一、TL;DR
- BPE有什么问题:依旧会遇到OOV问题,并且中文、日文这些大词汇表模型容易出现训练中未出现过的字符
- Byte-level BPE怎么解决:与BPE一样是高频字节进行合并,但BBPE是以UTF-8编码UTF-8编码字节序列而非字符序列
- Byte-level BPE利用utf-8编码,利用动态规划解码,最大程度的还原字符的语义和上下文信息(这是我理解为什么LLM能够通过NTP进行理解的最主要原因)
- Qwen是使用BBPE算法,增加了中文的能力,词汇表包括151,643 tokens
二、实际业务的使用
字节级别字节对编码(BBPE)是一种高效的分词算法,它将输入文本分割为可变长度的字节 n-gram(子词),并将其映射为词汇表中的 token ID。以下是 BBPE 分词算法将输入文本转换为 token ID 的详细过程,以及如何结合词表进行文件操作:
2.1 输入文本的字节表示
-
UTF-8 编码:首先,输入文本(如一行字符串)会被转换为 UTF-8 字节序列。UTF-8 编码将每个 Unicode 字符映射为 1 到 4 个字节。
-
示例:假设输入文本是
"Hello, 世界",其 UTF-8 字节序列为:[72, 101, 108, 108, 111, 44, 32, 228, 189, 160, 229, 165, 189]其中,
"Hello,"是 ASCII 字符,每个字符占用 1 个字节;而"世界"是 UTF-8 编码的中文字符,每个字符占用 3 个字节。
2.2 BBPE 分词
-
学习词汇表:BBPE 通过迭代合并最频繁出现的字节对来构建词汇表。词汇表中包含基本字节(0-255)和通过 BPE 合并生成的字节 n-gram。
-
分词过程:输入的字节序列会被分割成词汇表中存在的子词(字节 n-gram)。这些子词是通过 BPE 合并规则生成的。
-
示例:假设词汇表中有以下条目:
72, 101, 108, 108, 111, 44, 32, 228, 189, 160, 229, 165, 189
72 101, 108 108, 111 44, 32 228, 189 160, 229 165 1892.3 映射为 Token ID
-
词汇表文件:BBPE 的词汇表通常存储在一个文件中,文件格式类似于:
-
72 101 108 108 108 111 44 32 228 189 160 229 165 189 -
映射过程:分词器将分割后的子词与词汇表文件进行匹配,找到对应的 token ID。
-
示例:假设分词后的子词为
[72 101, 108 108, 111 44, 32 228, 189 160, 229 165 189],其对应的 token ID 可能是:[10, 15, 20, 25, 30, 35]其中,
72 101在词汇表中的行号是 10,108 108的行号是 15,依此类推。
2.4 文件操作
-
加载词汇表:分词器在初始化时会加载词汇表文件,将其内容存储到内存中,以便快速查找。
# 假设词汇表文件名为 vocab.txt
with open('vocab.txt', 'r', encoding='utf-8') as f:vocab = [line.strip() for line in f.readlines()]# 将子词映射为 token ID
def tokenize(input_text):# 将输入文本转换为 UTF-8 字节序列byte_sequence = input_text.encode('utf-8')# 分词(这里简化为直接匹配,实际分词器会更复杂)tokens = []for subword in byte_sequence.split():subword_str = ' '.join(map(str, subword))token_id = vocab.index(subword_str)tokens.append(token_id)return tokensinput_text = "Hello, 世界"
token_ids = tokenize(input_text)
print(token_ids)2.5 总结
-
输入文本 → UTF-8 字节序列 → BBPE 分词 → 映射为 Token ID
-
词汇表文件是 BBPE 分词的核心,它存储了所有可能的子词及其对应的 token ID。
三、Byte-level BPE算法原理
paper链接: https://arxiv.org/pdf/1909.03341
papr:Neural Machine Translation with Byte-Level Subwords
3.1 为什么要开发Byte-level BPE
- 解决不了中文/日语这种语言:几乎所有的分词算法都是基于字符级词汇表构建的(字符、子词或单词),但对于日语和中文的字符丰富且存在噪声文本的语言,罕见字符可能会不必要地占据词汇表的槽位,从而限制其紧凑性
- 字节表示会引入计算成本:使用字节级别表示文本,并将 256 个字节集作为词汇表可以解决这个问题,但是会引入高昂的计算成本
3.2 实际合并方法和举例
与BPE算法的差异:

来自日语 - 英语的不同词汇表分词示例。
空格被下划线替换,而空格用于分隔词元。,随着分词粒度从细到粗,词元的形态是如何变化的:字节(256)→ 字节级别字节对编码(BBPE,1K、2K、4K、8K)→ 字符(8K)→ 字节级别字节对编码(BBPE,16K、32K)→ 字节对编码(BPE,16K、32K)。

BBPE算法在基于字节(Byte)进行合并过程和BPE一致、也是选取出现频数最高的字符对进行合并,合并过程如下图所示: 关注到红色箭头,输入是日文当词表大小是1K时,A8 BC 两个字节并没有合并成一个 Token,在词表大小是2K时,A8BC被BBPE合并成一个Token。
3.3 原理上具体怎么做?
别看了,直接用就好,最重要的还是理解对input text进行分词后查表再转成encoder的过程
字节级别表示的编码:
- 使用 UTF-8 编码文本,它将每个 Unicode 字符编码为 1 到 4 个字节。这使得我们可以将句子建模为字节序列,而不是字符序列。
- 13.8 万个 Unicode 字符覆盖了 150 多种语言,但我们使用 UTF-8 字节(256 个可能字节中的 248 个)来表示任何语言的句子。
如何解决计算成本高昂的问题?
字节级别的n-gram方法来减少计算成本:
编码过程:
- 将Unicode字符映射为1-4个字节
- 将字节序列分割为可变长度的 n 元组(字节级别的“子词”)
- 使用深度卷积层或双向循环层与门控循环单元(GRU)来对 BBPE embedding进行上下文化
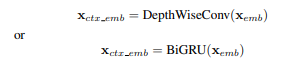
解码过程:
- 采用动态规划算法从字节序列恢复Unicode字符
- 对于给定的字节序列 {B}kN,我们用 f(k) 表示我们可以从中恢复的最大字符数。然后 f(k) 具有最优子结构
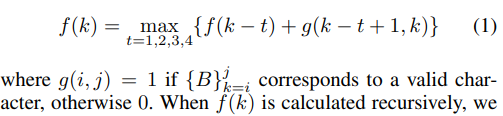
如果 {B}kj 对应一个有效的字符,则 g(i,j)=1,否则为 0。当 f(k) 递归计算时,我们还在每个位置 k 记录选择,以便通过回溯恢复解决方案。
解码过程中-说人话:
- 使用动态规划去恢复最有效(g代表有效性指示函数)和可恢复的最大字符数(动态词汇表便于最大化的数据还原)
四、Qwen的应用
4.1 Qwen3的技术报告原文:

4.2 Qwen实际代码实现:
参考:https://github.com/QwenLM/Qwen/blob/main/tokenization_note.md
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen-7B', trust_remote_code=True)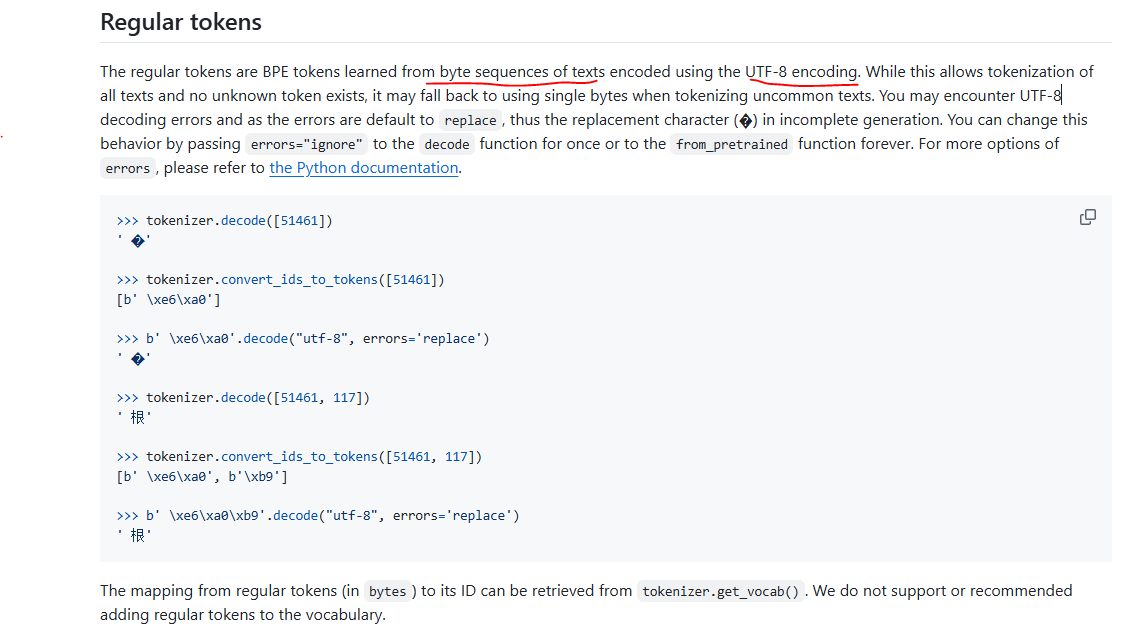
特殊字符的处理:
特殊标记对模型具有特殊功能,例如表示文档结束。理论上,这些标记在输入文本中不存在,仅在输入文本经过处理后才会出现。
可以在微调或其他需要它们的框架中这样指定特殊标记:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen-7B', trust_remote_code=True, pad_token='<|endoftext|>')