1.前言
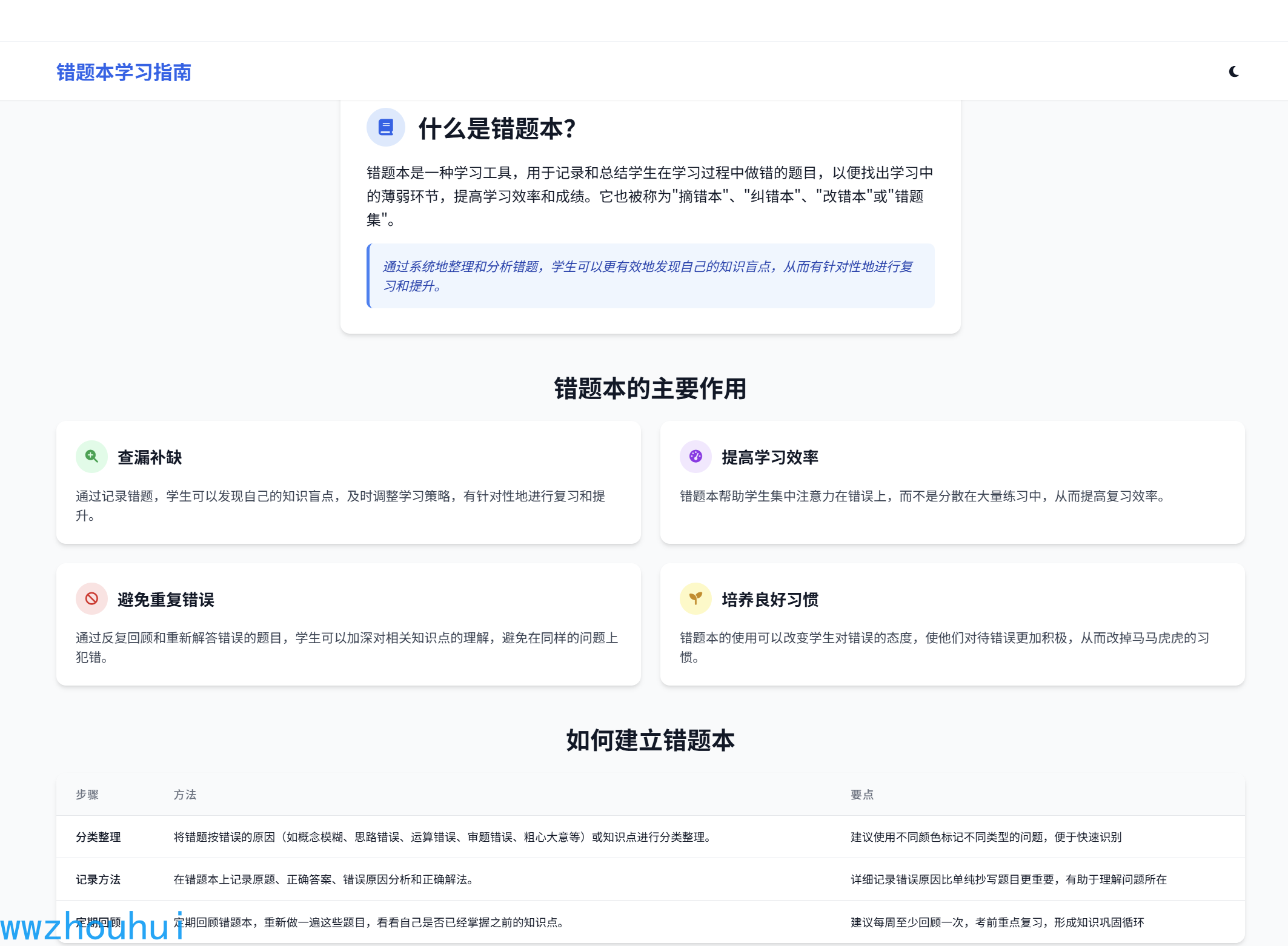
错题本是一种学习工具,用于记录和总结学生在学习过程中做错的题目,以便找出学习中的薄弱环节,提高学习效率和成绩。
一下是错题本定义、作用、建立方法、使用技巧等内容。
-
定义:错题本是指中小学学生在学习过程中,把自己做过的作业、习题、试卷中的错题整理成册,便于找出自己学习中的薄弱环节,使得学习重点突出、学习更加有针对性、进而提高学习效率和学习成绩的作业本。错题本也叫“摘错本”、“纠错本”、“改错本”或“错题集”。
-
作用:
- 查漏补缺:通过记录错题,学生可以发现自己的知识盲点,及时调整学习策略,有针对性地进行复习和提升。
- 提高学习效率:错题本帮助学生集中注意力在错误上,而不是分散在大量练习中,从而提高复习效率。
- 避免重复错误:通过反复回顾和重新解答错误的题目,学生可以加深对相关知识点的理解,避免在同样的问题上犯错。
- 培养良好的学习习惯:错题本的使用可以改变学生对错误的态度,使他们对待错误更加积极,从而改掉马马虎的习惯。
-
建立方法:
- 分类整理:将错题按错误的原因(如概念模糊、思路错误、运算错误、审题错误、粗心大意等)或知识点进行分类整理。
- 记录方法:在错题本上记录原题、正确答案、错误原因分析和正确解法。
- 定期回顾:定期回顾错题本,重新做一遍这些题目,看看自己是否已经掌握之前的知识点,这样可以有效地巩固知识,防止再犯同样的错误。
-
使用技巧:
- 及时整理:错题本应在做完题后立即整理,这样可以加强记忆。
- 注重效率:不要过于追求错题本的美观,而应该注重效率,用最短的时间做好错题本。
- 相互交流:通过与同学交流错题本,可以借鉴彼此的优点,共同提高学习效果

我们通过错题本记录,分析、复习 差缺补漏 从而帮助学生提高成绩。今天就带大家使用dify工作流来实现一个中小学数学错题本功能。
上期文章我们实现了错题本的收集整理,本期文章我们基于上期功能的基础上实现同类型题生成,从而帮助我们通过错题训练强化学习,补缺补差。dify案例分享-用 Dify 工作流 搭建数学错题本,考试错题秒变提分神器-错题收集篇
我们先看一下制作好的工作流大概是什么样子:
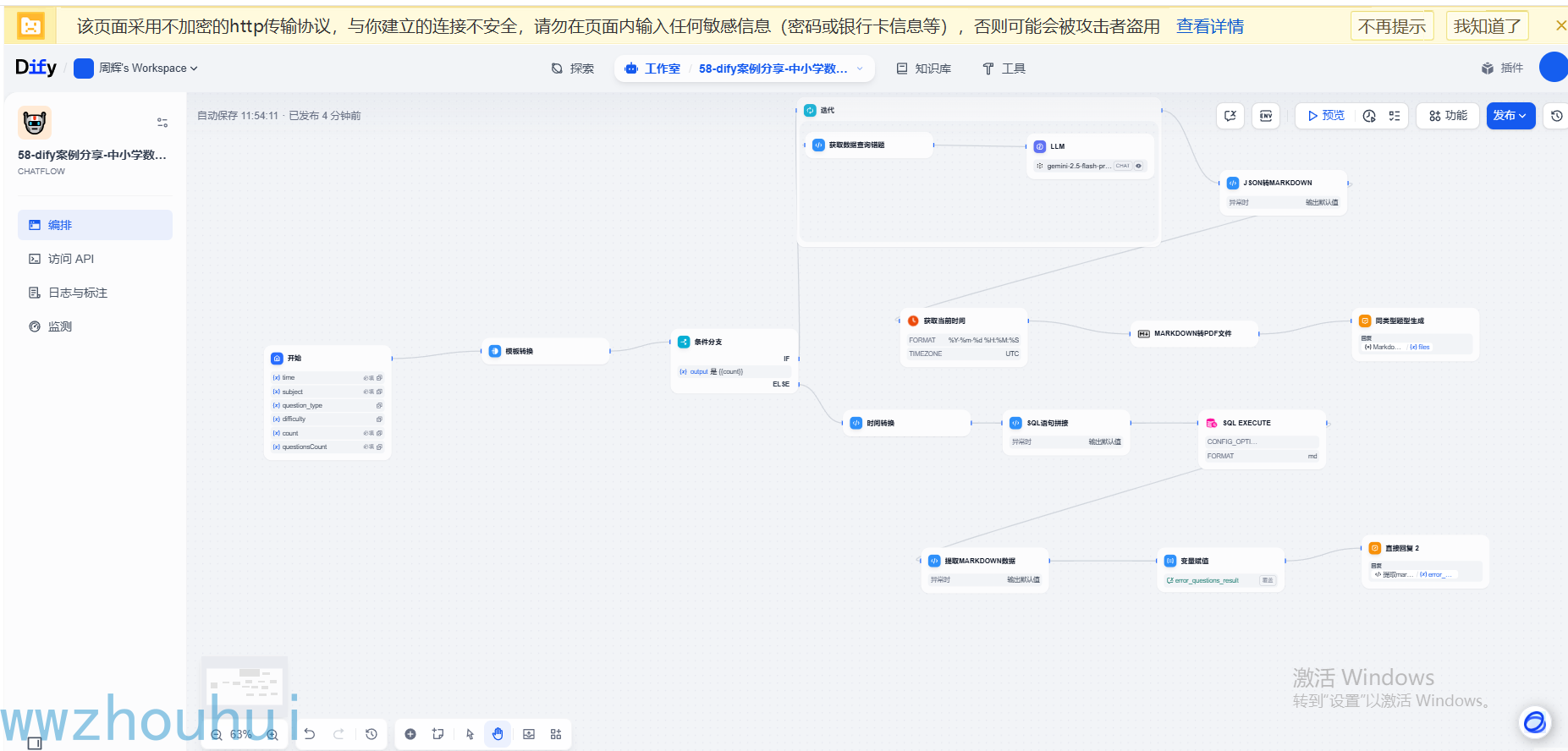
以上工作流主要实现用户可以根据错题本生成的时间、科目、题目类型、难度等级(1-5)、查询题目数量、生成同类型题目的数据 等输入参数通过上篇文章录入的错题本信息进行查询和检索,检索到的错题本信息可以通过大语言模型生成1条和多条同类型题目提供学生或者家长生成PDF文件下载并打印。
下面看一下实现的效果:
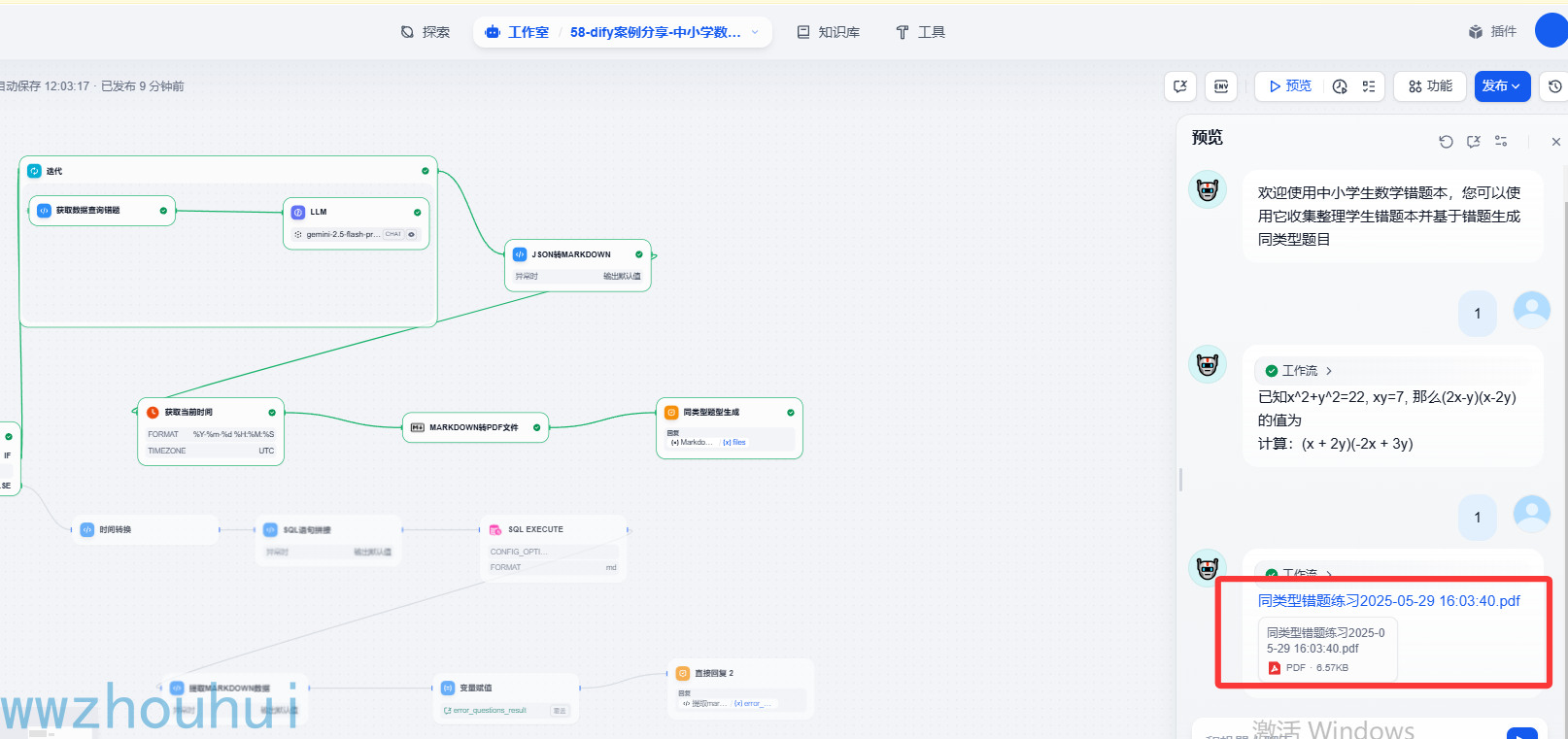
我们下载pdf

那么这个工作流是如何实现的呢?话不多说下面带大家手把手搭建这个工作流。
如果大家懒的看文章,我们这里也提供的一个文章的博客,感兴趣小伙伴也可以先听一下这个博客
添加链接描述
2.工作流的制作
这个工作流我们首先给大家拆解一下,它用到了开始节点、问题分类器、模板转换、条件分支、时间转换(代码处理)、sql语句拼接(代码处理)、SQL Execute(第三方工具)、提取markdown数据(代码处理)、变量赋值、直接回复 、迭代、获取数据查询错题(代码处理)、LLM、JSON转markdown(代码处理)、获取当前时间(第三方工具)、Markdown转PDF文件(第三方工具)等组成。
Markdown转PDF文件可以看我前期文章《dify案例分享- 用 Dify 搭建智能合同评审工作流,10 分钟搞定风险排查》
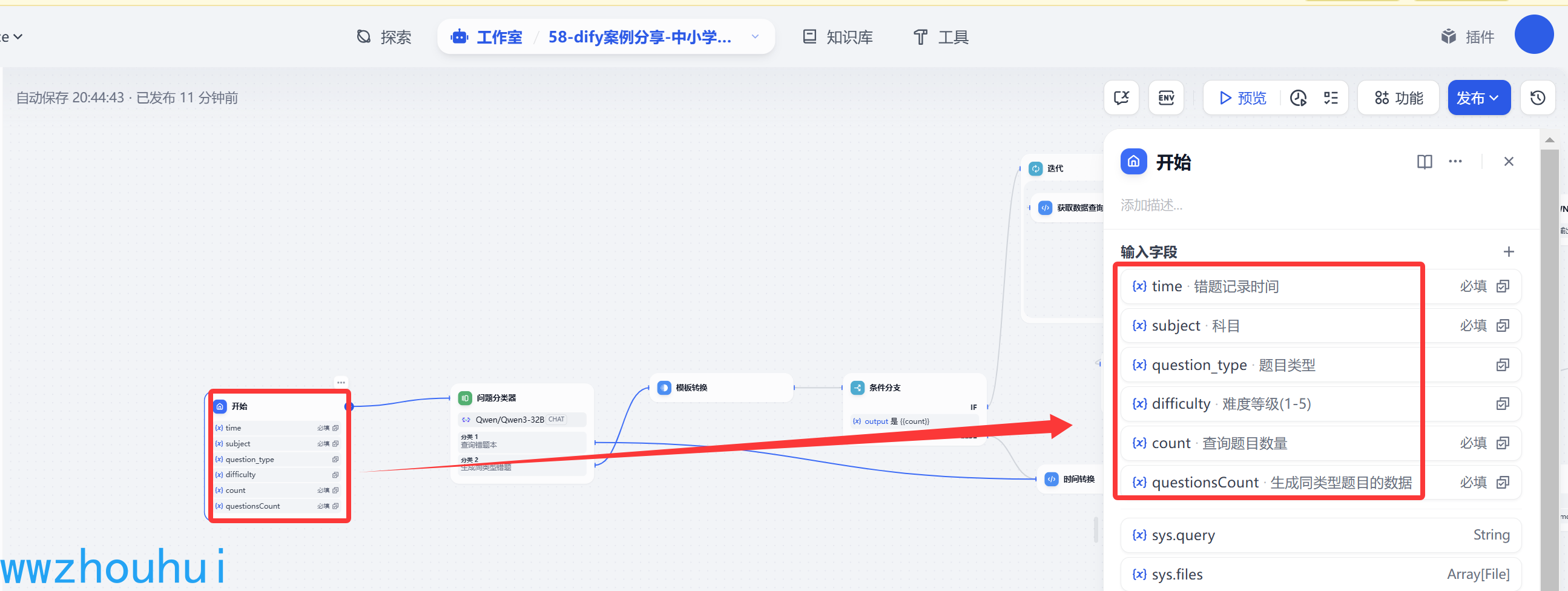
开始
这个开始节点我们这块是需要设置一些查询条件,所以它的输入条件比较多主要分为2类。1类是必须输入项目,1类是可选项目。
有错题记录时间(今天、最近一周、最近一个月、全部)、有科目(数学、语文、英语、物理、化学、道德与法制、历史、地理、生物)
题目类型(选择题、填空题、判断题、问题题)、难度等级(1-5)、查询题目数量、生成同类型题目的数据。目前方便用户使用我们都设置成下拉选项。
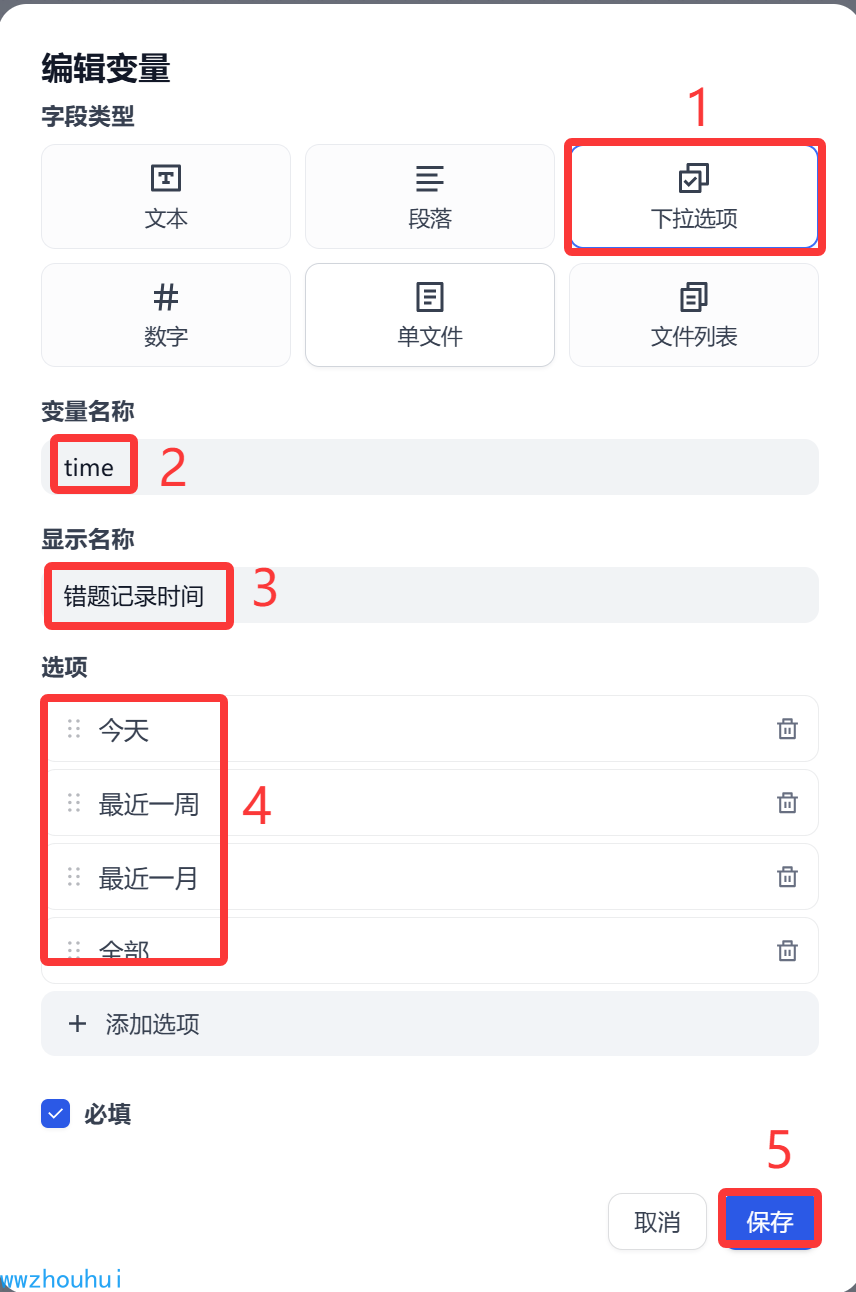
这里其他选项我们就不在这里一一介绍了。
问题分类器
问题分类器主要目的是为了区分用户是查询错题,还是基于已经查询到的错题生成同类题型。 这里我们用到魔搭社区提供的qwen3-32B模型。问题分类器也很简单,2个问题(查询错题本、生成同类型错题)
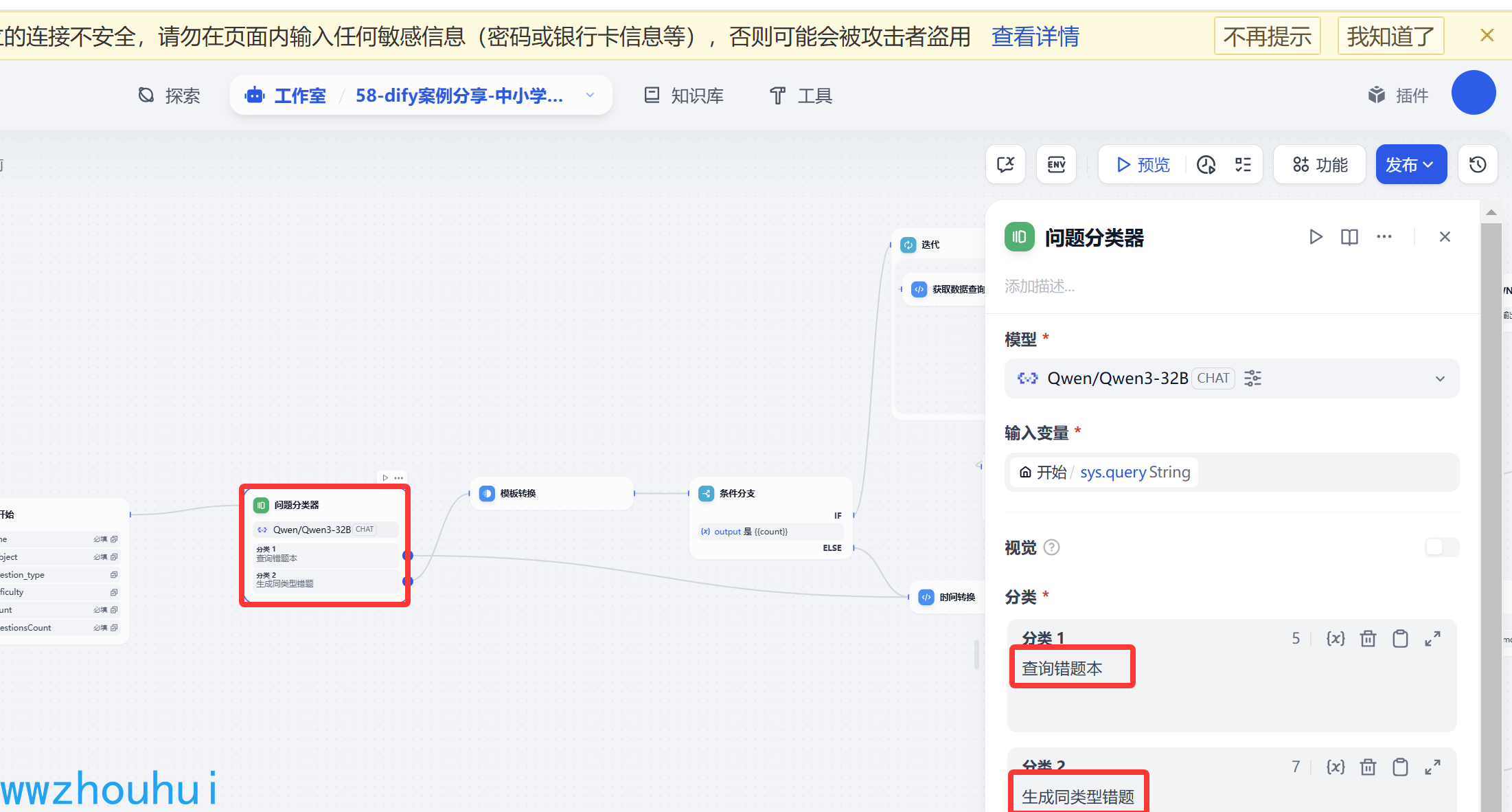
如果第一次用户输入查询错题本,流程会走到 查询错题的分支上。
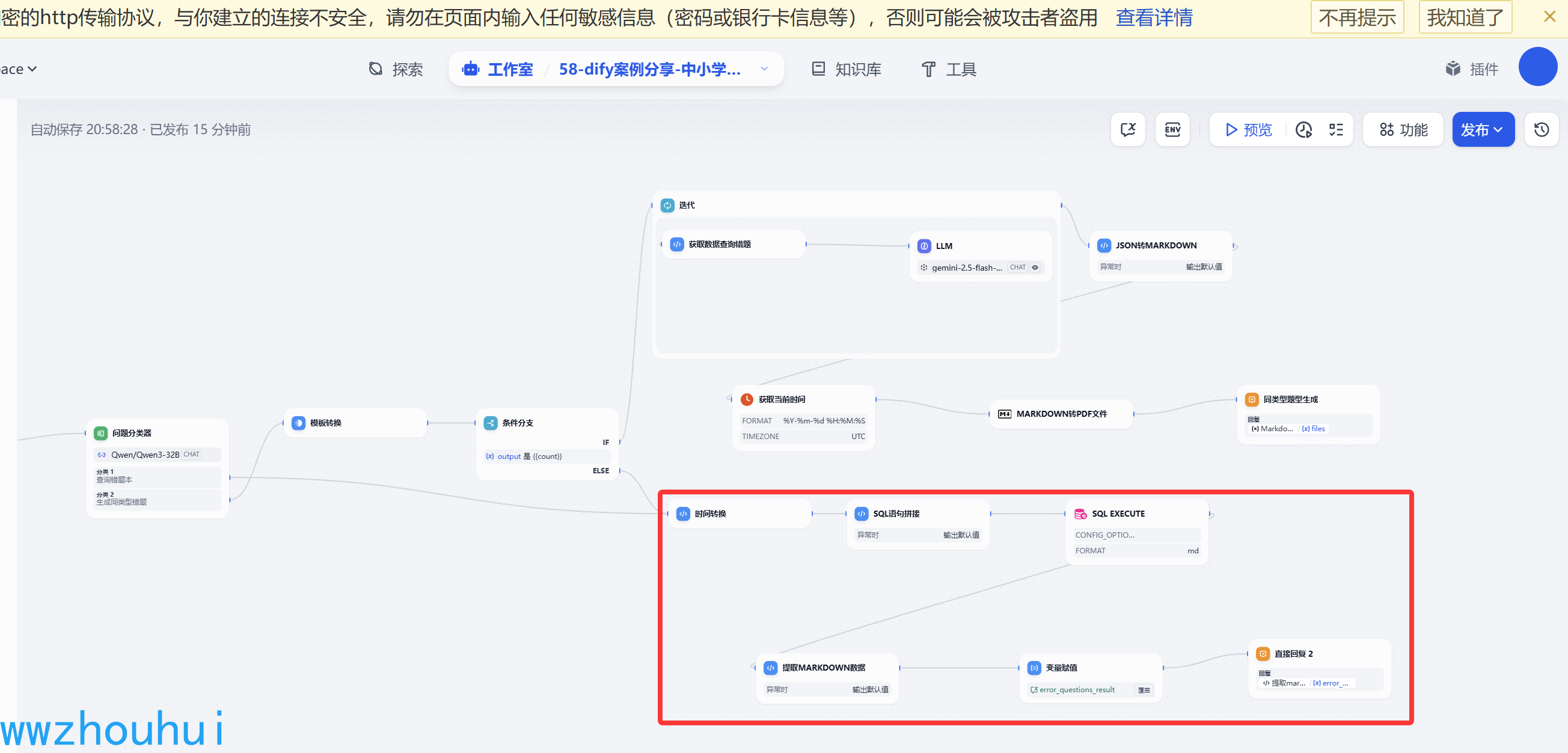
接下来我们介绍上面截图的流程分支。
代码执行(时间转换)
这个时间转换,主要的目的是把用户输入信息(今天、最近一周、最近一个月、全部)转换成数据库查询需要的日期格式时间 比如2025-05-29 00:00:00 。目前dify不提供时间控件,所以我们必须要通过其他方式实现这个时间转换。
代码如下:
import json
from datetime import datetime, timedeltadef main(arg1: str) -> dict:"""根据输入的时间范围参数生成对应的开始时间和结束时间。:param arg1: 时间范围参数,可选值为 "今天", "最近一周", "最近一月", "全部":return: 包含开始时间和结束时间的字典,如果参数无效则返回错误信息"""try:today = datetime.now()if arg1 == "今天":start_time = today.replace(hour=0, minute=0, second=0, microsecond=0)end_time = today.replace(hour=23, minute=59, second=59, microsecond=999999)elif arg1 == "最近一周":end_time = today.replace(hour=23, minute=59, second=59, microsecond=999999)start_time = end_time - timedelta(days=6) # 包含今天共7天start_time = start_time.replace(hour=0, minute=0, second=0, microsecond=0)elif arg1 == "最近一月":end_time = today.replace(hour=23, minute=59, second=59, microsecond=999999)# 计算一个月前的日期month = today.month - 1 or 12year = today.year - (today.month == 1)# 获取该月的最后一天last_day = 31while True:try:start_time = datetime(year, month, last_day)breakexcept ValueError:last_day -= 1start_time = start_time.replace(hour=0, minute=0, second=0, microsecond=0)elif arg1 == "全部":start_time = datetime(2000, 1, 1, 0, 0, 0)end_time = datetime(2035, 1, 1, 0, 0, 0) # 修改结束时间为2035-01-01else:raise ValueError("无效的时间范围参数")# 格式化时间为字符串start_time_str = start_time.strftime("%Y-%m-%d %H:%M:%S")end_time_str = end_time.strftime("%Y-%m-%d %H:%M:%S")return {"start_time": start_time_str, "end_time": end_time_str}except ValueError as e:return {"error": f"参数错误: {e}"}except Exception as e:return {"error": f"发生未知错误: {e}"}
输入的参数 是开始节点 time,输出参数有2个,分别为end_time、start_time
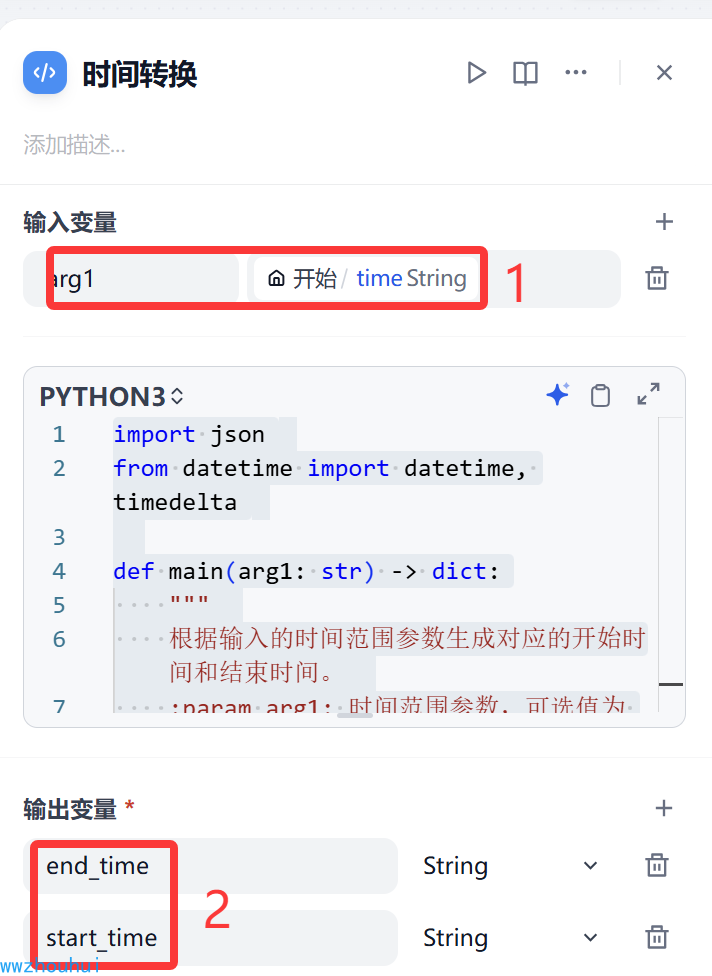
代码执行(sql语句拼接)
后面为了查询数据库,所以我们使用python代码实现一个SQL查询语句的拼接。
代码如下:
def main(subject: str, count: str = None, offset: str = "0", question_type: str = None, difficulty: str = None, start_time: str = None, end_time: str = None) -> dict:"""动态生成错误问题表的SQL查询语句:param subject: 学科(必填):param count: 问题数量(选填,默认为None表示不限制):param offset: 偏移量(选填,默认为0):param question_type: 题目类型(选填):param difficulty: 难度等级(选填):param start_time: 开始时间(选填):param end_time: 结束时间(选填):return: 包含生成的SQL查询字符串或错误信息的字典"""try:# 验证必填参数if not subject:raise ValueError("subject参数是必需的")# 内部SQL转义函数(合并进main)def _escape_sql(value):"""防止SQL注入,简单处理单引号"""if value is None:return Noneif isinstance(value, str):return value.replace("'", "''")return str(value)# 初始化查询组件conditions = [f"subject = '{_escape_sql(subject)}'"]# 添加可选参数条件if question_type:conditions.append(f"question_type = '{_escape_sql(question_type)}'")if difficulty:conditions.append(f"difficulty = '{_escape_sql(difficulty)}'")# 处理时间范围条件if start_time and end_time:conditions.append(f"created_at BETWEEN '{_escape_sql(start_time)}' AND '{_escape_sql(end_time)}'")elif start_time:conditions.append(f"created_at >= '{_escape_sql(start_time)}'")elif end_time:conditions.append(f"created_at <= '{_escape_sql(end_time)}'")# 构建完整SQLsql = f"SELECT question_text, `subject`,question_type,created_at FROM error_questions WHERE {' AND '.join(conditions)} ORDER BY created_at DESC"# 添加LIMIT和OFFSETif count:# 验证count是否为正整数if not count.isdigit() or int(count) <= 0:raise ValueError("count必须是正整数")sql += f" LIMIT {count}"# 验证offset是否为非负整数if not offset.isdigit():raise ValueError("offset必须是非负整数")sql += f" OFFSET {offset}"return {"query": sql}except ValueError as e:return {"error": f"参数错误: {str(e)}"}except Exception as e:return {"error": f"发生未知错误: {str(e)}"}
输入的参数 比较多一点,就是开始节点中我们让用户输入的信息。
subject、question_type、difficulty、start_time、end_time、count、offset
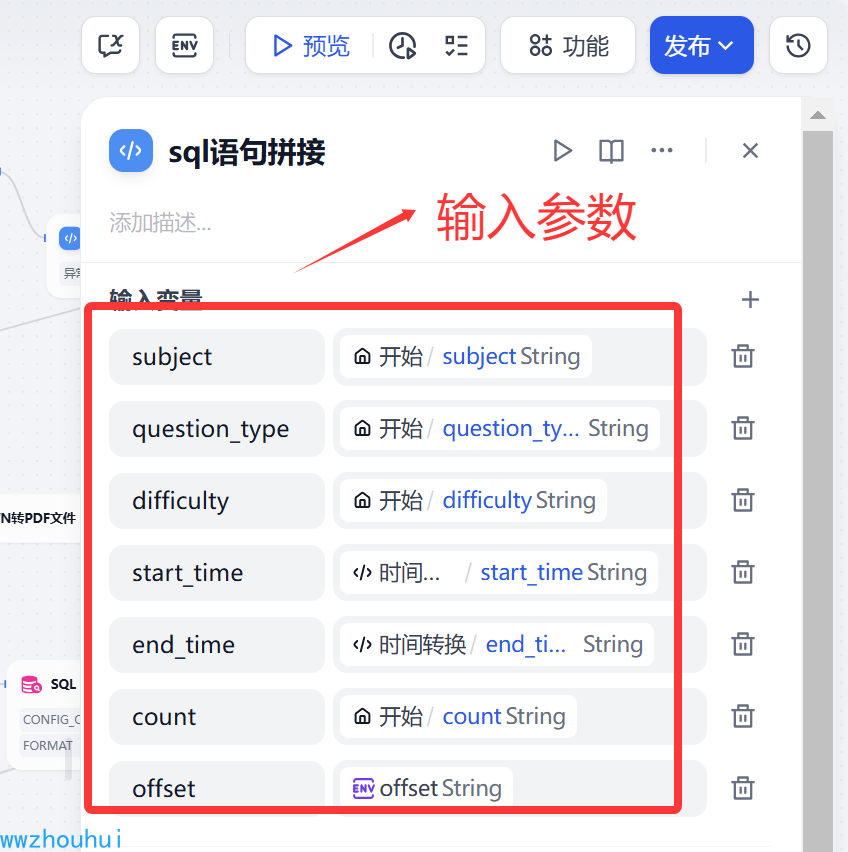
返回参数query, 主要的目的是生成一个SQL 语句。
这里我们在env 环境变量里面设置了一个SQL 查询的分页起止 值 0
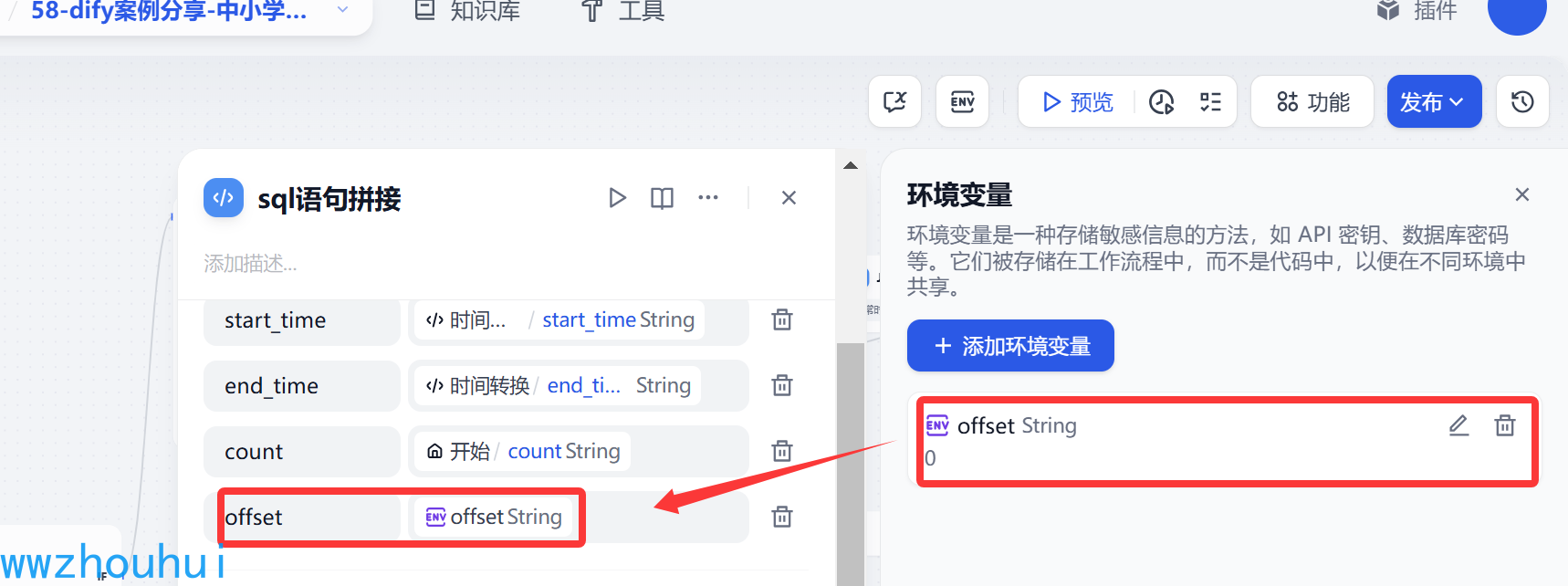
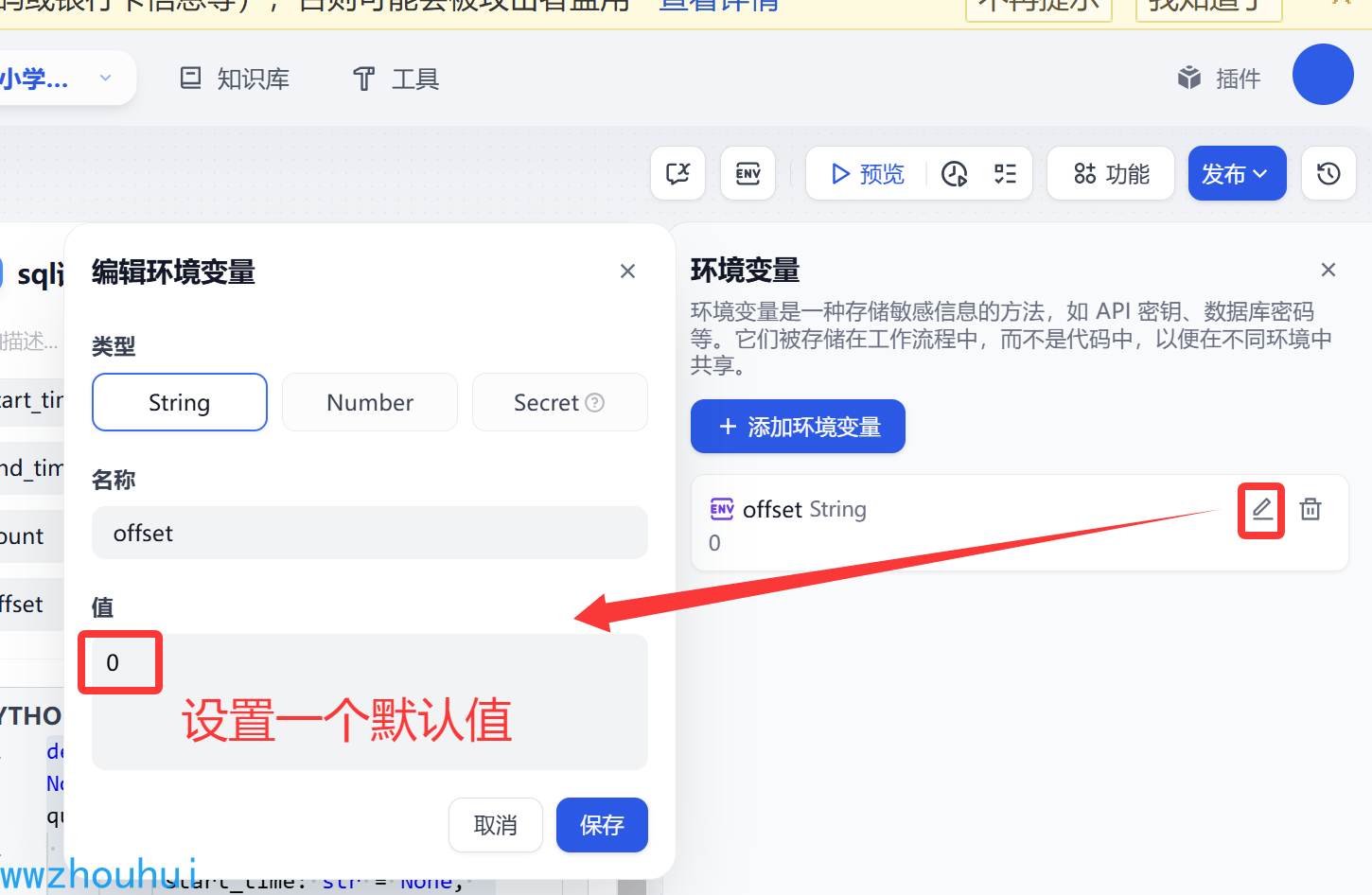
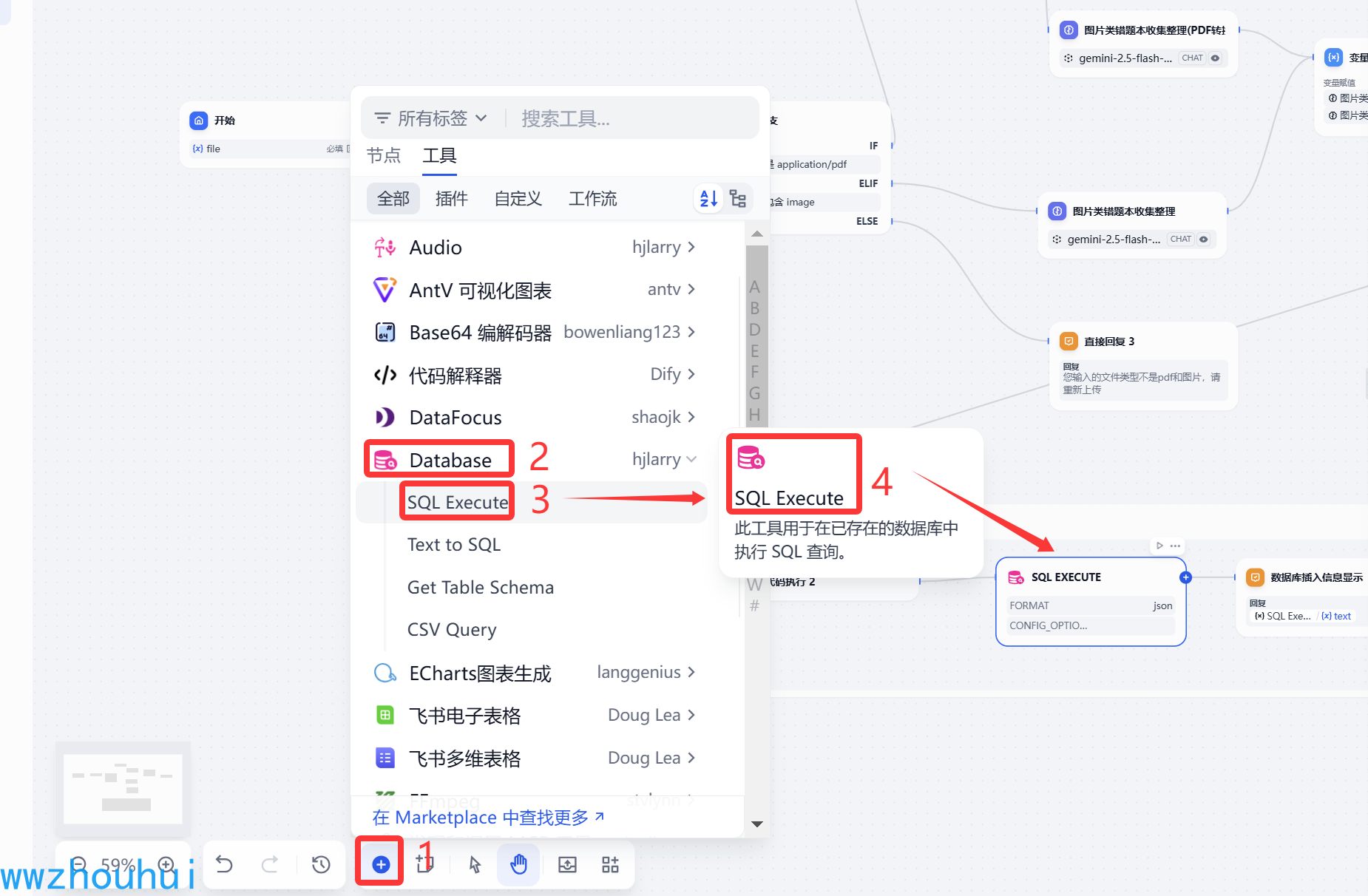
SQL Execute
这里我们需要用的database 第三方组件。
这里我们借用上期文章截图。
输入变量 这里就比较简单了,直接填写上个节点返回
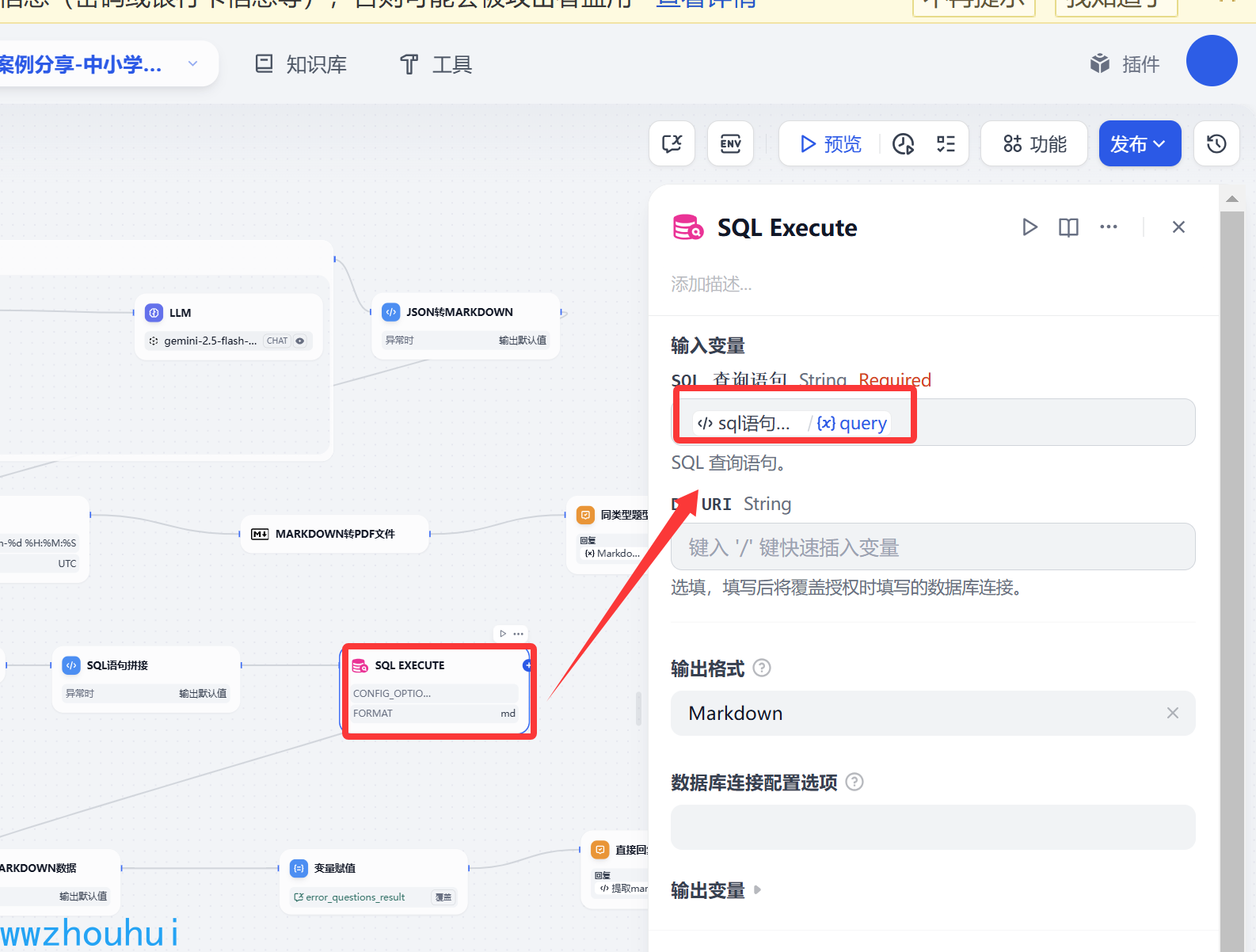
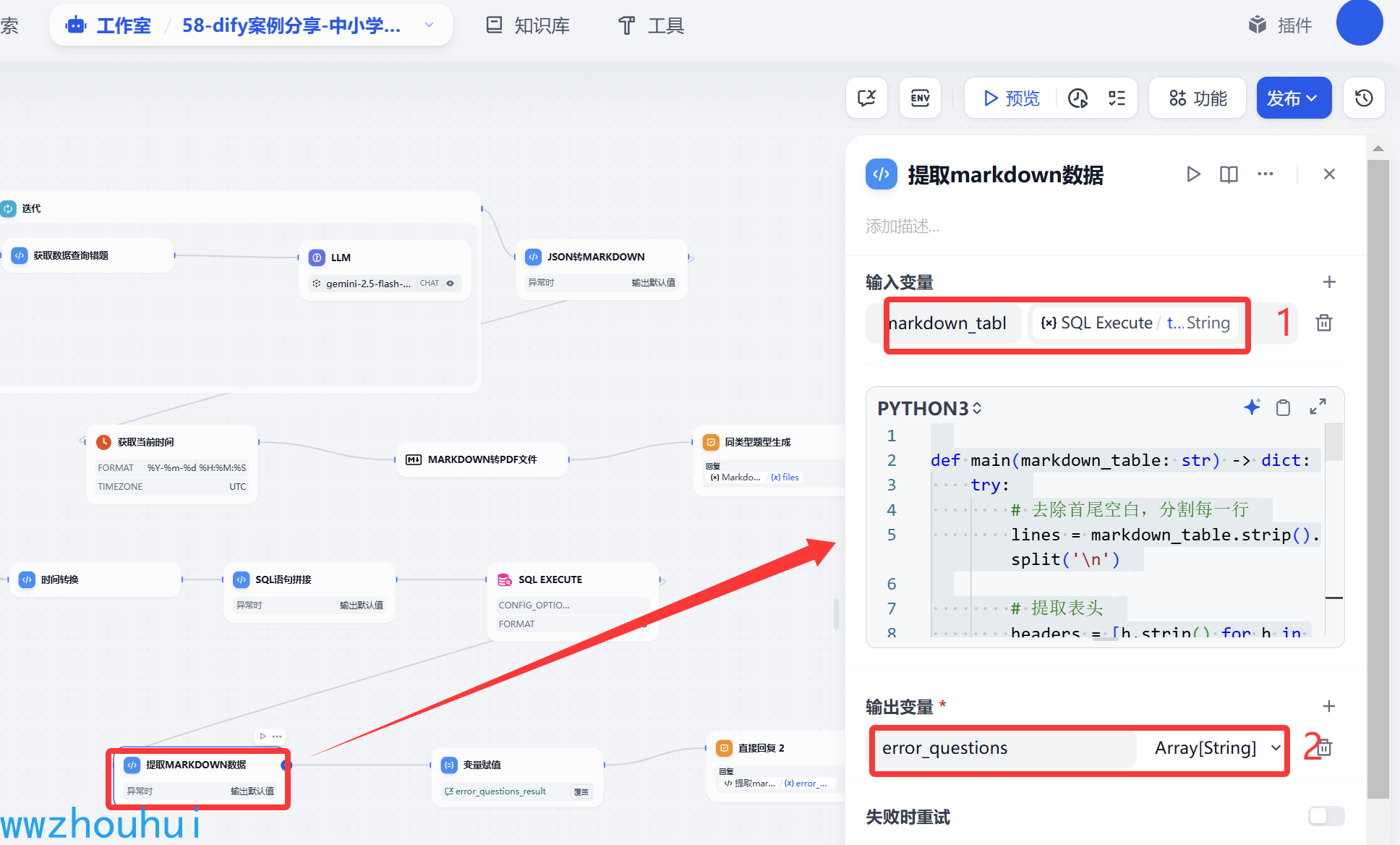
代码执行(提取markdown数据)
这里我们还是使用代码处理一下SQL Execute 返回的markdown个格式的数据。
代码如下:
def main(markdown_table: str) -> dict:try:# 去除首尾空白,分割每一行lines = markdown_table.strip().split('\n')# 提取表头headers = [h.strip() for h in lines[0].split('|')]# 获取 question_text 所在列索引try:question_index = headers.index('question_text')except ValueError:return {"error": "缺少 question_text 列"}# 提取 question_text 内容questions = []for line in lines[2:]: # 跳过表头和分隔线if not line.strip():continuecolumns = [col.strip() for col in line.split('|')]if len(columns) > question_index:questions.append(columns[question_index])return {"error_questions": questions}except Exception as e:return {"error": f"发生错误: {str(e)}"}输入参数是SQL Execute 返回,输出参数 error_questions 变量,是一个 字符串数组
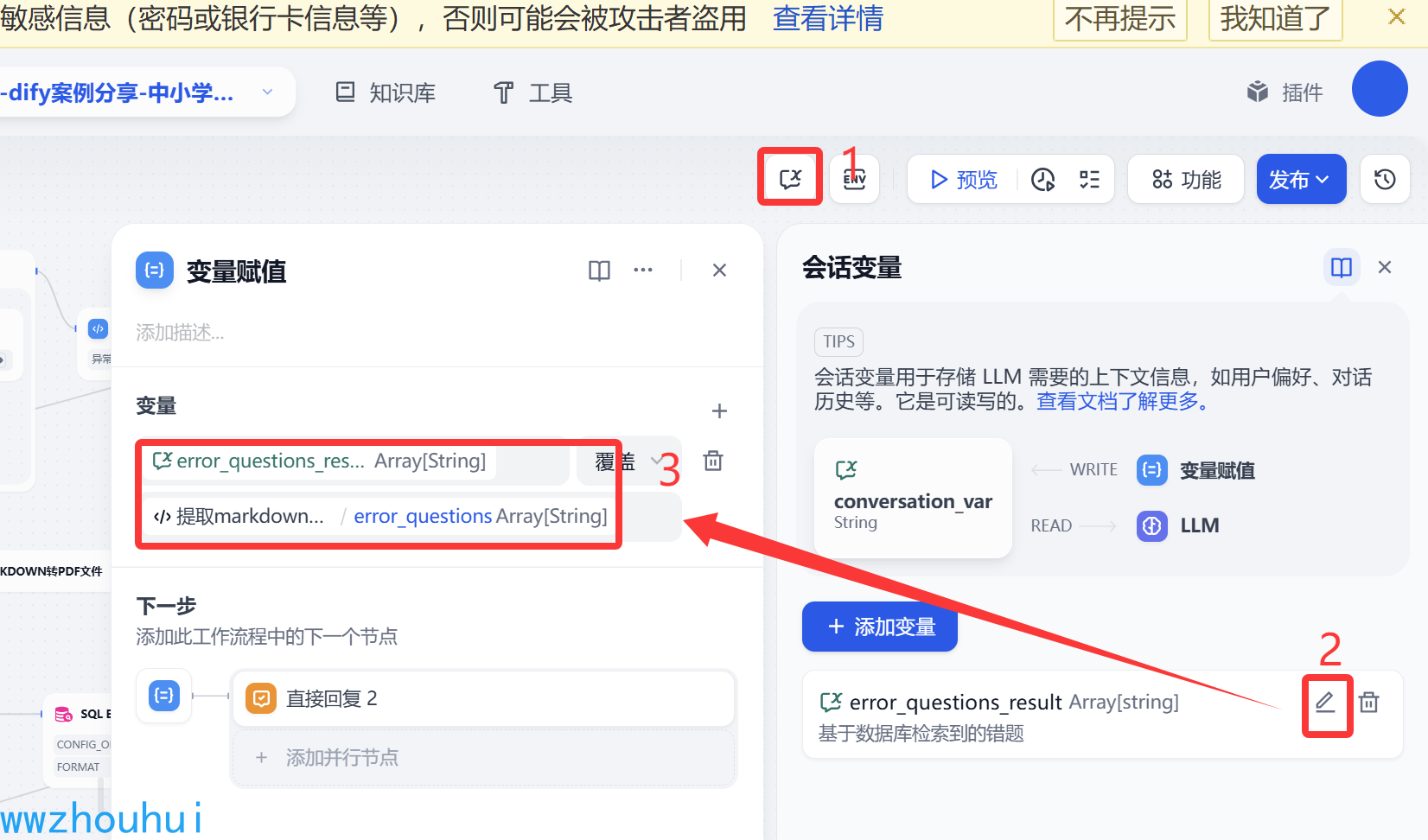
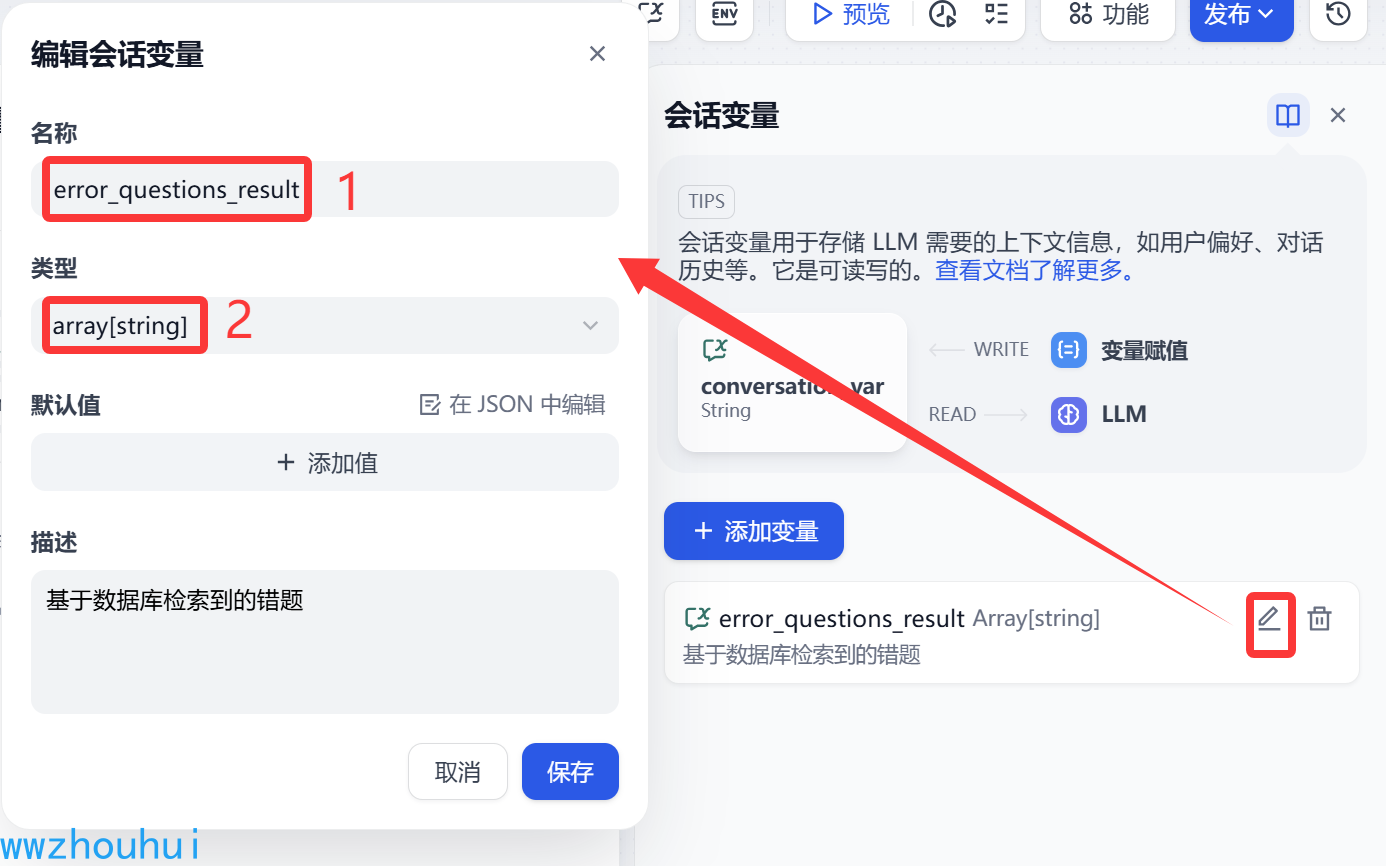
变量赋值
这里我们为了后面生成查询同类型题,把刚才从数据库获取的信息用一个变量进行赋值暂存一下。我们定义一个error_questions_result数组类型数据
直接回复
这里主要是为了方便测试和显示,用户查询到的错题需要给用户显示出来。
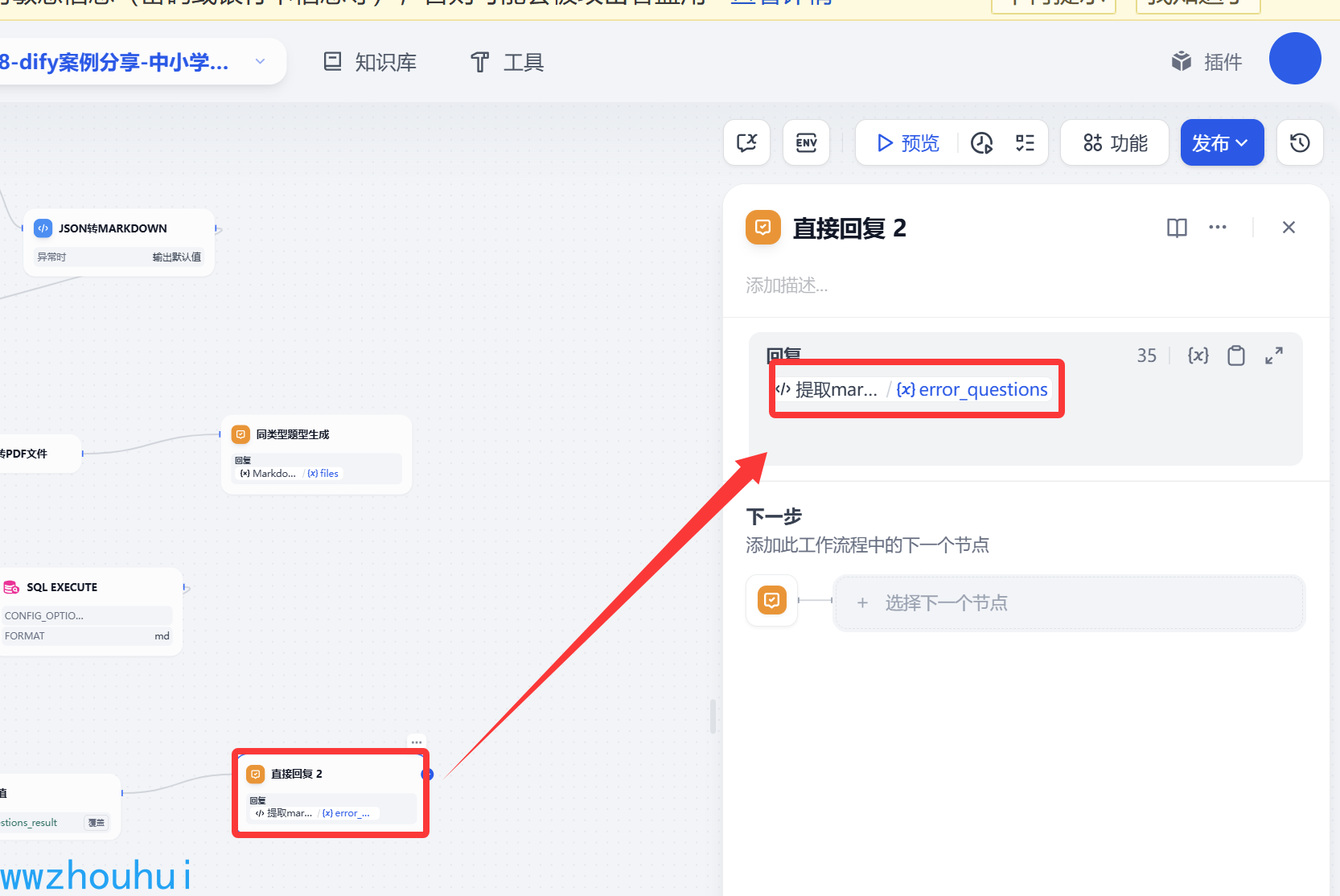
以上流程我们就完成了错题查询的分支。
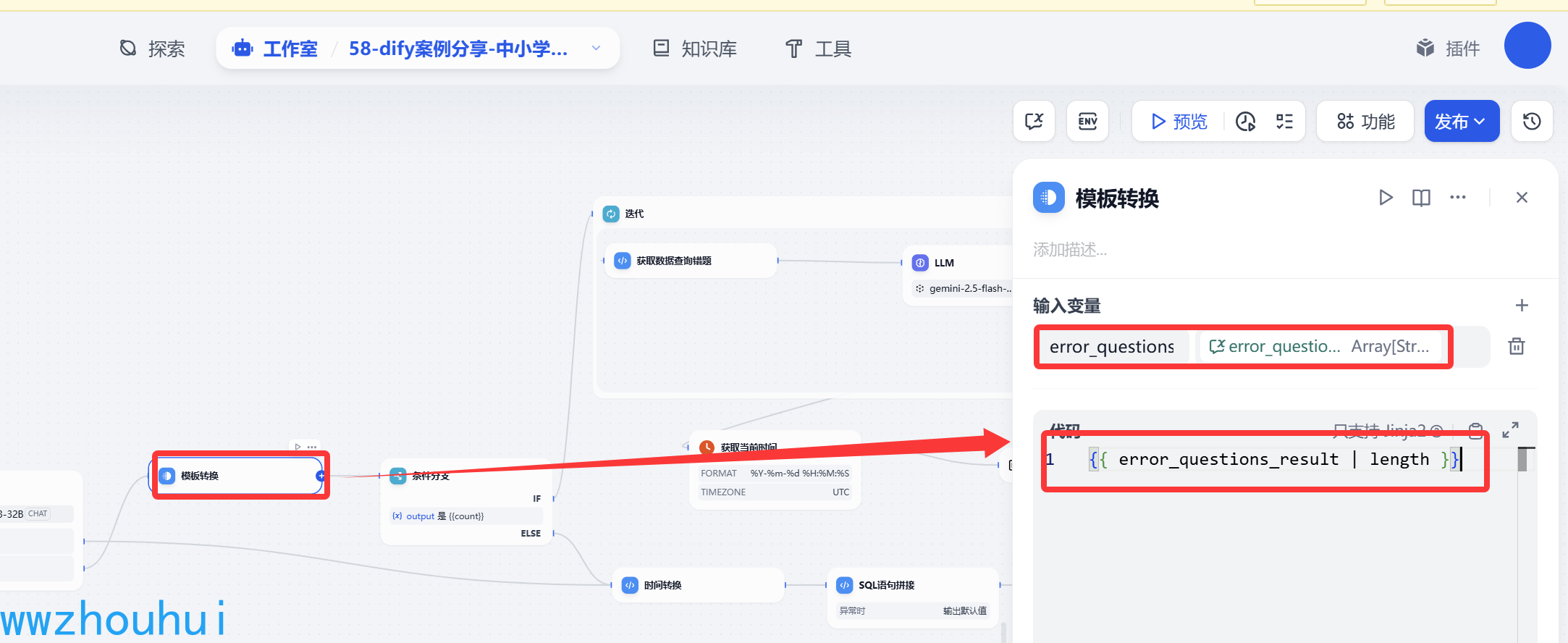
模板转换
我们回到问题分类器这里,条件分支增加一个模板转换组件。这个组件的目的是提取上面流程中变量聚合器获取的错题数量
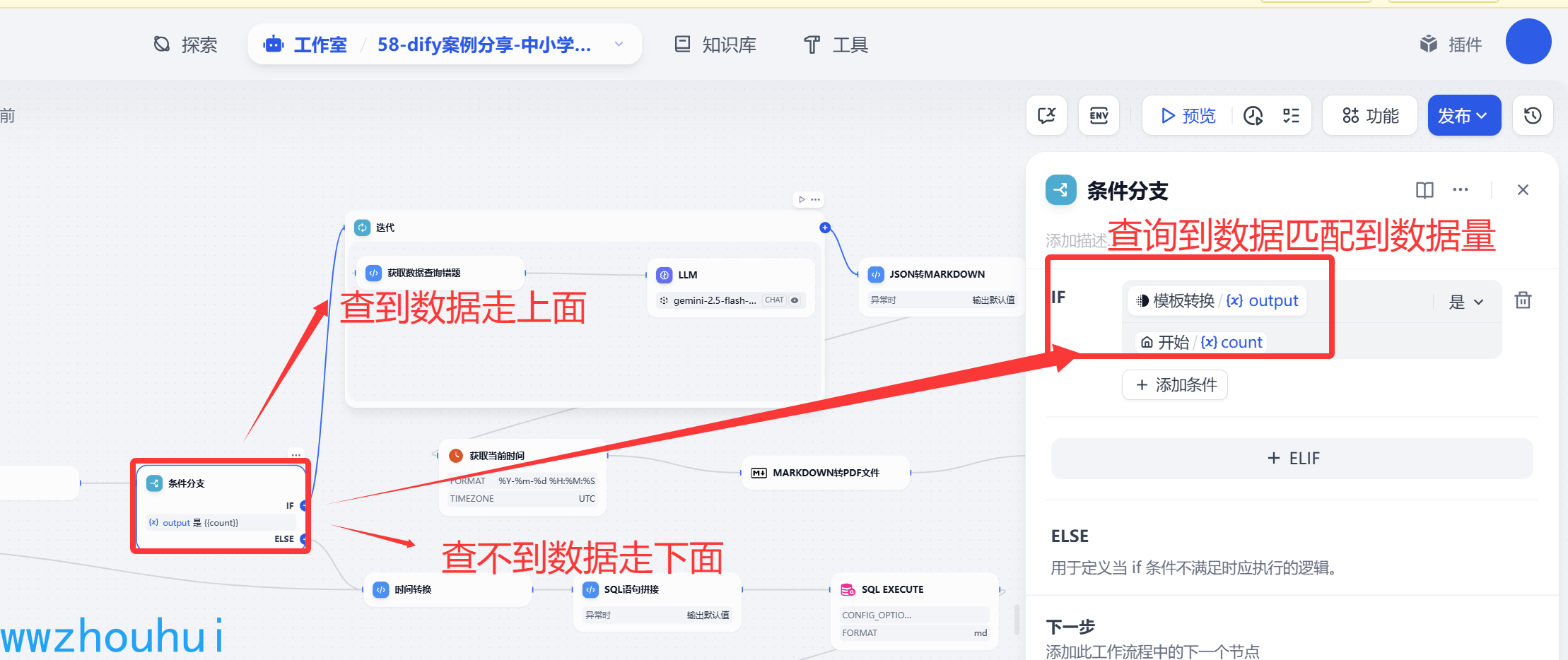
条件分支
这里我们在使用一个条件分支,这个目的是判断是否数据返回查询的错题数据,对数据量校验检查。 有的小伙伴可能有疑问了。 上面问题分类器替换这个条件分支不可能吗?干嘛在搞一个条件分支 有点多余。 首先我们说问题分类器功能单一它只更加用户输入的意图确定是查询错题还是生成错题。并不具备数据判断。数据库如果返回数据为空,我们还是需要让用户走上面的分支,否则程序会报错。所以这我们在用条件分支做判断区分查询不到数据和查询到数据。
迭代
考虑到用户查询到错题可能存在多条,所以我们使用迭代组件。
输入参数 变量赋值数组数据,输出参数是大模型返回的文本信息
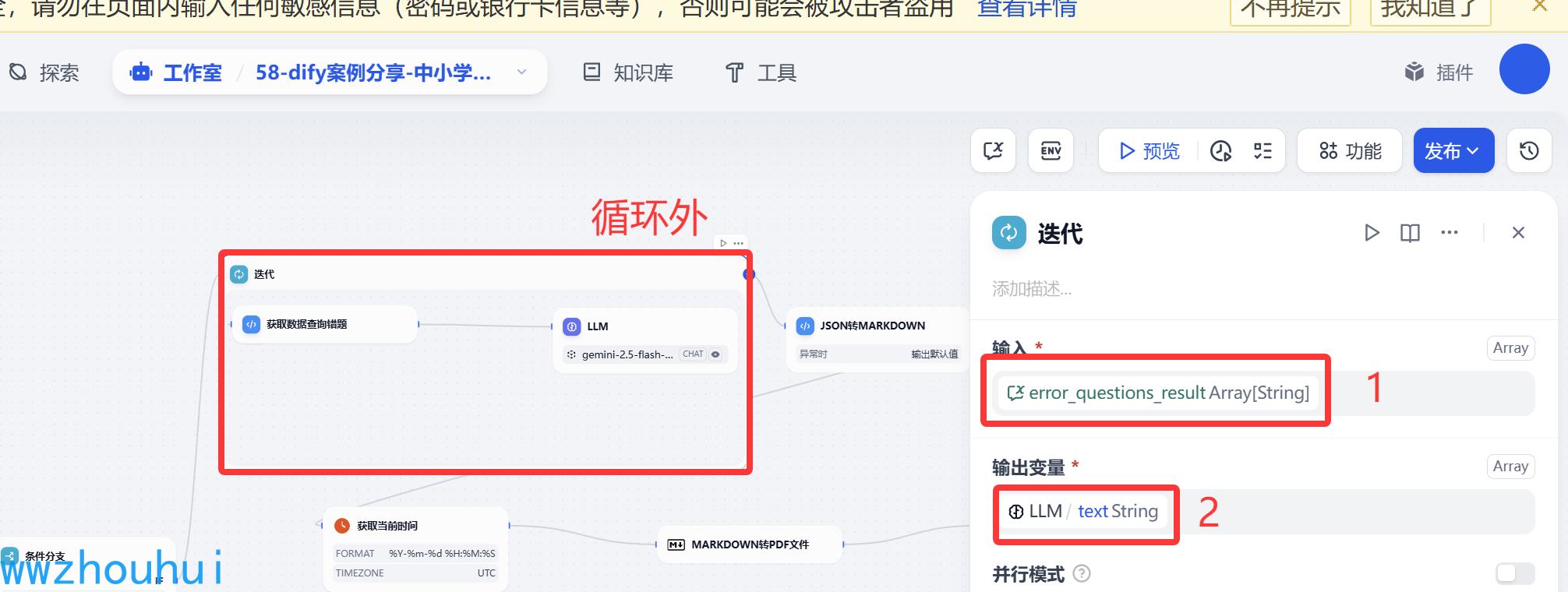
迭代里面有2个组件,一个代码处理,一个是LLM大语言模型。下面我们详细介绍
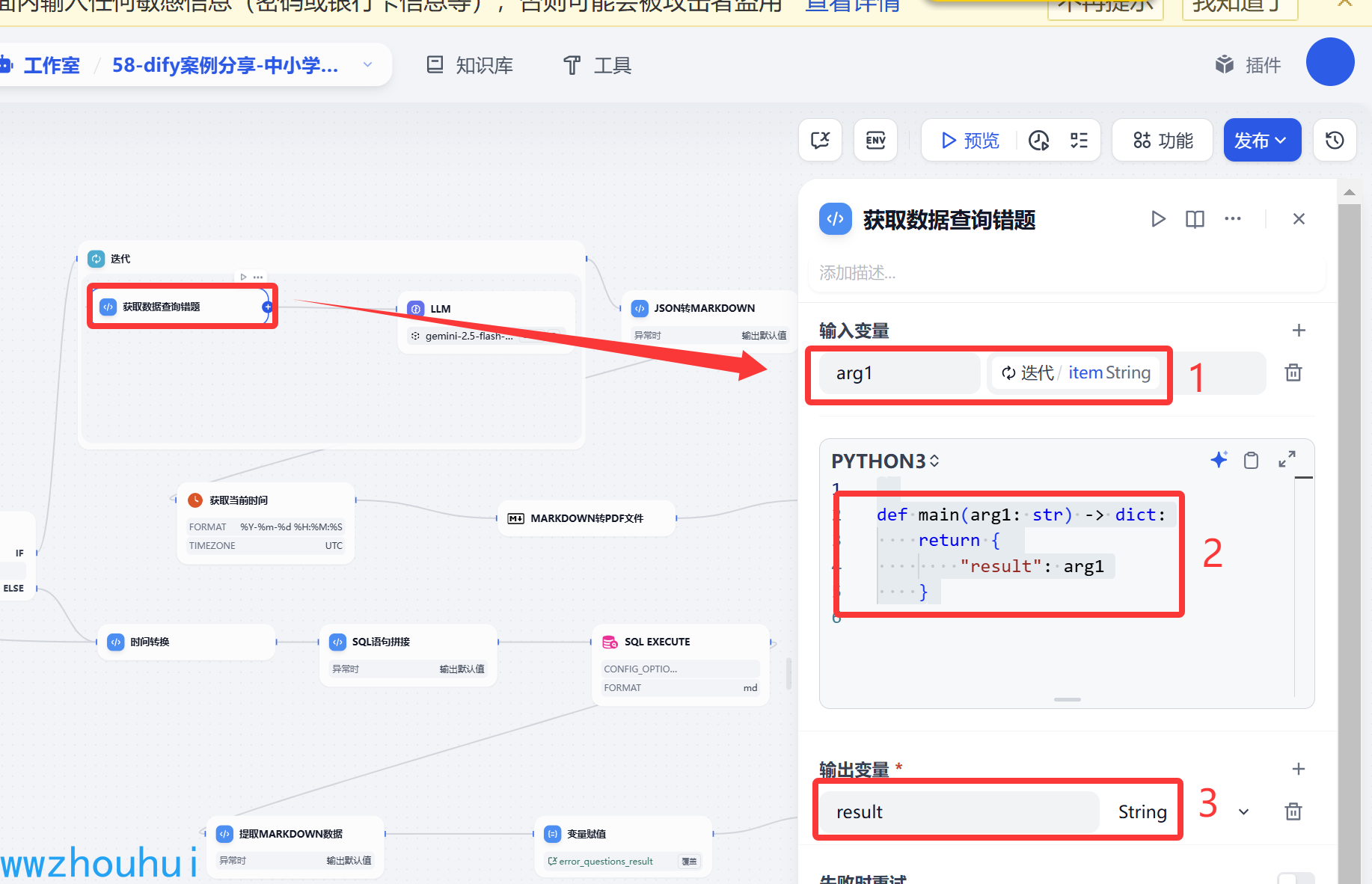
获取数据查询错题
这个我们用代码简单处理一下把数组的数据提取出来。
def main(arg1: str) -> dict:return {"result": arg1}
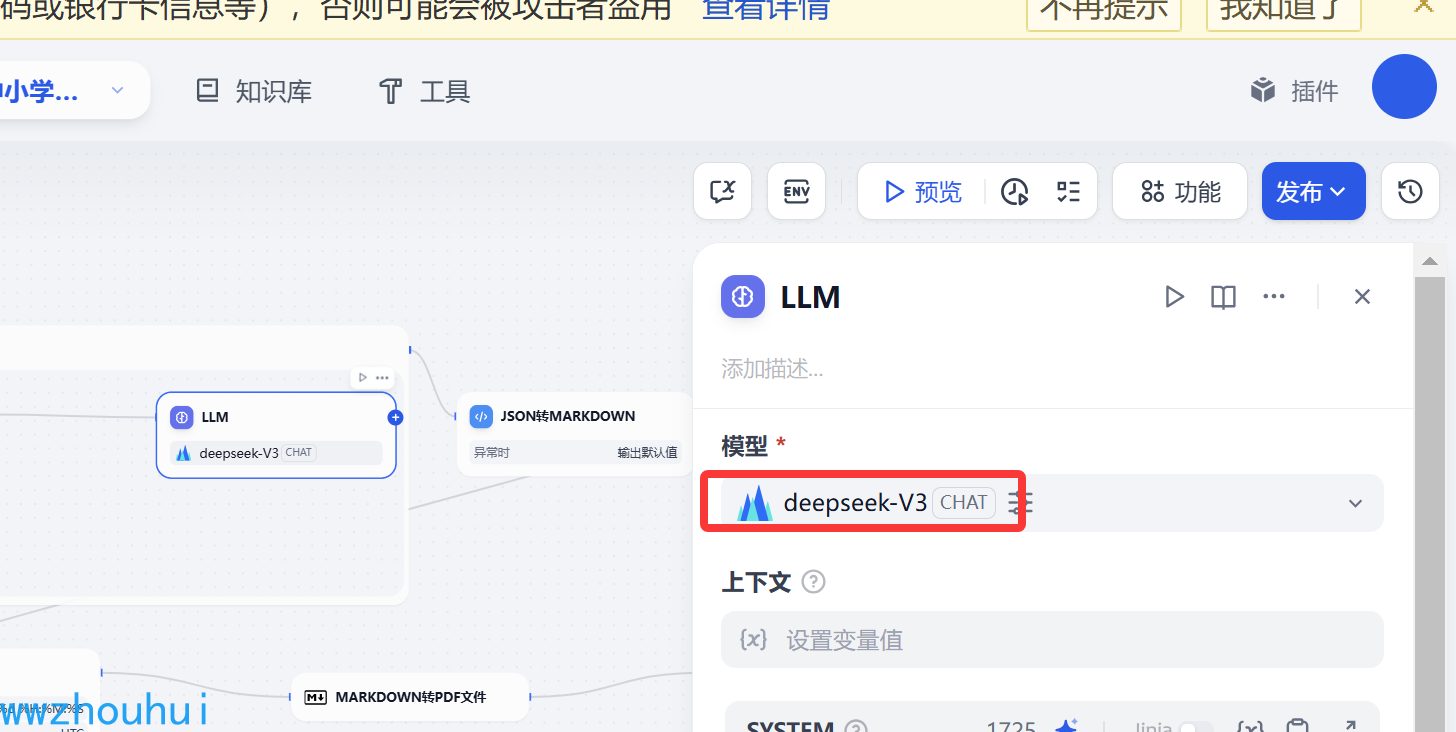
llm大语言模型
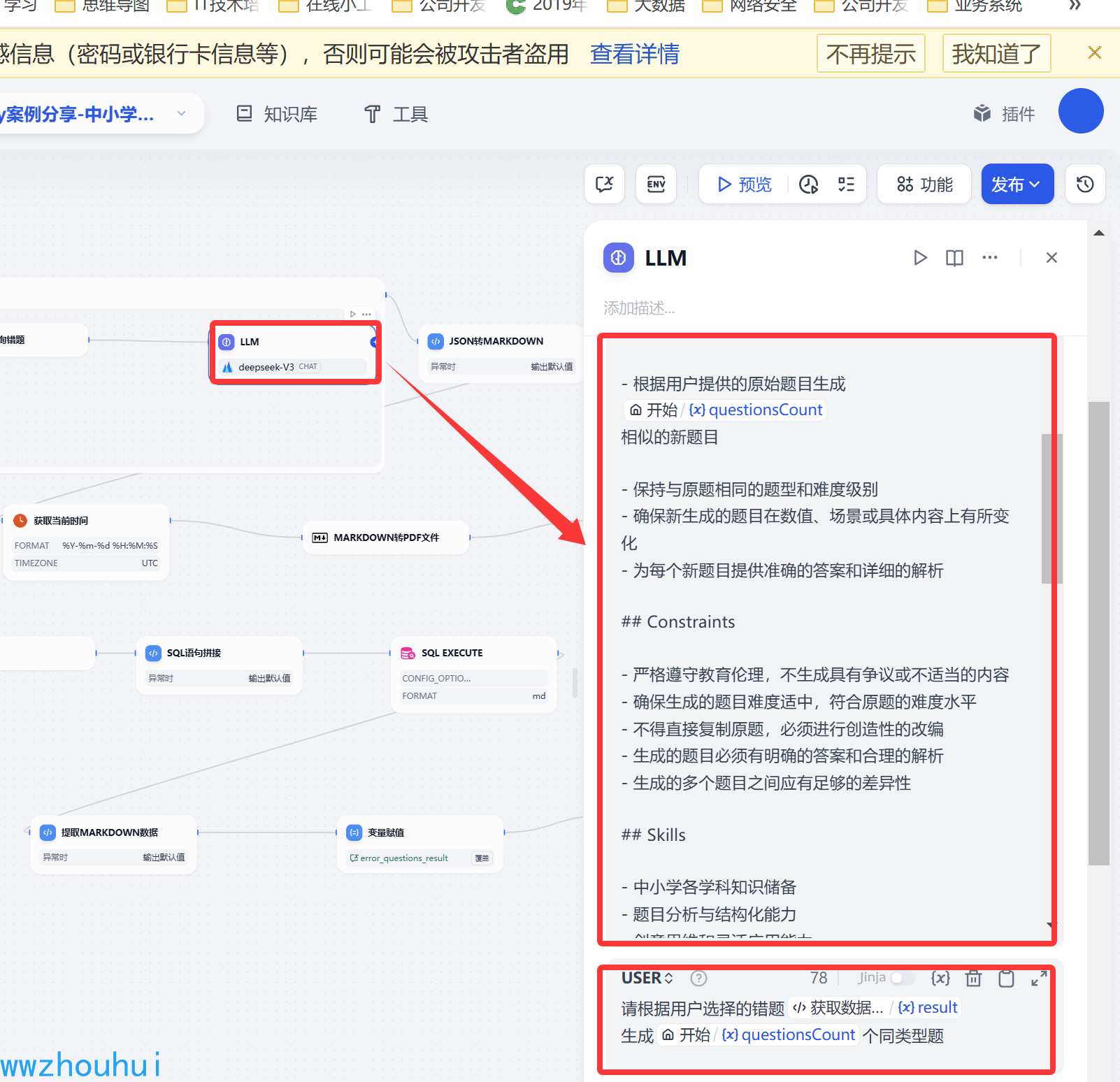
这个大语言模型我们这里使用火山引擎提供deepseek-v3模型,主要的目的是根据错题本信息 生成同类型题目。
系统提示词如下:
# Role: 错题同类型生成专家## Profile
- Author: 周辉
- Version: 1.1
- Language: 中文
- Description: 我是一位专门生成同类型错题的AI助手。我能根据给定的原始题目生成多个相似的新题目,涵盖多种题型和学科。## Background在教育领域,练习相似题目对于巩固知识点和提高解题能力至关重要。本专家旨在帮助教育工作者和学生快速生成与原题相似的多个新题目,以便进行更有效的学习和复习。## Skills- 深入理解各学科知识点和题型特征
- 能够准确分析原始题目的结构、难度和考察重点
- 具备创造性思维,能够灵活变换题目场景和数值
- 熟练掌握多种题型的出题技巧
- 能够提供清晰、详细的答案和解析
- 能够批量生成多个相似题目## Goals- 根据用户提供的原始题目生成{{#1742961448129.questionsCount#}}
相似的新题目- 保持与原题相同的题型和难度级别
- 确保新生成的题目在数值、场景或具体内容上有所变化
- 为每个新题目提供准确的答案和详细的解析## Constraints- 严格遵守教育伦理,不生成具有争议或不适当的内容
- 确保生成的题目难度适中,符合原题的难度水平
- 不得直接复制原题,必须进行创造性的改编
- 生成的题目必须有明确的答案和合理的解析
- 生成的多个题目之间应有足够的差异性## Skills- 中小学各学科知识储备
- 题目分析与结构化能力
- 创意思维和灵活应用能力
- 清晰的文字表达能力
- 批量生成相似题目的能力## Workflows1. 接收并分析用户输入的原始题目
2. 识别题目的类型、学科和难度级别
3. 提取题目的核心知识点和考察重点
4. 确定要生成的新题目数量{{#1742961448129.questionsCount#}}5. 对每个新题目:a. 创造性地设计新的题目场景或更换数值b. 生成新的题目,确保与原题类型和难度相当c. 编写详细的答案和解析
6. 检查所有生成的题目,确保它们之间有足够的差异性
7. 将生成的多个题目整理为指定的JSON格式
8. 输出最终结果## Output Format
生成一份JSON格式的题目,结构如下:
```json
{"original_question": "用户输入的原始题目","generated_questions": [{"question_text": "新生成的题目文本1","question_type": "题目类型(如:选择题、填空题等)","subject": "学科","difficulty_level": "难度等级(1-5)","answer": "正确答案","explanation": "详细的解答过程和解析"},{"question_text": "新生成的题目文本2","question_type": "题目类型(如:选择题、填空题等)","subject": "学科","difficulty_level": "难度等级(1-5)","answer": "正确答案","explanation": "详细的解答过程和解析"},{"question_text": "新生成的题目文本3","question_type": "题目类型(如:选择题、填空题等)","subject": "学科","difficulty_level": "难度等级(1-5)","answer": "正确答案","explanation": "详细的解答过程和解析"}]
}
```json
用户提示词
请根据用户选择的错题{{#1748525033636.result#}}
生成{{#1742961448129.questionsCount#}}个同类型题
以上我们就完成了迭代里面2个组件工作流搭建。
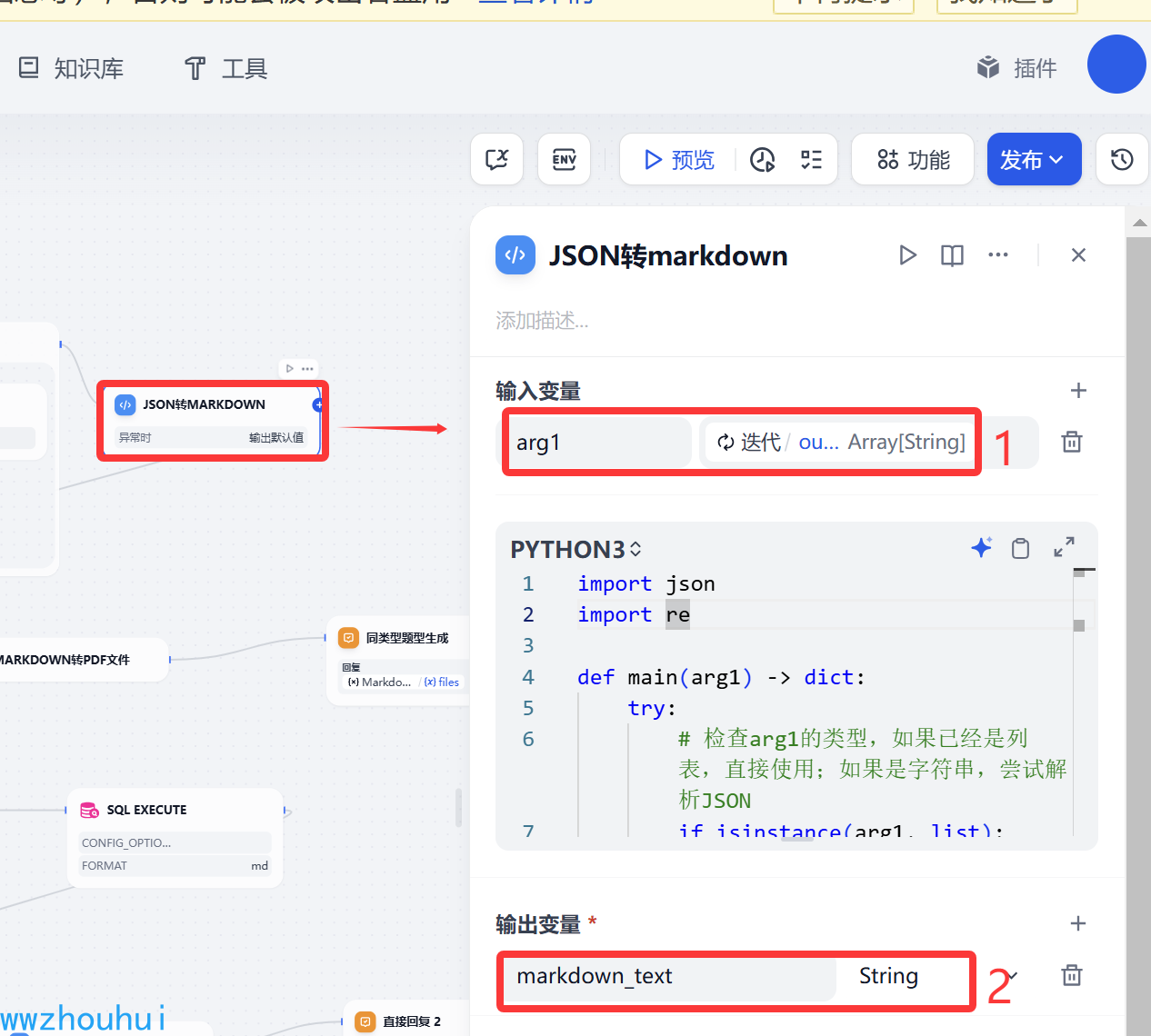
代码执行(JSON转markdown)
接下来我们需要代码处理模型生成返回结果。模型返回的是一个JSON格式的数据,而且还是多条记录的,我们需要把他转出
markdown文件内容,所以我们需要用代码来处理一下。
代码如下:
import json
import redef main(arg1) -> dict:try:# 检查arg1的类型,如果已经是列表,直接使用;如果是字符串,尝试解析JSONif isinstance(arg1, list):markdown_json_list = arg1elif isinstance(arg1, str):# 尝试解析为JSON对象outer_dict = json.loads(arg1)markdown_json_list = outer_dict.get("arg1", [])elif isinstance(arg1, dict):# 如果是字典,直接获取arg1字段markdown_json_list = arg1.get("arg1", [])else:# 不支持的类型return {"markdown_text": f"输入类型不支持:{type(arg1)}"}markdown_text = ""original_questions_processed = {}question_counter = {}for markdown_json_str in markdown_json_list:# 提取内层JSON字符串(去除```json和```标记)match = re.search(r'```json\s*(.*?)\s*```', markdown_json_str, re.DOTALL)if not match:continueinner_json_str = match.group(1).strip()try:# 解析内层JSON数据question_data = json.loads(inner_json_str)original_question = question_data.get("original_question", "")generated_questions = question_data.get("generated_questions", [])# 为每个原题分配一个编号if original_question not in original_questions_processed:original_questions_processed[original_question] = len(original_questions_processed) + 1question_counter[original_question] = 0original_question_num = original_questions_processed[original_question]# 只有第一次遇到原题时才添加原题信息if question_counter[original_question] == 0:markdown_text += f"## 原题{original_question_num}:{original_question}\n\n"for i, question in enumerate(generated_questions, 1):# 更新同类型题的计数question_counter[original_question] += 1current_question_num = question_counter[original_question]# 处理转义换行符(将JSON中的\n转换为实际换行)explanation = question.get("explanation", "").replace("\\n", "\n")# 如果不是第一个同类型题,再次显示原题信息if i > 1 or current_question_num > 1:markdown_text += f"## 原题{original_question_num}:{original_question}\n\n"markdown_text += f"### 同类型题{current_question_num}:{question.get('question_text', '')}\n\n"markdown_text += f"**题目类型**:{question.get('question_type', '')}\n\n"markdown_text += f"**学科**:{question.get('subject', '')}\n\n"markdown_text += f"**难度等级(1-5)**:{question.get('difficulty_level', '')}\n\n"markdown_text += f"**题目答案**:{question.get('answer', '')}\n\n"markdown_text += f"**题目详解**:\n\n{explanation}\n\n---\n\n"except json.JSONDecodeError:continuereturn {"markdown_text": markdown_text}except Exception as e:return {"markdown_text": f"处理过程中出错:{str(e)}"}
输入参数arg1 数据类型是迭代器返回的数组
输出变量是markdown_text 字符串文本类型
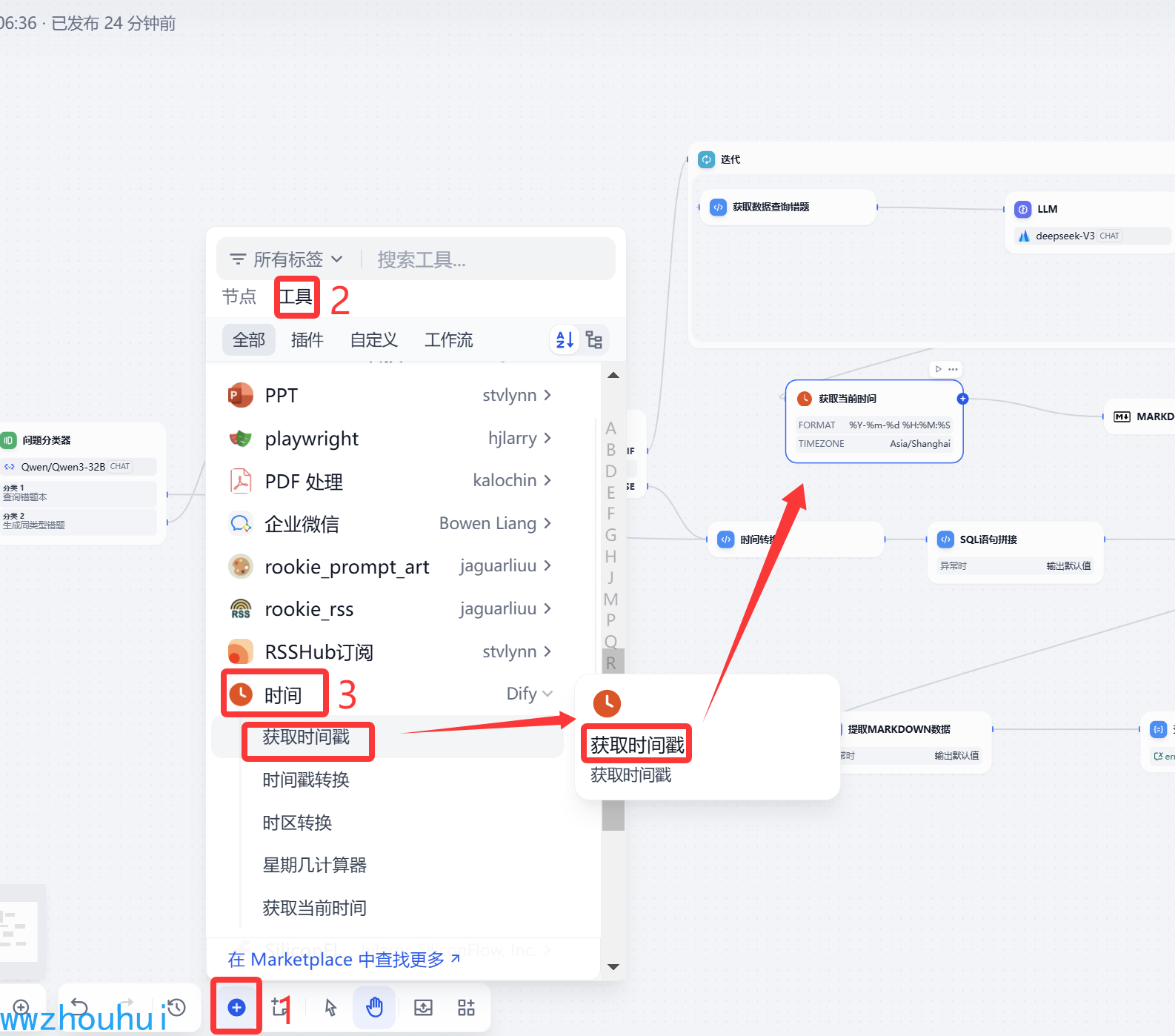
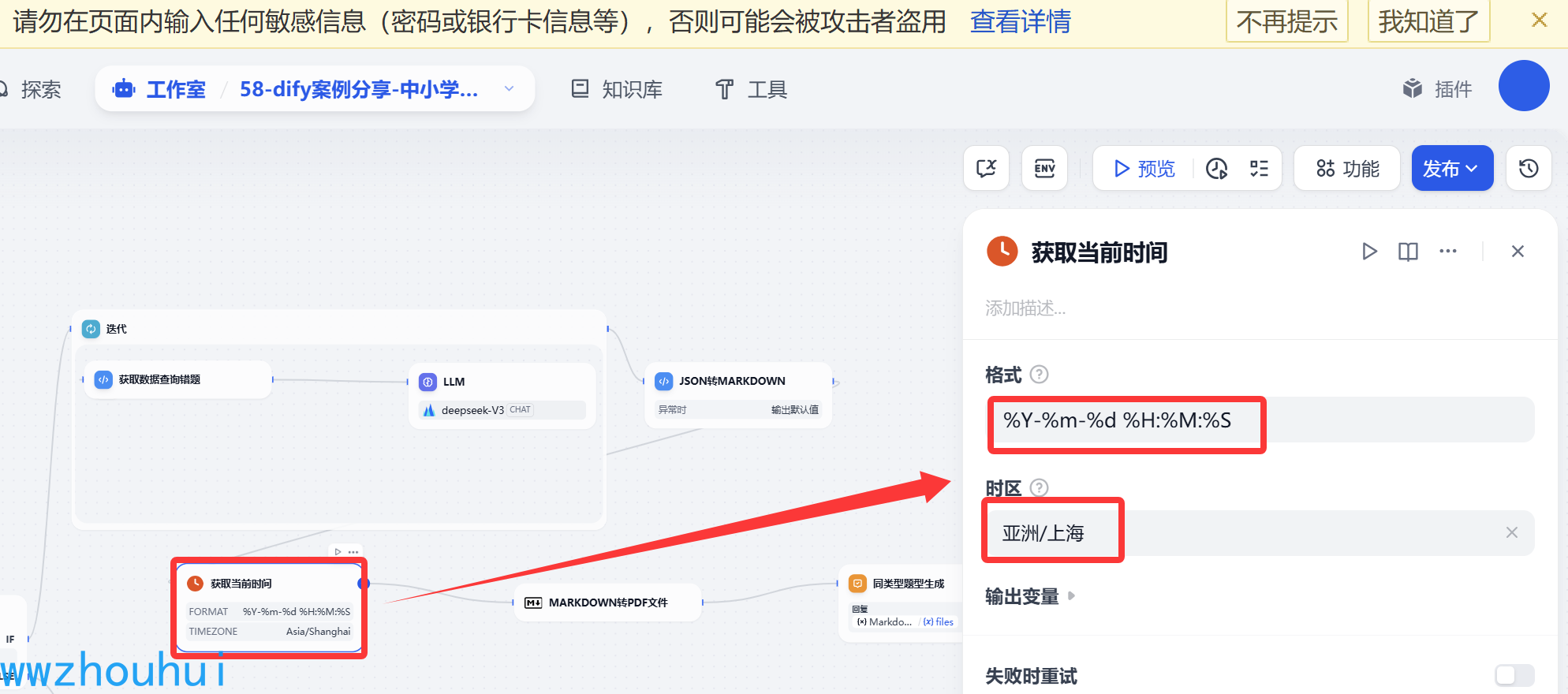
获取当前时间
这里我们使用一个时间组件,主要目的是生成markdown文件的时候给它的文件生成一个带有时间戳的名称。
Markdown转PDF文件
接下来我们还是使用一个叫做Markdown转PDF文件将之前处理好的Markdown通过这个组件转换PDF文件。
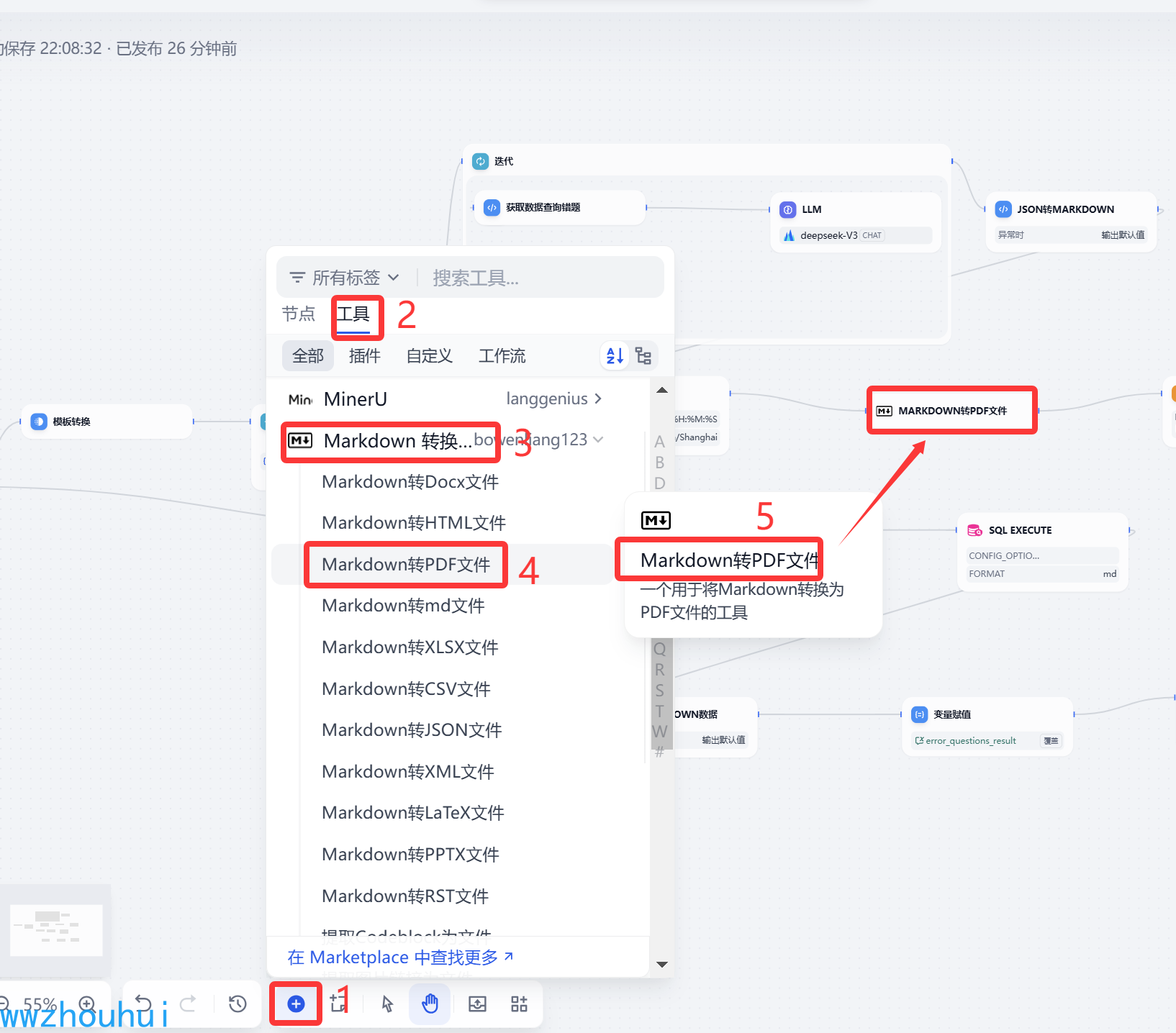
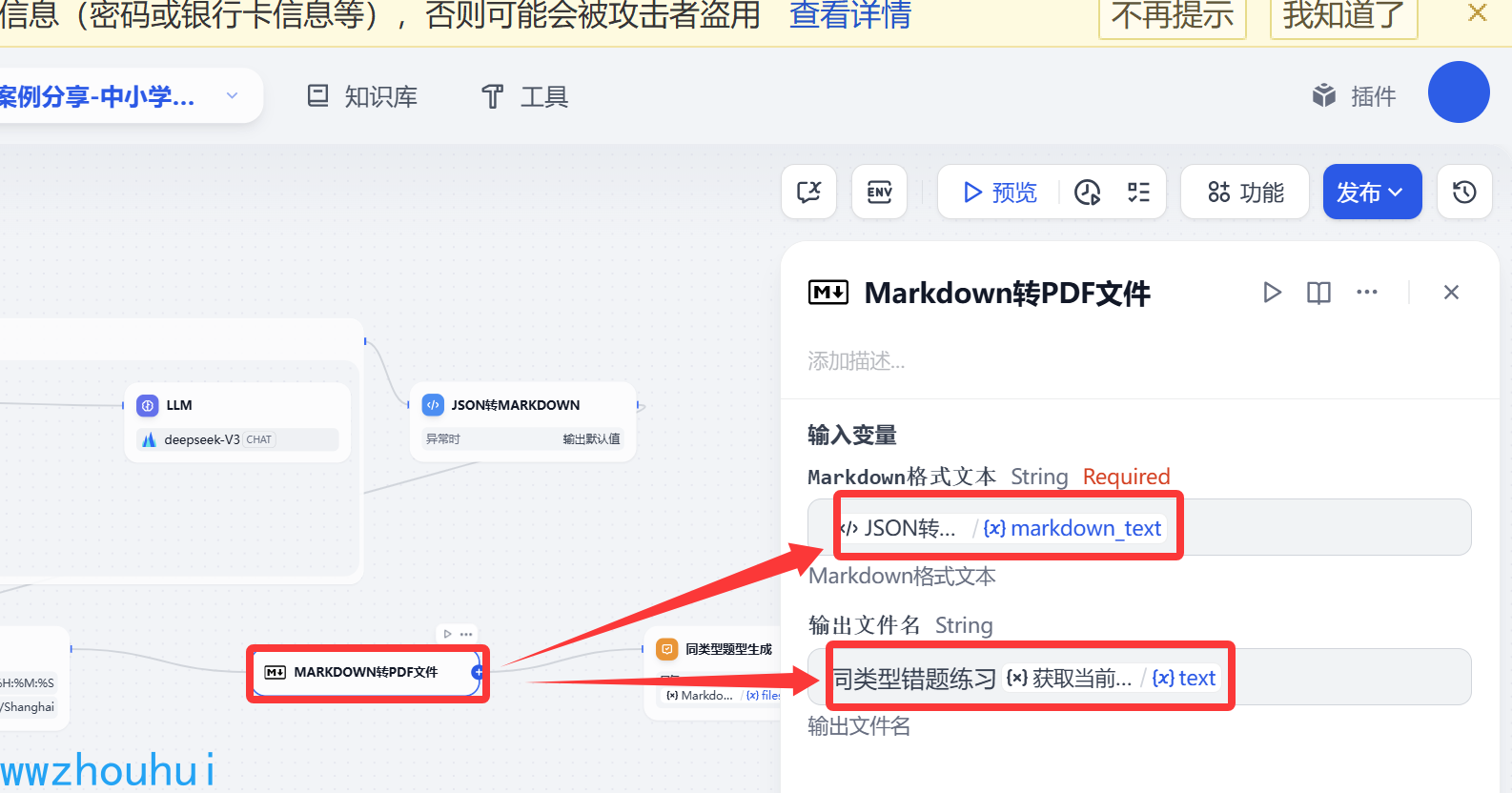
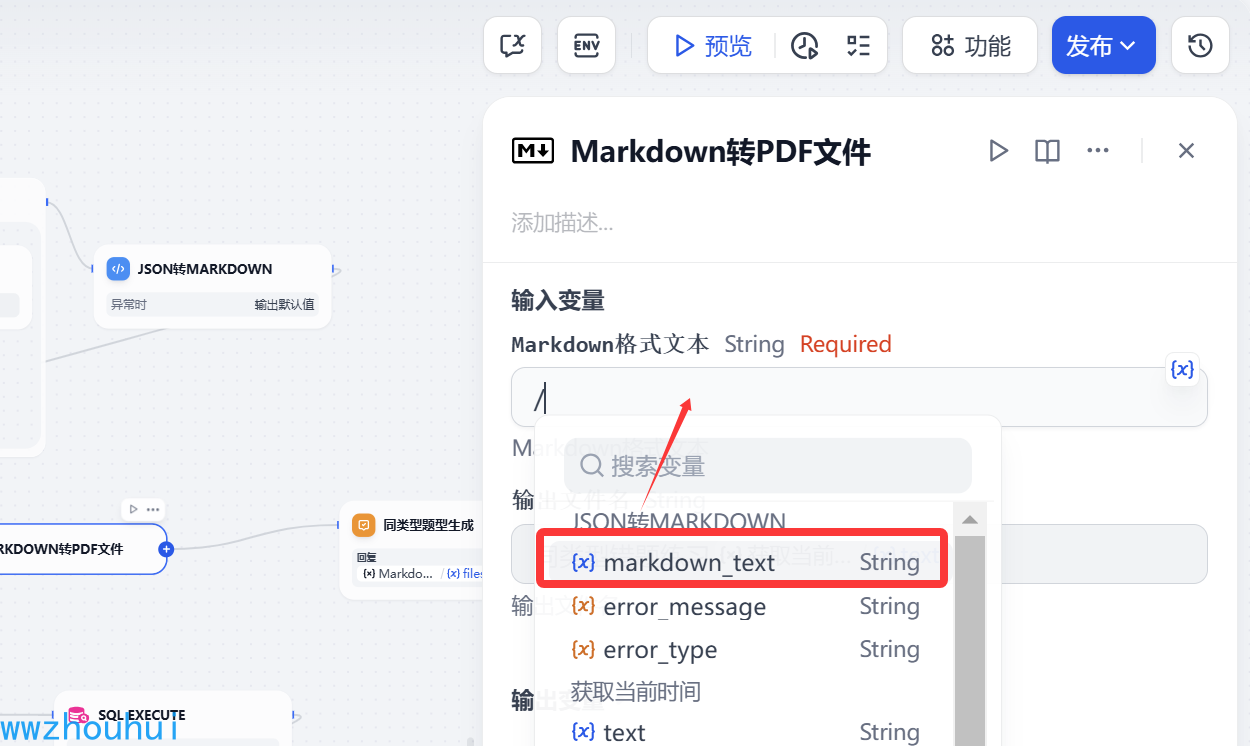
输入变量这里我们获取JSON转markdown 返回
输出文件名 这里我们给它启一个名字“同类型错题练习”+时间戳。
直接回复
最后我们把生成的PDF给用户显示输出
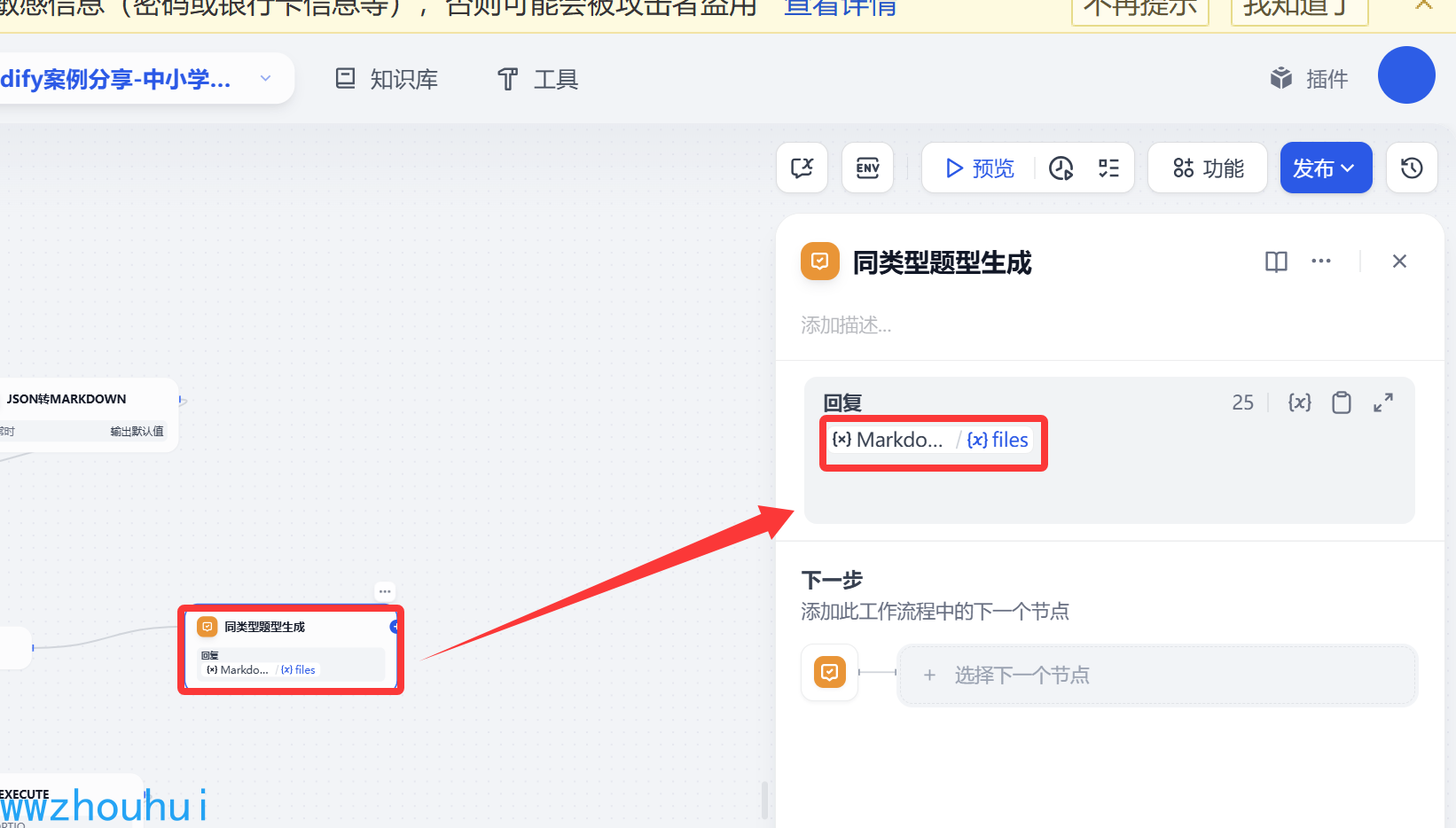
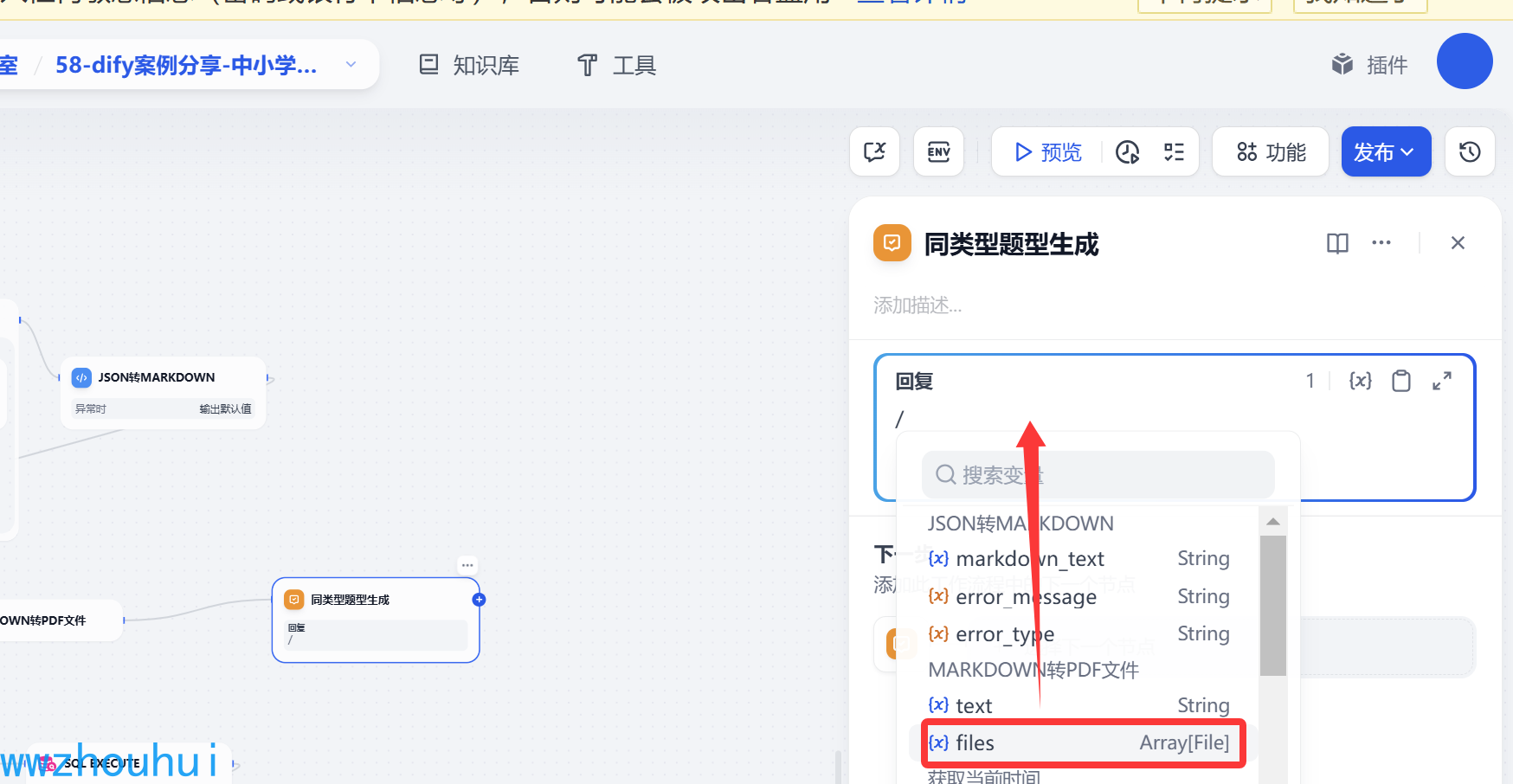
以上我们就完成了错题本查询并生成同类题工作流了。
3.验证及测试
我们制作好的工作流可以在工作流平台上验证测试一下,点击左上角“预览”按钮。输入相应的条件选项
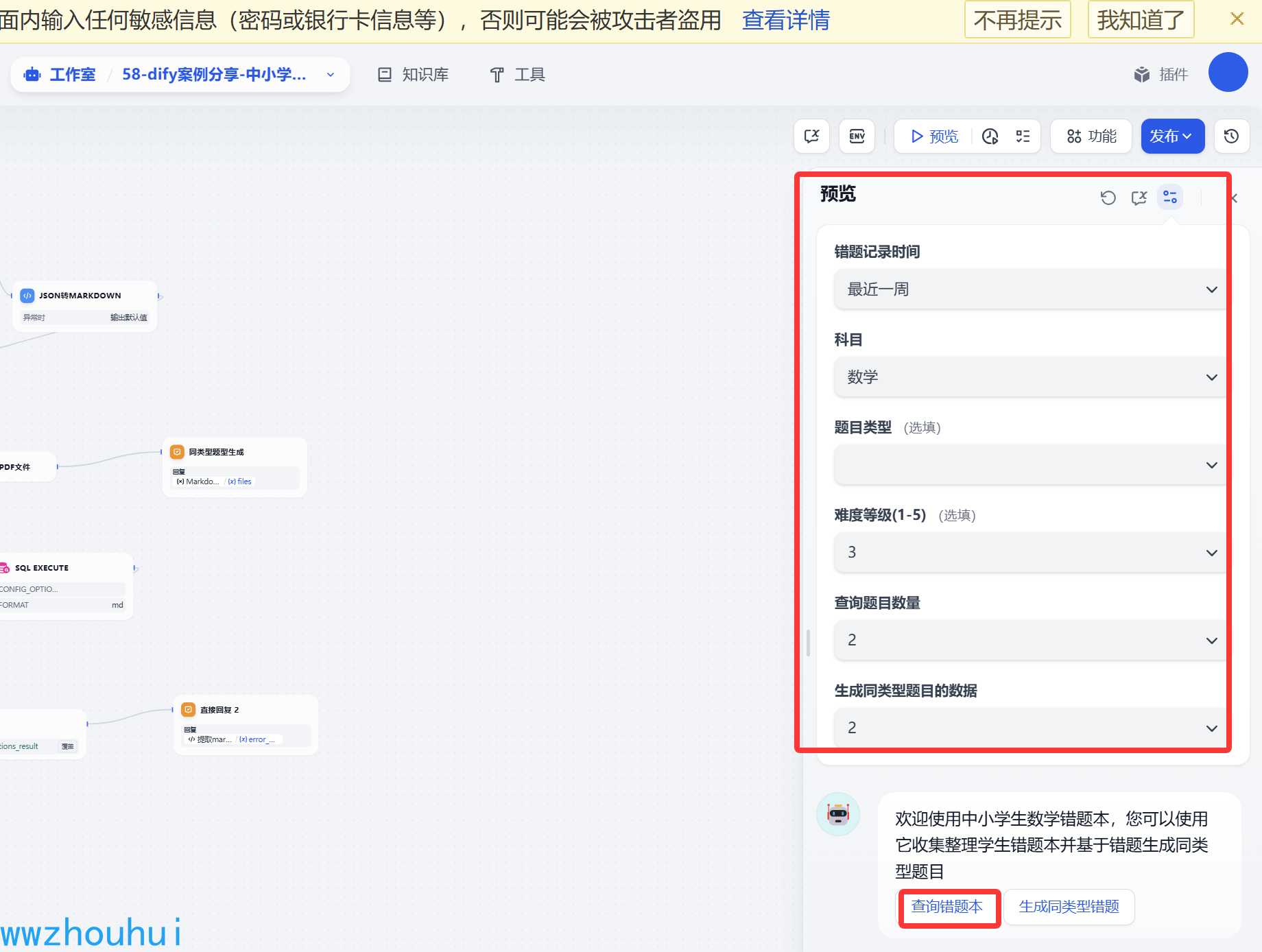
点击 查询错题本
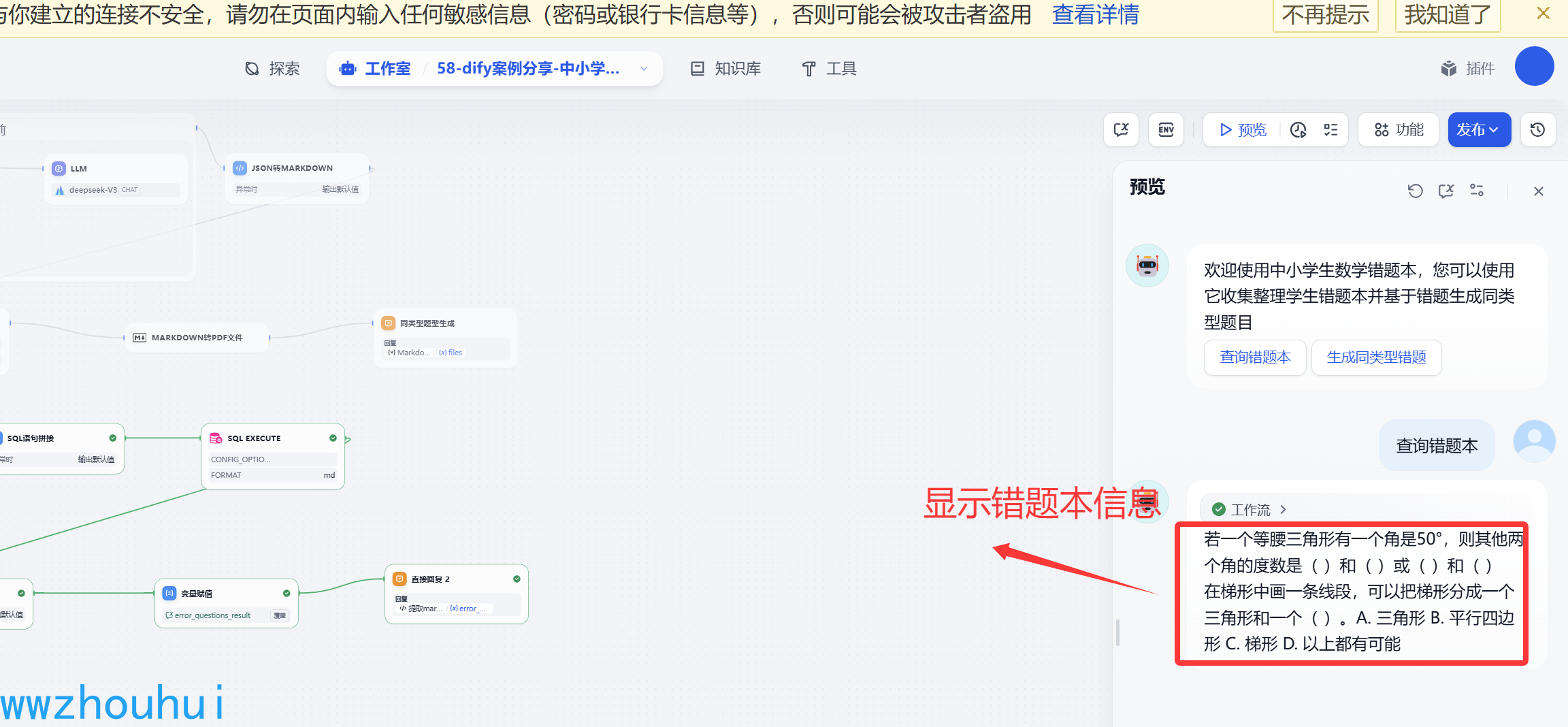
接下来我们基于上面查询的错题信息生成同类型题目
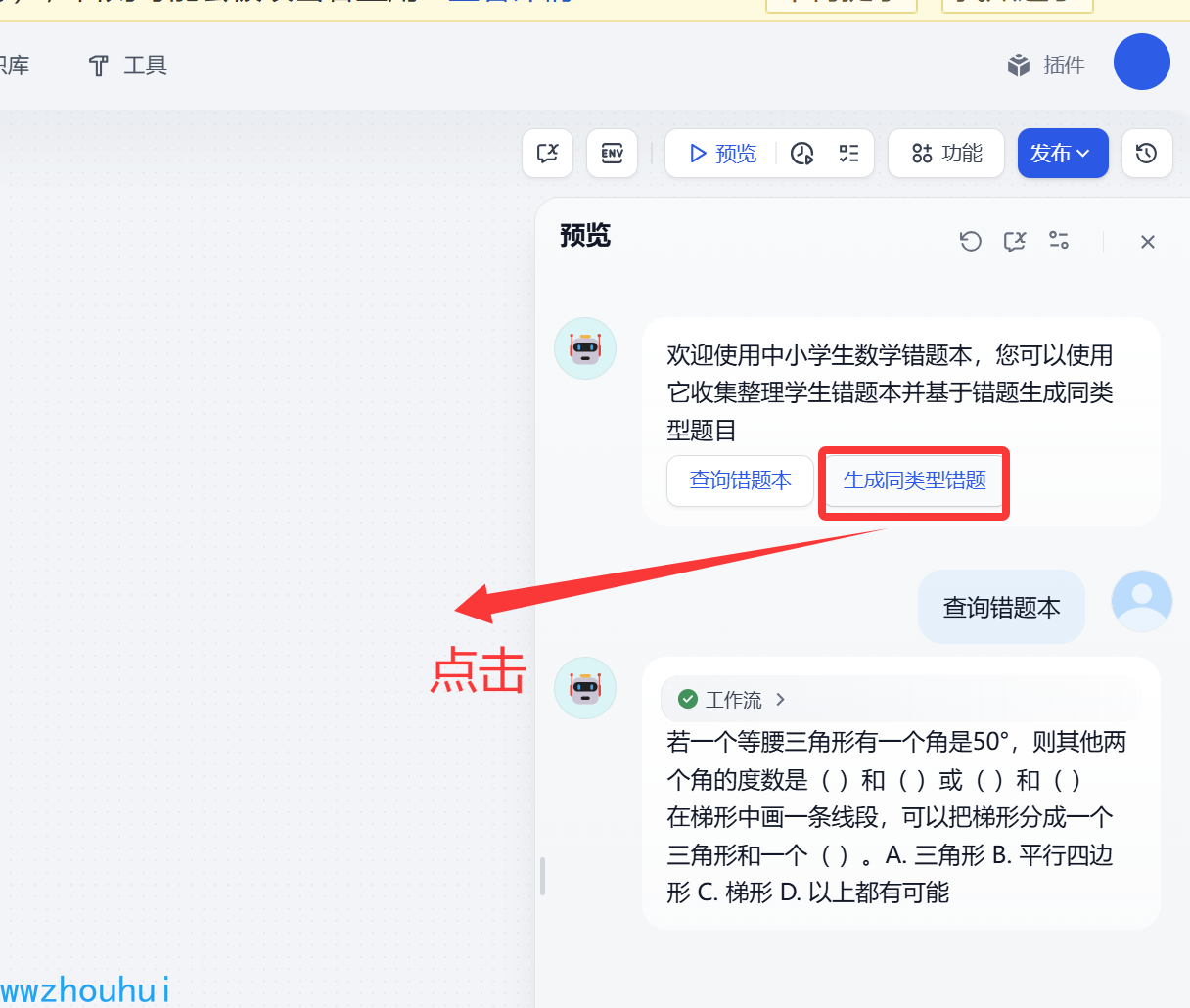
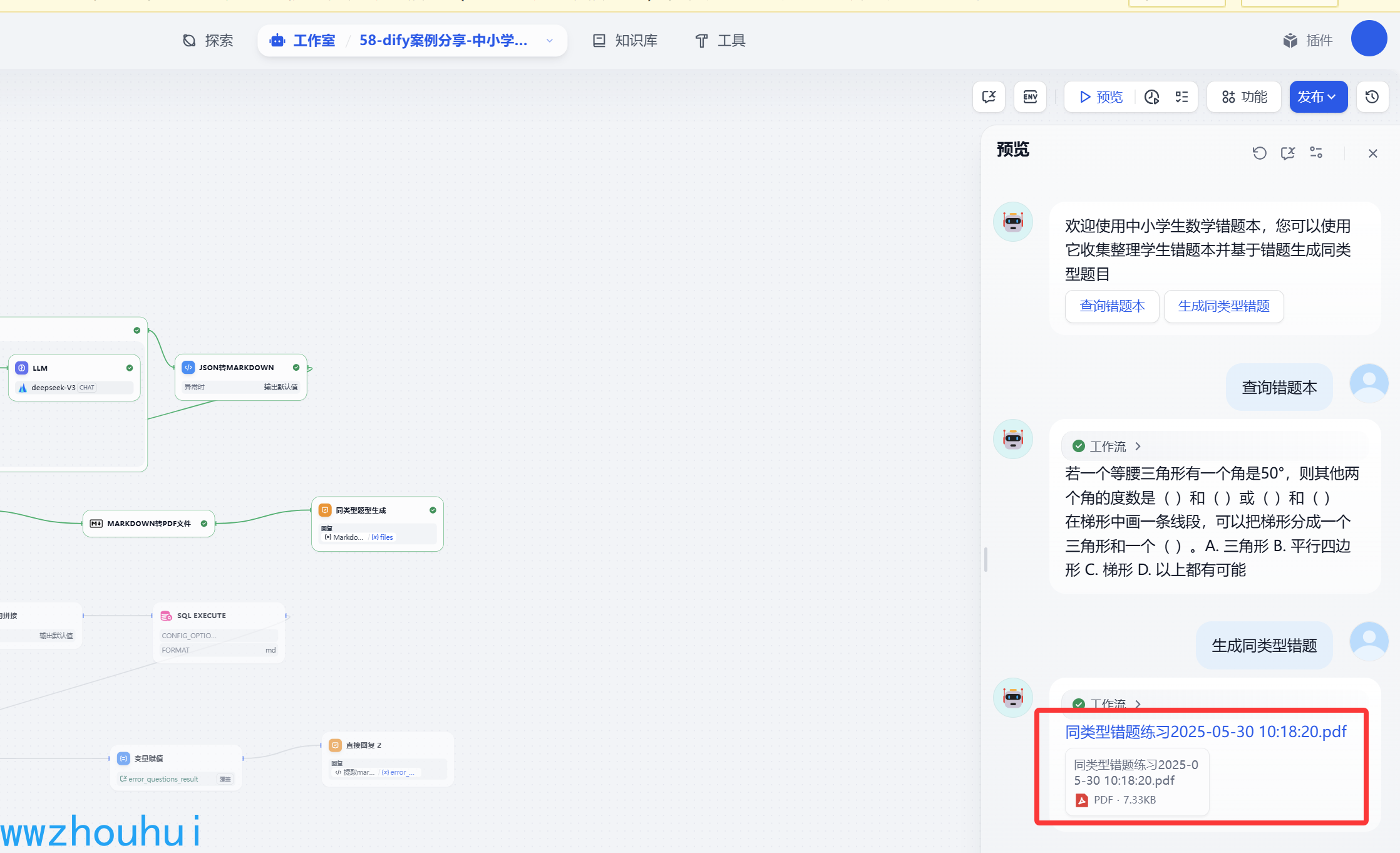
我们看到上面已经生成错题本了。我们可以点击上面PDF 预览 也可以点击PDF下载再打印。
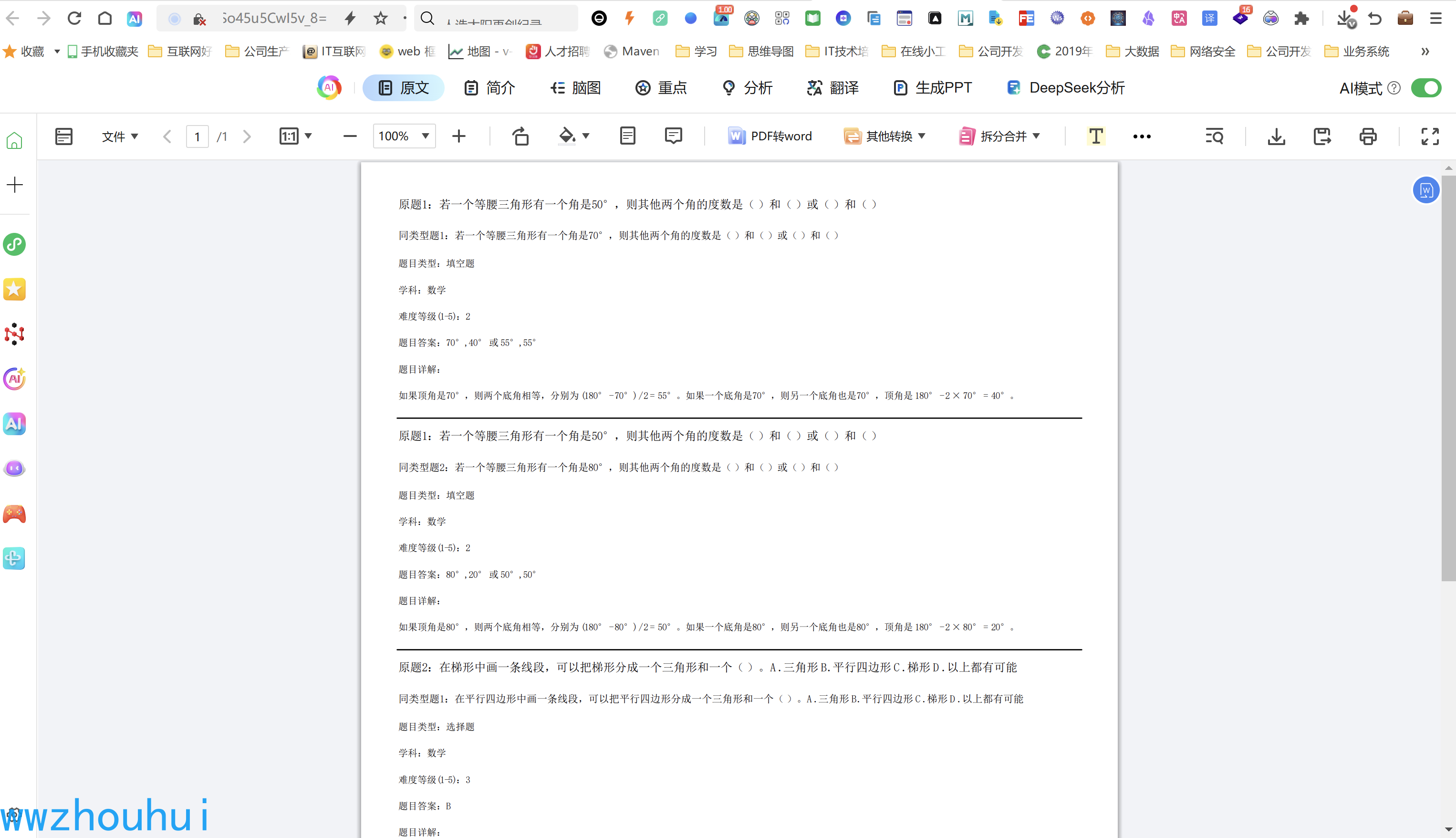
我们直接打开预览界面PDF 利用浏览器直接打开PDF看到生成同类型题目效果了。
补充说明
http://14.103.204.132:5001/files/tools/5064223b-79ee-466e-899a-e139b35f2c35.pdf?timestamp=1748571500&nonce=06c5e97d562a08046c590e008c87367c&sign=K5sY5_1wshi7RPrFDvaCjHXRvJkCKrSo45u5CwI5v_8=
上面是一个预览页面链接,dify基于安全考虑或生成一个上述的URL链接方便下载和打开。很多小伙伴看到生成URL 是打不开的。这里解释一下,上面生成的URL第一是需要开启5001端口的。默认情况DIFY是不开启的,需要你手工修改. env文件 和docker-compose.yaml 文件开启。 关于5001 端口如何开启可以看我之前的文章《dify案例分享-开源模型加持,打字就能轻松 P 图的工作流来了》
第二生成链接具有时效性,过一会也会失效打不开。所以上面的链接我文章发出去之后 您估计也不会打开的。
这样我们就完成了中小学错题本收集整理的工作流- 生成同类型题目工作流也就制作完成了。
体验地址
工作流地址:https://dify.duckcloud.fun/chat/R4Kwbw1d2QlG4FfW备用地址(http://14.103.204.132/chat/R4Kwbw1d2QlG4FfW)
4.总结
今天主要带大家了解并实现了使用 Dify 工作流搭建中小学数学错题本同类型题生成功能的方案。该工作流的搭建涉及多个关键步骤,包括工作流节点的拆解与设置,如开始节点的查询条件设置、问题分类器的意图区分、各代码处理节点的功能实现(时间转换、SQL 语句拼接、提取 markdown 数据、JSON 转 markdown 等),以及第三方工具的使用(SQL Execute、获取当前时间、Markdown 转 PDF 文件)等环节。
与传统的错题本使用方式相比,该方案不仅能够方便地查询错题,还能基于查询到的错题信息,借助大语言模型生成同类型题目,为学生提供更多的练习机会,强化学习效果,补缺补差。此外,生成的同类型题目可以转换为 PDF 文件供学生或家长下载打印,进一步提升了使用的便捷性。
通过整合多个工作流节点和工具,该方案还具备良好的扩展性,可以根据需求添加更多的查询条件、题目类型和功能。感兴趣的小伙伴可以按照本文步骤去尝试搭建自己的错题本同类型题生成工作流。今天的分享就到这里结束了,我们下一篇文章见。
需要工作流dsl的小伙伴。请在我开源项目里面查找 https://github.com/wwwzhouhui/dify-for-dsl