目录
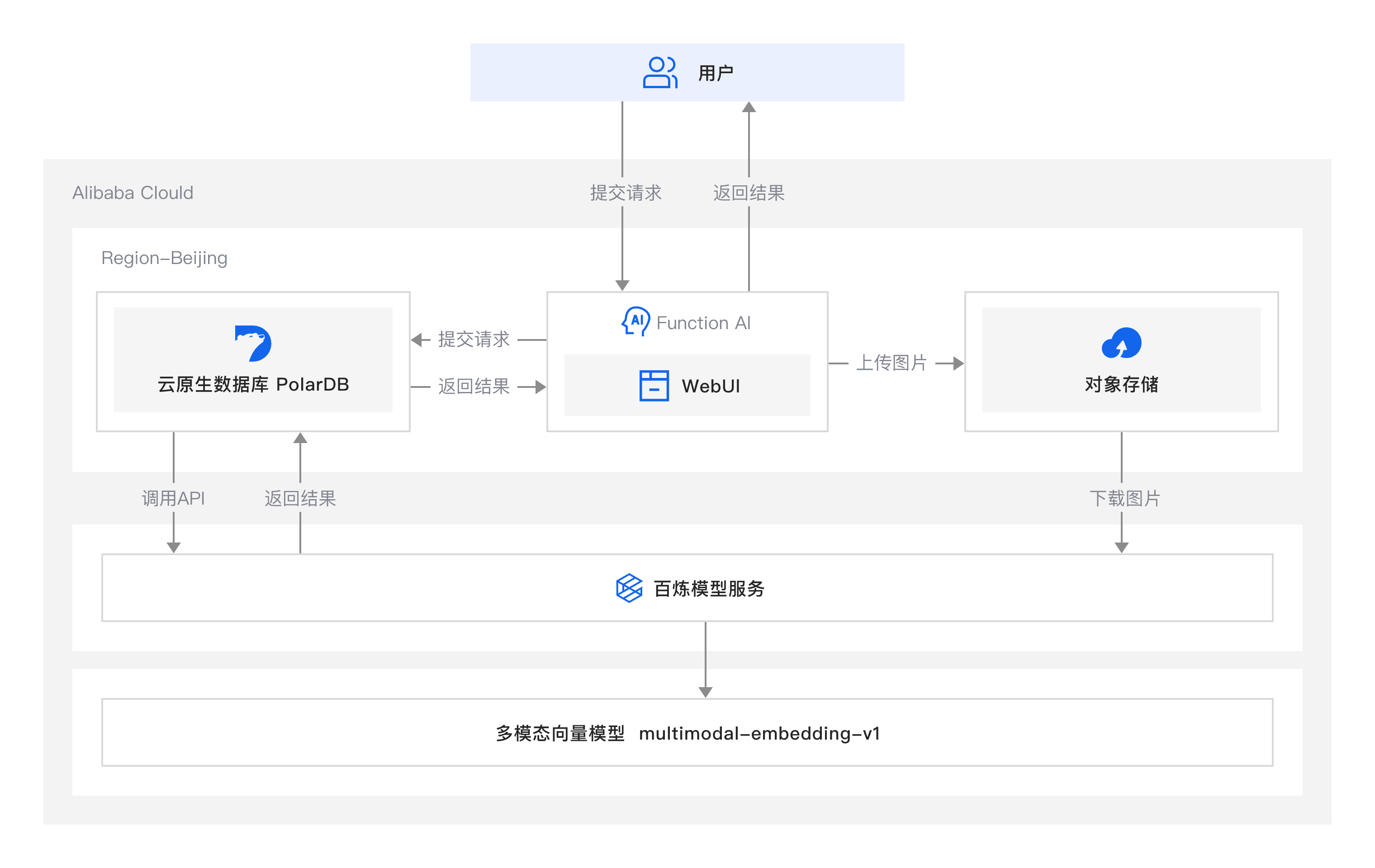
一、为何要选用Bright Data网页+自动化抓取——帮助我们高效高质解决以下问题!
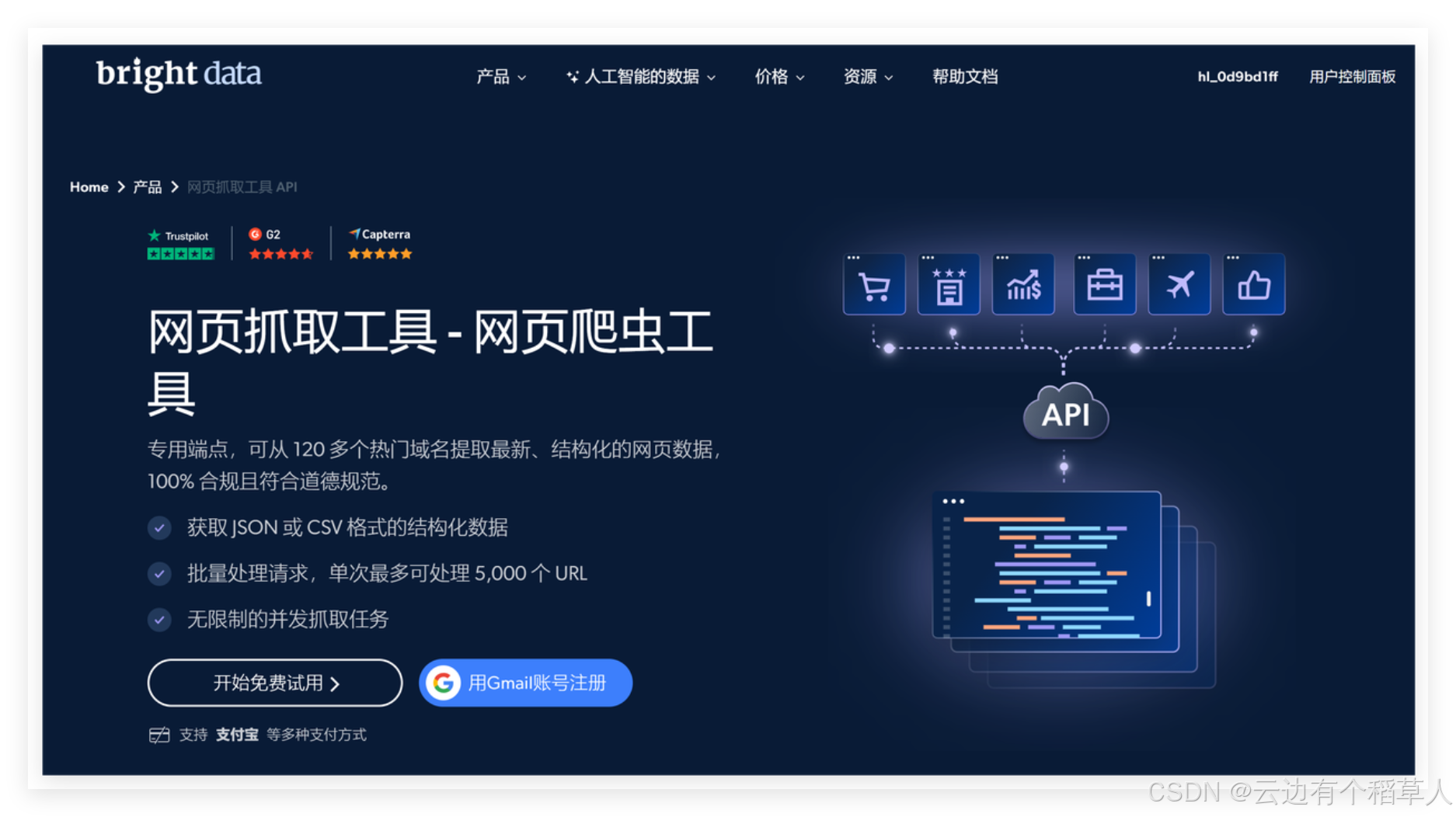
二、Bright Data网页抓取工具 - 网页爬虫工具实测
2.1 首先注册用户
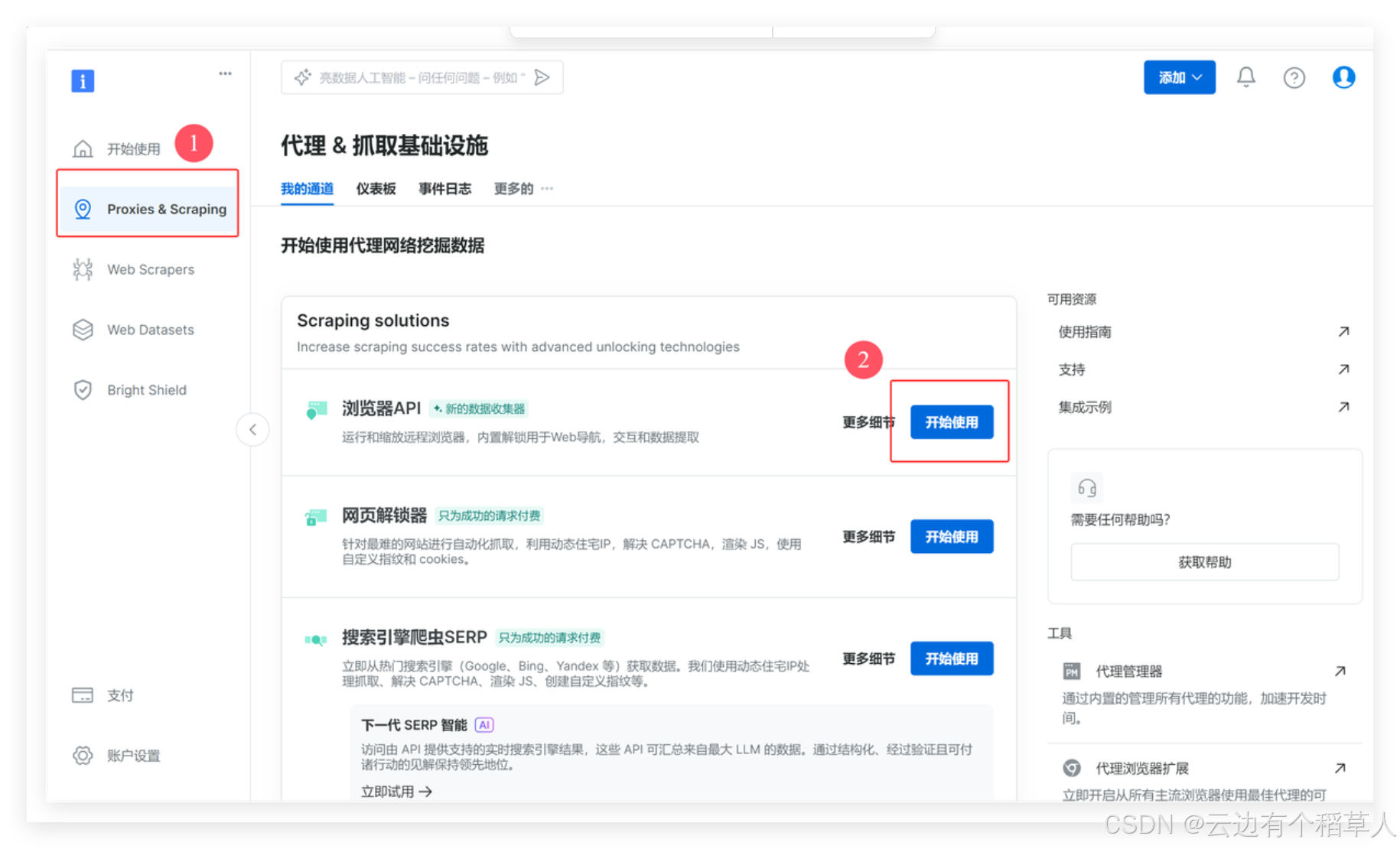
2.2 首先点击 Proxies & Scraping ,再点击浏览器API的开始使用
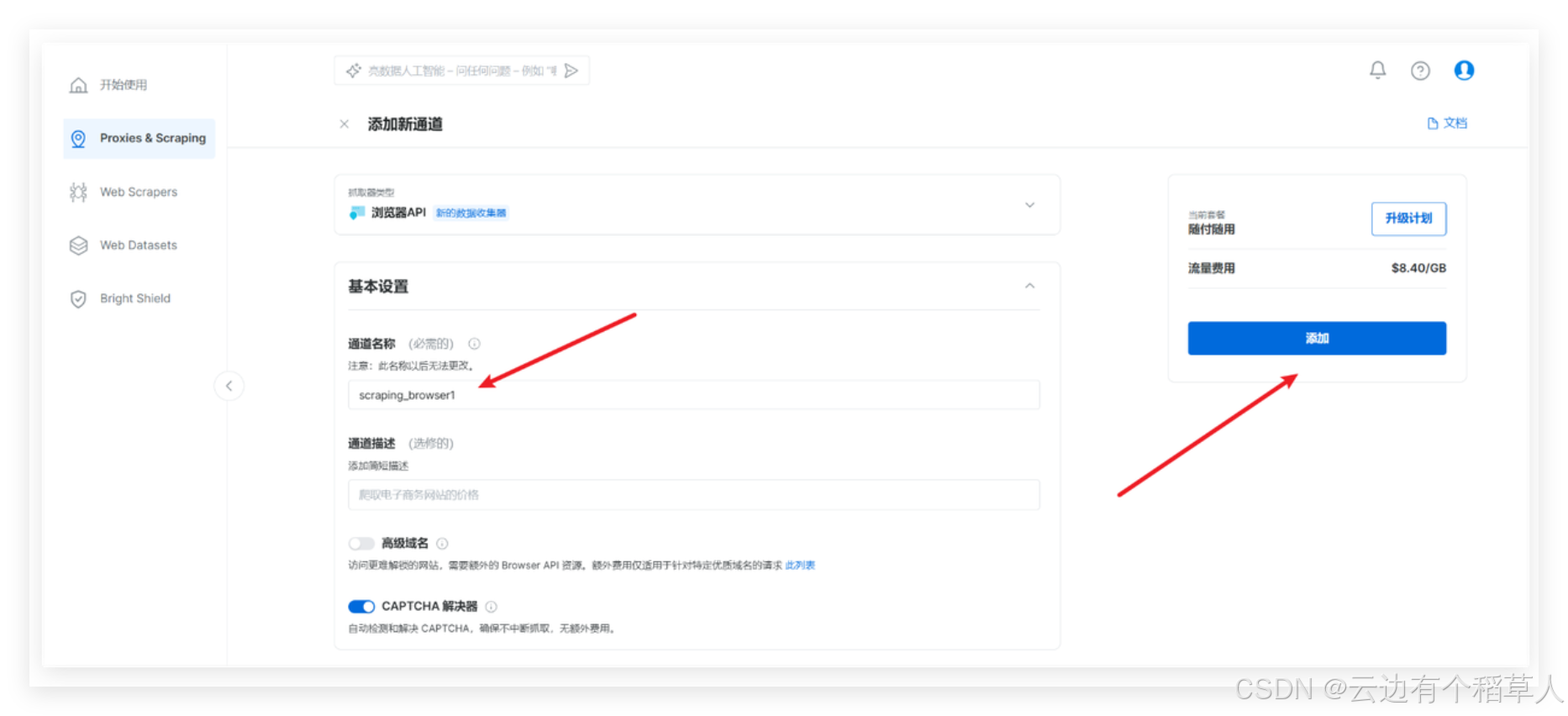
2.3 填写通道名称,打开CAPTCHA解决器,再点击添加
2.4 点击探索测试环境
2.5 实例
2.6 亮数据集成的AI工具帮我们生成过滤器高效进行数据的筛选
三、Web Scrapers API
3.1 什么是 Web Scraper API?
3.2 Web Scraper API的主要功能
3.3 实测
四、Bright Data与自动化工具的结合
4.1 结合n8n实现电商价格监测自动化流程
4.2 国内自动化平台结合实例:腾讯云函数+Bright Data抓取+微信企业号通知
五、Bright Data网页抓取工具的核心优势
5.1 全球分布的庞大代理网络
5.2 高匿名性与反反爬虫技术
5.3 易用的API与自动化集成
5.4 数据质量保障和合规支持
5.5 灵活定制与多数据源支持
六、Bright Data结合电商平台用户行为数据采集的应用优势分析
6.1 跨地域用户行为全覆盖
6.2 智能绕过反爬虫保护,实现稳定数据流
6.3 实时和批量数据抓取相结合
6.4 高质量数据保障AI模型训练基础
6.5 合规数据采集助力企业风险控制
七、总结
正文开始——
一、为何要选用Bright Data网页+自动化抓取——帮助我们高效高质解决以下问题!
-
大规模数据采集的效率问题 手动采集网页数据不仅费时费力,而且容易出错。自动化抓取能够快速、持续且高效地从大量网页获取数据,大幅提升数据采集的速度和准确性。
-
应对动态网页和反爬机制 现代网站常使用动态加载技术(如AJAX)和复杂的反爬虫机制(如IP封锁、验证码、用户行为检测等)。BrightData 提供了庞大的代理网络和智能抓取解决方案,可以绕过这些限制,保证数据采集的稳定性和连贯性。
-
数据质量和覆盖面的保障 通过BrightData的全球代理节点,可以采集来自不同地区、不同设备类型的网页数据,保证数据的多样性和代表性,避免数据偏差。
-
降低技术门槛和运维成本 BrightData 提供了多种API和自动化工具,集成方便,用户无需从零开发复杂的爬虫框架,节省开发和维护资源。
-
实时性和持续更新的数据需求 在电商比价、市场监控、舆情分析等场景,需要实时或定期更新数据。自动化加BrightData能支持定时任务,持续抓取最新数据,确保信息的时效性。
总结来说,自动化与BrightData网页抓取结合,能够解决传统数据采集中的效率低、反爬难、数据不全和维护复杂等问题,满足业务对高质量、大规模、实时数据的需求。
二、Bright Data网页抓取工具 - 网页爬虫工具实测
2.1 首先注册用户
点击进行注册用户
2.2 首先点击 Proxies & Scraping ,再点击浏览器API的开始使用
2.3 填写通道名称,打开CAPTCHA解决器,再点击添加
2.4 点击探索测试环境
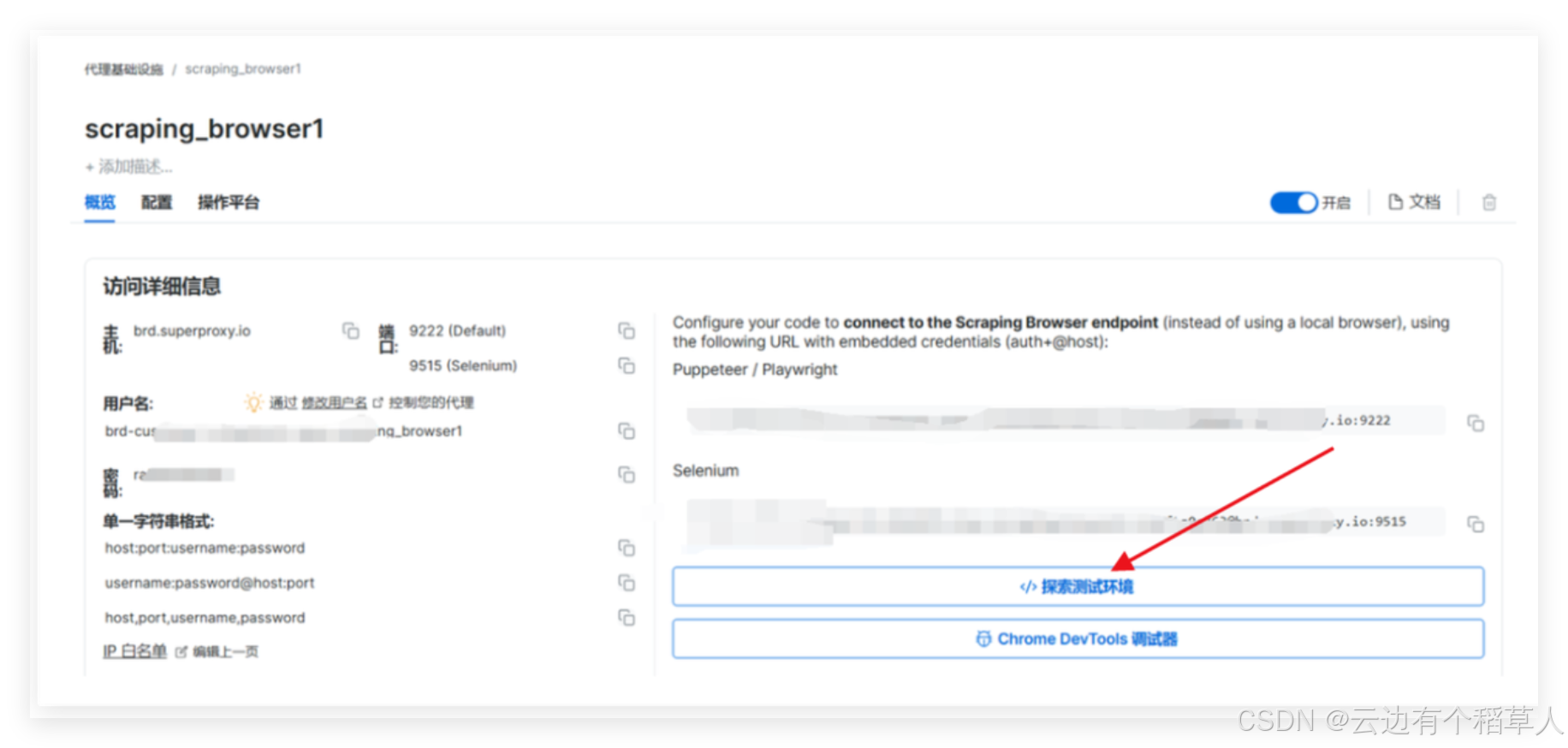
可以看到操作平台有可用的代码实例
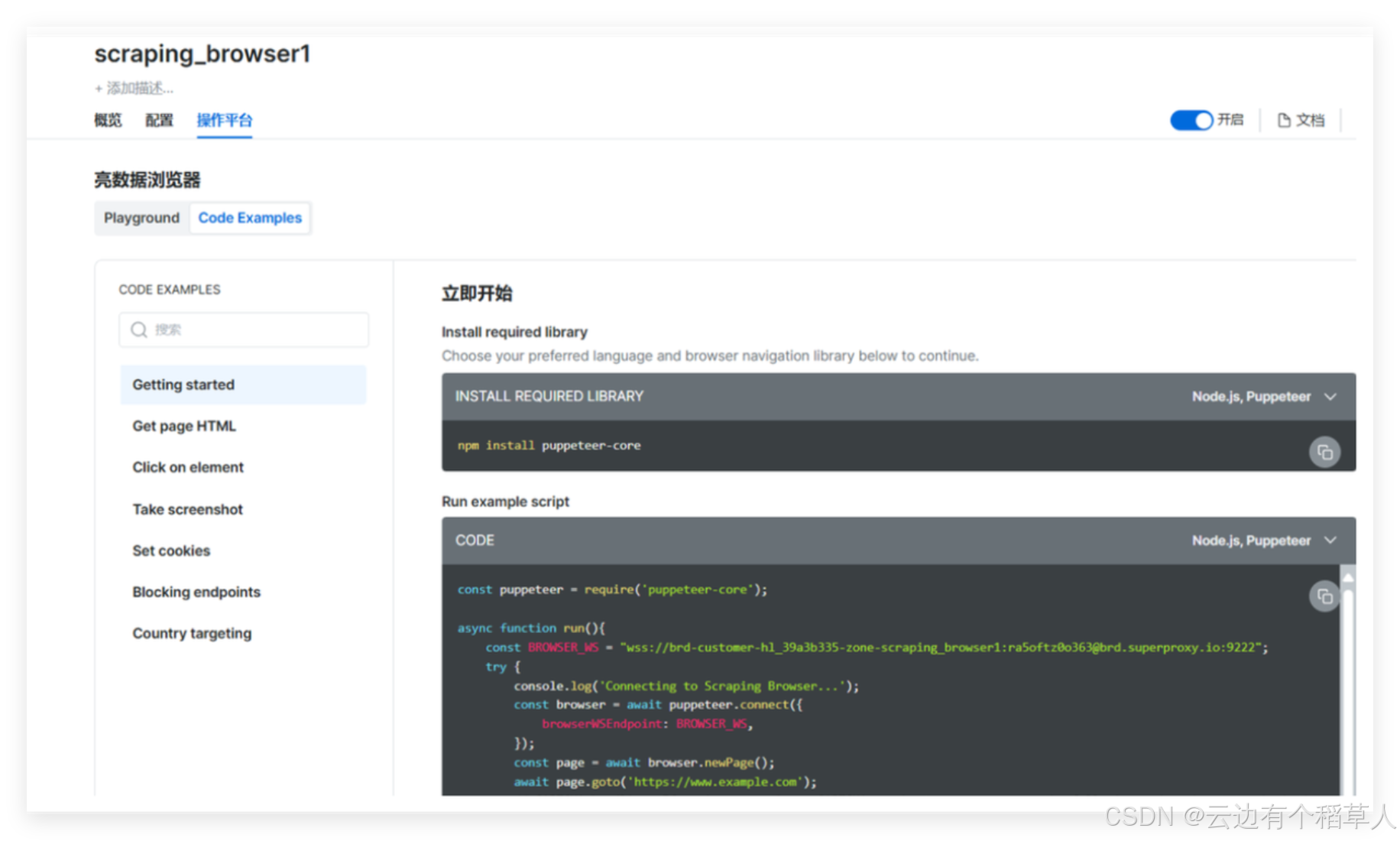
2.5 实例
以亚马逊平台的电脑产品为例首先获取用户对商品的评价数据,python代码如下:
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.common.by import By
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
import pandas as pd# 替换为你自己的信息即可
AUTH = 'brd-customer-您的客户 ID-zone-您的区域:您的密码'
SBR_WEBDRIVER = f'https://{AUTH}@brd.superproxy.io:9515'def main():print('连接到 Scraping Browser...')sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')with Remote(sbr_connection, options=ChromeOptions()) as driver:print('连接成功!正在导航到亚马逊电脑产品列表...')driver.get('https://www.amazon.com/s?k=laptop')print('页面加载完成!正在提取商品链接...')driver.implicitly_wait(10)# 获取所有商品的容器products = driver.find_elements(By.XPATH, '//div[@data-component-type="s-search-result"]')product_links = []for link in product_links:print(f'正在访问商品页面: {link}')driver.get(link)try:# 找到评价页面链接review_link = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '//a[@data-hook="see-all-reviews-link-foot"]'))).get_attribute('href')driver.get(review_link)# 获取该款式的所有评价数try:total_reviews_count = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '//div[@data-hook="total-review-count"]'))).textexcept:total_reviews_count = None# 获取评价容器reviews = WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.XPATH, '//div[@data-hook="review"]')))for review in reviews:try:# 提取评价标题title = review.find_element(By.XPATH, './/a[@data-hook="review-title"]').textexcept:title = Nonetry:# 提取评价内容content = review.find_element(By.XPATH, './/span[@data-hook="review-body"]').textexcept:content = Nonetry:# 提取评价星级rating = review.find_element(By.XPATH, './/i[@data-hook="review-star-rating"]').textexcept:rating = Nonetry:# 提取评价者reviewer = review.find_element(By.XPATH, './/span[@class="a-profile-name"]').textexcept:reviewer = Nonetry:# 提取评价时间review_date = review.find_element(By.XPATH, './/span[@data-hook="review-date"]').textexcept:review_date = Nonetry:# 提取评价的评价数review_helpful_count = review.find_element(By.XPATH, './/span[@data-hook="helpful-vote-statement"]').textexcept:review_helpful_count = Noneall_reviews.append({'评价网址': review_link,'评价标题': title,'评价内容': content,'评价星级': rating,'评价者': reviewer,'评价时间': review_date,'该款式的所有评价数': total_reviews_count,'评价的评价数': review_helpful_count})except:print('未找到该商品的评价页面')# 将数据保存到 DataFramedf = pd.DataFrame(all_reviews)# 将数据保存到 CSV 文件df.to_csv('amazon_laptop_reviews.csv', index=False, encoding='utf-8-sig')print('数据提取完成,已保存到 amazon_laptop_reviews.csv')if __name__ == '__main__':main()数据采集结果如下:

2.6 亮数据集成的AI工具帮我们生成过滤器高效进行数据的筛选
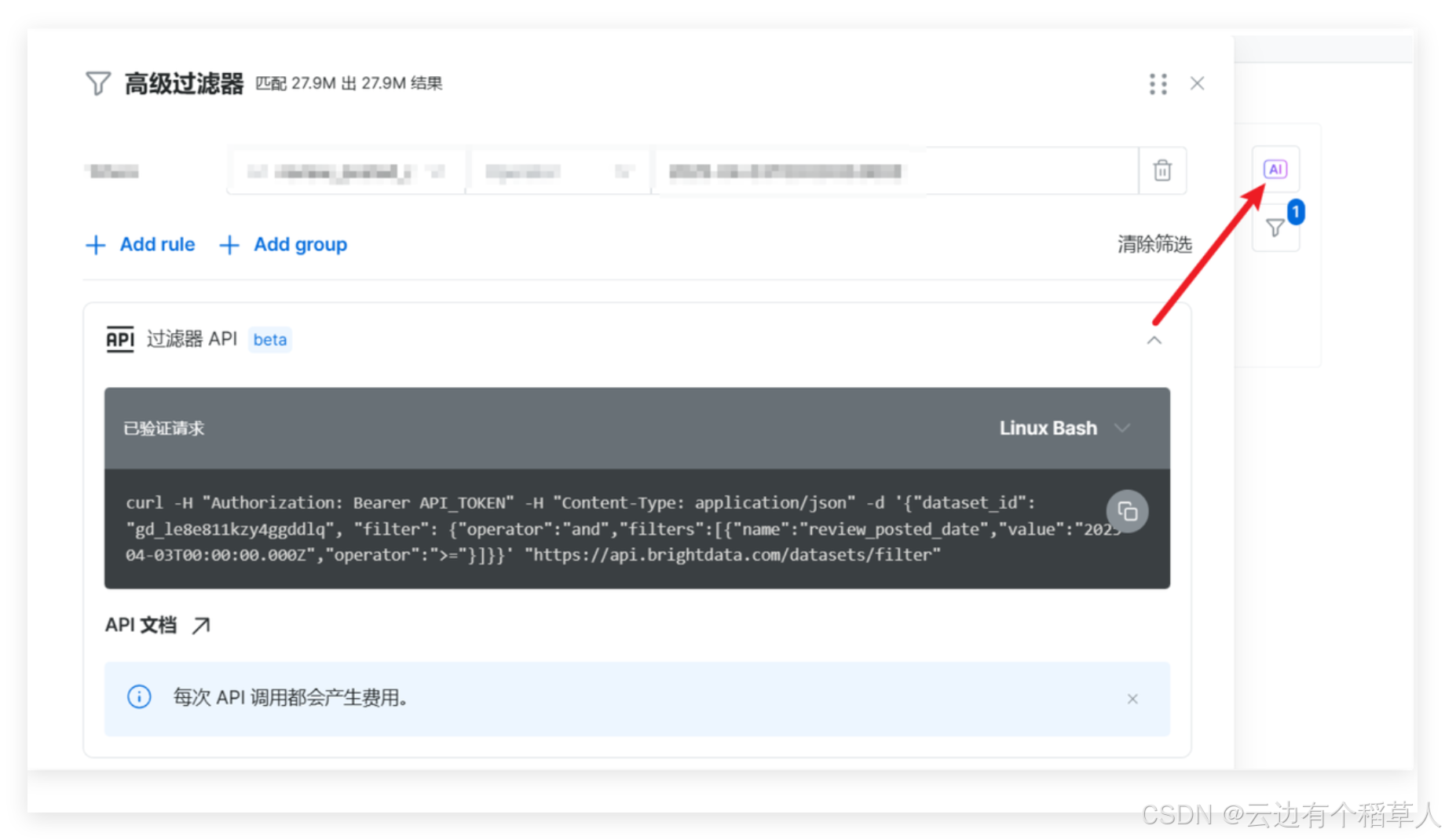
三、Web Scrapers API
3.1 什么是 Web Scraper API?
Bright Data的Web Scraper API 是一个基于云的网页抓取API服务,允许用户通过简单的API调用,自动化抓取目标网页中的结构化数据。它集成了代理网络、反爬虫绕过、数据提取与交付功能,使得用户无需自己开发复杂的爬虫程序,也能快速稳定地获得高质量网页数据。
3.2 Web Scraper API的主要功能
-
无需自建爬虫:用户通过配置页面采集规则,无需担心编码细节,API自动帮您完成复杂抓取工作。
-
自动处理动态网页:支持JavaScript渲染内容自动抓取,解决SPA和AJAX页面采集难题。
-
内置反反爬机制:自动绕过网站防爬措施,包括IP封禁、验证码识别、频率限制等。
-
灵活定制抓取规则:支持多种选择器(CSS selector、XPath)定义采集数据目标。
-
数据格式多样:支持JSON、CSV等格式输出,便于后续集成。
-
高可靠稳定性:结合全球住宅代理IP池,实现高速且抗封禁的抓取体验。
-
自动分页处理:支持自动识别并抓取分页数据,覆盖全量内容。
-
调度与监控:接口支持定时调度,抓取任务可监控异常及执行状态。
3.3 实测
Web Scraper里面有各种网站的丰富爬虫应用可以直接使用
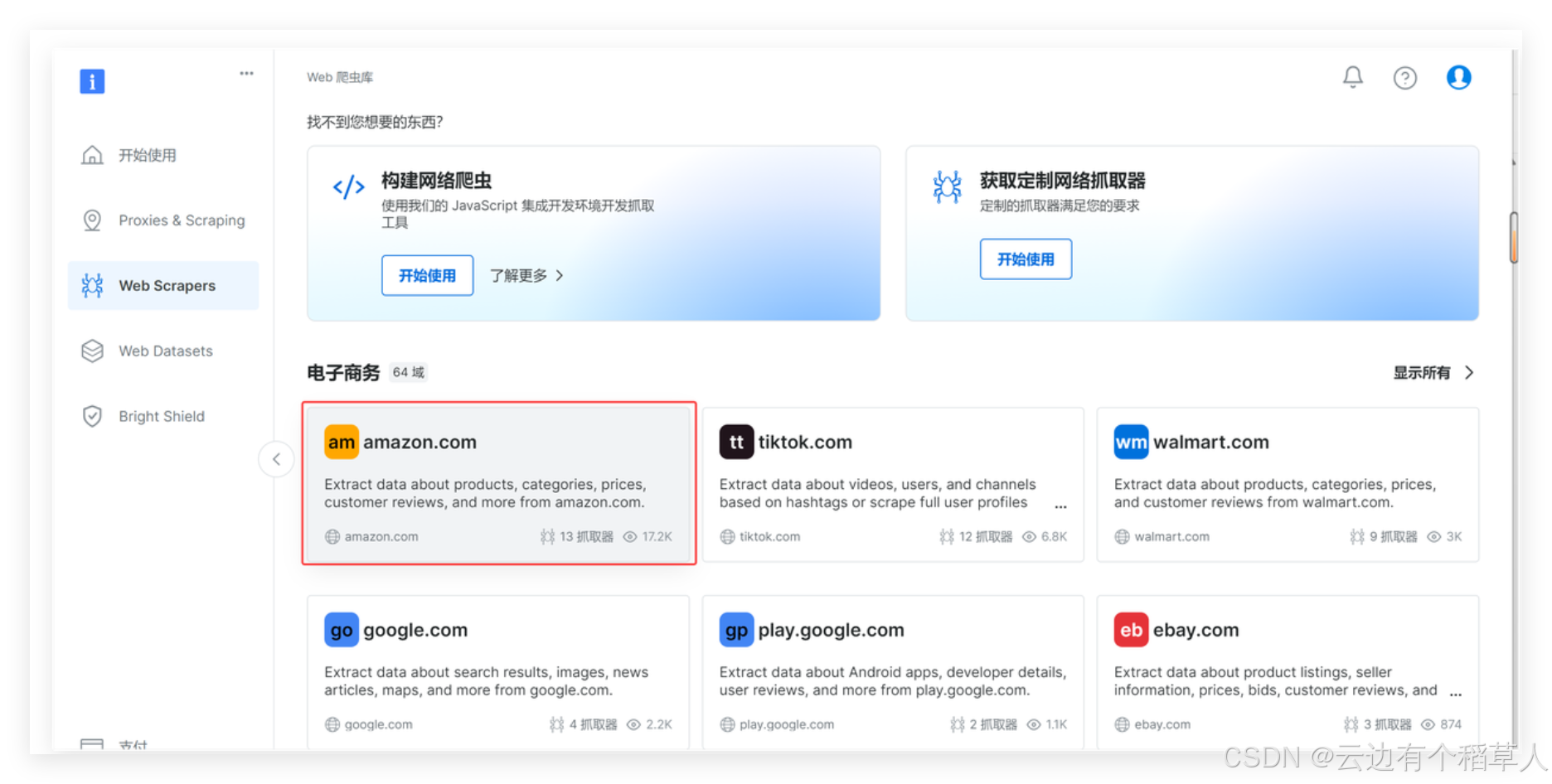
我们找到amazon.com下面的Amazon products - discover by category url,一款按照产品类别来抓取的工具
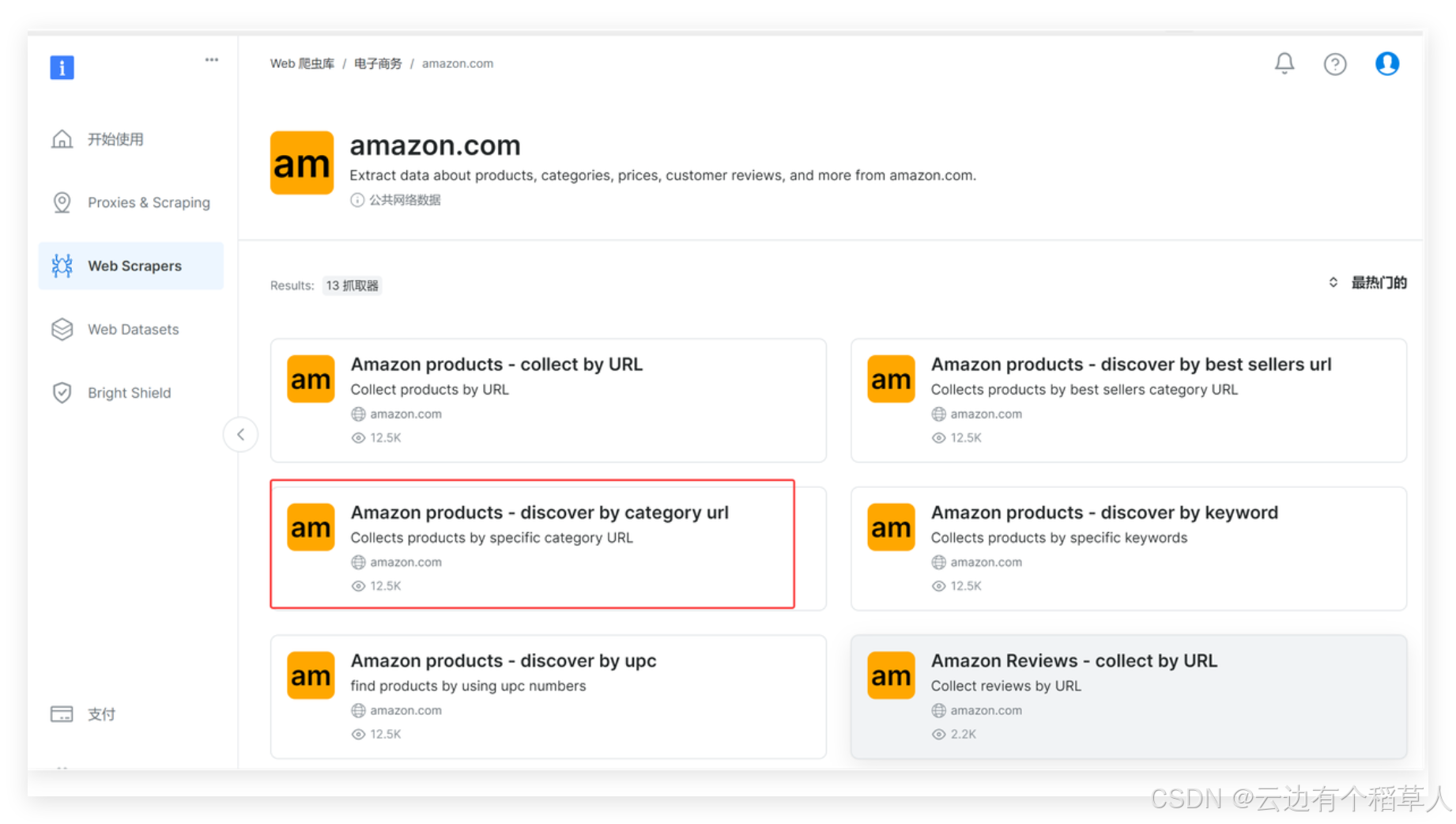
这里选择无代码抓取器,点击下一个
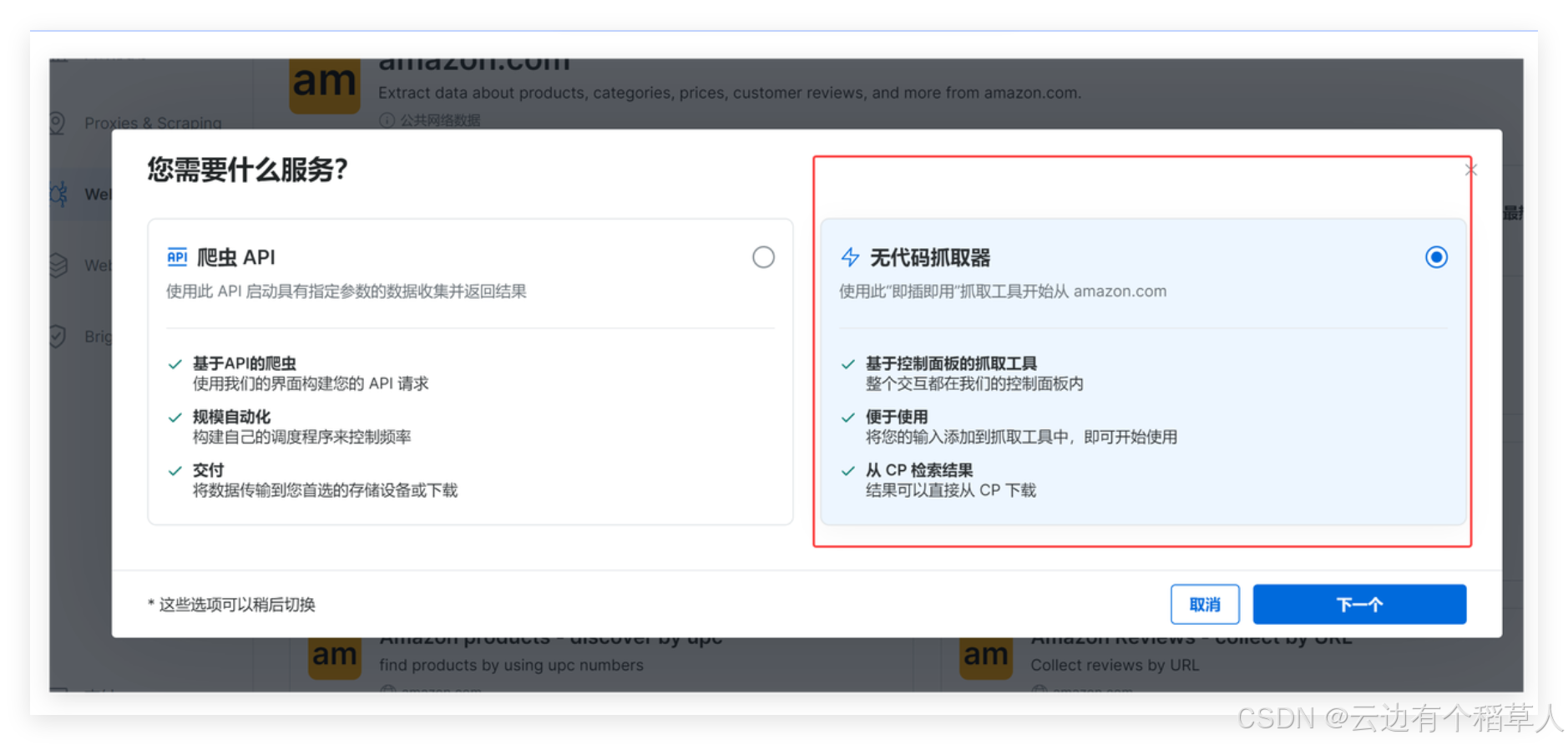
在里面填入自己需要的商品的网页链接
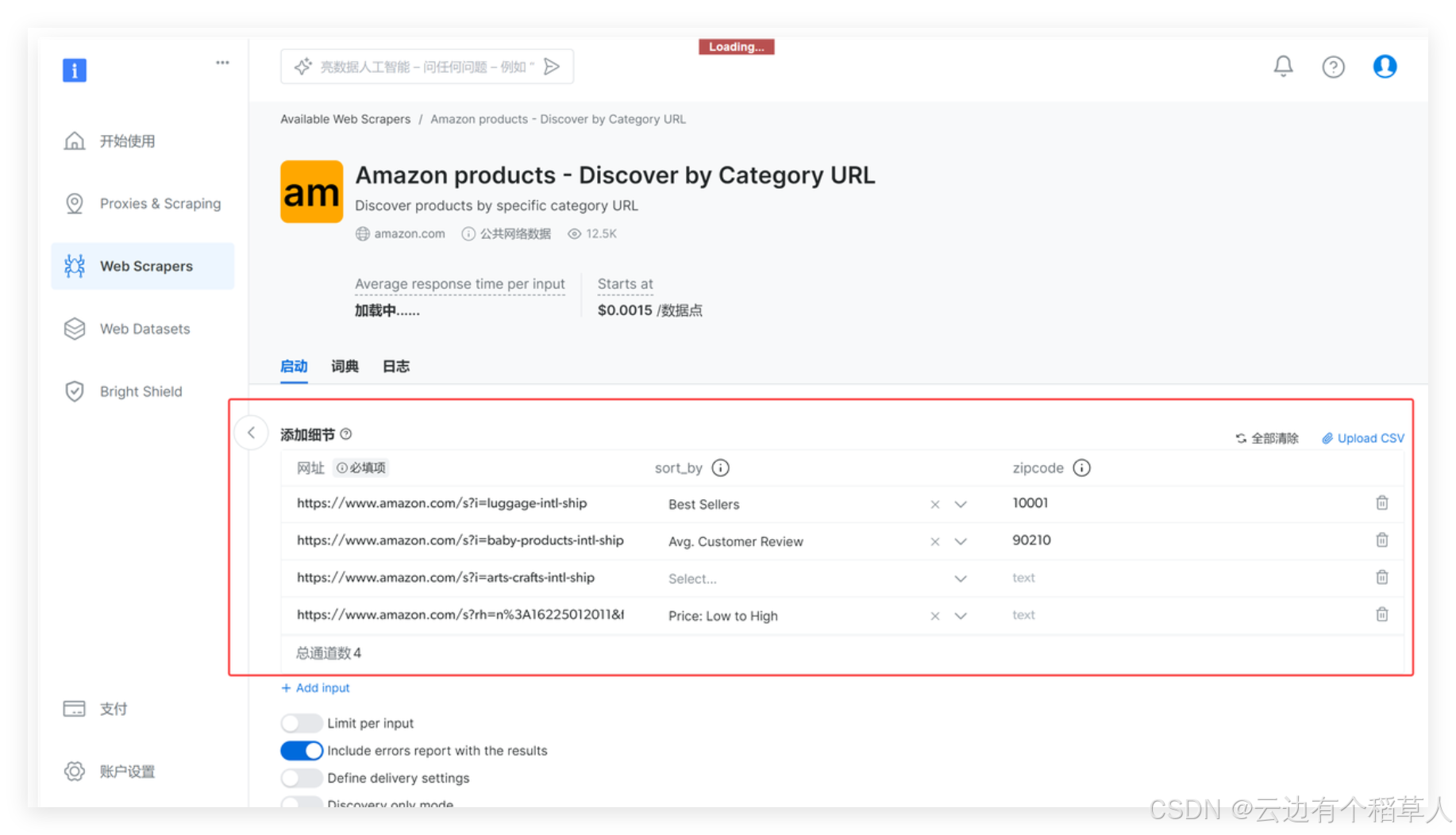
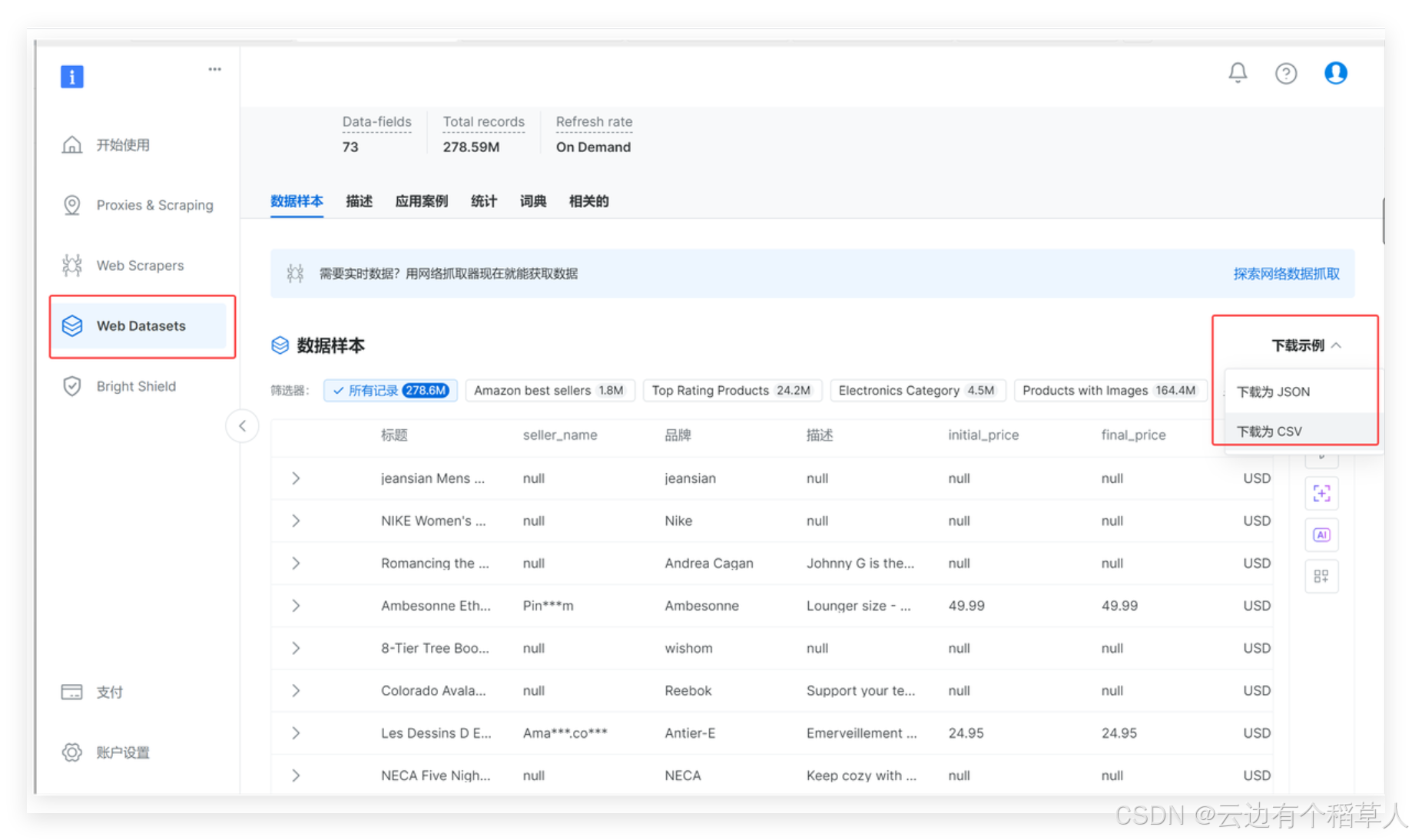
填写完毕之后,点击下方的start collecting开始收集数据,下面就是获取的数据样本:
四、Bright Data与自动化工具的结合
4.1 结合n8n实现电商价格监测自动化流程
应用场景:企业需要实时监控竞争对手电商平台的产品价格波动,及时调整自家定价策略。
流程步骤:
-
定时触发:n8n的定时触发节点每小时启动执行。
-
调用Bright Data API:通过HTTP请求节点调用Bright Data的Web Scraper API,抓取目标电商网页的产品价格数据。
-
数据清理和格式转换:利用n8n的函数节点对抓取的JSON数据进行解析,提取关键信息,如商品名称、当前价格、变动百分比等。
-
条件判断和通知:设置条件节点判断价格是否低于预设阈值,如果满足条件,通过钉钉消息节点或者企业微信节点发出预警通知给相关运营人员。
-
存储数据:使用数据库节点将数据写入企业数据库或数据仓库,便于历史价格分析与报表生成。
n8n流程示意图:
定时触发 --> HTTP请求(Bright Data API)--> 函数解析 --> 条件判断 --> 钉钉/企业微信通知↓数据库存储节点4.2 国内自动化平台结合实例:腾讯云函数+Bright Data抓取+微信企业号通知
应用场景:制造企业需要每天自动抓取行业新闻,实时掌握市场动态,同时将重要新闻推送至企业微信群。
流程步骤:
-
腾讯云函数作触发器:每天定时调用对应函数。
-
云函数中发起Bright Data请求:利用Bright Data提供的API接口完成新闻抓取。
-
处理爬取结果:对抓到的新闻信息筛选、去重,提取标题和摘要。
-
通过微信企业号API发送消息:将精选新闻自动推送到企业微信群,确保团队及时获悉。
-
日志写入COS(对象存储):保存当天抓取的原始数据做备份。
五、Bright Data网页抓取工具的核心优势


5.1 全球分布的庞大代理网络
-
Bright Data 拥有数百万真实的住宅和移动IP地址,遍布全球各地,极大提升抓取的覆盖范围和数据多样性。
-
对于电商平台,不同地域用户行为差异巨大,代理网络保证跨地域采集的真实性和完整性,使数据具备更高代表性。
-
代理质量高,反爬虫难度低,避免采集时被目标网站封禁,大幅提高抓取成功率。
5.2 高匿名性与反反爬虫技术
-
真实IP代理和灵活流量控制,有效防止被电商平台反爬虫策略检测。
-
智能切换IP和请求头,模拟真实用户行为,减少封禁风险。
-
支持Captcha自动识别及绕过,提高抓取稳定性。
5.3 易用的API与自动化集成
-
提供RESTful API,方便客户自动化调用,快速集成进现有数据采集或BI系统。
-
支持定时任务和大批量请求,满足电商平台数据实时更新需求。
-
配合爬虫管理平台实现任务调度、数据可视化监控与管理。
5.4 数据质量保障和合规支持
-
自动去重、清洗机制,提升采集数据的准确性和完整性。
-
遵循robots.txt协议和数据隐私法规,在合规前提下采集,降低法律和商业风险。
-
提供采集日志和轨迹,方便审计和溯源。
5.5 灵活定制与多数据源支持
-
支持多种网页类型(静态页面、动态JavaScript渲染页面)。
-
配合Selenium等自动化工具处理复杂交互,确保电商平台商品详情、用户评论、行为轨迹等多样信息采集。
六、Bright Data结合电商平台用户行为数据采集的应用优势分析
6.1 跨地域用户行为全覆盖
电商平台运营覆盖全球,用户行为受文化、促销活动和物流差异影响。Bright Data多地域代理网络支持同时采集欧洲、北美、亚洲用户行为数据,提供多维度洞察:
-
浏览页面路径
-
商品点击频次
-
加购物车行为
-
购买转化率
-
用户评论和评分动态
帮助运营团队精准分析地域用户偏好和差异,制定个性化营销策略。
6.2 智能绕过反爬虫保护,实现稳定数据流
电商平台普遍具备强反爬手段,如IP封禁、请求频率限制等。Bright Data代理池结合自动切换IP和请求指纹,确保数据采集过程不中断,实现连续稳定的数据流输入。
6.3 实时和批量数据抓取相结合
-
对促销活动、秒杀场景等时效性强的用户行为,可利用Bright Data网页抓取工具实现实时数据采集,帮助运营快速响应市场变化。
-
对历史用户行为进行批量采集和分析时,批量请求能力保证爬取效率,支持海量数据构建深度用户画像。
6.4 高质量数据保障AI模型训练基础
通过亮数据处理流程,采集到的用户行为数据结构规范、准确完整,确保后续基于这些数据开展的用户画像构建、购买预测、推荐算法等AI任务效果显著提升。
6.5 合规数据采集助力企业风险控制
电商行业高度重视用户隐私和合规性,Bright Data的合规机制有效保障数据采集过程中符合GDPR、CCPA等法律法规要求,降低企业法律风险。
七、总结
Bright Data在网页抓取工具方面具备强大的全球住宅和移动代理网络,能有效绕过反爬虫机制,保障抓取稳定性和高成功率。其工具支持动态网页渲染和自动分页,配备易用的API接口和自动化功能,帮助用户快速、高效地获取高质量结构化数据,广泛适用于电商、金融、市场监测等多个行业,总的来说亮数据(Bright Data)是一个非常好的工具,解决了我们抓取数据的各种问题,快来体验Bright Data 网页抓取+自动化吧!
完——
至此结束——
我是云边有个稻草人
期待与你的下一次相遇!