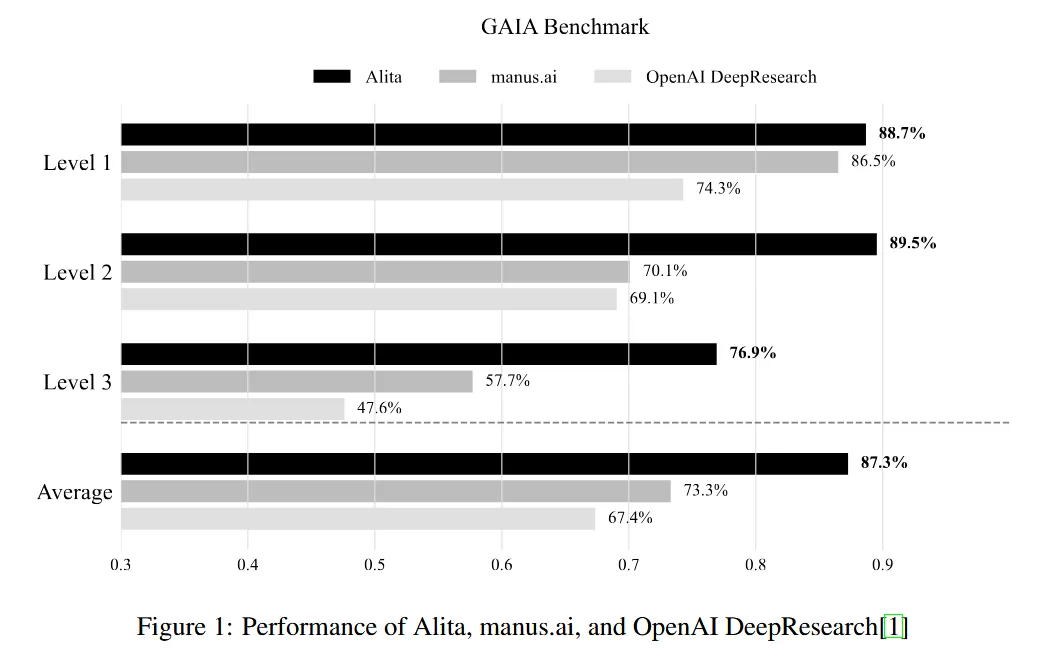
在深度学习模型训练中,学习率调度器(Learning Rate Scheduler)是影响模型收敛效果和训练稳定性的关键因素。选择合适的学习率调度策略,往往能让模型性能产生质的飞跃。本文将深入对比PyTorch中最常用的四种学习率调度器,帮助您在实际项目中做出最佳选择。
为什么需要学习率调度?
学习率是深度学习优化算法中最重要的超参数之一。固定的学习率往往无法在整个训练过程中保持最优效果:
- 训练初期:需要较大的学习率快速逼近最优解
- 训练中期:需要适中的学习率稳定收敛
- 训练后期:需要较小的学习率精细调优
学习率调度器正是为了解决这个问题,通过动态调整学习率来实现更好的训练效果。
四种主流学习率调度器详解
| 调度器 | 工作原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| StepLR | 每隔固定的 step_size 个 epoch,将当前学习率乘以 gamma,学习率呈“阶梯式”下降。 | - 实现简单、衰减时机可预测- 适合在特定训练阶段快速降低学习率 | - 学习率突变可能导致训练不稳定- 需要手动调节衰减点,缺乏自适应性 | - 传统 CNN 训练(如 ResNet、VGG)- 需要在特定里程碑(如第 30、60、90 轮)降低学习率 |
| ExponentialLR | 每个 epoch 都将学习率乘以固定的 gamma,学习率呈平滑的指数下降。 | - 衰减平滑,不会产生骤变- 参数简单,只需调节一个 gamma | - gamma 值难以确定:过小衰减太快,过大衰减太慢- 无法实现阶段性学习率保持 | - 需要平滑指数衰减的模型训练- 快速迭代的小模型实验 |
| CosineAnnealingLR | 使用余弦函数形式进行退火,在一个周期 T_max 内,学习率从初始值平滑下降到 eta_min(默认 0),可配合重启(Warm Restarts)。 | - 退火过程非常平滑,有利于模型收敛- 前期下降较快,后期收敛缓慢- 可配合重启跳出局部最优 | - 需要预先确定周期长度 T_max- 最终学习率会趋近 0,后期可能过慢,需要配合 eta_min 或 Warm Restarts | - 现代深度学习研究中常用- 长期训练需要平滑退火- 与 Warm Restarts 结合进行多周期退火 |
| OneCycleLR | 分两阶段: 升温 (pct_start):LR 从很小值线性上升到 退火:LR 从 | - 集成 Warm-up 和退火优势- 内置 momentum 调度,训练效果更好- 前期大步长跳出局部,后期精细收敛 | - 参数较多:max_lr、total_steps、pct_start、div_factor、final_div_factor 等需调节- 需预先确定总训练步数,不宜中途干预 | - 预训练模型微调、大批量训练- 需要快速收敛、短期内达到最佳效果- 对超参数敏感度要求较低的场景 |
Warm-up预热机制
Warm-up是在训练初期使用较小学习率逐步"预热"到目标学习率的技术,特别适用于大批量训练和Transformer模型。
为什么需要Warm-up?
- 防止梯度爆炸:训练初期模型参数随机,大学习率可能导致梯度过大
- 提高稳定性:缓慢启动有助于模型找到稳定的优化方向
- 适配大批量:大批量训练时warm-up几乎是必需的
实现Warm-up的三种方法
方法1:使用LambdaLR
def create_warmup_scheduler(optimizer, warmup_epochs=5):def lr_lambda(epoch):if epoch < warmup_epochs:return float(epoch + 1) / float(warmup_epochs)return 1.0return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
方法2:使用SequentialLR
from torch.optim.lr_scheduler import SequentialLR, LinearLR, CosineAnnealingLR# Warm-up阶段
warmup_scheduler = LinearLR(optimizer,start_factor=0.1,end_factor=1.0,total_iters=5
)# 主调度器
main_scheduler = CosineAnnealingLR(optimizer,T_max=95
)# 组合调度器
scheduler = SequentialLR(optimizer,schedulers=[warmup_scheduler, main_scheduler],milestones=[5]
)
方法3:自定义调度器类
class WarmupCosineScheduler(torch.optim.lr_scheduler._LRScheduler):def __init__(self, optimizer, warmup_epochs, total_epochs, base_lr, final_lr=0.0, last_epoch=-1):self.warmup_epochs = warmup_epochsself.total_epochs = total_epochsself.base_lr = base_lrself.final_lr = final_lrsuper().__init__(optimizer, last_epoch)def get_lr(self):epoch = self.last_epoch + 1if epoch <= self.warmup_epochs:# 线性升温warmup_factor = epoch / float(self.warmup_epochs)return [self.base_lr * warmup_factor for _ in self.optimizer.param_groups]else:# 余弦退火t = epoch - self.warmup_epochsT = self.total_epochs - self.warmup_epochsreturn [self.final_lr + 0.5 * (self.base_lr - self.final_lr) * (1 + math.cos(math.pi * t / T))for _ in self.optimizer.param_groups]
完整的调度器工厂函数
基于上述分析,这里提供一个完整的调度器创建函数:
def create_scheduler(optimizer, config):"""创建学习率调度器"""if config.lr_schedule == 'step':return torch.optim.lr_scheduler.StepLR(optimizer,step_size=config.lr_step_size,gamma=config.lr_gamma)elif config.lr_schedule == 'exponential':return torch.optim.lr_scheduler.ExponentialLR(optimizer,gamma=config.lr_gamma)elif config.lr_schedule == 'cosine':return torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max=config.lr_cosine_steps,eta_min=config.get('lr_eta_min', 0))elif config.lr_schedule == 'onecycle':return torch.optim.lr_scheduler.OneCycleLR(optimizer,max_lr=config.lr_max,total_steps=config.total_steps,pct_start=config.get('lr_pct_start', 0.3),anneal_strategy=config.get('lr_anneal_strategy', 'cos'),cycle_momentum=config.get('cycle_momentum', True),div_factor=config.get('lr_div_factor', 25.0),final_div_factor=config.get('lr_final_div_factor', 1e4))elif config.lr_schedule == 'warmup_cosine':return WarmupCosineScheduler(optimizer,warmup_epochs=config.warmup_epochs,total_epochs=config.total_epochs,base_lr=config.lr,final_lr=config.get('lr_final', 0.0))else:return None
选择指南:什么时候用哪个调度器?
| 场景 | 推荐调度器 | 理由 |
|---|---|---|
| 传统CNN训练 | StepLR | 经典有效,在关键epoch降低学习率 |
| 快速原型验证 | ExponentialLR | 参数简单,平滑衰减 |
| 现代深度学习研究 | CosineAnnealingLR + Warm-up | 效果最佳,广泛认可 |
| 预训练模型微调 | OneCycleLR | 集成升温退火,快速收敛 |
| 大批量训练 | OneCycleLR 或 Warm-up + 主调度器 | 处理大批量训练的稳定性问题 |
| Transformer训练 | Warm-up + CosineAnnealingLR | Transformer标准做法 |
| 长期训练实验 | CosineAnnealingLR with Restarts | 避免局部最优,持续优化 |
实际训练示例
以下是一个完整的训练循环示例:
import torch
import torch.nn as nn
import torch.optim as optim# 模型和优化器初始化
model = YourModel()
optimizer = optim.AdamW(model.parameters(), lr=1e-3, weight_decay=0.01)# 选择调度器
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer,max_lr=1e-3,epochs=100,steps_per_epoch=len(train_loader),pct_start=0.1,anneal_strategy='cos'
)# 训练循环
for epoch in range(100):model.train()for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# OneCycleLR需要每个batch调用一次if isinstance(scheduler, torch.optim.lr_scheduler.OneCycleLR):scheduler.step()# 其他调度器每个epoch调用一次if not isinstance(scheduler, torch.optim.lr_scheduler.OneCycleLR):scheduler.step()# 记录当前学习率current_lr = optimizer.param_groups[0]['lr']print(f'Epoch {epoch}, LR: {current_lr:.6f}')
调参建议
StepLR调参
step_size:通常设为总epoch数的1/3或1/4gamma:常用值0.1、0.5、0.9
ExponentialLR调参
gamma:建议范围0.95-0.99,需要根据总epoch数调整
CosineAnnealingLR调参
T_max:设为总epoch数或一个周期长度eta_min:可设为初始LR的1/100或0
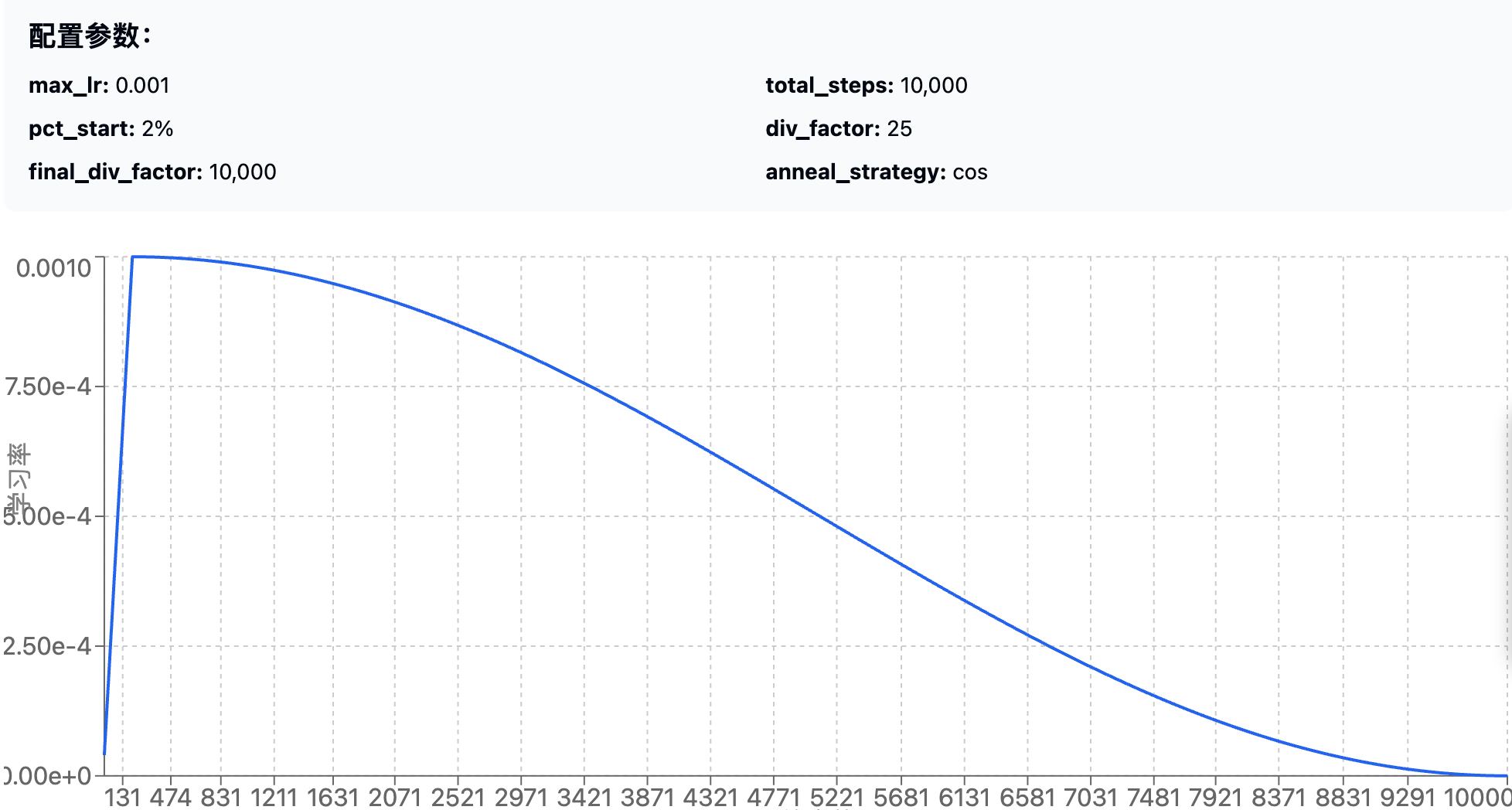
OneCycleLR调参
max_lr:通过LR Range Test确定pct_start:升温阶段占比,通常0.1-0.3div_factor:初始LR倍数,通常10-25
总结
学习率调度器的选择应该基于具体的任务特点、模型架构和训练目标:
- 追求稳定性:选择ExponentialLR或CosineAnnealingLR
- 需要快速收敛:选择OneCycleLR
- 经典CNN训练:选择StepLR
- 现代深度学习:选择CosineAnnealingLR + Warm-up
- 大批量训练:必须考虑Warm-up机制
记住,最佳的学习率调度策略往往需要通过实验验证。建议在新项目中尝试多种调度器,通过验证集性能来选择最适合的方案。
希望本文能帮助您在深度学习项目中选择和使用合适的学习率调度器,实现更好的训练效果!




![[定昌linux开发板]设置密码策略](https://i-blog.csdnimg.cn/direct/b848d84c4aae448a8e818ea0e67a95a9.jpeg)