RCU初步分析
- 背景知识
- RCU介绍
- 名词定义
- RCU的基本执行过程
- 基本过程
- 基本思想
- 示意图
- 基本流程
- 示例代码
- 并发执行示意图
- RCU特性
- 简易RCU实现
- 基于spinlock的实现
- 基于计数器的实现
- 基于线程变量的实现
- Linux内核中经典RCU实现介绍
背景知识
随着硬件晶体管的尺寸越来越小,CPU的频率上限基本保持在4G左右。这说明虽然摩尔定律仍然在晶体管密度方面有效,但是在提高单线程性能方面已经不再有效,也意味着编写单线程代码并简单的等待 CPUs 一两年时间不再是一个可行的方法。所有主流厂商最近的趋势是朝多核/多线程系统发展,并行是充分利用这些系统性能的好办法,以此让软件更能符合硬件的变化从而提高软件的性能。
并行编程领域是一个革新式的变化,同时也涉及众多的领域——它需要考虑硬件平台的实现方式、软件任务间的通信、任务同步等多种复杂的情况。
Linux中的RCU是并行编程的一个典型应用,下面主要介绍RCU的内容。
RCU介绍
RCU全称read-copy-update,是一种同步机制。当多个线程同时读取和更新通过指针链接且属于共享数据结构(例如,链表、树,哈希表)时,避免使用锁。每当线程在共享内存中插入或删除数据结构的元素时,所有读者都可以保证看到并遍历旧结构或新结构,从而避免不一致(例如,取消引用空指针)。
它主要用在读取性能至关重要的场合,以更多空间为代价实现快速操作;这使得所有读者继续进行,就好像不涉及同步一样,因此它们会很快,但也会使更新更加困难。
名词定义
- 宽限期:grace period,简写gp,这是一个等待期,以确保所有与执行删除的数据相关的 reader访问完毕。
- 静止状态:Quiescent State,简写 qs,在任意时刻,一个特定的CPU只要看起来处于 阻塞状态、IDLE循环、或者离开了内核后,我们就知道所有RCU读端临界区已 经完成。这些状态被称为“静止状态”。
RCU的基本执行过程
基本过程
- 采用发布——订阅机制添加新的数据;
- 等待已有的 RCU 读者退出临界区;
- 允许在不影响或者延迟其他并发 RCU 读者的前提下改变数据;
基本思想
- 示例代码
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->b = 2;
q->c = 3;
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
kfree(p);
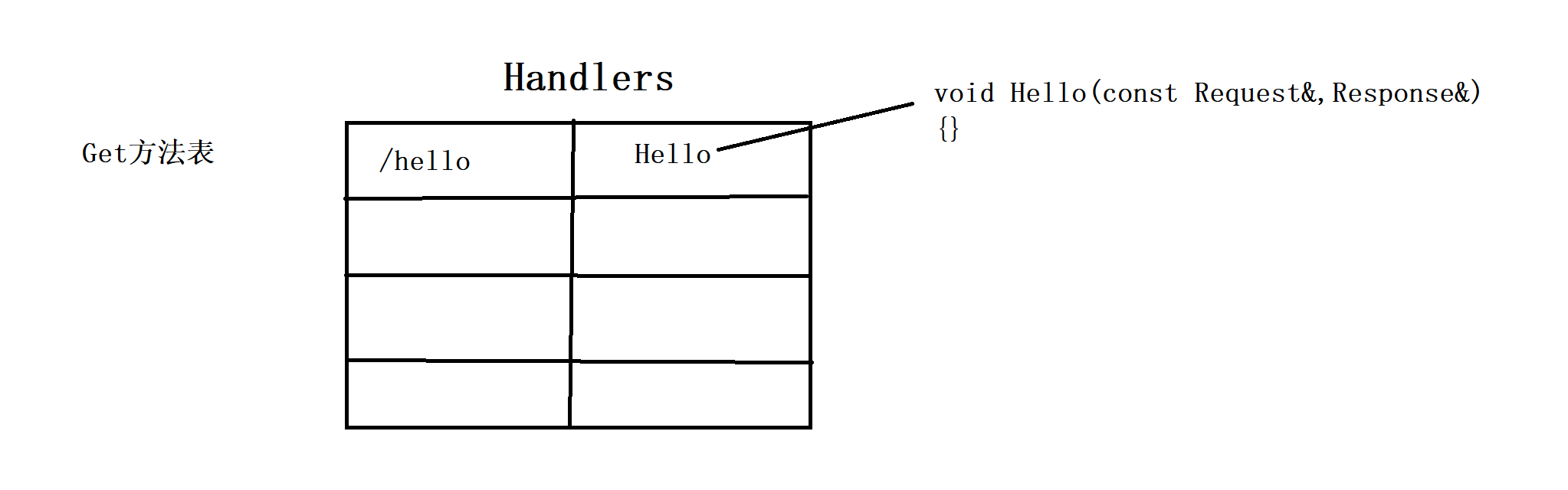
示意图






- 先给指针q分配一个空间;
- 给指针q赋值;
- 将新生成的q指向p的下一个节点;
- 再将p的上一个节点指向q;
- 等宽限期结束后,在将p释放掉;
- 第三第四步的顺序不能反,否则会造成读端在读取数据的时候出现空指针;
基本流程
- 读端通过rcu_read_lock()进入临界区;
- 读端通过rcu_read_unlock()退出临界区;
- 更新端通过rcu_assign_pointer()等发布原语发布数据;
- 更新端通过synchronize_rcu()等待宽限期结束;
示例代码
- 读端:
rcu_read_lock();
p = rcu_dereference(head);... ...
rcu_read_unlock();
该段代码通过rcu_read_lock()进入临界区,然后获取指针p,并对p进行一些列操作,最后通过rcu_read_unlock()退出临界区。
- 更新端
spin_lock(&lock);
p = head;
rcu_assign_pointer(head, NULL);
spin_unlock(&lock);
synchronize_rcu();
kfree(p);
该段代码先通过rcu_assign_pointer()函数将head置为NULL,然后通过synchronize_rcu()等待宽限期结束。当synchronize_rcu()函数返回时,表示宽限期结束,所有的读端都已经退出临界区,此时可以释放p(原来head)指向的空间。
并发执行示意图

RCU特性
- RCU读端和更新端可以同时操作,并发执行;
- RCU采用数据担保的方式,为读端提供可靠数据;
- 读端读到的数据有可能是旧的也可能是新的;
- 宽限期结束时,读端要退出临界区;
- 典型RCU读端在临界区内不允许中断、休眠等操作;
简易RCU实现
宽限期的开始和结束都是要看是否有当前有读端在临界区内,所以RCU最重要的过程也就是如下3个:
- 读端进入临界区
- 读端退出临界区
- 等待宽限期结束
下面我们通过几个简单的实现来重点了解一下这三个方面的内容。
基于spinlock的实现
DEFINE_SPINLOCK(rcu_gp_lock);static void rcu_read_lock(void)
{spin_lock(&rcu_gp_lcok);
}static void rcu_read_unlock(void)
{spin_unlock(&rcu_gp_lock);
}static void synchronize_rcu(void)
{spin_lock(&rcu_gp_lock);spin_unlock(&rcu_gp_lock);
}
基于计数器的实现
atomic_t rcu_refcnt;static void rcu_read_lock(void)
{atomic_inc(&rcu_refcnt);smp_mb();
}static void rcu_read_unlock(void)
{smp_mb();atomic_dec(&rcu_refcnt);
}static void synchronize_rcu(void)
{smp_mb();while(atomic_read(&rcu_refcnt) != 0) {poll(NULL, 0, 10);}smp_mb();
}
基于线程变量的实现
static void rcu_read_lock(void)
{spin_lock(&__get_thread_var(rcu_gp_lock));
}static void rcu_read_unlock(void)
{spin_unlock(&__get_thread_var(rcu_gp_lock));
}static void synchronize_rcu(void)
{for_each_running_thread(t){spin_lock(&per_thread(rcu_gp_lock, t));spin_unlock(&per_thread(ruc_gp_lock, t));}
}
Linux内核中经典RCU实现介绍
在Linux内核中RCU有多种实现方式:
- 基于单核的tiny实现
- 基于静止状态的实现
- 基于任务的实现
- 可睡眠的SRCU
- … …
这些实现主要是跟踪宽限期的方式不同。下面主要对基于静止状态的RCU的宽限期跟踪实现的介绍。
经典RCU 读端临界区限制其中的内核代码不允许阻塞。这意味着在任意时刻,一个特定的CPU只要看起来处于阻塞状态、IDLE循环、或者离开了内核后,我们就知道所有RCU读端临界区已经完成。这些状态被称为“静止状态”,当每一个CPU已经经历过至少一次静止状态时,RCU宽限期结束。
为了减少对CPU的遍历,所有CPU的静止状态会保存到一个struct rcu_state的结构体中类型为struct rcu_node的数组中。为了减少CPU上报时对数据锁的竞争,RCU采用了分级控制,如下图:

在一个rcu_node中,第一个上报静止状态的CPU会将数据保存在该层的节点中;只有另外一个CPU也上报了静止状态的时候,才会将该节点的两个CPU的静止状态同时上报的上一层的rcu_node中。这样做的好处是:在底层同一时间至多有两个CPU会竞争锁,在顶层锁的竞争也相对较少;这样大大减少了CPU相互竞争的机会,提高了RCU宽限期检测的性能。
上图是立体示意图,实际在Linux中采用数组来实现。示意图如下:

Linux会在RCU初始化的时候会根据实际CPU的数量来动态生成CPU的层级关系。