文章目录
- 1. 静态资源的缓存处理
- 1.1 什么是缓存
- 1.2 什么是Web缓存
- 1.3 Web缓存的种类
- 1.3.1 客户端缓存
- 1.3.2 服务端缓存
- 1.4 为什么要用浏览器缓存
- 1.5 浏览器缓存的执行流程
- 1.6 浏览器强缓存和弱缓存的区别
- 1.6.1 强缓存(Strong Cache)
- 1.6.2 弱缓存(Weak Cache)
- 2. Nginx中与浏览器缓存相关的指令
- 2.1 expires指令
- 2.2 add_header指令(Cache-Control)
- 3. Nginx的跨域问题
- 3.1 本域和同源策略
- 3.2 跨域的概念
- 3.3 跨域问题案例演示
- 3.3.1 新建HTML文件
- 3.3.2 修改nginx.conf文件
- 3.3.3 通过浏览器访问
- 3.4 解决方案
- 4. 静态资源防盗链
- 4.1 什么是资源盗链
- 4.2 静态资源防盗链演示
- 4.3 防盗链的实现原理
- 4.3.1 Referer请求头
- 4.3.2 valid_referers指令
- 4.3.3 实战案例
- 4.4 针对目录进行防盗链
如果想了解更多与Nginx相关的内容,可以查看Nginx专栏中的文章: Nginx
视频教程:26-Nginx中浏览器缓存的相关概念
1. 静态资源的缓存处理
1.1 什么是缓存
缓存(Cache)在计算机科学中指的是一种访问速度比普通随机存取存储器(RAM)更快的特殊高速存储器。缓存通常使用静态随机存取存储器(SRAM)技术,而不是动态随机存取存储器(DRAM),因为SRAM具有更快的访问速度,尽管SRAM的成本较高且集成度较低
缓存的设置是现代计算机系统提高性能的关键因素之一。缓存的工作原理是利用程序访问的局部性原理,即程序在一段时间内倾向于访问相对集中的内存区域。通过将频繁使用的数据和指令存储在缓存中,计算机可以减少访问较慢主存(通常使用DRAM)的次数,从而显著提高数据访问速度和整体系统性能
1.2 什么是Web缓存
Web缓存是指存储在Web服务器和客户端(如浏览器)之间的Web资源的副本。它的主要目的是减少网络带宽的使用,提高页面加载速度,减轻服务器负载,并改善用户体验
当用户访问一个网站时,浏览器会根据一定的缓存机制(如HTTP缓存头信息,如Cache-Control、Expires、ETag等)来判断是否可以直接使用本地缓存的资源,还是需要向服务器发送请求以获取最新的资源。如果缓存机制判断资源没有更新(例如,通过比较ETag或Last-Modified时间戳),则浏览器会直接使用本地缓存的副本,从而避免了不必要的网络请求和数据传输
只有当服务器明确标识资源已经更新(例如,通过发送新的ETag值或更新Last-Modified时间戳),浏览器才会发送请求以获取更新的资源。这种机制确保了用户始终能够访问到最新的内容,同时又能充分利用缓存的优势来提高性能
除了浏览器端的缓存,Web缓存还可以存在于其他位置,如代理服务器、CDN(内容分发网络)节点等。这些缓存机制共同工作,以实现更高效的网络通信和更快的Web体验
1.3 Web缓存的种类
1.3.1 客户端缓存
客户端缓存主要是指在用户浏览器中实现的缓存机制,它用于存储用户访问过的Web资源,以便在后续访问时能够快速加载页面
- 浏览器缓存:
- 内存缓存:存储在浏览器的内存中,用于快速访问最近使用的数据。内存缓存通常用于存储体积小的资源,如CSS文件和JavaScript文件
- 磁盘缓存:存储在用户的硬盘上,用于保存体积较大的资源,如图像、视频和其他媒体文件
- 离线缓存:通过Service Workers和Cache API实现,允许网站在用户设备上存储大量数据,即使在离线状态下也能访问
- HTTP缓存:
- 强缓存:通过设置HTTP响应头中的
Cache-Control和Expires字段,浏览器可以直接从本地缓存中加载资源,而无需向服务器发送请求 - 协商缓存:通过设置
Last-Modified和ETag字段,浏览器在发送请求时会带上If-Modified-Since和If-None-Match头,服务器根据这些信息判断资源是否更新,从而决定是否返回新的资源
- 强缓存:通过设置HTTP响应头中的
1.3.2 服务端缓存
服务端缓存主要是指在服务器端实现的缓存机制,它用于存储和复用服务器生成的动态内容,以减轻服务器负载并提高响应速度
- 代理服务器缓存:
- 透明代理缓存:位于客户端和服务器之间,无需客户端或服务器进行任何特别的配置即可工作。它监听和缓存经过它的所有请求
- 反向代理缓存:位于服务器端,通常用于缓存服务器生成的动态内容。反向代理可以减轻后端服务器的负载,并提供更好的性能
- CDN(内容分发网络)缓存:
- CDN提供商在全球范围内部署了多个缓存服务器,用于存储和分发静态内容,如图像、CSS、JavaScript文件等。CDN可以显著减少内容传输延迟,提高全球用户的访问速度
- 应用层缓存:
- 在应用程序内部实现的缓存机制,可以缓存计算结果、会话数据、配置信息等。应用层缓存通常使用内存数据存储,如Redis、Memcached等
- 网关缓存:
- 网关缓存通常用于企业环境中,它位于内部网络和互联网之间,可以缓存从互联网请求的资源,减少对外部网络的依赖
1.4 为什么要用浏览器缓存
- 减少服务器负载:当浏览器缓存了网页资源后,用户在下次访问相同页面时,可以直接从本地缓存加载这些资源,而不需要再次从服务器请求。这样可以显著减少服务器的请求次数,减轻服务器的负载
- 提高页面加载速度:从本地缓存加载资源比从服务器下载要快得多。这意味着网页可以更快地显示内容,从而提升用户体验
- 节省带宽:由于资源是从本地缓存而非服务器加载,因此可以减少网络传输的数据量,节省带宽资源
- 减少延迟:从本地缓存加载资源可以减少因网络延迟导致的加载时间,特别是在移动设备或网络条件较差的环境中
1.5 浏览器缓存的执行流程
我们先来认识下HTTP协议中和页面缓存相关的字段
| Header | 说明 |
|---|---|
| Expires | 指定缓存资源的过期日期和时间。浏览器在请求资源时,会检查当前时间是否超过了Expires中指定的时间。如果超过了,则认为缓存已过期,需要重新从服务器获取资源 |
| Cache-Control | 设置和缓存相关的配置信息。这是一个更灵活和强大的缓存控制机制,可以设置多种指令,如max-age(资源在缓存中有效的秒数)、no-cache(每次使用资源前都需要重新验证)、no-store(禁止缓存)、public(缓存对所有用户可见)、private(缓存仅对单个用户可见)等。 |
| Last-Modified | 指示资源的最后修改时间。浏览器在下次请求资源时,可以发送一个If-Modified-Since头部,包含上次获取资源的Last-Modified值。服务器会检查资源是否在指定时间后修改过,如果没有修改,则返回304 Not Modified状态码,浏览器可以使用本地缓存;如果修改过,则返回最新的资源 |
| ETag | 请求变量的实体标签的当前值,通常是一个资源的唯一标识符,如文件的MD5值或哈希值。类似于Last-Modified,浏览器在下次请求时可以发送一个If-None-Match头部,包含上次获取资源的ETag值。服务器会检查资源的ETag是否与指定值匹配,如果不匹配,则返回最新的资源;如果匹配,则返回304 Not Modified状态码,浏览器可以使用本地缓存 |
以下是浏览器缓存的执行流程示意图
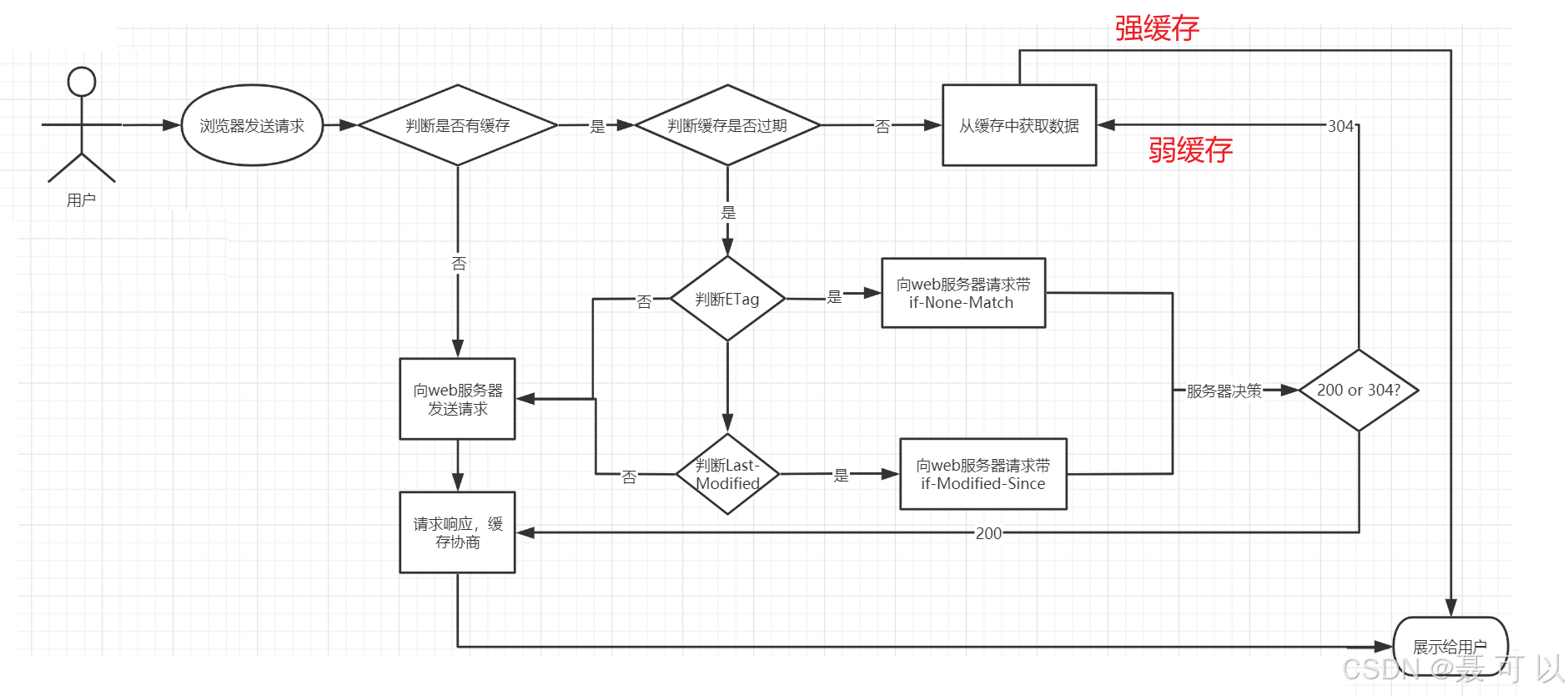
- 首次请求:用户通过浏览器首次请求某个资源,此时浏览器中没有该资源的缓存,因此需要向服务器发送请求
- 服务器响应:服务器接收请求后,返回资源以及相应的HTTP响应头,包括缓存相关信息(如
Expires,Cache-Control,ETag,Last-Modified等)。浏览器将这些信息存储在缓存中 - 重复请求:当用户再次请求同一资源时,浏览器首先检查本地缓存中是否有该资源的副本
- 缓存命中:如果找到了缓存副本,浏览器会检查缓存是否过期(例如,通过
Expires或Cache-Control中的max-age) - 缓存有效:如果缓存未过期,浏览器直接从缓存中读取资源,无需再向服务器发送请求
- 缓存过期:如果缓存过期,浏览器需要进一步检查资源是否在服务器上有更新
- 验证更新:浏览器可以通过发送带有
ETag或Last-Modified头的条件请求(如If-None-Match或If-Modified-Since)来询问服务器资源是否有更新 - 资源未变:如果服务器确认资源自缓存以来未更改,它会返回304 Not Modified状态码,指示浏览器继续使用缓存中的版本
- 资源已变:如果资源有更新,服务器将返回新的资源以及相应的HTTP响应头,浏览器会将新资源存储在缓存中以供未来使用
1.6 浏览器强缓存和弱缓存的区别
视频教程:28-浏览器强缓存和弱缓存的效果演示
强缓存和弱缓存的区别可以参考本文的 浏览器缓存的执行流程 示意图
1.6.1 强缓存(Strong Cache)
强缓存是指当缓存未过期时,浏览器直接从本地读取缓存,不会向服务器发送请求
强缓存主要通过以下HTTP头部字段来控制:
- Expires:指定缓存资源失效的日期和时间。当当前时间小于Expires值时,缓存有效
- Cache-Control:提供更细粒度的缓存控制
max-age:缓存资源在客户端缓存的最大时间(秒)no-cache:表示不使用本地缓存,每次请求都需要向服务器发送请求以验证缓存no-store:表示不存储任何缓存must-revalidate:表示资源在过期前可以命中强缓存,过期后必须向服务器发送请求以验证缓存
1.6.2 弱缓存(Weak Cache)
弱缓存是指当缓存过期后,浏览器会向服务器发送请求以验证缓存是否仍然有效
弱缓存主要通过以下HTTP头部字段来控制:
- Last-Modified: 表示资源最后修改的时间
- ETag: 资源的实体标签,通常是资源的唯一标识符,用于验证资源是否发生变化
- If-Modified-Since: 请求头部字段,用于发送Last-Modified值,询问服务器资源是否在此时间之后有修改
- If-None-Match: 请求头部字段,用于发送ETag值,询问服务器资源是否与此ETag不匹配
当弱缓存命中时,浏览器会发送带有If-Modified-Since或If-None-Match头的请求到服务器。服务器会根据这些头部字段检查资源是否有更新:
- 如果资源未发生变化(Last-Modified未更新或ETag未更改),服务器返回304 Not Modified状态码,浏览器继续使用本地缓存
- 如果资源已发生变化,服务器返回新的资源内容,浏览器更新本地缓存
弱缓存机制允许服务器控制缓存的有效性,确保用户始终获取最新的资源,同时减少了不必要的数据传输
2. Nginx中与浏览器缓存相关的指令
如果需要利用Nginx进行浏览器缓存的相关设置,就需要用到如下指令
2.1 expires指令
expires指令用来控制页面缓存的作用,可以通过expires指令控制HTTP响应头中的Expires和Cache-Control字段
| 语法 | 默认值 | 位置 |
|---|---|---|
| expires [modified] time; | expires off; | http、server、location |
| expires epoch | max | off; |
| 参数 | 描述 |
|---|---|
| time | 可以是整数或负数,指定资源的过期时间(以秒为单位)。如果是负数,Cache-Control 将被设置为 no-cache;如果是0,Cache-Control 将被设置为 max-age=time |
| epoch | 将 Expires 设置为 1970-01-01 00:00:01 GMT,并将 Cache-Control 设置为 no-cache |
| max | 将 Expires 设置为 2037-12-31 23:59:59 GMT,并将 Cache-Control 设置为 max-age=315360000(大约10年) |
| off | 默认不缓存 |
2.2 add_header指令(Cache-Control)
add_header指令用于添加指定的响应头和响应值
| 语法 | 默认值 | 位置 |
|---|---|---|
| add_header name value [always]; | — | http、server、location |
Cache-Control作为响应头信息,可以设置如下值
Cache-control: must-revalidate
Cache-control: no-cache
Cache-control: no-store
Cache-control: no-transform
Cache-control: public
Cache-control: private
Cache-control: proxy-revalidate
Cache-Control: max-age=<seconds>
Cache-control: s-maxage=<seconds>
| 指令 | 说明 |
|---|---|
| must-revalidate | 缓存必须在使用之前验证其有效性,如果资源已过期,则必须重新从源服务器获取 |
| no-cache | 缓存前必须先验证资源的有效性,如果资源已过期,则必须重新从源服务器获取 |
| no-store | 不缓存请求或响应的任何部分,确保敏感信息不会被存储在缓存中 |
| no-transform | 代理服务器不得更改响应的内容格式,例如不得压缩或转换媒体类型 |
| public | 响应可以被任何缓存存储,包括中间代理和客户端缓存 |
| private | 响应只能被特定用户缓存,不能被共享缓存(如代理服务器)存储 |
| proxy-revalidate | 要求中间缓存服务器在提供缓存之前必须重新验证响应的有效性 |
| max-age=<秒> | 指定响应的最大缓存时间(以秒为单位),如果响应的 Age 大于 max-age,则缓存必须视为过期 |
| s-maxage=<秒> | 类似于 max-age,但仅适用于共享缓存(如代理服务器),对私有缓存无效 |
3. Nginx的跨域问题
3.1 本域和同源策略
同源策略规定,一个域下的 JavaScript 脚本不能直接访问或读取另一个域的资源,也不能直接向另一个域发起请求
在了解什么是跨域之前,我们需要先了解两个概念:本域和同源策略
- 本域:同协议、同域名、同端口
- 同源策略:为了保护用户隐私和防止恶意网站窃取数据,浏览器默认只允许与本域的接口进行交互

3.2 跨域的概念
当浏览器发出一个请求时,只要请求URL的协议、域名、端口三者之间任意一个与当前页面URL不同,就称为跨域
| 当前页面URL | 请求URL | 是否跨域 | 原因 |
|---|---|---|---|
| http://www.test.com | http://www.test.com/index.html | 否 | 同源(协议、域名、端口都相同) |
http😕/www.test.com | https😕/www.test.com/index.html | 是 | 协议不同 |
http://www.test.com | http://www.baidu.com | 是 | 域名不同 |
http://www.test.com:8080 | http://www.test.com:8088 | 是 | 端口不同 |
3.3 跨域问题案例演示
本次演示使用的是Windows操作系统,在Linux操作系统上的操作步骤相差无几
出现跨域问题会发生什么呢,我们通过一个案例演示一下
3.3.1 新建HTML文件
在nginx的html目录下新建一个名为crossOrigin.html的文件
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>跨域问题演示</title><script src="https://unpkg.com/axios@1.9.0/dist/axios.min.js"></script><style>body {margin: 0;padding: 0;box-sizing: border-box;font-family: 'PingFang SC', 'Microsoft YaHei', sans-serif;background-color: #f5f7fa;display: flex;justify-content: center;align-items: center;min-height: 100vh;padding: 20px;}.container {background-color: white;border-radius: 12px;box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1);padding: 40px;text-align: center;}button {background-color: #007bff;color: white;border: none;padding: 10px 20px;border-radius: 5px;cursor: pointer;transition: background-color 0.3s ease;}button:hover {background-color: #0056b3;}.result {margin-top: 20px;padding: 15px;background-color: #e9ecef;border-radius: 5px;display: none; /* Initially hide the result */}</style>
</head>
<body><div class="container"><button id="btn">获取数据</button><div id="result" class="result"></div>
</div><script>document.getElementById('btn').addEventListener('click', function() {const resultElement = document.getElementById('result');resultElement.style.display = 'none'; // Hide result before new requestaxios.get('http://127.0.0.1:6250/getUser').then(function(response) {if (response.data) { // Check if data existsresultElement.textContent = JSON.stringify(response.data, null, 2);resultElement.style.display = 'block'; // Show result only if there is data}}).catch(function(error) {console.error('Error fetching data:', error);});});
</script></body>
</html>
3.3.2 修改nginx.conf文件
在监听80端口的server块中添加以下location块
location /crossorigin {alias html;index crossOrigin.html;
}
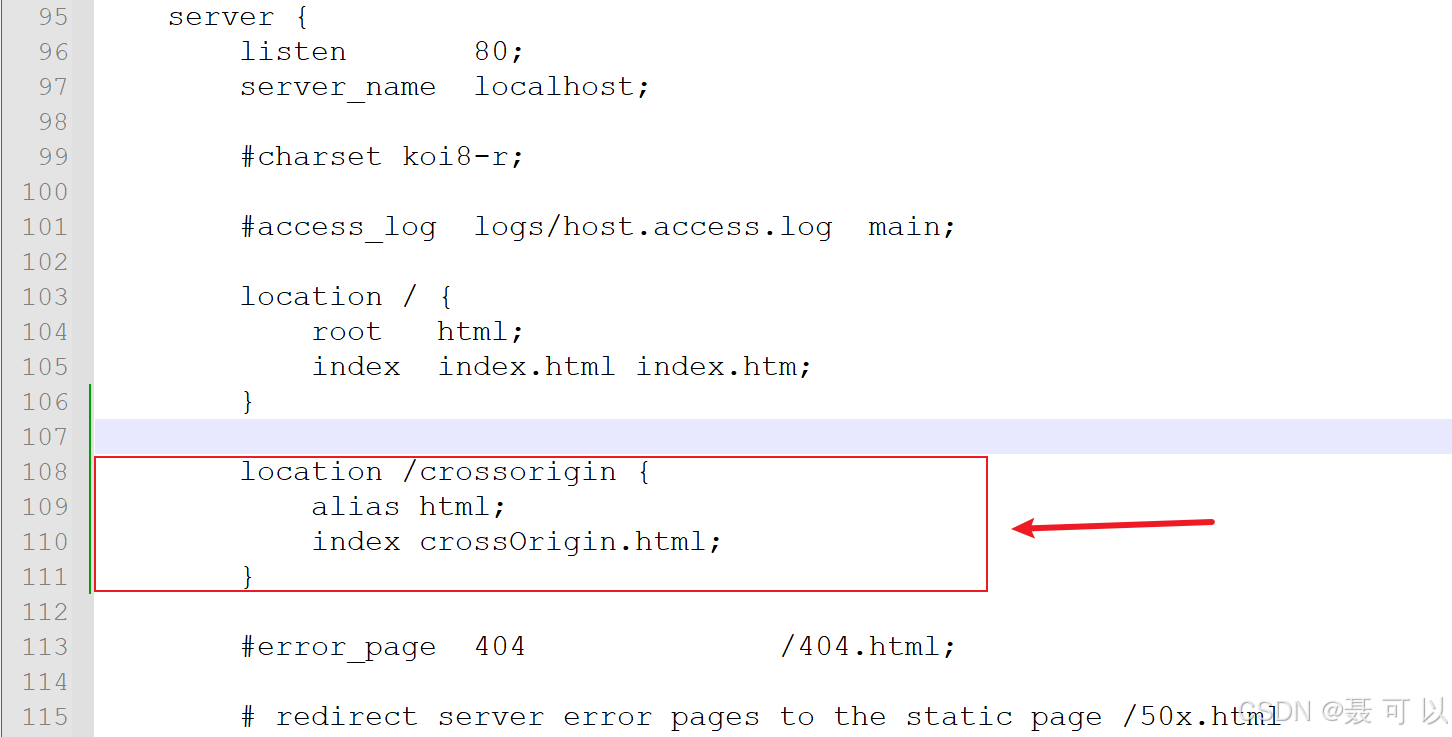
填写一个新的server块(将127.0.0.1改成你的服务器的IP地址)
server {listen 6250;server_name 127.0.0.1;location /getUser {default_type application/json;return 200 '{"id":1,"name":"TOM","age":18}';}
}
修改nginx.conf文件后记得重载配置文件
3.3.3 通过浏览器访问
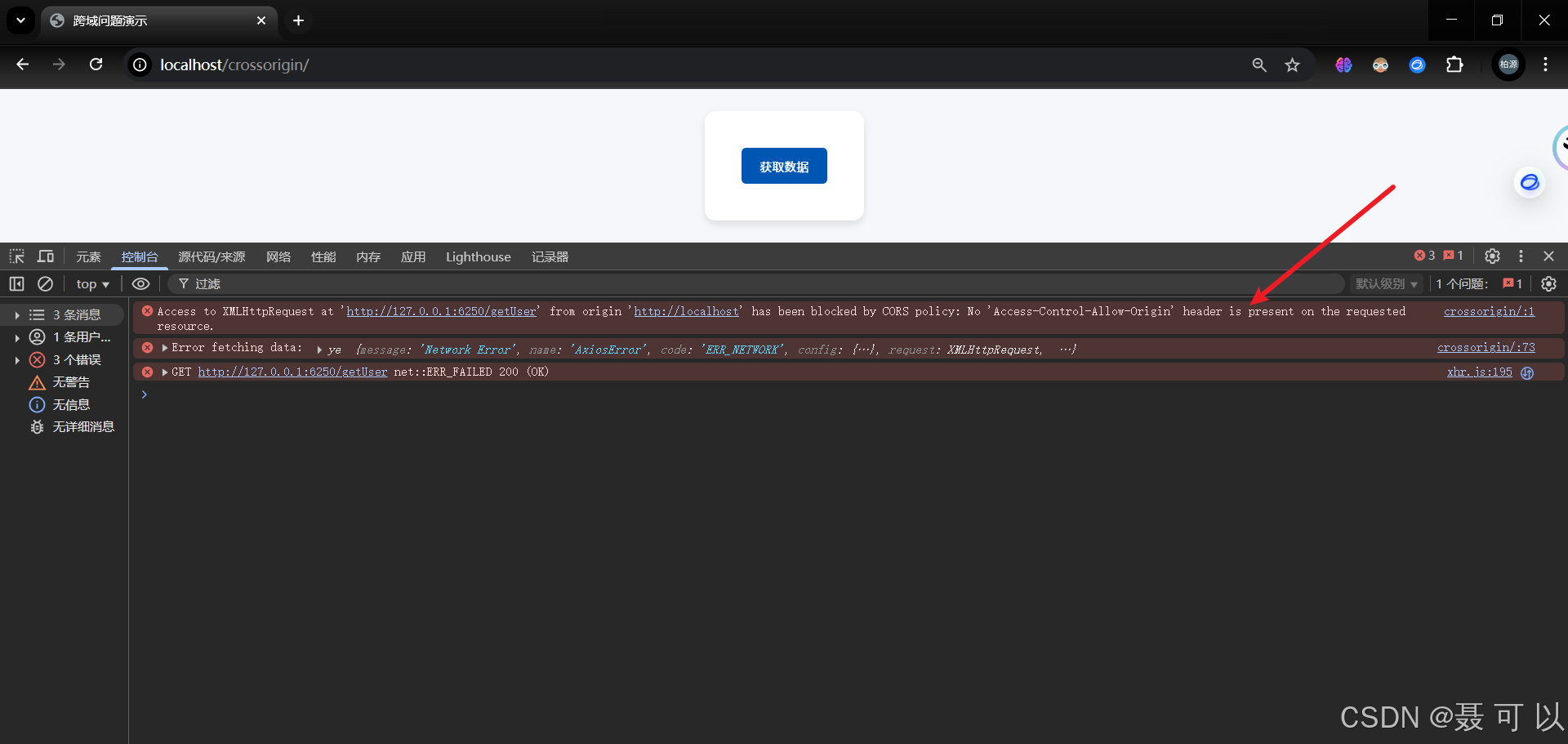
在浏览器访问localhost/crossorigin网址(将localhost改成nginx.conf文件中对应的server_name)
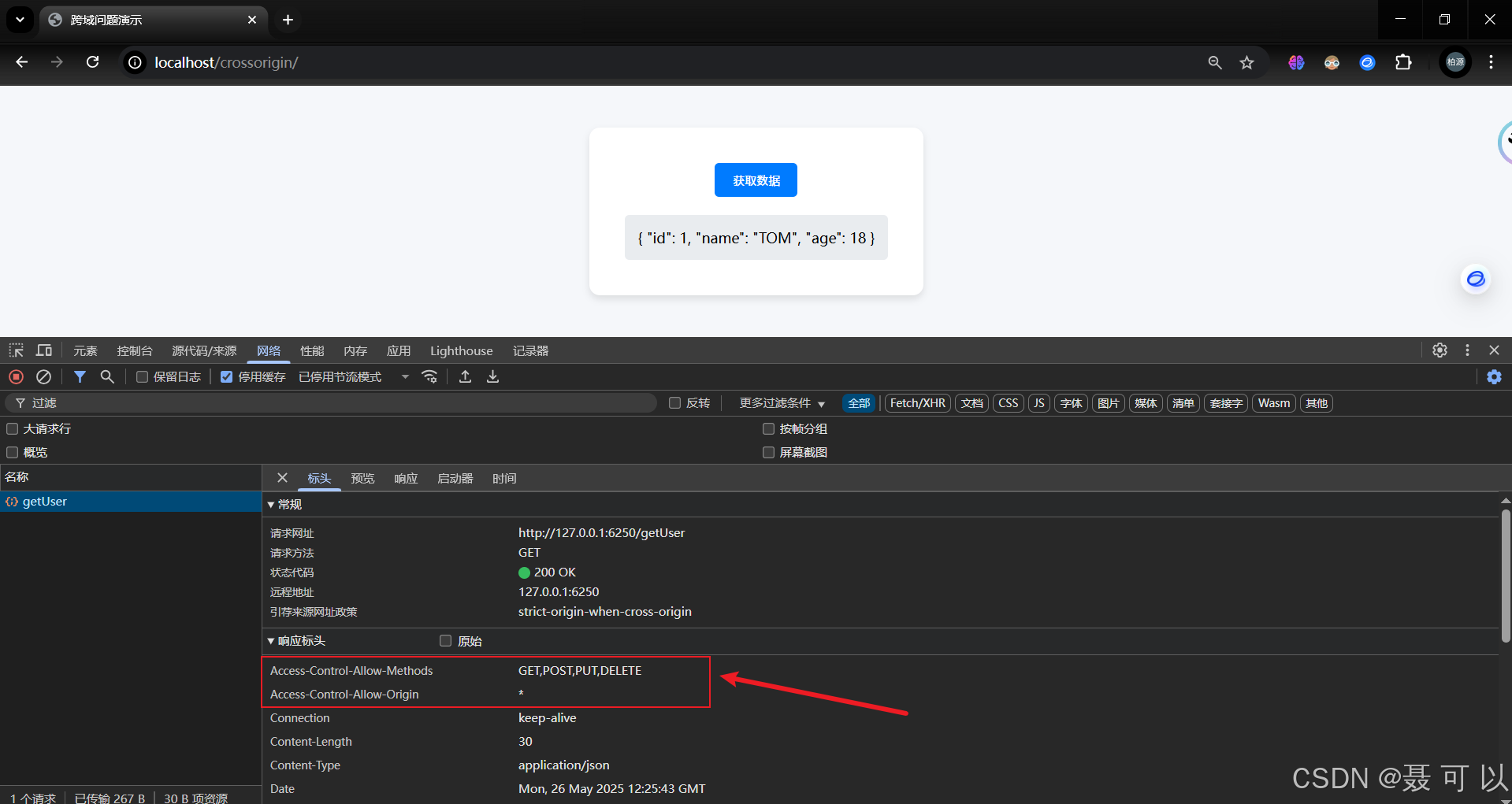
localhost/crossorigin
打开浏览器的控制台后点击获取数据按钮,可以看到控制台出现了Access to XMLHttpRequest at 'http://127.0.0.1:6250/getUser' from origin 'http://localhost' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.信息
3.4 解决方案
使用add_header指令添加一些头信息
| 语法 | 默认值 | 位置 |
|---|---|---|
| add_header name value… | http、server、location |
如果解决跨域问题,需要添加两个头信息,一个是Access-Control-Allow-Origin,另一个是Access-Control-Allow-Methods
Access-Control-Allow-Origin:直译过来是允许跨域访问的源地址信息,可以配置多个(多个用逗号分隔),也可以使用*代表所有源Access-Control-Allow-Methods:直译过来是允许跨域访问的请求方式,值可以为 GET POST PUT DELETE…,可以全部设置,也可以根据需要设置,多个用逗号分隔
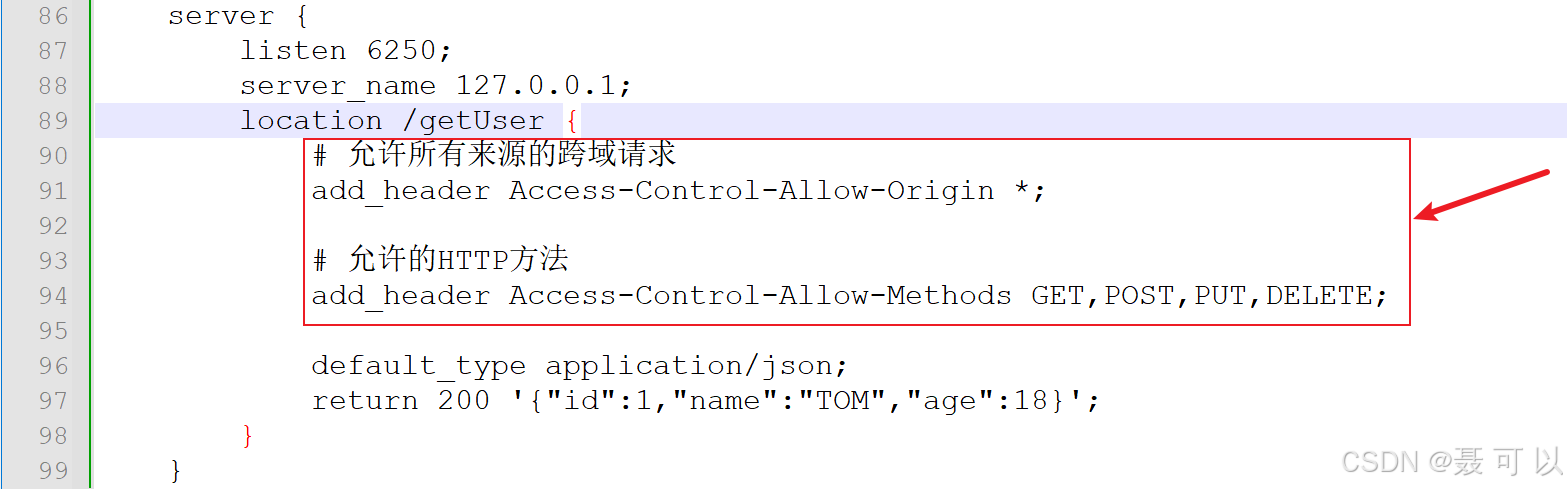
在location块中添加以下信息
# 允许所有来源的跨域请求
add_header Access-Control-Allow-Origin *;# 允许的HTTP方法
add_header Access-Control-Allow-Methods GET,POST,PUT,DELETE;
重载nginx.conf配置文件,再次在浏览器访问localhost/crossorigin网址(将localhost改成nginx.conf文件中对应的server_name)
localhost/crossorigin
可以发现数据已经成功获取了,响应头中也多了Access-Control-Allow-Origin和Access-Control-Allow-Methods两个属性
4. 静态资源防盗链
视频教程:33-Nginx静态资源盗链的效果展示
视频教程中用的是Linux操作系统,本次演示使用的是Windows操作系统,整体步骤相差无几
4.1 什么是资源盗链
资源盗链指的是资源不在自己服务器上,而是通过技术手段,绕过别人的限制,将别人的内容放到自己页面上最终展示给用户,以此来盗取大网站的空间和流量,简而言之就是用别人的东西成就自己的网站
4.2 静态资源防盗链演示
FangDaoLian
在Nginx的html目录下新建一个名为FangDaoLian.html的文件,文件内容如下
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>静态资源防盗链示例</title>
</head>
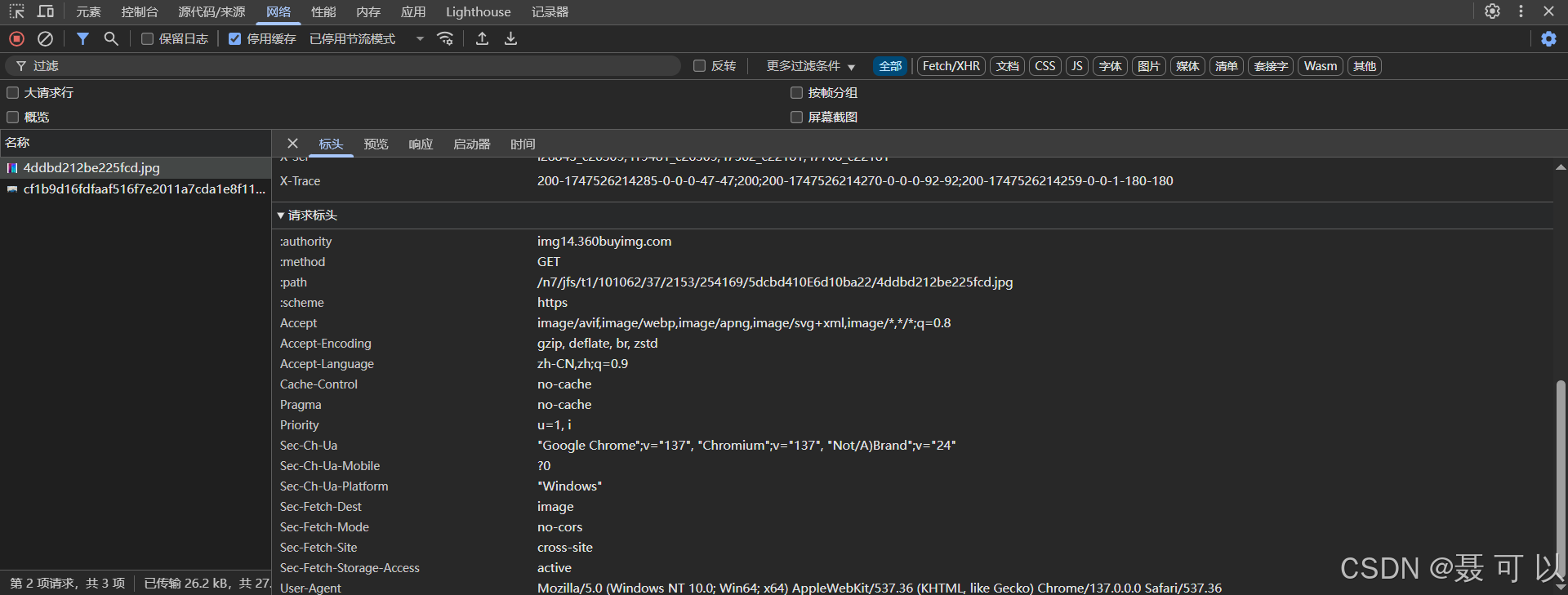
<body><h1>静态资源防盗链示例</h1><p>以下图片来自京东和百度</p><!-- 京东图片 --><h2>京东图片</h2><img src="https://img14.360buyimg.com/n7/jfs/t1/101062/37/2153/254169/5dcbd410E6d10ba22/4ddbd212be225fcd.jpg" alt="京东图片"><!-- 百度图片 --><h2>百度图片</h2><img src="https://pics7.baidu.com/feed/cf1b9d16fdfaaf516f7e2011a7cda1e8f11f7a1a.jpeg?token=551979a23a0995e5e5279b8fa1a48b34&s=BD385394D2E963072FD48543030030BB" alt="百度图片"></body>
</html>
接着往nginx.conf文件中添加以下内容
server {listen 8765;server_name localhost;location / {root html;index FangDaoLian.html;}
}
浏览器访问http://localhost:8765/网址
http://localhost:8765/
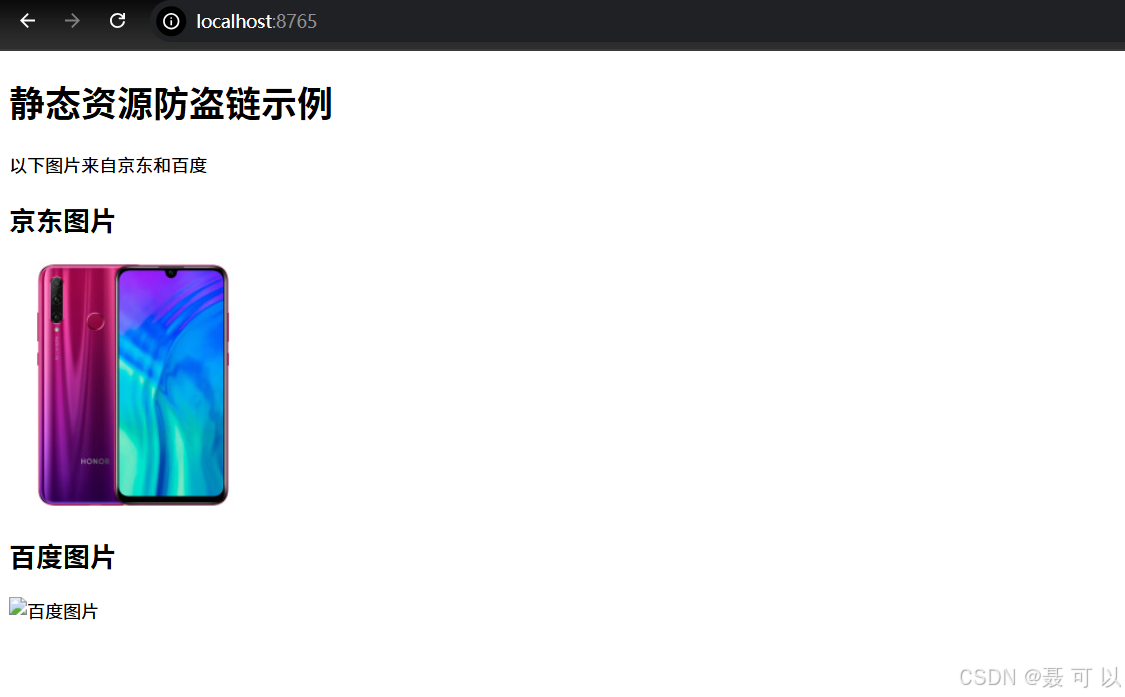
可以发现,京东图片成功显示出来了,而百度图片没有显示出来。按下F12打开浏览器的控制台,可以发现加载百度图片的请求被拒绝了
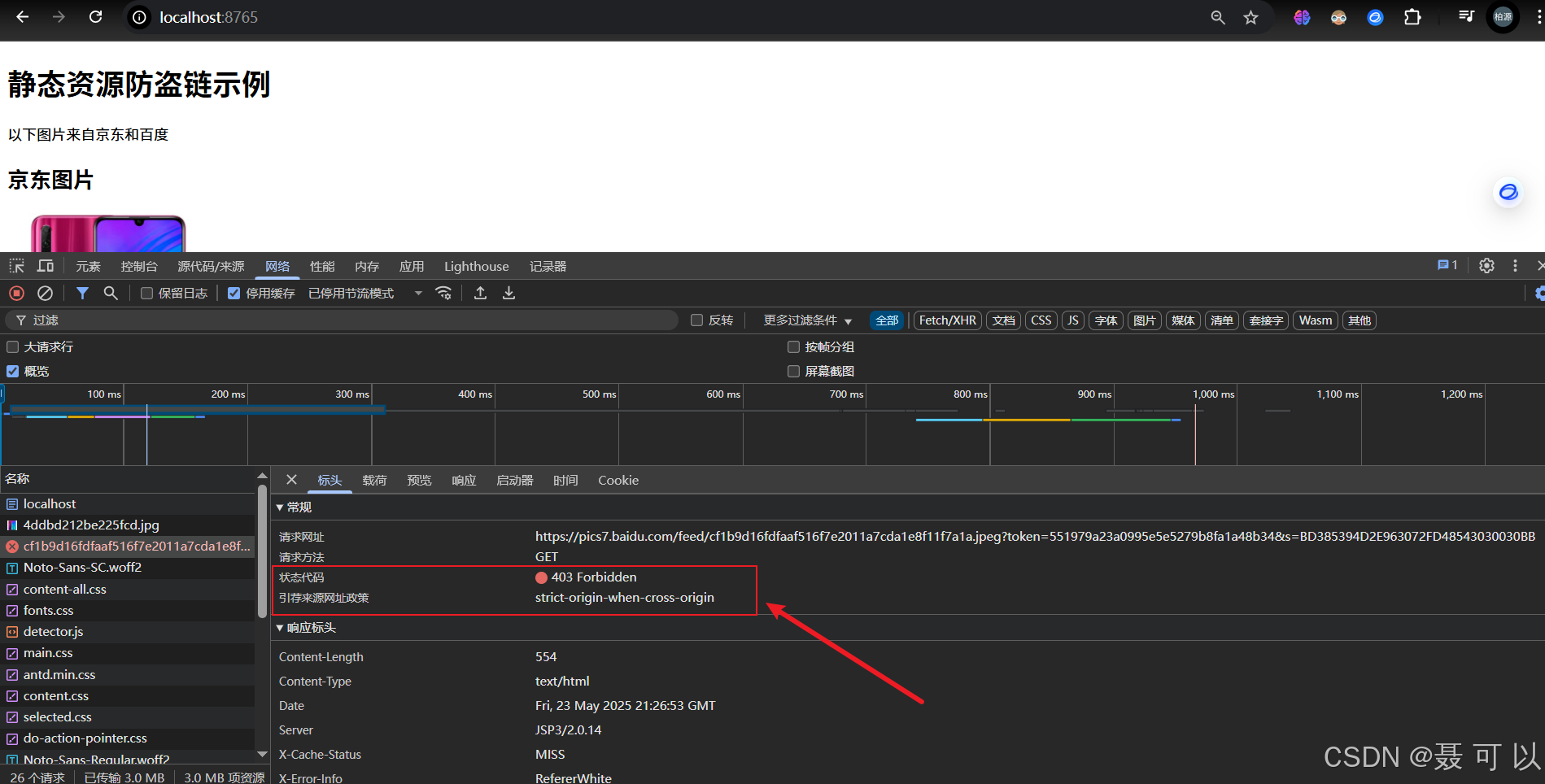
在浏览器中直接输入百度图片的URL,是可以查看到图片的,在本地的HTML文件中引入百度图片也可以查看,但是通过Nginx访问HTML文件后百度的图片就不显示了,说明百度图片确实做了防盗链处理
4.3 防盗链的实现原理
4.3.1 Referer请求头
在了解防盗链的实现原理之前,我们需要先学习一个名为Referer的HTTP的头信息。当浏览器向web服务器发送请求的时候,一般都会带上Referer请求头,告诉服务器该请求是从哪个页面链接过来的
我们访问CSDN官网,按下F12快捷键打开浏览器控制台,打开网络一栏后,刷新页面,查看某个请求的标头信息,可以看到请求携带的Referer信息(CSDN上的图片也做了防盗链处理)
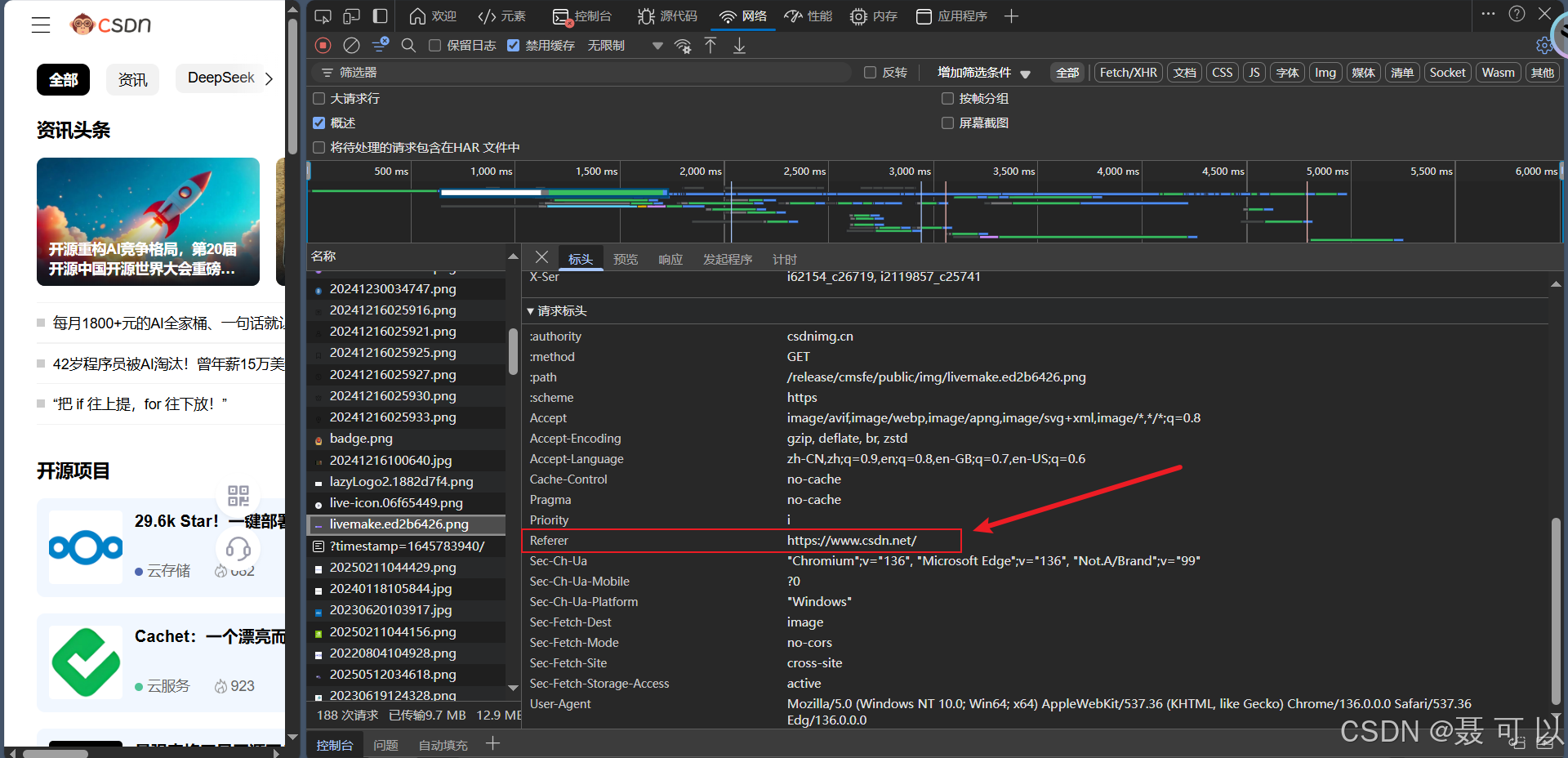
在本地直接打开HTML文件时,如果HTML文件发起请求获取网络资源文件,请求中不会有Referer头信息,可以用本文的静态资源防盗链演示章节提供的FangDaoLian.html文件进行测试
后台服务器可以根据获取到Referer信息来判断请求是否来源于信任的网站
- 如果请求来源于信任的网站,则放行请求
- 如果请求不是来源于信任的网站,则返回403(服务端拒绝访问)状态码
4.3.2 valid_referers指令
nginx会自动将referer请求头和valid_referers后面的内容进行匹配,如果匹配到了就将$invalid_referer变量置0,如果没有匹配到,则将·$invalid_referer·变量置为1,匹配的过程中不区分大小写
| 语法 | 默认值 | 位置 |
|---|---|---|
| valid_referers none | blocked | server_names | string … | server、location |
-
none:如果Header中的Referer为空,允许访问
-
blocked:在Header中的Referer不为空,但是该值被防火墙或代理进行伪装过,如不带"http://" 、"https://"等协议头的资源,允许访问
-
server_names:指定具体的域名或者IP
-
string:支持正则表达式和*的字符串,如果是正则表达式,需要以
~开头表示
示例如下
# 定义一个location块,匹配以.png、.jpg或.gif结尾的URL路径
location ~* \.(png|jpg|gif)$ {# 设置允许的引用来源列表valid_referers none blocked www.baidu.com 192.168.200.222 www.example.org;# 如果请求的Referer不在允许列表中($invalid_referer为真)if ($invalid_referer) {# 返回403 Forbidden状态码,拒绝访问return 403;}# 设置根目录为/usr/local/nginx/htmlroot /usr/local/nginx/html;
}
4.3.3 实战案例
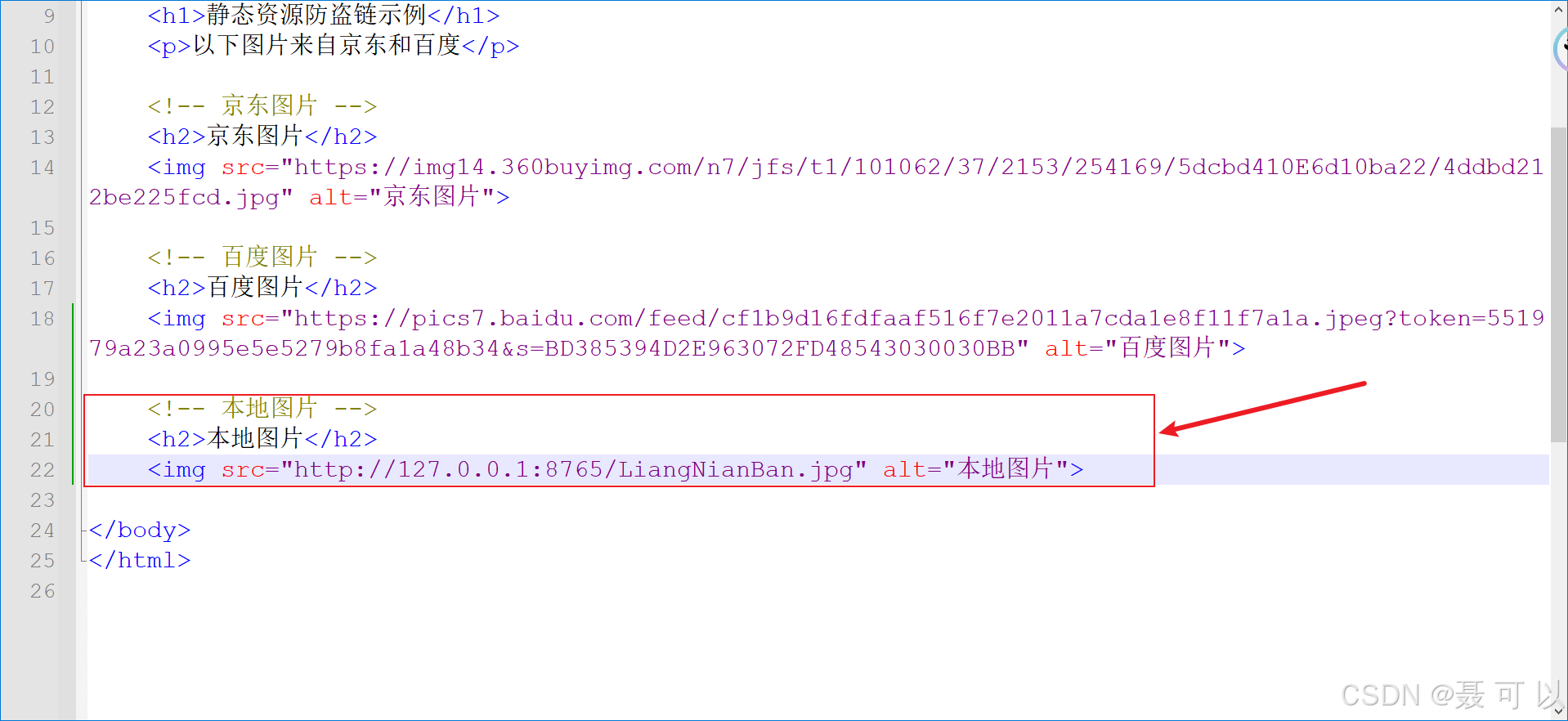
我们动手实现一下防盗链,在FangDaoLian.html文件中新增一个img标签
<!-- 本地图片 -->
<h2>本地图片</h2>
<img src="http://127.0.0.1:8765/LiangNianBan.jpg" alt="本地图片">
在nginx的html目录下新建一个名为images的目录,将以下图片粘贴到images目录中,并将图片命名为LiangNianBan.jpg
LiangNianBan.jpg

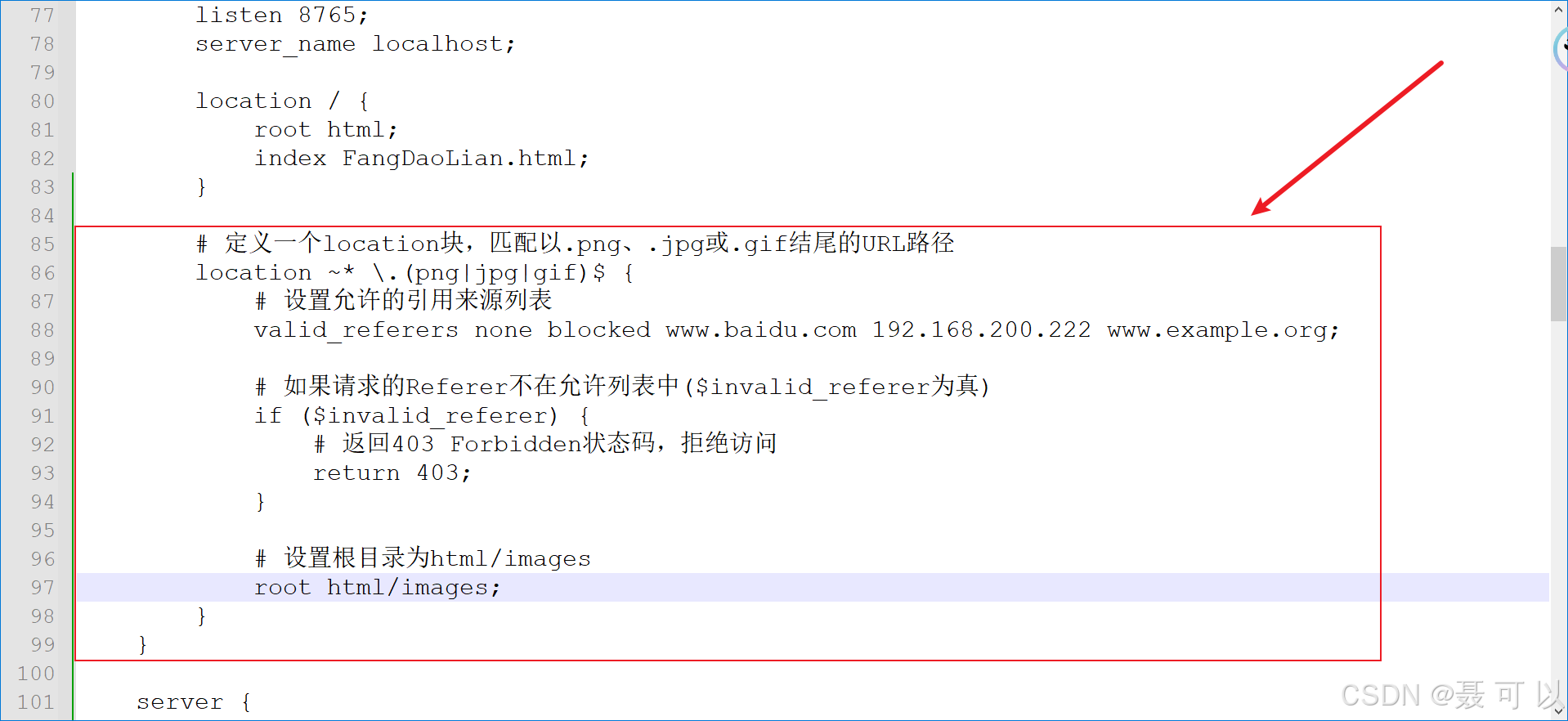
在location块中添加防盗链相关的内容
# 定义一个location块,匹配以.png、.jpg或.gif结尾的URL路径
location ~ \.(png|jpg|gif)$ {# 设置允许的引用来源列表valid_referers none blocked www.baidu.com 192.168.200.222 www.example.org;# 如果请求的Referer不在允许列表中(invalid_referer为真)if ($invalid_referer) {# 返回403 Forbidden状态码,拒绝访问return 403;}# 设置根目录为html/imagesroot html/images;
}
添加完成后重载nginx.conf配置文件
浏览器直接访问localhost:8765/LiangNianBan.jpg网址,图片能够正常显示
localhost:8765/LiangNianBan.jpg
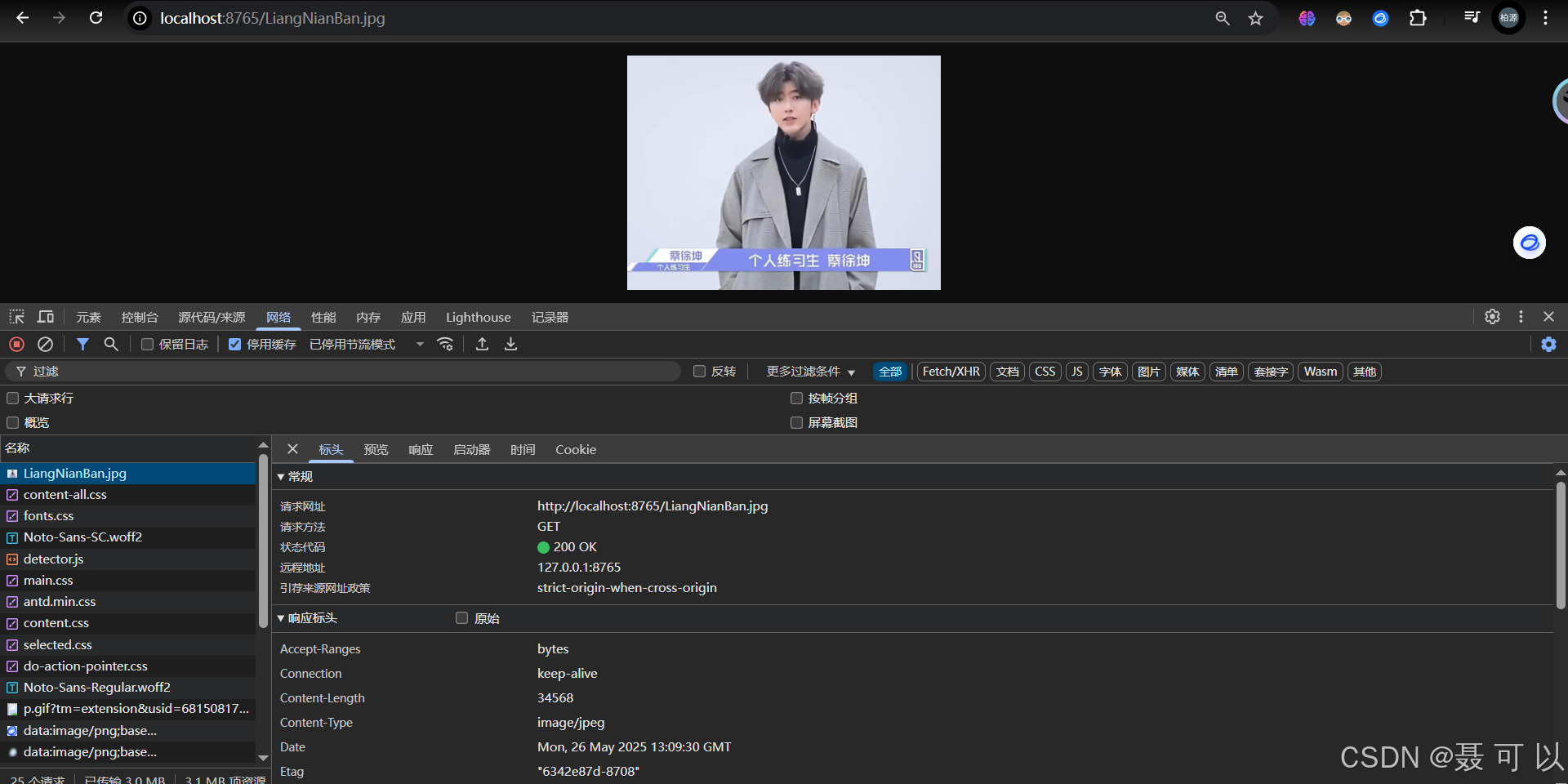
如果访问http://localhost:8765/网址,通过nginx返回的HTML文件间接访问图片文件,可以发现图片加载不出来了
http://localhost:8765/
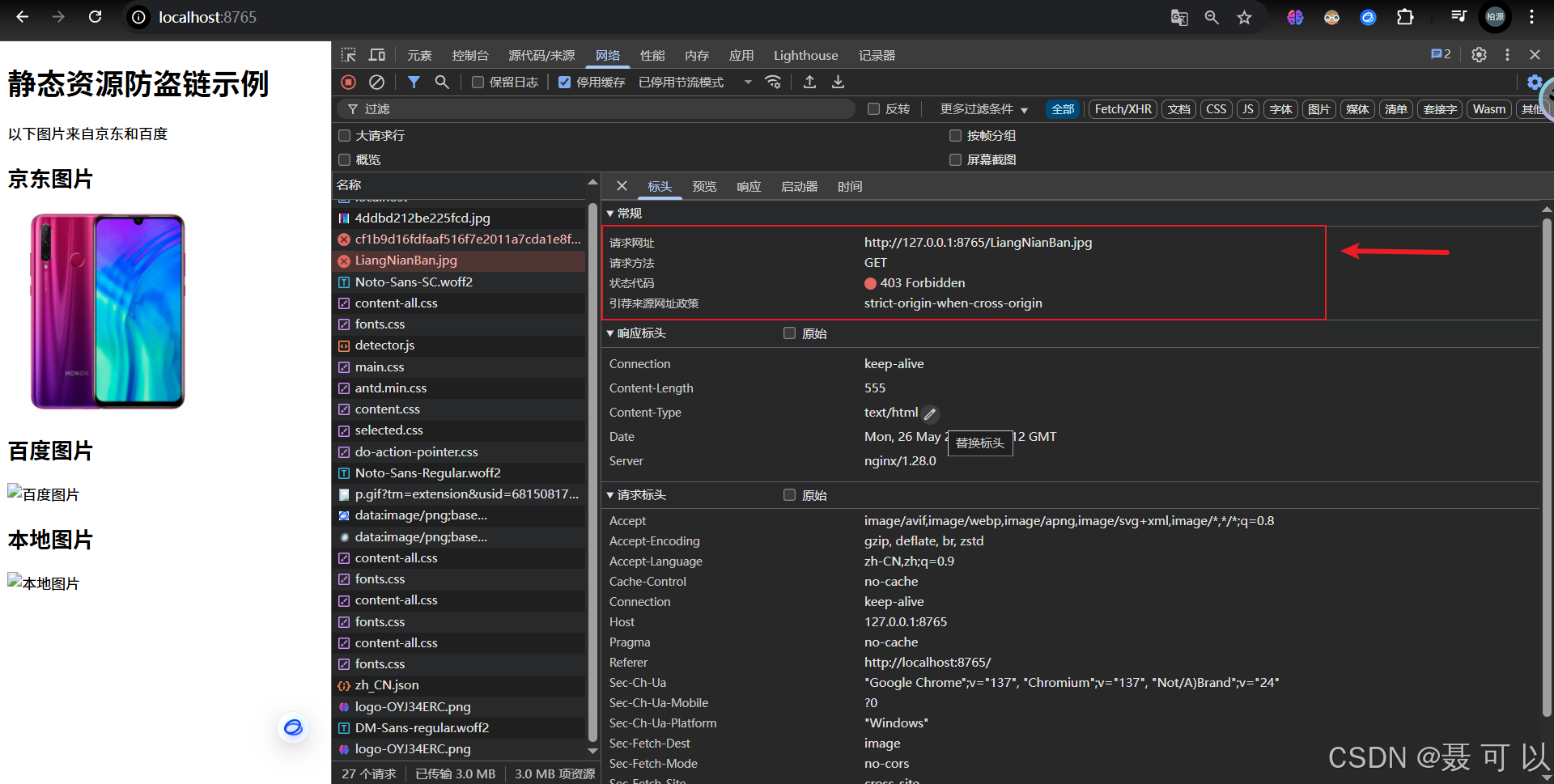
如果在valid_referers中添加localhost域名,可以发现图片能够显示出来了
注意:localhost和127.0.0.1在nginx.conf文件中并不等价
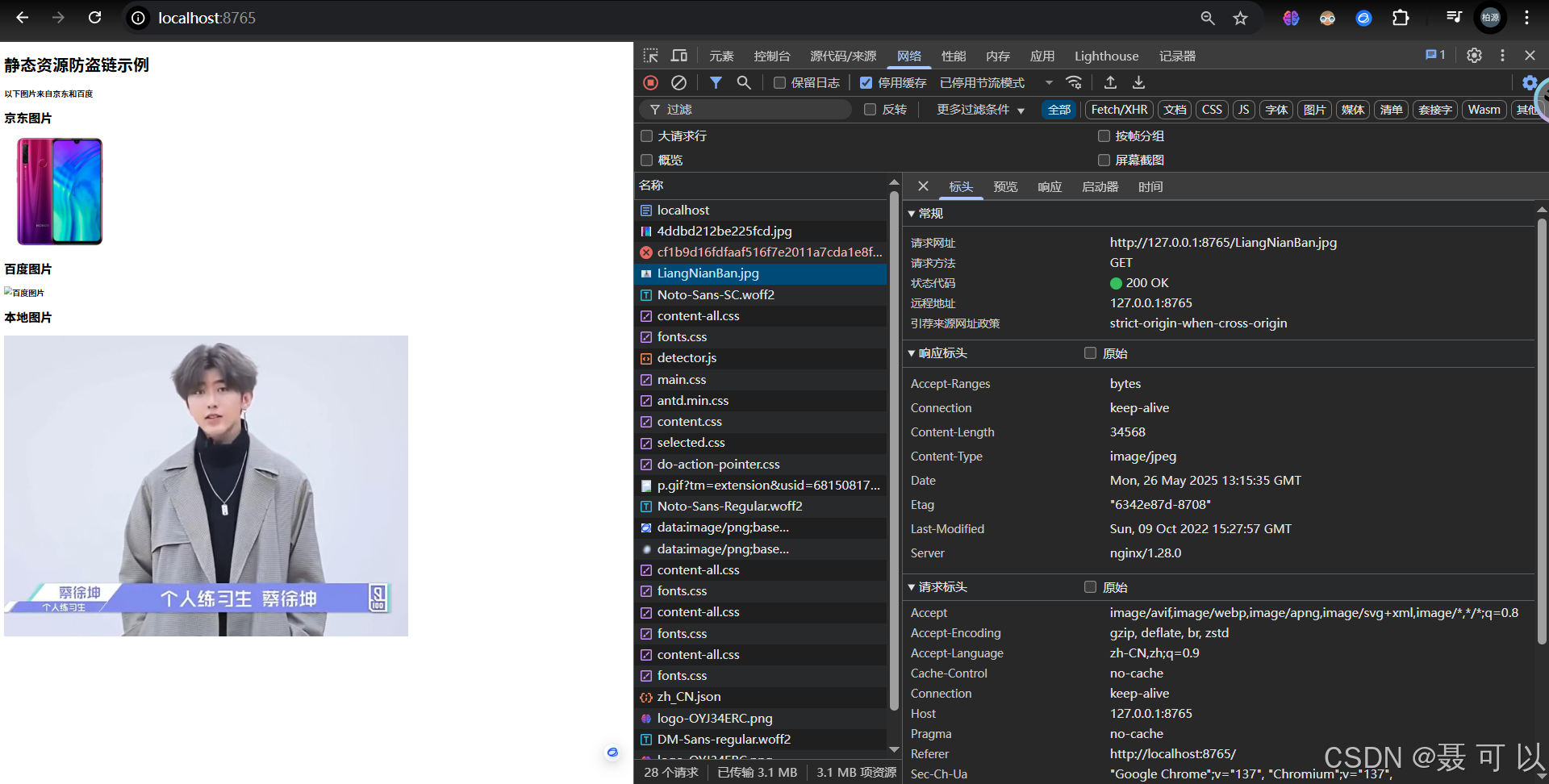
4.4 针对目录进行防盗链
如果有很多图片,或者说是有很多静态资源,该如何批量进行防盗链呢
location /images {valid_referers none blocked www.baidu.com 192.168.200.222;if ($invalid_referer){return 403;}root /usr/local/nginx/html;
}
这样我们可以对一个目录下的所有资源进行防盗链操作,但是Referer的限制比较粗,比如随意加一个Referer,上面的方式是无法进行限制的,这个问题改如何解决
此处我们需要用到Nginx的第三方模块ngx_http_accesskey_module实现防盗链,至于如何在Nginx中使用第三方模块的功能,我们在后面的Nginx的模块篇再进行详细的讲解