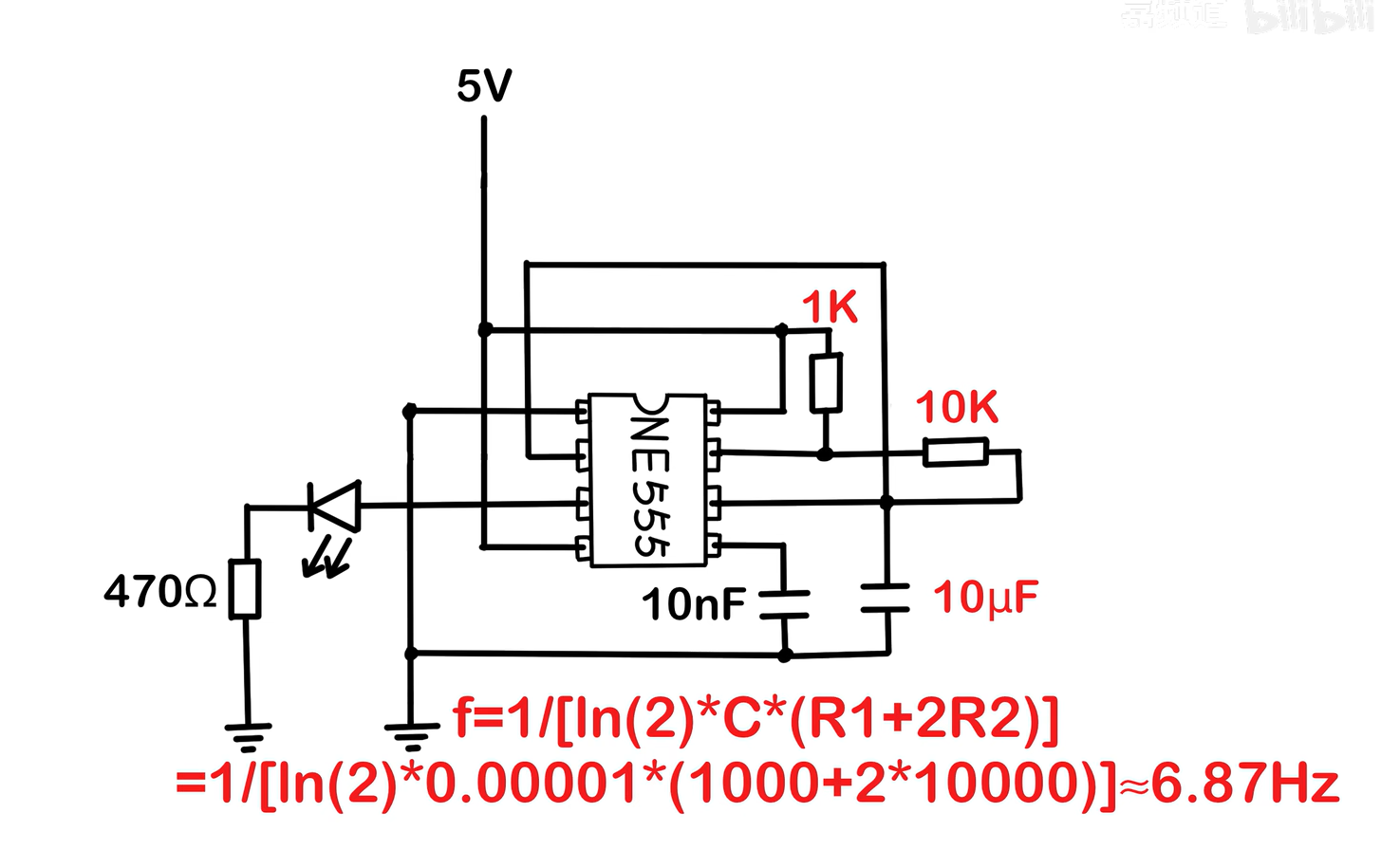
摘要
预训练的VLMs,对于跨任务的迁移学习至关重要,然而,在few-shot数据集上微调会导致过拟合,降低在新任务上的性能。为解决这个问题,提出一种新的多模态表征学习框架(MMRL),该框架引入了一个共享、可学习且与模态无关的表示空间,MMRL将空间标记(tokens)投影到文本和图像表征标记(tokens)上,从而促进多模态交互。与之前仅有话类token特征的方法不同,MMRL在encoders的最高层集成了表示tokens——在encoders中,数据集特定的特征更为突出,同时在较低层保留了广义知识。在训练过程中,表征特征和类特征都被优化,其中对表征tokens应用了一个可训练的投影层,而类别token投影层则保持冻结,以保留预训练知识,此外,还引入了一正则化项,以使类别特征和文本特征与来自冻结VLM的零样本特征对齐,从而保证模型的泛化能力,在推理阶段,采用了解耦策略,即对与基础类别,同时利用表征特征和类别特征;而对于新任务,则仅使用保留了更多通用知识的类别特征,在15个数据集上进行的大量实验表明,MMRL优于现有最先进的方法,在任务特定适配与泛化之间实现了平衡的权衡。Code is available at
https://github.com/yunncheng/MMRL
1、介绍
介绍了视觉语言模型(VLMs),如CLIP,因其能利用文本和视觉模态的互补信息而受到关注,但在适应新任务时存在局限性,因为微调大规模架构需要大量计算资源。
为促进VLMs的高效适应,提出了提示工程和集成等策略,但手动设计提示耗时且需要专业知识,无法保证找到最优提示。CoOp引入了提示学习,通过优化连续可学习的向量来实现高效的数据集适应。MaPLe发现仅在文本模态内进行提示学习可能并非最优,提出了一种多模态提示学习方法,通过耦合函数将深度提示嵌入到VLM编码器的较低层中,以增强视觉和文本表征之间的对齐。
除了提示学习外,还介绍了适配器风格学习方法,通过在VLMs中集成轻量级模块来调整为下游数据集提取的特征。CLIP-Adapter和MMA是这种方法的例子,它们通过不同的方式优化文本和视觉表征之间的对齐。
当前的多模态深度提示学习方法在浅层应用提示拼接可能会损害通用知识,且主要更新都集中在文本提示上。此外,提示学习和适配器风格方法都容易过拟合到特定的数据分布或任务类别,导致VLMs的泛化能力和零样本学习能力下降。
为应对这些挑战,我们提出了一种新颖的多模态表征学习框架,该框架有别于传统的提示学习和适配器风格方法。具体而言,我们在编码器的较高层引入了一个共享、可学习且与任何模态都无关的表征空间。这个空间作为多模态交互的桥梁,将该空间中的标记映射到图像和文本表征标记上,然后与原始编码器标记拼接,以实现有效的多模态交互。我们的表征标记旨在从下游任务中学习数据集特定的知识,同时对原始分类标记进行正则化处理,以保留大量可泛化的知识。MMRL具有三个关键优势:(1)一个无偏的共享表征空间,促进了平衡的多模态学习;(2)通过避免在编码器的浅层集成提示,保留了原始VLM的泛化能力;(3)与仅通过可学习的提示或适配器来优化类别标记特征的提示学习或适配器风格方法不同,我们的方法支持跨类别的解耦推理。在训练过程中,我们优先优化表征标记特征,其投影层是可训练的,而原始类别标记的投影层则保持固定。为进一步保留类别标记的泛化能力,我们使用一个正则化项,将其特征与来自冻结VLM的零样本特征对齐。在推理阶段,对于基础类别,我们同时利用表征标记和类别标记特征;而对于未见类别或新数据集,则仅使用类别标记特征。我们的主要贡献总结如下:
• 我们引入了多模态表征学习(MMRL)框架,该框架包含一个共享、无偏且可学习的空间,该空间桥接了图像和文本模态,在原始编码器的较高层促进了多模态交互。
• 采用解耦策略,通过为下游任务适配表征标记,同时对新任务中的原始类别标记进行正则化处理,保留了VLM的泛化能力。
• 大量实验表明,MMRL显著提高了下游任务的适应性和泛化能力,相较于基线方法取得了更优的性能。
2、相关工作
2.1 Vision-Language Models
2.2 Efficient Transfer Learning
提示学习方法已被证明在适配视觉语言模型(VLMs)方面是有效的。CoOp 通过将固定模板替换为可学习的连续向量,开创了提示学习的先河,提高了灵活性,但牺牲了CLIP的零样本和泛化能力。为解决这一问题,CoCoOp融入了视觉线索来生成针对特定实例的提示,从而提高了对类别分布变化的泛化能力,而ProDA 则通过学习提示分布来增强适应性。PLOT 利用最优传输方法来对齐视觉和文本模态。KgCoOp 通过最小化学习到的提示与精心设计的提示之间的差异,保留了通用的文本知识。ProGrad 选择性地更新与通用知识对齐的梯度,而RPO 则利用掩码注意力机制来缓解内部表征的偏移。除了以文本为中心的方法外,MaPLe 通过耦合函数将文本提示映射为视觉提示并加以整合,促进了跨模态的协同作用。ProVP 采用单模态视觉提示,并通过对比特征重构来使提示的视觉特征与CLIP的分布对齐。PromptSRC 采用自正则化策略来缓解过拟合问题,而MetaPrompt 则应用了一种基于元学习的提示调整算法,鼓励针对特定任务的提示能够在不同领域或类别之间进行泛化。TCP 将文本知识适配为类别感知的标记,从而增强了泛化能力。
适配器风格学习方法代表了VLM适配的另一条高效途径。CLIP-Adapter 使用轻量级适配器(以两层多层感知机(MLP)的形式实现)来通过交叉熵优化改进CLIP的特征表示。在此基础上,Tip-Adapter 缓存了训练特征,以便在测试特征和训练特征之间进行高效的相似度计算。然而,这两种方法在预测之前都是独立处理图像和文本表示的。为了解决这种分离问题,MMA 将不同分支的特征整合到一个共享空间中,允许跨分支的梯度流动,并增强了模态之间的连贯性。
除了上述方法外,还有几种方法利用大型语言模型(LLMs),如GPT-3,进行文本增强或在整个数据集上应用蒸馏技术来提高性能。然而,这些方法所带来的计算需求增加可能会使它们超出高效迁移学习的预期范围。
3、方法
本方法与之前方法一致,建立在预训练的VLM, CLIP的基础上,
3.1. Preliminary
首先定义方法中的符号,在CLIP包含两个编码器:图像编码器和文本编码器
。
Image Encoding: 图像编码器,由L个transformer 层组成,定义为
.输入图像
,它被划分为M个固定大小的patchs,每个补丁都被投影到一个patch embedding中,结果为
其中M表示patch的个数,
为embedding (嵌入)维度。初始嵌入向量
与一个可学习的类别标记(token)
和位置编码相结合,形成transformer的输入序列,每一层都处理这个序列:
经过所有的transformer层之后,一个patch投影层将类别token
的输出映射到共享的V-L潜在空间中
其中
Text encoding:对于输入文本,例如“A photo of a [CLASS].”它被tokenized 和转化为embeddings,其中N是token的长度,
是embedding的维度,开始文本(BOT)和结束文本(EOT)标记,分别表示为
和
标记序列边界,这些 token embeddings和位置编码,通过文本编码器的L个Transformer层
,如下所示:
在最后一层之后,EOT标记的输出通过
投影到共享的V-L空间中。
其中
Classification with CLIP: 通过图像特征和文本特征
,对于C个类别,CLIP计算
与每个
之间的余弦相似度。
其中
表示
norm,类别概率使用sotftmax函数计算
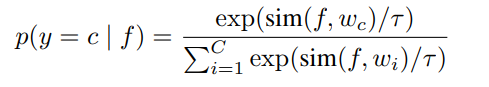
其中是温度参数,最终预测类别是概率得分最高的那个。

3.2 Multi-Modal Representation Learning (MMRL)
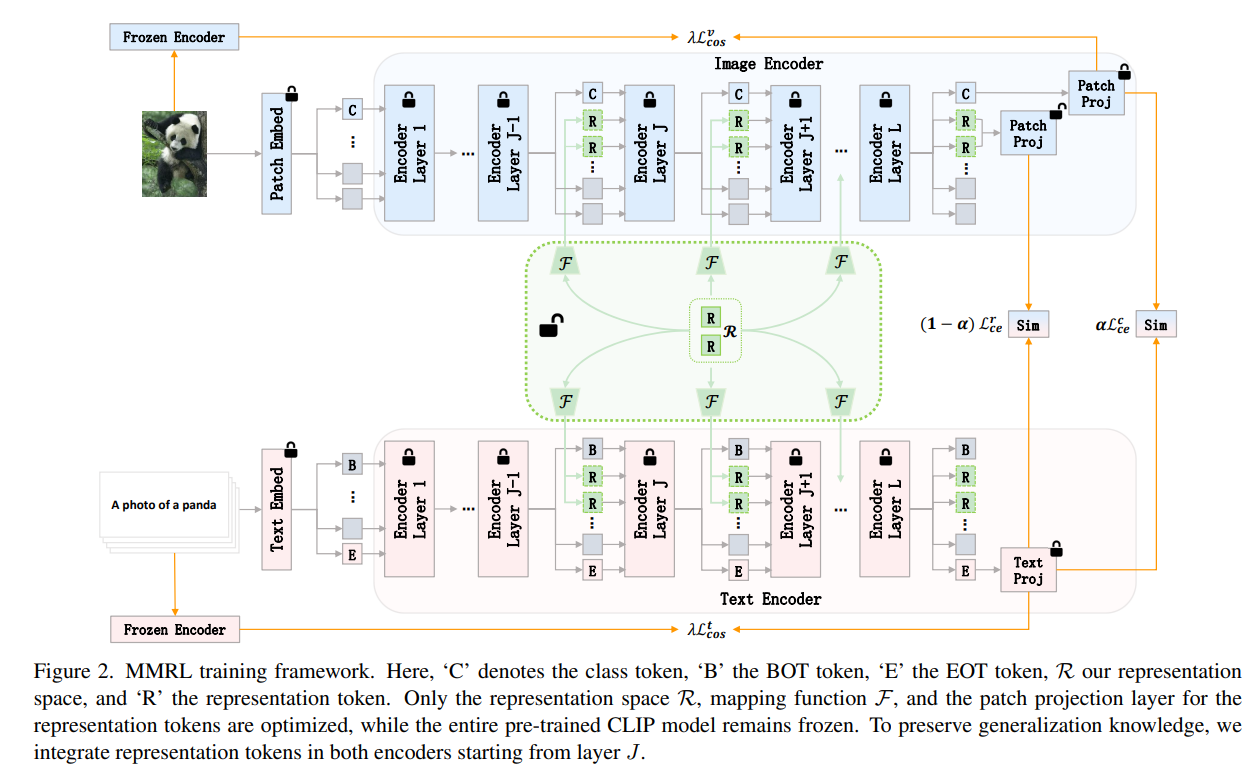
我们提出的MMRL旨在解决使用少量数据调整预训练VLM的挑战,同时保持对新任务的泛化能力。MMRL的训练和推理框架分别如图2和图3所示。下面,我们将详细介绍方法论。
3.2.1 Learnable Representation Space
MMRL 建立了一个共享的、可学习的表征空间 ,以促进多模态交互,通过从高斯分布中采样进行初始化。使用一个可学习的映射函数
,实现为一个线性层,我们将该空间中的标记
—其中 K 是tokens的数量,dr 是表征空间的维度——投影到视觉和文本模态中。
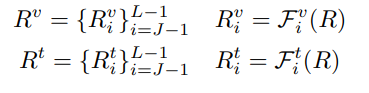
其中和
分别表示在第 (i+1) 层transformer中的视觉和文本模态的表征tokens。索引 J 表示这些表征token开始整合到编码器的起始层。
3.2.2. Integration into Higher Encoder Layers
为了在预训练的CLIP模型的较低层中保留广义知识,从第J层开始,将表征token 和
集成到图像编码器
和文本编码器
的较高层中
对于图像编码器
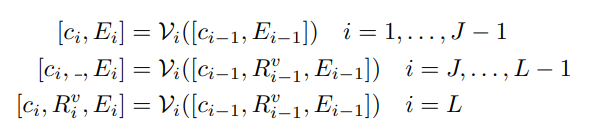
对于文本编码器,虽然之前的提示学习涉及替换
的部分以融入深度提示,我们保留了整个
并在其之前插入
,旨在保留原始文本信息,
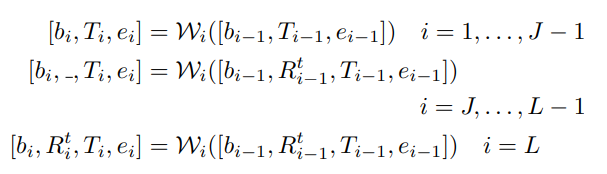
由于文本编码器的自回归特性,我们调整了注意力掩码矩阵以适应嵌入长度的增加。
3.2.3. Representation Learning
表征学习旨在利用表征token进行特定数据集的适应,而类标记则保留了原始CLIP的预训练知识。通过一系列旨在在训练和推理过程中保持泛化的策略,MMRL能够为不同的任务提供灵活的推理,详情如下。
训练阶段:同时优化表征标记(representation tokens)和原始类别标记(original class token)的特征,但主要侧重于表征特征,以保留预训练知识。具体而言,表征标记的投影层是可训练的,而类别标记的投影层则保持固定。对于图像编码器,在经过L层Transformer层后,得到类别标记的输出
,以及K个表征标记的输出
。表征标记的最终输出
,是通过计算这K个标记的平均值得到的,
![]()
其中,。随后,我们应用补丁投影层(patch projection layers),将类别标记和表征标记的输出都映射到通用的视觉-语言(V-L)潜在空间中,从而得到类别特征
和表征特征
。
![]()
其中,是CLIP中用于类别特征的原始,即冻结的补丁投影层,而用于表征特征的
是可训练的。
对于文本编码器W,考虑到文本的序列特性,在经过L层Transformer层处理后,将与原始CLIP模型中相同的EOT标记映射到通用的视觉-语言(V-L)空间中,从而得到文本特征。
![]()
利用图像特征、
,以及针对C个类别的文本分类器{
,采用交叉熵损失函数来分别优化类别特征和表征特征。
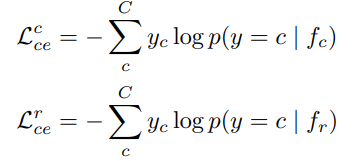
其中,如果图像属于类别
,则
,否则
。为了进一步保留类别特征的泛化能力,我们最大化
与冻结的CLIP特征
之间的余弦相似度,从而显式地引导训练过程。
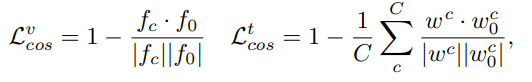
最终MMRL的损失函数为
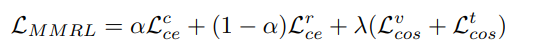
其中控制特征之间的平衡,
是惩罚系数
Testing on Base Classes:对于在训练过程中见过的分布内类别,我们将数据集特定的表征特征与保留泛化能力的类别特征相结合。一个属于分布内测试样本属于第
类的概率是
![]()
其中和
分别是从类标记和表示标记中提取的特征。
Testing on Novel Classes:对于在训练过程中未见过的类别或新的数据集,我们完全依赖于类标记,这些标记保留了通用知识。
![]()