Django ORM开发指南:模型设计与高效查询完全攻略
关键词:Django ORM、模型设计、数据库查询优化、Model关系、QuerySet、数据库性能、Python Web开发、ORM最佳实践
摘要:深入解析Django ORM的核心概念和高级用法,从模型设计原则到查询优化技巧,通过实际案例演示如何构建高效的数据访问层。本文将帮助开发者掌握Django ORM的精髓,避免常见的性能陷阱,打造可维护的企业级应用。
前言:为什么Django ORM如此受欢迎?
想象一下,你正在开发一个在线书店系统。传统的方式下,你需要写大量的SQL语句来处理用户、订单、图书之间复杂的关系。但是使用Django ORM,你只需要用Python代码就能优雅地表达这些业务逻辑:
# 查找某个用户最近购买的科技类图书
user.orders.filter(created_at__gte=last_month,items__book__category='Technology'
).distinct()
这就是Django ORM的魅力——它让我们能够用面向对象的思维来操作关系数据库,既保持了Python的简洁优雅,又提供了强大的数据库功能。
今天我们就来深入探索Django ORM的世界,学会如何设计高效的模型和编写优化的查询。
第一部分:Django ORM核心理念
什么是ORM?把数据库表变成Python类
ORM(Object-Relational Mapping)就像是数据库世界和Python世界之间的翻译官。它把数据库中的表转换成Python中的类,把表中的行转换成类的实例。

让我们从一个简单的例子开始:
# 传统SQL方式
CREATE TABLE books (id INTEGER PRIMARY KEY,title VARCHAR(200),author VARCHAR(100),price DECIMAL(8, 2),published_date DATE
);# Django ORM方式
class Book(models.Model):title = models.CharField(max_length=200)author = models.CharField(max_length=100)price = models.DecimalField(max_digits=8, decimal_places=2)published_date = models.DateField()
看到了吗?Django ORM让我们可以用Python类来定义数据库结构,这样既直观又便于维护。
Django Model的核心组件
一个Django Model就像是一个数据的蓝图,包含以下核心组件:
- 字段类型(Field Types):定义数据的类型和约束
- 元数据(Meta):控制模型的行为和数据库设置
- 方法(Methods):为模型添加业务逻辑
- 管理器(Manager):控制查询和操作的入口
class Book(models.Model):# 字段定义title = models.CharField(max_length=200, verbose_name="书名")isbn = models.CharField(max_length=13, unique=True, verbose_name="ISBN")price = models.DecimalField(max_digits=8, decimal_places=2, verbose_name="价格")# 自定义方法def __str__(self):return self.titledef get_absolute_url(self):return f"/books/{self.pk}/"# 元数据class Meta:db_table = 'bookstore_book'verbose_name = "图书"verbose_name_plural = "图书"ordering = ['-published_date']
第二部分:字段类型详解与最佳实践
常用字段类型的选择原则
选择合适的字段类型就像选择合适的工具一样重要。让我们看看各种字段类型的最佳使用场景:

class User(models.Model):# 文本字段username = models.CharField(max_length=50, unique=True) # 短文本,有长度限制bio = models.TextField(blank=True) # 长文本,无长度限制# 数字字段age = models.PositiveIntegerField() # 正整数balance = models.DecimalField(max_digits=10, decimal_places=2) # 精确小数# 日期时间字段created_at = models.DateTimeField(auto_now_add=True) # 创建时自动设置updated_at = models.DateTimeField(auto_now=True) # 更新时自动修改birth_date = models.DateField(null=True, blank=True) # 可为空的日期# 布尔字段is_active = models.BooleanField(default=True)is_premium = models.BooleanField(default=False)# 选择字段GENDER_CHOICES = [('M', '男'),('F', '女'),('O', '其他'),]gender = models.CharField(max_length=1, choices=GENDER_CHOICES, default='O')
字段参数的智慧使用
每个字段都有很多参数,合理使用这些参数能让我们的模型更加健壮:
class Product(models.Model):name = models.CharField(max_length=100,verbose_name="产品名称",help_text="产品的显示名称,最多100个字符")slug = models.SlugField(unique=True,verbose_name="URL别名",help_text="用于URL的友好名称")price = models.DecimalField(max_digits=10,decimal_places=2,verbose_name="价格",validators=[MinValueValidator(0)] # 自定义验证器)status = models.CharField(max_length=20,choices=[('draft', '草稿'),('published', '已发布'),('archived', '已归档'),],default='draft',db_index=True # 为经常查询的字段添加索引)
第三部分:模型关系设计的艺术
理解三种关系类型
数据库中的关系就像现实世界中的关系一样。让我们用一个博客系统来理解:
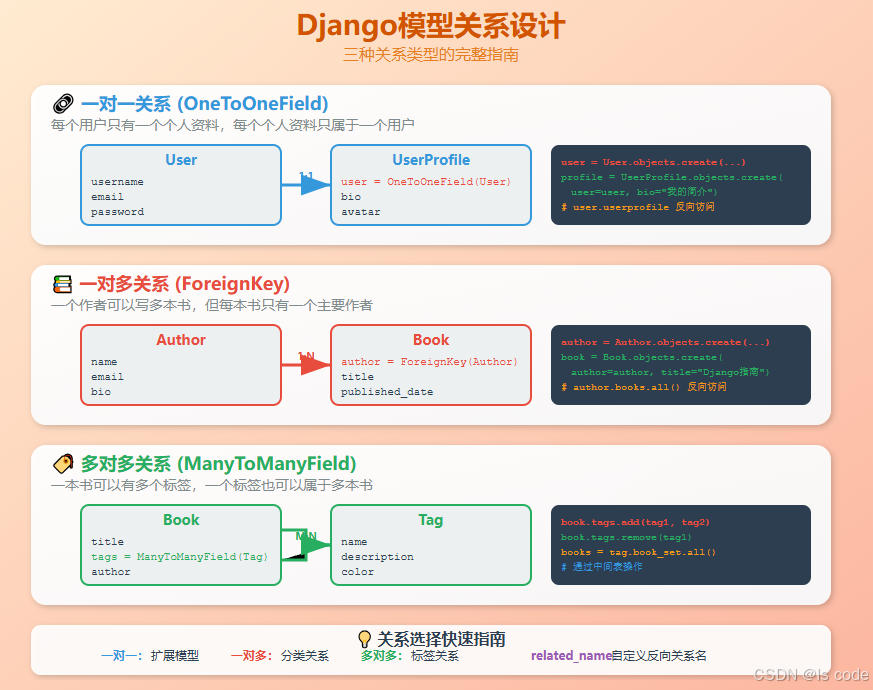
一对一关系(OneToOneField)
就像每个人只有一个身份证,每个身份证只属于一个人:
class User(models.Model):username = models.CharField(max_length=50)email = models.EmailField()class UserProfile(models.Model):user = models.OneToOneField(User, on_delete=models.CASCADE)bio = models.TextField()avatar = models.ImageField(upload_to='avatars/')phone = models.CharField(max_length=20)def __str__(self):return f"{self.user.username}的个人资料"
一对多关系(ForeignKey)
就像一个作者可以写多本书,但每本书只有一个主要作者:
class Author(models.Model):name = models.CharField(max_length=100)email = models.EmailField()class Book(models.Model):title = models.CharField(max_length=200)author = models.ForeignKey(Author, on_delete=models.CASCADE,related_name='books' # 反向关系名称)published_date = models.DateField()def __str__(self):return f"{self.title} by {self.author.name}"
多对多关系(ManyToManyField)
就像一本书可以有多个标签,一个标签也可以属于多本书:
class Tag(models.Model):name = models.CharField(max_length=50, unique=True)def __str__(self):return self.nameclass Book(models.Model):title = models.CharField(max_length=200)author = models.ForeignKey(Author, on_delete=models.CASCADE)tags = models.ManyToManyField(Tag, blank=True)def __str__(self):return self.title
复杂关系的高级用法
有时候简单的多对多关系不够用,我们需要在关系中存储额外的信息:
class Order(models.Model):user = models.ForeignKey(User, on_delete=models.CASCADE)created_at = models.DateTimeField(auto_now_add=True)total_amount = models.DecimalField(max_digits=10, decimal_places=2)class OrderItem(models.Model):order = models.ForeignKey(Order, on_delete=models.CASCADE, related_name='items')product = models.ForeignKey(Product, on_delete=models.CASCADE)quantity = models.PositiveIntegerField()unit_price = models.DecimalField(max_digits=8, decimal_places=2)class Meta:unique_together = ['order', 'product'] # 确保同一订单中产品不重复@propertydef subtotal(self):return self.quantity * self.unit_price
第四部分:查询艺术——从基础到高级
QuerySet的魔法世界
Django的QuerySet就像是一个智能的数据库查询构建器,它具有延迟执行的特性:
# 这些操作都不会立即执行数据库查询
books = Book.objects.all() # 获取所有书籍
tech_books = books.filter(category='Technology') # 筛选科技类书籍
recent_books = tech_books.filter(published_date__gte='2020-01-01') # 筛选2020年后出版的# 只有在需要数据时才会执行查询
for book in recent_books: # 这时才执行数据库查询print(book.title)
高效查询的黄金法则

1. 使用select_related优化一对一和外键查询
# 低效的查询(N+1问题)
books = Book.objects.all()
for book in books:print(f"{book.title} by {book.author.name}") # 每次循环都查询数据库# 高效的查询
books = Book.objects.select_related('author').all()
for book in books:print(f"{book.title} by {book.author.name}") # 只查询一次数据库
2. 使用prefetch_related优化多对多和反向外键查询
# 低效的查询
authors = Author.objects.all()
for author in authors:books = author.books.all() # 每个作者都会产生一次查询print(f"{author.name}: {books.count()} books")# 高效的查询
authors = Author.objects.prefetch_related('books').all()
for author in authors:books = author.books.all() # 使用预加载的数据,不产生额外查询print(f"{author.name}: {books.count()} books")
3. 只获取需要的字段
# 获取所有字段(可能包含大量不需要的数据)
books = Book.objects.all()# 只获取需要的字段
books = Book.objects.values('title', 'price').all()# 或者排除不需要的字段
books = Book.objects.defer('content', 'description').all()
复杂查询的构建技巧
Q对象:构建复杂的查询条件
from django.db.models import Q# 查找标题包含"Python"或者作者名包含"Smith"的书籍
books = Book.objects.filter(Q(title__icontains='Python') | Q(author__name__icontains='Smith')
)# 复杂的条件组合
books = Book.objects.filter(Q(published_date__gte='2020-01-01') & (Q(price__lt=50) | Q(rating__gte=4.5))
)
F对象:字段之间的比较
from django.db.models import F# 查找价格低于平均价格的书籍
books = Book.objects.filter(price__lt=F('average_price'))# 更新所有书籍的价格(增加10%)
Book.objects.update(price=F('price') * 1.1)
聚合查询:统计分析的利器
from django.db.models import Count, Sum, Avg, Max, Min# 获取每个作者的书籍数量
authors_with_book_count = Author.objects.annotate(book_count=Count('books')
).filter(book_count__gte=2)# 计算每个类别的平均价格
category_stats = Book.objects.values('category').annotate(avg_price=Avg('price'),total_books=Count('id'),max_price=Max('price')
)# 获取总销售额
total_sales = Order.objects.aggregate(total=Sum('total_amount'),average=Avg('total_amount')
)
第五部分:性能优化实战
数据库查询性能诊断
Django提供了强大的调试工具来帮助我们识别性能问题:
# settings.py 中启用查询日志
LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'console': {'class': 'logging.StreamHandler',},},'loggers': {'django.db.backends': {'handlers': ['console'],'level': 'DEBUG',},},
}# 使用django-debug-toolbar
from django.db import connectiondef analyze_queries():# 执行一些数据库操作books = Book.objects.select_related('author').all()# 查看执行的SQL查询for query in connection.queries:print(f"Time: {query['time']}")print(f"SQL: {query['sql']}")
缓存策略的应用
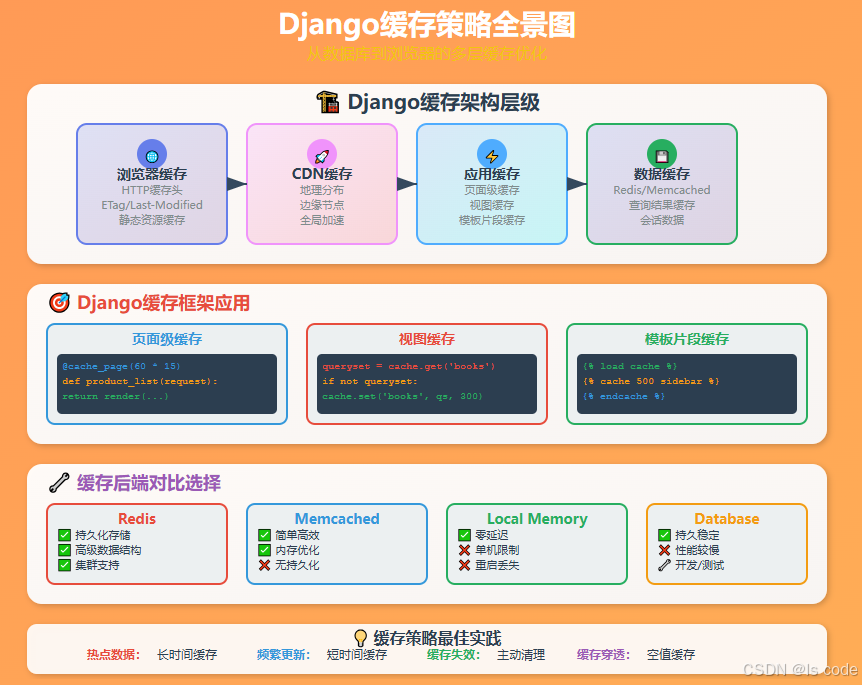
from django.core.cache import cache
from django.views.decorators.cache import cache_page
from django.utils.decorators import method_decoratorclass BookListView(ListView):model = Booktemplate_name = 'books/list.html'def get_queryset(self):# 缓存热门书籍查询结果cache_key = 'popular_books'queryset = cache.get(cache_key)if queryset is None:queryset = Book.objects.filter(rating__gte=4.0).select_related('author').order_by('-published_date')[:20]cache.set(cache_key, queryset, 300) # 缓存5分钟return queryset# 使用装饰器缓存整个视图
@cache_page(60 * 15) # 缓存15分钟
def book_detail(request, book_id):book = get_object_or_404(Book, id=book_id)return render(request, 'books/detail.html', {'book': book})
数据库索引优化
class Book(models.Model):title = models.CharField(max_length=200, db_index=True) # 单字段索引isbn = models.CharField(max_length=13, unique=True) # 唯一索引category = models.CharField(max_length=50)published_date = models.DateField()class Meta:# 复合索引indexes = [models.Index(fields=['category', 'published_date']),models.Index(fields=['-published_date', 'rating']),]# 唯一约束unique_together = [['title', 'author']]
第六部分:高级特性与最佳实践
自定义Manager和QuerySet
class PublishedBookManager(models.Manager):def get_queryset(self):return super().get_queryset().filter(status='published')def by_category(self, category):return self.get_queryset().filter(category=category)def recent(self, days=30):from django.utils import timezonefrom datetime import timedeltasince = timezone.now() - timedelta(days=days)return self.get_queryset().filter(published_date__gte=since)class Book(models.Model):title = models.CharField(max_length=200)status = models.CharField(max_length=20, default='draft')category = models.CharField(max_length=50)published_date = models.DateField()# 默认managerobjects = models.Manager()# 自定义managerpublished = PublishedBookManager()def __str__(self):return self.title# 使用自定义manager
recent_tech_books = Book.published.by_category('Technology').recent(7)
模型验证与清理
from django.core.exceptions import ValidationError
from django.core.validators import MinValueValidator, MaxValueValidatorclass Book(models.Model):title = models.CharField(max_length=200)price = models.DecimalField(max_digits=8, decimal_places=2,validators=[MinValueValidator(0), MaxValueValidator(1000)])rating = models.FloatField(validators=[MinValueValidator(0), MaxValueValidator(5)])def clean(self):# 自定义验证逻辑if self.price and self.rating:if self.price > 100 and self.rating < 3.0:raise ValidationError('高价书籍的评分不能低于3.0')def save(self, *args, **kwargs):# 保存前的数据处理self.title = self.title.strip().title()self.full_clean() # 执行验证super().save(*args, **kwargs)
信号的妙用
from django.db.models.signals import pre_save, post_save, post_delete
from django.dispatch import receiver
from django.utils.text import slugify@receiver(pre_save, sender=Book)
def generate_slug(sender, instance, **kwargs):"""自动生成URL友好的slug"""if not instance.slug:instance.slug = slugify(instance.title)@receiver(post_save, sender=Order)
def update_inventory(sender, instance, created, **kwargs):"""订单创建后更新库存"""if created:for item in instance.items.all():product = item.productproduct.stock -= item.quantityproduct.save()@receiver(post_delete, sender=Book)
def cleanup_files(sender, instance, **kwargs):"""删除书籍时清理相关文件"""if instance.cover_image:instance.cover_image.delete(save=False)
第七部分:实战案例——构建博客系统
让我们通过一个完整的博客系统来综合运用Django ORM的各种特性:
from django.contrib.auth.models import User
from django.urls import reverse
from taggit.managers import TaggableManagerclass Category(models.Model):name = models.CharField(max_length=50, unique=True)slug = models.SlugField(unique=True)description = models.TextField(blank=True)class Meta:verbose_name_plural = "Categories"def __str__(self):return self.nameclass PublishedPostManager(models.Manager):def get_queryset(self):return super().get_queryset().filter(status='published')class Post(models.Model):STATUS_CHOICES = [('draft', '草稿'),('published', '已发布'),('archived', '已归档'),]title = models.CharField(max_length=200, verbose_name="标题")slug = models.SlugField(unique=True, verbose_name="URL别名")author = models.ForeignKey(User, on_delete=models.CASCADE, related_name='posts',verbose_name="作者")category = models.ForeignKey(Category, on_delete=models.SET_NULL, null=True,related_name='posts',verbose_name="分类")content = models.TextField(verbose_name="内容")excerpt = models.TextField(max_length=300, blank=True, verbose_name="摘要")featured_image = models.ImageField(upload_to='posts/', blank=True, verbose_name="特色图片")status = models.CharField(max_length=20, choices=STATUS_CHOICES, default='draft',db_index=True,verbose_name="状态")# 时间字段created_at = models.DateTimeField(auto_now_add=True)updated_at = models.DateTimeField(auto_now=True)published_at = models.DateTimeField(null=True, blank=True)# 统计字段view_count = models.PositiveIntegerField(default=0)like_count = models.PositiveIntegerField(default=0)# 标签支持tags = TaggableManager(blank=True)# Managersobjects = models.Manager()published = PublishedPostManager()class Meta:ordering = ['-published_at', '-created_at']indexes = [models.Index(fields=['-published_at']),models.Index(fields=['status', '-published_at']),models.Index(fields=['category', '-published_at']),]def __str__(self):return self.titledef get_absolute_url(self):return reverse('post_detail', kwargs={'slug': self.slug})def save(self, *args, **kwargs):# 自动生成摘要if not self.excerpt and self.content:self.excerpt = self.content[:297] + '...'# 发布时设置发布时间if self.status == 'published' and not self.published_at:from django.utils import timezoneself.published_at = timezone.now()super().save(*args, **kwargs)def get_similar_posts(self, count=5):"""获取相似文章"""return Post.published.filter(category=self.category).exclude(id=self.id)[:count]class Comment(models.Model):post = models.ForeignKey(Post, on_delete=models.CASCADE, related_name='comments')author_name = models.CharField(max_length=50)author_email = models.EmailField()content = models.TextField()created_at = models.DateTimeField(auto_now_add=True)is_approved = models.BooleanField(default=False)class Meta:ordering = ['created_at']def __str__(self):return f'{self.author_name} on {self.post.title}'
高效的视图查询
from django.shortcuts import get_object_or_404
from django.core.paginator import Paginatordef post_list(request, category_slug=None):# 基础查询集,使用select_related优化posts = Post.published.select_related('author', 'category').prefetch_related('tags')# 分类筛选category = Noneif category_slug:category = get_object_or_404(Category, slug=category_slug)posts = posts.filter(category=category)# 搜索功能search_query = request.GET.get('q')if search_query:posts = posts.filter(Q(title__icontains=search_query) |Q(content__icontains=search_query) |Q(tags__name__icontains=search_query)).distinct()# 分页paginator = Paginator(posts, 10)page = request.GET.get('page')posts = paginator.get_page(page)return render(request, 'blog/post_list.html', {'posts': posts,'category': category,'search_query': search_query,})def post_detail(request, slug):# 使用select_related避免N+1查询post = get_object_or_404(Post.published.select_related('author', 'category'),slug=slug)# 增加浏览量Post.objects.filter(id=post.id).update(view_count=F('view_count') + 1)# 获取评论comments = post.comments.filter(is_approved=True).select_related('author')# 获取相似文章similar_posts = post.get_similar_posts()return render(request, 'blog/post_detail.html', {'post': post,'comments': comments,'similar_posts': similar_posts,})
第八部分:常见陷阱与解决方案
N+1查询问题
这是Django ORM中最常见的性能问题:
# 问题代码:每次循环都会产生一次查询
posts = Post.objects.all()
for post in posts:print(f"{post.title} by {post.author.username}") # N+1查询!# 解决方案:使用select_related
posts = Post.objects.select_related('author').all()
for post in posts:print(f"{post.title} by {post.author.username}") # 只有一次查询
大量数据的内存问题
# 问题代码:会将所有数据加载到内存
all_posts = Post.objects.all()
for post in all_posts:process_post(post)# 解决方案1:使用iterator()
for post in Post.objects.iterator():process_post(post)# 解决方案2:分批处理
from django.core.paginator import Paginatorpaginator = Paginator(Post.objects.all(), 1000)
for page_num in paginator.page_range:page = paginator.page(page_num)for post in page:process_post(post)
事务管理最佳实践
from django.db import transaction@transaction.atomic
def create_order_with_items(user, items_data):"""创建订单和订单项的原子操作"""order = Order.objects.create(user=user)for item_data in items_data:OrderItem.objects.create(order=order,product=item_data['product'],quantity=item_data['quantity'],unit_price=item_data['unit_price'])# 更新库存product = item_data['product']product.stock -= item_data['quantity']product.save()return order# 手动事务控制
def complex_operation():with transaction.atomic():# 创建保存点sid = transaction.savepoint()try:# 执行一些操作risky_operation()except Exception:# 回滚到保存点transaction.savepoint_rollback(sid)raiseelse:# 释放保存点transaction.savepoint_commit(sid)
第九部分:测试与调试
模型测试的最佳实践
from django.test import TestCase
from django.core.exceptions import ValidationError
from django.db import IntegrityErrorclass BookModelTest(TestCase):def setUp(self):self.author = Author.objects.create(name="Test Author",email="test@example.com")def test_book_creation(self):"""测试书籍创建"""book = Book.objects.create(title="Test Book",author=self.author,price=29.99)self.assertEqual(book.title, "Test Book")self.assertEqual(book.author, self.author)self.assertEqual(str(book), "Test Book")def test_book_validation(self):"""测试书籍验证"""with self.assertRaises(ValidationError):book = Book(title="Expensive Bad Book",author=self.author,price=200,rating=1.0)book.full_clean()def test_book_manager(self):"""测试自定义管理器"""# 创建测试数据Book.objects.create(title="Published Book",author=self.author,status='published')Book.objects.create(title="Draft Book",author=self.author,status='draft')# 测试自定义管理器self.assertEqual(Book.published.count(), 1)self.assertEqual(Book.objects.count(), 2)
性能测试
from django.test import TestCase
from django.test.utils import override_settings
from django.db import connectionclass QueryPerformanceTest(TestCase):def setUp(self):# 创建测试数据for i in range(100):author = Author.objects.create(name=f"Author {i}")for j in range(10):Book.objects.create(title=f"Book {i}-{j}",author=author)def test_query_efficiency(self):"""测试查询效率"""with self.assertNumQueries(1):# 应该只产生一次查询books = list(Book.objects.select_related('author').all()[:10])with self.assertNumQueries(2):# 应该产生两次查询(主查询 + prefetch)authors = list(Author.objects.prefetch_related('books').all()[:5])
总结:Django ORM的最佳实践清单
通过本文的深入学习,我们掌握了Django ORM的核心概念和高级用法。让我用一个清单来总结最重要的最佳实践:
📋 模型设计清单
- ✅ 选择合适的字段类型和参数
- ✅ 合理设计模型关系和反向关系名称
- ✅ 为经常查询的字段添加索引
- ✅ 使用模型验证确保数据完整性
- ✅ 编写清晰的
__str__方法
📋 查询优化清单
- ✅ 使用
select_related优化一对一和外键查询 - ✅ 使用
prefetch_related优化多对多和反向外键查询 - ✅ 只获取需要的字段(
values、defer、only) - ✅ 使用
F对象进行字段级操作 - ✅ 避免在循环中执行查询
📋 性能监控清单
- ✅ 启用查询日志监控SQL执行
- ✅ 使用django-debug-toolbar进行开发调试
- ✅ 为大量数据使用
iterator()或分页 - ✅ 适当使用缓存策略
- ✅ 编写性能测试用例
Django ORM是一个强大而优雅的工具,掌握了这些概念和技巧,你就能够构建高效、可维护的Django应用。记住,最好的代码不仅要能工作,还要能让团队成员轻松理解和维护。
继续实践,持续优化,你会发现Django ORM能够成为你构建Web应用的得力助手!
参考资料与进一步学习:
- Django官方文档 - Models
- Django官方文档 - QuerySets
- Django最佳实践指南
- Two Scoops of Django
- High Performance Django