📖标题:TAT-R1: Terminology-Aware Translation with Reinforcement Learning and Word Alignment
🌐来源:arXiv, 2505.21172
🌟摘要
最近,像DeepSeek-R1这样的深度推理大型语言模型(LLM)在数学和编码等任务中取得了重大进展。受此启发,一些研究采用了强化学习(RL)来增强模型的深度推理能力,提高机器翻译(MT)的质量。然而,术语翻译是机器翻译中的一项重要任务,在深度推理法学中尚未得到探索。在本文中,我们提出了TATR1,这是一个通过强化学习和单词对齐训练的术语感知翻译模型。具体来说,我们首先使用单词对齐模型提取关键字翻译对。然后,我们利用提取的对齐关系仔细设计了三种基于规则的对齐奖励。有了这些对齐奖励,RL训练的翻译模型可以学会专注于关键信息的准确翻译,包括源文本中的术语。实验结果证明了TAT-R1的有效性。与基线模型相比,我们的模型显著提高了术语翻译的准确性,同时在一般翻译任务上保持了可比的性能。此外,我们对机器翻译的DeepSeek-R1类训练范式进行了详细的消融研究,并揭示了几个关键发现。代码、数据和模型将公开发布。
🛎️文章简介
🔸研究问题:这如何提高大语言模型(LLM)在机器翻译中对特定术语的翻译准确性?
🔸主要贡献:论文提出了TAT-R1,一个首个使用强化学习和词对齐奖励进行术语感知翻译的模型。
📝重点思路
🔸通过词对齐技术设计针对术语翻译任务的有效强化学习奖励信号。
🔸利用三种不同的词对齐奖励(答案对齐词奖励、答案对齐顺序奖励和思考对齐词奖励)来优化翻译模型。
🔸使用群体相对策略优化(GRPO)算法训练模型,同时结合格式奖励和COMET奖励来确保翻译的流畅性和语义准确性。
🔎分析总结
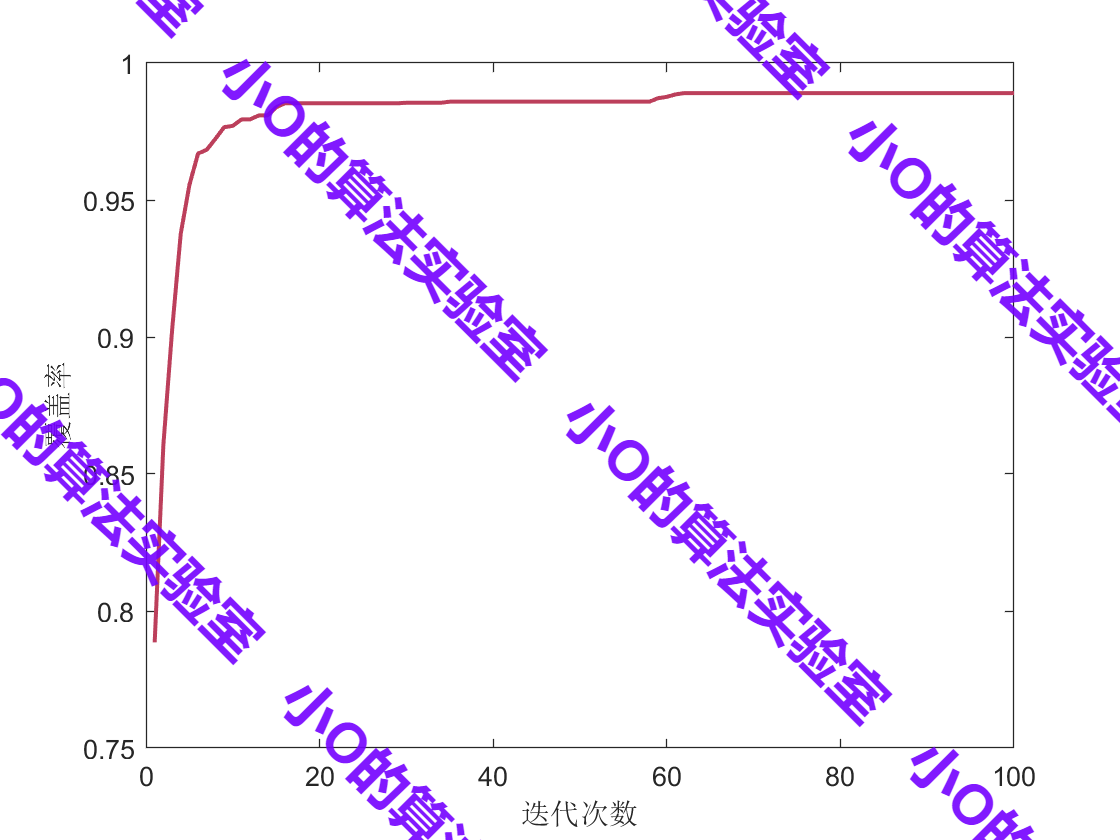
🔸实验结果表明,TAT-R1在术语翻译任务上显著提高了翻译准确性,相较于基线模型表现更佳,同时在一般翻译任务上保持了可比的性能。
🔸通过与其他奖励机制(如BLEU)对比,文章指出使用词对齐奖励后,模型在翻译的流畅度和语义质量方面有显著提升。
🔸进一步的消融实验表明,逐步引入的词对齐奖励能够有效提升模型性能,验证了这些奖励机制的有效性。
💡个人观点
论文首次将强化学习与词对齐技术结合应用于术语翻译,通过设计多种基于词对齐的奖励机制,显著提升了术语翻译的准确性和质量。
🧩附录