名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)目录
- 一、EasyVoice是什么?
- 1. 核心特性一览
- 2. 技术架构概览
- 二、安装部署指南
- 1. Docker极简部署(推荐新手)
- 2. Docker Compose部署(推荐团队)
- 3. 源码编译部署(推荐开发者)
- 三、功能特性深度解析
- 1. 超长文本处理能力
- 2. 流式传输黑科技
- 3. 多角色配音系统
- 4. AI智能配音推荐
- 四、实战案例:制作有声小说
- 1. 准备文本内容
- 2. API调用示例
- 3. 效果对比分析
- 五、性能优化与最佳实践
- 1. 并发参数调优
- 2. 大模型配置优化
- 3. 存储路径规划
- 六、进阶应用场景
- 七、与主流TTS工具对比
- 八、常见问题解答
- 1. 性能相关问题
- 2. 配置相关问题
- 3. 部署相关问题
- 总结与建议
很高兴你打开了这篇博客,更多好用的软件工具,请关注我、订阅专栏《实用软件与高效工具》,内容持续更新中…
在这个人工智能飞速发展的时代,文本转语音(TTS)技术已经从科幻电影走进了我们的日常生活。无论是听书App、导航软件,还是智能助手,语音合成技术都在默默地为我们服务。
今天要给大家介绍的EasyVoice,就是一款让人眼前一亮的开源TTS工具,它不仅能让文字"开口说话",还能实现多角色配音,简直就是内容创作者的福音!
一、EasyVoice是什么?
EasyVoice是由开发者cosin2077开源的一款智能文本转语音解决方案,专门为需要将长文本转换为高质量语音的用户设计。简单来说,它就像是给你的文字配了一个"专业播音员",而且这个播音员还能模拟不同的角色声音!
- 🌟 GitHub: https://github.com/cosin2077/easyVoice
-
🌐 在线体验: https://easyvoice.ioplus.tech/
1. 核心特性一览
让我们先来看看EasyVoice的"豪华配置":
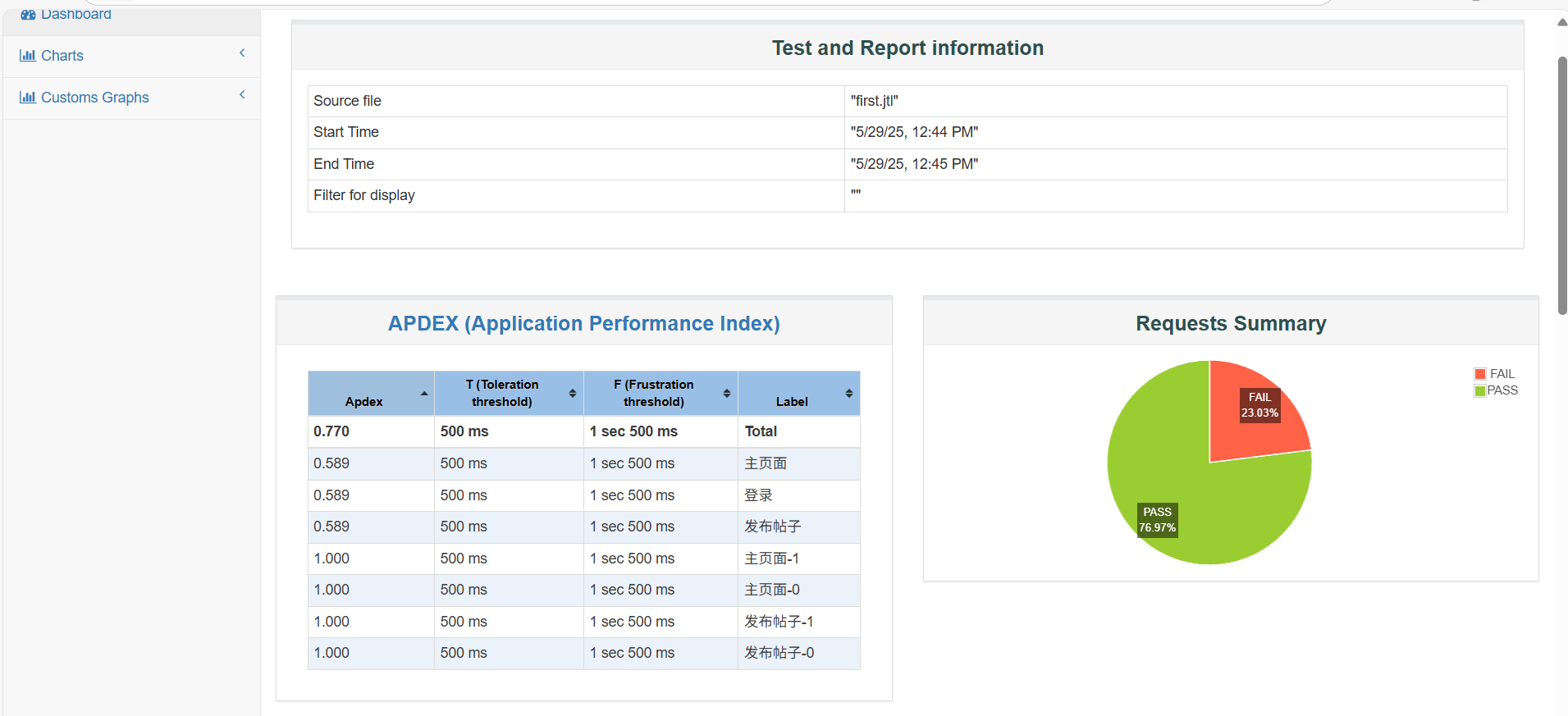
| 功能特性 | 描述 | 应用场景 |
|---|---|---|
| 超长文本支持 | 支持超过10万字的文本转换 | 小说配音、长篇文档朗读 |
| 流式传输 | 边转换边播放,无需等待 | 实时语音交互、直播配音 |
| 多角色配音 | 支持不同角色的声音切换 | 有声小说、广播剧制作 |
| AI智能推荐 | 自动为不同段落推荐最佳配音 | 智能化内容生产 |
| 字幕同步生成 | 语音和字幕同步输出 | 视频制作、无障碍内容 |
| 多语言支持 | 中文、英文等多种语言 | 国际化内容制作 |
2. 技术架构概览
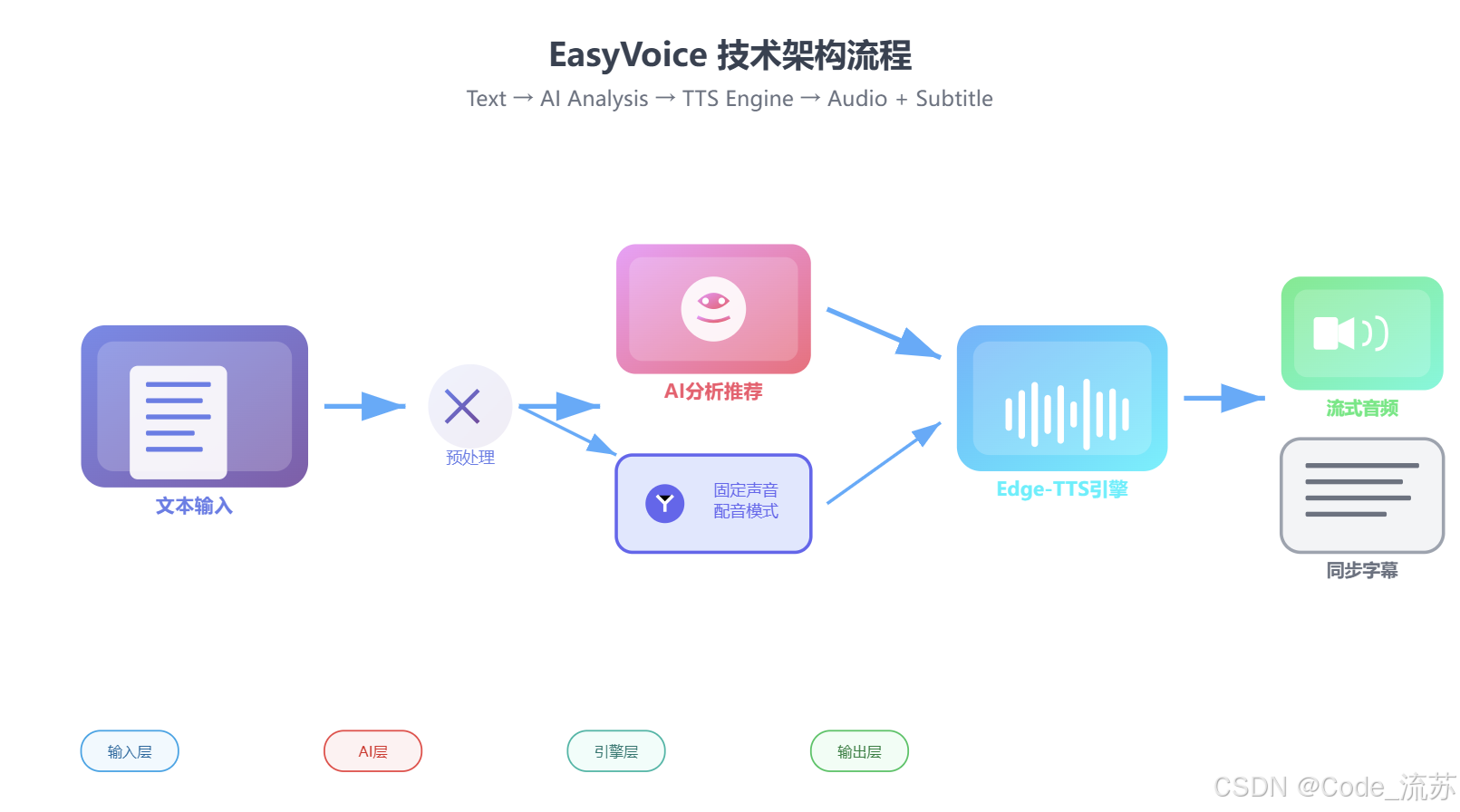
EasyVoice采用了模块化的设计思路,核心依赖Microsoft Edge-TTS API提供免费的语音合成服务,同时集成OpenAI兼容的大模型来实现智能配音推荐。整个系统支持Docker容器化部署和Node.js环境运行,让开发者可以根据需求选择最适合的部署方式。
二、安装部署指南
作为一个"友好"的开源项目,EasyVoice提供了多种部署方式,从小白友好的Docker一键部署,到开发者喜爱的源码编译,应有尽有。
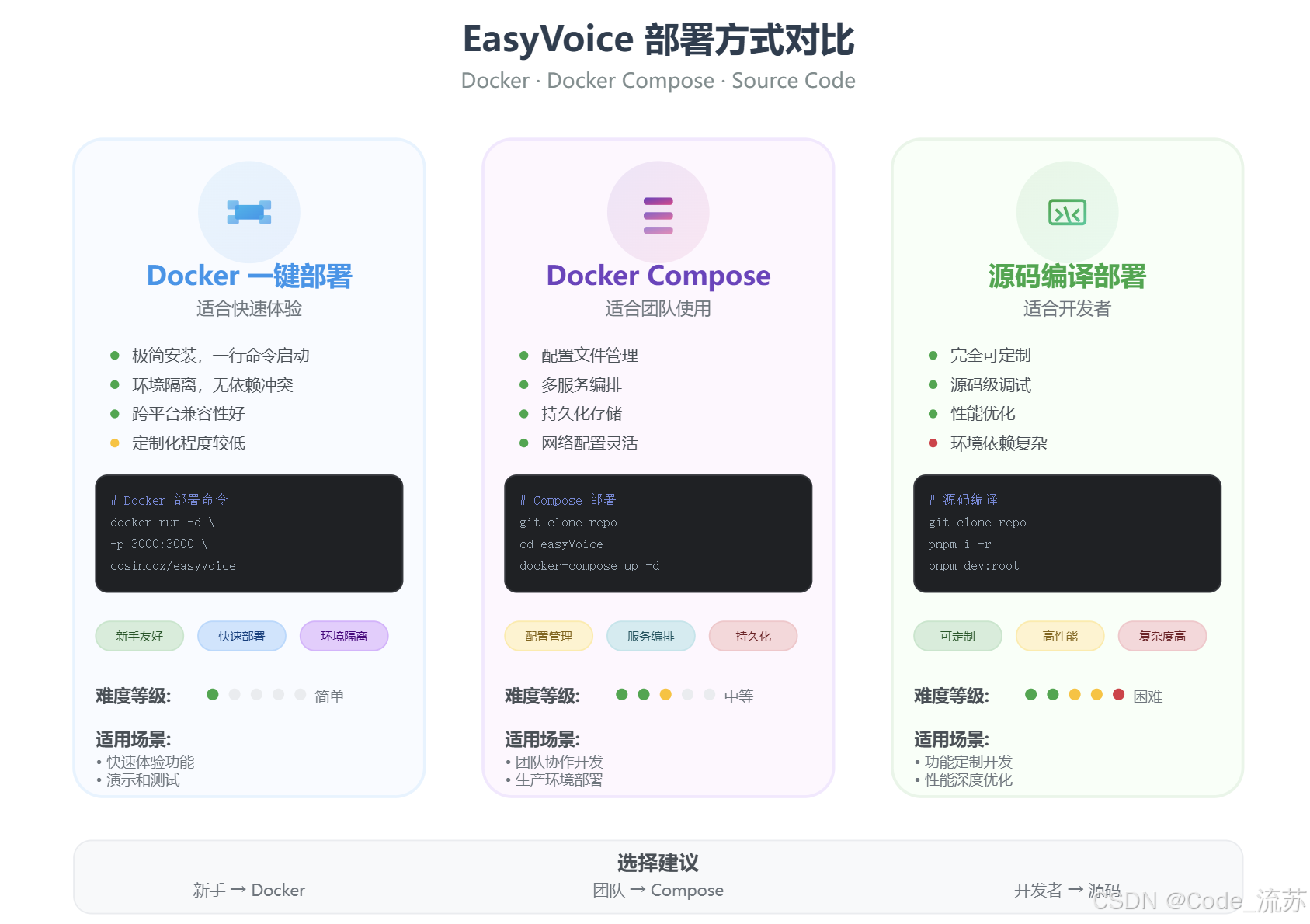
1. Docker极简部署(推荐新手)
如果你只是想快速体验,那么Docker部署绝对是最佳选择:
# 一行命令启动服务
docker run -d -p 3000:3000 -v $(pwd)/audio:/app/audio cosincox/easyvoice:latest
这行命令的含义:
-d:后台运行容器-p 3000:3000:将容器的3000端口映射到本机-v $(pwd)/audio:/app/audio:挂载音频文件存储目录
2. Docker Compose部署(推荐团队)
对于团队使用或需要持久化配置的场景,推荐使用Docker Compose:
# 克隆项目
git clone https://github.com/cosin2077/easyVoice.git
cd easyVoice# 一键启动
docker-compose up -d
3. 源码编译部署(推荐开发者)
想要深度定制或参与开源贡献的开发者,可以选择源码编译:
# 启用pnpm包管理器
corepack enable
# 或者使用npm安装
npm install -g pnpm# 克隆仓库
git clone git@github.com:cosin2077/easyVoice.git
cd easyVoice# 安装依赖
pnpm i -r# 开发模式启动
pnpm dev:root# 生产模式构建和启动
pnpm build:root
pnpm start:root
三、功能特性深度解析
EasyVoice之所以在众多TTS工具中脱颖而出,主要得益于其独特的功能设计和强大的技术实现。
1. 超长文本处理能力
传统的文本转语音工具往往对文本长度有严格限制,但EasyVoice打破了这个束缚:
核心优势:
- 支持10万字以上的长文本处理
- 智能文本分段,避免内存溢出
- 并发处理,显著提升转换速度
- 无缝拼接,保证音频连贯性
2. 流式传输黑科技
最让人惊喜的是EasyVoice的流式传输功能。想象一下,你输入一篇长文章,不用等整篇文章转换完成,就能立即听到开头的语音——这就是流式传输的魅力!
技术原理:
- 边转换边传输:文本转换完一段就立即播放一段
- 低延迟响应:用户体验接近实时交互
- 缓冲管理:智能缓冲策略确保播放流畅
3. 多角色配音系统
这是EasyVoice最具特色的功能之一。
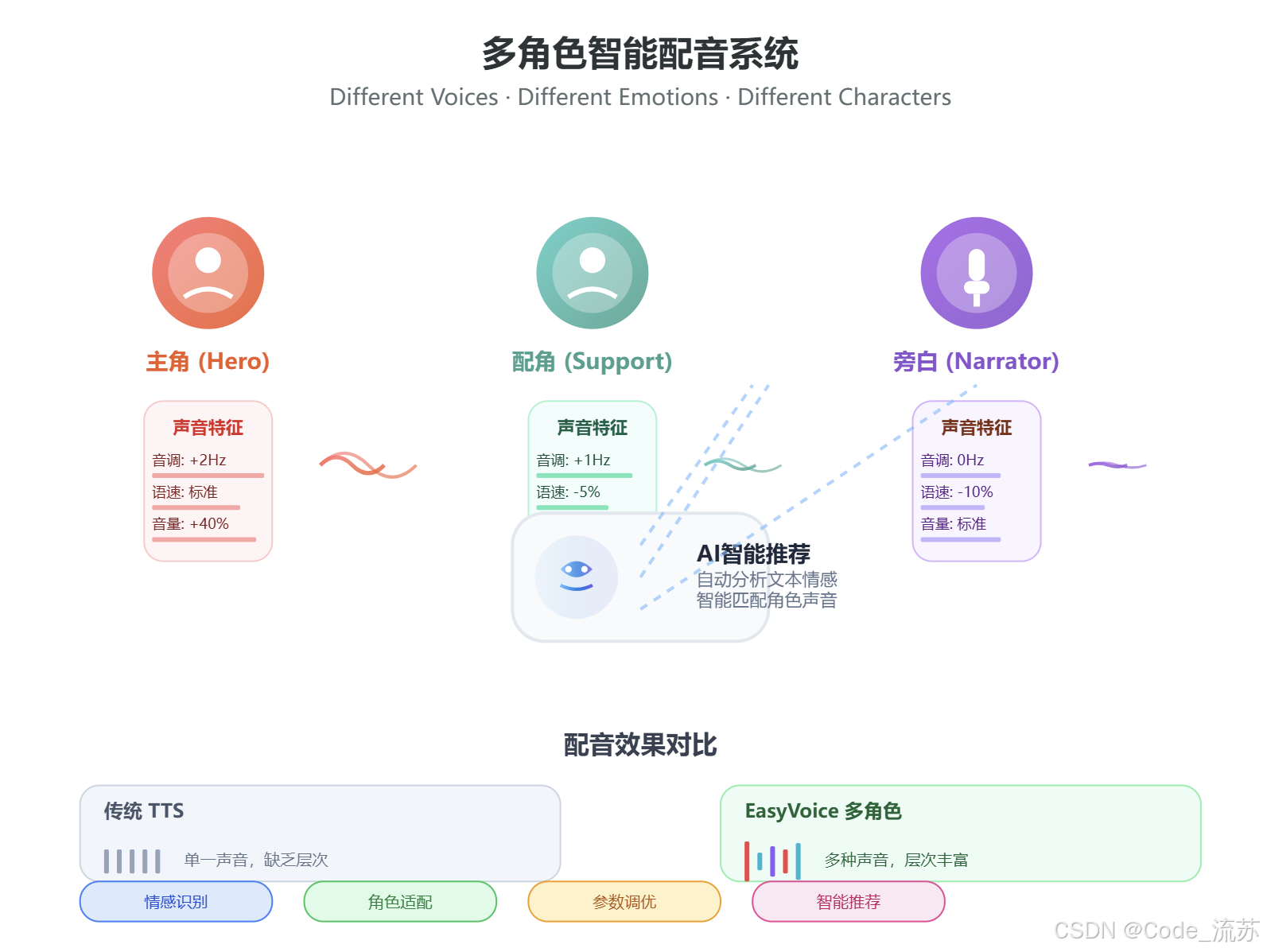
通过JSON配置,你可以为不同的角色分配不同的声音:
{"data": [{"desc": "旁白","text": "在一个风雨交加的夜晚...","voice": "zh-CN-YunxiNeural","rate": "0%","pitch": "0Hz","volume": "0%"},{"desc": "主角","text": "我一定要找到真相!","voice": "zh-CN-YunjianNeural","volume": "40%"},{"desc": "配角","text": "小心,前面有危险...","voice": "zh-CN-XiaoyiNeural","volume": "-20%"}]
}
支持的音频参数调节:
| 参数 | 作用 | 示例值 | 效果 |
|---|---|---|---|
voice | 声音模型选择 | zh-CN-YunxiNeural | 选择不同的声音角色 |
rate | 语速调节 | +20% / -10% | 加快或放慢语速 |
pitch | 音调调节 | +5Hz / -3Hz | 调节声音高低 |
volume | 音量调节 | +40% / -20% | 调节音量大小 |
4. AI智能配音推荐
EasyVoice集成了大模型AI来实现智能配音推荐,这个功能简直就是懒人福音:
AI推荐的优势:
- 自动角色识别:AI自动识别对话中的不同角色
- 情感分析:根据文本情感调整语音参数
- 风格适配:自动适配不同文体的配音风格
- 参数优化:智能优化语速、音调、音量等参数
四、实战案例:制作有声小说
让我们通过一个实际案例来体验EasyVoice的强大功能。假设我们要为一段小说对话制作有声配音:
1. 准备文本内容
旁白:夜深人静,书房里只有翻书的沙沙声。
张三:这个案子太奇怪了,所有的线索都指向同一个人。
李四:你是说王五?可是他昨天还在我这里喝茶呢。
张三:正是因为这样才奇怪!凶手往往就在我们身边。
旁白:两人对视一眼,都从对方眼中看到了震惊。
2. API调用示例
curl -X POST http://localhost:3000/api/v1/tts/generateJson \-H "Content-Type: application/json" \-d '{"data": [{"desc": "旁白","text": "夜深人静,书房里只有翻书的沙沙声。","voice": "zh-CN-YunxiNeural","rate": "-10%","pitch": "-2Hz"},{"desc": "张三","text": "这个案子太奇怪了,所有的线索都指向同一个人。","voice": "zh-CN-YunjianNeural","volume": "20%"},{"desc": "李四", "text": "你是说王五?可是他昨天还在我这里喝茶呢。","voice": "zh-CN-XiaoyiNeural","pitch": "+1Hz"}]}'
3. 效果对比分析
| 传统TTS | EasyVoice多角色配音 |
|---|---|
| 单一声音,略显单调 | 多种声音,层次丰富 |
| 无法区分角色 | 角色声音差异明显 |
| 情感表达有限 | AI智能情感适配 |
| 需要后期处理 | 一键生成专业效果 |
五、性能优化与最佳实践
在实际使用EasyVoice时,掌握一些性能优化技巧可以让你事半功倍:
1. 并发参数调优
EasyVoice支持通过环境变量调节Edge-TTS的并发参数:
# 设置并发限制(建议值:3-8)
EDGE_API_LIMIT=5
调优建议:
- 🔥 服务器部署:可以设置为8-10,充分利用服务器性能
- 💻 个人电脑:建议设置为3-5,避免网络请求过于频繁
- ⚠️ 注意事项:并发过高可能触发API限制
2. 大模型配置优化
对于AI智能配音功能,合理配置大模型可以显著提升效果:
# OpenAI兼容配置
OPENAI_API_KEY=your_api_key
OPENAI_BASE_URL=https://openrouter.ai/api/v1/
MODEL_NAME=deepseek-chat# 或者使用其他兼容服务
OPENAI_BASE_URL=https://api.deepseek.com/v1/
MODEL_NAME=deepseek-reasoner
模型选择建议:
| 使用场景 | 推荐模型 | 特点 |
|---|---|---|
| 日常使用 | DeepSeek-Chat | 响应快速,成本较低 |
| 专业制作 | GPT-4 | 效果最佳,分析精准 |
| 高频使用 | Claude-3 | 平衡性能与成本 |
3. 存储路径规划
合理规划音频文件存储可以提升管理效率:
项目根目录/
├── audio/ # 音频输出目录
│ ├── single/ # 单个音频文件
│ ├── multi-role/ # 多角色配音文件
│ └── subtitle/ # 字幕文件
├── logs/ # 日志文件
└── config/ # 配置文件
六、进阶应用场景
EasyVoice的应用场景远比我们想象的广泛,让我们看看一些创新应用:
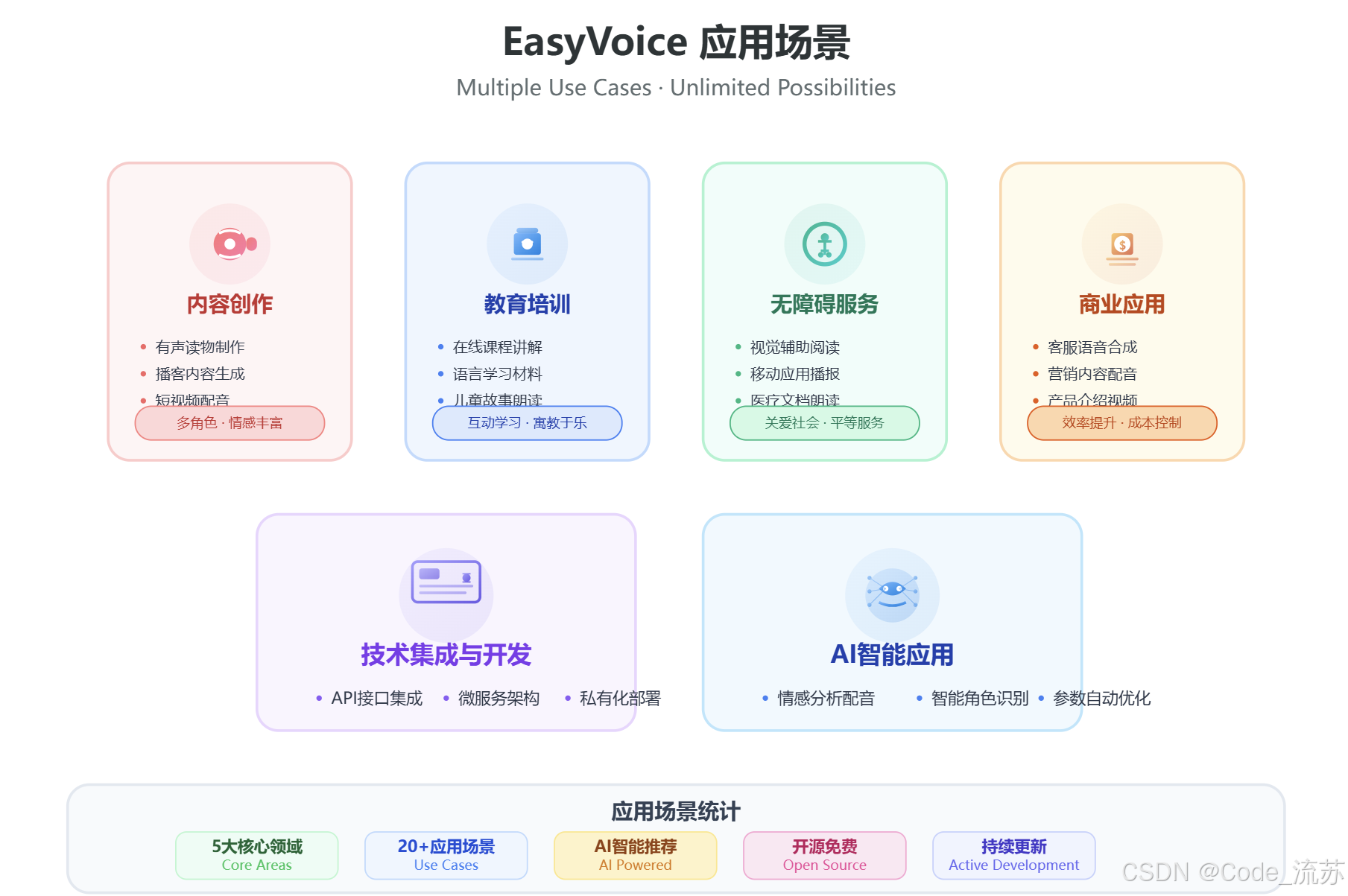
七、与主流TTS工具对比
让我们客观地分析一下EasyVoice在开源TTS生态中的位置:

优势总结:
- 开源免费:无需担心成本和版权问题
- 功能创新:多角色配音和AI推荐配音是独有特色
- 部署灵活:支持私有化部署,数据安全可控
- 持续发展:活跃的开源社区,功能持续更新
八、常见问题解答
在使用EasyVoice过程中,用户经常遇到一些问题,这里整理了最常见的几个:
1. 性能相关问题
Q: AI推荐配音为什么比较慢?
A: AI推荐配音需要经过以下步骤:
- 文本分段处理
- 发送给大模型分析
- 获取配音参数建议
- 生成音频并拼接
优化建议:
- 选择响应更快的大模型(如DeepSeek)
- 调整
EDGE_API_LIMIT参数提高并发 - 对于简单场景可以使用固定声音配音
2. 配置相关问题
Q: 如何配置OpenAI兼容的API?
A: 在.env文件中添加以下配置:
OPENAI_API_KEY=your_api_key
OPENAI_BASE_URL=openai_compatible_base_url
MODEL_NAME=openai_model_name
支持的兼容服务包括:
- OpenRouter:
https://openrouter.ai/api/v1/ - DeepSeek:
https://api.deepseek.com/v1/ - 其他OpenAI兼容服务
3. 部署相关问题
Q: Docker部署后无法访问怎么办?
A: 检查以下几个方面:
- 端口映射:确保
-p 3000:3000正确设置 - 防火墙:检查系统防火墙是否开放3000端口
- 容器状态:使用
docker ps查看容器是否正常运行 - 日志分析:使用
docker logs container_name查看错误日志
总结与建议
EasyVoice作为一款开源文本转语音工具,在功能创新和用户体验方面都表现出色。它不仅解决了传统TTS工具的痛点,还通过多角色配音和AI智能推荐等特色功能,为内容创作者提供了强大的工具支持。
适合使用EasyVoice的场景:
- ✅ 内容创作者:需要制作有声内容的自媒体从业者
- ✅ 教育工作者:希望为教学材料添加语音的老师
- ✅ 开发者:需要为应用集成TTS功能的程序员
- ✅ 企业用户:需要私有化部署TTS服务的公司
使用建议:
- 新手用户:建议从Docker一键部署开始,快速体验功能
- 专业用户:推荐源码部署,便于深度定制和功能扩展
- 团队使用:配置好大模型API,充分利用AI智能推荐功能
- 生产环境:注意性能优化和监控,确保服务稳定性
随着人工智能和语音技术的不断发展,像EasyVoice这样的开源工具将会发挥越来越重要的作用。它不仅降低了技术门槛,让更多人能够享受到先进的语音合成技术,还通过开源的方式推动了整个行业的发展。
项目信息:
- 🌟 GitHub: https://github.com/cosin2077/easyVoice
- 🌐 在线体验: https://easyvoice.ioplus.tech/
如果你正在寻找一款功能强大、使用简单的文本转语音工具,那么EasyVoice绝对值得一试。它不仅能满足你的基本需求,还能通过其独特的功能设计,为你的创作带来更多可能性。
很感谢你能看到这里,如果你有哪些好用在用或者想吐槽的软件,欢迎在评论区分享!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
![[Redis] Redis:高性能内存数据库与分布式架构设计](https://i-blog.csdnimg.cn/direct/b56fff400a73425db7254e4b07301c93.png#pic_center)