内容提要
- 预处理
- 库文件
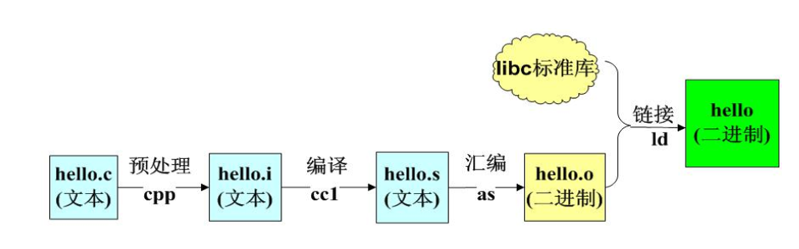
预处理
- 预处理
- 编译
- 汇编
- 链接
什么是预处理
预处理就是在源文件(.c文件)编译之前,所进行的一部分预备操作,这部分操作是由预处理器(预处理程序)自动完成。当源文件在编译时,编译器会自动调用预处理程序来完成预处理执行的操作,预处理执行解析完成才能进入下一步的编译过程。
查看预处理结果:
gcc 源文件 -E -o 程序名
预处理
宏定义
不带参数的定义
-
语法:
#define 宏名称 宏值(替换文本) -
预处理机制:此时的预处理只做数据的替换,不做类型检查
-
注意:宏定义不会占用内存空间,因为在编译前已经将宏名称替换成了宏值
-
宏展开:在预处理阶段将宏名称替换成宏值的过程称之为“宏展开”。
-
案例:
#include <stdio.h>#define PI 3.1415926int main() {float l,s,r;printf("请输入圆的半径:\n");scanf("%f",&r);// 计算周长l = 2.0 * PI * r;// 计算面积s = PI * r * r;printf("l=%10.4f\ns=%10.4f\n",l,s);return 0; }
带参数的定义
-
语法:
#define 宏名(参数列表) 替换表达式 -
面试题:
#define multi(a,b) (a)*(b) #define multi(a,b) a * b -
案例:
#include <stdio.h>// 带参数的宏定义,宏名一般小写 #define multi_1(a,b) (a) * (b) #define multi_2(a,b) a * bint main() {int result1 = multi(7+2,3); // 27printf("%d\n", result1);int result1 = multi(7+2,3); // 13printf("%d\n", result2);return 0; }
宏定义的作用域
-
#define命令出现在程序中函数的外面,宏名的有效范围为定义命令之后到本源文件结束。 -
可以用
#undef命令终止宏定义的作用域#include <stdio.h>#define PI 3.14 // PI的作用域3~12行 #define DAY 29void func1(){float r = 4;float s = PI * r * r; // 预处理后:float s = 3.14 * r * r;int day = DAY; // 预处理后:int day = 29; }#undef PI // 终止了PI的范围#define PI 3.1415926void func2() {float r = 4;float s = PI * r * r; // 预处理后:float s = 3.1415926 * r *rint day = DAY; }int main() {return 0; }
宏定义中引用已定义的宏名
-
案例:
#include <stdio.h>#define R 3.0 // 半径 #define PI 3.14 #define L 2 * PI * R // 在宏定义中引用已定义的宏名 #define S PI * R * R // 面积#define P_WIDTH = 800 #define P_HEIGHT = 480 #define SIZE = P_WIDTH * P_HEIGHTint main() {printf("L=%f\nS=%f\n",L,S);return 0; }
预处理结果:

条件编译
定义:根据设定的条件选择编译的语句代码。
预处理机制:将满足条件的语句进行保留,将不满足条件的语句进行删除,交给下一步编译。
语法:
-
语法1:
根据找到标记,来决定是否参与编译(标记存在为真,不存在为假)
#ifdef 标记 ...语句代码1 #else ...语句代码2 #endif -
语法2:
根据是否找到标记,来决定是否参与编译(标记不存在为真,存在为假)
#ifndef 标记 ...语句代码1 #else ...语句代码2 #endif -
语法3:
根据表达式的结果,来决定是否参与编译(表达式成立为真,不成立为假)
-------单分支 #if 表达式 ...语句代码1 #endif -------双分支 #if 表达式 ...语句代码1 #else ...语句代码2 #endif-------多分支 #if 表达式 ...语句代码1 #elif 表达式n ...语句代码n #else ...语句代码n+1 #endif案例:
#include <stdio.h>// 定义一个条件编译的标记
#define LETTER 0 // 默认是大写int main()
{// 测试用的字母字符串char str[20] = "C Language";char c;int i = 0;// 遍历获取每一个字符while((c = str[i]) != '\0'){
#if LETTERif(c >= 'a' && c <= 'z'){c -= 32;}
#elseif(c >= 'A' && c <= 'z'){c += 32;}
#endifprintf("%c", c);i++;}printf("\n");return 0;
}
文件包含
概念
所谓“文件包含”处理是指一个源文件可以将另一个源文件的全部内容包含进来。这是用于多文件开发。通常,一个常规的C语言程序包含多个源文件(*.c)当某些公共资源需要在各个源文件中使用时,为了避免多次编写相同的代码,我们一般会进行代码的抽取(*.h),然后在各个源码文件中直接包含即可。
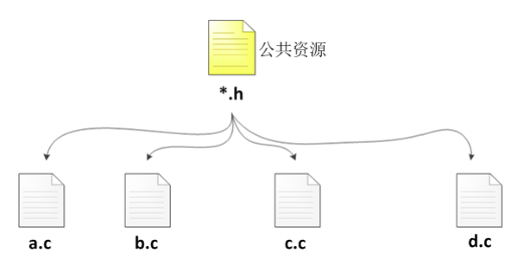
注意:*.h中的函数声明必须要在*.c中对应的函数定义。(函数一旦声明,就一定要定义)
头文件(.h)的内容
头文件中所存放的内容就是各个源文件的彼此可见的公共资源,包括:
- 全局变量的声明
- 普通函数的声明
- 静态函数的定义
- 宏定义
- 结构体、共用体的定义
- 枚举常量列表的定义
- 其他头文件包含
示例代码:
myhead.h
extern int global; // 全局变量的声明
extern void func1(); // 普通函数的声明
static void func2() // 静态函数的声明,写在.h中,引用此文件的.c文件直接调用,写在.c文件,只能这个.c文件访问
{...
}#define max(a,b) ((a) > (b) ? (a) : (b)) // 定义
struct node // 结构体定义
{...
};union attr // 共用体定义
{...
};enum SEX // 枚举常量列表定义
{...
};#include <stdio.h> // 引入系统头文件
#include "myhead.h" // 引入自定义文件
特别说明
1.全部变量、普通函数的定义一般出现在某个源文件(*.c)中,其他源文件想要使用都需要进行声明,因此一般放在头文件中更方便
2.静态函数、宏定义、结构体、共用体、枚举的定义都只能在其他所在文件可见,因此如果多个源文件都需要的话,放到头文件时最方便的选择
预处理机制:将文件中的内容替换文件包含指令
包含方式
1.#include <xxx.h>:系统会到标准库文件目录(Linux下/usr/include)查找包含的文件,建议对于系统库访问采用这种写法。
2.#include "xxx.h":在当前工程路径下(Linux下./)查找包含的文件,如果未找到,就去标准库文件目录下查找,建议对于自定义库采用这种写法。
案例
-
myheah.h
#ifndef _MYHEAD_H #define _MYHEAD_H/*** 数组的累加和运算* @param int* int数组* @param int 数组大小*/ extern int sum(const int*, int);#endif //_MYHEAD_H -
myhead.c
#include <stdio.h> #include "myhead.h"/*** 数组的累加和运算*/ int sum(const int *arr, int len) {const int *p = arr;int sum = 0;for(; p < arr + len; p++){ sum += *p;}return sum; } -
app.c
#include <stdio.h> #include "myhead.h" int main(int argc,char *argv[]) {int arr[] = {11,12,13,14,15};int result = sum(arr, sizeof(arr)/sizeof(arr[0]));printf("数组累加和的结果是%d\n", result);return 0; } -
多条编译命令
gcc app.c myhead.c -o app
避免头文件重复包含的方法
其实就是头文件去重复。
由于头文件包含指令#include的本质是复制粘贴,并且一个头文件中可以嵌套包含其他头文件,因此很容易出现头文件被重复包含的情况。此时就需要我们进行去重,去重需要用到预处理提供的去重相关指令。
语法:
#define __xxx_H // 一般为 头文件名大写+下划线+H
#define __xxx_H
..
#endif
案例:
#ifndef MYHEAD_H
#define MYHEAD_H/*** 数组的累加和运算* @param int* int数组* @param int 数组大小*/
extern int sum(const int*, int);#endif //MYHEAD_H
库文件
什么是库文件
库文件本质上是经过编译后生成的可被计算机执行的二进制代码。但注意库文件不能独立运行,库文件需要加载到内存中才能执行。库文件大量存在于windows, linux, MacOS等软件平台上。
库文件的分类
- 静态库
- windows:xxx.lib
- linux:libxxxx.a
- 动态库(共享库)
- windows:xxx.dll
- linux:libxxxx.so.major.minor(libmy.so.1.1)
注意:不同的软件平台因编译器、链接器不同,所生成的文件是不兼容的。
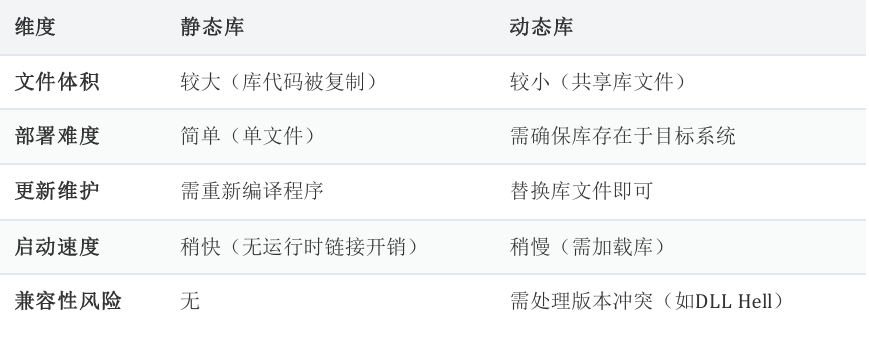
静态库与动态库的区别
1.静态库链接时,将库中所有内容包含到最终的可执行程序中。
2.动态库链接时,将库中的符号信息包含到最终可执行文件中,在程序运行是,才将动态库中符号的具体实现加载到内存中。
静态库与动态库的优缺点
1.静态库
- 优点:生成的可执行程序不再以来静态文件
- 缺点:可执行程序体积较大
2.动态库
- 优点:生成的可执行程序体积小;动态库可被多个应用程序共享
- 缺点:可执行程序运行依然依赖动态库文件
静态库与动态库对比
库文件创建
Linux系统下库文件命名规范:libxxxx.a(静态库)libxxxx.so(动态库)
静态库文件的生成
- 将需要生成库文件对应的源文件(
*.c)通过编译(不链接)生成*.o目标文件 - 用
ar命令生成的*.o打包生成libxxxx.a
库的生成:

库的使用

动态库文件的生成
- 利用源文件(
*.c)通过编译(不链接)生成位置无关*.o目标文件 - 将目标文件链接为
*.o文件
库的生成

库的使用

注意:如果在代码编译过程或者运行中链接了库文件,系统会到/lib和/usr/lib目录下查找库文件,所以建议直接将库文件放在/lib或者/usr/lib,否则系统可能无法找到库文件,造成编译错误或者运行错误

扩展内容
-
查看应用程序(例如:app)依赖的动态库

-
动态库使用方式
-
编译时链接动态库,运行时系统自动加载动态库
-
程序运行时,手动加载动态库
-
实现:
- 涉及内容
- 头文件:#include <dlfcn.h>
- 接口函数:dlopen、dlclose、dlsym
- 依赖库:-ldl
- 示例代码:
#include <stdio.h> #include <dlfcn.h> int main(int argc,char *argv[]) {// 1. 加载动态库 "/lib/libdlfun.so"// - RTLD_LAZY: 延迟绑定(使用时才解析符号,提高加载速度)// - 返回 handler 是动态库的句柄,失败时返回 NULLvoid* handler = dlopen("/lib/libdlfun.so", RTLD_LAZY); if (handler == NULL) {// 打印错误信息(dlerror() 返回最后一次 dl 相关错误的字符fprintf(stderr, "dlopen 失败: %s\n", dlerror());return -1;}// 2. 从动态库中查找符号 "sum"(函数名)// - dlsym 返回 void*,需强制转换为函数指针类型 int sum(int *arr, int size); // - 这里假设 "sum" 是一个接受两个int*,int参数、返回 int 的函数int (*paddr)(int*, int) = (int (*)(int*, int))dlsym(handler, "sum");if (paddr == NULL){fprintf(stderr, "dlsym 失败: %s\n", dlerror());dlclose(handler); // 关闭动态库(释放资源)return -1;}// 3. 调用动态库中的函数 "sum",计算{11,12,13,14,15}的累加和int arr[5] = {11,12,13,14,15};printf("sum=%d\n", paddr(arr, sizeof(arr)/sizeof(arr[0])));// 4. 关闭动态库(释放内存和资源)dlclose(handler);return 0; }- 编译命令:
gcc demo06.c -ldl - 涉及内容
-