1.进程的介绍
1. 进程的基本概念
在 Python 中,进程是操作系统分配资源和调度的基本单位,代表一个独立的程序执行实例。Python 的 multiprocessing 模块支持多进程编程,允许在单个程序中并行运行多个进程。每个进程拥有:
-
独立的 Python 解释器实例
-
独立的内存空间
-
不受全局解释器锁(GIL)限制,适合 CPU 密集型任务
2. 使用进程的优点
✅ 并行计算
-
多进程可充分利用多核 CPU,每个进程运行在单独的核心上,实现真正的并行计算。
✅ 内存隔离
-
进程间不共享内存,避免数据竞争和同步问题,提高稳定性。
3. 需要注意的问题
⚠ 更高的资源开销
-
进程的创建和销毁比线程更消耗资源(内存、CPU)。
⚠ 进程间通信(IPC)较复杂
-
由于内存隔离,进程间通信需要特殊机制,如:
-
Queue(线程安全的队列) -
Pipe(管道,适用于两个进程通信) -
Value/Array(共享内存,需同步控制
-
4.进程的创建与使用:
以下是如何使用multiprocessing模块创建和启动两个进程的简单实例:
from multiprocessing import Processdef print_numbers():for i in range(5):print(i)def print_letters():for letter in 'abcde':print(letter)# 创建进程
process1=Process(target=print_numbers)
process2=Process(target=print_letters)# 启动进程
process1.start()
process2.start()# 等待进程完成
process1.join()
process2.join()5.结论:
Python 的 多进程编程 提供了一种高效的并发执行方案,尤其适用于:
✅ CPU 密集型任务(如数值计算、数据处理)
✅ 需要隔离执行环境(避免数据竞争,提高稳定性)
对比线程的优势与代价
✔ 优势
-
绕过 GIL 限制,真正并行执行
-
充分利用多核 CPU,提升计算效率
-
内存隔离,避免线程间的同步问题
⚠ 代价
-
进程创建和切换开销更大(相比线程)
-
进程间通信(IPC)更复杂(需使用
Queue、Pipe、共享内存等机制)
适用场景建议
-
优先使用多进程:计算密集型任务(如机器学习、科学计算)
-
优先使用多线程:I/O 密集型任务(如网络请求、文件读写)
正确使用多进程能显著提升 Python 程序的性能,但需权衡资源开销和开发复杂度。
2.进程的使用
1.进程的概述
程序 vs. 进程
| 程序 | 进程 |
|---|---|
静态的代码文件(如 14.py) | 动态执行的实例(程序运行时的状态) |
| 存储在磁盘上 | 加载到内存中执行 |
| 无执行状态 | 包含代码、数据、内存、CPU 资源等 |
关键概念
-
进程是操作系统分配资源的基本单位(CPU、内存、文件句柄等)。
-
进程 = 程序代码 + 运行时资源(数据、内存、寄存器状态等)。
-
每个进程独立运行,拥有自己的地址空间,互不干扰。
示例
-
双击
14.py→ Python 解释器运行它 → 创建一个进程(分配内存、CPU 时间等)。 -
同时运行两个
14.py→ 两个独立进程(即使代码相同,内存和状态各自独立)。
2.进程的创建与简单使用
multiprocessing 模块就是跨平台版本的多进程模块,提供了一个 Process 类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情。
from multiprocessing import Processdef work():print('子进程任务启动...')if __name__ =="__main__":# 创建进程对象p = Process(target=work)# 启动进程p.start()并行执行两个循环任务
import time
from multiprocessing import Processdef proc():while True:print("当前任务被子进行运行...")time.sleep(1)if __name__=='__main__':p = Process(target=proc)p.start()while True:print("当前任务被主进程运行...")time.sleep(1)创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动
获取进程的pid
import os
from multiprocessing import Processdef proc():print(f'子进程运行中,pid={os.getpid()}')print('子进行即将退出...')if __name__ == '__main__':print(f'父进程pid:{os.getpid()}')p=Process(target=proc)p.start()3.进程的内置参数与内置方法
multiprocessing.Process内置参数
| 参数名称 | 参数作用 |
|---|---|
| target | 如果传递了函数的引用,可以任务这个子进程就执行这里的代码 |
| args | 给target指定的函数传递的参数,以元组的方式传递 |
| kwargs | 给 target 指定的函数传递命名参数 |
| name | 给进程设定名称,也可以不设定 |
| group | 指定进程组,大多数情况下用不到 |
multiprocessing.Process内置方法
| 方法名称 | 方法作用 |
|---|---|
| start() | 启动子进程实例(创建子进程) |
| is_alive() | 判断子进程是否存活 |
| join(<timeout>) | 是否等待子进行执行结束或等待多少秒 |
| terminate() | 不管任务是否完成都立即终止子进程 |
给子进程指定的函数传递参数
import os
import time
from multiprocessing import Processdef proc_1(name,age,**kwargs):for i in range(10):print(f'子进程运行中:{name},{age},{os.getpid()}')print(f'传递的不定长kw参数为:{kwargs}')time.sleep(0.5)if __name__ == '__main__':p=Process(target=proc_1,args=('admin',22),kwargs={'address':'克州'})p.start()time.sleep(1) # 主程序休眠一秒p.terminate() # 不管任务是否完成都立即终止子进程# 使用join方法确保了子进程已经被操作系统清理,如果没有调用join方法则子进程会成为僵尸进程p.join()print(p.is_alive()) # 判断子进程对象是否存活进程间不共享全局变量
import os
import time
from multiprocessing import Processnums=[11,22]def work_1():print('子进程-1的pid为:%d,初始列表=%s'%(os.getpid(),nums))for i in range(1,4):nums.append(i)time.sleep(1)print('子进程-1的pid为:%d,操作后的列表=%s'%(os.getpid(),nums))def work_2():print('子进程-2的pid为:%d,全局列表=%s'%(os.getpid(),nums))if __name__ == '__main__':p1=Process(target=work_1)p1.start()p1.join()p2=Process(target=work_2)p2.start()
3.进程与线程的对比
1. 功能区别
| 进程 | 线程 | |
|---|---|---|
| 功能 | 完成多任务(如同时运行多个QQ) | 完成多任务(如一个QQ中的多个聊天窗口) |
| 独立性 | 独立运行,资源隔离 | 共享进程资源,依赖进程存在 |
2. 定义对比
| 进程 | 线程 | |
|---|---|---|
| 资源分配 | 系统分配资源的基本单位 | 进程的一个执行单元 |
| 调度单位 | 操作系统调度 | CPU调度和分派的基本单位 |
| 资源拥有 | 独立内存空间和系统资源 | 仅拥有必要资源(程序计数器、寄存器、栈),共享进程资源 |
3. 关键区别
| 对比维度 | 进程 | 线程 |
|---|---|---|
| 数量关系 | 一个程序至少一个进程 | 一个进程至少一个线程 |
| 资源占用 | 独立内存单元,资源占用多 | 共享内存,资源占用少 |
| 执行方式 | 可独立执行 | 必须依赖进程存在 |
| 并发性 | 并发性较低(切换开销大) | 并发性高(切换开销小) |
| 类比 | 工厂中的一条完整流水线 | 流水线上的工人 |
4. 优缺点分析
| 优点 | 缺点 | |
|---|---|---|
| 进程 | 资源隔离,安全性高,稳定性强 | 创建/切换开销大,通信复杂 |
| 线程 | 创建/切换快,通信简单,高效并发 | 资源共享导致同步问题,不稳定 |
5. 使用建议
-
选择进程:需要安全隔离、CPU密集型任务
-
选择线程:需要高效并发、I/O密集型任务
4.进程通信
1. 概述
-
必要性:进程间需要数据交换(如生产者-消费者模型)
-
挑战:进程拥有独立内存空间,无法直接访问彼此数据
-
解决方案:操作系统提供的IPC机制
2. 主要通信方式
| 机制 | 实现方式 | 特点 | Python实现 | 适用场景 |
|---|---|---|---|---|
| 管道(Pipe) | 单向/双向字节流 | 简单高效;仅适用于父子进程 | multiprocessing.Pipe() | 少量数据交换 |
| 队列(Queue) | 先进先出(FIFO)的消息队列 | 线程安全;支持多生产者/消费者 | multiprocessing.Queue() | 多进程任务分发 |
| 共享内存 | 映射同一块物理内存 | 最快IPC方式;需要同步机制 | multiprocessing.Value/Array | 高性能数据共享 |
| 信号(Signal) | 系统预定义事件通知 | 异步通信;信息量有限 | signal模块 | 进程控制 |
| 套接字(Socket) | 网络通信接口 | 支持跨网络通信;开销较大 | socket模块 | 分布式系统 |
| 文件 | 磁盘文件读写 | 简单但效率低;需要处理竞态条件 | 普通文件操作 | 临时数据交换 |
3. Python多进程通信最佳实践
-
简单通信 → 使用
Queue -
高性能需求 → 共享内存+同步锁
-
跨机器通信 → Socket
-
父子进程 → Pipe
4. 注意事项
-
避免死锁:获取多个锁时按固定顺序
-
注意序列化:传输对象需可pickle
-
资源释放:显式关闭通信通道
5.Queue的使用
可以使用multiprocessing模块的Queue实现多进程之间的数据传递。
Queue本身是一个消息列队程序,首先用一个实列来演示一下Queue的工作原理:
from multiprocessing import Queuequeue=Queue(3) # 初始化一个Queue对象,最多可接收三条put消息queue.put('消息1')
queue.put('消息2')
print(queue.full()) # 判断当前队列是否已满:Falsequeue.put('消息3')
print(queue.full())# 如果队列已满put_nowait会立即抛出异常,put等待两秒会抛出异常
# queue.put('消息4',True,2)
# queue.put_nowait()# 推荐的方式,先判断消息队列是否已满,再写入
if not queue.full():queue.put_nowait('消息4')# 读取消息时,先判断消息队列是否为空,再读取
if not queue.empty():for i in range(queue.qsize()):print(queue.get_nowait())6.进程队列对象内置方法概述
| 方法名称 | 方法作用 |
|
| 返回当前队列包含的消息数量 |
|
| 如果队列为空,返回 |
|
| 如果队列已满,返回 |
|
| 获取队列中的一条消息,然后将其从列队中移除 |
|
| 如果队列为空则直接抛出异常,相当于 |
|
| 将 |
|
| 如果队列已满则直接抛出异常,相当于 |
7.进程队列代码示例
在父进程中创建两个子进程,一个往队列里写数据;一个从队列里读数据
import time,randomfrom multiprocessing import Process,Queue# 写数据进程执行的代码:
def write(queue):for item in ['A','B','C']:print(f'向队列上传的值为:{item}')queue.put(item)time.sleep(random.random())# 读数据进程执行的代码
def read(queue):while True:item=queue.get()if item is not None:print(f'向队列获取的值为:{item}')time.sleep(random.random())else:breakif __name__ == '__main__':q=Queue()p1=Process(target=write,args=(q,)) # 写入p2=Process(target=read,args=(q,)) # 读取p1.start()p2.start()# 等待写入任务完成后主进程继续向下执行p1.join()# 使用主进程向队列传递哨兵q.put(None)# 等待读取任务完成后主进程继续向下执行p2.join()print('主程序即将退出...')
5.进程池
1.使用Pool创建进程池
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态 生成多个进程,但是如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
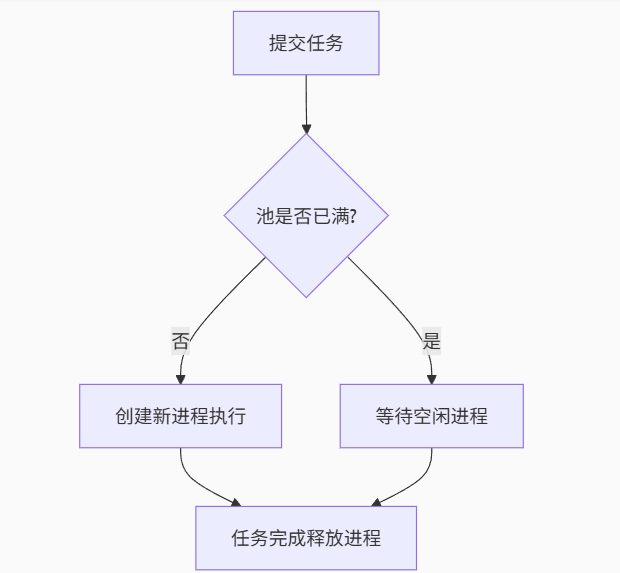
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。
工作流程如下图:
代码示例
import os
import time
import random
from multiprocessing import Pooldef worker(proc_name,*args,**kwargs):p_start=time.time()print(f'{proc_name}开始执行,进程号为:{os.getpid()}')print('任务接收到的args不定长参数为:',args)print('任务接收到的kw不定长参数为:',kwargs)# random.random():随机生成0~1之间的浮点数time.sleep(random.random()*2)p_stop=time.time()print(f'{proc_name}执行完毕,子进程耗时为:{p_stop - p_start:.2f}')if __name__ == '__main__':# 主程序启动计时main_start=time.time()# 定义一个进程池,最大进程数3pool=Pool(3)for item in range(1,11):# apply_async(要调用的目标,(传递给目标的参数,))# 每次循环将会用空闲出来的子进程去调用目标pool.apply_async(worker,(item,'测试参数-1','测试参数-2'),kwds={'proc_kw':'proc_attr'})# 同步执行 执行该方法会导致主进程堵塞# pool.apply(worker,(item,))# 关闭进程池,关闭后pool不再接收新的请求pool.close()# 等待pool中所有子进程执行完成,必须放在close语句之后pool.join()main_stop=time.time()print(f'主程序耗时:{main_stop - main_start:.2f}')multiprocessing.Pool常用函数解析:
| 方法名称 | 方法作用 |
|
| 使用非阻塞方式调用 |
|
| 关闭 |
|
| 不管任务是否完成,立即终止任务 |
|
| 主进程阻塞并等待子进程的退出, 必须在 |
2.进程池中的Queue
如果要使用 Pool 创建进程,就需要使用 multiprocessing.Manager()中的Queue(),而不是 multiprocessing.Queue()。否则可能会得到一条如下的错误信息: RuntimeError: Queue objects should only be shared between processes through inheritance.
以下实列演示了进程池中的进程如何通信:
import os
import time
from random import randint
from multiprocessing import Manager,Pooldef reader(queue):print(f'读取任务启动,进程的pid为:{os.getpid()}')while True:message=queue.get()if message is not None:print(f'读取任务从队列中获取到消息为:{message}')else:breakdef writer(queue):print(f'写入任务启动,进程的pid为:{os.getpid()}')url_list=['https://www.baidu.com','https://www.goole.com','https://www.facebook.com','https://www.yahoo.com','https://www.linkedin.com','https://www.github.com','https://www.bing.com']for item in url_list:queue.put(item)time.sleep(randint(1,2)) # 模拟IO延迟queue.put(None) # 任务退出前传递哨兵信号if __name__ == '__main__':print('主程序启动...')# 无法使用进程中的Queue队列# q=Queue()# 使用Manager中的Queueq=Manager().Queue()pool=Pool()pool.apply_async(writer,(q,))pool.apply_async(reader,(q,))pool.close()pool.join()print('主程序即将退出...')
3.获取进程池返回值
同步/并发 获取返回值
import time
from random import random
from multiprocessing import Pool# 返回值从进程池获取,父子进程没有返回值
def proc_func(num):# 模拟随机延迟time.sleep(random())# 任务函数使用return将计算结果返回return num * numif __name__ == '__main__':pool = Pool(5)# 存放future对象result_list = list()for item in range(1, 11):result = pool.apply_async(proc_func, args=(item,))# 将future对象添加到列表中result_list.append(result)for item in result_list:# 使用进程池结果对象中的get方法获取结果print(item.get())if __name__ == '__main__':pool = Pool(5)
利用map()方法获取返回值
import time
from random import random
from multiprocessing import Pooldef proc_func(num):time.sleep(random())return num*numif __name__ == '__main__':pool=Pool(5)result=pool.map(proc_func,range(1,11))print(result)注意点:
- map()是一次性获取所有子进程的返回值,自带close、join
- apply_async是分批返回
4.使用 concurrent 模块创建进程池
concurrent 模块创建进程池的使用方式与线程池保持一致,以下为代码示例:
import os
import time
from random import randint
from multiprocessing import Manager
from concurrent.futures import ProcessPoolExecutordef reader(queue):print(f'读取任务启动,进程的pid为:{os.getpid()}')while True:message=queue.get()if message is not None:print(f'读取任务从队列中获取到消息为:{message}')else:print('读取任务结束.')breakdef writer(queue):print(f'写入任务启动,进程的pid为:{os.getpid()}')url_list=['https://www.baidu.com','https://www.google.com','https://www.facebook.com','https://www.yahoo.com','https://www.linkedin.com','https://www.github.com','https://www.bing.com']for item in url_list:queue.put(item)time.sleep(randint(1,2)) # 模拟IO延迟queue.put(None) # 任务退出前传递哨兵信号def main():print('主程序启动...')with Manager() as manager:q=manager.Queue()with ProcessPoolExecutor() as executor:executor.submit(writer,q)executor.submit(reader,q)print('主程序即将退出...')if __name__ == '__main__':main()
6.进程中的生产者与消费者模式
在进程中使用生产者与消费者模式和线程稍有不同,以下为代码示例:
哨兵模式
import time
import queue
from multiprocessing import Process,Queue# 定义生产者函数
def producer(name,queue):for i in range(1,6):item=f'产品{i}'queue.put(item) # 将项放入队列中# 定义消费者函数
def consumer(name,queue):while True:item=queue.get() # 从队列中获取项if item is None:queue.put(item) # 为了让其他消费者也能停止,重新放入哨兵对象。break # 如果为None则停止循环print(f'消费者{name}消费了{item}')time.sleep(2) # 假设消费需要更多时间if __name__ == '__main__':# 创建队列对象q= Queue()# 创建和启动生产者进程producer_process=Process(target=producer,args=('小明',q))producer_process.start()# 创建和启动消费者线程consumer_process=Process(target=consumer,args=('小红',q))consumer_process.start()# 等待生产者进行执行完毕producer_process.join()# 使用主程序往队列中添加哨兵信号:Noneq.put(None)# 等待消费者进程完成consumer_process.join()# 主程序退出print('程序结束')
task_done在进程环境中的
Queue不支持task_done()方法,需要替换成JoinableQueue
import time
from multiprocessing import Process,JoinableQueue as Queue# 定义生产者函数
def producer(name,queue):for i in range(1,6):item=f'产品{i}'queue.put(item) # 将项放入队列中print(f'生产者{name}生产了{item}')time.sleep(1) # 假设生产需要一些时间# 定义消费者函数
def consumer(name,queue):while True:item = queue.get() # 从队列中获取项print(f'消费者{name}消费了{item}')time.sleep(2) # 假设消费需要更多时间queue.task_done() # 指示队列中的任务已经处理完成if __name__ == '__main__':q= Queue()# 创建和启动生产者进程producer_process = Process(target=producer, args=('小明', q))producer_process.start()# 创建和启动消费者线程consumer_process = Process(target=consumer, args=('小红', q))# 将消费者设置为守护进程后启动consumer_process.daemon=Trueconsumer_process.start()# 等待生产者任务完成producer_process.join()# 等待队列任务完成,如果队列完成则允许主程序退出q.join()print('主程序结束...')