本篇文章主要讲解 ElasticSearch 中分布式系统的概念,包括节点、分片和并发控制等,同时还会提到分页遍历和深度遍历问题的解决方案。
节点
- 节点是一个 ElasticSearch 示例
- 其本质就是一个 Java 进程
- 一个机器上可以运行多个示例但生产环境推荐只运行一个
- 每一个节点都有名字,通过配置文件配置
- 每一个节点启动后都会分配一个 UID,保存在 data 目录下
Coordinating Node
- 处理请求的节点,叫 Coordinating Node
- 路由请求到正确的节点,例如创建索引的请求,需要路由到 Master
- 所有节点默认都是 Coordinating Node
- 通过将其他类型设置成 False,使其成为 Dedicated Coordinating Node
Data Node
- 可以保存数据的节点,叫做 Data Node
- 节点启动后,默认就是数据节点。可以设置 node.data:false 禁止
- Data Node 的职责
- 保存分片数据。在数据扩展上起到了至关重要的作用(由 Master Node 决定如何把分片分发到数据节点上)
- 通过增加数据节点
- 可以解决数据水平扩展和解决数据单点问题
Master Node
- Master Node 的职责
- 处理创建,删除索引等请求/决定分片被分配到哪个节点 /负责索引的创建与删除
- 维护并且更新 Cluster State
- Master Node 的最佳实践
- Master 节点非常重要,在部署上需要考虑解决单点的问题
- 为一个集群设置多个 Master 节点/每个节点只承担 Master 的单一角色
Master Eligible Nodes
- 一个集群,支持配置多个 Master Eligible 节点。这些节点可以在必要时(如 Master 节点出现故障,网络故障时)参与选主流程,成为 Master 节点
- 每个节点启动后,默认就是一个 Master Eligible 节点
- 可以设置 node.master: false 禁止
- 当集群内第一个 Master Eligible 节点启动时候,它会将自己选举成 Master 节点
选主过程
- 互相 Ping 对方,Node ld 低的会成为被选举的节点
- 其他节点会加入集群,但是不承担 Master 节点的角色。一旦发现被选中的主节点丢失,就会选举出新的 Master 节点
脑裂问题
- Split-Brain,分布式系统的经典网络问题,当出现网络问题,一个节点和其他节点无法连接
- Node 2 和 Node 3 会重新选举 Master
- Node 1 自己还是作为 Master 组成一个集群,同时更新 Cluster State
- 导致 2 个 Master 维护不同的 Cluster State,当网络恢复时,无法选择正确恢复
解决方法
- 限定选举条件,设置 quorum(仲裁),只有当 Master Eligible 节点数大于 quorum 时才能进行选举
- 7.0 后无需配置
分片
Primary Shard
- 分片是 ElasticSearch 分布式存储的基石(主分片 / 副本分片)
- 通过主分片,将数据分布在所有节点上
- Primary Shard 可以将一份索引的数据分散在多个 Data Node 上,实现存储的水平扩展
- 主分片数在索引创建时候指定,后续默认不能修改,如要修改需重建索引
Replica Shard
- 数据可用性
- 通过引入副本分片(Replica Shard)提高数据的可用性。一旦主分片丢失,副本分片可以 Promote 成主分片。副本分片数可以动态调整。每个节点上都有完备的数据。如果不设置副本分片,一旦出现节点硬件故障,就有可能造成数据丢失
- 提升系统的读取性能
- 副本分片由主分片(Primary Shard)同步。通过支持增加 Replica 个数,一定程度可以提高读取的吞吐量
分片数的设定
- 如何规划一个索引的主分片数和副本分片数
- 主分片数过小:例如创建了 1 个 Primary Shard 的 Index。如果该索引增长很快,集群无法通过增加节点实现对这个索引的数据扩展
- 主分片数设置过大:导致单个 Shard 容量很小,引发一个节点上有过多分片,影响性能
- 副本分片数设置过多,会降低集群整体的写入性能
集群健康状态
GET /_cluster/health{"cluster_name" : "lanlance","status" : "green","timed_out" : false,"number_of_nodes" : 2,"number_of_data_nodes" : 2,"active_primary_shards" : 21,"active_shards" : 42,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}
- Green:健康状态,所有的主分片和副本分片都可用
- Yellow:亚健康,所有的主分片可用,部分副本分片不可用
- Red:不健康状态,部分主分片不可用
文档到分片的路由算法
- s h a r d = h a s h ( r o u t i n g ) / 主分片数 shard = hash(routing) / 主分片数 shard=hash(routing)/主分片数
- Hash 算法确保文档均匀分散到分片中
- 默认 routing 值是文档 id
- 可以自行制定 routing 值,与业务逻辑绑定也可以
- 是 Primary Shard 数不能修改的根本原因
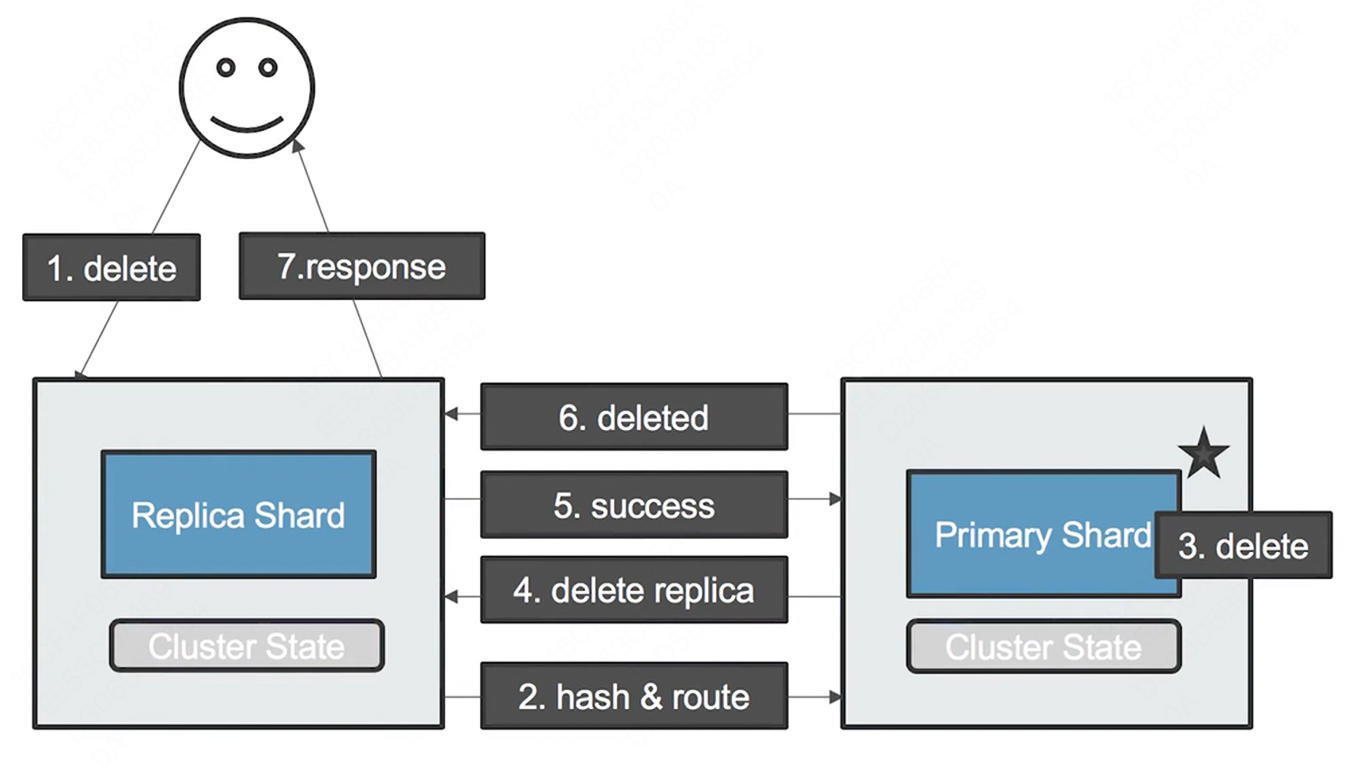
删除一个文档的流程
分片的内部原理
倒排索引的不可变性
倒排索引采用 Immutable Design,一旦生成,不可更改
不可变性,带来了的好处如下:
- 无需考虑并发写文件的问题,避免了锁机制带来的性能问题
- 一旦读入内核的文件系统缓存,便留在哪里。只要文件系统存有足够的空间,大部分请求就会直接请求内存,不会命中磁盘,提升了很大的性能
- 缓存容易生成和维护/数据可以被压缩
但坏处是如果需要让一个新的文档可以被搜索,需要重建整个索引。
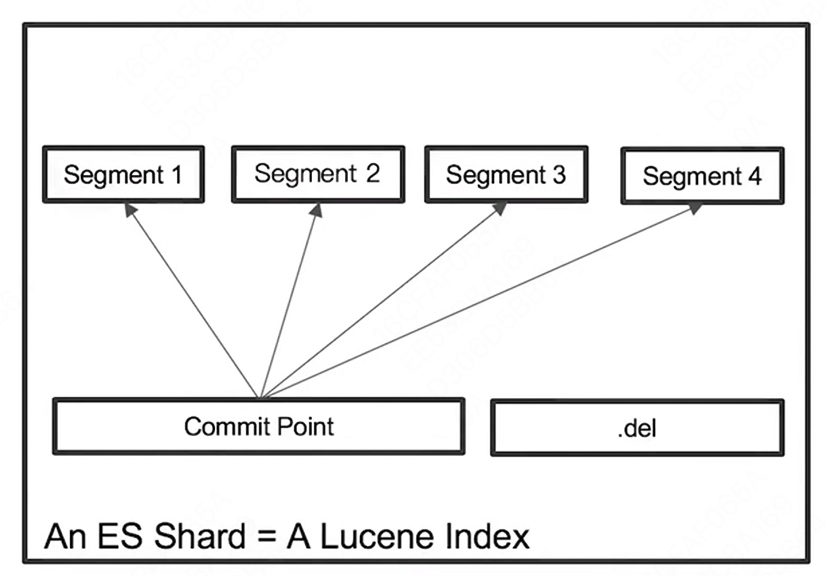
Lucene Index
- 在 Lucene 中,单个倒排索引文件被称为 Segment。Segment 是自包含的,不可变更的。多个 Segments 汇总在一起称为 Lucene 的 Index,其对应的就是 ES 中的 Shard
- 当有新文档写入时,会生成新 Segment,查询时会同时查询所有 Segments,并且对结果汇总。Lucene 中有一个文件用来记录所有 Segments 信息,叫做 Commit Point
Refresh
- 将 Index buffer 写入 Segment 的过程叫 Refresh。Refresh 不执行 fsync 操作
- Refresh 默认 1 秒发生一次,可通过 index.refresh_interval 配置。Refresh 后数据就可以被搜索到了。这也是为什么 ElasticSearch 被称为近实时搜索
- 如果系统有大量的数据写入,那就会产生很多的 Segment
- Index Buffer 被占满时会触发 Refresh,默认值是 JVM 的 10%
Transaction Log
- Segment 写入磁盘的过程相对耗时,借助文件系统缓存,Refresh 时先将 Segment 写入缓存以开放查询
- 为了保证数据不会丢失,所以在 Index 文档时同时写 Transaction Log,高版本开始 Transaction Log 默认落盘。每个分片有一个 Transaction Log
- 在 ES Refresh 时 Index Buffer 被清空,Transaction log 不会清空
Flush
- 调用 Refresh,清空 Index Buffer
- 调用 fsync,将缓存中的 Segments 写入磁盘
- 清空 Transaction Log
默认 30 分钟调用一次,当 Transaction Log 满时(默认 512 MB)也会调用
Merge
- Segment 很多,需要被定期合并
- 减少 Segments / 真正删除已经删除的文档
- ES 和 Lucene 会自动进行 Merge 操作
- POST my_index / _forcemerge
分布式搜索的运行机制
ElasticSearch 的搜索会分为 Query 和 Fetch 两阶段进行。
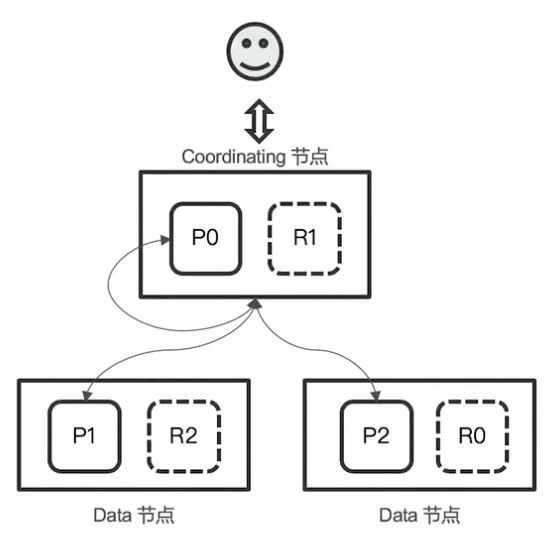
Query
- 用户发出搜索请求到 ES 节点。节点收到请求后,会以 Coordinating 节点的身份,在 6 个主副分片中随机选择 3 个分片,发送查询请求。
- 被选中的分片执行查询,进行排序。每个分片都会返回 From+Size 个排序后的文档 Id 和排序值给 Coordinating 节点。
Fetch
- Coordinating Node 会将 Query 阶段从每个分片获取的排序后的文档 Id 列表重新进行排序。选取 From 到 From+Size 个文档的 Id。
- 以 multiget 请求的方式到相应的分片获取详细的文档数据。
潜在有性能不好和相关性算分不准的问题。
解决算分不准的问题
- 数据量不大的时候主分片数设置为 1,数据量大的时候保证文档均匀分散在各个分片上。
- 使用 DFS Query Then Fetch。会进行一次完整的相关性算法,耗费更多资源,性能不好。
排序
- 排序是针对字段原始内容进行的,倒排索引无法发挥作用,需要正排索引。
- ElasticSearch 中有两种实现方法。
- FieldData
- Doc Values(列式存储,对 Text 类型无效)
Doc Values 和 Field Data 比较:
| 特性 | Doc Values | Field Data |
|---|---|---|
| 存储位置 | 磁盘 (内存映射访问) | 堆内存 (JVM Heap) |
| 加载时机 | 按需加载 (惰性加载到 OS 缓存) | 按需构建 (首次用于聚合/排序时构建在内存中) |
| 数据结构 | 列式存储 (按文档 ID 组织值) | 列式存储 (按段构建) |
| 适用字段 | keyword, numeric, date, ip, boolean | text (默认关闭),其他字段类型 (已废弃) |
| 默认启用 | 是 (对于支持它的字段类型) | 否 (尤其对于 text 字段,7.0+ 默认关闭) |
| 内存占用 | 低 (利用 OS 文件缓存,不直接占用 JVM 堆) | 高 (直接占用 JVM 堆内存) |
| 垃圾回收 | 无影响 (由 OS 管理缓存) | 显著影响 (对象在堆上,易引发 GC 压力) |
| 适用操作 | 聚合、排序、脚本 (高效) | text 字段聚合 (分词后的词条) |
| 安全性 | 高 (不易引发 OOM) | 低 (不当配置易导致节点 OOM) |
| 版本趋势 | 推荐并默认 | 仅限 text 字段聚合需求 (其他字段已弃用) |
分页和遍历
分布式系统中深度分页的问题
- ES 天生就是分布式的。查询信息同时数据保存在多个分片、多台机器上,ES 天生就需要满足排序的需要(按照相关性算分)。
- 当一个查询:From=990,Size =10。会在每个分片上先都获取 1000 个文档。通过 Coordinating Node 聚合所有结果。最后再通过排序选取前 1000 个文档。
- 页数越深,占用内存越多。为了避免深度分页带来的内存开销。ES 有一个设定,默认限定到 10000 个文档。
使用 Search After 避免深度分页问题
- 避免深度分页的性能问题,可以实时获取下一页文档信息
- 不支持指定页数 (From)
- 只能往下翻
- 第一步搜索需要指定 sort,并且保证值是唯一的 (可以通过加入 id 保证唯一性)
- 然后使用上一次最后一个文档的 sort 值进行查询。
示例
1、插入数据
POST users/_doc
{"name":"user1","age":10}
POST users/_doc
{"name":"user2","age":11}
POST users/_doc
{"name":"user2","age":12}
POST users/_doc
{"name":"user2","age":13}
2、执行查询
POST users/_search
{"size": 1,"query": {"match_all": {}},"sort": [{"age": "desc"} ,{"_id": "asc"} ]
}POST users/_search
{"size": 1,"query": {"match_all": {}},"search_after":[10,"ZQ0vYGsBrR8X3IP75QqX"],"sort": [{"age": "desc"} ,{"_id": "asc"} ]
}
Scroll API
Scroll API 是 Elasticsearch 为大数据集深度遍历设计的查询机制,通过创建快照式上下文(Snapshot Context)保证分页一致性,适用于离线导出、全量迁移等场景。
示例
DELETE users
POST users/_doc
{"name":"user1","age":10}
POST users/_doc
{"name":"user2","age":20}
POST users/_doc
{"name":"user3","age":30}
POST users/_doc
{"name":"user4","age":40}POST /users/_search?scroll=5m
{"size": 1,"query": {"match_all" : {}}
}// 这条数据无法查到
POST users/_doc
{"name":"user5","age":50}POST /_search/scroll
{"scroll" : "1m","scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAWAWbWdoQXR2d3ZUd2kzSThwVTh4bVE0QQ=="
}
Scroll API 与 Search After 的对比
| 特性 | Search After | Scroll API |
|---|---|---|
| 设计目标 | 实时深度分页(用户交互场景) | 大数据集离线遍历(导出/迁移) |
| 实时性 | 基于当前索引状态(实时可见变更) | 快照冻结(创建后索引变更不可见) |
| 内存消耗 | 低(无服务端状态) | 高(服务端维护上下文,占用堆内存) |
| 分页一致性 | 依赖 PIT 保障一致性 | 天然一致性(快照隔离) |
| 适用场景 | 用户界面逐页浏览(如订单列表翻页) | 全量数据导出、ETL 迁移、离线分析 |
| 是否支持跳页 | ❌ 仅顺序连续分页 | ❌ 仅顺序连续遍历 |
| 资源释放 | 无状态(客户端自主管理游标) | 需显式删除 Scroll ID(否则超时释放) |
| 性能开销 | 低(分片级游标定位) | 中(维护上下文,但比 from/size 高效) |
| 最大深度 | 仅受文档总数限制 | 同左 |
| 推荐排序方式 | 业务字段 + _id(确保唯一性) | ["_doc"](最高效,避免排序计算) |
| 版本演进 | 主流实时分页方案(结合 PIT 使用) | 逐渐被 Async Search 替代(大数据异步查询) |
并发控制
ES 使用乐观锁进行并发控制。
ES 的乐观并发控制
ES 中的文档是不可变更的。如果你更新一个文档,会将就文档标记为删除,同时增加一个全新的文档。同时文档的 version 字段加 1。
示例
DELETE products
PUT products
PUT products/_doc/1
{"title":"iphone","count":100
}// success
PUT products/_doc/1?if_seq_no=1&if_primary_term=1
{"title":"iphone","count":100
}// fail
PUT products/_doc/1?if_seq_no=1&if_primary_term=1
{"title":"iphone","count":102
}// success
PUT products/_doc/1?version=30000&version_type=external
{"title":"iphone","count":100
}
写在最后
这是该系列的第七篇,主要讲解 ElasticSearch 中分布式系统的概念,包括节点、分片和并发控制等,同时提到了分页遍历和深度遍历问题的解决方案。可以自己去到 Kibana 的 Dev Tool 实战操作,未来会持续更新该系列,欢迎关注👏🏻。
同时欢迎关注小红书:LanLance。不定时分享职场思考、大厂方法论和后端经验❤️
参考
- https://github.com/onebirdrocks/geektime-ELK/
- https://www.elastic.co/elasticsearch/







![[定昌linux开发板]设置密码策略](https://i-blog.csdnimg.cn/direct/b848d84c4aae448a8e818ea0e67a95a9.jpeg)