C++11:可变模板参数 & tuple
- 可变模板参数
- 语法
- 函数模板展开参数包
- 递归展开
- 初始化列表 + 逗号表达式
- 类模板展开参数包
- 递归展开
- 继承展开
- std::tuple
- 基本操作
- 解包 std::tie
- 原理
- 空基类优化
- emplace 原理
可变模板参数
不知道你有没有仔细观察过 C语言的 printf 函数,它是大部分人第一个接触到的 C语言库函数,但是它其实并不简单。
例如:
printf("name is %s, age is %d\n", "lisa", 19);
printf("addr %s", "beijin");
可以发现,printf函数可以接收任意个数,任意类型的参数,这底层使用了C语言的可变参数机制,但是这个机制其实非常复杂,非常难用。C++11后,支持了可变模板参数,同样可以让 函数/类 接收任意数量,任意类型的参数,不过也有些复杂,随着 C++14 和 C++17 的改进,可变模板参数的语法逐渐趋于简洁,本博客专注于讲透 C++11 中的可变模板参数机制,并讲解其两个重要应用std::tuple和emplace的原理。
语法
可变模板参数的语法如下:
template <typename... Args>
void func(Args ...args)
{}
在模板参数列表中,通过 typename... Args 声明一个 参数包,这是多个类型构成的集合,而且Args本身就是一个类型。
在函数参数列表中,Args ...args,使用Args这个类型,定义了一个参数变量args,在代码中就可以使用args了。
此时在外部,就可以调用这个函数模板,往里面传参数了:
func(1, 3.14, "hello world", 'x');
func(5);
以上代码,会让编译器去对函数模板做推演,推演出两个函数:func<int, double, const char*, char> 和 func<int>。也就是说,可变模板参数的本质,还是在编译期对模板进行推演,有多少种 Args 的参数版本,就推演出多少种实例。
另外的,可变模板参数,也可以用于非类型模板参数,例如:
template <int... args>
void func()
{}
此时args就不是一个类型了,而是包含了不定数量int值的一个参数包。不过这种用的比较少,简单了解即可。
对于args本身,也有两种常见操作:
- 求长度
template <typename... Args>
void func(Args ...args)
{std::cout << sizeof...(args) << std::endl;
}
此处语法有点特殊,sizeof...()表示求一个参数包内有多少个参数。
- 展开
void add(int x, int y)
{std::cout << x + y << std::endl;
}template <typename ...Args>
void func(Args ...args)
{add(args...);
}
此处 add(args...) 的意思是:把args一个一个展开,传给add函数。要注意的是,此时你调用func函数必须传入两个int,否则会调用失败。
例如func(1, 2)就会输出3。
在展开时,可以使用表达式对 args 做处理:
template <typename ...Args>
void func(Args ...args)
{add((args * 2)...);
}
此处(args * 2)...,会把args每个参数拿去做* 2 这个表达式,在一个一个传给add函数,如果此时再去执行func(1, 2)就会输出6。
此外,在C++11的初始化列表中也支持在{}对参数进行展开:
template <typename ...Args>
void func(Args ...args)
{std::initializer_list<int> lt{ args... };
}
这样就会把args的所有参数拿来构造一个初始化列表,不过要确保args的每个参数都是int。
总结一下,args的常见操作就是sizeof...()求长度,以及传入函数()内部和初始化列表{}内部做展开,并且在展开的同时,可以使用表达式对每个参数做处理。
那么问题来了,要如何一个一个拿到args的每一个类型?这就涉及到参数包的展开。对于函数模板和类模板,有不同的展开方式,接下来一一讨论。
函数模板展开参数包
递归展开
想要拿到参数包里的每个参数,最基础的方法就是递归展开,流程如下:
void printArgs()
{
}template <typename T, typename ...Args>
void printArgs(T t, Args ...args)
{std::cout << t << std::endl;printArgs(args...);
}
在递归展开中,至少要写两个模板,其中第一个模板一般为<typename T, typename... Args>,T用于接收参数包中的第一个参数,Args用于接收后续参数。这样就可以把传入的多个参数的第一个单独拿出来处理,随后printArgs(args...)递归进入下一次调用,注意此时args已经少了一个参数,第二个参数成为新的T。
例如printArgs(1, 3.15, 'x')这个调用,第一次T = int,第二次T = double,第三次T = char。
但是这样还有问题,第三次调用T = char时args为空,下一次再调用printArgs就会出错,因为没有可以匹配的模板。为此专门写一个无参版本的printArgs(),它什么也不干,只是为了保证最后一次args为空时调用不会出错。
初始化列表 + 逗号表达式
在前文说过,在函数()内部,以及初始化列表{}内部可以展开参数包,并且可以对展开的参数包做处理,那么基于初始化列表 + 逗号表达式也可以完成参数包的展开。
template <typename ...Args>
void printArgs(Args... args)
{std::initializer_list<int>{(std::cout << args << std::endl, 0)...};
}
在 printArgs 函数中,为了输出每一个参数,在初始化列表{}中把args通过...进行展开,也就是{ args... }。
但是我们不能保证args的每一个参数,类型都相同,这样初始化列表就会出错。因此把每个元素固定为整形,通过逗号表达式固定返回0,代码就变成了{ (args, 0)... }。在逗号表达式中,会从前往后依次执行每一个表达式,但是整个表达式的返回结果是最后一个值。也就是说 (args, 0) 这个逗号表达式,会先执行每个args,随后返回0,从而构成一个所有数值都为0,长度与args相同的初始化列表。
在刚才的表达式中,args本身什么也不做,因为它只是一个值,既然我们要输出每一个参数,那么可以用std::cout,最后表达式就变成了{ (std::cout << args << std::endl, 0)... }。如果你希望拿args的每个参数去调用函数,也可以写为{ (func(args), 0)... }。
经过一步一步推导,你应该可以理解这种方式是如何来的了,它相比于递归展开,可以少些一个终止函数,看起来会简洁一些,但是想要理解还是需要一步一步理清思路的。
别忘了,不只有初始化列表{}可以做参数展开,函数参数列表也可以做参数展开,那还可以写出这样的骚操作:
template <typename ...Args>
void donothing(Args... args)
{ }template <typename ...Args>
void printArgs(Args... args)
{donothing((std::cout << args << std::endl, 0)...);
}
写一个donothing函数,顾名思义啥也不做。随后在调用donothing时,在传参时进行参数包展开,其中 (std::cout << args << std::endl, 0)...和之前完全相同,最后把多个0作为参数,传递给donothing函数。
但是这段代码有可能会导致逆序输出,在不同编译器上执行结果不同,这可能是因为函数的传参顺序不同,导致std::cout执行顺序不同,没有初始化列表稳定,简单了解就好。
类模板展开参数包
递归展开
类模板的递归展开,其实和函数模板的递归展开是相同的,就是设置一个<typename T, typename... Args>,每次把参数包的第一个参数取出来。
template <typename... Args>
struct Processor;// 基本情况:参数包为空
template <>
struct Processor<>
{void process() {}
};// 递归情况:处理第一个类型,然后递归处理剩余的类型
template <typename Head, typename... Args>
struct Processor<Head, Args...>
{void process() {// 处理 Head 类型std::cout << "Processing type: " << typeid(Head).name() << std::endl;// 递归处理剩余的类型Processor<Args...> tail_processor;tail_processor.process();}
};
这个其实和函数展开过程几乎一模一样。
继承展开
另一种是通过继承,这也是std::tuple的实现原理,稍后会讲解。
继承展开的原理,就是让 class<A, B, C, D> 去继承 class<B, C, D>,在 class<A, B, C, D> 这一层只处理A这个值。而class<B, C, D> 继承 class<C, D>,以此类推,直到 class<D> 继承空 class<>。
// 前向声明,在定义之前使用
template<typename... Types>
struct TypeList
{
};// 基础情况:参数包为空
template<>
struct TypeList<>
{std::list<std::string> type_list;
};// 递归情况:从参数包中取出一个类型
template<typename First, typename... Args>
struct TypeList<First, Args...>: public TypeList<Args...>
{TypeList(){this->type_list.push_front(typeid(First).name());}
};
TypeList这个类,把所有参数的名字存到了一个list<string>里面,现在详细分析一下他是如何完成的。
用户传入一个参数包后,只要参数包不为空,就会匹配TypeList<First, Args>这个特化,而TypeList<First, Args> 继承 TypeList<Args>。假如用户传入 <int, double, float>,那么 First = int,Args = <double, float>,也就完成了TypeList<int, double, float> 继承 TypeList<double, float>。
在最后,当模板参数为空,匹配 TypeList<> 这个特化,就会定义一个类成员 type_list,这个成员被一层一层public继承下去,所有子类都可见。
在每一层的 TypeList 中,都会把自己类型的名称push_front 到继承下来的 type_list 中,这也就是刚才说的:“每一个层级,只处理第一个参数First”。
std::tuple
std::tuple在 C++11 引入,其可以存储任意数量,任意类型的多个元素,其实说到这里,应该就可以感觉到和可变模板参数关系很大了,先简单讲解它的操作,再讲解原理。
创建一个 tuple 语法如下:
std::tuple<type1, type2, type3 ...> name(value1, value2, value3 ...);
例如:
std::tuple<int, std::string, double> t1(42, "Hello", 3.14);
基本操作
- 获取元素
获取tuple中元素的语法还挺特别的,需要用一个std::get函数,如果要获取第n + 1个元素,语法为:
std::get<n>(tuple);
此处的n是下标,而下标从0开始,因此第n + 1个元素是std::get<n>;
例如:
std::tuple<int, float, double> tp(1, 2.2, 3.14);
std::get<1>(tp);
这样就拿到了第二个元素2.2。
有几个注意事项:
std::get<n>中的n必须是在编译期就可以确定的数值,例如宏,常量std::get返回的是引用
- 获取元素个数
想要获取一个tuple的个数,通过模板类std::tuple_size来完成。
std::tuple_size<decltype(tuple)>::value
此处 tuple_size 是一个类,通过模板参数传入 tuple 的类型,类中的value静态成员就是这个tuple的长度。
例如:
std::tuple<int, float, double> tp(1, 2.2, 3.14);
std::tuple_size<decltype(tp)>::value
- 合并
通过 std::tuple_cat 函数,可以把多个tuple合并成一个。
std::tuple_cat(tuple1, tuple2, tuple3 ...);
函数最后返回一个新的合并后的tuple。
由于多个tuple合并起来,模板参数就特别多,比如:
std::tuple<int, float, double> tp1(1, 2.2, 3.14);
std::tuple<int, float, double> tp2(1, 2.2, 3.14);
std::tuple<int, float, double> tp3(1, 2.2, 3.14);auto tp4= std::tuple_cat(tp1, tp2, tp3);
此处tp4的类型就是:
std::tuple<int, float, double, int, float, double, int, float, double>
大部分时候,会用auto接受返回值。
解包 std::tie
每次获取元素,都要通过std::get<n>,这太复杂了,有没有更简便的语法?
有的,std::tie就可以快速拿到tuple,pair中元素的值,并且赋值到已有变量上。
std::tuple<int, double, std::string> tp(10, 3.14, "Hello");int a;
double b;
std::string c;std::tie(a, b, c) = tp;
这样解包后,a = 10,b = 3.14,c = "hello",这样就可以很快拿到tuple内部的值了。
此外,pair也可以这样取值:
int a;
std::string b;std::pair<int, std::string> p(2, "hello");
std::tie(a, b) = p;
如果希望跳过某些值,可以使用std::ignore进行占位:
std::tuple<int, double, std::string> tp(10, 3.14, "Hello");int a;
std::string c;
std::tie(a, std::ignore, c) = tp;
这样只有a = 10,c = "hello",而3.14被忽略了。
原理
刚刚说过,tuple的特点是可以接收任意数量,任意类型的参数,这也是可变模板参数的特性。tuple这个看似简单的类,其实原理并不简单。
本文使用的源代码来自于,GNU libstdc++版本。
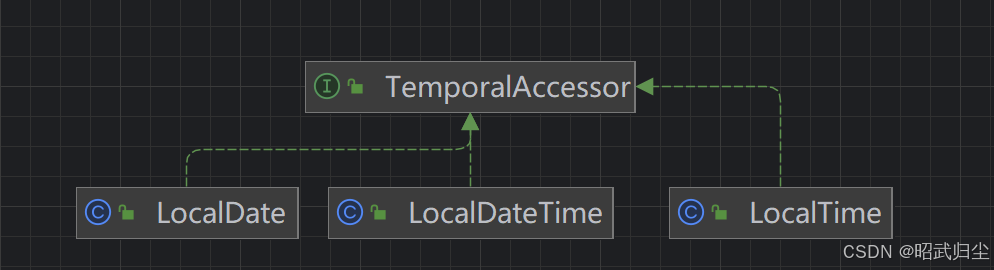
std::tuple 源代码中类定义如下:
template<typename... _Elements>class tuple;template<typename... _Elements>class tuple : public _Tuple_impl<0, _Elements...>template<>class tuple<>
可以看到的是,tuple接收可变模板参数 typename... _Elements。第一个是通用的声明,第二个是通过继承展开,第三个则是不带任何参数的版本。
其中第二个版本通过继承展开模板参数,但是它有点蹊跷,他不是继承std::tuple,而是继承了一个 _Tuple_impl<0, _Elements...>。
- _Tuple_impl
_Tuple_impl源代码中定义如下:
template<size_t _Idx, typename... _Elements>struct _Tuple_impl;template<size_t _Idx, typename _Head, typename... _Tail>struct _Tuple_impl<_Idx, _Head, _Tail...>: public _Tuple_impl<_Idx + 1, _Tail...>,private _Head_base<_Idx, _Head>template<size_t _Idx, typename _Head>struct _Tuple_impl<_Idx, _Head>: private _Head_base<_Idx, _Head>
这也有三个版本,它还有点复杂,我们把第一个参数_Idx删掉,以及继承的_Head_base删掉,就会发现其实和之前的继承展开是一样的:
template<typename... _Elements>struct _Tuple_impl;template<typename _Head, typename... _Tail>struct _Tuple_impl<_Head, _Tail...>: public _Tuple_impl<__Tail...>template<typename _Head>struct _Tuple_impl<_Head>
第一个是通用的声明,第二个声明中,把第一个参数_Head单独提取出来,剩余的用参数包 ..._Tail接收,并且去继承_Tuple_impl<__Tail...>,这不就是典型的继承展开吗?
最后一个声明,是单个参数的特化,作为整个继承链的终点。
再把_Idx加回来,其实这个_Idx就是每个元素的下标,每次继承_Idx + 1。
以std::tuple<int, double, float>为例,其继承链条如下:

- _Head_base
tuple还要存储一个一个元素,那这些元素存储在哪里?
不少人可能会想到,存在每一层继承的_tuple_impl做类成员,比如这样:
template<typename _Head, typename... _Tail>struct _Tuple_impl<_Head, _Tail...>: public _Tuple_impl<__Tail...>
{_Head head; // 这一层的元素
}
用参数包头部的类型_Head去定义一个成员,用这个成员存储元素。这样当然没问题,但是C++在这里做了一个更加精妙的设计,再看到_Tuple_impl的定义:
template<size_t _Idx, typename _Head, typename... _Tail>struct _Tuple_impl<_Idx, _Head, _Tail...>: public _Tuple_impl<_Idx + 1, _Tail...>,private _Head_base<_Idx, _Head>
它不仅仅继承了_Tuple_impl<_Idx + 1, _Tail...>,而且还私有继承了一个 _Head_base<_Idx, _Head>。
_Head_base的源代码定义如下:
template<size_t _Idx, typename _Head>struct _Head_base<_Idx, _Head, true>: public _Head
它去继承了_Head。也就是说,_Tuple_impl<_Idx, _Head, _Tail...>去继承_Head_base<_Idx, _Head>,而_Head_base<_Idx, _Head>去继承_Head,通过继承关系,来拿到 _Head 这个类型!
还是以std::tuple<int, double, float>为例,其继承链条如下:

那这就有人要问了,这么大费周章的搞这样的继承关系,到底有啥用?
我们来观察几个现象:
class Empty
{ };std::cout << "Empty size: " << sizeof(Empty) << std::endl;
std::cout << "tuple<Empty> size: " << sizeof(std::tuple<Empty>) << std::endl;
std::cout << "tuple<int> size: " << sizeof(std::tuple<int>) << std::endl;
std::cout << "tuple<Empty, int> size: " << sizeof(std::tuple<Empty, int>) << std::endl;
此处 Empty 是一个空类。
输出结果:
Empty size: 1
tuple<Empty> size: 1
tuple<int> size: 4
tuple<Empty, int> size: 4
一个奇怪的现象发生了!为什么 tuple<int> 和 tuple<Empty, int> 的大小都是 4 byte!
首先,Empty的大小是1 byte,虽然这个类没有任何成员,也没有虚函数之类的,类里面就是完全为空。但是定义一个Empty变量的时候,是需要地址的,为了给这个空类分配一个地址,就要给他分配至少一个字节的空间,所以Empty和tuple<Empty>的大小都是1 byte。
但是int是4 byte,按理来说 tuple<Empty, int> 应该是5 byte啊,为什么少了一个字节?
这就是此处tuple设计的巧思,在面对空类的时候,可以缩减内存!
这涉及到一个空基类优化 EBO 的概念:
空基类优化
刚才提到,当一个类为空类的时候,编译器依然为其分配1 byte 的空间,保证这个类的实例有地址。但是C++还有另外一个机制:
当一个空类作为基类,其内存大小会被优化为
0 byte
验证:
class Empty
{ };class EmptyImpl : public Empty
{int x;
};
此处 EmptyImpl 继承了 Empty,并且定义了一个额外的变量int x。
std::cout << "Empty size:" << sizeof(Empty) << std::endl;
std::cout << "EmptyImpl size:" << sizeof(EmptyImpl) << std::endl;
代码输出结果为:
Empty size:1
EmptyImpl size:4
可以看到,EmptyImpl的大小为 4 byte,也就是那个整形的大小,也就是说,基类的1 byte被优化掉了!这就是空基类优化。
回看之前的代码:
class Empty
{ };std::cout << "Empty size: " << sizeof(Empty) << std::endl;
std::cout << "tuple<Empty> size: " << sizeof(std::tuple<Empty>) << std::endl;
std::cout << "tuple<int> size: " << sizeof(std::tuple<int>) << std::endl;
std::cout << "tuple<Empty, int> size: " << sizeof(std::tuple<Empty, int>) << std::endl;
其继承关系如下:

我特意用红色字体标注了每个类的大小,在红色的类_Tuple_impl<0, Empty, int>发生了空基类优化,此时优化掉了来自Empty一个字节,从而缩减了内存占用!
有人可能要说了,为了这一个字节至于吗?
这个细节优化的远不止一个字节,首先,如果这个类有多个空基类,所有的基类都可以被优化。
假如一个tuple有一个int,一百个Empty:

最后这个tuple还是占用4byte,一共发生了一百次空基类优化,那么就节省了100 byte。
另外,在对象的内存对齐规则中,最后类的大小,是最大对齐数的整数倍。如果一个tuple<long long, Empty>,不使用空基类优化,那么它存储两个成员至少需要8 + 1 byte,但是由于内存对齐,最后占用的大小就是16 byte。也就是说,哪怕只发生了一次空基类优化,由于内存对齐存在,也很可能优化了不止1 byte。
emplace 原理
最后再来看看,可变模板参数的第二个应用,emplace系列接口。这个系列的接口也是C++11版本引入的,它使用了右值引用,可变模板参数 两大新特性。
现有一个Date日期类:
class Date
{
public:Date(int year, int month, int day): _year(year), _month(month), _day(day){std::cout << "Date: constructor" << std::endl;}Date(const Date& other){_year = other._year;_month = other._month;_day = other._day;std::cout << "Date: copy" << std::endl;}private:int _year;int _month;int _day;
};
它实现了构造函数和拷贝构造。
现在使用std::list存储这个日期类,并分别用push_back和emplace_back分别插入两个元素:
std::list<Date> lt;std::cout << "push_back:" << std::endl;
lt.push_back({2025, 5, 31});std::cout << "emplace_back:" << std::endl;
lt.emplace_back(2025, 5, 31);输出结果:
push_back:
Date: constructor
Date: copy
emplace_back:
Date: constructor
可以看到,emplace_back相比于push_back少了一次copy,这是如何做到的?
来看看list的emplace_back源码:
void emplace_back(_Args&&... __args)
{this->_M_insert(end(), std::forward<_Args>(__args)...);
}
看到熟悉的身影了,_Args&&... __args不就是可变模板参数吗?而且还是以右值引用的形式。
这个_args参数通过完美转发,发送到了_M_insert这个函数,这个函数用于在指定迭代器前面插入元素,而传入end迭代器,表示在链表尾部插入元素。
代码如下:
void _M_insert(iterator __position, _Args&&... __args)
{_Node* __tmp = _M_create_node(std::forward<_Args>(__args)...);__tmp->_M_hook(__position._M_node);this->_M_inc_size(1);
}
_M_create_node这个函数是关键,它负责list节点的构造,_M_hook就是在处理链表节点之间的指针连接,_M_inc_size是链表长度的自增。
在建造节点的时候,还是通过完美转发把参数包传进去了!
template<typename... _Args>
_Node* _M_create_node(_Args&&... __args)
{auto __p = this->_M_get_node();auto& __alloc = _M_get_Node_allocator();__allocated_ptr<_Node_alloc_type> __guard{__alloc, __p};_Node_alloc_traits::construct(__alloc, __p->_M_valptr(),std::forward<_Args>(__args)...);__guard = nullptr;return __p;
}
在 _M_create_node中,调用了_Node_alloc_traits::construct,这其实就是在使用定位new的语法,把参数包传进去,然后在指定的内存位置调用构造函数new一个对象。可以简单看成:
new __p->_M_valptr() Date(2025, 5, 3); // 定位 new
源码不再深入解析了,到达_M_create_node就够了。
在整个emplace_back过程中,三个参数(2025, 5, 3)一直通过 可变模板参数 + 右值引用 + 完美转发,一直传入到Date这个构造函数手中,然后在目的地进行构造。也就是说这个过程中,没有发生Date的拷贝构造,而是直接把构造Date所需的参数,通过右值引用不断地往内转发,最后在目的地调用构造函数。
对于push_back来说,它在最外层就构造好了Date对象,随后把最外层的对象 拷贝/移动 进去,在最内层的_M_create_node,进行拷贝构造,这个过程至少发生一次拷贝构造,所以看起来push_back就比emplace_back多了一次拷贝过程。
但是实际上在C++11之后,在STL容器内如果发生了拷贝,比如vector扩容。此时会去检测被拷贝的类有没有移动构造,移动赋值,如果实现了移动,并且移动过程中不会抛出异常noexcept,那么会优先调用移动。移动的效率大部分情况下比拷贝要高不少,所以push_back这样的接口,性能也得到了大幅提高,很多时候和emplace甚至差别不大。



![[创业之路-400]:企业战略管理案例分析-战略规划-创新焦点](https://i-blog.csdnimg.cn/direct/7a6cf055450944a493903327bde23041.png)