苹果炮轰AI推理模型:全是假思考 模式匹配非真思考
article/2025/6/9 8:09:41
苹果炮轰AI推理模型:全是假思考 模式匹配非真思考。苹果近日发布了一篇研究论文,指出包括DeepSeek、o3-mini和Claude 3.7在内的推理模型并未真正进行思考,所谓的思考实际上只是模式匹配。为了更客观地测试这些模型的推理能力,研究人员设计了四类谜题环境:汉诺塔、跳棋交换、过河问题和积木世界。这些谜题的难度可以精确控制。
随着问题难度增加,推理模型最初会延长思考时间,但随后思考深度反而下降。即使仍有充足的token预算,它们在最需要深入思考时却选择了放弃。当问题复杂度继续增加并超过某个临界点时,无论是推理模型还是标准模型都会经历完全的性能崩溃,准确率直线下降至零。

对此,有网友讽刺称:“苹果拥有最多的资金,两年来也没有拿出像样的成果,现在自己落后了,却来否定别人的成果。”据报道,Apple Intelligence在2024年的WWDC上正式亮相。在过去的一年里,苹果宣传中的许多功能都经历了延期、不够完善甚至被下架。不过也有人认为,这篇论文并非完全消极,而是呼吁设立更好的推理机制和评估办法。
相关文章
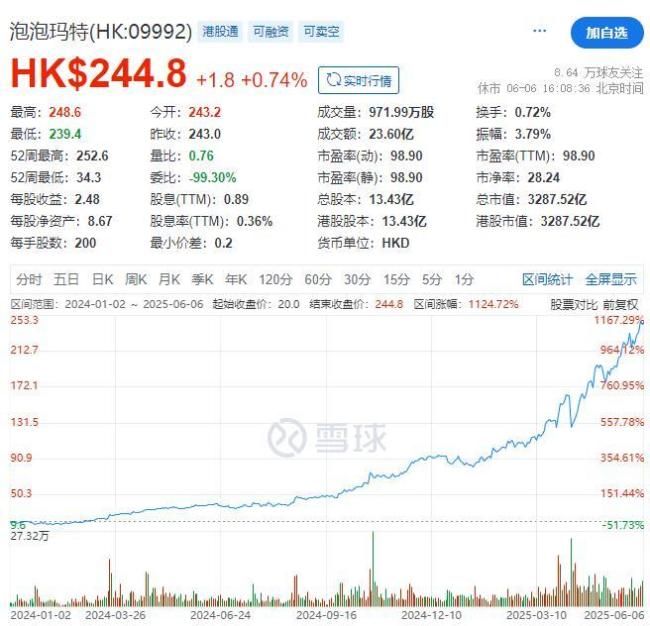
河南首富换人了 王宁取代秦英林登顶
6月8日,根据福布斯实时富豪榜显示,泡泡玛特创始人王宁的身家达到203亿美元,超越牧原股份创始人秦英林的163亿美元,成为河南新首富。近期,泡泡玛特旗下Labubu系列爆火,一些联名或限量款的Labubu更是卖出了几千上万元的天价。Labubu的火爆直接推动了泡泡玛特股价上涨。截至…

天津国际邮轮母港重回双邮轮母港模式
6月8日,随着搭载2000余名旅客的“爱达地中海”号国际邮轮抵达天津,标志着该邮轮以天津港为邮轮母港的正式回归,也标志着天津国际邮轮母港重回“梦想号+地中海号——双邮轮母港模式”。而随着当天晚些时候该轮启程前往日本,也为2025年天津暑期邮轮热拉开了序幕。面对即将到来…

中国女排吴梦洁赛后采访落泪 自责未能更好帮助球队
6月8日,2025世界女排联赛中国北京站在国家体育馆进入到最后一天的比赛。中国队以2:3(25-19、20-25、31-29、26-28、12-15)的成绩不敌土耳其队,中国选手吴梦洁得到17分。赛后,吴梦洁在接受采访时眼含热泪,她认为自己太着急了,没能为球队带来更大帮助。吴梦洁表示:“我觉…

男子被银环蛇咬伤救治十多天化险为夷 抗蛇毒血清显神威
男子被银环蛇咬伤救治十多天化险为夷!今年5月18日,崇左扶绥县的邓先生在田间劳动时被剧毒的银环蛇咬伤,导致呼吸衰竭命悬一线。由于及时注射抗蛇毒血清且抢救得当,邓先生于6月6日顺利出院。近日,毒蛇伤人事件引起较大关注,当地医疗机构也接诊了多例蛇咬伤患者。目前广西抗…

比亚迪汉家族累销突破101万辆 5月销量再创新高
比亚迪汉家族累销突破101万辆 5月销量再创新高!6月8日,比亚迪公布了最新销量数据。其中,王朝系列和海洋系列共销售348393辆,腾势系列销量为15806辆,方程豹系列销量为12592辆,仰望系列销量为139辆。比亚迪汉家族5月销量达到21672辆,累计销量突破101万辆大关。比亚迪海洋网…

万亩水稻疑因污染无水可种 官方回应并采取措施
近日,有网友在社交平台发布视频,称安徽蚌埠市淮上区沫河口镇有河流水体污染,导致周边农民的秧苗死亡,耽误农时。6月8日,蚌埠市及淮上区联合工作组发布情况通报。针对6月6日群众反映的情况,市、区两级迅速成立由多部门组成的联合工作组开展工作。6月6日,工作组委托省直属…

高考历史上3次启用备用卷,第一次竟是因为高考试卷失窃!
高考历史上3次启用备用卷。中国高考历史上有三次启用过备用卷。第一次启用备用卷,是03年四川南充,“高考试卷失窃”事件,为了公平,全省启用备用卷。2003年19岁的杨博在高考前夕避开所有的试卷保护措施,偷了6份试卷,被发现后国家立马启用高考备用卷,难度直接翻了一倍。没…

17岁女孩试裤子店员一眼发现异常 无心提醒成救命关键
17岁的婷婷还在读高二。前段时间,妈妈带着她去逛街买衣服。试裤子时,店员帮忙觉得孩子身形消瘦但肚子却有点大,建议家长带去医院看看。结果一查吓一跳,婷婷的肚子里竟然长了一个巨大的肿瘤,直径长达27厘米。店员无心的提醒成了救命关键。婷婷回忆说,当时在试裤子,店员用…

电视剧《七根心简》开播 奇幻冒险新篇章
6月8日,由优酷出品、蔡岳勋执导的奇幻冒险剧《七根心简》开播。该剧改编自尾鱼的经典小说,原著作者也担任了剧本编审。宋威龙和刘浩存等新生代演员领衔主演,讲述了五个拥有金、木、水、火、土属性的年轻人组成“凤凰小分队”,在“神棍”的指引下踏上收服危害人间的心简的冒…

博主:苏超爆火的关键可能是成本低 低成本促进草根体育繁荣
博主:苏超爆火的关键可能是成本低 低成本促进草根体育繁荣。关于苏超的爆火,很多人将其归因于“天时、地利、人和”以及足球文化等因素。然而,我认为真正的关键在于成本。这些年国内爆火的草根体育赛事有一个共同点:成本特别低。当我们讨论国外社区足球和多级联赛时,往往忽…
专家:忽视刷牙出血或导致牙齿掉光 从出血到掉牙仅三步
专家:忽视刷牙出血或导致牙齿掉光 从出血到掉牙仅三步。牙龈发红、刷牙时出血或啃苹果后留下血印,可能是牙周炎的早期症状。最近,北京大学数学学院教师韦东奕开通了个人账号,视频中网友发现他的牙齿有缺失。据家属回应,韦东奕曾多次治疗牙周炎,还需去医院进一步检查。牙周…

首次、突破、一流!上个周末 大国工程好消息不断
刚刚过去的周末,我国多个工程好消息不断!首次、突破、一流……交出一张亮眼成绩单。实现国际首次突破!中国散裂中子源新设备通过验收2025年6月7日,中国散裂中子源(CSNS)直线加速器首支紧凑型P波段大功率超构材料速调管,在中国科学院高能物理研究所东莞研究部通过各项指标…

特朗普下令解放洛杉矶 驱逐非法移民恢复秩序
美国总统特朗普于6月8日在其社交媒体平台“真实社交”上发文,称洛杉矶被非法移民和罪犯“入侵占领”,暴力叛乱分子聚集并袭击联邦探员,企图阻碍政府的驱逐行动。他指示国土安全部长诺姆、国防部长赫格塞思和司法部长邦迪等官员采取一切必要行动,将洛杉矶从移民入侵中解放出…

马斯克:新党就叫美国党 在线投票获八成支持
马斯克:新党就叫美国党 在线投票获八成支持!马斯克在与美国总统特朗普公开发生争执后,于当地时间5日在社交平台X上发起了一项投票,询问是否应该在美国创建一个真正代表80%中间派的新政党。根据美国哥伦比亚广播公司(CBS)和《国会山报》等媒体的报道,马斯克在6日晚援引该…

考生走出考场直接飙了一段歌剧 情绪的最真实爆发
考生走出考场直接飙了一段歌剧 情绪的最真实爆发。考生走出考场的第一句话,往往是最直接、最真实的情绪爆发,浓缩了备考的压力、临场发挥的感受以及对未来的复杂期待。这些话语像一面镜子,映照出个体心态和群体情绪的缩影。最常见的表达是宣泄型:“终于结束了!”这是长期高…

女孩试裤子店员提醒肚子大查出肿瘤 无心提醒成救命关键
17岁的婷婷还在读高二。前段时间,妈妈带她去逛街买衣服。试裤子时,店员帮忙发现她身形消瘦但肚子有些大,建议家长带她去医院检查。结果一查,发现婷婷肚子里长了一个直径长达27厘米的巨大肿瘤。店员无心的提醒成了救命的关键。婷婷表示,当时在试裤子时,店员摸了下她的肚子…
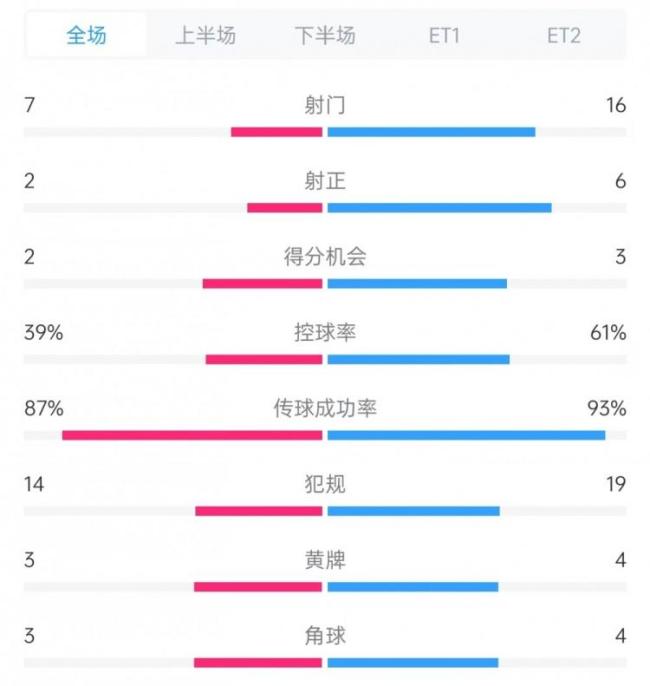
葡萄牙vs西班牙 点球大战定胜负
在欧国联决赛中,葡萄牙与西班牙激战120分钟,最终比分为2-2。随后的点球大战中,葡萄牙胜出,成功夺得冠军。比赛数据如下:射门次数上,西班牙以16次领先于葡萄牙的7次;射正次数方面,西班牙同样占据优势,为6次对2次;进球机会方面,西班牙有3次,而葡萄牙则为2次;控球率方…
京东高薪挖人抢滩酒旅市场 加码布局新赛道
京东近期加大了在酒旅市场的布局力度。公司已启动相关业务,并在业内积极招募人才,甚至有传言称京东以三倍薪资从飞猪、同程、携程等平台挖人。京东在销售方面主打机票“无捆绑”卖点,并为多家酒店提供官方补贴,希望通过高频消费带动低频消费获取新的增长点。事实上,京东早…

特朗普抨击加州州长和洛杉矶市长无能 指责抗议活动失控
美国总统特朗普8日凌晨在社交媒体上再次批评加利福尼亚州州长和洛杉矶市长无能,称连续两天发生的抗议活动是由煽动者和收钱制造麻烦的人发起的,这种行为不会被容忍。他还质疑洛杉矶抗议活动中参与者戴口罩的行为和目的,并表示从现在开始不允许在抗议活动中戴口罩。自6日上午…

洛杉矶骚乱后纽约也乱了 抗议ICE搜捕行动
近日,美国纽约曼哈顿发生了一场示威活动,近150名抗议者与警方发生冲突,反对美国移民与海关执法局(ICE)在该市及全国范围内加大对非法移民的搜捕力度。超过20人在此次冲突中被捕。此前一天,在加利福尼亚州洛杉矶也发生了类似的骚乱。在曼哈顿,愤怒的蒙面示威者对警察大喊…
推荐文章
- 涉嫌抄袭!北京两高校相继通报:启动调查!学术诚信受考验
- 儿媳爷爷得知三口遇难伤心过度去世 一家三口被撞案家属抱儿孙遗照进法院
- 石景山游乐园15日恢复开园 全面排查确保安全
- 分析师:美债美股挑战远未结束 关税不确定性加剧市场波动
- 宁德时代回应美国加征关税 影响可控预案已做
- 马尔代夫宣布禁止以色列人入境 声援巴勒斯坦
- 五胞胎参加高考 五福娃迎人生大考
- 女排庄宇珊:下次就不会给对手机会了 展现女排精神
- 实拍美军坦克装甲车搭乘军列前往华盛顿 准备参加14日阅兵式
- 女子收陌生包裹被骗52万?半年内向全国发出诈骗包裹近百万个
- 李莎旻子在长沙探班周笔畅演唱会 表达对后者长达20年的喜爱
- 《七根心简》双胞胎姐妹互换身份被凶手误杀