文章目录
- 1 引言
- 1.1 发展脉络与现状
- 1.2 面临挑战
- 1.3 本文目标
- 2 图结构数据基础
- 2.1 关键元素
- 2.2 数学定义与常用符号
- 2.3 图的常见类型
- 2.4 为什么这些定义重要?
- 3 GNN 核心思想:消息传递机制
- 4 典型应用场景
- 4.1 推荐系统 (用户–物品二分图)
- 4.2 分子属性预测 (化学/药物发现)
- 4.3 交通流量预测 (时空图 ST-GNN)
- 4.4 社交网络分析 (复杂网络科学)
- 5 快速上手机框架
- 5.1 选型速查
- 5.2 五分钟上手示例(PyG)
- 5.3 实用小贴士
- 6 结语 · 展望与行动指南
- 6.1 关键收获回顾
- 6.2 前沿趋势展望
- 6.4 结束语
1 引言
在过去十年里,图神经网络(Graph Neural Networks,GNNs)迅速崛起,成为深度学习研究与工业落地最活跃的方向之一。与 CNN 在图像领域、RNN 在序列领域的成功相对应,GNN 旨在处理非欧氏结构数据──即节点间存在复杂连接关系的图。从电商商品推荐到药物分子性质预测,再到城市交通流量调度,图结构在真实世界无处不在,而传统神经网络难以直接利用其中的拓扑信息。
为什么需要 GNN?
- 数据形态变化:社交网络、引文网络、知识图谱、化学分子、交通路网等本质上都是节点 + 边的表示;把它们硬塞进欧氏空间会丢失邻接关系这一关键信息。
- 任务需求升级:推荐系统希望利用“用户–物品”的交互图做冷启动;药物研发要求在分子图上预测生物活性;导航系统需要实时推断道路图的拥堵情况。
- 硬件与算法共振:GPU/TPU 的并行算力、海量开源图数据,以及深度学习自动微分框架的成熟,为大规模图学习奠定了基础。
1.1 发展脉络与现状
- 早期尝试(1990s–2016)
Spektral 早期 RecGNN 通过迭代信息传播求固定点,计算量大、收敛慢。随着 CNN/RNN 在 Euclidean 域的突破,学者们开始探索将卷积/循环思想迁移到图域。 - 爆发期(2017–2020)
- GCN(2017)提出拉普拉斯谱卷积的高效近似,引发大规模跟进。
- GAT(2018)用注意力机制动态分配邻居权重,提升了表达能力。
- GraphSAGE 与 PinSAGE 解决了工业级大图的可扩展性问题。
- 多样化阶段(2021–至今)
现有研究已形成四大主流类别(图片¹中提出的新分类框架):- RecGNNs:信息递归传播模型
- ConvGNNs:包含频谱与空间两条技术路线
- 图自编码器(GAE):以重构/对比学习为目标的无监督框架
- 时空 GNN(STGNNs):处理交通、传感器等动态图
研究重点从设计更深网络、增强可解释性,转向可扩展性、异质图建模、动态图学习等更贴近应用的议题。
1.2 面临挑战
- 深度易过平滑:层数增加后节点表示趋同,信息衰减。
- 规模与计算瓶颈:亿级节点的大图对显存和算力提出挑战。
- 异质与动态性:节点/边多类型共存、拓扑随时间演化,模型需同时刻画结构和时间依赖。
- 评估标准碎片化:公开数据集和指标多而不统一,横向对比难度大。
1.3 本文目标
本文聚焦 GNN 入门,将围绕以下三条主线展开:
- 核心概念:图数据基本术语、消息传递机制、典型数学表示。
- 经典模型:GCN、GAT、GraphSAGE、GIN 等代表性方法的直观讲解与对比。
- 实战指南:从数据预处理、模型选型到训练调优,给出可落地的实践经验,并指出常见误区。
通过阅读,你将能够:
- 快速建立图学习思维:理解为何“邻居即信息”,以及消息传递的本质。
- 选对模型、避开坑:根据任务规模与数据特征,合理选型并规避常见陷阱。
- 把 GNN 用起来:借助 PyTorch Geometric / DGL 等框架,完成一个端到端的小项目原型。
本文阅读建议
- 若你已熟悉 CNN/RNN,可将 GNN 视为其在图域的自然推广;
- 若你关注工业落地,可重点阅读后文的“训练流程与实践要点”;
- 若你想深入研究,可参考附录列出的综述、基准数据集与开源实现。
2 图结构数据基础
2.1 关键元素
- 节点 (Node):图中的实体,如用户、商品、城市路口、分子中的原子
- 边 (Edge):节点之间的关系,可带方向与权重,如“关注”关系、道路长度、化学键
- 特征 (Feature)
- 节点特征 x v ∈ R d \mathbf{x}_v \in \mathbb{R}^{d} xv∈Rd:年龄、类别、原子类型等
- 边特征 x ( v , u ) e ∈ R c \mathbf{x}_{(v,u)}^{e} \in \mathbb{R}^{c} x(v,u)e∈Rc:权重、距离、键类型等
- 全局特征 x g \mathbf{x}^{g} xg:整张图的属性,如分子的 pH 值、交通网的天气信息
2.2 数学定义与常用符号
| 符号 | 意义 | 说明 |
|---|---|---|
| G = ( V , E ) G=(V,E) G=(V,E) | 图 | V V V 为节点集合, E E E 为边集合 |
| n = ∣ V ∣ n = \lvert V\rvert n=∣V∣ | 节点数 | 图中节点的数量 |
| m = ∣ E ∣ m = \lvert E\rvert m=∣E∣ | 边数 | 图中边的数量 |
| A ∈ { 0 , 1 } n × n A\in\{0,1\}^{n\times n} A∈{0,1}n×n 或 A ∈ R n × n A\in\mathbb R^{n\times n} A∈Rn×n | 邻接矩阵 | 无权图: A i j = 1 A_{ij}=1 Aij=1 若 ( v i , v j ) ∈ E (v_i,v_j)\in E (vi,vj)∈E; 加权图: A i j = w i j A_{ij}=w_{ij} Aij=wij 表示权值 |
| X ∈ R n × d \mathbf X\in\mathbb R^{\,n\times d} X∈Rn×d | 节点特征矩阵 | 第 i i i 行为节点 v i v_i vi 的特征 x v i \mathbf x_{v_i} xvi |
| X e ∈ R m × c \mathbf X^{e}\in\mathbb R^{\,m\times c} Xe∈Rm×c | 边特征矩阵 | 第 k k k 行为第 k k k 条边 ( v i , v j ) (v_i,v_j) (vi,vj) 的特征 x ( v i , v j ) e \mathbf x^{e}_{(v_i,v_j)} x(vi,vj)e |
| N ( v ) \mathcal N(v) N(v) | 节点 v v v 的邻居集合 | { u ∣ ( v , u ) ∈ E } \{\,u\mid (v,u)\in E\} {u∣(v,u)∈E} |
Definition 1 (Graph)
一个无向图表示为 G = ( V , E ) G=(V,E) G=(V,E)。若 ( v i , v j ) ∈ E (v_i,v_j)\in E (vi,vj)∈E,则 A i j = A j i = 1 A_{ij}=A_{ji}=1 Aij=Aji=1;否则为 0 0 0。若每个节点携带 x v \mathbf{x}_v xv,则称为带属性图。
Definition 2 (Directed Graph)
若边有方向,则 A i j = 1 A_{ij}=1 Aij=1 不必有 A j i = 1 A_{ji}=1 Aji=1。无向图可视为一类特殊的有向图。
Definition 3 (Spatial–Temporal Graph)
若节点特征随时间变化,记作 X ( t ) \mathbf{X}^{(t)} X(t),则得到时空图 G ( t ) = ( V , E , X ( t ) ) G^{(t)}=(V,E,\mathbf{X}^{(t)}) G(t)=(V,E,X(t))。
2.3 图的常见类型
| 维度 | 取值 | 举例 |
|---|---|---|
| 有向 vs 无向 | 有向:边区分方向 无向:边无方向 | 有向:Twitter “关注” 无向:Facebook “好友” |
| 加权 vs 非加权 | 加权:边带实数/概率/流量等权重 非加权:仅表示连通性 | 加权:道路网络边权=距离/流量 非加权:论文引用 |
| 同质 vs 异质 | 同质:节点/边类型单一 异质:多类型节点或多类型边 | 同质:Cora 引文网(只有论文节点) 异质:用户–商品–标签三类节点,购买/浏览两类边 |
| 静态 vs 动态 | 静态:拓扑不随时间变化 动态:节点/边及其属性随时间演化 | 静态:分子、社交快照 动态:交通流量网、金融交易网 |
| 属性 vs 无属性 | 属性:节点/边携带数值或类别特征 无属性:仅有拓扑结构 | 属性:分子中原子类型、道路长度 无属性:纯拓扑社交网络 |
| 二分 vs 多分(可选) | 二分图:节点分成两类且仅跨类连边 多分图/超图:边可连接多个节点 | 二分:用户–商品购买行为 超图:学术合作中“一篇论文”连多作者 |
补充说明
- 上表维度可组合使用(例如“异质 + 动态 + 加权”)。
- 若原数据不含属性,可人工构造(如度数、PageRank、ID One-Hot 等)以提升模型性能。
2.4 为什么这些定义重要?
- 模型输入格式化:明确 A A A 与 X \mathbf{X} X 后,可直接喂入大多数 GNN 框架(PyG/DGL)。
- 算法设计差异:异质图需区分节点类型;动态图需额外建模时间依赖;加权图卷积需处理 A i j ≠ 1 A_{ij}\neq 1 Aij=1。
- 评估与复现:公开基准数据集(Cora、PubMed、QM9、PEMS-Bay 等)均遵循上述符号体系,方便横向对比。
Tips
- 若原始数据缺乏节点特征,可使用度数、Pagerank、One-Hot ID 等手工构造。
- 大图先做稀疏存储(COO/CSR);邻接矩阵不要变稠密,否则显存爆炸。
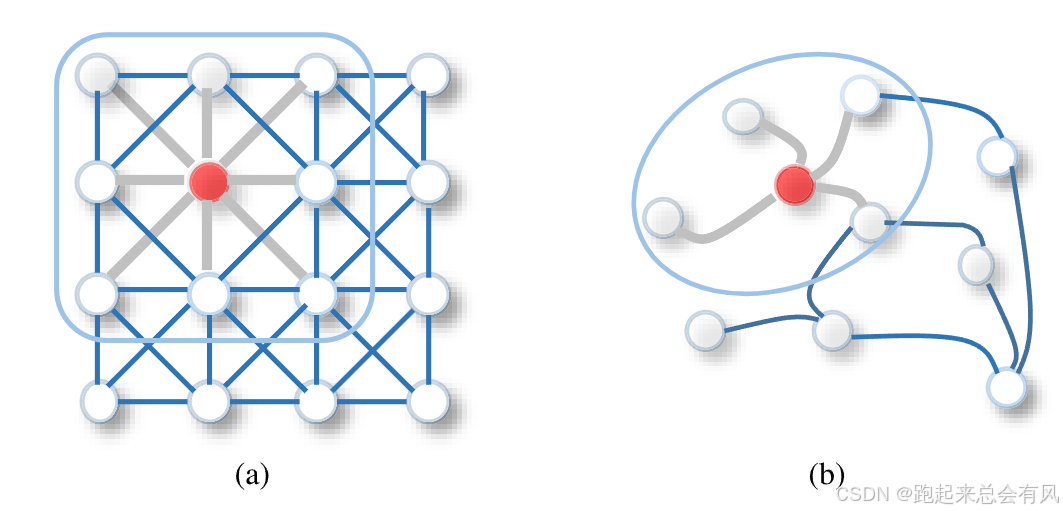
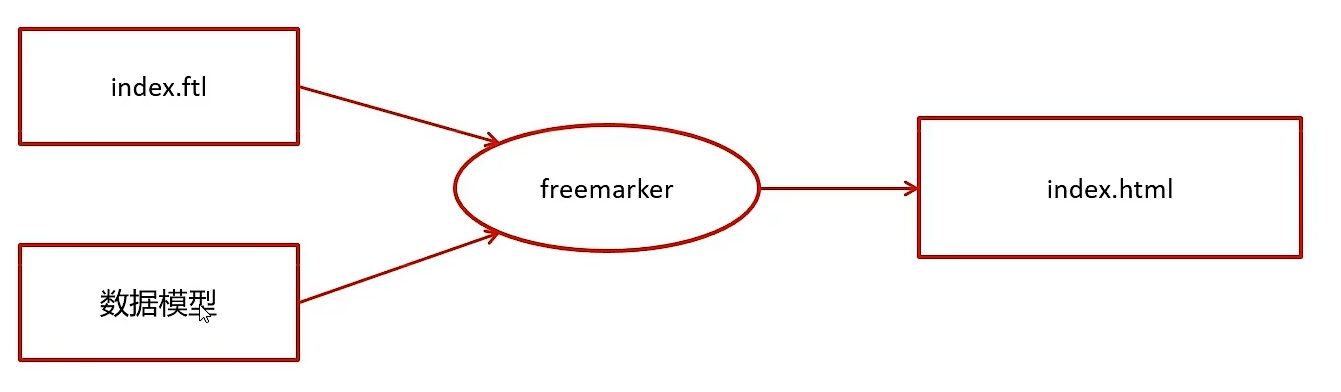
图 1 2-D 卷积 vs 图卷积
(a) 2-D 卷积:在规则网格(如 3 × 3 卷积核)上,红色像素的感受野由固定大小和固定顺序的 8 个邻接像素组成,卷积操作等价于对这些像素做加权求和。
(b) 图卷积:在非欧式图结构中,红色节点的邻居数量可变、顺序无关;一阶图卷积的简单做法是将红色节点及其所有邻居的特征取平均(或加权聚合),从而获得该节点的隐藏表示。与图像数据不同,图中节点的邻居既 无序 又 可变,因此卷积核无法用固定形状描述,而需借助邻居聚合机制实现。
3 GNN 核心思想:消息传递机制
GNN 可以看作 “邻居信息聚合 → 自身状态更新” 的递归堆叠。几乎所有主流 GNN(GCN、GAT、GraphSAGE、GIN 等)都可抽象为下式的不同实例:
h v ( k + 1 ) = U P D A T E ( k ) ( h v ( k ) , ⨁ u ∈ N ( v ) M E S S A G E ( k ) ( h v ( k ) , h u ( k ) , e u v ) ) h_v^{(k+1)} = \mathrm{UPDATE}^{(k)}\!\Bigl( h_v^{(k)}, \bigoplus_{u \in \mathcal{N}(v)} \mathrm{MESSAGE}^{(k)}( h_v^{(k)}, h_u^{(k)}, e_{uv}) \Bigr) hv(k+1)=UPDATE(k)(hv(k),u∈N(v)⨁MESSAGE(k)(hv(k),hu(k),euv))
- h v ( k ) h_v^{(k)} hv(k):第 k k k 层时节点 v v v 的表示
- N ( v ) \mathcal{N}(v) N(v):邻居集合
- ⊕ \oplus ⊕:可交换聚合(Sum / Mean / Max / Attention-Weighted-Sum)
- M E S S A G E \mathrm{MESSAGE} MESSAGE / U P D A T E \mathrm{UPDATE} UPDATE:可学习函数(MLP、注意力等)
直观理解:每层都在“收集邻居信息 → 更新自身状态”;堆叠多层即可捕获远距离依赖。
3.1 消息函数 M E S S A G E ( k ) \mathrm{MESSAGE}^{(k)} MESSAGE(k)
| 典型实现 | 数学形式 | 备注 |
|---|---|---|
| GCN | 1 d u d v h u ( k ) \dfrac{1}{\sqrt{d_ud_v}}\,h_u^{(k)} dudv1hu(k) | 拉普拉斯归一化 |
| GraphSAGE-mean | W ( k ) h u ( k ) W^{(k)}h_u^{(k)} W(k)hu(k) | 再经激活 σ \sigma σ |
| GAT | α u v ( k ) W ( k ) h u ( k ) \alpha_{uv}^{(k)}W^{(k)}h_u^{(k)} αuv(k)W(k)hu(k) | α u v \alpha_{uv} αuv 由注意力打分 |
| GIN | h u ( k ) h_u^{(k)} hu(k) | 聚合后再用 MLP 处理 |
3.2 聚合算子 ⊕ \oplus ⊕
- 求和 / 平均:效率高、稳定 —— GCN、GraphSAGE
- 加权和: ∑ u α u v ( ⋅ ) \sum_{u}\alpha_{uv}(\cdot) ∑uαuv(⋅) —— 权重可学习或基于度数
- 最大池化:保留邻居最强信号,适合稀疏激活
- 多头注意力拼接:GAT 中的 concat 操作
3.3 更新函数 U P D A T E ( k ) \mathrm{UPDATE}^{(k)} UPDATE(k)
典型写法
h v ( k + 1 ) = σ ( W cat [ h v ( k ) ∥ m v ( k ) ] ) \displaystyle h_v^{(k+1)} = \sigma\!\bigl(\mathbf W_{\text{cat}}\,[\,h_v^{(k)} \,\Vert\, m_v^{(k)}]\bigr) hv(k+1)=σ(Wcat[hv(k)∥mv(k)])
- 拼接再线性:GraphSAGE、GIN
- GRU/LSTM 门控:Gated GCN、GGNN —— 缓解梯度消失
- 残差 / 跳连: h ( k + 1 ) = h ( k ) + MLP ( m ( k ) ) h^{(k+1)} = h^{(k)} + \text{MLP}(m^{(k)}) h(k+1)=h(k)+MLP(m(k)) —— 允许更深网络
3.4 堆叠多层 & 全图读出
- 感受野扩大: k k k 层覆盖 k k k-跳邻居;层数过多易 过平滑(over-smoothing)。
- 全图表示:节点嵌入 { h v ( K ) } \{h_v^{(K)}\} {hv(K)} 可再经 READOUT(mean / sum / Set2Set / pooling)得到 h G \mathbf h_G hG,用于图分类或回归任务。
3.5 常见改进方向
| 痛点 | 解决思路 |
|---|---|
| 过平滑:高层节点表征趋同 | 残差、跳连、PairNorm、DropEdge |
| 过压缩 (over-squashing):远距依赖被折叠 | 更宽聚合、Dilated GNN、分层图池化 |
| 可扩展性:大图显存/计算瓶颈 | Neighbor / Layer / GraphSAINT 采样、分布式训练 |
| 异质 & 动态图 | Relational GCN、HGT、TGAT、TGN 等专用架构 |
小结
- 消息 = 邻居特征 + 边特征 + 权重
- 聚合 = 无序集合上的对称函数
- 更新 = 将自身旧状态与聚合结果融合
这一统一框架不仅囊括了几乎所有现有 GNN,也为未来模型的模块化设计提供了思路。
4 典型应用场景
GNN 的价值在于能直接利用拓扑 + 属性进行端到端学习,下面列出四大最常见也最成熟的落地方向,并给出典型任务、公开数据集与代表模型,方便快速上手或查阅。
4.1 推荐系统 (用户–物品二分图)
| 任务 | 场景 & 目标 |
|---|---|
| 链接预测 / CTR 预估 | 给定历史交互,预测用户–物品潜在边(点击、购买、收藏) |
| Top-K 推荐 | 生成用户候选物品列表并排序 |
| 冷启动 | 通过用户、物品特征缓解新节点无交互问题 |
- 数据集:MovieLens-1M、Pinterest-20M、Amazon-Book、Taobao。
- 代表模型
- PinSAGE(Pinterest):GraphSAGE + 随机游走采样,支持十亿级图。
- LightGCN / NGCF:去掉消息函数的非线性,只保留加权平均,效果反而更好且训练更快。
- GraphRec / DGCF:处理用户评论文本或多兴趣簇的异质图推荐。
- 工程要点
- 采用 Neighbor Sampling + Mini-Batch 解决大图显存瓶颈。
- 可将图嵌入与 召回 & 排序 双塔模型结合,线上延迟更低。
4.2 分子属性预测 (化学/药物发现)
| 任务 | 目标 |
|---|---|
| 回归 | 预测溶解度、LogP、能隙、毒性 (QSAR) |
| 分类 | 判断是否有活性/毒副作用 |
- 分子图:节点 = 原子属性 (原子序数、电负性),边 = 键类型 (单/双/芳香)。
- 数据集:QM9、ESOL、Tox21、PCBA、HIV(均收录于 MoleculeNet)。
- 代表模型
- MPNN / D-MPNN:消息函数显式考虑边特征。
- GIN / GIN-ε:强判别力,适合低资源数据集。
- DimeNet++ / SphereNet:在边长外融合角度信息,精度 SOTA。
- 工程要点
- 需对 SMILES 分子式做 RDKit 转图并标准化。
- 对不平衡数据采用 Focal Loss / Class-Balanced Loss。
4.3 交通流量预测 (时空图 ST-GNN)
| 任务 | 目标 |
|---|---|
| 速度/客流量多步预测 | 给定过去 N 个时间步,预测未来 T 步路段速度 / 站点客流 |
| 拥堵/事故检测 | 在线判断潜在堵点,辅助调度 |
- 图结构:节点 = 路口 / 感知器,边权 = 距离、时长、行驶方向。
- 数据集:METR-LA (207 传感器)、PEMS-BAY、NYC-Taxi、BikeNYC。
- 代表模型
- DCRNN:Diffusion Convolution + Seq2Seq GRU。
- STGCN / ASTGCN:卷积捕获空间依赖,注意力捕获时间依赖。
- GraphWaveNet / MTGNN:可学习动态邻接,适应非静态拓扑。
- 工程要点
- 先对缺失传感器读数做插值;归一化后再喂入模型。
- 评估常用 MAE / RMSE / MAPE,多步预测要报告 Horizon-wise 误差。
4.4 社交网络分析 (复杂网络科学)
| 子任务 | 说明 |
|---|---|
| 社区检测 / 表示学习 | 基于节点表示聚类或直接监督学习社区标签 |
| 关键节点识别 | 估算节点影响力 (K-core, PageRank, GNN-based Centrality) |
| 谣言与情感传播 | 构建内容 + 传播链异质图,预测信息可信度 & 情绪走向 |
| Friend / Follower 推荐 | 与 4.1 相似,但侧重社交图结构特性 |
- 数据集:Cora / Citeseer / PubMed(引文网)、Reddit、Twitter-Rumor、OGB 系列 (e.g., ogbn-arxiv)。
- 代表模型
- GraphSAGE / DeepWalk / node2vec:大规模表征学习基线。
- Heterogeneous GNN (HGT, R-GCN):多类型节点、边。
- Simple-GCN / SIGN / SGC:推断速度快,友好线上部署。
- 工程要点
- 隐私限制下常需 匿名化 & K-匿名 处理数据。
- 对超大社交图可采用 Graph Learning Service (e.g., DGL-KE, AliGraph) 做训练 + 在线推理分离。
思考:GNN 场景远不止于此——知识图谱补全、代码图漏洞检测、电力/蛋白质结构预测、金融风控图等都已取得显著效果。选择合适的数据建模方式与 GNN 架构,是落地成败的关键。
5 快速上手机框架
| 框架 | 特点 | 适合场景 | 资料 |
|---|---|---|---|
| PyTorch Geometric (PyG) | PyTorch 原生,100+ 算子/Pooling,社区活跃 | 学术原型 & Kaggle | https://github.com/pyg-team/pytorch_geometric |
| DGL | 多后端 (PT/TF/MX)、DistDGL 分布式、GraphBolt 采样 | 工业级大图 | https://www.dgl.ai |
| GraphGym | YAML 配置即可批量跑模型/数据/超参,自动记录 WandB | 论文复现 & 架构搜索 | https://github.com/snap-stanford/GraphGym |
| Spektral | Keras 风格 API,支持动态图序列 | 需要 TF/TPU 场景 | https://github.com/danielegrattarola/spektral |
| TorchDrug | 分子/蛋白质管线完善,支持 3-D 结构 | 药物发现 & 生成 | https://github.com/DeepGraphLearning/torchdrug |
| GraphStorm | 基于 DGL 的企业流水线,自动特征/采样/推理 | 离线训练 + 在线部署 | https://github.com/awslabs/graphstorm |
| OGB Toolbox | 与 OGB 数据集无缝对接,脚本+排行榜 | 标准基准对比 | https://github.com/snap-stanford/ogb |
5.1 选型速查
| 关注重点 | 推荐 |
|---|---|
| 最快原型 | PyG |
| 超大图训练 | DGL + DistDGL / GraphStorm |
| 批量实验 | GraphGym |
| TensorFlow 生态 | Spektral |
| 分子任务 | TorchDrug |
| 排行榜冲分 | OGB Toolbox |
5.2 五分钟上手示例(PyG)
# pip install torch ... # 省略安装命令,见官网import torch
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import GCNConvdata = Planetoid(root='data', name='Cora')[0]class GCN(torch.nn.Module):def __init__(self, in_dim, hid, n_cls):super().__init__()self.conv1 = GCNConv(in_dim, hid)self.conv2 = GCNConv(hid, n_cls)def forward(self, x, edge_index):x = self.conv1(x, edge_index).relu()return self.conv2(x, edge_index)model = GCN(data.num_node_features, 16, int(data.y.max())+1)
opt = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
loss_fn = torch.nn.CrossEntropyLoss()for epoch in range(200):model.train(); opt.zero_grad()out = model(data.x, data.edge_index)loss = loss_fn(out[data.train_mask], data.y[data.train_mask])loss.backward(); opt.step()if epoch % 20 == 0:acc = (out.argmax(1)[data.test_mask] == data.y[data.test_mask]).float().mean()print(f'E{epoch:03d} loss={loss:.3f} acc={acc:.3f}')
5.3 实用小贴士
- 显存不足?
NeighborLoader/GraphSAINT采样批训练 - 实验管理:PyG & DGL 均兼容 WandB / TensorBoard;GraphGym 自动输出 Markdown 报告
- 推理部署
- 小图 → 导出 TorchScript
- 大图 → 离线嵌入 + ElasticSearch 召回,或用 DGL Serving / GraphStorm Inference
- 调参经验:层数 2‒3,隐藏维 64‒256;
DropEdge 0.1常带来泛化提升
通过上述框架与示例,你可以在 5 分钟 内跑通最小 GNN,并按需扩展到工业级规模。
6 结语 · 展望与行动指南
图神经网络(GNN)已从最初的学术探索,迅速成长为横跨推荐系统、药物发现、智慧交通等场景的“刚需”技术。消息传递机制奠定了 GNN 的统一数学框架;GCN / GAT / GraphSAGE / GIN 等经典模型为工程落地提供了坚实基座;而采样、大图分布式训练、正则化技巧则解决了规模化部署的核心痛点。
6.1 关键收获回顾
- 核心概念:邻居聚合 → 自身更新,两步递归即是 GNN 的灵魂。
- 模型谱系:从谱域卷积到空间卷积,再到异质、动态、时空扩展,几乎所有场景都能找到合适分支。
- 落地要诀:
- 小图 → 直接全图卷积;大图 → 采样 + Minibatch
- 过平滑 → 残差 / 跳连 / PairNorm;过压缩 → Dilated 聚合 / 图池化
- 工具链:PyG・DGL・GraphGym 等框架让“跑一个 SOTA”变成分钟级体验。
6.2 前沿趋势展望
| 方向 | 亮点 & 挑战 |
|---|---|
| 自监督 GNN | GPT-style 预训练 + Graph Contrast → 降低标签依赖,OGB-MAG240M 已验证效果;挑战:负样本采样 & 模型对比稳定性 |
| 图生成模型 | Diffusion / Flow 方式生成分子 & 3-D 结构,助力药物设计;挑战:保证化学有效性与多样性 |
| 可解释性 | Message Flow / GNNExplainer 可视化邻居贡献;挑战:解释稳定性 & 人工可读性 |
| 类 ChatGPT 的图大模型 | 统一多任务(分类 / 回归 / 生成) + 多模态输入(文本、图像、图);挑战:显存 & 训练费用 |
| 硬件友好 GNN | FPGA/ASIC 深度图加速器,边缘端实时推理;挑战:稀疏访存 & 动态图更新 |
6.4 结束语
Practice makes perfect.
GNN 正处于“模型百花齐放、落地快速裂变”的黄金阶段。把本文提及的 框架 + 模板代码 运行一遍,阅读两篇最新顶会论文,再尝试将你的业务数据建成图,你就已经迈出了成为“图力工程师”的第一步。
愿你在图的世界里,越走越远,越走越稳。🚀





![[java八股文][JavaSpring面试篇]SpringCloud](https://i-blog.csdnimg.cn/img_convert/0b326c93749653e1f2b6ed02a7ee56f2.png)