摘要
我们提出了通用文档处理(UDOP)模型,一种基础的文档人工智能模型,它将文本、图像和布局模态与多种任务格式统一在一起,包括文档理解和生成。UDOP利用文本内容与文档图像之间的空间关联,通过一种统一的表示来建模图像、文本和布局模态。通过一种新颖的视觉-文本-布局变换器,UDOP将预训练和多领域下游任务统一为基于提示的序列生成方案。UDOP在大规模未标注文档语料库上进行预训练,采用创新的自监督目标和多样的标注数据。UDOP还学习通过遮蔽图像重建,从文本和布局模态生成文档图像。据我们所知,这是文档人工智能领域首次有一个模型能够同时实现高质量的神经文档编辑和内容定制。我们的方法在8个文档人工智能任务中设立了新的最先进标准,例如文档理解和问答,涵盖了金融报告、学术论文和网站等不同数据领域。UDOP在文档理解基准测试中排名第一。
1. 引言
文档人工智能研究数字文档的信息提取、理解和分析,例如商业发票、税务表格、学术论文等。它是一个多模态任务,其中文本结构性地嵌入在文档中,同时还有符号、图像和样式等其他视觉信息。与经典的视觉-语言研究不同,文档数据具有二维空间布局:文本内容基于不同的文档类型和格式(如发票与税务表格)在不同位置进行结构性分布;格式化数据如图像、表格和图表也被布局在文档中。因此,能够有效且高效地建模和理解布局对于文档信息提取和内容理解至关重要,例如标题/签名提取、欺诈支票检测、表格处理、文档分类以及文档中的自动数据录入。
文档人工智能具有独特的挑战,使其与其他视觉-语言领域不同。例如,文本和视觉模态之间的跨模态交互在这里比常规视觉-语言数据更为强烈,因为文本模态是视觉上定位于图像中的。此外,下游任务在领域和范式上也十分多样,例如文档问答、布局检测、分类、信息提取等。这带来了两个挑战:(1)如何利用图像、文本和布局模态之间的强相关性,并将它们统一建模为一个整体的文档?(2)如何使模型能够高效且有效地学习不同领域的视觉、文本和布局任务?
近年来,文档人工智能领域取得了显著进展。大多数模型框架与传统的视觉-语言框架类似:一类工作继承了视觉-语言模型,通过视觉网络(如视觉变换器)对图像进行编码,然后将编码结果与文本一起输入到多模态编码器中;另一类工作使用一个联合编码器处理文本和图像。一些模型将文档视为仅包含文本的输入。在这些工作中,布局模态通常表示为浅层位置编码,例如在文本编码中添加二维位置编码。文档数据中固有的模态之间的强关联性未得到充分利用。此外,为了执行不同的任务,许多模型不得不使用任务特定的头部,这既低效又需要为每个任务进行手动设计。
为了应对这些挑战,我们提出了通用文档处理(UDOP),一个基础的文档人工智能模型,它统一了视觉、文本和布局以及不同的文档任务。与以往将图像和文档文本视为两个独立输入的做法不同,在UDOP中,我们提出通过统一的布局引导表示来对它们进行建模:在输入阶段,我们将文本标记的嵌入与文本所在图像块的特征结合起来。这种简单而新颖的布局引导表示大大增强了文本和视觉模态之间的交互。
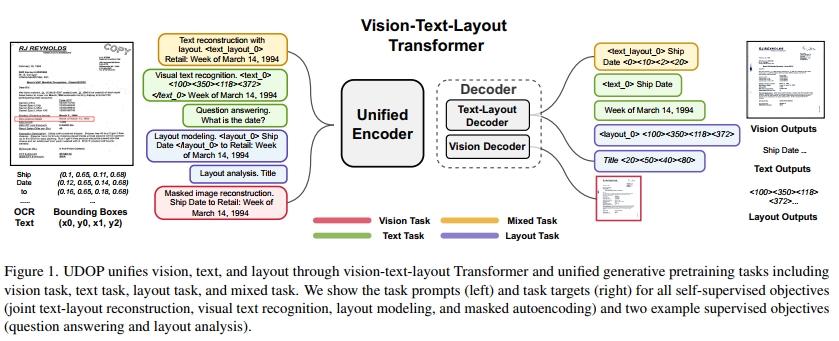
除了布局引导表示,为了形成统一的不同视觉、文本和布局任务的范式,UDOP首先构建了一个同质化的词汇表,用于文本和文档布局,将布局(即边界框)转换为离散化的标记。其次,我们提出了视觉-文本-布局(VTL)变换器,它由一个模态无关的编码器、文本-布局解码器和视觉解码器组成。VTL变换器允许UDOP联合编码和解码视觉、文本和布局。UDOP将所有下游任务统一为一个序列到序列的生成框架。除了上述讨论的模态统一和任务范式的挑战外,另一个问题是,之前的工作使用了最初为单一模态学习设计的自监督学习目标,例如遮蔽语言建模,或经典的视觉-语言预训练方法,例如对比学习。而我们提出了新颖的自监督学习目标,旨在支持整体文档学习,包括布局建模、文本和布局重建以及视觉识别,这些目标能够同时考虑文本、视觉和布局的建模(参见第4节)。除了序列生成,UDOP还可以利用遮蔽自编码器(MAE)[14]通过从文本和布局模态重建文档图像来生成视觉文档。凭借这种生成能力,UDOP成为第一个能够实现高质量定制化联合文档编辑和生成的文档AI模型。
最后,我们的统一序列到序列生成框架使得我们能够方便地将所有主要的文档监督学习任务纳入预训练,包括文档布局分析、信息提取、文档分类、文档问答以及表格问答/自然语言推理(Table QA/NLI),尽管它们在任务和数据格式上存在显著差异。相比之下,之前的文档AI预训练方法仅限于无标签数据(或使用单一的辅助监督数据集,如FUNSD [55]),而由于缺乏建模灵活性,忽略了大量带有高质量监督信号的标注数据。总体而言,UDOP在1100万个公开未标注文档上进行了预训练,并结合了来自11个监督数据集(共计180万个示例)的数据。表4中的消融研究表明,仅使用我们提出的自监督目标进行预训练的UDOP,相比于之前的模型展现了显著的改进,且在预训练中加入监督数据进一步提高了性能。
我们在FUNSD [18]、CORD [34]、RVLCDIP [13]、DocVQA [33]和DUE-Benchmark [2]上对UDOP进行了评估。UDOP在DUE-Benchmark的排行榜上获得7个任务的第一名,并且在CORD上也取得了最先进的结果,从而使UDOP成为一个强大且统一的基础文档AI模型,适用于各种文档理解任务。
总而言之,我们的主要贡献包括:
-
统一的文档AI中视觉、文本和布局模态的表示和建模。
-
将所有文档任务统一到序列到序列的生成框架中。
-
在预训练中结合了新颖的自监督目标与监督数据集,实现了统一的文档预训练。
-
UDOP能够处理和生成文本、视觉和布局模态,这在文档AI领域中是首次出现的。
-
UDOP 是一个文档 AI 的基础模型,在 8 个任务上实现了最先进的技术,并且有显著的优势。
2. 相关工作
在多模态学习中统一模型架构。
统一不同模态(如视觉、语言和语音)的模型架构是一个新兴的研究方向。受自然语言处理、计算机视觉和语音处理巨大成功的启发,多模态学习中的模型架构正朝着Transformer的方向发展。一类工作将文本 token 嵌入和投影的图像块作为输入,传递给一个多模态的 Transformer [6, 42]。其他模型使用双塔或三塔架构,每个模态分别编码。双塔架构上方的投影头或融合网络生成多模态表示 [38, 56]。
通过生成框架统一任务。
最近,关于跨不同任务和领域统一训练过程的研究取得了显著进展。研究 [8] 在 1.8k 个任务上微调语言模型。研究 [7] 通过将训练目标转化为序列生成来统一多个视觉-语言任务。进一步的工作 [31, 49, 50] 通过将图像和边界框转化为离散 token,进一步结合了更多的任务,如图像生成。
文档人工智能。
LayoutLM [53] 在文档数据上预训练了 BERT 模型,使用了掩码语言建模和文档分类任务,并集成了 2D 位置信息和图像嵌入。随后的工作 [15, 16, 55] 也采用了类似 VL-BERT 的架构,并包括了额外的预训练任务,如提出的掩码图像/区域建模,并利用布局信息中的阅读顺序 [12]。研究 [11, 29] 使用多模态编码器来建模通过 CNN 提取的区域特征,并结合句子级的文本表示,使用自监督目标进行训练。研究 [20] 提出了一个无 OCR 模型,直接从文档图像生成文本输出。研究 [36] 在无标注和有标注的文档数据上训练生成语言模型,使用生成训练目标。研究 [10] 提出了将文档建模为包含边界框的 token 集合的方案。
3. 通用文档处理
我们介绍了 UDOP,一个新的文档 AI 框架,具有统一的学习目标和模型架构,能够处理文本、视觉和布局,如图 1 所示。在本节中,我们将具体讨论 UDOP 中提出的 Vision-Text-Layout Transformer,并将在下一节介绍统一的生成预训练方法。在文档处理过程中,给定一个文档图像 v,通常会使用光学字符识别(OCR)技术从 v 中提取文档中的文本 token { s i } \{ s _ { i } \} {si} 及其边界框 { ( x i 1 , y i 1 , x i 2 , y i 2 ) } , \{ ( x _ { i } ^ { 1 } , y _ { i } ^ { 1 } , x _ { i } ^ { 2 } , y _ { i } ^ { 2 } ) \} , {(xi1,yi1,xi2,yi2)}, 即每个 token 的布局信息。
( x i 1 , y i 1 ) ( x _ { i } ^ { 1 } , y _ { i } ^ { 1 } ) (xi1,yi1)和 ( x i 2 , y i 2 ) ( x _ { i } ^ { 2 } , y _ { i } ^ { 2 } ) (xi2,yi2) 分别表示边界框左上角和右下角的坐标。因此,假设我们有 M 个单词 token,输入是三元组 ( v , { s i } i = 1 M , { ( x i 1 , y i 1 , x i 2 , y i 2 ) } i = 1 M ) ( v , \{ s _ { i } \} _ { i = 1 } ^ { M } , \{ ( x _ { i } ^ { 1 } , y _ { i } ^ { 1 } , x _ { i } ^ { 2 } , y _ { i } ^ { 2 } ) \} _ { i = 1 } ^ { M } ) (v,{si}i=1M,{(xi1,yi1,xi2,yi2)}i=1M)。图 1 展示了一个文档示例(左侧)和下游任务(右侧)。
3.1. 统一的视觉、文本和布局编码器
我们在输入阶段使用一个统一的 Transformer 编码器来融合视觉、文本和布局模态。对于传统的视觉-文本数据,文本模态通常是对应图像或任务提示(如问题)的高级描述。不同于此,在文档图像中,文本嵌入在图像内,即文本和图像像素之间有一一对应关系。为了利用这种对应关系,我们提出了一种新的 Vision-Text-Layout (VTL) Transformer 架构,基于布局信息动态融合并统一图像像素和文本 token。
具体来说,给定文档图像 v ∈ R H × W × C \pmb { v } \in \mathbb { R } ^ { H \times W \times C } v∈RH×W×C,其中包含 M 个单词 token { s i } i = 1 M \{ s _ { i } \} _ { i = 1 } ^ { M } {si}i=1M,以及提取的布局结构 { ( x i 1 , y i 1 , x i 2 , y i 2 ) } i = 1 M \{ ( x _ { i } ^ { 1 } , y _ { i } ^ { 1 } , x _ { i } ^ { 2 } , y _ { i } ^ { 2 } ) \} _ { i = 1 } ^ { M } {(xi1,yi1,xi2,yi2)}i=1M,我们首先将 v 划分为 H P × W P { \frac { H } { P } } \, \times \, { \frac { W } { P } } PH×PW图像块,每个图像块的大小为 P × P × C P × P × C P×P×C。然后,我们对每个图像块使用 D 维向量进行编码,并将所有图像块的嵌入向量组合成一个序列 { v i ∈ R D } i = 1 N \{ \pmb { v } _ { i } \in \mathbb { R } ^ { D } \} _ { i = 1 } ^ { N } {vi∈RD}i=1N,其中 N = H P × W P \begin{array} { r } { N = \frac { H } { P } \times \frac { W } { P } } \end{array} N=PH×PW。文本 tokens 也通过词汇查找转换为 D 维的数值嵌入 { s i } i = 1 M \{ s _ { i } \} _ { i = 1 } ^ { M } {si}i=1M。
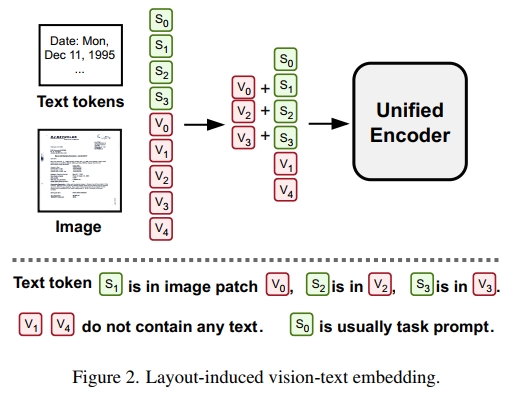
布局诱导的视觉-文本嵌入。接下来,我们构建一个统一的视觉、文本和布局表示,如图 2 所示。我们定义图像块和 token 嵌入的布局指示函数 φ 如下:
ϕ ( s i , v j ) = { 1 , i f t h e c e n t e r o f s i ′ s b o u n d i n g b o x i s w i t h i n t h e i m a g e p a t c h v j . 0 , o t h e r w i s e . ( 1 ) \phi ( \pmb { s } _ { i } , \pmb { v } _ { j } ) = \left\{ \begin{array} { l l } { \mathrm { ~ 1 , ~ } \mathrm { ~ i f ~ t h e ~ c e n t e r ~ o f ~ } s _ { i } \mathrm { ' s ~ b o u n d i n g ~ b o x ~ } } \\ { \quad \mathrm { ~ i s ~ w i t h i n ~ t h e ~ i m a g e ~ p a t c h ~ } \pmb { v } _ { j } . } \\ { \mathrm { ~ 0 , ~ } \mathrm { ~ o t h e r w i s e . } } \end{array} \right.\quad(1) ϕ(si,vj)=⎩ ⎨ ⎧ 1, if the center of si′s bounding box is within the image patch vj. 0, otherwise.(1)
然后,对于每个文本 token 嵌入 s i s_i si,其联合表示是其图像块特征和文本特征的和:
s i ′ = s i + v j ; 其中 ϕ ( s i , v j ) = 1 s'_i = s_i + v_j; \quad \text{其中} \quad \phi(s_i, v_j) = 1 si′=si+vj;其中ϕ(si,vj)=1
对于没有任何文本 token 的图像块 v j v_j vj,即对于所有 i i i, ϕ ( s i , v j ) = 0 \phi(s_i, v_j) = 0 ϕ(si,vj)=0,其联合表示 v j ′ v'_j vj′ 只是其自身:
v j ′ = v j v'_j = v_j vj′=vj
需要注意的是,我们没有为包含文本 token 的图像块设计专门的联合表示,因为这些图像块的特征已经与文本嵌入融合。然后, { s i ′ } \{s'_i\} {si′} 和 { v j ′ } \{v'_j\} {vj′} 被输入到 VTL Transformer 编码器中。这些联合表示通过显式地利用视觉、文本和布局的空间相关性,在模型的输入阶段极大地增强了它们之间的互动。
为了进一步统一布局和文本表示,受最近生成目标检测进展的启发 [4,49],我们将布局模态(即连续的文本边界框坐标)离散化为布局 tokens。假设我们有一个边界框 ( x i 1 , y i 1 , x i 2 , y i 2 ) ( x _ { i } ^ { 1 } , y _ { i } ^ { 1 } , x _ { i } ^ { 2 } , y _ { i } ^ { 2 } ) (xi1,yi1,xi2,yi2) 正规化到 [0, 1] 之间。得到的布局 token 将是每个坐标乘以词汇表大小,并四舍五入到最近的整数。例如,如果边界框为 ( 0.1 , 0.2 , 0.5 , 0.6 ) (0.1, 0.2, 0.5, 0.6) (0.1,0.2,0.5,0.6),而布局词汇表大小为 500,则布局 tokens 为 ⟨ 50 , 100 , 250 , 300 ⟩ \langle 50, 100, 250, 300 \rangle ⟨50,100,250,300⟩。布局 tokens 可以方便地插入到文本上下文中,并优雅地用于布局生成任务(例如,位置检测)。更多细节将在第 4 节中讨论。
位置偏差
我们遵循 TILT [36] 的方法,将 2D 文本 token 的位置编码为 2D 相对注意力偏差,类似于 T5 中使用的相对注意力偏差。然而,与 T5、TILT 或先前文档 AI 工作中的 Transformer 模型 [16,36] 不同,我们在 VTL Transformer 编码器中不使用 1D 位置嵌入,因为联合嵌入和 2D 位置偏差已经包含了输入文档的布局结构。
3.2 视觉-文本-布局解码器
如前一节所述,VTL 编码器能够紧凑且联合地编码视觉、文本及其布局。为了执行各种文档生成任务(将在第 4 节讨论),VTL 解码器被设计为联合生成所有的视觉、文本和布局模态。
VTL 解码器由文本-布局解码器和视觉解码器组成,如图 1(中)所示。文本-布局解码器是一个单向的 Transformer 解码器,用于以序列到序列的方式生成文本和布局 tokens。对于视觉解码器,我们采用 MAE [14] 的解码器,并直接生成图像像素,同时结合文本和布局信息。图像解码过程的详细讨论将在第 4.1 节的“文本和布局的掩蔽图像重建”部分展开。文本-布局解码器和视觉解码器都会交叉注意到 VTL 编码器。
模型配置等信息将在第 5.1 节中提供。
4. 统一生成式预训练
为了在不同的训练目标和数据集之间实现统一,我们创建了一个带有任务提示的通用生成任务格式。我们在大规模文档上对 UDOP 进行了预训练,涵盖了有标签和无标签的文档。表 1 总结了任务提示和目标,分别列出了所有自监督和监督任务,上部和下部块分别对应自监督和监督任务。
4.1 自监督预训练任务
我们提出了多种创新的自监督学习目标,用于无标签文档的训练。无标签文档包含 OCR 文本输入以及 token 级别的边界框和文档图像。在本小节的其余部分,我们将使用以下输入文本作为示例:
“Ship Date to Retail: Week of March 14, 1994”
(1) 联合文本-布局重建
该任务要求模型重建缺失的文本并将其定位在文档图像中。具体来说,我们会掩蔽一部分文本 tokens,并要求模型重建这些 tokens 及其边界框(即布局 tokens)。例如,假设掩蔽了“Ship Date”和“of”,则输入序列和目标序列如下所示:

这里 <text_layout_0> 和 <text_layout_1> 表示文本-布局哨兵 token,<100><350><118><372> 和 <100><370><118><382> 分别表示“Date to”和“of”的布局 token。我们使用与掩蔽语言建模(MLM)[9] 相似的掩蔽比例 15%,因为该任务可以被解释为掩蔽文本-布局建模。
(2) 布局建模 要求模型在给定文档图像和上下文文本的情况下,预测(组)文本 token 的位置。例如,要预测“Ship Date”和“of”的位置,输入序列和目标序列如下所示:
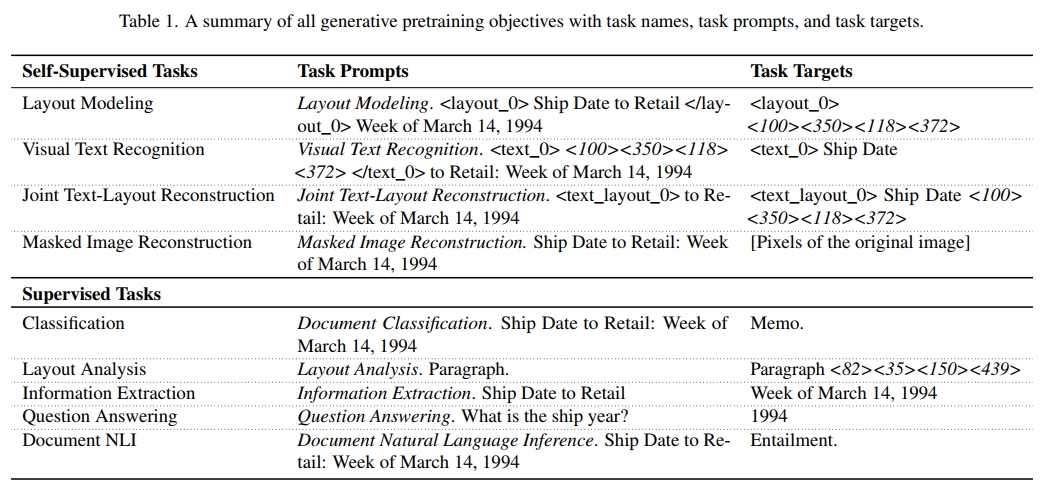

请注意,这个预训练任务与之前的“联合文本-布局重建”任务有不同的哨兵 token,使用的是 <layout_sent_0>,因为生成的内容不同(布局与文本+布局)。我们使用较大的掩蔽比例 75%,因为小的掩蔽比例会导致任务变得过于简单。
(3) 视觉文本识别在给定图像位置时识别文本。例如,要识别位于 <100><350><118><372> 和 <100><370><118><382> 处的文本 token,输入和目标序列如下所示:

请注意,这个预训练任务也有不同的哨兵 token,使用的是 <text_0>。我们使用 50% 的掩蔽比例,以区分它与“联合文本-布局重建”任务,并将哨兵 token(例如 <text_0>)和布局 token(例如 <0><10><2><20>)的布局(边界框)设置为 (0,0,0,0)。这个目标有助于模型通过理解视觉-文本对应关系来学习联合视觉-文本嵌入。
(4) 带有文本和布局的掩蔽图像重建旨在重建包含文本和布局的图像,如图 3 所示。我们采用 MAE 目标 [14] 进行视觉自监督学习。最初,MAE 掩蔽图像块的一部分,并将未掩蔽的图像块输入到视觉编码器中。然后,它将编码器的输出传递给视觉解码器,以重建掩蔽的图像块。MAE 使用均方误差,并仅对掩蔽的图像块应用损失。为了将 MAE 解码过程定制化以适应文档图像生成和我们的任务统一框架,我们做了以下修改:
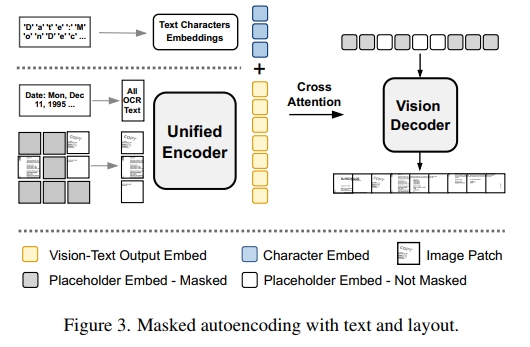
(4.a) 字符嵌入的跨注意力:在文档中,文本内容主要由字母字符、数字和标点符号组成。文本 token 的字符级组成对于视觉生成应该是有帮助的。我们在视觉解码器中添加了跨注意力机制,使其能够同时关注文本 token 编码器的特征和 token 中字符的嵌入(如图 3 左上所示)。这些字符嵌入是可训练的参数,并未通过编码器进行编码。通过这种跨注意力机制,虽然仅增加了线性计算复杂度,但显著提高了图像生成的质量。
(4.b) 图像解码:接下来,我们描述 MAE 解码过程。对于 UDOP,我们不能直接将统一编码器的输出传递给视觉解码器,因为联合视觉-文本嵌入仅包含未掩蔽的图像块(如 3.1 节所述),并且图像块与文本 token 已经融合。因此,我们提出让视觉解码器接受一系列可训练的占位符嵌入。占位符序列的长度和顺序与目标图像的图像块相同。我们使用两种类型的占位符嵌入来指示图像块是否在输入文档图像中被掩蔽。视觉解码器通过跨注意力机制,既关注编码器的视觉-文本输出,又关注字符嵌入。上述过程如图 3 所示。我们将在 6.1 节展示高质量生成的可视化效果。
4.2. 有监督预训练任务
自监督任务利用大规模无标签数据学习鲁棒的表示。而有监督任务则使用标签数据进行细粒度的模型监督。我们在预训练中包含以下有监督任务:
- 文档分类:该任务是预测文档类型。任务提示为“Document Classification on (Dataset Name)”,例如“Document Classification on RVLCDIP”,然后是文本 token。目标是文档类别。我们使用 RVL-CDIP [13],该数据集包含 16 种文档类别。
- 布局分析:该任务是预测文档中某个实体的位置,如标题、段落等。任务提示为“Layout Analysis on (Dataset Name)”,然后是实体名称。目标是覆盖给定实体的所有边界框。我们使用 PubLayNet [57] 数据集。
- 信息抽取:该任务是预测文本查询的实体类型和位置(例如,摘要段落)。任务提示为“Information Extraction on (Dataset Name) (Text Query)”。目标是查询每个 token 的实体标签和边界框。我们使用 DocBank [28]、Kleister Charity (KLC) [41]、PWC [19] 和 DeepForm [43] 数据集。
- 问答:该任务是回答与文档图像相关的给定问题。任务提示为“Question Answering on (Dataset Name)”,然后是问题和所有文档 token。目标是答案。我们使用 WebSRC [3]、VisualMRC [45]、DocVQA [33]、InfographicsVQA [32] 和 WTQ (WikiTableQuestions) [35] 数据集。
- 文档自然语言推理(NLI):该任务预测文档中两句之间的蕴涵关系。任务提示为“Document Natural Language Inference on (Dataset Name)”,然后是句子对。目标是“Entailment”或“Not Entailment”。我们使用 TabFact [5] 数据集进行此任务。
5. 实验设置
5.1. 模型预训练
模型配置:在 UDOP 中,统一编码器和文本-布局解码器遵循 T5-large [39] 的编码器-解码器架构。视觉解码器是 MAE-large 解码器 [14]。总体来说,UDOP 具有 794M 可训练参数。对于分词器,我们使用来自 Hugging Face Transformers [51] 的 T5 分词器和嵌入。此外,我们扩展了词汇表以容纳特殊 token(例如新的哨兵和布局 token)。
数据:对于自监督学习,我们使用 IIT-CDIP 测试集 1.0 [25],这是一个在之前的工作中广泛使用的大规模文档集合 [16, 53, 55]。该数据集包含 1100 万个扫描文档,包含文本和通过 OCR 提取的 token 级边界框。监督数据集如 4.2 节所述。
课程学习:在我们的最终设置中,我们使用较大的图像分辨率 1024,因为较低的分辨率会导致文档文本无法识别,既不适合检测也不适合生成。这会导致图像补丁序列长度为 (1024=16)² = 4096,比小图像分辨率(例如 224)需要更长的训练时间。因此,我们采用课程学习,从相对较小的分辨率开始,逐步扩展到 1024 分辨率。实际上,我们在预训练过程中使用了 3 种分辨率:224 → 512 → 1024。我们在附录 E 中展示了这三阶段的性能。
训练:我们使用 Adam [23] 优化器,学习率为 5e-5,1000 步预热,批大小为 512,权重衰减为 1e-2, β 1 = 0.9 , β 2 = 0.98 β_1 = 0.9,β_2 = 0.98 β1=0.9,β2=0.98。对于每个课程学习阶段,我们训练 1 个 epoch。
5.2. 下游评估
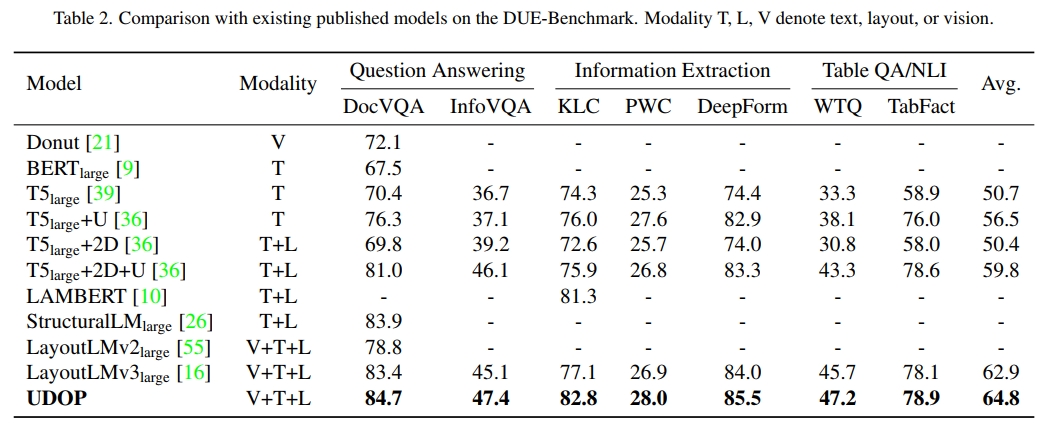
我们在 FUNSD [18]、CORD [34]、RVLCDIP [13] 和 DocVQA [33] 数据集上报告了结果,并在下文中描述了各自的设置。我们还在 DUE-Benchmark [2] 的 7 个数据集上报告了结果,见表 2。微调训练细节见附录 D.6,性能方差见表 9 和表 10。请注意,对于所有下游任务,我们使用数据集中提供的原始 OCR 注释。
FUNSD(Form Understanding in Noisy Scanned Documents)[18]:该数据集包含 149 个训练样本和 50 个测试样本。我们评估实体识别任务:预测文本 token 的实体类别,“question”(问题)、“answer”(答案)、“header”(标题)或 “other”(其他)。任务格式为,假设标题为 “The Title”,其实体为 “[I-Header]”,则编码器输入为 “The Title”,生成目标为 “The Title [I-Header]”。评估指标为 F1 分数。
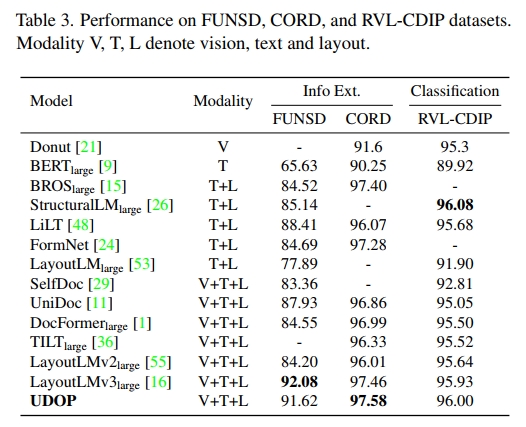
CORD (Consolidated Receipt Dataset for Post-OCR Parsing) [34] 是一个重要的信息提取数据集,包含 30 个标签,分为 4 类,例如 “total”(总计)或 “subtotal”(小计)。该数据集包含 1,000 个收据样本,训练集、验证集和测试集分别包含 800、100 和 100 个样本。评估指标为 F1,任务格式与 FUNSD 相同。
RVL-CDIP 是我们之前讨论过的文档分类数据集。该数据集包含 320k/40k/40k 的训练/验证/测试图像。评估指标是分类准确率。
DUE-Benchmark 包含 7 个数据集和 3 个领域,包括文档问答(DocVQA [33]、InfographicsVQA [32])、关键信息提取(KLC [41]、PWC [19]、DeepForm [43])和表格 QA/NLI(WTQ [35]、TabFact [5])。任务提示格式可以在 4.2 节找到,数据集的详细信息可见附录。
结果
预训练的模型在每个评估数据集上进行了微调。如表 2 所示,我们的模型 UDOP 在 DUE-Benchmark 的 7 个任务中取得了 SOTA 性能,并在 2022 年 11 月 11 日的排行榜中位列第一。它还在 CORD 和表 3 中设定了 SOTA 性能。值得注意的是,UDOP 是一个开放词汇生成模型,使用一个单一模型来处理所有任务。相比之下,大多数基线方法为每个数据集使用特定任务的网络,并且是基于分类的模型。然而,UDOP 仍然比这些模型表现更好。
课程学习(见附录表 8)表明,随着图像分辨率增大,UDOP 的性能稳步提升。例如,UDOP 在 DUE-Benchmark 上的平均表现随着分辨率从 224、512 到 1024 的变化,分别为 63.9、64.3 和 65.1。值得注意的是,我们的模型在 224 分辨率下的表现已经超过了之前的最佳模型(例如,DUE-Benchmark 上的平均为 62.9)。然后,我们仅使用自监督目标(224 分辨率)训练 UDOP。它的表现(见表 4)也超过了基线,显示了统一表示、TVL transformer 和提出的自监督目标的有效性。
6. 分析
6.1. 可视化分析
掩码图像重建
图6展示了掩码图像重建的结果。即使在较高的掩码比例下,模型仍然能够从文本和布局信号中高质量地重建文档图像:重建的内容清晰、一致,并且几乎与原始图像完全相同(所有演示均在未见过的文档上进行)。

文档生成与编辑
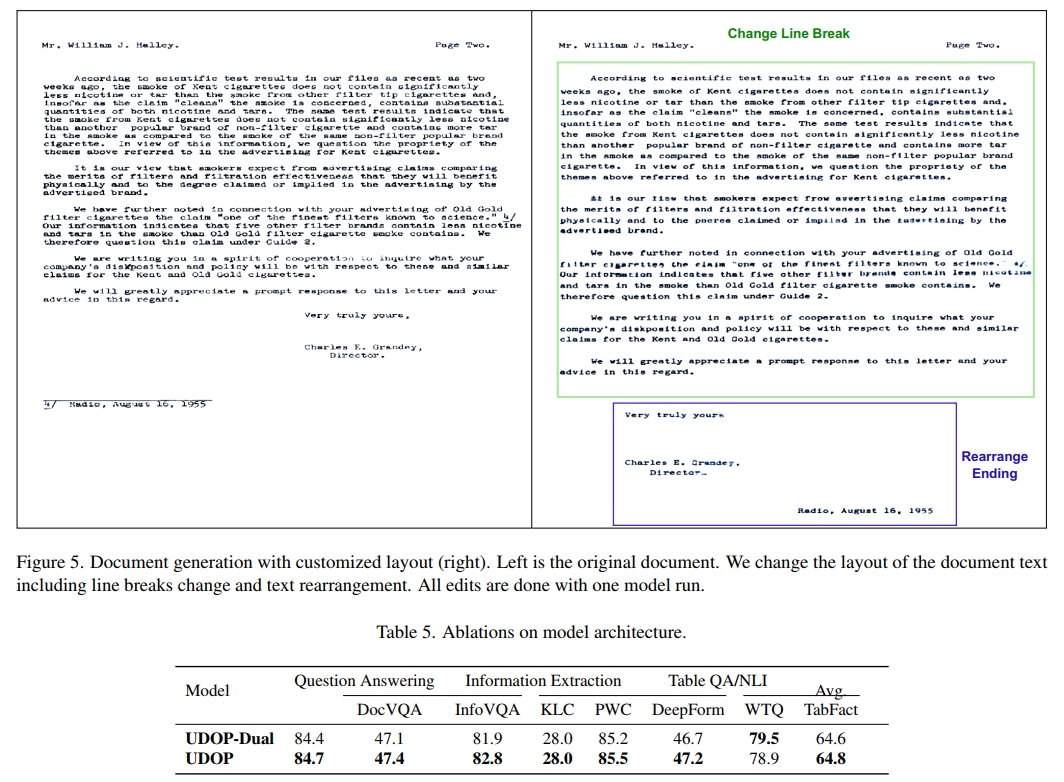
在文档AI领域,UDOP首次实现了可控的高质量文档生成和编辑。如图4所示,可以通过自定义内容编辑和添加文档图像内容。生成的内容具有高分辨率,并且在字体、大小、样式和方向上与上下文保持一致(例如,图4中的垂直数字)。更多生成示例可见附录B。这是通过在文档图像中掩盖待编辑的区域,在文本输入中指定自定义内容,并通过布局嵌入来定义它们的位置来实现的。这一创新功能可以为未来的研究生成增强文档数据。
布局自定义
UDOP能够执行可控的高质量文档布局编辑。我们在图5中展示了示例,其中我们的模型可以通过从头开始重新生成文档来编辑文档的布局。这是通过仅保留少数图像补丁作为提示,改变内容的边界框,然后用新布局重新生成文档图像来完成的。
6.2. 消融分析
预训练目标
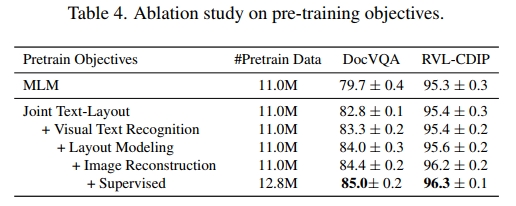
表4展示了在DocVQA和RVL-CDIP验证集上的预训练目标的消融研究。我们首先开发了一个MLM(掩码语言建模)基线,即一个仅在BERT的MLM [9]上预训练的UDOP模型,掩盖15%的输入token。通过布局/文本自监督目标(“布局建模”,“视觉文本数据”以及“联合文本-布局重建”)进行预训练的UDOP模型(224图像分辨率)优于仅使用掩码语言建模(MLM)训练的模型,验证了这些目标的有效性。表4还展示了每个预训练任务的相对有效性。布局建模比联合文本-布局建模有所改进;掩码图像重建比基于文本的预训练任务有所提升。加入视觉自监督学习(掩码图像重建)和监督学习进一步提高了性能。

模态特定模型变种
在多模态学习领域,一个常见的模型架构是双塔模型,其中视觉和文本分别由两个模态特定的编码器进行编码[38,56]。因此,我们探索了UDOP的一种变种,即不使用一个统一的编码器,而是分别使用一个文本编码器(用于编码文本和布局token)和一个视觉编码器。两个编码器都使用位置偏差来表示布局信息,遵循之前的研究工作。我们将这个变种命名为UDOP-Dual。对于UDOP-Dual,文本-布局编码器-解码器遵循T5-large架构,视觉编码器-解码器与MAE-large相同。该模型总共有1098M可训练参数。
如表5和表11所示,在大多数数据集中,使用一个统一编码器的效果优于分别使用编码器。唯一的例外是WTQ和RVL-CDIP,在这两个数据集上,UDOP-Dual取得了SOTA(最先进)性能。
额外的监督训练阶段
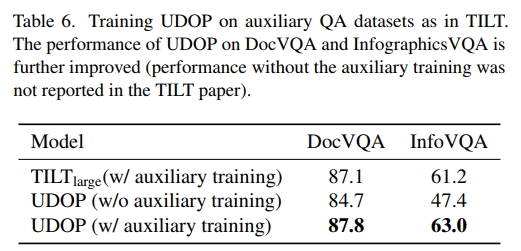
TILT [36]在DocVQA进行微调之前,在广泛的问答数据集(如阅读理解数据集SQuAD [40])上执行额外训练。这使得TILT模型在DocVQA和InfographicsVQA上的性能得到了显著提高。为了公平比较,我们也在相同的数据集上对UDOP进行了微调,然后在DocVQA或InfographicsVQA上进行测试。如表6所示,通过这种辅助训练,UDOP进一步提高了性能,并超越了TILT。
6.3. 视觉模态的有效性
在文档AI领域,视觉模态(即文档图像)的有效性尚不明确。我们通过从模型输入中移除视觉嵌入来探索这一点,结果如表7所示。实验结果表明,在视觉信息丰富的任务中(例如InfographicsVQA),视觉模态的作用更加突出,而在以文本为主的数据任务中(例如DocVQA),视觉模态的作用相对较小。

7. 结论
在本研究中,我们提出了UDOP,一个面向文档AI的基础模型。UDOP通过利用文档中视觉、文本和布局模态之间的强空间关联,统一了这些模态,采用了布局驱动的视觉-文本表示和视觉-文本-布局变换器。它还通过生成框架统一了所有自监督和监督的文档任务。UDOP在8个任务上达到了最先进的性能,目前在文档理解基准测试的排行榜上排名第一。首次在文档AI领域,UDOP实现了可定制的真实文档生成和编辑。我们在附录中讨论了该工作的局限性和社会影响。
论文名称:
Unifying Vision, Text, and Layout for Universal Document Processing
论文地址:
https://openaccess.thecvf.com/content/CVPR2023/papers/Tang_Unifying_Vision_Text_and_Layout_for_Universal_Document_Processing_CVPR_2023_paper.pdf