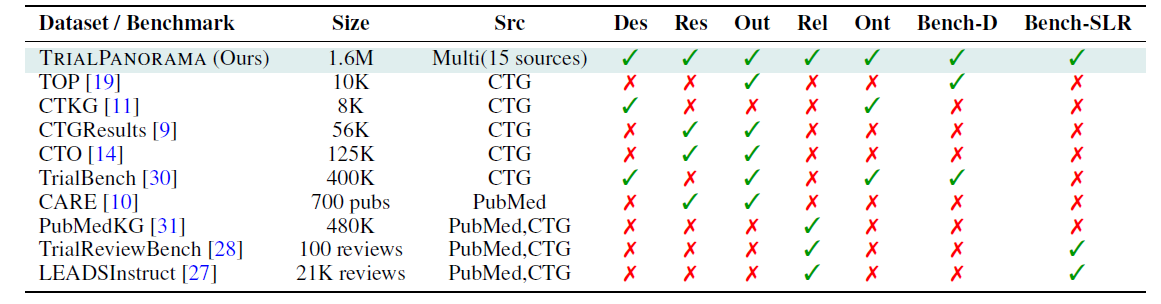
Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal LLMs
➡️ 论文标题:Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal LLMs
➡️ 论文作者:Yilun Hua, Yoav Artzi
➡️ 研究机构: Cornell University
➡️ 问题背景:人类在互动过程中会自发地使用更高效的语言,通过形成临时的语言惯例来提高沟通效率。这种现象在人类语言中非常普遍,但在多模态大型语言模型(MLLMs)中是否也能观察到,以及这些模型是否能自发地提高沟通效率,目前尚未有深入研究。
➡️ 研究动机:研究团队旨在评估多模态大型语言模型(MLLMs)是否能在互动中自发地形成临时的语言惯例,以提高沟通效率。通过引入ICCA框架,研究团队希望了解这些模型在互动中的适应能力,并探讨其背后的机制。
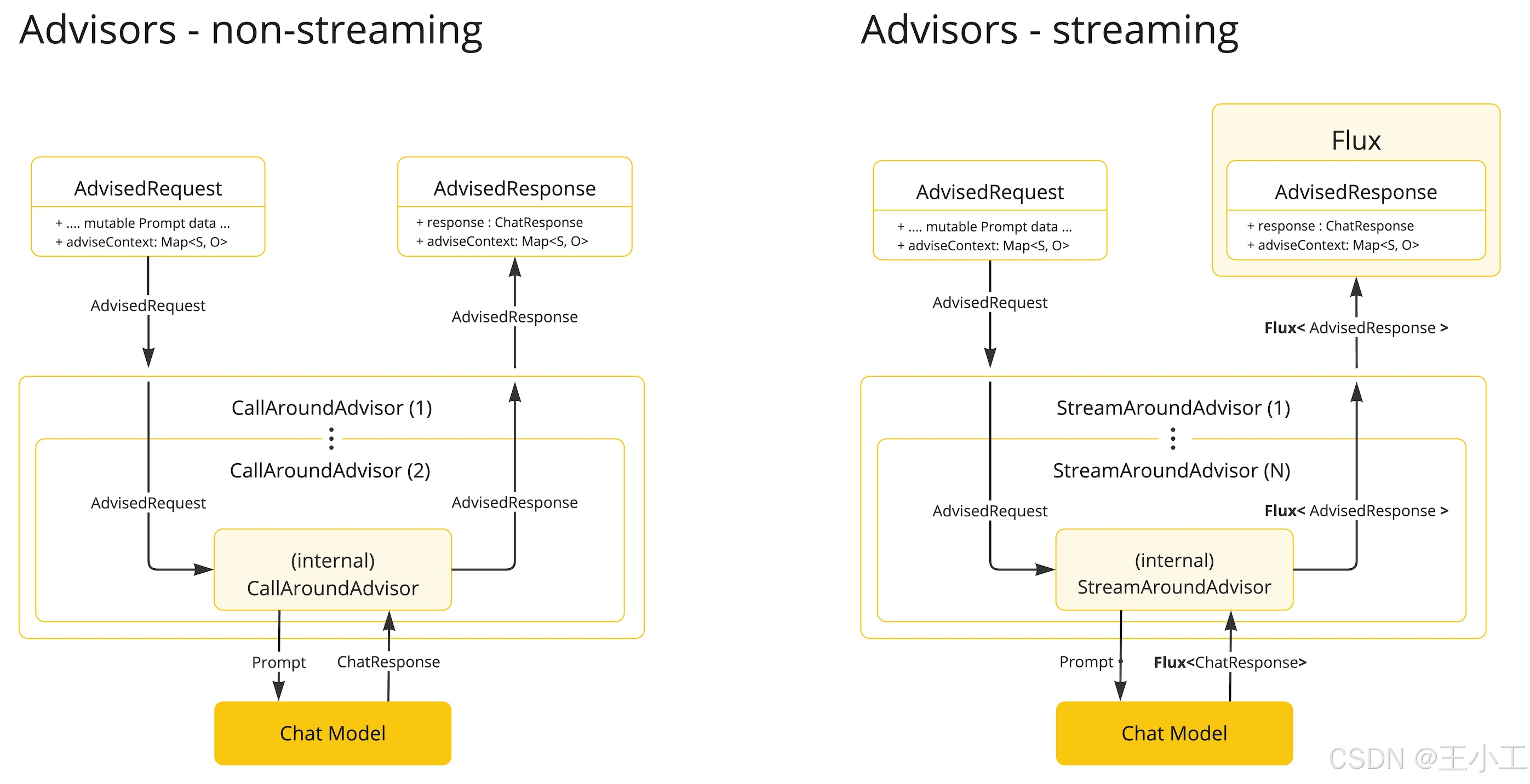
➡️ 方法简介:研究团队提出了ICCA(In-context Conversational Adaptation)框架,用于评估MLLMs在互动中形成临时语言惯例的能力。ICCA使用人类-人类参考游戏互动数据集,通过自动化的方式评估模型作为说话者或听者时的表现。研究团队设计了四种不同的提示变体,以评估模型在不同指导下的表现。
➡️ 实验设计:实验在五个代表性的MLLMs上进行,包括IDEFICS、LLaVa-1.5、GPT4-vision、Gemini 1.0 Pro Vision和Claude 3 opus。实验设计了四种不同的提示变体,从标准提示到明确的指令,逐步增加对模型的指导强度。实验结果表明,尽管GPT4、Gemini和Claude在重提示下表现出一定的适应趋势,但所有模型都无法自发地提高沟通效率。此外,实验还评估了模型作为听者时的表现,发现GPT4在互动过程中逐渐提高了准确性,而其他模型的表现则较差。
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
➡️ 论文标题:MiniCPM-V: A GPT-4V Level MLLM on Your Phone
➡️ 论文作者:Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, Qianyu Chen, Huarong Zhou, Zhensheng Zou, Haoye Zhang, Shengding Hu, Zhi Zheng, Jie Zhou, Jie Cai, Xu Han, Guoyang Zeng, Dahai Li, Zhiyuan Liu, Maosong Sun
➡️ 研究机构: MiniCPM-V Team, OpenBMB
➡️ 问题背景:多模态大语言模型(MLLMs)的快速发展显著提升了AI在理解、推理和交互方面的能力,但这些模型通常参数量巨大,计算负担沉重,导致它们主要部署在高性能的云服务器上,限制了其在移动设备、离线场景、能源敏感场景和隐私保护场景中的应用。
➡️ 研究动机:为了克服这些限制,研究团队开发了MiniCPM-V系列模型,旨在实现高性能与高效能之间的平衡,使其能够在端侧设备上部署。通过集成最新的MLLM技术,MiniCPM-V系列模型在性能、OCR能力、高分辨率图像感知、可信行为、多语言支持和端侧部署优化等方面表现出色。
➡️ 方法简介:研究团队通过精心设计的架构、数据和训练策略,开发了MiniCPM-V系列模型。最新版本的MiniCPM-Llama3-V 2.5在多个基准测试中表现出色,超过了GPT-4V-1106、Gemini Pro和Claude 3等大型模型。该模型支持1.8M像素的高分辨率图像感知,具备强大的OCR能力,多语言支持超过30种语言,并且在端侧设备上实现了高效的部署。
➡️ 实验设计:研究团队在多个公开数据集上进行了实验,包括视觉-语言感知(VLP)和图像到图像(I2I)任务。实验评估了模型在不同条件下的表现,如不同分辨率的图像输入、多语言支持和端侧部署的效率。实验结果表明,MiniCPM-V系列模型在性能和效率之间实现了良好的平衡,为未来的端侧MLLMs的发展提供了有价值的参考。
Mini-Monkey: Alleviating the Semantic Sawtooth Effect for Lightweight MLLMs via Complementary Image Pyramid
➡️ 论文标题:Mini-Monkey: Alleviating the Semantic Sawtooth Effect for Lightweight MLLMs via Complementary Image Pyramid
➡️ 论文作者:Mingxin Huang, Yuliang Liu, Dingkang Liang, Lianwen Jin, Xiang Bai
➡️ 研究机构: 华中科技大学、华南理工大学
➡️ 问题背景:近年来,多模态大语言模型(MLLMs)在处理高分辨率图像方面受到了广泛关注。然而,现有的滑动窗口式裁剪策略在适应分辨率增加时,容易切断物体和连接区域,导致语义不连续,特别是在处理小或不规则形状的物体或文本时,这种现象尤为明显,被称为语义锯齿效应。这一效应在轻量级MLLMs中尤为显著。
➡️ 研究动机:为了解决语义锯齿效应,研究团队提出了一种互补图像金字塔(CIP)方法,旨在通过动态构建图像金字塔,为基于裁剪的MLLMs提供补充的语义信息,从而减少语义不连续性。此外,为了减少计算开销,研究团队还提出了一种尺度压缩机制(SCM),通过压缩冗余的视觉令牌来减少额外的计算负担。
➡️ 方法简介:研究团队提出了一种插件式解决方案——互补图像金字塔(CIP),该方法能够动态地构建图像金字塔,为MLLMs提供不同尺度的补充语义信息。CIP通过在不同尺度上提供互补的语义特征,即使在某一尺度上丢失了物体语义,也可以通过其他尺度的特征进行补偿。此外,研究团队还提出了一种尺度压缩机制(SCM),该机制利用预训练的注意力层和多尺度信息生成注意力权重,进而压缩冗余的视觉令牌,以减少计算开销。
➡️ 实验设计:研究团队在多个公开数据集上进行了实验,包括通用多模态理解和文档理解任务。实验结果表明,CIP和SCM的结合使用能够显著提升轻量级MLLMs的性能,特别是在处理高分辨率图像时。例如,2B参数的Mini-Monkey在多个基准测试中超越了8B参数的InternVL2-8B模型,特别是在OCR相关任务中,Mini-Monkey在OCRBench上的得分比InternVL2-8B高12分。此外,实验还表明,直接微调预训练的MLLMs并不能提升性能,而结合CIP的微调则可以显著提升模型的性能。
REVISION: Rendering Tools Enable Spatial Fidelity in Vision-Language Models
➡️ 论文标题:REVISION: Rendering Tools Enable Spatial Fidelity in Vision-Language Models
➡️ 论文作者:Agneet Chatterjee, Yiran Luo, Tejas Gokhale, Yezhou Yang, Chitta Baral
➡️ 研究机构: Arizona State University、University of Maryland, Baltimore County
➡️ 问题背景:当前的文本到图像(Text-to-Image, T2I)和多模态大型语言模型(Multimodal Large Language Models, MLLMs)在多种计算机视觉和多模态学习任务中得到了广泛应用。然而,这些视觉-语言模型在处理空间关系时存在显著的不足,尤其是在生成图像时无法准确地表示输入文本中提到的空间关系。
➡️ 研究动机:为了克服这些模型在空间关系理解上的不足,研究团队开发了REVISION框架,该框架通过3D渲染技术生成空间上准确的合成图像,从而提高T2I模型的空间保真度。REVISION旨在通过提供额外的指导,改善现有T2I模型在空间关系上的表现。
➡️ 方法简介:REVISION是一个基于3D渲染的管道,能够根据文本提示生成空间上准确的合成图像。该框架支持100多个3D资产、11种空间关系、多种背景、相机视角和光照条件。REVISION解析输入文本提示,生成相应的3D场景,并使用Blender进行渲染,以确保输出图像在对象及其空间排列上与输入提示完全匹配。
➡️ 实验设计:研究团队在VISOR和T2I-CompBench两个基准数据集上进行了实验,评估了REVISION对T2I模型空间保真度的提升效果。实验设计了不同的背景类型、去噪步骤数量等因素的变化,以及对不同空间关系类型的评估,以全面测试模型在空间关系上的表现和鲁棒性。此外,研究团队还引入了RevQA基准,用于评估MLLMs在复杂空间推理任务上的表现。
Infusing Environmental Captions for Long-Form Video Language Grounding
➡️ 论文标题:Infusing Environmental Captions for Long-Form Video Language Grounding
➡️ 论文作者:Hyogun Lee, Soyeon Hong, Mujeen Sung, Jinwoo Choi
➡️ 研究机构: Kyung Hee University
➡️ 问题背景:长视频-语言定位(Long-Form Video-Language Grounding, LFVLG)任务要求模型在长视频中精确定位与自然语言查询相关的时刻。与人类能够利用丰富的经验和知识快速排除无关信息不同,现有的LFVLG方法容易受到小规模数据集中的浅层线索的影响,导致在处理长视频时性能不佳。
➡️ 研究动机:为了克服现有LFVLG方法的局限性,研究团队提出了EI-VLG方法,通过利用多模态大型语言模型(MLLM)生成的环境描述来增强模型的能力,帮助模型更有效地排除无关信息,从而提高长视频中的定位精度。
➡️ 方法简介:EI-VLG方法包括三个主要组件:环境编码器(Environment Encoder, EE)、视频-语言定位模型(Video-Language Grounding Model, VLG)和环境注入器(Environment Infuser, EI)。环境编码器从视频中生成环境描述并编码,环境注入器将这些描述注入到VLG模型中,以帮助模型更好地理解视频内容。
➡️ 实验设计:研究团队在EgoNLQ数据集上进行了广泛的实验,该数据集包含14,000个训练样本和4,000个验证样本,平均视频长度为8分钟。实验评估了不同环境描述生成器和注入架构的效果,验证了EI-VLG方法在长视频定位任务中的有效性和优越性。实验结果表明,EI-VLG在多个评估指标上均优于现有的最先进方法。