ES作用
在海量数据中,执行搜索功能,使用mysql,效率过低,
如果关键字输入不准确,一样可以搜索到想要的数据
讲搜索关键字,以红色字体展示
ES介绍
ES是基于java语言并且基于Lucene编写的搜索引擎框架,提供了分布式全文搜索的功能
Lucene本身是一个搜索引擎能力
全文检索:能拼装成一个词的,则拼装,不能拼装那么就单个
8666手机壳
8
666
手机壳
根据关键词去分词库搜索,找到匹配的内容(倒排索引)
数据假如是死数据Solr更好,假如数据实时改变,则使用Solr查询速度
Solr搭建集群,需要依赖Zookeeper来帮助管理,ES本身支持集群搭建,不需要第三方介入
ES对云计算和大数据支持的特别好。
ES倒排索引
将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中
当用户去查询数据时候,会将用户的查询关键字进行分词,
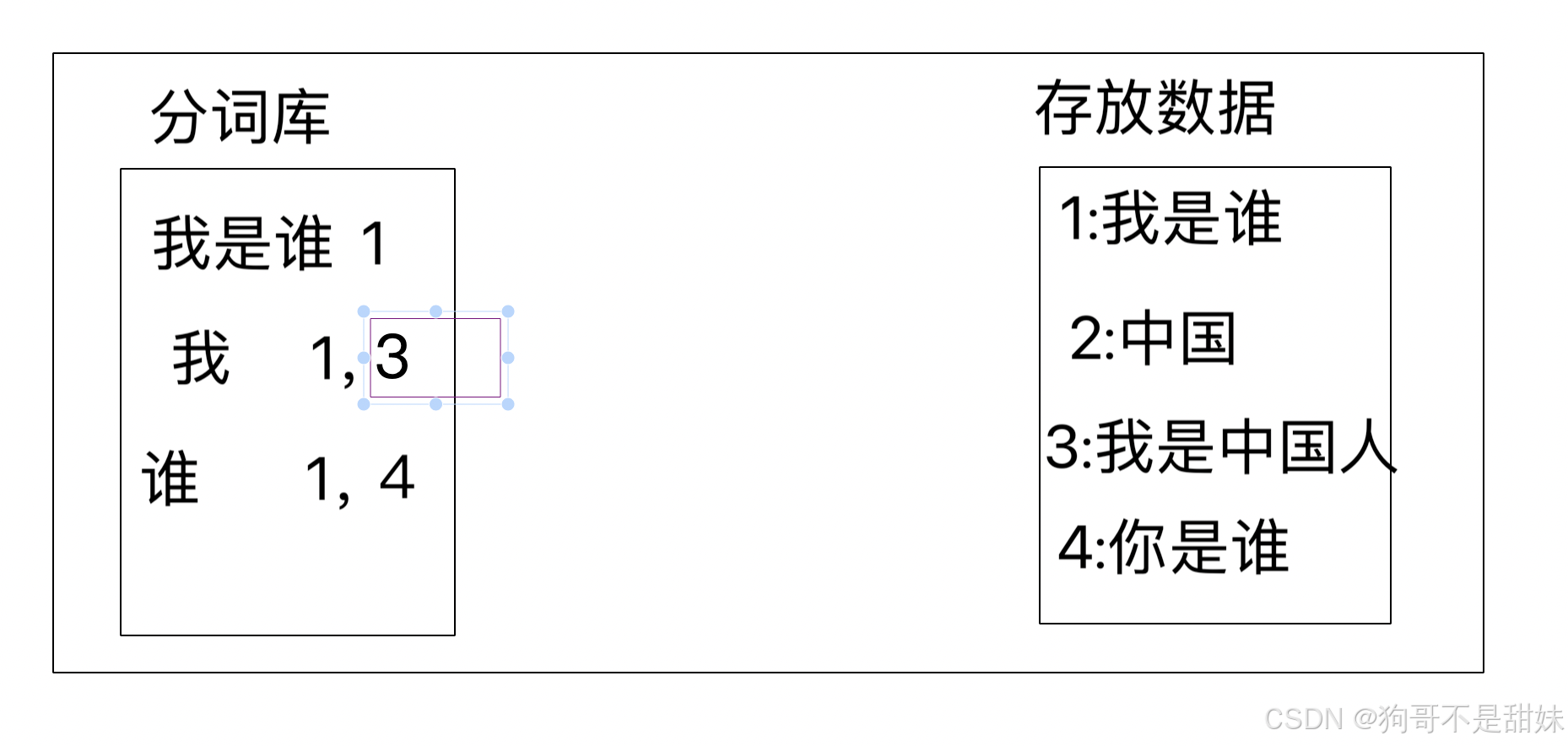
ES数据结构
ES,最小单位叫field,一般叫属性,就是类似于MySQL的字段;多个field组成一个document,一般叫文档,类似于MySQL的行;多个document组成一个Type,一般叫类型,类似于MySQL上的表(版本不一样,Type略有不同,详情可参考后面的Type介绍);多个表汇总一个Index下,一般叫索引,类似于MySQL的数据库,
索引
备份的分片必须放到不同的服务器中
类型type
文档
一个索引下可以创建多个类型。
一个类型下,可以有多个文档,这个文档类似于Mysql表中的多行数据
属性:field(如同于列)
操作ES的Result语法
Get请求:
http://ip:port/index:查询索引信息
http://ip:post/index/type/doc_id 查询指定的文档信息
Post请求:
http://ip:port/index/type/_search 查询
http://ip:port/index/type/doc_id/_update 修改文档,在请求体中json字符串代表修改的具体信息
Put请求:
http://ip:port/index :创建一个索引,需要在请求体中指定索引的信息,类型,结构
http://ip:port/index/type/_mappings:代表创建索引时候,指定索引的文档存储的属性的信息
Delete请求
http://ip:port/index/type/doc_id 删除指定的文档
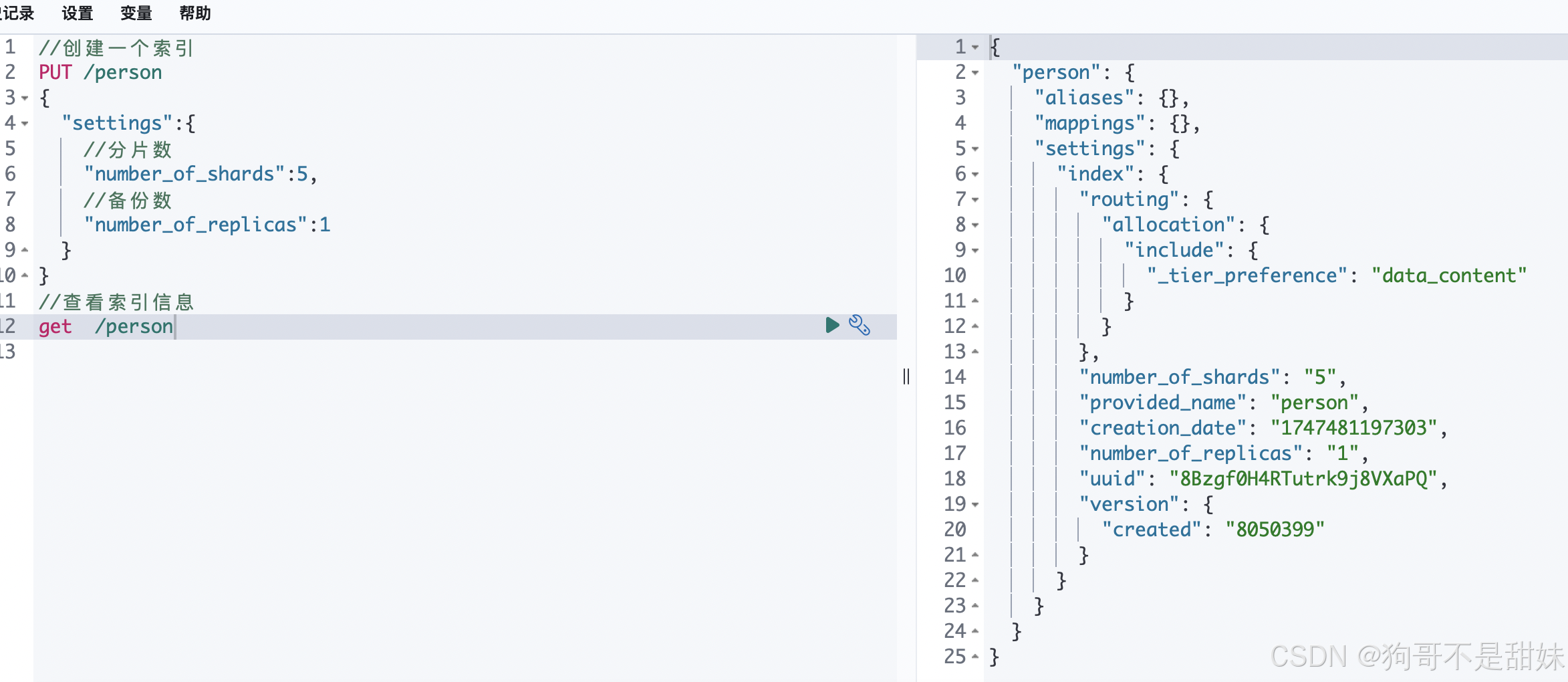
创建索引
//创建一个索引 PUT /person {"settings":{//分片数"number_of_shards":5,//备份数"number_of_replicas":1} }查看索引信息
//查看索引信息 get /person
3.3.3删除索引
//删除索引 delete /person3.4ES中Field可以指定的类型
String 被分成两种类型:text and Keyword ,
text被使用的较多,
- 一般被用于全文检索,全文检索,支持模糊、精确查询,不支持聚合,排序操作;
- test类型的最大支持的字符长度无限制,适合大字段存储;
keyword:
- 不进行分词,直接索引,支持模糊、支持精确匹配,支持聚合、排序操作。
- keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
- 使用场景: 存储邮箱号码、url、name、title,手机号码、主机名、状态码、邮政编码、标签、年龄、性别等数据。 用于筛选数据(例如: select * from x where status='open')、排序、聚合(统计)。 直接将完整的文本保存到倒排索引中
数值类型:long,integer,short,byte,double,float,half_float(比float精度还要小一半),scaled_float(用long来表达)date类型(可以指定具体格式,比如年月日,时分秒,毫秒值啥的)
布尔类型:boolean类型,表达true和false
二进制类型:binary类型,暂时支持Base64 encode string .
long_range:赋值时,无序指定具体的内容,只需要存储一个范围即可,指定lt,gt,gte,lte啥的
Integer_range:同上
double_range:
ip_range:
geo_point:用来存储经纬度的
ip类型
ip:可以存储ipv4/ipv6都支持




创建索引,并且指定数据结构
没有type之后,直接可以插入,他会帮助你创建索引
_doc是文档(属性已经是半个废弃状态。)
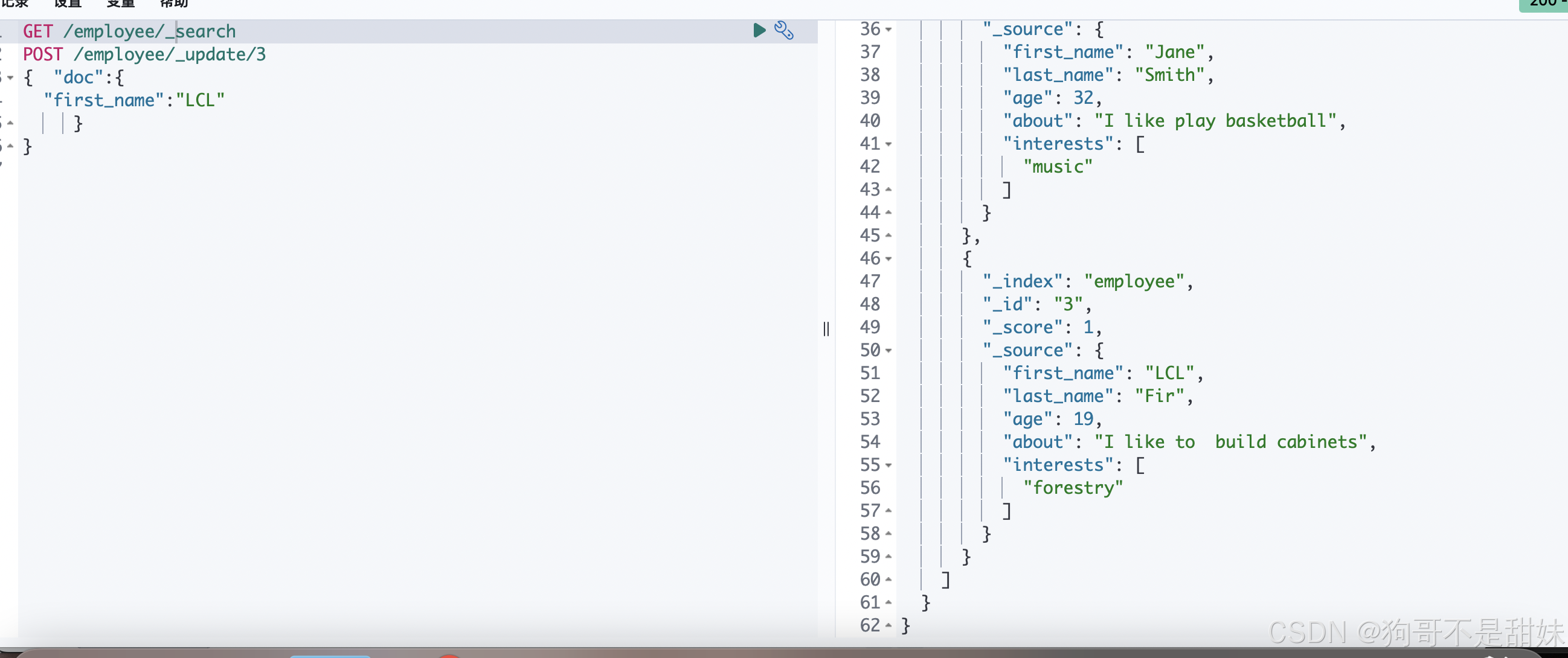
PUT /employee/_doc/1
{"first_name":"John","last_name":"Smith","age":25,"about":"I love go rock climbing","interests":["sports","music"]
}PUT /employee/_doc/2
{"first_name":"Jane","last_name":"Smith","age":32,"about":"I like play basketball","interests":["music"]
}PUT /employee/_doc/3
{"first_name":"Lcl","last_name":"Fir","age":19,"about":"I like to build cabinets","interests":["forestry"]
}查询数据
全部查询(应该是根据索引来查询,后面加上_search)
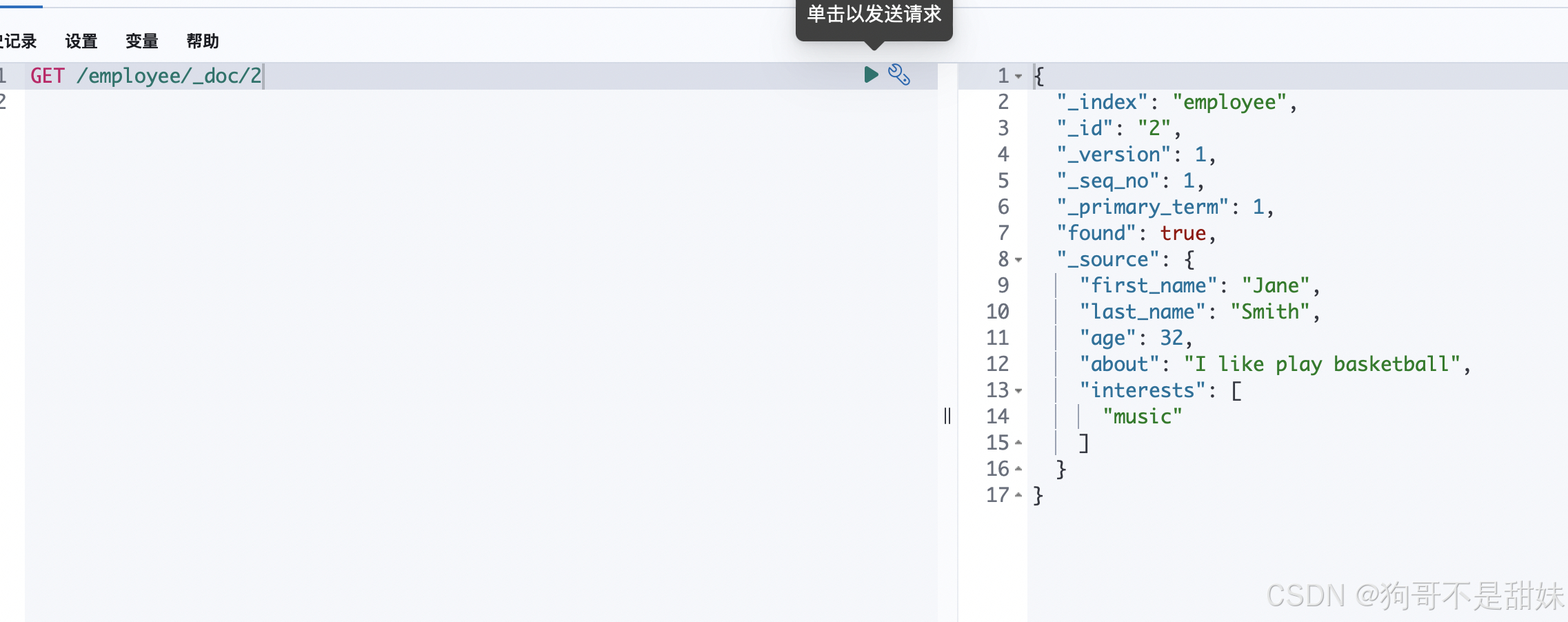
GET /employee/_search可以根据id查找,会从
employee_doc索引中获取 ID 为2的文档。
修改数据,
POST /employee/_update/3
{ "doc":{"first_name":"LCL"}
}
修改成功
如何操作ES
package com.bite.friend.domain.question.es;
import lombok.Getter;
import lombok.Setter;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;import java.time.LocalDateTime;@Getter
@Setter
//对应的每条数据,相当于一行的数据 ,index时索引名字
@Document(indexName = "idx_question")
public class QuestionES {@Id@Field(type = FieldType.Long)private Long questionId;@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")private String title;//代表难度,@Field(type = FieldType.Byte)private Integer difficulty;@Field(type = FieldType.Long)private Long timeLimit;@Field(type = FieldType.Long)private Long spaceLimit;@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")private String content;@Field(type = FieldType.Text)private String questionCase;@Field(type = FieldType.Text)private String mainFuc;@Field(type = FieldType.Text)private String defaultCode;//时间类型@Field(type = FieldType.Date, format = DateFormat.date_hour_minute_second)private LocalDateTime createTime;public QuestionES() {}
}
里面内置了save方法,因此他直接调用这个方法就可以了

为什么不拿数据库,而是拿ES
首先你数据库的话匹配不是很方便,你的模糊查询,要么写很多条,要么写的非常复杂很长,可读性不高
索引使用es,因为ES支持一个分词的操作
ES天生是集群模式
假设三个节点,随便打到任何节点上
假如使用倒排索引,索引的字段一半很长,如果用B+树,他的深度可能很深
性能无法保证,索引可能失效
精准度差,无法与其他属性产生相关性。
全文检索:B+树不适合,因为大多都是文本字段
id和文本字段连接,因为文本字段很大,很容易一条数据超过他的节点容量,所以有可能我一条节点用很多个节点存储
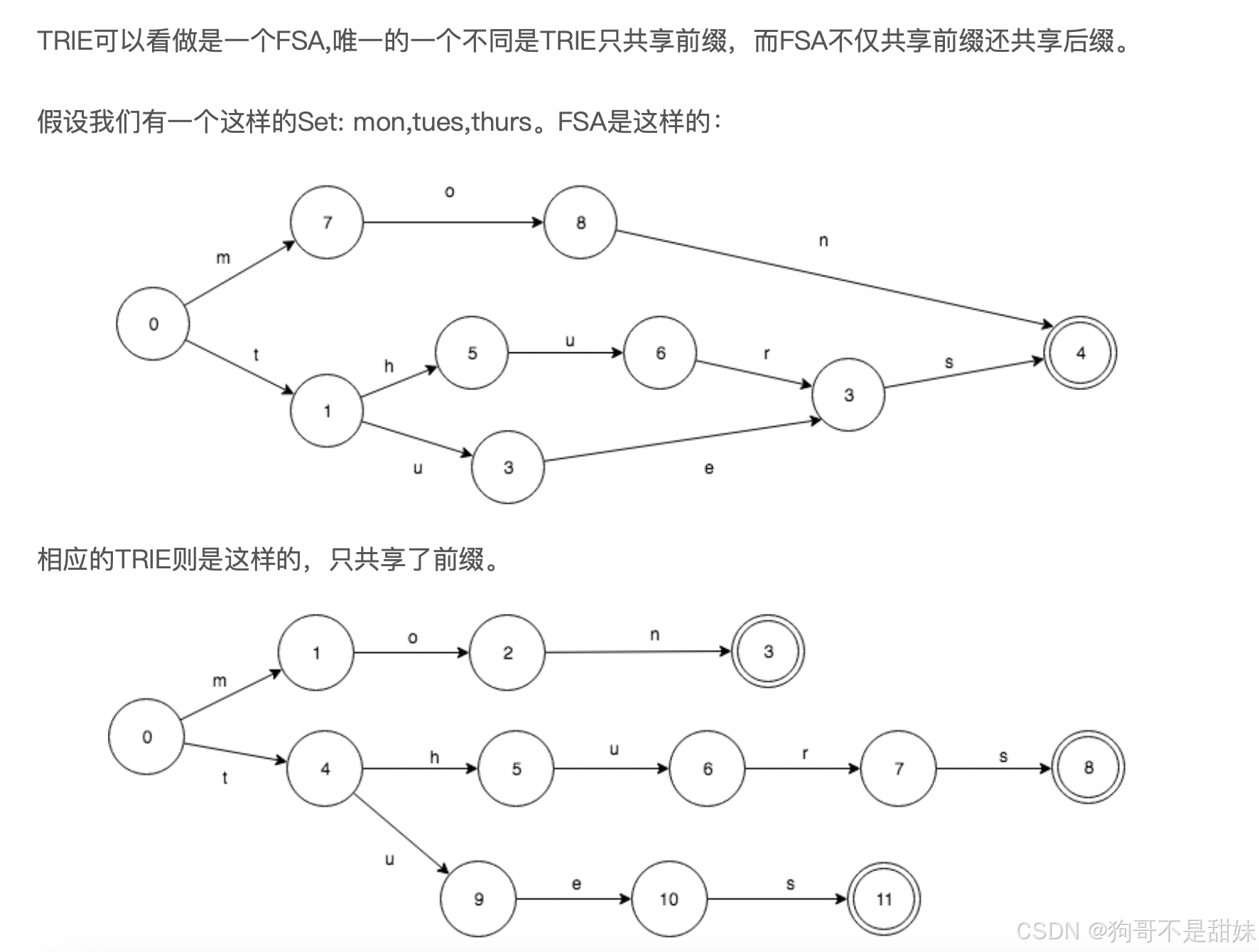
怎么理解共享后缀
aaabcdwdwbbbbbb
aaawdwhdiubbbbbb
中间不一样,但是我们的后面一样
FSA结构
FST结构(这个写的真好)关于Lucene的词典FST深入剖析 | 申艳超-博客
总结以下,加入节点过程:
- 1)新插入input放入frontier,这里还没有加入FST
- 2)依据当前input, 对上次插入数据进行freezeTail操作, 放入FST内
- 3)构建input的转移(Arc)关系
- 4)解决Output冲突,重新分配output,保证路径统一(NO_OUTPUT,不执行)