,那里需要进一步分析,如 ❸ 所示)。
综上分析,我们验证了:DKD 更重要,但在大模型中被 UnC 抑制,这可能是大教师模型反而带来更差学生模型的根本原因。
❸ TKD 在不同学习难度的 token 上起着不同作用。
我们在表 1 中观察到一个有趣的现象:在“易学集”上进行训练时,将 TKD 添加到 DKD 上(即 “TKD+DKD”)会显著降低性能,相较于仅使用 DKD(例如,准确率从 60.02% 降至 44.66%)。而相反,在“难学集”上,添加 TKD 却带来了显著的性能提升。
这些结果促使我们进一步研究 TKD 在不同类型 token 上的特殊作用。我们通过“α×TKD+DKD”的设定,比较不同 TKD 和 DKD 组合的性能。图 4 展示了不同 α 值下的对比实验结果。可以看到,TKD 在不同训练集中的表现确实不同:
-
TKD 会削弱易学 token 的知识迁移效果;
-
但却有助于难学 token 的学习。
我们将这一现象归因于 token 的学习难度差异。对于易学 token,以目标为导向的学习(TKD)可能会损害学生模型的多样性(Tan et al., 2008);而对于难学 token,添加目标相关的监督信号可以降低其学习难度,从而提升模型性能。
3 Improving Knowledge Distillation with Adaptive Teaching Modes
根据第 §2 节中的观察,我们认识到:不同 token 应采用不同的教学模式,而知识蒸馏在大模型教师上的副作用(即性能下降)主要源于忽视了这一原则。为此,我们提出一种改进的自回归知识蒸馏方法:自适应教学模式(ATKD)。本节将详细介绍 ATKD 方法。
Motivation and Overview of ATKD.除了 §2 节中的实证发现之外,我们的 ATKD 方法还受到一项著名教育倡议 “少教多学(Teach Less, Learn More)” 的启发(Tan et al., 2008)。该倡议强调,减少机械重复的学习、提高教学的多样性与灵活性,有助于提升教学质量和学生学习效果。从直觉上看,由于教师模型与学生模型之间能力差距巨大,对“易学 token”的目标导向学习(target-oriented learning)可能会鼓励学生仅模仿教师的表层模式,而难以学习其“深层知识”(dark knowledge)(Gudibande et al., 2023)。换句话说,学生模型在泛化至更广泛任务时会表现不佳,从而导致性能次优。受到这一点的启发,我们的 ATKD 方法旨在鼓励学生模型针对不同的 token 从不同的角度进行学习。简而言之,ATKD 跳过对易学 token 的目标导向教学,而将更多关注放在难学 token 的多样知识学习上。通过这种方式,ATKD 迫使学生学习更灵活、更多样的知识,从而提升整体性能。
为了实现上述目标,首先需要区分“易学 token”和“难学 token”。正如 §2.2 中的 ❶ 所指出的,UNC(不确定性)可以有效衡量 token 的学习难度,因此我们将 UNC 作为划分依据。具体来说,对于每一个 mini-batch,我们根据 UNC 对训练 token 排序,选取前 k 个 token 作为“难学 token”,其余则为“易学 token”。之后,ATKD 对这些 token 应用如下的自适应教学模式:
如前所述,TKD(Target Knowledge Distillation)和 DKD(Dark Knowledge Distillation)在易学与难学 token 上的作用是不同的。因此,我们不再对所有 token 使用统一的教学策略,而是针对易学与难学 token 分别使用自适应的教学模式。具体而言,我们将 TKD 与 DKD 解耦(即 DKD 不会被 UNC 抑制),以增强学生模型的多样学习能力。
-
对于易学 token:考虑到学生模型很容易学到目标类别信息,我们跳过目标导向教学(即不使用 TKD);
-
对于难学 token:我们同时使用 TKD 和 DKD,因为从实证上看,目标导向教学对于学习这些难点是必不可少的。

4 Evaluation
4.1 Setup
我们在多个语言模型(LM)基准任务上进行了广泛实验,涵盖了多样的语言生成任务(记作 NLG)和语言理解任务(记作NLU)。
具体来说:
-
NLG 包含 5 个广泛使用的生成任务基准:DollyEval(Gu 等,2023)、VicunaEval(Chiang 等,2023 、SelfInst(Wang 等,2022)、Koala(Geng 等,2023)、WizardLM(Xu 等,2023)
-
NLU 包含 3 个主流分类任务:、MMLU(Hendrycks 等,2020)、DROP(Dua 等,2019)、BBH(Suzgun 等,2022)
所有任务的详细信息见附录 A.1。
在 NLG上,我们通过直接评估模型的指令响应输出,报告其零样本性能,并使用 LLM-as-judge 指标进行评估。我们使用 Gu 等(2023)中的相同评估提示词,指示 ChatGPT 判断模型响应的有用性。值得注意的是,对于NLG中的每个查询,我们将最大输出 token 数设置为 256。至于 NLU,我们遵循 Chen 等(2023)的方法,并使用 Chia 等(2023)提供的代码进行基准评估。
具体地说,对于 MMLU(Hendrycks 等,2020),我们使用 5-shot 的直接提示方式,并测量其精确匹配(exact-match)得分;对于 Drop(Dua 等,2019)和 BBH(Suzgun 等,2022),我们使用 3-shot 的直接提示,并报告精确匹配得分。
模型(Models)我们在三种类型、不同规模的语言模型上评估了 ATKD 方法:
-
OPT(Zhang 等,2022):学生模型为 125M,教师模型为 350M、1.3B、2.7B 和 6.7B;
-
Pythia(Biderman 等,2023):学生模型为 410M,教师模型为 1.4B 和 2.8B;
-
LLaMA:学生模型为 68M(Miao 等,2023),教师模型为 1.1B(Zhang 等,2024)和 7B(Touvron 等,2023)。
我们使用 Alpaca-GPT4(Peng 等,2023a)作为训练数据,该数据集包含 52K 个 GPT-4 生成的指令-响应对。
对于教师模型,我们使用的训练批大小为 128,最大学习率为 2e-5;对于学生模型,根据模型规模的不同,学习率从 {2e-4, 2e-5} 中选择,批大小设为 256,最大 tokenizer 长度为 512。所有模型均训练 3 个 epoch,所有实验均在 8 张 NVIDIA A800(80GB)GPU 上进行。
基线(Baselines)在主实验中,我们考虑了 5 个先进的蒸馏(KD)方法作为基线:Supervised KD(Hinton 等,2015)、Reverse KD(Gu 等,2023)、ImitKD(Lin 等,2020)、f-distill(Wen 等,2023)和 GKD(Agarwal 等,2024)。作为参考,我们还报告了教师模型的性能,以作为上限。我们使用 Liu 等(2023)提供的代码库来实现这些基线方法并进行学生模型蒸馏。
4.2 Compared Results
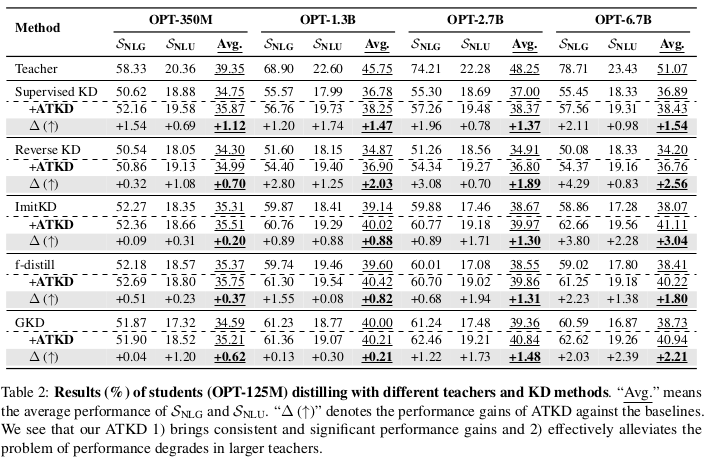
表 2 和表 3 展示了学生模型蒸馏后的结果。为了便于说明,我们仅分别报告了NLG 和 NLU的整体表现,具体的细节结果列于表 7 和表 10 中。
从这些结果中我们可以发现:
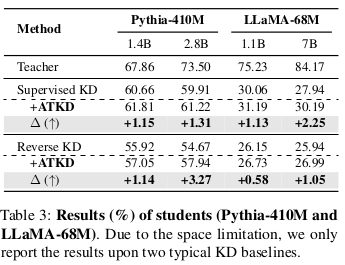
ATKD 有效缓解了“大教师模型性能退化”问题。如图所示,各种基线 KD 方法都受到该问题的影响,例如使用 GKD 蒸馏 OPT 时,教师为 1.3B 时学生得分为 40.00%,而教师为 6.7B 时反而降为 38.73%。然而,在我们提出的 ATKD 方法的帮助下,学生模型在使用更大教师时,普遍能获得更好的性能,即缓解了性能退化问题。这些结果证明了 ATKD 在提升教学质量方面的有效性。ATKD 在所有模型规模与类型中均带来了稳定且显著的性能提升。从表 2 可见,与各个基线方法相比,我们的 ATKD 在不同模型规模下都能持续取得更好的性能,平均性能提升最高可达 +3.04%。
此外,如表 3 所示,除了在 OPT 系列中表现良好之外,ATKD 在 Pythia 系列和 LLaMA 系列模型中也表现优异。这些结果表明了 ATKD 的通用性,也暗示其在更多语言模型中的广泛应用潜力。ATKD 对多种基线 KD 方法都有帮助。在前期分析中,我们仅在典型的 Supervised KD 上进行了实验。此处我们进一步探讨了 ATKD 与其他基线 KD 方法的可组合性。如表 2 所示,ATKD 可为所有基线 KD 方法带来稳定的性能提升。例如,在 ATKD 的帮助下,Reverse KD 和 ImitKD 的平均性能分别提升了 +1.80% 和 +1.36%。
4.3 Ablation Study
在本节中,我们:1)首先评估比例 k的影响;2)随后研究系数 λ的效果。值得注意的是,我们在本部分中使用 Supervised KD 作为基线,并报告 OPT-125M 在NLG任务上的性能。
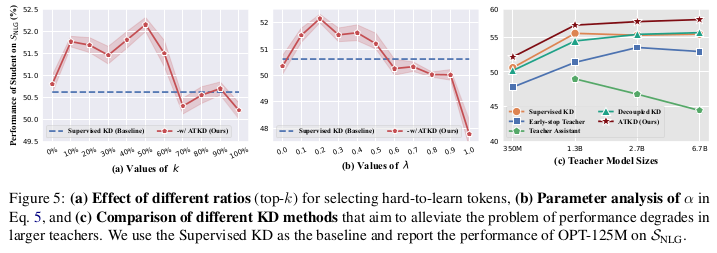
比例 k的影响用于选择 hard-to-learn token 的比例 k 是 ATKD 中的重要超参数。在本研究中,我们通过评估在 NLG任务上不同 k 值(从 0% 到 100%,以 10% 为间隔)下的性能来分析其影响。图 5(a) 展示了平均结果,从中可以发现:
1)过大的 k值(例如 70%)会导致性能下降,因为被选中的许多 token 实际上是“伪” hard-to-learn,可能会扰乱自适应教学;
2)模型性能在 10% 到 50% 之间稳定提升,且当 k=50时表现最佳,因此我们将其设为默认配置。
系数 λ 的影响用于平衡不同目标的系数 λ(见公式 5)同样需要研究。图 5(b) 展示了 λ在 [0, 1] 范围内的实验结果。观察可知:
相比仅学习 hard-to-learn token,引入部分 easy-to-learn token 的监督信号可以带来更好的性能;
然而,过大的 λ值(例如 0.9)会削弱 ATKD 的有效性,因为对 easy-to-learn token 学习的过度关注可能导致过拟合。
更具体地,λ=0.2时表现最佳,因此我们在实验中采用该设置。



![[Java 基础]打印金字塔](https://i-blog.csdnimg.cn/img_convert/038d5b5699da962cbdb9127c227d33c9.png)