目录
编辑
摘要
1. 引言
2. 法律AI模型的核心原理
2.1 自注意力机制的法律应用
2.2 法律任务特定公式
2.3 位置编码与法律文本结构
3. 从通用模型到法律专用AI的演进
3.1 模型架构演进
3.2 训练流程优化
4. 法律AI的应用场景与案例分析
4.1 合同审查与生成
4.2 法律问答与咨询
4.3 司法预测与案件分析
5. 挑战与未来方向
5.1 当前技术挑战
5.2 未来发展方向
后记
参考文献
摘要
本文深入探讨了人工智能大模型在法律领域的应用原理、技术演进和实际案例。首先,介绍了基于Transformer架构的法律AI模型核心机制,包括自注意力机制和任务特定公式;其次,分析了从通用大语言模型到法律专用模型的演进路径;接着,详细阐述了法律AI在合同审查、法律问答和案件预测等场景的应用实例;最后,讨论了当前面临的伦理、偏见和效率挑战,以及未来发展方向。通过数学公式和案例分析,本文为读者提供了对法律AI技术原理的全面理解,强调其在提升法律效率和公平性方面的潜力。
关键词:法律AI、大语言模型、Transformer、法律文本处理、智能法律助手
1. 引言
近年来,人工智能大模型在法学领域掀起革命性变革。以ChatGPT为代表的大语言模型,通过海量法律文本训练,展现出在合同分析、法律咨询和司法预测等方面的强大能力。法律AI不仅提升了法律服务的效率,还降低了专业门槛,但同时也引发了关于偏见、伦理和可靠性的讨论。本文将从技术原理出发,系统解析法律AI大模型的工作机制,帮助读者理解其如何变革传统法律实践。全球法律科技市场预计到2025年将突破250亿美元,凸显了该领域的巨大潜力。
2. 法律AI模型的核心原理
法律AI大模型基于Transformer架构,但针对法律文本的特性进行了优化。法律文本通常具有高度结构化、专业术语密集的特点,模型通过自注意力机制捕捉上下文依赖关系。
2.1 自注意力机制的法律应用
自注意力机制是Transformer的核心,其公式如下:
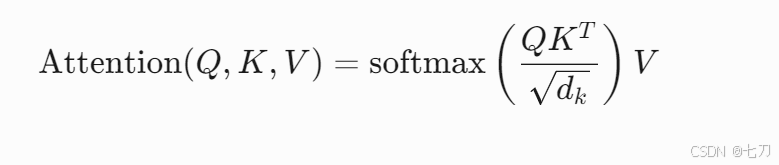
其中:
Q(Query) 表示查询向量,用于定位关键法律条款。K(Key) 表示键向量,对应法律文本中的实体(如“合同条款”)。V(Value) 表示值向量,存储语义信息(如“违约责任”)。d_k是键向量的维度,通常设置为512或1024以处理复杂法律文档。- softmax函数确保注意力权重归一化,聚焦于相关部分。
在法律AI中,多头注意力机制扩展了这一概念:
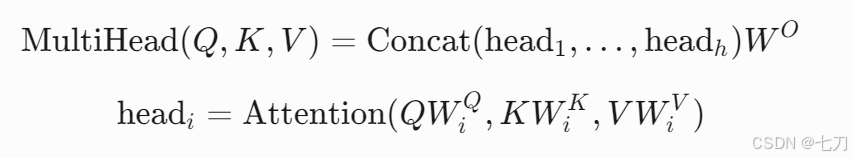
这里,h 表示头数(通常8-16),每个头独立学习不同法律特征(如条款类型或时间序列),提升模型对合同漏洞的检测能力。
2.2 法律任务特定公式
针对法律应用,模型输出层采用任务驱动公式。例如,在法律文本分类(如判断合同风险等级)中,使用交叉熵损失函数:
其中:
y_i是真实标签(0表示低风险,1表示高风险)。p_i是模型预测概率,通过sigmoid函数输出:p_i = \sigma(Wx + b)。N是样本数,训练数据通常来自法律数据库。
在司法预测任务中,模型可能采用序列生成公式:
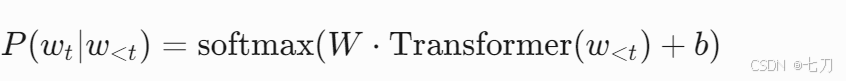
这里,w_t 表示预测的下一个词(如“胜诉”),模型基于历史词序列 w_{<t} 输出概率分布,用于生成法律意见书。
2.3 位置编码与法律文本结构
法律文档强调顺序(如条款编号