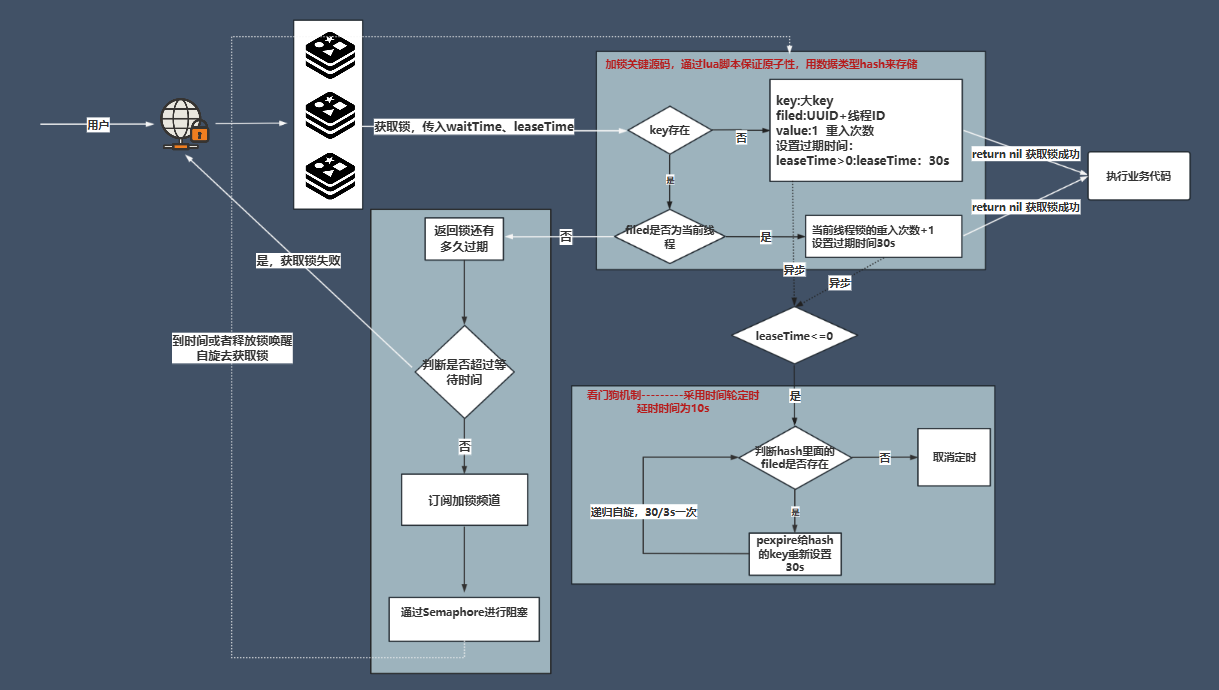
一、数据层优化:构建高质量检索基础
(一)动态语义分块技术
传统固定长度分块易切断完整语义,采用基于相似度的动态分块策略可显著提升上下文连贯性。通过LangChain的SemanticChunker实现语义边界检测,当相邻文本相似度低于0.4时自动切分,避免将“设备型号-参数-操作步骤”等关联内容分割到不同块。
from langchain_experimental.text_splitter import SemanticChunker
from langchain.embeddings import HuggingFaceEmbeddingsembedder = HuggingFaceEmbeddings(model_name="BAAI/bge-base-zh")
splitter = SemanticChunker(embedder, breakpoint_threshold=0.4) # 相似度阈值设为0.4
chunks = splitter.split_text(long_document) # 自动识别语义边界
应用效果:在医疗病历检索场景中,症状-诊断-治疗的上下文关联度提升35%,关键信息遗漏率降低22%。
(二)多粒度索引体系构建
建立三层索引结构实现粗细粒度结合的检索能力:
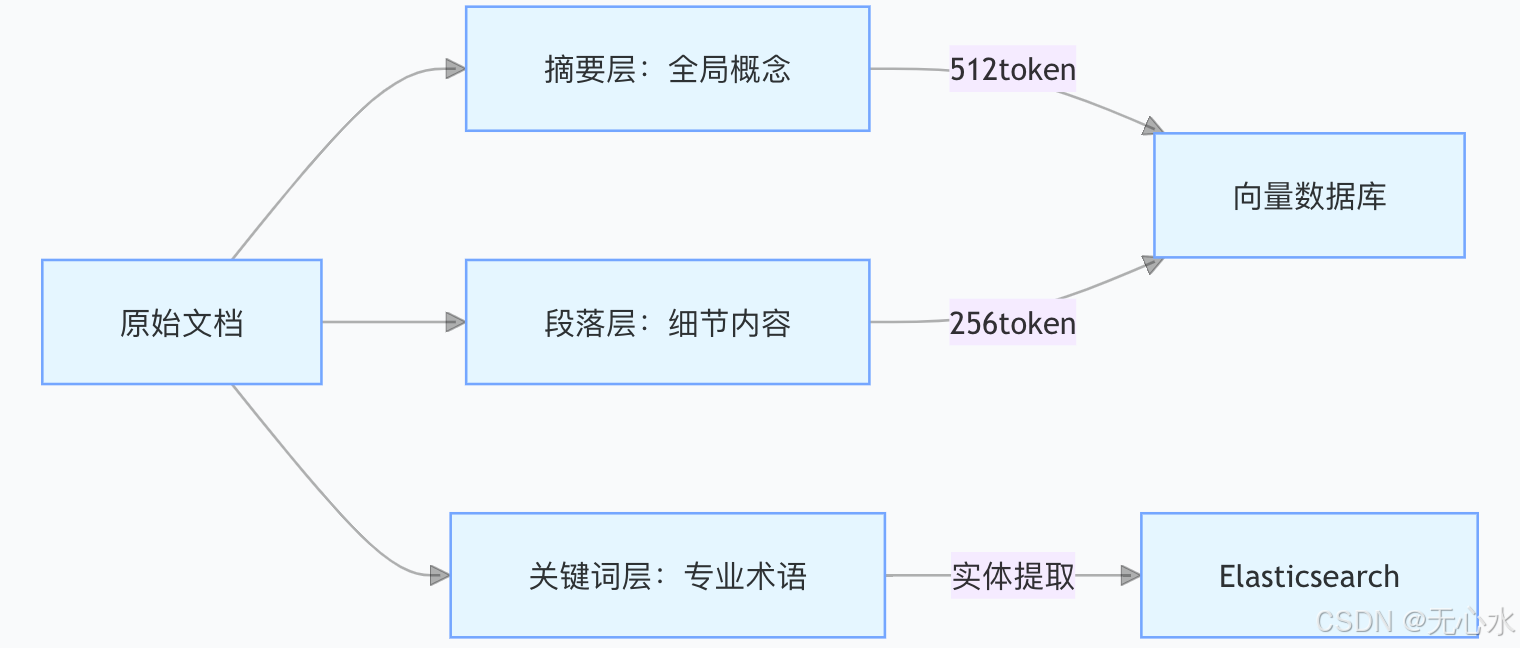
- 摘要层:利用GPT-3生成128字摘要,涵盖文档核心论点,用于快速概览检索。
- 段落层:按自然段分块,保留完整逻辑单元,适合精确内容定位。
- 关键词层:提取专业术语及同义词(如“房颤→心房颤动”),通过Elasticsearch实现关键词精确匹配。
金融合同场景实践:通过三层索引,合同条款检索的Hit@3指标从68%提升至92%,违约条款定位效率提升4倍。
(三)数据增强策略
1. 查询扩展(HyDE)
利用LLM生成假设答案作为补充查询,解决用户模糊需求问题。例如用户提问“如何提升销售额”,HyDE生成“提升销售额的营销策略有哪些”,扩展检索维度。
# HyDE查询扩展示例
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAIprompt = PromptTemplate(template="用户问题:{query}\n假设答案:",input_variables=["query"]
)
llm = OpenAI(temperature=0.7)
expanded_query = llm(prompt.format(query=user_query))
2. 同义词注入
构建领域同义词库并结合ChatGPT生成变体术语,如“区块链→分布式账本技术”、“CPU→中央处理器”。通过向量数据库的同义词搜索功能,将相关术语的向量距离缩短30%。
二、算法层优化:提升检索精准度与召回率
(一)混合检索加权融合
结合向量检索与关键词检索的优势,根据场景动态调整权重:
from langchain.retrievers import BM25Retriever, EnsembleRetriever# 初始化双检索器
vector_retriever = FAISSVectorRetriever(vectorstore=vector_db)
keyword_retriever = BM25Retriever.from_texts(texts=keyword_corpus)# 权重配置(技术文档侧重向量检索,客服对话侧重关键词)
ensemble_retriever = EnsembleRetriever(retrievers=[vector_retriever, keyword_retriever],weights=[0.7, 0.3] # 技术文档场景权重分配
)
调参经验:
- 法律文书:[0.6, 0.4](向量+法律条文关键词)
- 电商客服:[0.4, 0.6](商品名称+属性关键词)
(二)查询重写三阶策略
针对不同查询类型实施分级处理:
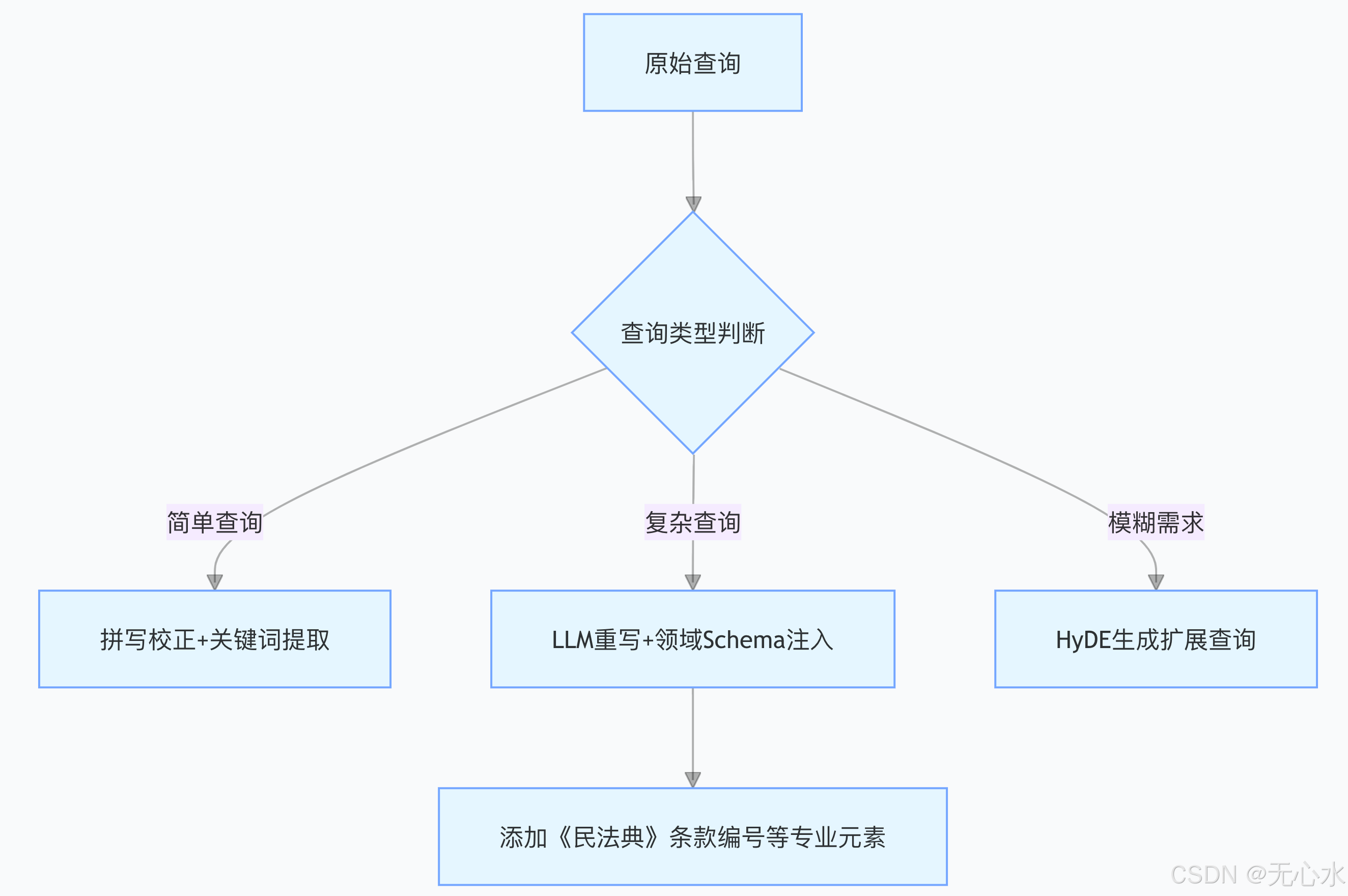
法律场景示例:
原始查询:“合同违约如何处理”
重写后:“根据《民法典》第五百七十七条,合同违约的责任承担方式有哪些”
(三)嵌入模型微调实战
使用企业私有数据对通用嵌入模型进行微调,提升领域术语表征能力: