CODE: CVPR 2024
https://jiuntian.github.io/interactdiffusion
Abstract
大规模文本到图像(t2i)扩散模型在基于文本描述生成连贯图像方面展示了令人难以置信的能力,从而在内容生成方面实现了广泛的应用。虽然最近的进步已经引入了对物体定位、姿态和图像轮廓等因素的控制,但我们在控制生成内容中物体之间交互的能力方面仍然存在一个关键的差距。在生成的图像中控制好交互可以产生有意义的应用,例如创建具有交互角色的逼真场景。在这项工作中,我们研究了用人-物体交互(HOI)信息来调节T2I扩散模型的问题,这些信息由一个三重标签(人、动作、物体)和相应的边界框组成。我们提出了一个可插拔的交互控制模型,称为InteractDiffusion,它扩展了现有的预训练T2I扩散模型,使它们能够更好地适应交互。具体来说,我们对HOI信息进行标记,并通过交互嵌入来学习它们之间的关系。训练了一个条件反射自注意力机制层,将HOI令牌映射到视觉令牌,从而在现有的T2I扩散模型中更好地调节视觉令牌。我们的模型实现了控制现有T2I扩散模型的相互作用和位置的能力,在HOI检测分数以及FID和KID的保真度方面大大优于现有基线。
Introduction
大量文献广泛研究了如何通过类[7,31]、文本[19,21,22,24]、图像(包括边缘、线条、涂鸦和骨架)[1,13,30]和布局[1,5,15,28,32]来控制扩散模型的图像生成。然而,这些不足以有效地表达细微的意图和期望的结果,特别是对象之间的交互。我们的工作引入了图像生成中的另一个重要控制:interaction---交互
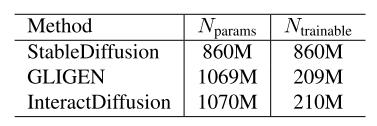
相互作用是指两个实体或个人之间的相互作用。毫无疑问,互动是描述我们日常活动的一个组成部分。然而,我们发现现有的扩散模型可以很好地处理静态图像,如绘画或风景照片,但在生成涉及交互的图像时面临巨大挑战。例如,GLIGEN[15]将布局作为帮助指定对象位置的条件,但控制对象之间的关系或交互仍然是一个开放的难题,如图图所示。文本到图像(t2i)扩散模型中交互层面的控制有无数的应用,例如电子商务、游戏、互动讲故事等。
本文研究了以交互为条件的图像生成问题,即如何在图像生成过程中指定交互。它面临三大挑战:
a)交互表示:如何用有意义的令牌表示来表示交互信息。
b)复杂的交互关系:具有交互作用的物体之间的关系是复杂的,产生连贯的图像仍然是一个很大的挑战。
c)将条件融入现有模型:目前T2I扩散模型在图像生成质量上较好,但缺乏交互控制。一个可以无缝集成到它们中的可插拔模块是必不可少的。
为了解决上述问题,我们提出了一个名为InteractDiffusion的交互控制模型,作为现有T2I扩散模型的可插拔模块,如图所示,旨在实施交互控制。
首先,为了向扩散模型提供条件信息,我们将每个交互对视为HOI三元组,并将其信息转换为包含有关位置、大小和类别标签信息的有意义的令牌表示。特别是,我们为每个HOI三元组生成三个不同的令牌,即主题、动作和对象令牌。主题和对象令牌都包含有关位置、大小和对象类别的信息,而动作令牌则包含交互的位置及其类别标签。
其次,表示复杂交互的挑战在于对多个交互的令牌之间的关系进行编码,其中令牌来自不同的交互实例,并且在交互实例中具有不同的角色。为了解决这个问题,我们提出了实例嵌入和角色嵌入来对相同交互的令牌进行分组,并在语义上嵌入它们的角色。
第三,由于现有的变压器块由自注意力机制层和交叉注意层[22]组成,我们在它们之间添加了一个新的交互自注意力机制层,以将交互令牌合并到现有的T2I模型中。这有助于在训练期间保留原始模型,同时结合额外的交互条件反射信息。
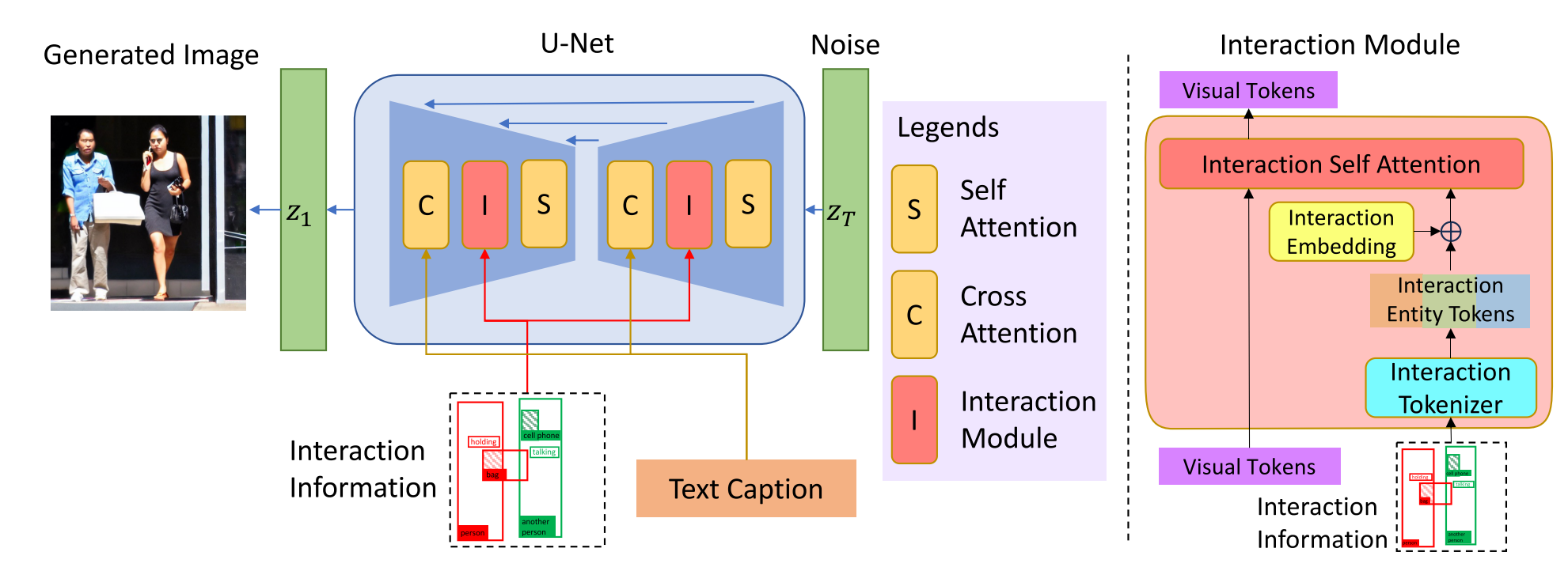
图2。 InteractDiffusion的整体框架。我们提出的可插拔交互模块I将交互信息无缝地集成到现有的T2I扩散模型中(左)。提议的模块I(右)包括将交互信息转换为有意义的令牌的交互令牌器(第3.2节)、包含复杂交互关系的交互嵌入(第3.3节)、以及交互自注意力机制(第3.4节),将交互控制信息集成到现有T2I扩散模型的视觉标记中。
贡献:
(i)解决了现有T2I模型中的相互作用失配问题,提出了一个新的挑战:控制T2I扩散模型中的相互作用。针对已有的T2I模型,提出了一种新的可插拔的交互扩散框架。它结合了交互信息作为训练交互可控T2I扩散模型的附加条件,提高了生成图像中交互的精度。
(ii)为了有效地捕捉复杂的交互关系,我们引入了一种新的方法,将〈主语、动作、宾语〉的位置和类别信息标记化为三个不同的标记符。然后,这些令牌被分组在一起,并通过嵌入框架在它们的交互角色中指定。这种创新的方法增强了对复杂交互的表示。
(iii)在HOI检测得分方面,InteractDiffination显著优于基线方法,并在FID和KID指标略有改善的情况下保持世代质量。据我们所知,这项工作是首次尝试将相互作用控制引入扩散模型。
Related Work
Human-Object Interactions 人-物交互(HOI)的最新进展主要集中在检测图像中的HOI。它旨在通过边界框定位交互的人和物体对,并将这些物体及其交互以三元形式进行分类,例如(人,喂食,猫)。最近的HOI检测工作[4,14,17,27,29]是基于der的,并显示出有希望的结果。然而,它们仍然受到数据稀缺性的影响,这阻碍了对罕见交互的检测性能。与此同时,HOI图像合成作为HOI检测的逆任务,研究相对较少。InteractGAN[9]提出了通过人体姿态和人与物体的参考图像生成HOI图像。然而,这种方法是复杂的,因为它需要一个姿势模板池和人类和物体的参考图像。一个更密切相关的工作是基于布局建议的[12]方法,该方法侧重于根据HOI三重体对场景布局建议进行综合。然而,它只能根据输入生成“对象放置”建议。我们的工作重点是一个新的问题,即在不需要人体姿态信息和参考图像的情况下,使用简单的边界框和交互关系,以端到端的方式控制现有T2I扩散模型中的交互。这种方法有效地解决了HOI检测任务对更多数据的需求,并开辟了广泛的应用领域。
Diffusion Models
Controlling Image Generation T2I扩散模型[19,21,22,24]通常使用CLIP[20]等预训练语言模型来指导图像扩散过程。这允许生成的图像的内容由提供的文本标题控制。然而,单独的文本标题通常不能提供对生成内容的足够控制,特别是当目标是创建特定内容时,例如对象位置和布局、场景深度图、人物姿势、边界线和交互。为了解决这个问题,几个模型提出了不同的方法来控制生成的内容,包括对象布局[15 Gligen: Open-set grounded text-to-image generation.,32 Layoutdiffusion: Controllable diffusion model for layout-to-image generation.]和图像[30 Adding conditional
control to text-to-image diffusion models.]。虽然通过对象布局和图像控制图像生成通常可以产生更好的结果,但图像的一个重要方面在很大程度上被忽略了,即对象之间的交互。我们的工作通过加强对生成内容中的交互的控制,扩展了当前T2I模型的功能。
Method
我们首先阐述问题,然后详细说明我们的InteractDiffusion模型,如图图所示。它包括四个部分:(a)将交互条件转换为令牌的交互令牌器,(b)链接交互三元组令牌之间关系的交互嵌入,(c)在图像补丁和交互信息之间构建注意力的交互转换器,(d)生成具有交互条件的图像的交互条件扩散模型。
Preliminary
我们研究了将交互条件d与文本标题条件c一起纳入现有T2I扩散模型的问题。我们的目标是训练一个扩散模型fθ(z, c, d)来生成以交互d和文本标题c为条件的图像,其中z是初始噪声。稳定扩散模型是潜扩散模型(Latent Diffusion Model, LDM)[22]的放大模型,具有更大的模型和数据量,是最好的模型之一。与其他扩散模型不同,LDM分为两个阶段以降低计算复杂度。它首先学习双向投影,将图像x从像素空间投影到潜在空间作为潜在表示z,然后在潜在空间中训练具有潜在z的扩散模型fθ(z, c)。我们的工作重点是第二阶段,因为我们只对调节具有交互作用的扩散模型感兴趣。
LDM学习一个长度为t的固定马尔可夫链的反向过程,它可以被解释为一个等加权的去噪自编码器序列ϵθ(zt, t);t = 1,···,T,它们被训练来预测其输入zt的去噪版本,其中zt是输入z的带噪版本。
无条件目标可以看作是
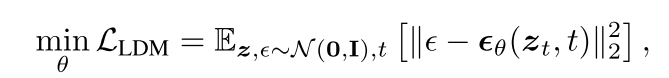
其中t从{1,···,t}均匀采样。该模型从噪声zT到zT−1、zT−2、···、z0迭代产生噪声较小的样本,其中模型ϵθ(zT, t)由UNet[23]实现。通过在第一阶段训练的解码器,将潜伏空间中的z0单次投射回图像空间,从而获得最终图像。
Conditioning 在LDM中,为了使用文本标题等多种模式来调节扩散模型,在UNet主干上添加了交叉注意机制。将各种模态的条件输入记为y,并使用域特定编码器τθ(·)将y投影到中间标记表示τθ(y)。
在StableDiffusion中,用y表示的文本标题用于调节模型。它使用一个表示为τθ(·)的CLIP编码器将文本标题y投影到77个文本嵌入中,即τθ(y)。特别地,StableDiffusion的条件目标可以看作
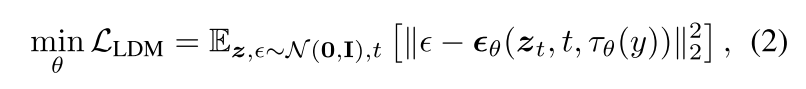
其中τθ(·)表示CLIP文本编码器,y表示文本标题。
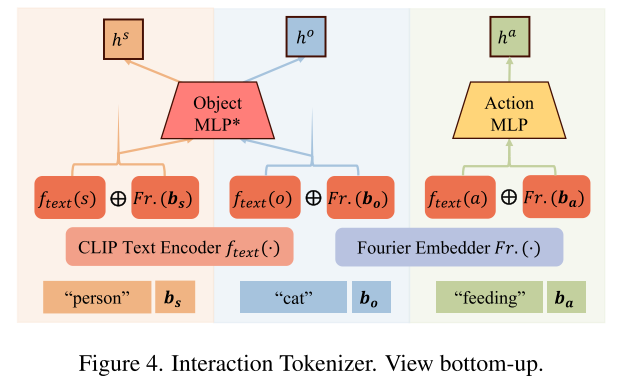
Interaction Tokenizer (InToken)
交互标记器(InToken)我们将交互d定义为一个三元组标签,由<主题s、动作a和对象o >组成,以及它们对应的分别表示为< bs、ba和bo >的边界框。我们使用主题和对象边界框来描述它们的位置和大小,并引入动作边界框来指定动作的空间位置。例如,一个主体(如女人、男孩)对一个特定的物体(如手提包、球)做一个特定的动作(如搬运、踢)。
为了获得动作边界框,我们定义了一个“between”操作,应用于主题和对象边界框。设bs和bo用它们的角坐标[αi,βi]表示,i = 1,2,3,4,则对bs和bo进行“between”运算得到ba为:
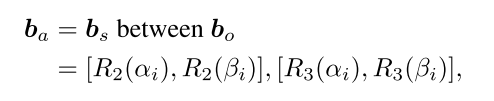
其中Rk(·)为其参数的第k位。“between”操作结果的一些示例如图3所示。
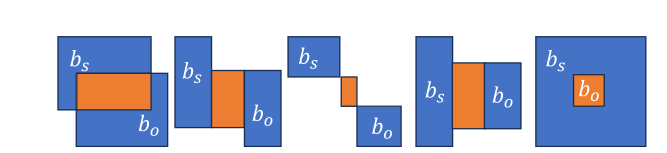
图3。“Between”操作获取主题和对象边界框之间的动作焦点区域(以橙色突出显示)。
这样,图像的交互条件输入为:
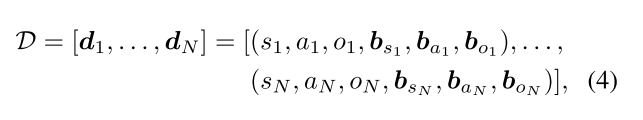
其中N为交互实例的数量。
Subject and Object tokens 我们首先将文本标签和边界框预处理为中间表示。特别地,我们使用预训练的CLIP文本编码器对主体、动作和对象的文本进行编码,作为具有代表性的文本嵌入,并使用傅立叶嵌入[18]按照GLIGEN[15]对它们各自的边界框进行编码。为了生成主体和客体令牌,hs, ho,我们使用多层感知器ObjectMLP(·)将它们融合为:
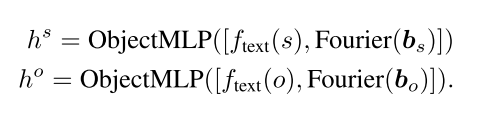
Action token 对于动作令牌,我们训练了一个单独的多层感知器ActionMLP(·),因为动作在语义上与主体和客体分开,
![]()
对于每个交互,我们将交互条件输入d转换为令牌的三元组h:
![]()
其中InToken(·)是等式的组合。(5)至(7),如图4所示。

Interaction Embedding (InBedding)
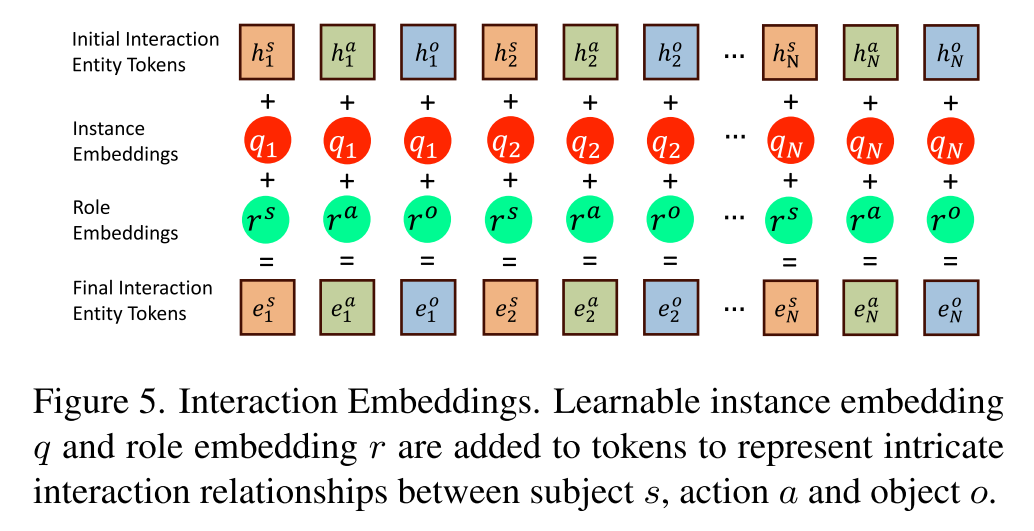
交互作用是主体、客体及其行为之间错综复杂的关系。由方程(8)可知,令牌hs、ha、ho分别嵌入(如图图2所示)。对于多个交互实例,所有令牌hs i、ha i、ho i;i = 1,···,N,分别嵌入。因此,有必要按交互实例对这些令牌进行分组,并在交互实例中指定令牌的不同角色。[6]中介绍的片段嵌入,已经证明了它在捕获文本序列中片段之间关系方面的有效性,方法是将可学习的嵌入添加到标记中,将单词序列分组到片段中。在我们的工作中,我们扩展了这个概念,将令牌分组为三元组。具体来说,我们添加了一个新的实例嵌入,表示为q∈{q1,…, qN}到交互实例h∈{h1,···,hN}为:
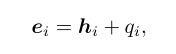
其中,同一实例中的所有令牌共享相同的实例嵌入。这将所有令牌分组到交互实例或三元组中。此外,三元组中的每个令牌都有不同的作用。
因此,我们用三个角色嵌入r∈{rs, ra, ro}来嵌入他们的角色,形成最终的实体令牌ei:
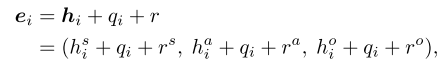
其中rs、ra和ro分别表示主体、动作和客体的角色嵌入。从方程(10)中我们可以看到,所有实例中相同角色的令牌共享相同的角色嵌入。在交互实体令牌hi中加入实例和角色嵌入(如图所示)对复杂的交互关系进行了编码,即指定了令牌的角色和交互实例,从而显著改善了图像生成,特别是在具有多个交互实例的场景中。

Interaction Transformer (InFormer)
由于在大规模预训练过程中获得的知识,诸如Stable Diffusion这样的大规模T2I模型已经在大规模图像-文本对上进行了训练,并在生成高度逼真的图像方面表现出了卓越的能力。在本文中,我们的目标是以最小的成本将交互控制纳入这些T2I模型。因此,保存它们所包含的宝贵知识是至关重要的。
我们将v = [v1,···,vM]表示为图像的视觉特征标记,c表示为c = τθ(y)的标题标记。在LDM模型中,Transformer块由两个注意层组成,即(i)视觉标记的自注意力机制层和(ii)对视觉标记和标题标记之间的注意进行建模的交叉注意层:
![]()
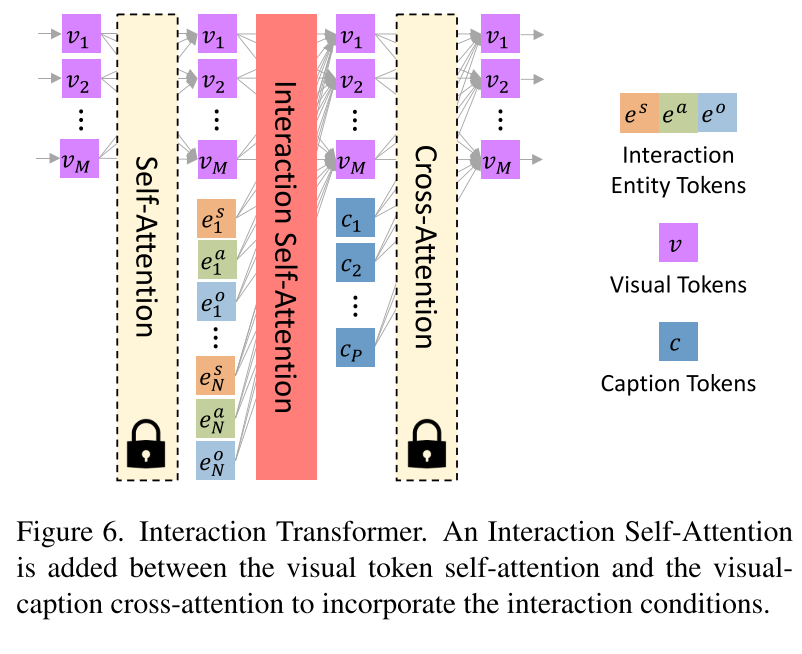
Interaction Self-Attention 在GLIGEN[15]之后,我们冻结了两个原始的注意层,并在它们之间引入了一个新的门控自注意力机制层,即交互自注意力机制(见图6)。这是为了将交互条件添加到现有的Transformer块上。与[15]不同的是,我们对视觉和交互令牌的连接进行自注意力机制[v, es, ea, eo],其重点关注交互关系如下:

其中TS(·)是一个令牌切片操作,只保留视觉令牌的输出,并切掉其他令牌,如图图所示,η是预定采样的超参数,控制交互自注意力机制的激活,γ是一个零初始化的可学习尺度,逐渐控制门的流量。注意,方程(12)在方程(11)的两个部分之间执行。综上所述,我们的交互自注意层将交互信息(包括交互、主题和对象边界框)转换为视觉标记。

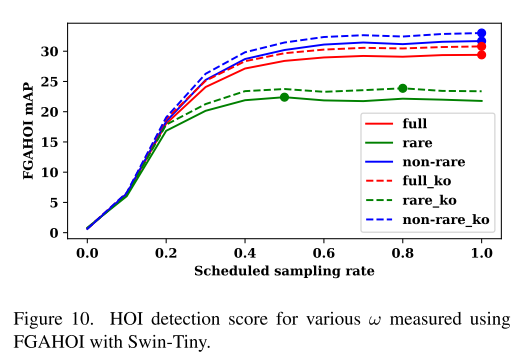
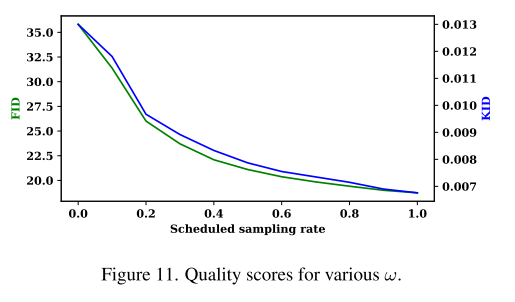
Scheduled Sampling 我们在训练时设置方程(12)中的η = 1,标准推理方案为[15]。然而,在某些情况下,新增加的交互自注意力机制层可能会对现有的T2I模型产生次优效果。因此,我们在交互自注意力机制层上加入了对采样间隔的控制,可以平衡文本标题和交互控制的水平。
从技术上讲,我们的调度抽样方案在推理时间内由超参数ω∈[0,1]控制。定义受交互控制影响的扩散步长比例为:
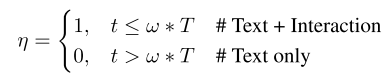
其中T为扩散步骤总数。

Interaction-conditional Diffusion Model
我们将InToken、InBedding和InFormer组合成可插拔的交互模块,在现有的T2I扩散模型中实现交互控制。采用LDM训练目标(方程(2))。将新加入的参数记为θ′,扩散模型现在定义为ϵθ,θ′(·),其中额外的相互作用信息由相互作用标记器τθ′(·)处理。因此,我们模型的总体训练目标是:
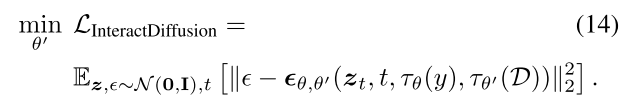
Experiments
我们在512x512分辨率下训练和评估模型。我们使用基于StableDiffusion v1.4的预训练GLIGEN模型初始化我们的模型。训练使用恒定的学习率5e-5和Adam优化,并对最初的10k迭代进行线性热身。它运行了50万次迭代,批处理大小为8(≈106 epoch),在2块NVIDIA GeForce RTX 4090 gpu上耗时约160小时。我们使用2的梯度累积步长,得到的有效批大小为16。对于推理,我们使用PLMS[16]采样器的扩散采样步长为50。更多细节载于补充文件第6节。
Datasets
我们的实验是在广泛使用的HICODET数据集[3]上进行的,该数据集包含47,776张图像:38,118张用于训练,9,658张用于测试。该数据集包括151,276个HOI注释:117,871个用于训练,33,405个用于测试。HICO-DET包括600种HOI三元组,由80个对象类别和117个动词类组成。我们提取测试集中的注释作为输入生成交互图像,随后使用FGAHOI[17]对生成的图像进行HOI检测。根据HICO-DET[3]中概述的评估方法,我们评估了默认和已知对象设置下的生成结果。在默认设置中,计算每个HOI类的所有测试图像的平均精度(AP)。另一方面,已知对象设置仅在包含相应HOI类中对象的图像上计算HOI类的AP(例如,HOI类“骑自行车”的AP仅在包含“自行车”对象的图像上计算)。我们报告了完整和罕见子集的HOI检测结果。Full和Rare子集分别由600和138个HOI类组成,其中Rare类定义为由少于10个训练样本代表的类。
Evaluation Metrics
Fr´echet Inception Distance 测量真实图像和生成图像(FID)之间Inception特征分布中的Fr ' cheet距离。
Kernel Inception Distance 使用多项式核测量真实图像和生成图像的初始特征之间的最大平均差异(MMD)的平方。它放宽了FID中的高斯假设,并且需要更少的样本。
HOI Detection Score 提出了HOI检测分数作为生成模型中相互作用可控性的度量。为了评估这一点,我们利用预训练的最先进的HOI检测器FGAHOI[17]来检测生成图像中的HOI实例,并将它们与HICO-DET中原始注释的真实值进行比较。这个过程量化了模型在交互生成中的可控性。我们将基于FGAHOI协议的HOI检测评分分为两类,即默认对象和已知对象。默认设置更具挑战性,因为它需要区分不相关的图像。FGAHOI是用swan - tiny和swan - large两种骨干来实现的,我们用这两种骨干来进行计算。
综上所述,FID和KID评估生成质量,而HOI Det. Score评估交互可控性。
Implementation Details
Negative Prompt 我们对所有世代使用以下否定提示:“长身体,低分辨率,糟糕的解剖结构,糟糕的手,缺失的手指,多余的手指,少的手指,裁剪,最差的质量,低质量”。
Model Complexity.
Network Architecture. 在所有的实验中,所有的方法都使用Stable Diffusion V1.4作为基础模型。除了U-Net中的变压器块被调整以包含我们的交互模块外,我们保持了网络架构。
Qualitative results

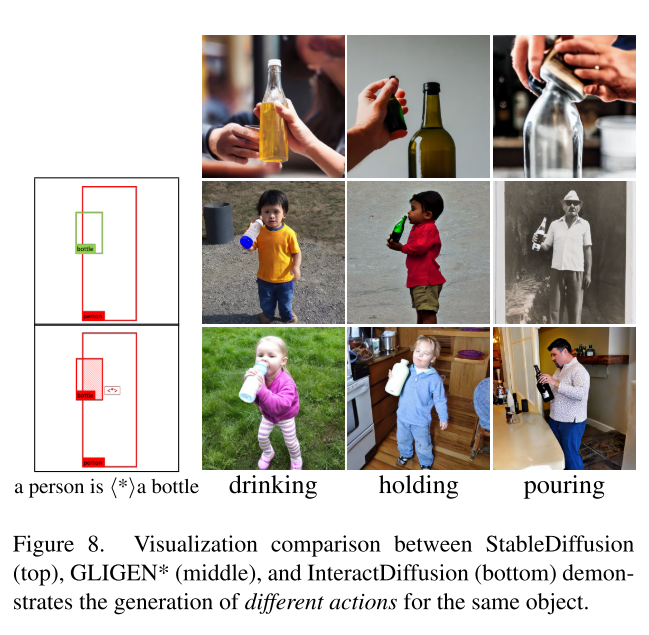
Quantitative results
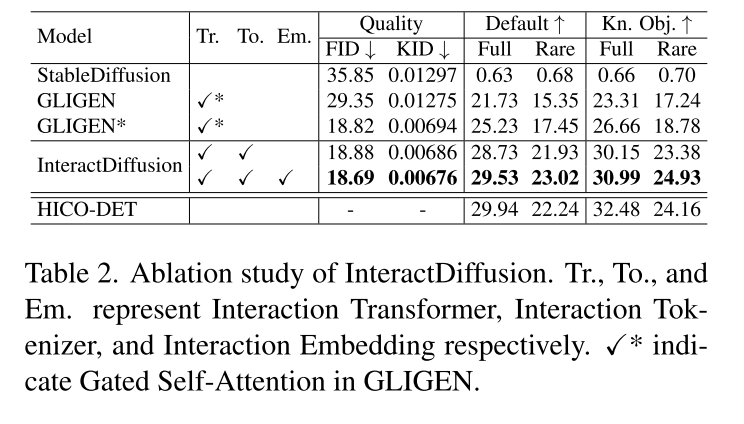
Ablation studies
Limitations
尽管在各种度量上有了显著的改进,但生成的交互仍然显示出与现实的一些差异,特别是在更精细的细节上。这可以在更大的探测器(即FGAHOI(SwinLarge))的mAP上发现,FGAHOI在探测HOI时更注重细节。此外,我们发现现有的大型预训练模型(CLIP[20],StableDiffusion[22])在预训练阶段以对象为中心,缺乏对交互的理解,这阻碍了InteractDiffusion在控制交互方面的表现。我们期望一个包含对象和交互的更多样化训练的大型模型可以提高InteractDiffusion的交互可控性。