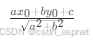导读:作为企业级应用开发中的关键技术,LangChain检索器(Retrievers)正成为构建高效RAG系统的核心组件。本文将深入探讨检索器的技术架构与实战应用,帮助开发者掌握这一重要的AI工程技术。
检索器的价值在于提供统一的检索接口,无论数据源来自向量数据库、传统关系型数据库还是搜索引擎,都能输出标准化的Document对象列表。这种设计显著提升了系统的可扩展性和维护性。特别值得关注的是MMR(最大边际相关性)检索算法,它能够在保证相关性的同时优化结果多样性,有效解决传统相似性搜索中的重复结果问题。
文章通过完整的代码示例演示了如何集成DashScope嵌入模型与Milvus向量数据库,构建生产级别的检索系统。实战案例涵盖了从基础的相似性搜索到高级的MMR检索配置,展示了不同搜索策略在实际场景中的性能差异。对于正在构建智能问答系统或文档检索应用的技术团队而言,这些实践经验将为项目实施提供重要的技术指导和最佳实践参考。
LangChain检索器Retrievers案例实战
什么是Retriever
Retriever是LangChain框架中的核心组件,专门负责从各种数据源中检索相关文档信息。它在检索增强生成(RAG)系统中扮演着关键角色,为大语言模型提供精准的上下文信息。
核心特性
统一接口设计:Retriever提供标准化的检索流程,无论数据来源如何(向量数据库、传统数据库或搜索引擎),最终都输出统一的Document对象列表,确保了系统的一致性和可维护性。
多源混合检索能力:支持同时查询多种数据源,包括向量库、传统数据库和搜索引擎,这种多源检索策略能够显著提高召回率,确保更全面的信息获取。
与VectorStore的协作关系:Retriever本身不直接管理数据存储,而是依赖VectorStore组件(如FAISS、Chroma等)来实现数据的向量化存储与检索操作。
RAG系统中的定位:在检索增强生成流程中,Retriever充当"数据入口"的角色,负责为生成模型提供精准、相关的上下文信息。
技术特点
模块化设计架构:采用插件式扩展机制,开发者可以根据业务需求自定义检索算法,支持混合搜索、结果重排序等高级功能。
异步处理支持:通过async_get_relevant_documents方法实现异步检索,在高并发场景下能够提供高效的检索性能。
链式调用集成:与LangChain生态系统中的其他组件(如Text Splitters、Memory等)实现无缝集成,支持复杂的文档处理流程。
from langchain_core.retrievers import BaseRetriever
核心概念解析:召回率(Recall)
召回率是信息检索和机器学习中衡量模型查全能力的核心指标。在文档检索场景中,如果系统需要从100篇相关文档中进行检索,最终找出了80篇,那么召回率就是80%。
召回率高意味着系统能够找到更多相关结果,减少遗漏,但可能会包含一些不相关的结果,这时准确率可能会相应降低。在实际应用中,需要在召回率和准确率之间找到最佳平衡点。
Retriever常见类型
基础检索器:VectorStoreRetriever
VectorStoreRetriever是最常用的检索器类型,它通过将文档嵌入为向量表示,利用相似度计算(如余弦相似度)来检索相关文档。
基础使用示例
from langchain_community.vectorstores import FAISS# 创建向量存储并转换为检索器
retriever = FAISS.from_documents(docs, embeddings).as_retriever(search_type="mmr", # 最大边际相关性搜索search_kwargs={"k": 5, "filter": {"category": "news"}}
)
as_retriever()方法详解
as_retriever()方法是向量库与检索器之间的桥梁,它将向量库实例转换为检索器对象,实现与LangChain链式调用(如RetrievalQA)的无缝对接。
源码实现:
def as_retriever(self, **kwargs: Any) -> VectorStoreRetriever:tags = kwargs.pop("tags", None) or [] + self._get_retriever_tags()return VectorStoreRetriever(vectorstore=self, tags=tags, **kwargs)
关键参数配置
search_type 搜索类型配置
| 类型 | 适用场景 | Milvus对应操作 |
|---|---|---|
| “similarity” | 基础相似度检索 | search() |
| “mmr” | 多样性结果优化 | max_marginal_relevance_search() |
| “similarity_score_threshold” | 阈值过滤检索 | search() + score_threshold |
MMR检索配置示例
最大边际相关性(MMR)搜索能够在保证相关性的同时优化结果的多样性,避免返回过于相似的文档。
mmr_retriever = vector_store.as_retriever(search_type="mmr",search_kwargs={"k": 3, # 最终返回的文档数量"fetch_k": 20, # 初始检索的候选文档数量"lambda_mult": 0.5 # 相关性与多样性的平衡因子}
)
综合案例实战
以下是一个完整的Retriever实现案例,展示了从文档准备到检索执行的完整流程。
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_milvus import Milvus
from langchain_core.documents import Document# 初始化嵌入模型
embeddings = DashScopeEmbeddings(model="text-embedding-v2", # 使用第二代通用文本嵌入模型max_retries=3,dashscope_api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
)# 构建测试文档集合
documents = [Document(page_content="MMR搜索和LangChain整合Milvus实战",metadata={"source": "humaonan.blog.csdn.net/article/details/148318637"}),Document(page_content="Milvus向量Search查询综合案例实战(下)",metadata={"source": "humaonan.blog.csdn.net/article/details/148292710"}),Document(page_content="Milvus向量Search查询综合案例实战(上)",metadata={"source": "humaonan.blog.csdn.net/article/details/148267037"}),Document(page_content="嵌入大模型与LLM技术全面解析与实战指南",metadata={"source": "humaonan.blog.csdn.net/article/details/148198246"})
]# 创建向量存储
vector_store = Milvus.from_documents(documents=documents,embedding=embeddings,collection_name="retriever_test1",connection_args={"uri": "http://192.168.19.152:19530"}
)# 配置检索器
retriever = vector_store.as_retriever(search_type="mmr",search_kwargs={"k": 2}
)# 执行检索
results = retriever.invoke("如何实现向量搜索?")
print(results)
检索策略对比分析
相似性搜索(Similarity Search):
- 优点:执行速度快,实现简单
- 缺点:可能返回过于相似的结果,缺乏多样性
- 适用场景:对检索速度要求较高,对结果多样性要求不高的场景
MMR搜索(Maximum Marginal Relevance):
- 优点:保证结果多样性,自动去重相似内容
- 缺点:执行速度相对较慢,计算复杂度较高
- 适用场景:需要多样化结果,避免信息重复的应用场景
实际应用建议
在生产环境中使用Retriever时,建议根据具体业务场景选择合适的检索策略。对于需要快速响应的实时查询系统,可以优先选择相似性搜索;对于需要全面、多样化信息的知识问答系统,建议使用MMR搜索策略。同时,可以通过调整lambda_mult参数来平衡相关性和多样性的权重,以获得最佳的检索效果。