使用代码处理数据集,发现了一些问题,以及解决办法~
下载了一组数据集,数据存放在CSV中,GBK格式。如下:

首先对每一列直接进行NER抽取,结果非常不好:
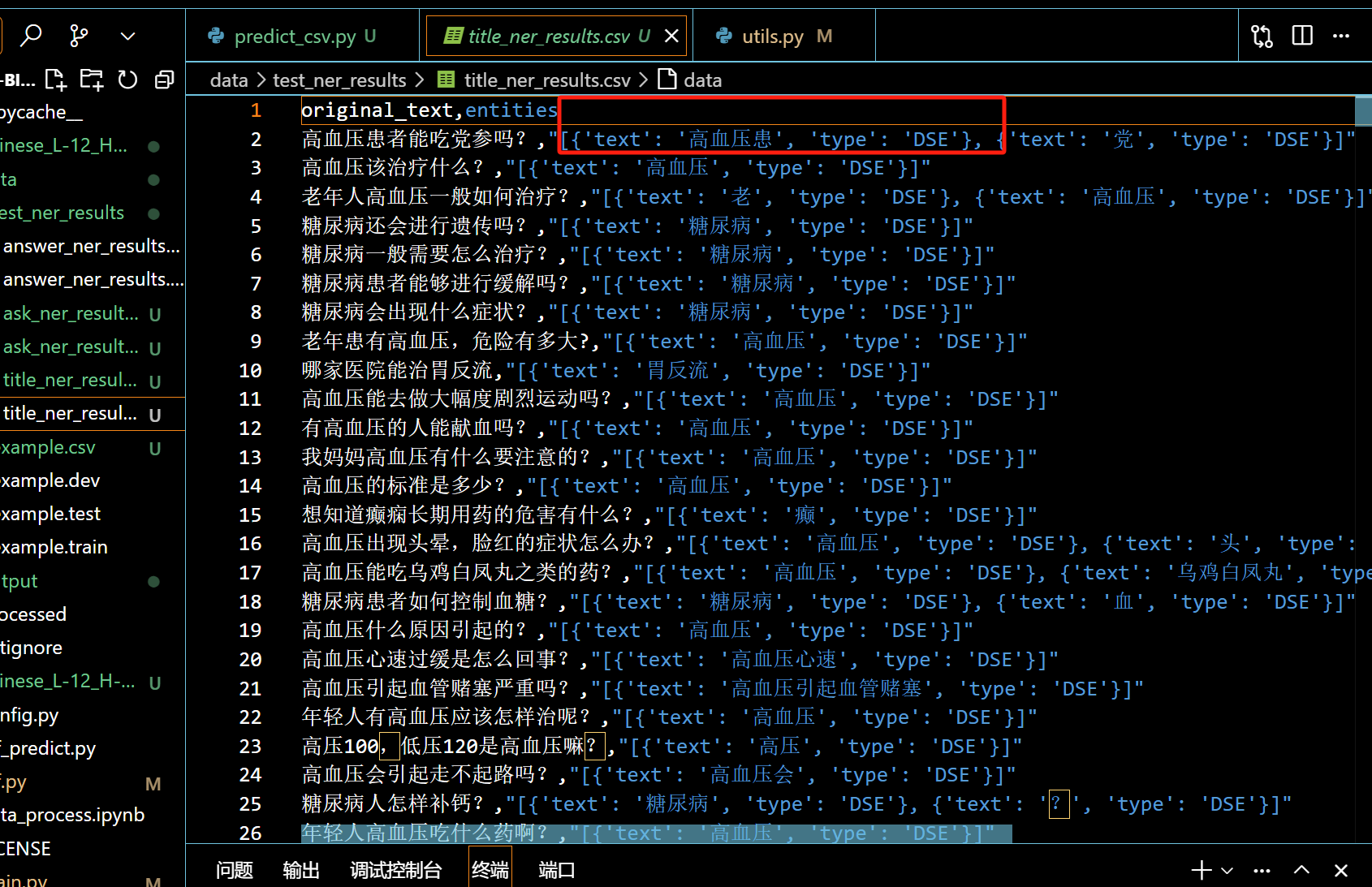
几乎是乱抽取的,解决办法是自己创建了一个词库:

创建词库需要对自己的数据集进行分词,然后对出现次数进行统计,我统计了前1000个:
import pandas as pd
import os
from collections import Counter
import jieba
from tqdm import tqdminput_dir = 'data/chinese_dialogue_medical'
fields = ['title', 'ask', 'answer']
all_text = []# 读取所有csv文件内容
def read_all_text():print("开始读取CSV文件...")csv_files = [f for f in os.listdir(input_dir) if f.endswith('.csv')]for file in tqdm(csv_files, desc="处理CSV文件"):path = os.path.join(input_dir, file)try:df = pd.read_csv(path, encoding='gbk')print(f"成功读取 {file} (GBK编码)")except Exception:try:df = pd.read_csv(path, encoding='gb18030')print(f"成功读取 {file} (GB18030编码)")except Exception as e:print(f"无法读取 {file}: {str(e)}")continuefor field in fields:if field in df.columns:texts = df[field].dropna().astype(str).tolist()all_text.extend(texts)print(f"从 {file} 的 {field} 字段中提取了 {len(texts)} 条文本")# 分词并统计高频词
def stat_terms():print("\n开始分词和统计...")words = []for text in tqdm(all_text, desc="分词处理"):words.extend(list(jieba.cut(text)))print("统计词频...")counter = Counter(words)# 过滤掉长度为1的词和常见无意义词stopwords = set([',', '。', '的', '了', '和', '是', '在', '我', '有', '也', '就', '不', '都', '与', '及', '或', '你', '他', '她', '吗', '啊', '吧', '哦', '呢', '!', '?', '、', ':', ';', '(', ')', '(', ')', '[', ']', '{', '}', ' ', '', '\n'])result = [(w, c) for w, c in counter.most_common() if len(w) > 1 and w not in stopwords]return resultif __name__ == '__main__':read_all_text()print(f"\n总共读取了 {len(all_text)} 条文本")result = stat_terms()print(f"\n统计出 {len(result)} 个高频词")# 输出前300个高频词到txtoutput_file = 'data/auto_medical_terms.txt'with open(output_file, 'w', encoding='utf-8') as f:for w, c in result[:1000]:f.write(f'{w}\t{c}\n')print(f'高频词统计完成,结果已保存到 {output_file}') 然后将疾病相关的词放到我的词表中去。
基于新的词表进行训练,结果如下:
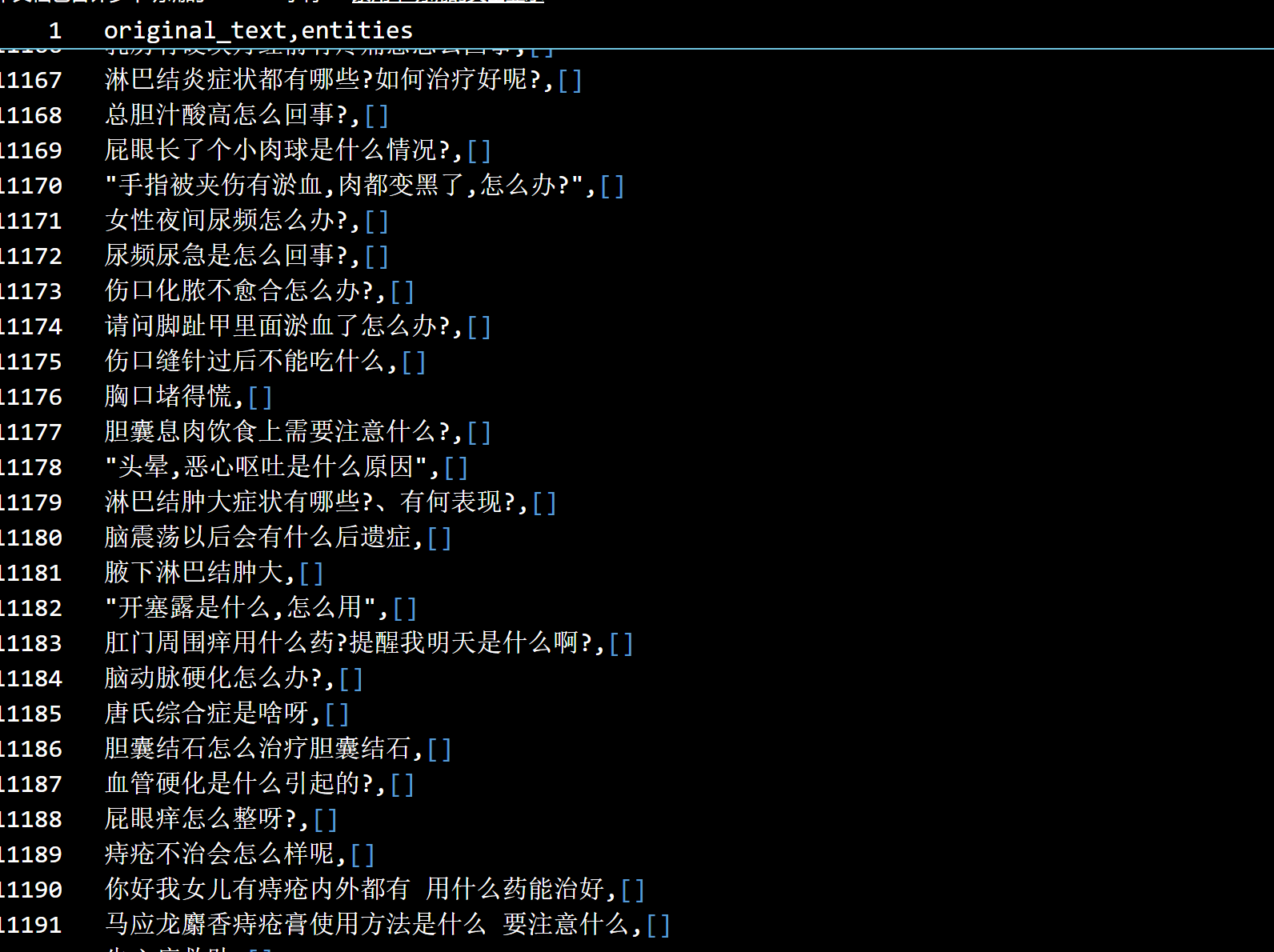
没有识别出来...解决中。
然后发现没有正确加载词表,此外词表未加入同义词等内容。解决中。
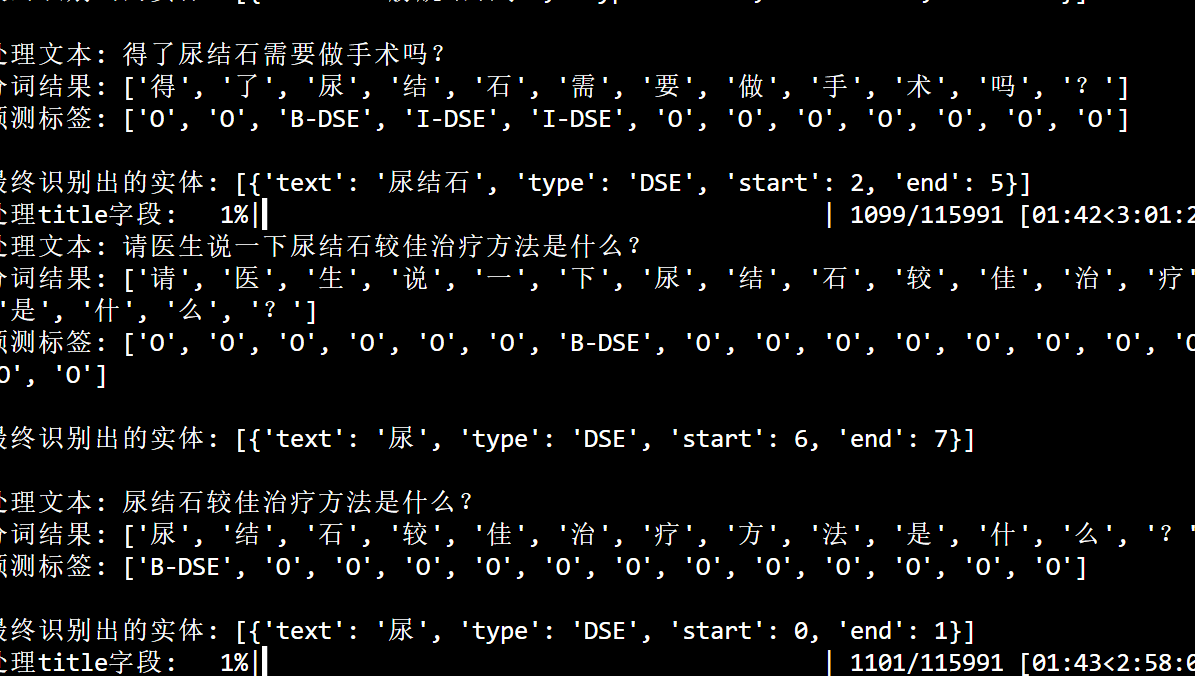
刚刚代码有问题,修改之后重新识别。首先,我第一次设计的词表非常不完善,后续增加了中国药典、疾病指南之类的官方书籍的目录进去,现在比较全面了。
其次,我刚刚没有使用到实体识别的模型。