Arena是Protobuf的C++特有特性,旨在优化内存分配效率,减少频繁的堆内存申请与释放。其核心机制如下:
- 预分配内存:Arena预先分配一大块连续内存(称为Block),对象创建时直接从该内存块中分配,避免了频繁调用new/malloc
- 批量释放:当Arena生命周期结束时,所有分配的内存一次性释放,无需逐个调用析构函数
- 内存复用:内存块不足时,按倍增策略(如初始4KB,最大64KB)扩展新块,减少内存碎片并提升缓存命中率
Arena的优点:
- 性能提升:减少内存分配次数,尤其适合创建大量短生命周期对象(如解析消息、序列化)。连续内存布局提高缓存命中率,加速数据编译
- 内存管理优化:批量释放内存,避免内存泄漏风险。支持跳过析构函数,避免不必要的析构调用
- 线程安全:Arena的分配操作线程安全,但销毁需由单一线程控制
下面通过一个简单的例子大致梳理Arena的源码实现。首先定义一个proto文件person.proto:
syntax = "proto3";
option cc_enable_arenas = true;package tutorial;message Person {int32 id = 1;repeated int32 value = 2;string name = 3;
}上述proto文件大致涵盖了几个常用的数据类型,包括基本数据类型、repeated及string数据类型。基于该proto文件使用protoc生成关于类Person的C++代码。使用Arena构造数据对象的code如下:
int32_t counter = 0;while (!hasTerminationRequested()){google::protobuf::Arena arena(options);tutorial::Person *person = google::protobuf::Arena::CreateMessage<tutorial::Person>(&arena);person->set_id(counter++);person->add_value(counter);person->add_value(counter + 1);person->add_value(counter + 2);person->set_name("helloworld" + std::to_string(counter));std::this_thread::sleep_for(CYCLE_TIME);}Arena负责建立和管理内存池,可以通过Arena对象申请内存池中的内存,在该内存上构造新的protobuf message对象。那么内存池的初始内存是怎么分配的呢?先放一张Arena对象整体管理的内存相关的数据结构示意图:
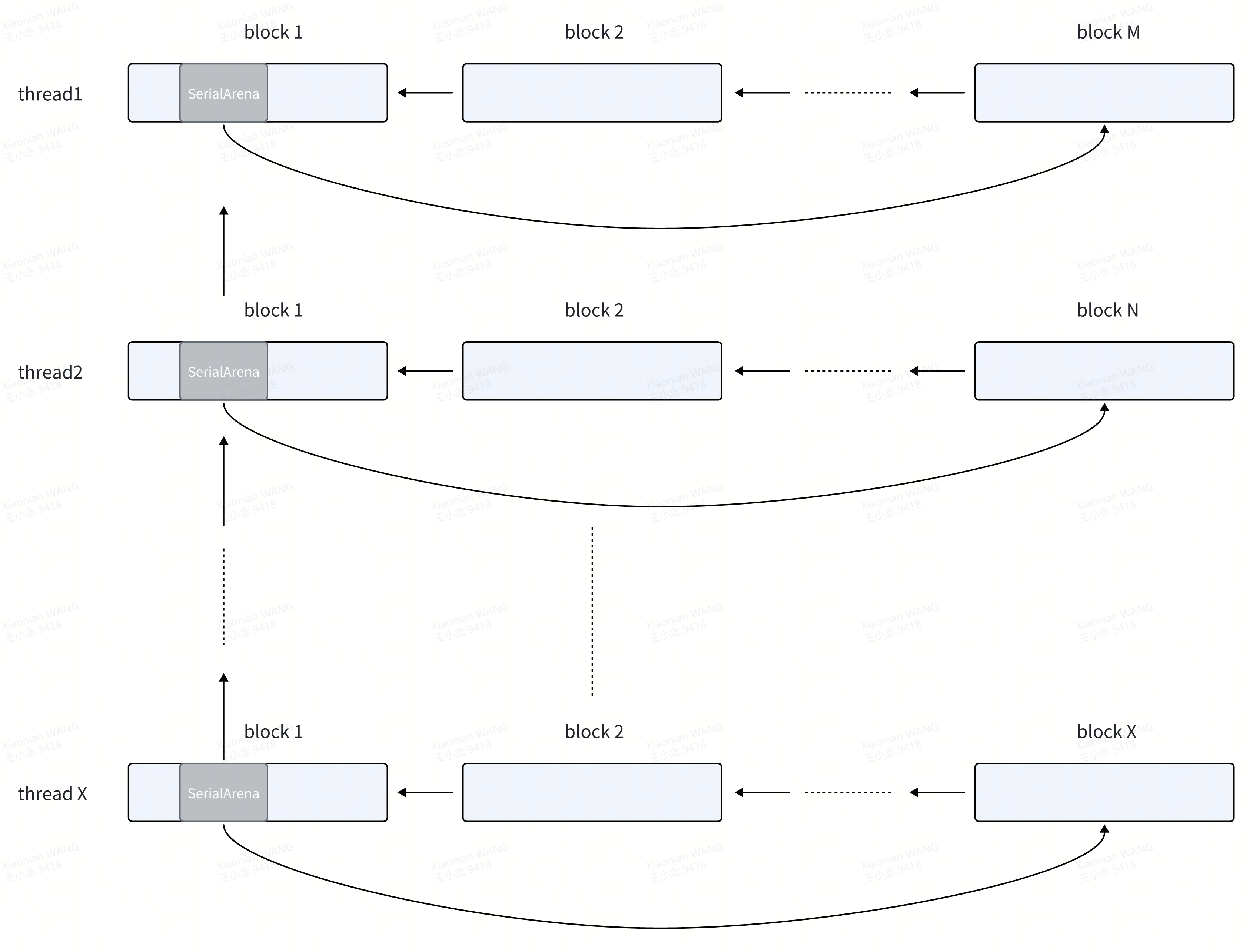
每个线程通过SerialArena对象管理一个block块内存区链表,当前线程的message对象的内存优先从该block链表中分配。SerialArena对象在第一个初始化的block内存区中构造。各个线程的SerialArena通过链表关联起来,由Arena对象管理。
下面来看特定线程中第一个block的初始化过程:
void ThreadSafeArena::InitializeWithPolicy(void* mem, size_t size,AllocationPolicy policy) {constexpr size_t kAPSize = internal::AlignUpTo8(sizeof(AllocationPolicy));constexpr size_t kMinimumSize = kBlockHeaderSize + kSerialArenaSize + kAPSize; (1)if (mem != nullptr && size >= kMinimumSize) {alloc_policy_.set_is_user_owned_initial_block(true);} else {auto tmp = AllocateMemory(&policy, 0, kMinimumSize); (2)mem = tmp.ptr;size = tmp.size;}
}(1)第一个Block的大小至少能够容纳Block、SerialArena及AllocationPolicy三个对象的大小。AllocationPolicy控制内存分配的方式,扩容策略等。
(2)实际分配内存
AllocateMemory的实现:
static SerialArena::Memory AllocateMemory(const AllocationPolicy* policy_ptr,size_t last_size, size_t min_bytes) {AllocationPolicy policy; // default policyif (policy_ptr) policy = *policy_ptr;size_t size;if (last_size != 0) {// Double the current block size, up to a limit.auto max_size = policy.max_block_size;size = std::min(2 * last_size, max_size); (1)} else {size = policy.start_block_size; (2)}// Verify that min_bytes + kBlockHeaderSize won't overflow.GOOGLE_CHECK_LE(min_bytes,std::numeric_limits<size_t>::max() - SerialArena::kBlockHeaderSize);size = std::max(size, SerialArena::kBlockHeaderSize + min_bytes);void* mem;if (policy.block_alloc == nullptr) {mem = ::operator new(size); (3)} else {mem = policy.block_alloc(size, size); (4)}return {mem, size};
}(1)(2)表明如果是第一个Block,大小为start_block_size(内存分配策略AllocationPolicy中的数据成员),之后如果继续分配Block,其大小为前一个大小的两倍,但是存在上限max_block_size(同样为内存分配策略AllocationPolicy中的数据成员)
(3)(4)表明内存分配方式可以由用户自定义,也可以使用默认的new分配方式从堆上分配
内存分配好,要在上面构造Block结构体了:
void ThreadSafeArena::InitializeWithPolicy(void* mem, size_t size,AllocationPolicy policy) {SetInitialBlock(mem, size);
}void ThreadSafeArena::SetInitialBlock(void* mem, size_t size) {SerialArena* serial = SerialArena::New({mem, size}, &thread_cache());serial->set_next(NULL);threads_.store(serial, std::memory_order_relaxed);CacheSerialArena(serial);
}SerialArena* SerialArena::New(Memory mem, void* owner) {GOOGLE_DCHECK_LE(kBlockHeaderSize + ThreadSafeArena::kSerialArenaSize, mem.size);auto b = new (mem.ptr) Block{nullptr, mem.size}; (1)return new (b->Pointer(kBlockHeaderSize)) SerialArena(b, owner); (2)
}先从分配内存的起始处构造Block对象,紧接着Block对象构造SerialArena对象。SerialArena对象的构造示意如下:
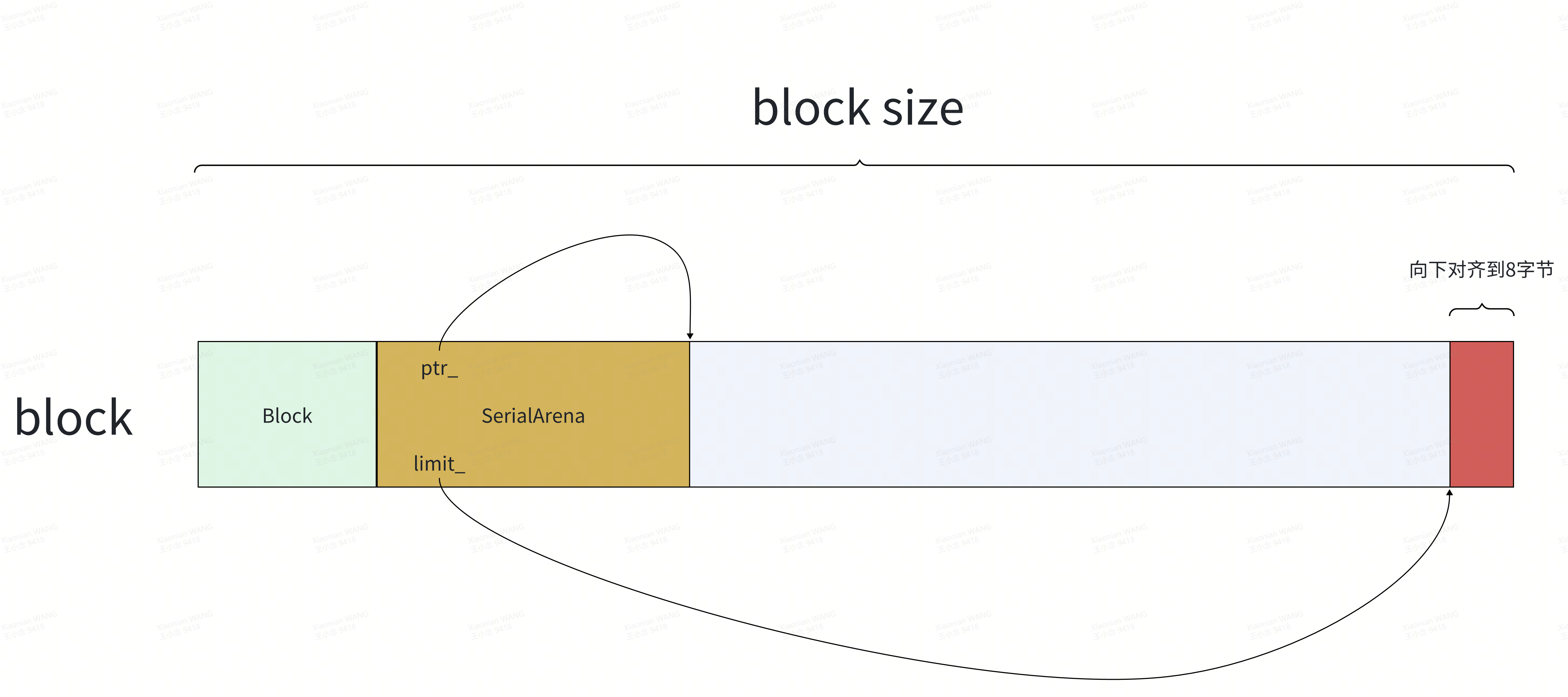
limit_为什么要向下对齐到8字节呢?因为从这个位置开始存储对象的析构函数地址。
接着看InitializeWithPolicy()的实现:
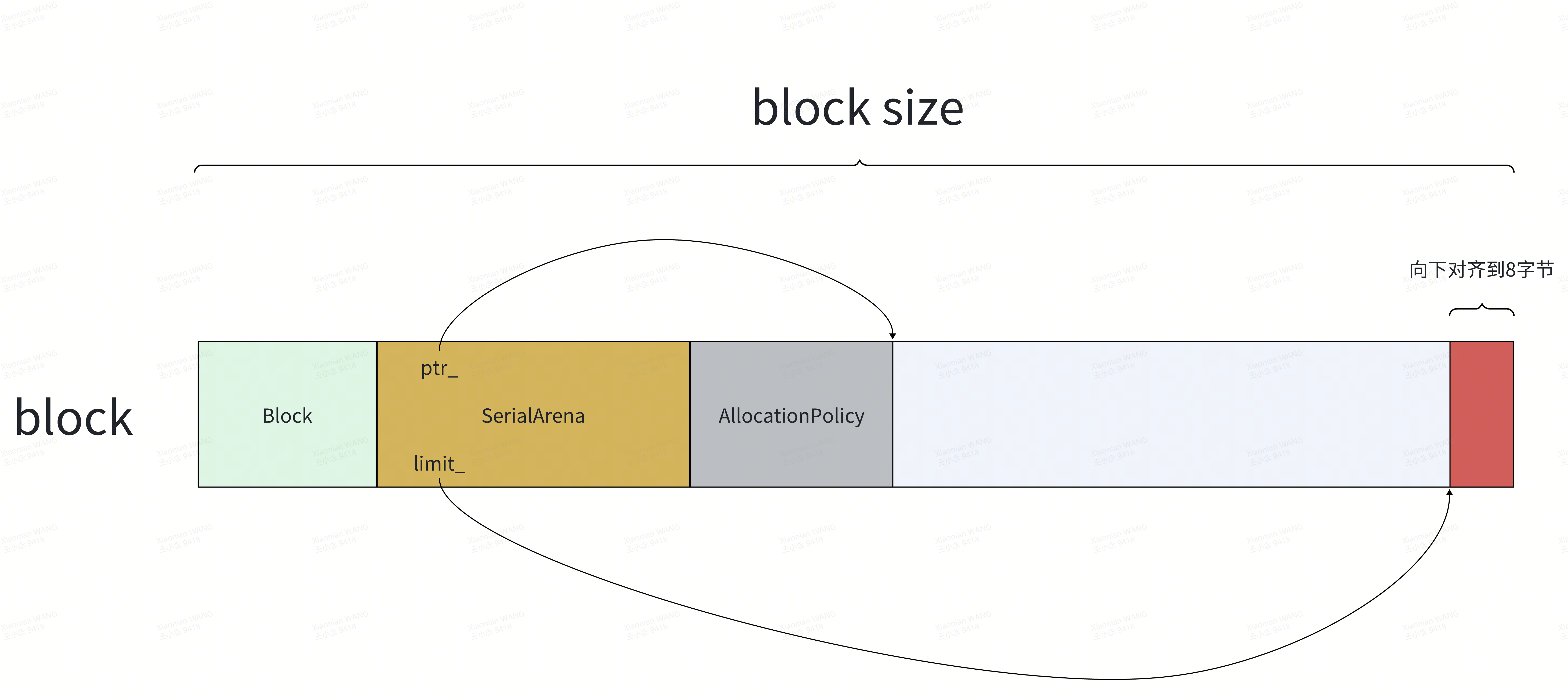
void ThreadSafeArena::InitializeWithPolicy(void* mem, size_t size,AllocationPolicy policy) {void* p;if (!sa || !sa->MaybeAllocateAligned(kAPSize, &p)) {GOOGLE_LOG(FATAL) << "MaybeAllocateAligned cannot fail here.";return;}new (p) AllocationPolicy{policy};
}紧跟着SerialArena对象构造AllocationPolicy对象,示意如下:
假设现在要通过Arena对象分配一段内存,并在该内存上构造一个新的message对象:
google::protobuf::Arena arena(options);tutorial::Person *person = google::protobuf::Arena::CreateMessage<tutorial::Person>(&arena);看下CreateMessage的实现:
template <typename T, typename... Args>
PROTOBUF_ALWAYS_INLINE static T* CreateMessage(Arena* arena, Args&&... args) {static_assert(InternalHelper<T>::is_arena_constructable::value,"CreateMessage can only construct types that are ArenaConstructable");// We must delegate to CreateMaybeMessage() and NOT CreateMessageInternal()// because protobuf generated classes specialize CreateMaybeMessage() and we// need to use that specialization for code size reasons.return Arena::CreateMaybeMessage<T>(arena, static_cast<Args&&>(args)...);
}PROTOBUF_NAMESPACE_OPEN
template<> PROTOBUF_NOINLINE ::tutorial::Person* Arena::CreateMaybeMessage< ::tutorial::Person >(Arena* arena) {return Arena::CreateMessageInternal< ::tutorial::Person >(arena);
}template <typename T, typename... Args>
PROTOBUF_NDEBUG_INLINE static T* CreateMessageInternal(Arena* arena,Args&&... args) {static_assert(InternalHelper<T>::is_arena_constructable::value,"CreateMessage can only construct types that are ArenaConstructable");if (arena == NULL) {return new T(nullptr, static_cast<Args&&>(args)...);} else {return arena->DoCreateMessage<T>(static_cast<Args&&>(args)...);}
}最终调用DoCreateMessage:
template <typename T, typename... Args>
PROTOBUF_NDEBUG_INLINE T* DoCreateMessage(Args&&... args) {return InternalHelper<T>::Construct(AllocateInternal(sizeof(T), alignof(T),internal::ObjectDestructor<InternalHelper<T>::is_destructor_skippable::value,T>::destructor,RTTI_TYPE_ID(T)),this, std::forward<Args>(args)...);
}以上实现可以概括为利用AllocateInternal分配内存,在分配的内存上构造message对象。AllocateInternal会调用AllocateAlignedWithCleanup:
std::pair<void*, SerialArena::CleanupNode*>
ThreadSafeArena::AllocateAlignedWithCleanup(size_t n,const std::type_info* type) {SerialArena* arena;if (PROTOBUF_PREDICT_TRUE(!alloc_policy_.should_record_allocs() &&GetSerialArenaFast(&arena))) {return arena->AllocateAlignedWithCleanup(n, alloc_policy_.get());} else {return AllocateAlignedWithCleanupFallback(n, type);}
}std::pair<void*, CleanupNode*> AllocateAlignedWithCleanup(size_t n, const AllocationPolicy* policy) {GOOGLE_DCHECK_EQ(internal::AlignUpTo8(n), n); // Must be already aligned.if (PROTOBUF_PREDICT_FALSE(!HasSpace(n + kCleanupSize))) { (1)return AllocateAlignedWithCleanupFallback(n, policy);}return AllocateFromExistingWithCleanupFallback(n); (2)}(1)中kCleanupSize = AlignUpTo8(sizeof(CleanupNode)),CleanupNode的定义为:
struct CleanupNode {void* elem; // Pointer to the object to be cleaned up.void (*cleanup)(void*); // Function pointer to the destructor or deleter.
};CleanupNode对象存储message对象的指针和其析构函数地址,在资源清理时会用到,该对象的构造从上面提到的limit_处开始。
(2)暂时只考虑第一次分配的Block对象空间大小满足需求:
std::pair<void*, CleanupNode*> AllocateFromExistingWithCleanupFallback(size_t n) {void* ret = ptr_;ptr_ += n;limit_ -= kCleanupSize;
#ifdef ADDRESS_SANITIZERASAN_UNPOISON_MEMORY_REGION(ret, n);ASAN_UNPOISON_MEMORY_REGION(limit_, kCleanupSize);
#endif // ADDRESS_SANITIZERreturn CreatePair(ret, reinterpret_cast<CleanupNode*>(limit_));}内存的分配仅仅是prt_及limit_位置的移动。继续看AllocateInternal的实现:
PROTOBUF_NDEBUG_INLINE void* AllocateInternal(size_t size, size_t align,void (*destructor)(void*),const std::type_info* type) {// Monitor allocation if needed.if (destructor == nullptr) {return AllocateAlignedWithHook(size, align, type);} else {if (align <= 8) {auto res = AllocateAlignedWithCleanup(internal::AlignUpTo8(size), type);res.second->elem = res.first;res.second->cleanup = destructor;return res.first;} else {auto res = AllocateAlignedWithCleanup(size + align - 8, type);auto ptr = internal::AlignTo(res.first, align);res.second->elem = ptr;res.second->cleanup = destructor;return ptr;}}}该函数结束后内存布局如下(假设构造的对象为t1):
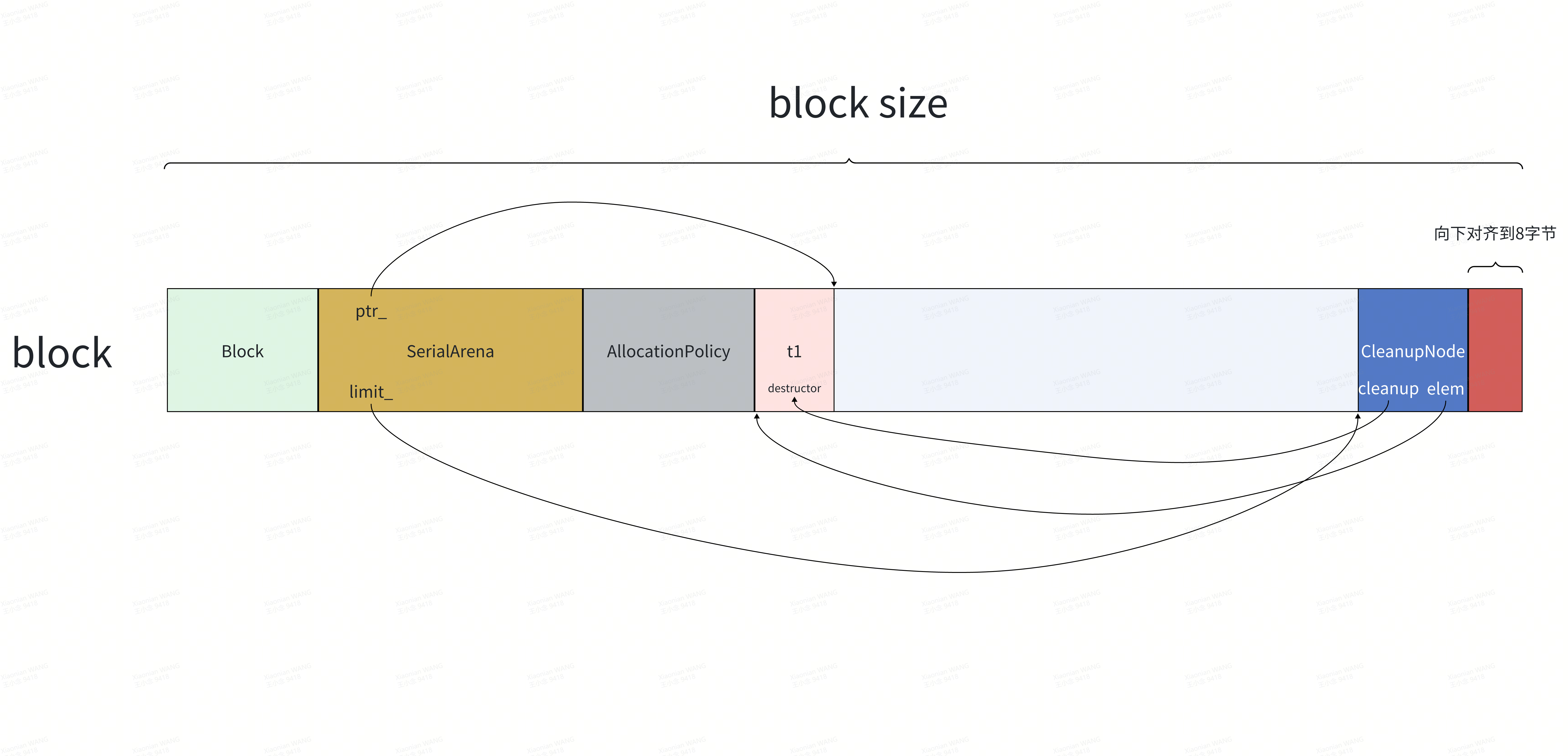
继续分配新的message对象(假设构造的对象为t2),分两种情况:
1. 若第一个Block空间仍然足够:
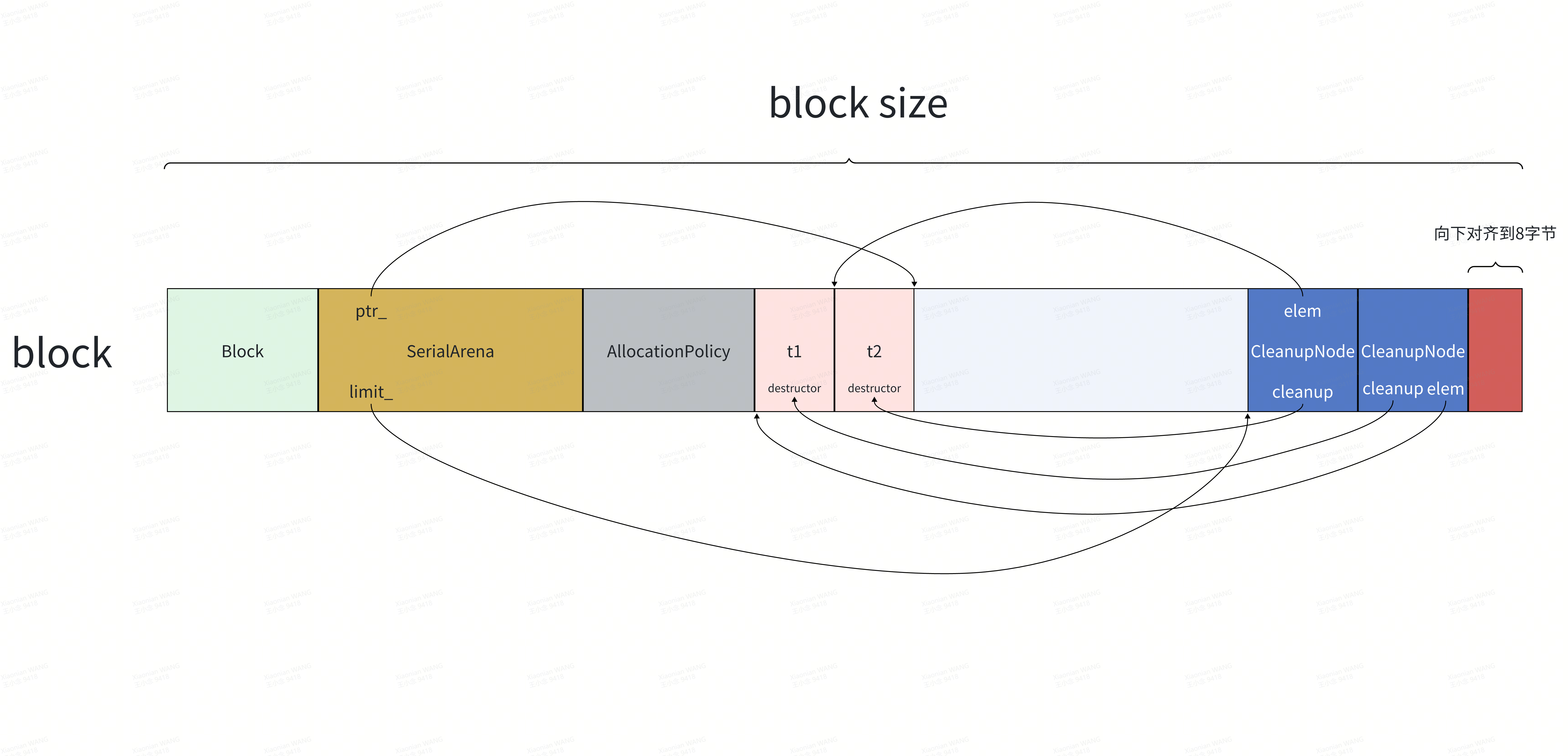
2.若第一个Block空间不足,无法继续容纳t2:
PROTOBUF_NOINLINE
std::pair<void*, SerialArena::CleanupNode*>
SerialArena::AllocateAlignedWithCleanupFallback(size_t n, const AllocationPolicy* policy) {AllocateNewBlock(n + kCleanupSize, policy);return AllocateFromExistingWithCleanupFallback(n);
}先分配一个新的Block,再在新的Block空间上为message对象分配空间。
void SerialArena::AllocateNewBlock(size_t n, const AllocationPolicy* policy) {// Sync limit to blockhead_->start = reinterpret_cast<CleanupNode*>(limit_); (1)// Record how much used in this block.space_used_ += ptr_ - head_->Pointer(kBlockHeaderSize);auto mem = AllocateMemory(policy, head_->size, n);// We don't want to emit an expensive RMW instruction that requires// exclusive access to a cacheline. Hence we write it in terms of a// regular add.auto relaxed = std::memory_order_relaxed;space_allocated_.store(space_allocated_.load(relaxed) + mem.size, relaxed);head_ = new (mem.ptr) Block{head_, mem.size};ptr_ = head_->Pointer(kBlockHeaderSize);limit_ = head_->Pointer(head_->size);
}(1)将CleanUp对象的起始地址缓存在同一个block上的Block对象的start数据成员,资源清理的适合会遍历调用:
void SerialArena::CleanupList() {Block* b = head_;b->start = reinterpret_cast<CleanupNode*>(limit_);do {auto* limit = reinterpret_cast<CleanupNode*>(b->Pointer(b->size & static_cast<size_t>(-8)));auto it = b->start;auto num = limit - it;if (num > 0) {for (; it < limit; it++) {it->cleanup(it->elem);}}b = b->next;} while (b);
}AllocateNewBlock执行完成后,ptr_和limit_会指向新分配的block上的地址:
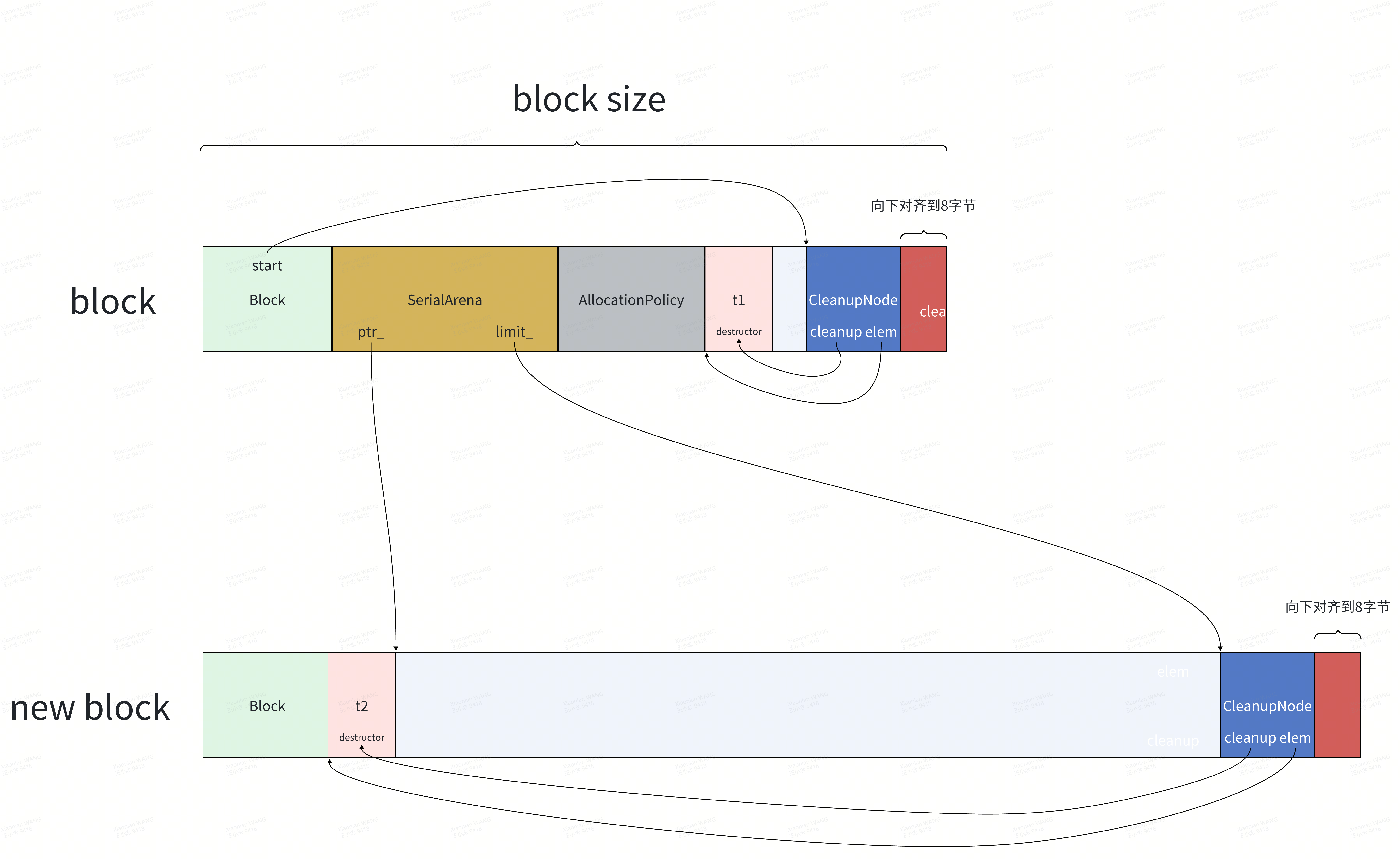
以上是固定大小message内存分配和构造的过程,接下来分析repeated字段存取操作实现:
google::protobuf::Arena arena(options);
tutorial::Person *person = google::protobuf::Arena::CreateMessage<tutorial::Person>(&arena);person->add_value(counter);
person->add_value(counter + 1);
person->add_value(counter + 2);repeated字段对应生成的c++代码中的RepeatedField,构造函数为:
template <typename Element>
inline RepeatedField<Element>::RepeatedField(Arena* arena): current_size_(0), total_size_(0), arena_or_elements_(arena){}class RepeatedField final {
private:void* arena_or_elements_;
};传入的Arena对象的指针存储在arena_or_elements_。add_value的实现:
inline void Person::add_value(int32_t value) {_internal_add_value(value);// @@protoc_insertion_point(field_add:tutorial.Person.value)
}inline void Person::_internal_add_value(int32_t value) {value_.Add(value);
}template <typename Element>
inline void RepeatedField<Element>::Add(const Element& value) {uint32_t size = current_size_;if (static_cast<int>(size) == total_size_) {// value could reference an element of the array. Reserving new space will// invalidate the reference. So we must make a copy first.auto tmp = value;Reserve(total_size_ + 1);elements()[size] = std::move(tmp);} else {elements()[size] = value;}current_size_ = size + 1;
}Reserve的实现的核心是struct Rep对象的构造及arena_or_elements_的赋值:
template <typename Element>
void RepeatedField<Element>::Reserve(int new_size) {if (total_size_ >= new_size) return;Rep* old_rep = total_size_ > 0 ? rep() : nullptr;Rep* new_rep;Arena* arena = GetArena();new_size = internal::CalculateReserveSize(total_size_, new_size);GOOGLE_DCHECK_LE(static_cast<size_t>(new_size),(std::numeric_limits<size_t>::max() - kRepHeaderSize) / sizeof(Element))<< "Requested size is too large to fit into size_t.";size_t bytes =kRepHeaderSize + sizeof(Element) * static_cast<size_t>(new_size);if (arena == nullptr) {new_rep = static_cast<Rep*>(::operator new(bytes));} else {new_rep = reinterpret_cast<Rep*>(Arena::CreateArray<char>(arena, bytes));}new_rep->arena = arena;int old_total_size = total_size_;// Already known: new_size >= internal::kMinRepeatedFieldAllocationSize// Maintain invariant:// total_size_ == 0 ||// total_size_ >= internal::kMinRepeatedFieldAllocationSizetotal_size_ = new_size;arena_or_elements_ = new_rep->elements;// Invoke placement-new on newly allocated elements. We shouldn't have to do// this, since Element is supposed to be POD, but a previous version of this// code allocated storage with "new Element[size]" and some code uses// RepeatedField with non-POD types, relying on constructor invocation. If// Element has a trivial constructor (e.g., int32_t), gcc (tested with -O2)// completely removes this loop because the loop body is empty, so this has no// effect unless its side-effects are required for correctness.// Note that we do this before MoveArray() below because Element's copy// assignment implementation will want an initialized instance first.Element* e = &elements()[0];Element* limit = e + total_size_;for (; e < limit; e++) {new (e) Element;}if (current_size_ > 0) {MoveArray(&elements()[0], old_rep->elements, current_size_);}// Likewise, we need to invoke destructors on the old array.InternalDeallocate(old_rep, old_total_size);}RepeatedField本质上利用数组实现,其内存空间的获取跟前述固定大小message对象的内存空间获取类似。现在假设已经为RepeatedField分配了一段内存,其内存布局如下:
若在设置值的过程中,内存大小已经不满足repeated字段值的继续添加,会做以下三件事情:
1. 在新的内存上构造message对象:
Element* e = &elements()[0];
Element* limit = e + total_size_;
for (; e < limit; e++) {new (e) Element;
}2. 将已经设置的repeated字段值拷贝到新分配的内存:
if (current_size_ > 0) {MoveArray(&elements()[0], old_rep->elements, current_size_);
}3. 析构在旧的内存上构造的对象:
void InternalDeallocate(Rep* rep, int size) {if (rep != nullptr) {Element* e = &rep->elements[0];if (!std::is_trivial<Element>::value) {Element* limit = &rep->elements[size];for (; e < limit; e++) {e->~Element();}}if (rep->arena == nullptr) {
#if defined(__GXX_DELETE_WITH_SIZE__) || defined(__cpp_sized_deallocation)const size_t bytes = size * sizeof(*e) + kRepHeaderSize;::operator delete(static_cast<void*>(rep), bytes);
#else::operator delete(static_cast<void*>(rep));
#endif}}}repeated字段的获取:
for (int i = 0; i < person->value_size(); ++i) {std::cout << person->value(i) << " ";
}inline const ::PROTOBUF_NAMESPACE_ID::RepeatedField< int32_t >&
Person::value() const {// @@protoc_insertion_point(field_list:tutorial.Person.value)return _internal_value();
}template <typename Element>
inline const Element& RepeatedField<Element>::Get(int index) const {GOOGLE_DCHECK_GE(index, 0);GOOGLE_DCHECK_LT(index, current_size_);return elements()[index];
}从以上代码可以看出,数据的获取依赖arena_or_elements_,该值被设为数组的起始地址。
最后看看string字段的存取:
google::protobuf::Arena arena(options);
tutorial::Person *person = google::protobuf::Arena::CreateMessage<tutorial::Person>(&arena);person->set_name("zerocopy" + std::to_string(counter));void ArenaStringPtr::Set(const std::string* default_value, std::string&& value,::google::protobuf::Arena* arena) {if (IsDefault(default_value)) {if (arena == nullptr) {tagged_ptr_.Set(new std::string(std::move(value)));} else {tagged_ptr_.Set(Arena::Create<std::string>(arena, std::move(value)));}} else if (IsDonatedString()) {std::string* current = tagged_ptr_.Get();auto* s = new (current) std::string(std::move(value));arena->OwnDestructor(s);tagged_ptr_.Set(s);} else /* !IsDonatedString() */ {*UnsafeMutablePointer() = std::move(value);}
}也是借助Arena对象申请对象,然后在内存上构造string对象。
最后提出一个问题供大家思考,基于protobuf能否实现共享内存上的零拷贝?





![[java八股文][JavaSpring面试篇]SpringCloud](https://i-blog.csdnimg.cn/img_convert/0b326c93749653e1f2b6ed02a7ee56f2.png)