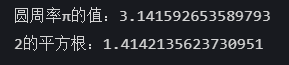
一、Cache数据库的高可用架构
对于Cache数据库的高可用性最佳实践,官方提供了以下几种策略:
集成基于操作系统级HA软件以及搭配共享存储的故障转移集群

基于操作系统的HA软件,搭配共享存储的方案,Cache实例安装在共享存储中,当故障发生时,在新的主节点上重启Cache,重启时,Cache实例会自动执行正常的启动恢复,包括WIJ,日志。
缺点:
需要第三方HA软件支持
切换流程由操作系统HA操作,可能会比较漫长
共享存储发生故障时,会导致数据灾难。
集成基于虚拟化平台的HA功能

监控运行在虚拟化平台上Cache实例虚拟机,当故障发生时在另一台Esxi主机拉起之前运行Cache实例虚拟机,不仅时间长,也不能及时响应,而且共享存储故障也是灾难的。
缺点:
需要第三方HA软件支持
切换流程由操作系统HA操作,可能会比较漫长
共享存储发生故障时,会导致数据灾难。
基于Cache的镜像集群自动故障转移

主备镜像分配至不同物理主机,每个故障转移成员在镜像集群中维护每个数据副本,数据更新只在主节点,备用节点通过日志文件与主节点保持同步,当主节点发生故障时,备用节点会自动快速接管并成为主实例。
二、高可用架构的选择
高可用架构选择
相较于以上集中高可用方案,最后的无共享模式的镜像集群成为实现Cache数据库高可用性的首选架构,相较于其他高可用架构,它至少具备以下几项优势:
无共享架构,消除存储单点故障问题
镜像副本兼顾报表查询以及数据备份功能
自动迅速故障转移
可灵活线性扩展
额外的及高可用性提升无论您对Cache数据库的高可用性采取何种方法,企业缓存协议 (ECP) 都可用于在用户和数据库服务器之间提供一层隔离,当数据库服务器出现故障时,用户仍保持与 ECP 应用服务器的连接,在中断期间主动访问数据库的用户会话将暂停,直到数据库服务器通过完成故障转移或重新启动故障系统再次变得可用。

通过ECP连接数据镜像集群
三、Cache数据库镜像集群的规划
镜像集群的组件简介
镜像成员:
要启用自动故障转移,镜像必须包含两个故障转移成员,物理上独立的系统,每个都托管一个 Caché 实例。
在任何给定时间,一个故障转移实例充当主要实例,为应用程序提供对镜像中数据库的访问权限,而另一个充当备份实例,维护这些数据库的同步副本,以准备接管作为主要实例。
当主 Caché 实例变得不可用时,备份将接管,提供对数据库的不间断访问,而没有数据丢失的风险。
当然镜像成员的类型还分同步和异步,这里不再详细阐述。

ISCA代理:
一个称为 ISCAgent 的进程在每个镜像成员的主机系统上运行,为镜像成员之间提供了一种额外的通信方式。ISCAgent 提供了一种方法,当两个故障转移成员之间的正常通信中断时,一个故障转移成员可以通过该方法获取有关另一个的信息。ISCAgent 可以向已关闭或断开连接的镜像成员发送数据。代理还参与故障转移决策;例如,与主实例和仲裁器都失去联系的备份可以联系主实例的 ISCAgent(假设主实例的主机系统仍在运行)以确认主实例在接管之前确实已关闭。

仲裁者:
仲裁器是一个独立的系统,托管一个 ISCAgent,镜像的故障转移成员与其保持持续联系,为他们提供在无法直接通信时安全地做出故障转移决策所需的上下文。一个仲裁器可以服务多个镜像,但是一个镜像一次只能使用一个仲裁器。
对于一个镜像集群,仲裁器也不是必须的,但强烈建议使用仲裁器,因为它显着增加了可以进行自动故障转移的故障场景的范围。

镜像集群的物理架构规划

简介
这是最简单的镜像配置。故障转移成员通过专用网络相互通信,而与它们的外部连接则通过公共网络进行,可选地通过镜像虚拟 IP (VIP)。
使用的配置
| VIP | 10.1.1.100 |
| 仲裁者地址 | 10.1.1.35 |
| 服务器地址 | 10.1.1.11 10.1.1.10 |
| 镜像集群所用私网地址 | 10.0.0.11 10.0.0.10 |
| ISCAgent地址 | 10.1.1.11 10.1.1.10 |
网络讲解
VIP 要求两个故障转移成员位于同一子网上。
虽然不是必要的,但建议使用此处描述的用于镜像通信的单独专用 LAN 来优化网络利用率控制。如果不使用这样的 LAN,则应将镜像配置中的镜像私有地址更改为使用蓝色背景上描绘的地址。
仲裁者的网络位置规划
如果故障转移成员位于一个数据中心,仲裁器可以放在同一个数据中心。在该数据中心内,仲裁者与故障转移成员之间的物理隔离应该与它们彼此之间的物理隔离相同;例如,如果您已将故障转移成员放置在单独的服务器机架中以避免一个机架中的电源或网络问题影响两个成员,那么您应该将仲裁器与这两个机架分开放置。
如果数据中心使用内部网络在镜像内进行通信,则仲裁器应放置在网络的公共侧,这样内部网络的故障不会使故障转移成员与仲裁器相互隔离。
如果故障转移成员位于不同的数据中心,则仲裁器应放置在第三个位置。这可能是另一个数据中心、由另一方托管的位置、公共或私有云服务,甚至是系统管理员的家(假设她有可靠的网络)。将仲裁器放置在代表用户社区的位置支持对网络中断的最佳镜像响应。
四、Cache集群故障切换所需要考虑的业务问题
如何保证切换时数据的一致性完整性
安全自动故障转移的要求
备份 Caché 实例只有在满足以下两个条件的情况下才能自动接管主实例:
备份实例已从主实例接收到最新的日志数据。
此要求保证在故障发生时,主数据库上进行的所有持久更新都已经或将要对备份数据库上进行,从而确保不会丢失任何数据。日常维护中也可以通过mirroe进程的状态监控器进行备份镜像状态监控,如下图所示,FailOver B日志同步状态为Active:
Status of Mirror MIR25FEB at 17:17:53 on 02/27/2014Member Name+Type Status Journal Transfer Dejournaling-------------------------- --------- ---------------- --------------MIR25FEB_AFailover Primary N/A N/AMIR25FEB_BFailover Backup Active Caught upMIR25FEB_CDisaster Recovery Connected Caught up Caught upMIR25FEB_DRead-Only Reporting Connected Caught up Caught upArbiter Connection Status:Arbiter Address: 127.0.0.1|2188Failover Mode: Arbiter ControlledConnection Status: Both failover members are connected to the arbiterPress RETURN to refresh, D to toggle database display, Q to quit,or specify new refresh interval <60>主实例不作为镜像集群的主镜像对外提供服务。(不到万不得已不要手工切换镜像角色)
此要求消除了两个故障转移成员同时充当主要成员的可能性,这可能导致逻辑数据库降级和完整性丧失。
Failover备份镜像挂起或因为网络问题失联会造成的影响
在正常镜像操作期间,备份故障转移成员的日志传输状态为Active,这意味着它已从主节点接收到所有日志数据并与主节点同步。如果活动备份未在服务质量 (QoS) 超时(默认8秒)内确认从主服务器接收到新数据,则主服务器撤销备份的活动状态,断开备份并暂时进入故障状态。当处于故障状态时,主节点不会提交任何新的日志数据(可能会导致应用程序暂停).

Backup Loses Connection to Primary
If the backup loses its connection to the primary, or exceeds the QoS timeout waiting for a message from the primary, and learns from the arbiter that the arbiter has also lost its connection to the primary or exceeded the QoS timeout waiting for a response from the primary, the backup takes over as primary and switches to agent controlled mode. When connectivity is restored, if the former primary is still operating in trouble state, the new primary forces down.
If the backup learns that the arbiter is still connected to the primary, it no longer considers itself active, switches to agent controlled mode, and coordinates with the primary’s switch to agent controlled mode through the arbiter; the backup then attempts to reconnect to the primary.
If the backup has lost its arbiter connection as well as its connection to the primary, it switches to agent controlled mode and attempts to contact the primary’s ISCAgent per the agent controlled mechanics.
简而言之,如果配置自动故障转移,当备库挂了,主库会hang默认的8秒,然后备库如果不能在8秒内响应,那么备库的活动日志同步状态(Active)就会被撤销,不具备自动故障转移中接管主库的资格,8秒过后主库还会作为主库继续运行,只不过mirror控制模式从仲裁切换到agent。
可以确定的是 如果配置了自动故障转移,当备库掉线 主库会等8秒,这8秒 主库不会提交任何新的日志,这有可能会导致某些应用的hang,如果8秒内,备库排除故障上线了,那么主库会保持备库日志传输的Active状态(也就是说备库具备接管主库的资格),如果8秒后,备库还是连不上,主库就把备库的日志同步状态标记为落后(不具备接管主库的资格),然后主库接着正常提交日志。当备库排除故障再次连接上主库后,备库会先通过主库上的ISCAgent
补全自己dang机时间段内的日志以保持和主库的数据同步,当数据都同步后,备库的日志传输就会被标记为Active状态,就具备了自动接管主库的资格,为下一次的自动故障转移做准备。
当发生自动故障切换后镜像集群恢复正常后如何回切
不需要手动回切,新加入的实例连接上之后自动作为备份镜像,并由镜像集群维护,保持与主库数据的一致性,随时做好下次自动故障切换准备。
常见的自动故障转移情景
尽管情况和细节各不相同,但有几种主要的主要中断情况,在这些情况下,活动备份故障转移成员会自动接管,如下所示:
通过关闭其 Caché 实例来启动主节点的计划中断(例如出于维护目的)。
发生自动故障转移是因为主备份指示主动备份接管。
由于意外情况,主 Caché 实例挂起。
发生自动故障转移是因为主节点检测到它已挂起并指示活动备份接管。
由于意外情况,主 Caché 实例被强制关闭或完全无响应。
在这种情况下,主节点无法指示备份节点接管。但是,在从仲裁器得知它也与主服务器失去联系后,或者通过联系主服务器的 ISCAgent 并获得主服务器已关闭的确认后,主动备份将接管。
主要的存储子系统发生故障。
存储故障的典型后果是主实例由于 I/O 错误而挂起,在这种情况下,主实例检测到它已挂起并指示活动备份接管(如场景 2 中所示)。但是,在某些情况下,可能适用场景 3 或场景 5 中描述的行为。
主服务器的主机系统发生故障或变得无响应。
如果活动备份从仲裁器获悉它也与主服务器失去联系,则会发生自动故障转移。
如果没有配置仲裁器,或者仲裁器在主主机故障之前变得不可用,则无法进行自动故障转移;在这些情况下,手动强制备份成为主要备份可能是一种选择。
网络问题隔离了主节点。
如果配置了仲裁器并且在网络发生故障时两个故障转移成员都连接到它,则主节点将无限期地进入故障状态。
如果活动备份从仲裁器获悉它也与主服务器失去联系,则会发生自动故障转移。
如果备份与仲裁器失去联系的同时与主服务器失去联系,则无法进行自动故障转移。如果两个故障转移成员都已启动,则当网络恢复时,备份会联系主节点,然后主节点会恢复作为主节点运行。或者,可以手动指定主节点。
如果在网络故障之前未配置仲裁器或其中一个故障转移成员与其断开连接,则无法进行自动故障转移,并且主节点继续作为主节点运行。
不活动的备份(因为它正在启动或已经落后)可以通过联系主节点的 ISCAgent 并获取最新的日志数据来接管上述场景 1 到 4。在方案 5 和 6 下,不活动的备份无法接管,因为它无法联系 ISCAgent;在这些情况下; 手动强制备份成为主要备份可能是一种选择。

这个对比oracle dg还不一样 ,如果是dg的最大保护,备库挂了,主库一致重连不上,主库就会被lgwr shutdown abort,而这个cache,根据官方文档,如果使用自动故障转移(也就是镜像是Failover模式),那么备库挂了,主库会等Qos超时时间,时间过了,主库也不会自杀,而是继续提供服务










![[HNCTF 2022 Week1]silly_zip](https://i-blog.csdnimg.cn/direct/36aad49dfe2c403c9d4f17a4ea905933.png)