目录
摘要
Abstract
BLIP-2
模型框架
预训练策略
模型优势
应用场景
实验
代码
总结
摘要
BLIP-2 是一种基于冻结的图像编码器和大型语言模型的高效视觉语言预训练模型,由 Salesforce 研究团队提出。它在 BLIP 的基础上进一步优化,通过轻量级的查询 Transformer桥接图像和文本模态,解决了先前模型在参数效率和多模态对齐方面的不足。BLIP-2 在少样本学习和零样本生成任务中表现出色,例如:在 zero-shot VQAv2 任务上比 Flamingo 提升了 8.7% 的性能,同时可训练参数减少了 54 倍。其高效的计算性能和轻量级设计使其在图像描述生成、视觉问答和图像到文本检索等任务上展现出强大的能力,为多模态人工智能的发展提供了新的方向。
Abstract
BLIP-2 is an efficient vision-language pre-training model based on frozen image encoders and large language models, proposed by the Salesforce research team. Building on the foundation of BLIP, it further optimizes the model by using a lightweight Query Transformer to bridge the image and text modalities, addressing the limitations of previous models in terms of parameter efficiency and multimodal alignment. BLIP-2 performs exceptionally well in few-shot learning and zero-shot generation tasks. For example, it achieves an 8.7% improvement in performance on the zero-shot VQAv2 task compared to Flamingo, while reducing the number of trainable parameters by 54 times. Its high computational efficiency and lightweight design enable it to demonstrate strong capabilities in tasks such as image captioning, visual question answering, and image-to-text retrieval, providing a new direction for the development of multimodal artificial intelligence.
BLIP-2
项目地址:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
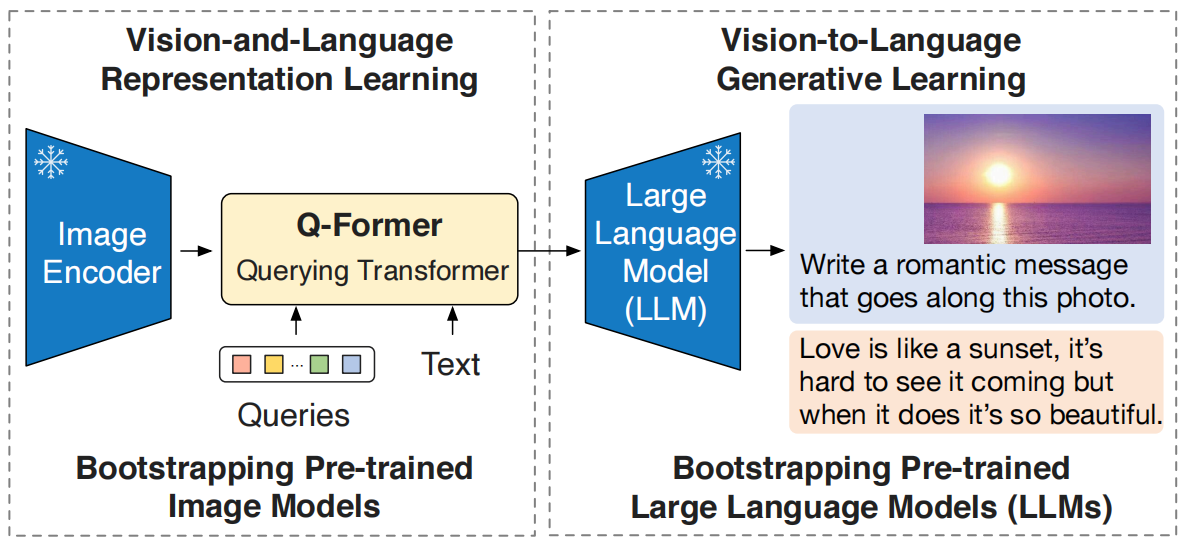
模型框架
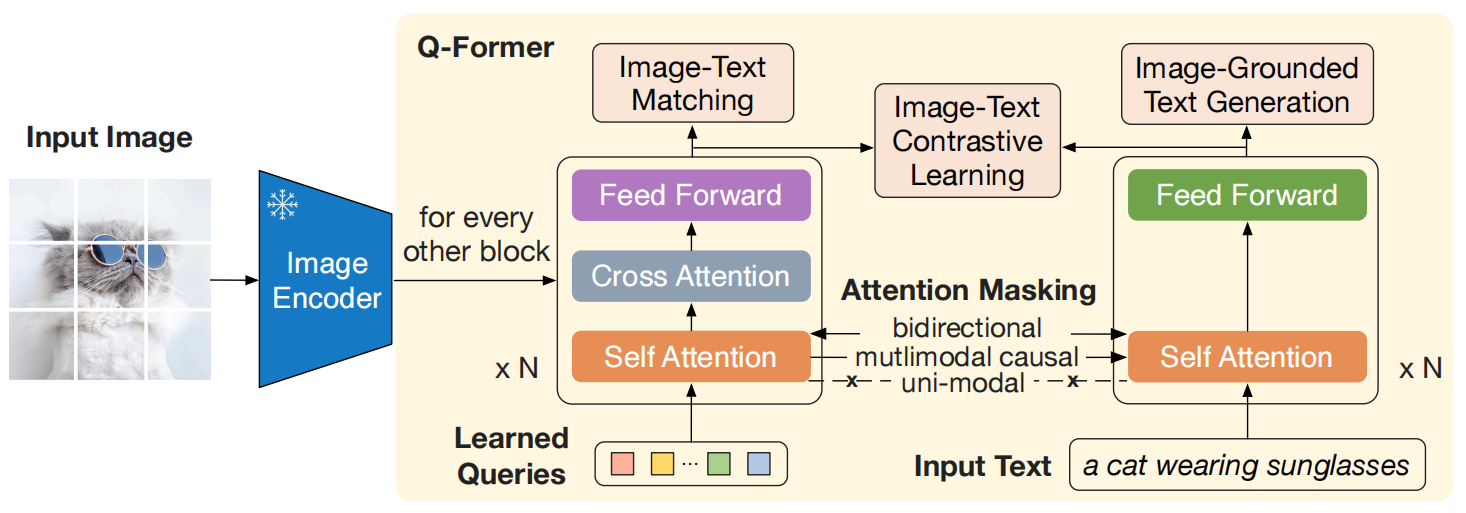
BLIP-2的核心架构包括三个主要部分:
冻结的图像编码器:通常使用类似CLIP的视觉模型(如ViT),其权重在训练过程中保持不变。
轻量级的查询Transformer:这是BLIP-2的核心模块,用于桥接图像编码器和语言模型之间的模态差距。Q-Former包含两个子模块:
- 图像Transformer:用于从冻结的图像编码器中提取视觉特征;
- 文本Transformer:作为文本编码器和解码器,用于生成文本。
冻结的大型语言模型:如Flan-T5或LLaMA,其权重在训练过程中也保持不变。
预训练策略
BLIP-2采用两阶段预训练策略:
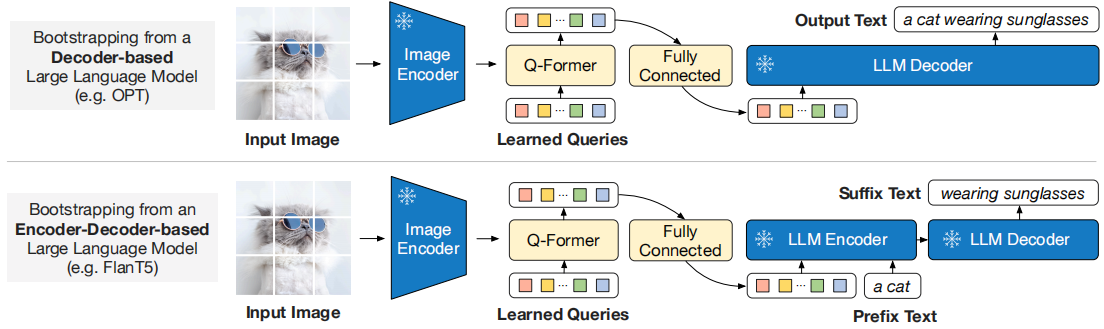
第一阶段:视觉语言表示学习:
- 使用冻结的图像编码器,通过图像-文本对比学习(ITC)、图像-文本匹配(ITM)和图像引导的文本生成(ITG)任务,学习视觉与语言的对齐;
- ITC任务通过对比图像和文本嵌入来对齐模态;
- ITM任务通过二分类任务判断图像和文本是否匹配。 ITG任务通过生成文本任务来学习图像特征。
第二阶段:视觉到语言的生成学习:
- 将Q-Former提取的视觉特征传递给冻结的LLM,通过语言建模损失进行预训练;
- 对于解码器型LLM,使用语言建模损失进行训练;
- 对于编码器-解码器型LLM,使用前缀语言建模损失进行训练。
模型优势
高效利用预训练模型:通过冻结图像编码器和LLM,显著减少了可训练参数的数量。例如,BLIP-2在zero-shot VQAv2任务上比Flamingo模型提升了8.7%的性能,但可训练参数减少了54倍。
强大的少样本学习能力:即使在训练参数较少的情况下,BLIP-2也能在多种视觉语言任务上达到最先进的性能。
计算效率高:由于使用了冻结的模型和轻量级的Q-Former,BLIP-2的计算效率更高,更易于部署和使用。
零样本图像到文本生成能力:BLIP-2能够根据自然语言指令生成与图像相关的文本。
应用场景
图像描述生成:能够根据图像生成准确的描述文本;
视觉问答:能够根据图像和问题生成答案;
图像到文本检索:能够根据图像检索相关的文本内容。
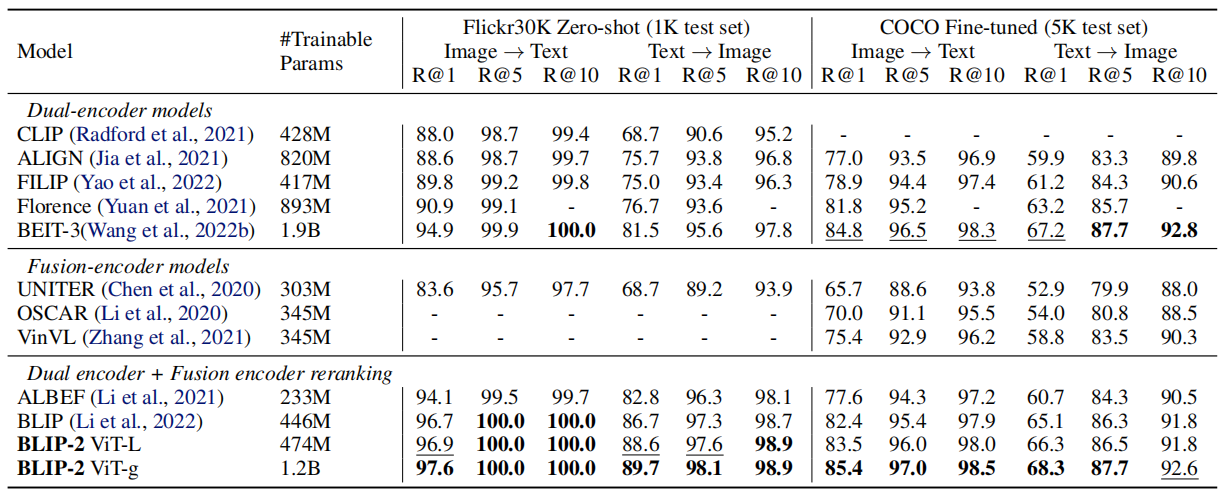
实验
零镜头能力:
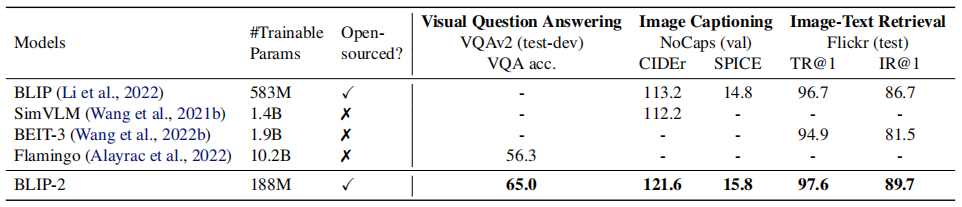
零镜头视觉问答:
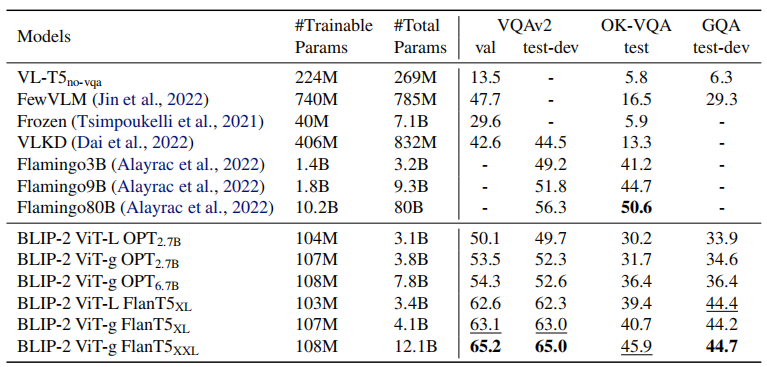
图像文本检索:
代码
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
import torch
import pandas as pd
from lavis.models import load_model_and_preprocess
from transformers import Blip2Processor, Blip2ForConditionalGeneration
from PIL import Image
import requestsdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# loads BLIP caption base model, with finetuned checkpoints on MSCOCO captioning dataset.
# this also loads the associated image processors
processor = Blip2Processor.from_pretrained("blip2-opt-2.7b/")
model = Blip2ForConditionalGeneration.from_pretrained("blip2-opt-2.7b/", torch_dtype=torch.float16
)
model.to(device)
# preprocess the image
# vis_processors stores image transforms for "train" and "eval" (validation / testing / inference)
raw_image = Image.open("https://storage.googleapis.com/sfr-vision-language-research/LAVIS/assets/merlion.png").convert("RGB")image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
# generate caption
res = model.generate({"image": image})print(res)
# ['a large fountain spewing water into the air']输入图像1:

输入图像2:

输出:

1、a person is holding a cup in their hand.
2、a man is cleaning a car with a pressure gun.
总结
BLIP-2 是一种创新的视觉语言预训练模型,通过结合冻结的图像编码器和大型语言模型,并引入轻量级查询Transformer桥接视觉与文本模态,有效解决了先前模型在参数效率和多模态对齐方面的不足。在少样本学习和零样本生成任务中,BLIP-2 表现卓越,例如在 zero-shot VQAv2 任务上性能比 Flamingo 提升了 8.7%,同时可训练参数减少了 54 倍。其高效的设计和强大的性能使其在图像描述生成、视觉问答和图像到文本检索等任务中展现出巨大优势,为多模态人工智能的发展提供了新的高效路径。
![[Protobuf]常见数据类型以及使用注意事项](https://i-blog.csdnimg.cn/direct/7b9edaddb85c4cf9a94c5fdf1f15a5cf.png#pic_center)